【Redis7】--5.复制、哨兵
文章目录
- 复制
-
- 1.环境配置
- 2.一主二仆
- 3.常见问题
- 4.薪火相传
- 5.反客为主
- 6.复制原理和工作流程
- 7.复制的缺点
- 哨兵
-
- 1.环境配置
-
- 1.1配置三个哨兵实例
- 1.2修改哨兵配置文件的内容
- 1.3配置主节点的访问密码
- 2.实操演示
-
- 2.1启动三个哨兵实例
- 2.2测试主从复制
- 2.3查看sentinel日志文件
- 2.4模拟master节点宕机
- 3.哨兵的选举流程
- 4.总结
复制
Redis复制是Redis的一项核心功能,用于将一个Redis数据库的所有数据复制到另一个Redis实例上,Redis复制可以提高系统的可用性、可靠性和扩展性,使得在发送故障时可以快速地恢复数据
Redis复制支持主从复制和从从复制两种方式,可以根据实际情况选择不同的方式来部署和管理Redis实例
- 主从复制
- 从从复制

就是主从复制,master以写为主,slave以读为主
当master数据变化的时候,自动将新的数据异步同步到到其他slave数据库
1.环境配置
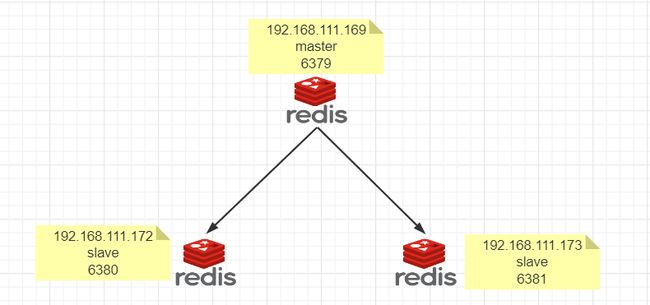
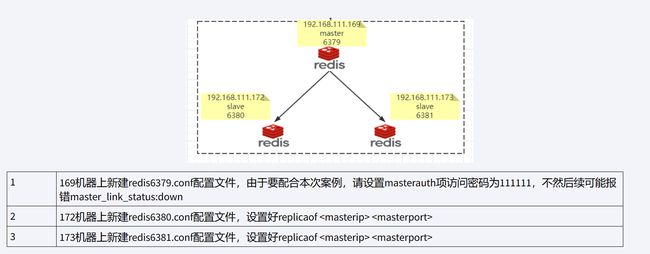
(1)克隆两个虚拟机,一主二仆,Redis设为主节点,Redis1和Redis2设为从节点
(2)三边网络都ping通且关闭防火墙
(3)修改redis.conf配置文件(redis6379.conf为例)
直接把最初的配置文件复制到之前自定义生成的/myredis下面,命名加上端口号
- 开启daemonize yes

- 注释掉bind 127.0.0.1

- protected-mode no

- 指定端口

- 指定当前工作目录,dir

- pid文件名字,pidfile

- log文件名字,logfile

- requirepass

- dump.rdb名字

- aof文件,appendfilename
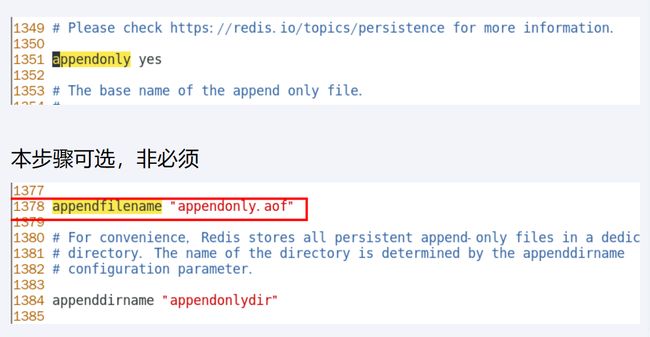
- 从机需要配置,主机不用
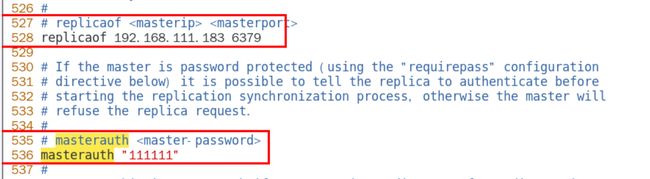
2.一主二仆
从节点配置了需要连接的主节点后,打开Redis客户端即可自动连接到主节点。并且开始同步主节点的数据。
这里我们需要先主后从依次启动服务端 server,这里读取刚刚写好的配置文件,同时记得这次启动要写好端口号,要不然默认访问6379,而配置文件又没配置6379在哪。
配从库不配主库
- 配置从机6380
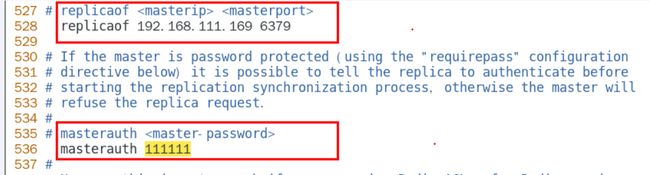
- 配置从机6381

先master后两台slave依次启动
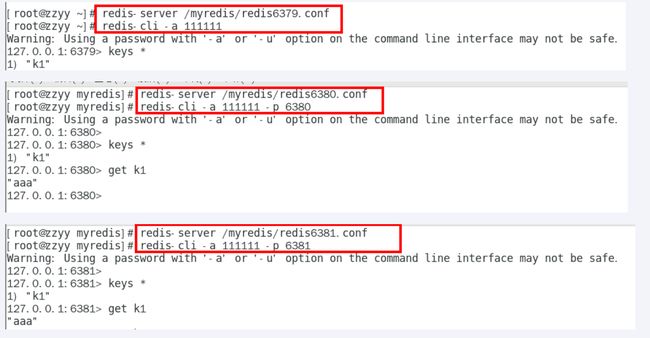
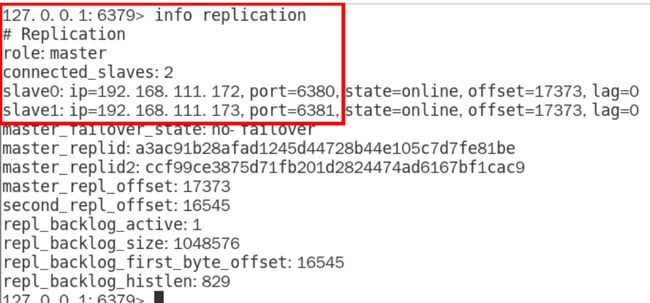
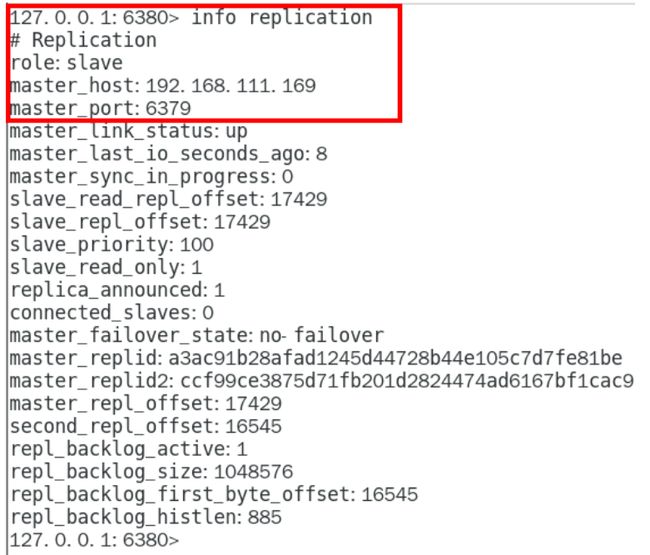
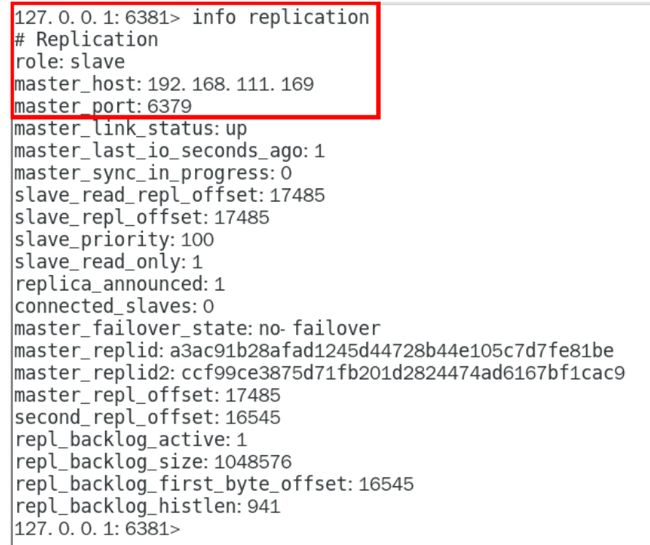
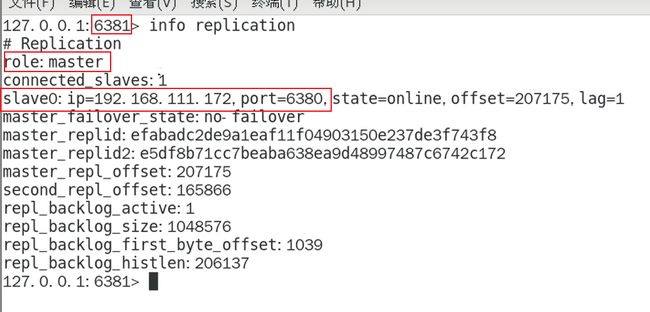
主从关系查看
主机日志:
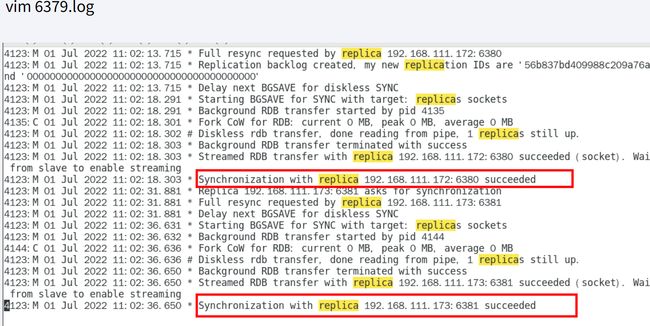
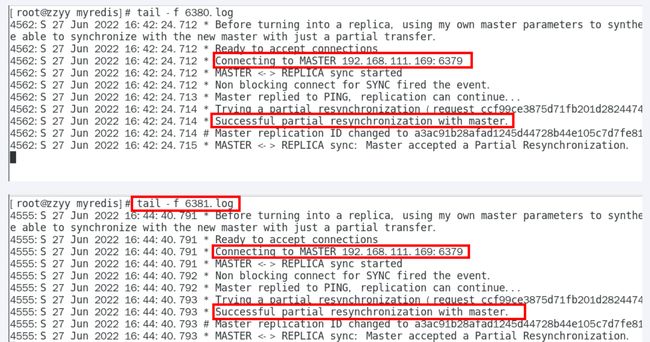
从机日志:
命令:使用info replication命令查看
 ‘
‘
3.常见问题
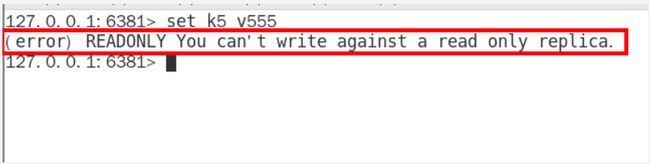
1.从机可以执行写命令吗?
slave不可以执行写命令。master负责写命令,slave负责读命令,当然master也可以读命令。
即使slave是另一台slave的master,也不能执行写命令。
2.slave是从头开始复制还是从切入点开始复制?
在 Redis 复制中,从节点(Slave)可以选择从头开始复制或者从切入点开始复制。
当从节点第一次连接主节点时,如果主节点没有持久化数据,从节点将从头开始复制。即主节点会将自己的全部数据发送给从节点,从节点将接收并保存全部数据。
当从节点与主节点已经建立了连接,并且已经有了初始数据同步,如果从节点断开与主节点的连接后重新连接,从节点可以选择从上次同步的位置(复制偏移量)继续同步数据,这样可以避免从头开始复制所带来的性能影响和数据冗余。
(master会检查backlog里面的offset,master和slave都会保存一个复制的offset和一个masterId)需要注意的是,如果从节点断开与主节点的连接时间过长,主节点可能已经自动执行了 BGSAVE 命令,生成了新的 RDB 文件,此时从节点需要从头开始复制。此外,如果从节点的内存不足,也可能需要从头开始复制,以避免内存溢出。
比如master写到k3,slave启动后会同步k3及之前的数据,然后跟随master同步数据。
3.主机shutdown后,从机会上位吗?
主节点关闭后,从节点不会变成主节点,它们会等待主节点重新启动,但是从节点的数据可以正常读取。
主节点重启后,主从关系依旧存在。
上面的配置都是配置文件固定写死
还可以使用命令操作手动指定
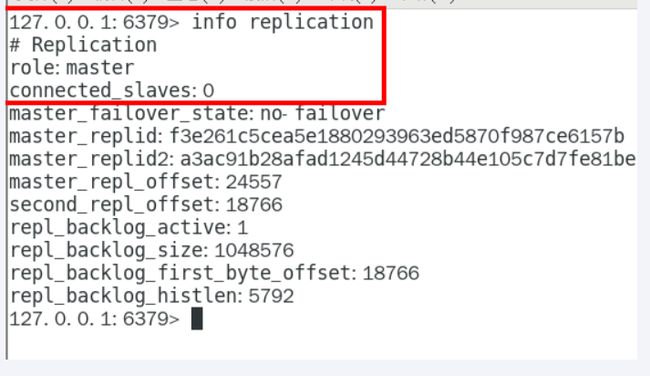
从机停机去掉配置文件中的配置项,3台目前都是主机状态,各不从属
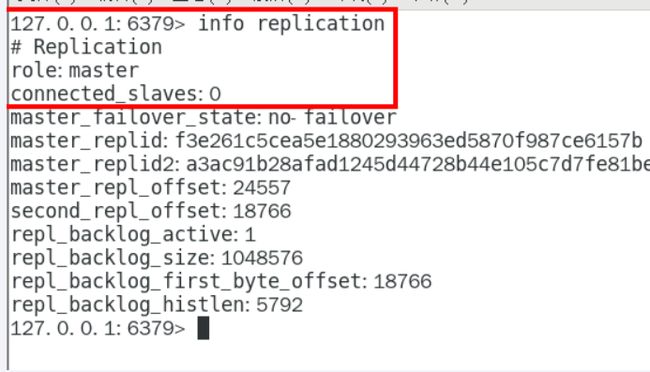
3台主机:
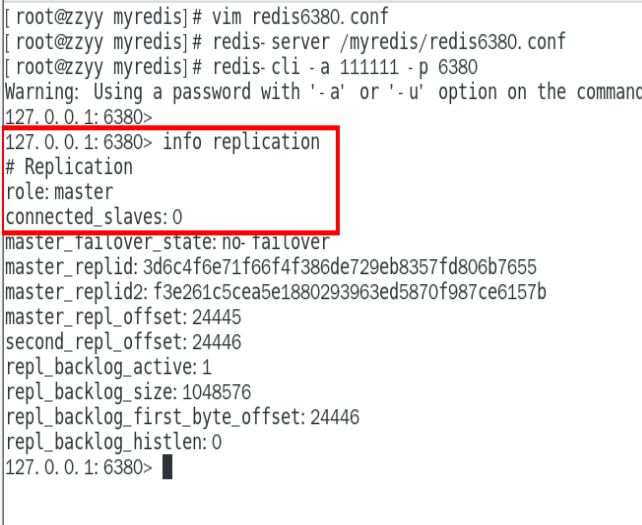
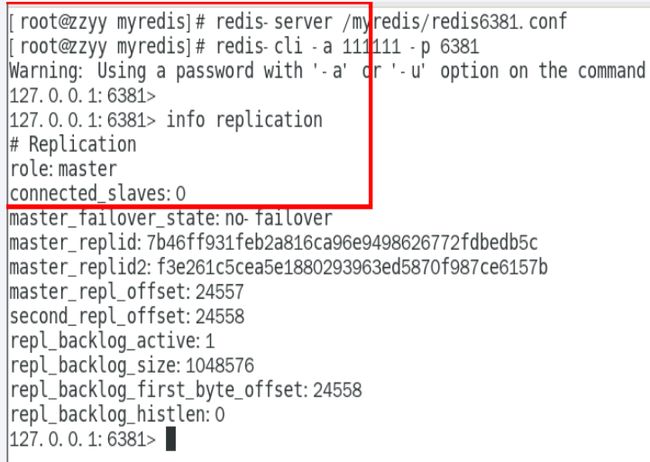
预设的从机上执行命令:slaveof主库IP 主库端口
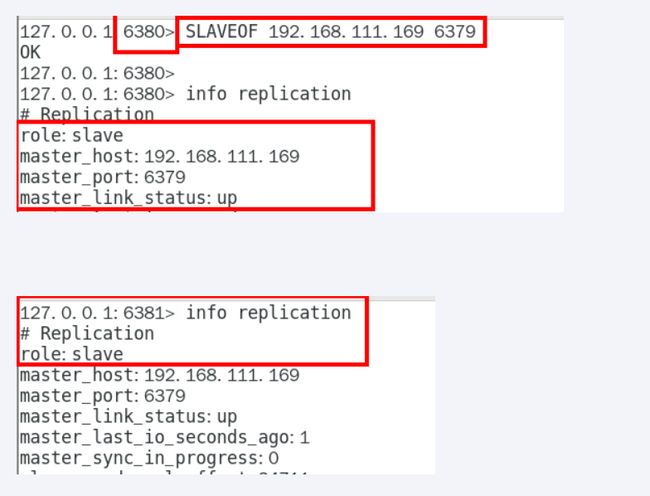
用命令使用的话,2台从机重启后,关系还在吗?
重启后,关系不在,临时命令,只是单次生效
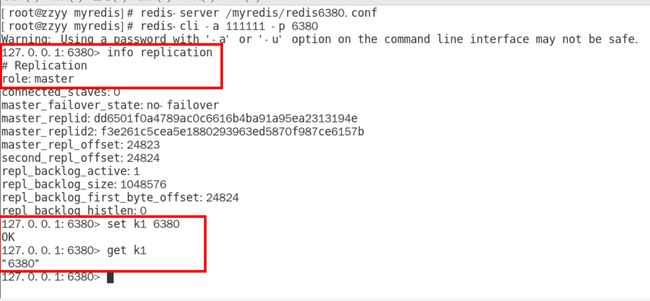
配置文件vs命令
配置文件:持久稳定
命令:当次生效
4.薪火相传
上一个slave可以是下一个slave的master,slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master,可以有效减轻主master的写压力
中途变更转向:会清除之前的数据,重新建立拷贝最新的
命令:slaveof 新主库IP 新主库端口
5.反客为主
命令:slaveof no one
使当前数据库停止与其他数据库的同步,转成主数据库
6.复制原理和工作流程
(1)从节点向主节点发送 SYNC 命令,请求全量复制。
(2)主节点接收到 SYNC 命令后,开始执行 BGSAVE 命令生成 RDB 文件,并在生成过程中记录所有执行的写命令。
(3)主节点在 BGSAVE 命令执行完毕后,将生成的 RDB 文件发送给从节点,同时将在执行 BGSAVE 命令期间记录的写命令发送给从节点,让从节点进行执行。
(4)从节点接收到主节点发送的 RDB 文件和写命令,并执行相应的操作来保持与主节点的数据一致。
(5)从节点持续监听主节点发来的新命令,并将其执行,以保持与主节点的数据同步。
(6)为了保持主节点和从节点之间的通信,master会发出PING包的周期默认是10秒:repl-ping-replica-period 10(在661行)
(6)当主节点发生故障时,从节点会尝试与其他主节点建立连接,并选举出一个新的主节点,从而成为新的从节点,保证系统的可用性和可靠性。

需要注意的是,Redis 复制是异步的,因此从节点可能存在数据不一致的情况。为了避免数据不一致,可以设置 Redis 的复制偏移量(replication offset),当从节点与主节点连接断开后,从节点可以通过该偏移量快速地同步数据。
7.复制的缺点
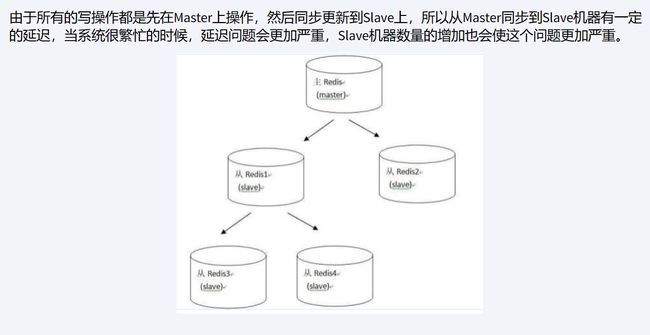
(1)数据同步延迟:由于 Redis 复制是异步的,从节点的数据可能会与主节点存在一定的延迟,因此从节点可能无法实时获取到最新的数据
(2)单点故障:当主节点发生故障时,需要手动进行故障转移或者使用集群来保证系统的可用性
(3)网络通信问题:当网络出现故障或者通信延迟过高时,复制的效率会受到影响,从节点可能无法及时接收到主节点发送的数据
(4)内存消耗问题:当从节点处理不过来主节点发送过来的写命令时,从节点会自动触发执行全量复制,这会导致从节点内存消耗变大
(5)数据安全问题:当主节点的数据被误删或者篡改时,从节点也会受到影响,因此需要采取一定的措施来保证数据的安全性
需要注意的是,这些缺点并不是 Redis 复制本身的问题,而是分布式系统中常见的问题,需要根据实际情况进行综合考虑和处理
哨兵
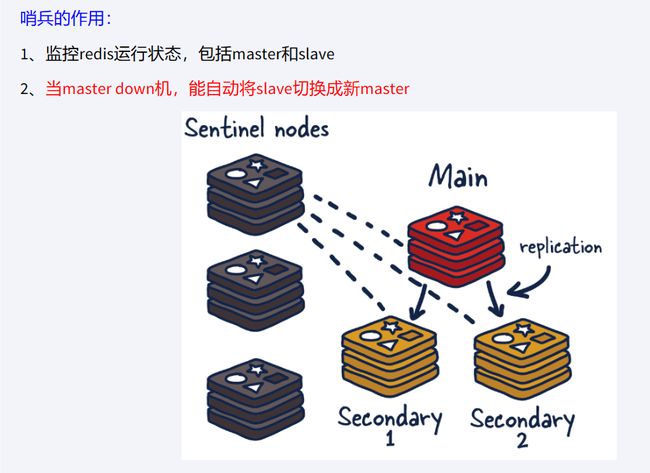
Redis Sentinel(哨兵)是Redis的高可用性解决方案之一,它可以用于监控和管理Redis主从复制集群,并在主节点发生故障时自动将节点升级为新的主节点,从而保证系统的高可用性和可靠性
Redis Sentinel 的主要功能如下:
1.监控 Redis 主节点和从节点的状态,包括节点的可用性、延迟等情况。
2.自动发现和识别 Redis 主从复制集群的拓扑结构。
3.在主节点发生故障时,自动将从节点升级为新的主节点,并将其他从节点重新连接到新的主节点。
4.支持 Redis 集群的自动故障转移、故障恢复和配置管理等功能。
5.提供监控和管理 Redis 集群的 API 和命令行工具。

1.环境配置
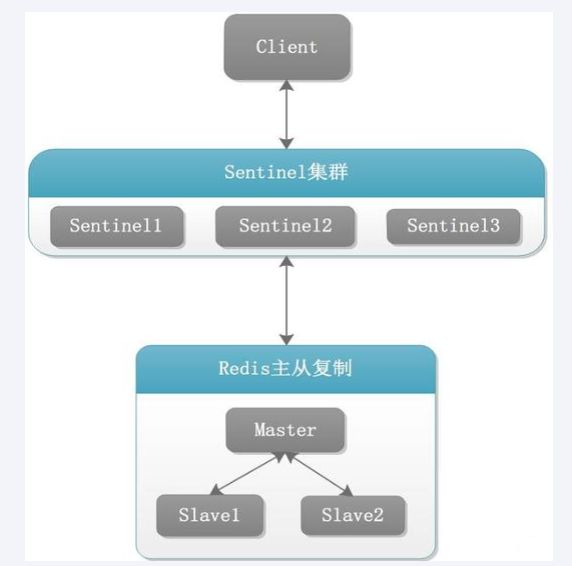
前提说明:
3个哨兵:自动监控和维护集群,不存放数据,只是吹哨人
1主2从:用于数据读取和存放
1.1配置三个哨兵实例
三个哨兵实例需要三台虚拟机,考虑到机器性能有限,这里将三个哨兵实例配置到一台虚拟机上(这里配置到主节点的那台虚拟机),配置三份不同的哨兵配置文件即可:sentinel26379.conf、sentinel26380.conf、sentinel26381.conf,将它们存放到/myredis下。
1.2修改哨兵配置文件的内容
/myredis目录下新建或拷贝sentinel.conf内容,名字不能错
先查看/opt目录下默认的sentinel.conf文件的内容
基础配置

- 关闭保护模式:protected-mode no
- 开启后台运行:daemonize yes
- 配置哨兵服务端口号:port 26379 (三个文件要不一样)
- 日志文件路径:logfile “/myredis/sentinel26379.log”
- pid文件路径:pidfile /var/run/redis-sentinel26379.pid
- 工作目录:dir /myredis
主要配置
- 设置要监控的master:
master monitor

master-name:给master取的名字。
quorum:同意故障迁移的法定票数。即表示有几个哨兵认可主观下线。达到一定票数后认定为客观下线(宕机、不可用)
- 配置连接master服务的密码:
sentinel-auth-pass
其他配置
sentinel down-after-milliseconds
指定多少毫秒之后,主节点没有应答哨兵,此时哨兵主观上认为主节点下线
sentinel parallel-syncs
表示允许并行同步的slave个数,当Master挂了后,哨兵会选出新的Master,此时,剩余的slave会向新的master发起同步数据
sentinel failover-timeout
故障转移的超时时间,进行故障转移时,如果超过设置的毫秒,表示故障转移失败
sentinel notification-script
配置当某一事件发生时所需要执行的脚本
sentinel client-reconfig-script
客户端重新配置主节点参数脚本
去除配置文件的注释,最终配置文件sentinel26379.conf的内容如下,sentinel26380.conf和sentinel26381.conf稍作修改即可
bind 0.0.0.0
daemonize yes
protected-mode no
port 26379
logfile "/myredis/sentinel26379.log"
pidfile /var/run/redis-sentinel26379.pid
dir /myredis
sentinel monitor mymaster 192.168.101.110 6379 2
sentinel auth-pass mymaster 123456
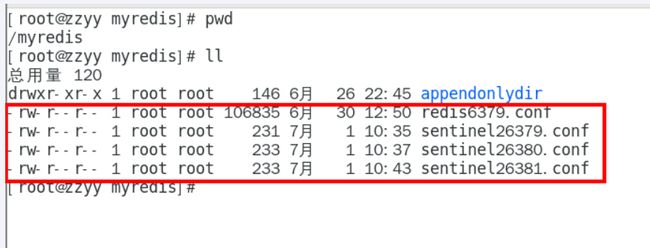
1.3配置主节点的访问密码
主节点宕机后,哨兵会选举一个从节点作为主节点,而之前的主节点会变成从节点,所以需要配置访问新主节点的密码。
这里所有节点都设置为同一密码,方便操作。
2.实操演示
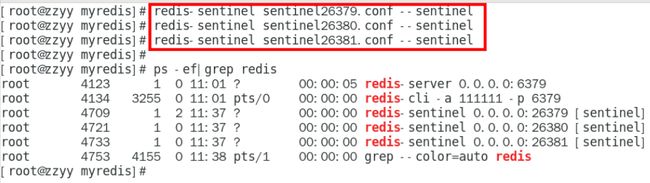
2.1启动三个哨兵实例
这里在redis(6379)那台机器上启动三个哨兵实例。
启动哨兵服务有两种方式:
- 使用redis-sentinel程序启动:redis-sentinel sentinel.conf
- 使用redis-server程序启动:redis-server sentinel.conf --sentinel
启动3个哨兵,完成监控:
-
redis-sentinel sentinel26379.conf --sentinel
-
redis-sentinel sentinel26380.conf --sentinel
-
redis-sentinel sentinel26381.conf --sentinel
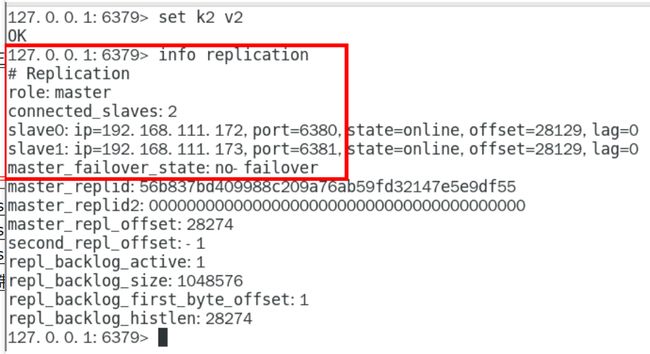
2.2测试主从复制
启动3个哨兵监控后再测试一次主从复制
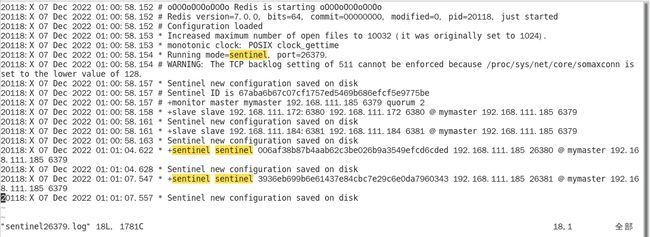
2.3查看sentinel日志文件
工作中排查问题肯定是要去查日志文件,这里可以发现,每个哨兵都会在日志把主机和从机记录,也会把所有其他哨兵一并记录,日志中写明他们保存在 disk,也就是磁盘里,那么我们要去哪里找到他们呢?
其实这里是重写了conf的配置文件,把相应的关系和信息都写入配置文件里了。
查看sentinel26379.log文件的主要内容:
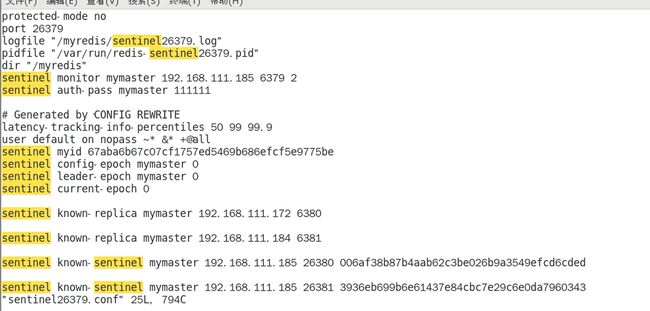
新配置保存到磁盘的意思就是新配置信息写入到sentinel.conf文件中,下面查看sentinel26379.conf文件新增的内容:
了解Broken pipe

2.4模拟master节点宕机
关闭master节点后,哨兵会重新选举一个从节点作为新的主节点。
首先三个哨兵实例会投票选举一个哨兵实例作为领导者,然后由该哨兵实例来选举一个新的主节点并且进行故障迁移(failover)
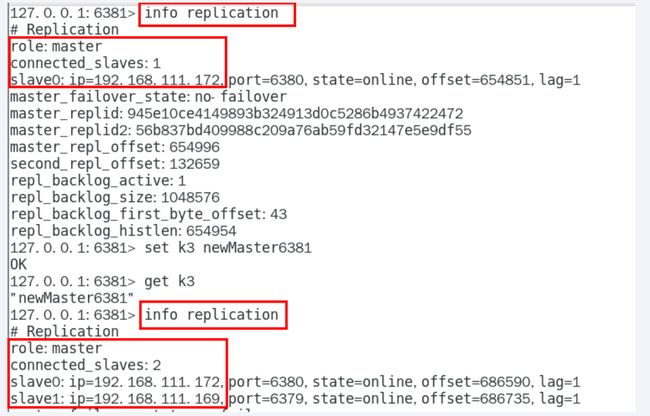
查看6380主从关系
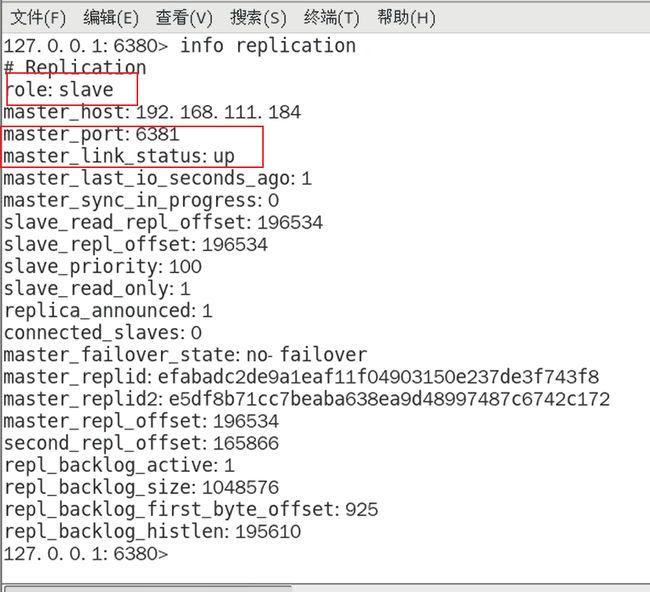
6381是master,从机为6380
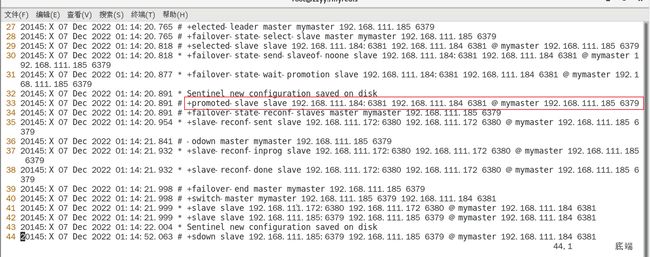
查看sentinel26379.log日志文件了解哨兵选举的过程:
redis6379实例由之前的主节点变为从节点

sentinel26381日志文件
选举新master6381为master
谁是master
6381被选为新master,上位成功
以前的6379从master降级变成了slave
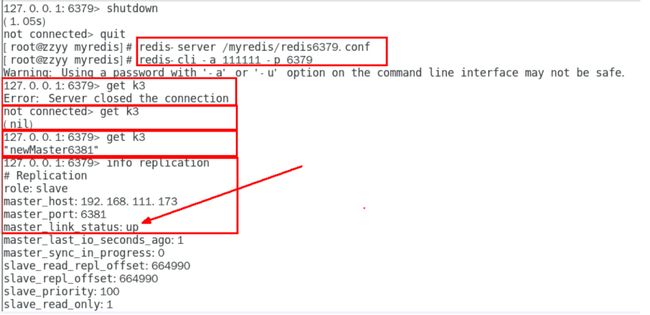
6380还是slave,只不过换了个新老大6381
对比配置文件
- 文件的内容,在运行期间会被sentinel动态进行更改
- master-slave切换后,master_redis.conf、slave_redis.conf和sentinel.conf的内容都会发生改变,即master_redis.conf中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换
3.哨兵的选举流程
哨兵检测到主节点不可用:当哨兵检测到主节点不可用时,会将主节点标记为下线状态(sdown),并向其他哨兵发送通知,通知其他哨兵主节点已经下线,其他哨兵也标记主节点下线后(odown),确定主节点不可用。
主观下线(sdown):指的是单个Sentinel实例对服务器做出的下线判断,即单个sentinel认为某个服务下线(有可能是接收不到订阅,之间的网络不通等等原因)。主观下线就是说如果服务器在sentinel down-after-milliseconds给定的毫秒数之内没有回应PING命令或者返回一个错误消息, 那么这个Sentinel会主观的(单方面的)认为这个master不可以用了。默认30秒。
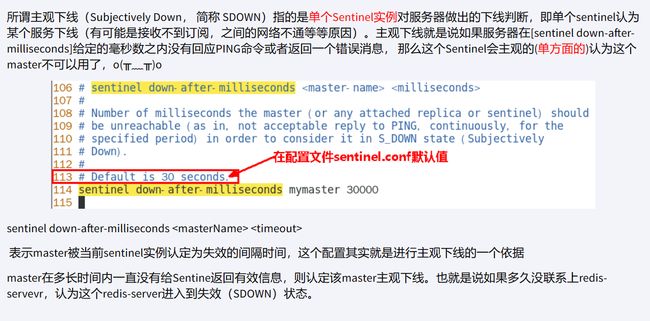
客观下线(odown):客观下线需要多个哨兵达成一致意见才能认为主节点真正不可用。
quorum(票数)这个参数是进行客观下线的一个依据。法定人数/法定票数(quorum)
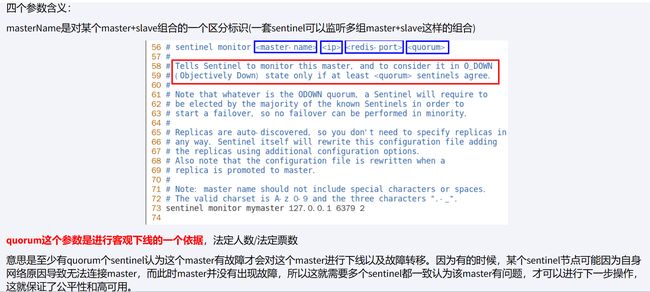
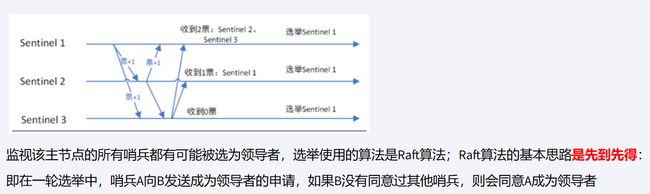
哨兵投票选举哨兵leader:哨兵在检测到主节点不可用后,会进入选举状态,此时哨兵将开始选举哨兵的领导者。(哨兵中选出一个兵王)
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;Raft算法的基本思路是先到先得:
1要票,23没有投过,要票成功,2要票,只能要到1,3要票,要不到,都投过,应该是没人手里一张票
哨兵leader开始推动故障切换流程并选举出一个新的master
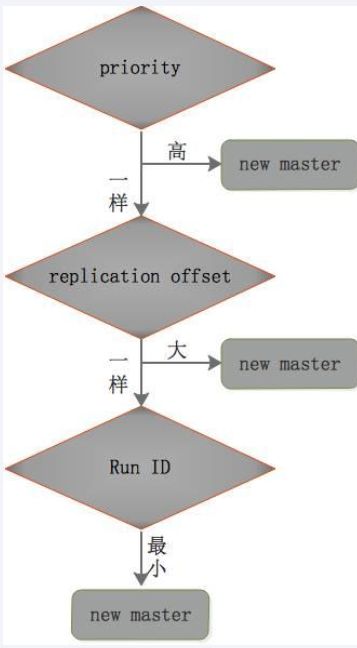
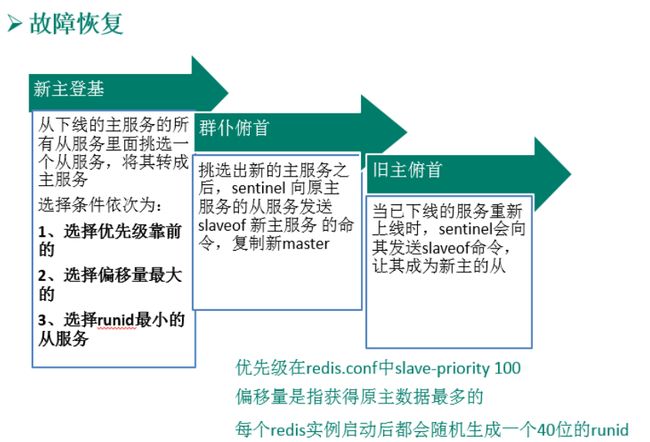
在从节点中选出新的master的规则:
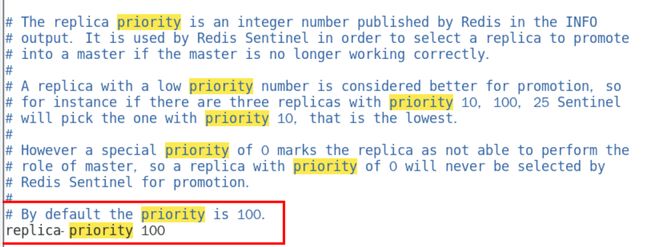
①redis.conf中优先级slave-priority或replica-priority高的从节点优先(数值越小优先级越高)
②复制偏移量(offset)大的从节点优先。
③Run ID最小的从节点优先(按字典顺序、ASCII码值比较),每个redis实例启动后都会随机生成一个40位的run id。
选举出新的master后由Sentinel leader完成failover工作(故障切换)
- 执行slaveof no one命令让选出来的从节点成为新的主节点,并通过slaveof命令让其他节点(包括原来的master)成为新主节点的从节点。
- Sentinel leader会向被重新配置的实例发送一个 CONFIG REWRITE 命令, 从而确保这些配置会持久化在硬盘里(写入配置文件)。
- 将之前已下线的老master设置为新选出的新master的从节点,当老master重新上线,它会成为新master的从节点,sentinel leader会让原来的master降级为slave并恢复正常工作。不用上线,就已经在log中写为slave,下次上线会对它重新配置。

4.总结
- 哨兵实例的数量应为多个,哨兵本身应该集群,保证高可用
- 哨兵实例的个数应该为奇数,方便投票选出Sentinel Leader
- 各个哨兵实例的配置应该一致
- 哨兵集群+主从复制,并不能保证数据零丢失(引出集群cluster,集群可以解决这一问题)
master宕机后,哨兵需要在一定时间内选出新的master并执行failover操作,这段时间内从节点无法写入数据,造成数据丢失。