论文 Stacked Cross Attention for Image-Text Matching 浅析(SCAN方法)
文章目录
-
- 1.前言
- 2.原理
-
- 2.1 Stacked Cross Attention(SCAN)
-
- 2.1.1 Image-Text Stacked Cross Attention.
- 2.1.2 Text-Image Stacked Cross Attention.
- 2.2 图像和文本的对齐
- 2.3 faster R-CNN图像特征框的提取
- 2.4 bi-directional GRU
- 3 总结
1.前言
这篇文章是2018年发表在ECCV上的一篇文章,文章主要研究了图像-文本的匹配问题,将不同模态的区域图像和段落中的单词进行对齐,最终进行图像-句子和句子-图像双向检索。作者提出了SCAN的方法,接下来将对论文原理进行解读。
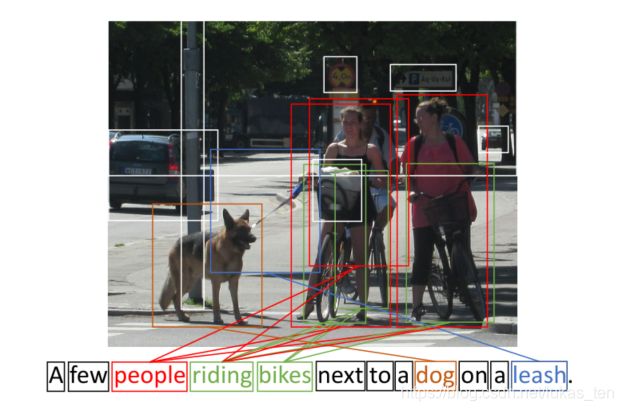
2.原理
先上论文的框架图:

2.1 Stacked Cross Attention(SCAN)
网络有两个输入,分别是图像特征集V = {v1, …, vk}和单词特征集E = {e1, …, en}
2.1.1 Image-Text Stacked Cross Attention.
先求图像特征和词特征的similarity :
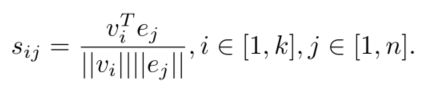
【注:在代码中,有self.fc = nn.Linear(img_dim, embed_size)规定了图像特征的输出向量长度为embed_size,且self.rnn = nn.GRU(word_dim, embed_size, num_layers, batch_first=True, bidirectional=use_bi_gru)规定了GRU词特征的输出向量长度也为embed_size,故上面求相似度的公式可以将图像的特征和单词特征进行内积。】
接着对图像和单词特征的相似度进行归一化处理:
![]()
将归一化后的相似度进行softmax处理,使其概率密度和为1:
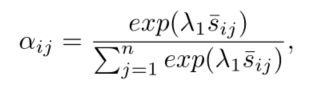
每个图像和段落中所有词向量加权求和(进行这一步操作可以考虑单词前后的语义关联):
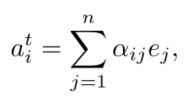
引入cosine函数,来计算图像特征vi和前面计算得到的ai的相似度:
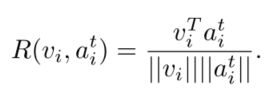
利用Log-SumExp pooling (LSE) 操作,得到整张图片图片I和段落T的相似度:
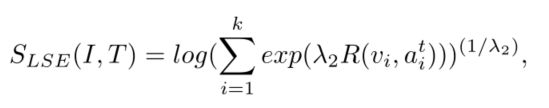
或者也可以用平均池化average pooling (AVG)来计算相似度:
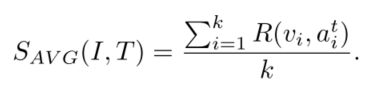
以上两个相似度可以用来度量图像特征和句子单词的匹配程度,值越高说明相关联程度越大。
2.1.2 Text-Image Stacked Cross Attention.
这部分的内容和前面 Image-Text的过程差不多,首先归一化相似度s,这个相似度s用cosine求得,用来衡量图像i区域和第j个单词的相似度:
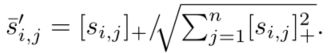
对上面得到的s进行softmax,使其概率密度和为1:
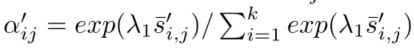
接着计算每个单词对应所有图像特征v的加权和:
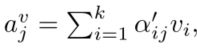
计算第j个单词和图像的相关联程度:
![]()
最终通过lse计算句子和图像的相似度分数:
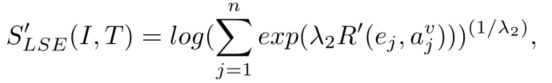
或者也可以利用平均池化计算相似度:
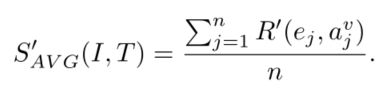
到这里,我们得到了图像-文本的相似度和文本-图像的相似度。
2.2 图像和文本的对齐
作者用了三元损失函数(triplet loss)计算总的损失来训练模型:
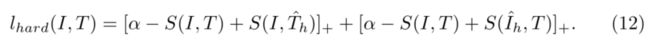
其中a代表margin,是一个常量,它的值越大可以迫使模型努力学习出让正样本和负样本的distance值越大,或者使两张相同类别的distance值更小。
Th正样本和Ih负样本的选取方式如下:
![]()
![]()
即是选取除了本身anchor之外相似度最高的图片和文本作为负样本来训练模型。
2.3 faster R-CNN图像特征框的提取
这里作者引入的是一个预训练好的模型,用来从全局图像中提取出有物体的区域,也就是前面提到的vi。论文中只是略讲了一下,需要学习完整的理论知识请移步bilibili。点此链接
2.4 bi-directional GRU
GRU是训练序列模型的网络,用来提取文本的特征。论文中用双向gru,提取两个方向的信息,最终将向量与句子上下文一起映射得到最终单词特征ei。
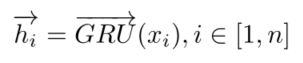
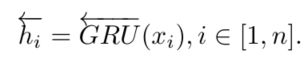
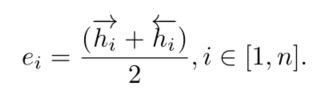
3 总结
在2020的CVPR中作者陈辉在这篇论文的基础上,提出了IMRAM的方法,检索性能有了进一步提升,感兴趣的朋友可以看看这篇论文。论文下载链接