java递归实现树形结构数据
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、树形结构是什么?
- 二、实现方案
-
- 1、stream流递归实现
-
- 1.1 实体类
- 1.2 实现类
- 2、jdk1.7以下实现
-
- 2.1 节点类
- 2.2 实现类
- 3、应用场景
-
- 3.1 用于前端方便展示
- 3.2 用于查找并构建子节点数据
- 总结
前言
本文提供两种递归实现思路
树形结构数据,大体的实现思路就是“父找子”,父节点去层层递归寻找子节点,最后组装成数据集合。
提示:以下是本篇文章正文内容,下面案例可供参考
一、树形结构是什么?
树形结构,和我们平常所触及到的无限级菜单,是同一个道理。
所谓树形结构,我们可以将其理解为:树根或者树冠,都可以无限分叉下去。
现有一张表,需要对表中数据进行分级查询(按照上下级关系进行排列),我们常用的数据库有: oracle和mysql;
如果使用oracle的话,使用connect by,很容易就能做到;
但是,mysql没有现成的递归函数,需要我们自己使用存储过程封装,而且,就算封装好了递归函数,mysql在执行的时候,查询速度会很慢。如何解决这个问题呢?
既然数据库不给力,我们只能交由程序来处理了,以减轻mysql数据库的压力。
二、实现方案
1、stream流递归实现
1.1 实体类
public class TreeBean {
/**
* id
*/
private Integer id;
/**
* 名称
*/
private String name;
/**
* 父id ,根节点为0
*/
public Integer parentId;
/**
* 子节点信息
*/
public List<TreeBean> childList;
public TreeBean() {
}
public TreeBean(Integer id, String name, Integer parentId, List<TreeBean> childList) {
this.id = id;
this.name = name;
this.parentId = parentId;
this.childList = childList;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getParentId() {
return parentId;
}
public void setParentId(Integer parentId) {
this.parentId = parentId;
}
public List<TreeBean> getChildList() {
return childList;
}
public void setChildList(List<TreeBean> childList) {
this.childList = childList;
}
/**
* 初始化数据
* @return
*/
public List<TreeBean> initializationData() {
List<TreeBean> list = new ArrayList<>();
TreeBean t1 = new TreeBean(1, "广东省", 0, new ArrayList<>());
TreeBean t2 = new TreeBean(2, "湖南省", 0, new ArrayList<>());
TreeBean t3 = new TreeBean(3, "广州市", 1, new ArrayList<>());
TreeBean t4 = new TreeBean(4, "长沙市", 2, new ArrayList<>());
TreeBean t5 = new TreeBean(5, "白云区", 3, new ArrayList<>());
TreeBean t6 = new TreeBean(6, "黄浦区", 3, new ArrayList<>());
TreeBean t7 = new TreeBean(7, "白云街道", 5, new ArrayList<>());
TreeBean t8 = new TreeBean(8, "深圳市", 1, new ArrayList<>());
TreeBean t9 = new TreeBean(9, "宝安区", 8, new ArrayList<>());
TreeBean t10 = new TreeBean(10, "福田区", 8, new ArrayList<>());
TreeBean t11 = new TreeBean(11, "南山区", 8, new ArrayList<>());
TreeBean t12 = new TreeBean(12, "南山街道", 11, new ArrayList<>());
TreeBean t13 = new TreeBean(13, "芙蓉区", 4, new ArrayList<>());
TreeBean t14 = new TreeBean(14, "岳麓区", 4, new ArrayList<>());
TreeBean t15 = new TreeBean(15, "开福区", 4, new ArrayList<>());
TreeBean t16 = new TreeBean(16, "岳阳市", 2, new ArrayList<>());
TreeBean t17 = new TreeBean(17, "岳麓街道", 14, new ArrayList<>());
list.add(t1);
list.add(t2);
list.add(t3);
list.add(t4);
list.add(t5);
list.add(t6);
list.add(t7);
list.add(t8);
list.add(t9);
list.add(t10);
list.add(t11);
list.add(t12);
list.add(t13);
list.add(t14);
list.add(t15);
list.add(t16);
list.add(t17);
return list;
}
}
1.2 实现类
/**
* 方式一:Stream流递归实现遍历树形结构
*/
public static void treeTest1() {
//获取数据
List<TreeBean> treeBeans = new TreeBean().initializationData();
//获取父节点
List<TreeBean> collect = treeBeans.stream().filter(t -> t.getParentId() == 0).map(
m -> {
m.setChildList(getChildren(m, treeBeans));
return m;
}
).collect(Collectors.toList());
System.out.println(JSON.toJSONString(collect));
}
/**
* 递归查询子节点
* @param root 根节点
* @param all 所有节点
* @return 根节点信息
*/
public static List<TreeBean> getChildren(TreeBean root, List<TreeBean> all) {
List<TreeBean> children = all.stream().filter(t -> {
return Objects.equals(t.getParentId(), root.getId());
}).map(
m -> {
m.setChildList(getChildren(m, all));
return m;
}
).collect(Collectors.toList());
return children;
}
2、jdk1.7以下实现
2.1 节点类
便于提供前端取值

2.2 实现类
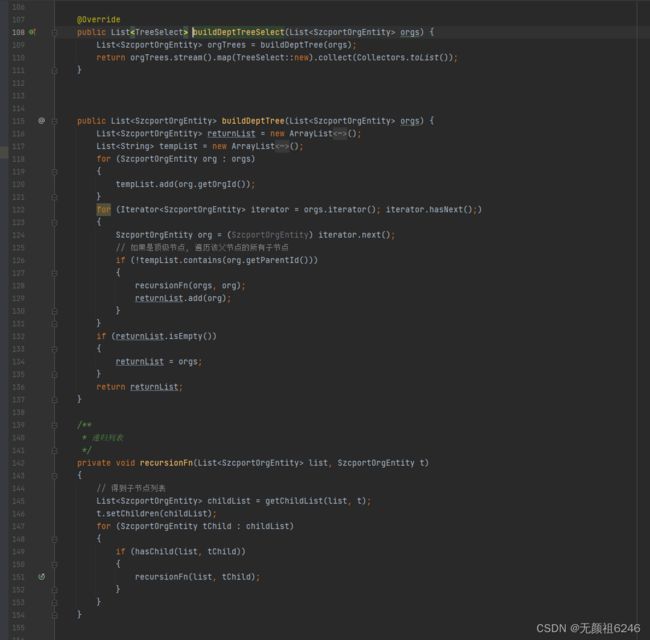
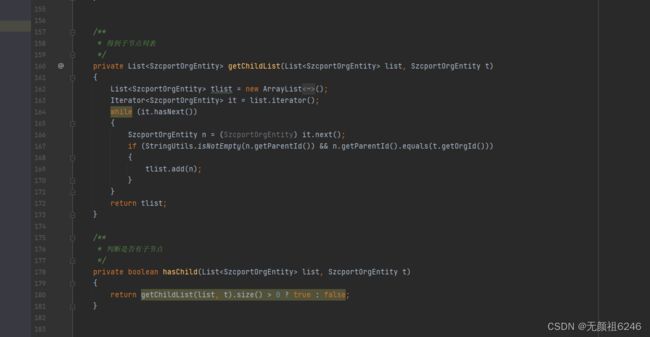
3、应用场景
3.1 用于前端方便展示

3.2 用于查找并构建子节点数据
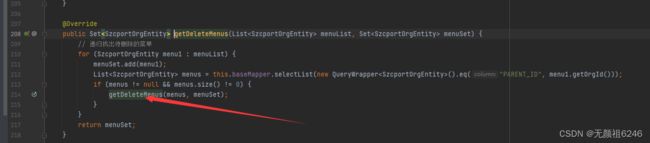
以删除菜单做例子,一般菜单未免会带子菜单,所以,“父找子” 需求应声而来;
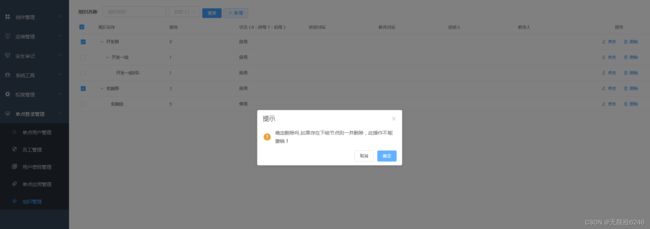
代码如下:

总结
资料参考:
链接1: java 树形数据处理(Stream流和Map两种方式实现)
链接2: java 递归实现树形结构的两种实现方式
哪位大佬如若发现文章存在纰漏之处或需要补充更多内容,欢迎留言!!!