【算法基础】栈和队列及常见变种与使用,双栈、动态栈、栈的迭代器,双端队列、优先队列、并发队列、延迟队列的使用
目录
一、栈(Stack)
二、 队列(Queue)
三、栈和队列的常见变种与使用
3.1 栈的常见的变种与使用
3.1.1 最小栈(Min Stack)
3.1.2 双栈(Two Stacks)
3.1.3 固定大小栈(Fixed-Size Stack)
3.1.4 可变大小栈(Resizable Stack)
3.1.5 栈的迭代器
3.2 队列的常见变种与使用
3.2.1 双端队列(Deque)
3.2.2 优先队列(Priority Queue)
3.2.3 并发队列(Concurrent Queue)
3.2.4 延迟队列(Delay Queue)
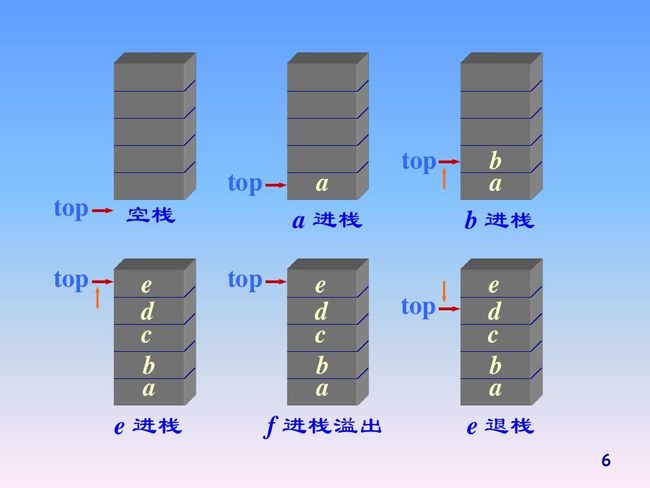
一、栈(Stack)
-
栈的基本概念
栈是一种线性数据结构,遵循后进先出(Last-In-First-Out,LIFO)原则。最后添加到栈中的元素是第一个被移除的。 -
栈的操作
- 压栈(Push):将元素添加到栈的顶部。
- 出栈(Pop):从栈的顶部移除元素。
- 查看栈顶(Peek):查看栈顶元素,不删除它。
- 判断栈是否为空。
-
示例代码与注释
# 创建一个空栈
stack = []
# 压栈操作
stack.append(1) # 添加元素1到栈
stack.append(2) # 添加元素2到栈
# 出栈操作
top_element = stack.pop() # 移除并返回栈顶元素
# 查看栈顶元素
top_element = stack[-1] # 查看栈顶元素,不删除它
# 判断栈是否为空
is_empty = len(stack) == 0 # 如果栈为空,返回True
4 栈的应用场景
- 函数调用和递归:用于保存函数调用的上下文。
- 表达式求值:用于解析和计算表达式。
- 浏览器的后退和前进功能:用于记录访问历史。
- 编译器的语法分析:用于跟踪括号匹配。
二、 队列(Queue)
-
队列的基本概念
定义:队列是一种线性数据结构,遵循先进先出(First-In-First-Out,FIFO)原则。最早添加到队列中的元素是第一个被移除的。 -
队列的操作
- 入队(Enqueue):将元素添加到队列的尾部。
- 出队(Dequeue):从队列的头部移除元素。
- 查看队头元素(Front):查看队列头部的元素,不删除它。
- 判断队列是否为空。
-
示例代码与注释
from collections import deque
# 创建一个空队列
queue = deque()
# 入队操作
queue.append(1) # 添加元素1到队列尾部
queue.append(2) # 添加元素2到队列尾部
# 出队操作
front_element = queue.popleft() # 移除并返回队头元素
# 查看队头元素
front_element = queue[0] # 查看队头元素,不删除它
# 判断队列是否为空
is_empty = len(queue) == 0 # 如果队列为空,返回True
4 对列的应用场景
- 任务调度:用于按照顺序执行任务。
- 数据缓冲:用于缓冲数据传输。
- 广度优先搜索(Breadth-First Search):在图算法中用于遍历图的层级结构。
三、栈和队列的常见变种与使用
- 栈可以使用数组或链表实现。
- 可以使用数组(List)实现栈,其中操作主要包括
append(压栈)和pop(出栈)。- 也可以使用链表实现栈,其中操作包括插入和删除操作在链表的头部。
- 队列可以使用数组、链表或双端队列(Deque)实现。
- 可以使用数组(List)实现队列,但效率较低,因为出队操作需要移动数组元素。
- 也可以使用链表实现队列,其中包括插入(入队)和删除(出队)操作。
3.1 栈的常见的变种与使用
最小栈(Min Stack):最小栈是一种支持在常数时间内获取栈中最小元素的栈。它通常包括
push(压栈)、pop(出栈) 和getMin(获取最小元素)操作。双栈(Two Stacks):双栈是由两个栈组成的数据结构,通常用于实现队列或在栈上执行一些复杂操作。
固定大小栈(Fixed-Size Stack):这种栈具有固定的容量限制,一旦达到容量上限,无法再添加更多元素。
可变大小栈(Resizable Stack):可变大小栈可以动态地增加或减少其容量,以适应变化的需求。
栈的迭代器(Stack Iterator):栈的迭代器是一种数据结构,允许按顺序遍历栈中的元素,而不需要改变栈的状态。
高级栈(Advanced Stack):高级栈可以包括其他功能,例如计算表达式、实现逆波兰表达式计算等。
示例:
3.1.1 最小栈(Min Stack)
最小栈(Min Stack)是一种特殊的栈数据结构,除了支持常规的栈操作(入栈和出栈),它还可以高效地获取栈中的最小元素,通常在常数时间内完成。最小栈通常用于需要在栈中保持跟踪最小元素的问题,同时保持常规栈操作的性能。
以下是一个Python示例,演示如何实现一个最小栈:
class MinStack:
def __init__(self):
# 主栈,用于存储元素
self.stack = []
# 辅助栈,用于存储最小元素
self.min_stack = []
def push(self, x):
self.stack.append(x)
# 如果辅助栈为空或新元素小于等于当前最小值,则将新元素入辅助栈
if not self.min_stack or x <= self.min_stack[-1]:
self.min_stack.append(x)
def pop(self):
# 出栈时,如果出栈元素等于当前最小值,也将辅助栈顶元素出栈
if self.stack:
if self.stack[-1] == self.min_stack[-1]:
self.min_stack.pop()
self.stack.pop()
def top(self):
if self.stack:
return self.stack[-1]
def get_min(self):
if self.min_stack:
return self.min_stack[-1]
# 创建最小栈
min_stack = MinStack()
# 入栈操作
min_stack.push(3)
min_stack.push(5)
min_stack.push(2)
min_stack.push(1)
# 获取栈顶元素和最小元素
print(min_stack.top()) # 输出: 1
print(min_stack.get_min()) # 输出: 1
# 出栈操作
min_stack.pop()
print(min_stack.top()) # 输出: 2
print(min_stack.get_min()) # 输出: 2
在上述示例中,我们使用两个栈来实现最小栈。主栈用于存储元素,而辅助栈用于存储当前最小元素。在入栈操作中,如果新元素小于等于当前最小元素,则将新元素同时入栈到主栈和辅助栈。在出栈操作中,如果出栈元素等于当前最小元素,则将辅助栈的栈顶元素出栈。通过这种方式,我们可以在常数时间内获取栈中的最小元素。
最小栈常用于解决需要频繁获取栈中最小值的问题,例如在设计支持
push、pop和getMin操作的栈时。这种数据结构可以帮助我们在不影响栈的性能的情况下获取最小元素。
3.1.2 双栈(Two Stacks)
双栈是由两个栈组成的数据结构,通常用于实现队列或在栈上执行一些复杂操作。
class TwoStacks:
def __init__(self):
# 两个栈,一个用于入队,一个用于出队
self.stack1 = []
self.stack2 = []
def enqueue(self, val):
# 将元素压入stack1,模拟入队操作
self.stack1.append(val)
def dequeue(self):
if not self.stack2:
# 如果stack2为空,将stack1中的元素逐个弹出并压入stack2,以颠倒顺序
while self.stack1:
self.stack2.append(self.stack1.pop())
# 弹出stack2的栈顶元素,模拟出队操作
if self.stack2:
return self.stack2.pop()
表达式求值:
双栈可以用于解析和求值表达式,例如算术表达式。一个栈用于操作符,另一个栈用于操作数。遍历表达式时,将操作数入栈,遇到操作符时,根据操作符对操作数进行计算。
两个栈的协作:
在某些算法中,两个栈可以协同工作,例如图的深度优先搜索(DFS)中使用两个栈来追踪遍历路径。
双栈是一种非常灵活的数据结构,可以根据需要用于不同类型的问题和应用。通过合理的设计和使用,双栈可以提高算法的效率和可读性。
3.1.3 固定大小栈(Fixed-Size Stack)
固定大小栈具有固定的容量限制,一旦达到容量上限,无法再添加更多元素。
class FixedSizeStack:
def __init__(self, max_size):
self.max_size = max_size
self.stack = []
def push(self, item):
if len(self.stack) < self.max_size:
self.stack.append(item)
else:
raise IndexError("Stack is full")
def pop(self):
if self.stack:
return self.stack.pop()
else:
raise IndexError("Stack is empty")
def peek(self):
if self.stack:
return self.stack[-1]
def is_empty(self):
return len(self.stack) == 0
def is_full(self):
return len(self.stack) == self.max_size
在上述示例中,我们创建了一个
FixedSizeStack类,它接受一个参数max_size,表示栈的最大容量。栈的入栈操作(push)会检查当前栈的大小是否小于最大容量,如果是,则将元素添加到栈中,否则抛出异常。出栈操作(pop)会弹出栈顶元素,查看栈是否为空,以及获取栈顶元素的方法(peek)也被实现。使用固定大小栈可以确保栈的容量不会超出限制,这在某些资源受限的情况下非常有用,例如内存分配或硬件资源管理。这种数据结构可帮助开发人员更好地控制和管理有限的资源。
3.1.4 动态栈(Resizable Stack)
动态可以动态地增加或减少其容量,以适应变化的需求。
class ResizableStack:
def __init__(self):
# 初始容量
self.capacity = 2
# 存储元素的列表
self.stack = [None] * self.capacity
# 当前元素数量
self.size = 0
def push(self, val):
if self.size == self.capacity:
# 如果栈已满,增加容量
self._resize(self.capacity * 2)
# 压栈操作
self.stack[self.size] = val
self.size += 1
def pop(self):
if self.size > 0:
# 出栈操作
self.size -= 1
val = self.stack[self.size]
self.stack[self.size] = None
if self.size <= self.capacity // 4:
# 如果栈的元素数量小于等于容量的四分之一,减小容量
self._resize(self.capacity // 2)
return val
else:
print("Stack is empty. Cannot pop element.")
def _resize(self, new_capacity):
# 调整栈的容量
new_stack = [None] * new_capacity
for i in range(self.size):
new_stack[i] = self.stack[i]
self.stack = new_stack
self.capacity = new_capacity
上述示例演示了一个可变大小栈,它可以动态地增加或减少容量,以适应栈的变化需求。当栈满时,它会将容量加倍,当栈的元素数量少于等于容量的四分之一时,它会将容量减半,以节省内存。这种栈适用于需要灵活管理内存的情况。
动态栈是一种常见的数据结构,用于管理和操作变动大小的数据集。在实际应用中,动态栈可以提高内存利用率,同时保持栈的性能。
3.1.5 栈的迭代器
栈的迭代器是一种数据结构,它允许按顺序遍历栈中的元素,而不需要改变栈的状态。这种迭代器通常是通过将栈中的元素复制到另一个数据结构(如列表)来实现的,然后可以在该数据结构上进行迭代操作。
以下是一个示例,演示了如何实现栈的迭代器以及如何使用它来遍历栈中的元素:
class StackIterator:
def __init__(self, stack):
# 接收一个栈作为参数
self.stack = stack
# 复制栈中的元素到列表,以便进行迭代
self.elements = list(stack)
def __iter__(self):
# 返回自身作为迭代器对象
self.current = 0
return self
def __next__(self):
# 迭代下一个元素,直到列表为空
if self.current < len(self.elements):
element = self.elements[self.current]
self.current += 1
return element
else:
# 列表为空,抛出StopIteration异常
raise StopIteration
class Stack:
def __init__(self):
self.items = []
def push(self, item):
self.items.append(item)
def pop(self):
if not self.is_empty():
return self.items.pop()
def is_empty(self):
return len(self.items) == 0
def size(self):
return len(self.items)
# 创建一个栈
stack = Stack()
# 压栈
stack.push(1)
stack.push(2)
stack.push(3)
# 创建栈的迭代器
stack_iterator = StackIterator(stack)
# 使用迭代器遍历栈中的元素
for element in stack_iterator:
print(element)
# 输出:
# 1
# 2
# 3
在上面的示例中,我们首先定义了一个名为
StackIterator的栈迭代器类,它接收一个栈作为参数,并将栈中的元素复制到列表self.elements中。然后,我们实现了__iter__和__next__方法,使得该类可以被用作迭代器。最后,我们在栈上创建了一个迭代器对象,并使用for循环遍历栈中的元素。这样,我们可以在不改变原始栈的情况下,按顺序访问栈中的元素。
3.2 队列的常见变种与使用
除了标准队列(FIFO,先进先出)之外,还有一些常见的队列变种,这些变种可以适应不同的需求和应用场景。以下是一些常见的队列变种:
优先队列(Priority Queue):元素带有优先级,按照优先级进行出队操作。通常实现为最小堆或最大堆。
双端队列(Deque,Double-ended Queue):允许在队列的两端进行插入和删除操作,可以用于双向搜索、滑动窗口等问题。
并发队列(Concurrent Queue):支持多线程并发访问的队列,通常提供线程安全的操作。
循环队列(Circular Queue):在队列的末尾和开头有相对位置关系,可以循环利用内存,常用于实现循环缓冲区。
阻塞队列(Blocking Queue):当队列为空时,出队操作会阻塞线程,当队列满时,入队操作会阻塞线程。常用于线程间通信和任务调度。
延迟队列(Delay Queue):元素在一定延迟时间后才能被出队,常用于定时任务调度和延迟处理。
无锁队列(Lock-free Queue):不使用锁机制实现的队列,用于高性能并发场景,通常基于原子操作实现。
优先级双端队列(Priority Deque):结合了优先队列和双端队列的特性,可以在两端插入和删除元素,并按照优先级出队。
有界队列(Bounded Queue):限制队列的最大容量,一旦达到容量上限,入队操作会阻塞或丢弃元素。
带有超时的队列(Timeout Queue):元素在队列中设置了超时时间,超过时间限制后自动出队。
这些队列变种可以根据不同的需求和场景选择使用,它们在计算机科学和工程中都有广泛的应用。根据具体问题的特性和性能要求,选择合适的队列变种是很重要的。
3.2.1 双端队列(Deque)
双端队列(Deque,Double-ended Queue)是一种具有双向插入和删除操作的数据结构,它允许在队列的两端执行入队和出队操作。双端队列的灵活性使其适用于各种应用场景,包括双向搜索、滑动窗口、实现队列和栈等。
在Python中,可以使用collections模块中的deque来创建双端队列。以下是双端队列的基本操作示例:
from collections import deque
# 创建一个双端队列
deque_obj = deque()
# 在队头插入元素
deque_obj.appendleft(1)
deque_obj.appendleft(2)
# 在队尾插入元素
deque_obj.append(3)
deque_obj.append(4)
# 双端队列的内容现在是 [2, 1, 3, 4]
# 在队头出队
front_element = deque_obj.popleft()
print(front_element) # 输出: 2
# 在队尾出队
rear_element = deque_obj.pop()
print(rear_element) # 输出: 4
# 双端队列的内容现在是 [1, 3]
上述示例中,我们首先导入
deque类,然后创建一个双端队列对象deque_obj。我们可以使用appendleft方法在队头插入元素,使用append方法在队尾插入元素。出队操作可以分别使用popleft方法和pop方法在队头和队尾执行。双端队列在处理需要从两端添加或删除元素的问题时非常有用,例如滑动窗口问题、实现队列和栈等。由于它支持双向操作,因此在一些特定场景中可以提供更高效的解决方案。
3.2.2 优先队列(Priority Queue)
优先队列(Priority Queue)是一种特殊的队列,其中每个元素都与一个优先级相关联,元素按照优先级的顺序进行出队。在优先队列中,具有较高优先级的元素先出队,而具有较低优先级的元素后出队。这种数据结构通常用于处理需要按照优先级顺序处理的任务或元素。
在Python中,可以使用heapq模块实现最小堆优先队列,也可以使用第三方库(如queue.PriorityQueue)来创建优先队列。
以下是一个使用heapq模块实现最小堆优先队列的示例:
import heapq
class PriorityQueue:
def __init__(self):
self.elements = []
def push(self, item, priority):
heapq.heappush(self.elements, (priority, item))
def pop(self):
if self.elements:
return heapq.heappop(self.elements)[1]
else:
raise IndexError("Priority queue is empty")
# 创建优先队列
pq = PriorityQueue()
# 添加元素到优先队列,带有优先级
pq.push("Task 1", 3)
pq.push("Task 2", 1)
pq.push("Task 3", 2)
# 出队操作将按照优先级顺序执行
print(pq.pop()) # 输出: "Task 2",因为它具有最高优先级
print(pq.pop()) # 输出: "Task 3"
print(pq.pop()) # 输出: "Task 1"
在这个示例中,我们创建了一个
PriorityQueue类,它使用heapq来实现最小堆优先队列。我们可以使用push方法添加元素和其对应的优先级,然后使用pop方法按照优先级顺序取出元素。注意,最小堆优先队列返回具有最小优先级的元素。如果需要最大堆优先队列,可以通过将优先级值取负数来实现。
优先队列常用于任务调度、搜索算法(如Dijkstra算法)和其他需要按照优先级处理元素的应用中。
3.2.3 并发队列(Concurrent Queue)
并发队列(Concurrent Queue)是一种队列数据结构,支持多线程并发访问,通常提供线程安全的入队和出队操作。这种队列类型用于多线程环境,以确保多个线程可以安全地访问和修改队列,防止竞态条件和数据损坏。
以下是一个Python示例,演示如何使用Python的queue模块创建并发队列:
import queue
import threading
import time
# 创建并发队列
concurrent_queue = queue.Queue()
# 定义一个生产者线程,向队列中添加数据
def producer():
for i in range(5):
item = f"Item {i}"
concurrent_queue.put(item)
print(f"Produced: {item}")
time.sleep(1)
# 定义一个消费者线程,从队列中获取数据
def consumer():
while True:
item = concurrent_queue.get()
if item is None:
break
print(f"Consumed: {item}")
concurrent_queue.task_done()
# 启动生产者线程
producer_thread = threading.Thread(target=producer)
producer_thread.start()
# 启动两个消费者线程
consumer_thread1 = threading.Thread(target=consumer)
consumer_thread2 = threading.Thread(target=consumer)
consumer_thread1.start()
consumer_thread2.start()
# 等待生产者线程完成
producer_thread.join()
# 向队列添加特殊的"None"值以通知消费者线程退出
concurrent_queue.put(None)
concurrent_queue.put(None)
# 等待消费者线程完成
consumer_thread1.join()
consumer_thread2.join()
在上述示例中,我们创建了一个并发队列
concurrent_queue,并定义了一个生产者线程(producer)负责向队列中添加数据,以及两个消费者线程(consumer)负责从队列中获取数据。队列的入队操作是线程安全的,因此多个线程可以同时添加数据。而出队操作也是线程安全的,因此多个消费者线程可以同时获取数据。使用并发队列可以很容易地管理多线程应用程序中的数据共享和同步,确保线程之间的协调和数据的完整性。
3.2.4 延迟队列(Delay Queue)
延迟队列(Delay Queue)是一种特殊的队列,其中的元素在一定的延迟时间之后才能被出队。通常,延迟队列用于实现任务调度和延迟处理,允许您安排在将来的某个时间执行特定的任务。延迟队列中的每个元素都具有与之关联的延迟时间,当延迟时间过去时,元素才会从队列中出队并执行相关操作。
以下是一个Python示例,演示如何使用延迟队列:
import queue
import threading
import time
# 创建延迟队列
delay_queue = queue.PriorityQueue()
# 定义一个延迟任务
def delayed_task(task, delay):
time.sleep(delay)
print(f"Executing task: {task}")
# 启动延迟任务线程
threading.Thread(target=delayed_task, args=("Task 1", 3)).start()
threading.Thread(target=delayed_task, args=("Task 2", 2)).start()
threading.Thread(target=delayed_task, args=("Task 3", 1)).start()
# 模拟添加延迟任务到队列中
delay_queue.put((time.time() + 5, "Task 4", 5)) # 延迟5秒执行
delay_queue.put((time.time() + 2, "Task 5", 2)) # 延迟2秒执行
delay_queue.put((time.time() + 3, "Task 6", 3)) # 延迟3秒执行
# 出队并执行延迟任务
while not delay_queue.empty():
item = delay_queue.get()
execute_time, task_name, delay = item
current_time = time.time()
if current_time >= execute_time:
print(f"Executing delayed task: {task_name}")
else:
# 如果任务还未到执行时间,重新放回队列
delay_queue.put(item)
time.sleep(1) # 等待1秒后再检查
在上述示例中,我们首先创建了一个基于优先级的延迟队列
delay_queue,然后使用多线程启动了一些延迟任务。延迟任务是通过delayed_task函数模拟的,它会在指定的延迟时间后执行任务。同时,我们还模拟了将延迟任务添加到队列中的情况,以及出队和执行延迟任务的过程。延迟队列对于需要按照计划在未来执行任务的应用程序非常有用,例如定时任务调度、消息传递系统等。它允许您安排和管理任务的执行,以满足特定的时间要求。