文本编辑命令和正则表达式
前言
正则表达式其实就是对文件内容的 增 删 改 查。
需要注意,正则表达式只能用于文本内容,不能对文件本身进行操作。
下面介绍文本三剑客之一的grep
Linux文本三剑客之一的grep
grep的功能就是查找和过滤
过滤(查找文本内容---正则表达式一块使用)
grep命令都是对 行 来进行处理
grep的相关命令
-v :取反
Cat /etc/fstab | grep -v “^$”
例如,此命令用于过滤 /etc/fstab中的非空行
-m:多个匹配只取第一行
grep -m 2 "root" /etc/passwd
# -m后一定得加数字,数字表示匹配之后多取几个
-n:显示匹配内容以及显示匹配行号
grep -n "root" /etc/passwd
#过滤root所在行,并且显示行号
-o:仅显示匹配到的字符,不再输出其他内容
grep -o "root" /etc/passwd
#过滤root,仅显示匹配到的字符,不显示所在行的其他内容
-q:什么都不显示,静默模式
grep -q "root" /etc/passwd![]()
-A(after):显示匹配到的行,并且显示匹配到的后几行(可自定义)
grep -A 3 "root" /etc/passwd
#过滤"root"所在行,并且显示这一行的后三行
-B(before:前几行):显示匹配到的行以及他的后几行,可自定义
grep -B 2 "hj" /etc/passwd
#显示"hj"所在行,并且显示该行的前两行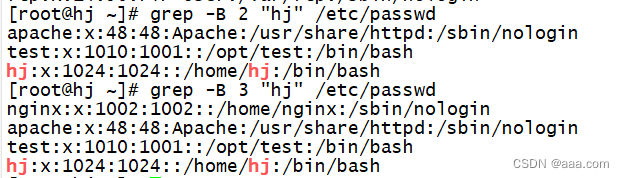
-C(前后各几行):显示匹配到的行以及他的前几行和后几行,可自定义
grep -C 3 "gdm" /etc/passwd
#匹配"gdm"所在行的前三行和后三行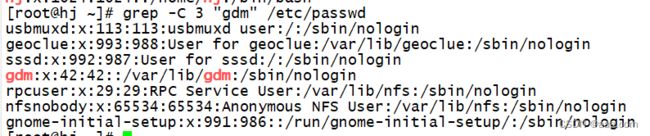
-e:实现多个逻辑或的关系
grep -e "root" -e "bash" -e "hj" /etc/passwd
#在/etc/passwd下,匹配含有"root","bash","hj"的行
-E:使用正则表达式
-f:过滤两个文件的相同内容

-r:递归目录,所有包含过滤内容的文件以及匹配的内容行,但是不处理软连接
grep -r "sh" /opt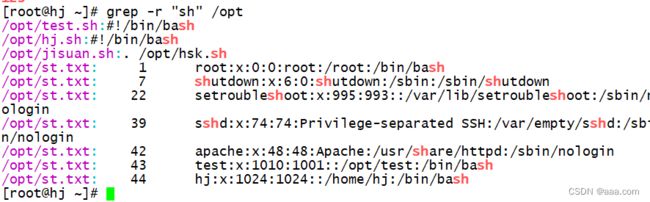
-R:递归目录下,所有包含过滤内容的文件以及匹配的内容行,可以处理软连接
管道符 | :常与grep一起使用
例如: cat /etc/passwd | grep -n "root"
前面的执行结果为管道符后面运行的参数
sort命令:以 行 为单位,对文本内容进行排序也可以根据不同的数据类型进行排序
格式
sort 选项 参数
cat /etc/passwd | sort 选项
-b:忽略每行前面的空格,进行排序而不是把空格缩进
-n:对数字进行排序(默认正向)
-r:反向排序
-u:去重,相同的数据行只显示一行
-o:输出文件,把排序后的结果,输出到指定的内容文件
思考题:怎么样不改变原文件的排序顺序,输出到另一个文件
cat -n /etc/passwd | sort -n -o /opt/st.txt
快捷去重命令 uniq:报告或者忽略文件中连续的重复行,常用于sort命令结合使用
格式:
uniq 选项 参数
cat 文件名 | uniq 选项
-c:统计连续重复的行的次数,合并重复的行
-u:显示仅出现一次的行,包括不连续的重复行
-d:仅显示重复出现的行(必须是连续的重复行)

tr:对字符进行替换,压缩,删除
格式:
tr 选项 参数
例如: echo 123 | tr 选项
常见选项:
-c:保留字符集1的字符,其他字符用字符集2来进行替换
echo abc | tr -c "ab" "z"
#"ab"为字符集1,因此"c"为字符集2,将“z”与字符集2"c",进行替换
#默认结尾会多打印一个,并且此操作必须要保留一个字符集-d:删除字符
echo abc | tr -d "ab"
#将字符集abc的ab字符删除![]()
-s:将重复出现的字符串压缩成一个字符
且可以替换字符集
echo $PATH | tr -s ":" "\n"
#将":"替换成"\n"

[root@hj ~]cat 456.txt | tr -s "a"
3abbbbbcccccc
3abc
[root@hj ~]cat 456.txt | tr -s "b"
3aaaabcccccc
3aaabc
[root@hj ~]cat 456.txt | tr -s "abc"
3abc
3abc
[root@hj ~]cat 456.txt
3aaaabbbbbcccccc
3aaabc

-t:也是替换
cut:对字符集进行截取和剪截
格式:
cut 选项 参数
cat 文件名 | cut 选项
常见命令
-d:指定分隔符,截取字段
-f:对字段进行截取
cut -d ':' -f 1-3 /etc/passwd
以 : 为分隔符,截取1-3列
cut -d ':' -f 1,3 /etc/passwd
以 : 为分隔符,截取1和3列
-b:以字节为单位进行截取
-c:以字符为单位截取


-complement :排除所指定的字段
--output-delimiter:更改原内容的分隔符

head -n 3 /etc/passwd | cut -d ':' -f 1-3 --output-delimiter="@"补充:
cut和awk有相似之处,都是对行来取列。
cut的默认分隔符是tab键,主要是切文本,指定分隔符最好是指向性越强越好
awk的默认分隔符就是空格,把多个连续的空格当作一个处理
文件拆分:split 可以把文件拆分成若干个小文件
通过split将文件拆分成若干个小文件,可以提高文件的打开速度
-l:指定行数拆分 (适用于小文件)
split -l 20 test.txt zzr将文件拆分成20行,不满20行的也单独拆分
-b:指定文件大小进行拆分 (适用于大文件)
split -b 2m 文件名 zzr
保留原文件拆分,m为拆分文件的大小分件合并:paste,cat
区别:
paste 左右合并
cat 上下合并
综合例题:
如何统计当前主机的连接状态,有多少个listen,有多少个estab
ss -nta | grep -v "^State" | cut -d " " -f1 | sort | uniq -c
#ss -nta:查询连接状态
#grep -v "^State":删除包含State所在的行
#cut -d " " -f1 :指定空格截取第一行
#sort:排序
#uniq -c:统计连续重复的行的次数,合并重复的行
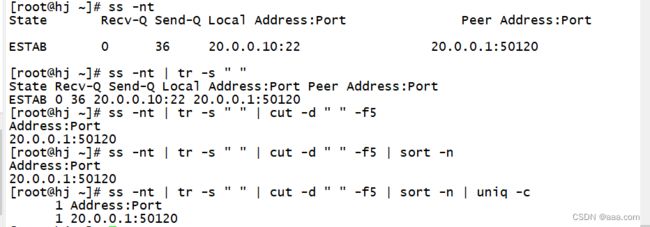
统计当前主机的连接数
ss -nt | tr -s " " | cut -d " " -f5 | sort -n | uniq -c
#tr -s " ":将空格压缩
# cut -d " " -f5 : 以空格为分隔符,对第五个字段截取
#sort -n:通过数字排序
#uniq -c:统计连续出现的行,合并重复行
正则表达式
正则表达式的作用就是匹配文件的内容,根据特定的字符和表达式来匹配。
通配符和正则表达式的区别
*:匹配任意一个或者多个字符
?:匹配任意一个字符
[ ]:可以是范围匹配也可以是单个字符

正则表达式元字符
.:匹配任意单个字符,可以是一个汉字
转义符:\

单个 . 就是匹配多个字符,加上\,经过转义,' \ .' 就是改变了原来 . 的含义,就是一个单个的 . 进行匹配
():分组 \(\)
[ ]:匹配任意范围内的单个字符
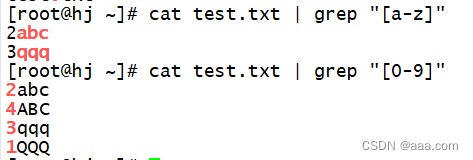
[a-z]
[A-Z]
[0-9]
使用正则表达式一定要把匹配内容引起来("" '')
[^a-z]:取反
[[:blank:]] 匹配空格或者制表

红色为空格
[:space:] :空格 tab键 换行符 回车 各种类型的空白
[:cntrl:] 退格,删除
正则表达式可以写在一个【】里面
