大数据技术之flink实现简单的wordcount
一.java版实现
离线版
本地运行
pom文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.antggroupId>
<artifactId>worldcountartifactId>
<version>1.0-SNAPSHOTversion>
<name>${project.artifactId}name>
<description>My wonderfull scala appdescription>
<inceptionYear>2018inceptionYear>
<properties>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<encoding>UTF-8encoding>
<scala.version>2.11.11scala.version>
<scala.compile.at.version>2.11scala.compile.at.version>
<flink.version>1.13.1flink.version>
<jdk.version>1.8jdk.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_${scala.compile.at.version}artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.6.6version>
<scope>compilescope>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
<scope>compilescope>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojogroupId>
<artifactId>build-helper-maven-pluginartifactId>
<version>3.0.0version>
<executions>
<execution>
<id>add-sourceid>
<phase>generate-sourcesphase>
<goals>
<goal>add-sourcegoal>
goals>
<configuration>
<sources>
<source>${basedir}/src/main/javasource>
<source>${basedir}/src/main/scalasource>
sources>
configuration>
execution>
executions>
plugin>
<plugin>
<artifactId>maven-compiler-pluginartifactId>
<version>2.3.2version>
<configuration>
<source>${jdk.version}source>
<target>${jdk.version}target>
<encoding>${encoding}encoding>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.confresource>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
project>
数据文件 : input.txt
a b a c a
d a b a
c c d
e f
a
java代码
package com.antg;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class FlinkWordCount4DataSet {
public static void main(String[] args) throws Exception {
// 创建Flink的代码执行离线数据流上下文环境变量
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 定义从本地文件系统当中文件路径
String filePath = "";
if (args == null || args.length == 0) {
filePath = "C:\\Users\\Administrator\\Desktop\\input.txt";
} else {
filePath = args[0];
}
// 获取输入文件对应的DataSet对象
DataSet<String> inputLineDataSet = env.readTextFile(filePath);
// 对数据集进行多个算子处理,按空白符号分词展开,并转换成(word, 1)二元组进行统计
DataSet<Tuple2<String, Integer>> resultSet = inputLineDataSet
.flatMap(
new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String line, Collector<Tuple2<String, Integer>> out)
throws Exception {
// 按空白符号分词
String[] wordArray = line.split("\\s");
// 遍历所有word,包成二元组输出
for (String word : wordArray) {
out.collect(new Tuple2<String, Integer>(
word, 1));
}
}
}).groupBy(0) // 返回的是一个一个的(word,1)的二元组,按照第一个位置的word分组
.sum(1); // 将第二个位置上的freq=1的数据求和
// 打印出来计算出来的(word,freq)的统计结果对
// 注:print会自行执行env.execute方法,故不用再最后执行env.execute正式开启执行过程
resultSet.print();
// 注:writeAsText的sink算子,必须要调用env.execute方法才能正式开启环境执行
// resultSet.writeAsText("d:\\temp\\output2", WriteMode.OVERWRITE)
// .setParallelism(2);
// 正式开启执行flink计算
// env.execute();
}
}
注意 :
- idea运行不会将scope为provided的依赖添加需要手动设置一下,具体参考文章 : https://blog.csdn.net/weixin_44745147/article/details/121434879
- 如果需要打包上传到服务器运行,需要将scope去掉,因为运行时需要这些依赖
运行结果 :

通过源码包运行
这种运行方式比较推荐,支持flink交互的所有方式,比较灵活,而且上传到服务器的时候也不需要将flink的依赖打入包中,极大压缩了包的大小
构建环境:
下载flink1.13.1的源码包 https://flink.apache.org/zh/downloads.html
直接解压即可 tar -zxvf 路径
使hadoop的环境变量生效
方式一 : 将hadoop的环境变量设置到profile中
方式二 : 每次执行命令的终端先运行命令 export HADOOP_CLASS hadoop classpath
flink的三种运行模式
application模式
./bin/flink run-application -t yarn-application -c com.antg.FlinkWordCount4DataSet ../../flink/original-worldcount-1.0-SNAPSHOT.jar hdfs:///user/fujunhua/data/input.txt
结果在集群上,所以本地看不了

per-job模式
./bin/flink run -t yarn-per-job -c com.antg.FlinkWordCount4DataSet ../../flink/original-worldcount-1.0-SNAPSHOT.jar hdfs:///user/fujunhua/data/input.txt
per-job模式的main方法在客户端,所以客户端可以看到结果

session模式
附加模式
首先需要将session提前开启
./bin/yarn-session.sh
运行任务(客户端不可中途退出)
./bin/flink run -c com.antg.FlinkWordCount4DataSet ../../flink/original-worldcount-1.0-SNAPSHOT.jar hdfs:///user/fujunhua/data/input.txt
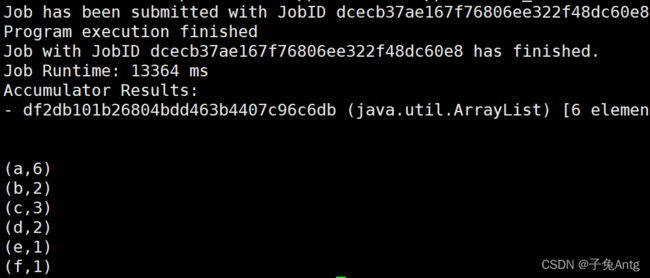
分离模式
开启session
./bin/yarn-session.sh -d
运行(客户端中途可退出)
命令与执行效果附加模式一样
实时版
本地运行
代码
package com.antg;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class FlinkWordCount4DataStream {
public static void main(String[] args) throws Exception {
//创建上下文
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据流
String host = "localhost";
int post = 9999;
DataStreamSource inputLineDataStream = env.socketTextStream(host,post);
//处理数据
DataStream<Tuple2<String, Integer>> resultStream = inputLineDataStream
.flatMap(
new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String line,
Collector<Tuple2<String, Integer>> out)
throws Exception {
// 按空白符号分词
String[] wordArray = line.split("\\s");
// 遍历所有word,包成二元组输出
for (String word : wordArray) {
out.collect(new Tuple2<String, Integer>(
word, 1));
}
}
}).keyBy(0) // 返回的是一个一个的(word,1)的二元组,按照第一个位置的word分组,因为此实时流是无界的,即数据并不完整,故不用group
// by而是用keyBy来代替
.sum(1); // 将第二个位置上的freq=1的数据求和
// 打印出来计算出来的(word,freq)的统计结果对
// 打印出来计算出来的(word,freq)的统计结果对
resultStream.print();
//启动处理
// 正式启动实时流处理引擎
env.execute();
}
}
启动项目并使用netcat向9999端口发送数据
nc64.exe -lp 9999

通过源码包运行
与离线处理的一样,只不过一般数据源不是socket发送的,而是类似kafka等中间件发送
二.scala版实现
离线版
pom文件
一般开发scala项目时要将对应的java依赖也引入方便之后开发
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.antggroupId>
<artifactId>worldcountartifactId>
<version>1.0-SNAPSHOTversion>
<name>${project.artifactId}name>
<description>My wonderfull scala appdescription>
<inceptionYear>2018inceptionYear>
<properties>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<encoding>UTF-8encoding>
<scala.version>2.11.11scala.version>
<scala.compile.version>2.11scala.compile.version>
<flink.version>1.13.1flink.version>
<jdk.version>1.8jdk.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_${scala.compile.version}artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-scala_${scala.compile.version}artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_${scala.compile.version}artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.6.6version>
<scope>compilescope>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
<scope>compilescope>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojogroupId>
<artifactId>build-helper-maven-pluginartifactId>
<version>3.0.0version>
<executions>
<execution>
<id>add-sourceid>
<phase>generate-sourcesphase>
<goals>
<goal>add-sourcegoal>
goals>
<configuration>
<sources>
<source>${basedir}/src/main/javasource>
<source>${basedir}/src/main/scalasource>
sources>
configuration>
execution>
executions>
plugin>
<plugin>
<artifactId>maven-compiler-pluginartifactId>
<version>2.3.2version>
<configuration>
<source>${jdk.version}source>
<target>${jdk.version}target>
<encoding>${encoding}encoding>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.confresource>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
project>
代码
package com.antg
import org.apache.flink.api.scala._
import org.apache.flink.api.scala.ExecutionEnvironment
object FlinkWordCount4DataSet4Scala {
def main(args: Array[String]): Unit = {
//获取上下文执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
//加载数据源-1-从内存当中的字符串渠道
// val source = env.fromElements("a b a c a", "a c d")
// 加载数据源-2-定义从本地文件系统当中文件路径
var filePath = "";
if (args == null || args.length == 0) {
filePath = "C:\\Users\\Administrator\\Desktop\\input.txt";
} else {
filePath = args(0);
}
val source = env.readTextFile(filePath);
//进行transformation操作处理数据
val ds = source.flatMap(x => x.split("\\s+")).map((_, 1)).groupBy(0).sum(1)
//输出到控制台
ds.print()
// 正式开始执行操作
// 由于是Batch操作,当DataSet调用print方法时,源码内部已经调用Excute方法,所以此处不再调用
//如果调用反而会出现上下文不匹配的执行错误
//env.execute("Flink Batch Word Count By Scala")
}
}
运行结果
与java版一致
后面几种运行方式也与java版一致这里就不赘述
实时版
依赖已经在离线版引入,这里就不赘述了
代码
package com.antg
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala.createTypeInformation
import org.apache.flink.streaming.api.scala._
object FlinkWOrdCount4DataStream4Scala {
def main(args: Array[String]): Unit = {
//获取上下文执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//加载或创建数据源-从socket端口获取
val source = env.socketTextStream("localhost", 9999, '\n')
//进行transformation操作处理数据
val dataStream = source.flatMap(_.split("\\s+")).map((_, 1)).keyBy(0).sum(1)
//输出到控制台
dataStream.print()
//执行操作
env.execute("FlinkWordCount4DataStream4Scala")
}
}