代码随想录刷题笔记10——动态规划
动态规划理论基础
动态规划定义
动态规划,英文:Dynamic Programming,简称DP,如果某一问题有很多重叠子问题,使用动态规划是最有效的。
所以动态规划中每一个状态一定是由上一个状态推导出来的,这一点就区分于贪心,贪心没有状态推导,而是从局部直接选最优的。
动态规划解题步骤
对于动态规划问题,代码随想录的解析方法是拆解为如下五步曲,这五步都搞清楚了,动态规划的题目做起来就会比较顺畅。
- 确定dp数组(dp table)以及下标的含义;
- 确定递推公式;
- dp数组如何初始化;
- 确定遍历顺序;
- 举例推导dp数组
至于为什么要先确定递推公式,然后在考虑初始化,是因为有一些情况是递推公式决定了dp数组的初始化情况。
动态规划的debug方法
找问题的最好方式就是把dp数组打印出来,看看究竟是不是按照自己思路推导的!
做动规的题目,写代码之前一定要把状态转移在dp数组的上具体情况模拟一遍,心中有数,确定最后推出的是想要的结果。
再写代码,如果代码没通过就打印dp数组,看看是不是和自己预先推导的哪里不一样;如果打印出来和自己预先模拟推导是一样的,那么就是自己的递归公式、初始化或者遍历顺序有问题了;如果和自己预先模拟推导的不一样,那么就是代码实现细节有问题。
斐波那契数
例题509(简单)斐波那契数
注意要点:
- 这道题目比较简单,因为初始化是已经给出的,递推公式也是给出的dp[i] = dp[i - 1] + dp[i - 2];
- 并且可以发现,当前元素的值只与前两个元素相关,就可以只维护两个数值即可。
下面贴出代码:
CPP版本
class Solution {
public:
int fib(int n) {
if (n <= 1) {return n;}
int dp[2] = {0};
dp[1] = 1;
for (int i = 2; i <= n; i++)
{
int sum = dp[0] + dp[1];
dp[0] = dp[1];
dp[1] = sum;
}
return dp[1];
}
};
C版本
int fib(int n){
if (n <= 1) {return n;}
int* dp = (int* )malloc(sizeof(int) * 2);
dp[0] = 0, dp[1] = 1;
for (int i = 2; i <= n; i++)
{
int now = dp[0] + dp[1];
dp[0] = dp[1];
dp[1] = now;
}
return dp[1];
}
爬楼梯
例题70(简单)爬楼梯
注意要点:
- 本题的递推公式,很容易联想到这跟斐波那契数列很相似,就是dp[i] = dp[i - 1] + dp[i - 2];
- 本题主要的难点在于dp[0]的初始化问题,起始可以直接跳过这个纠结点,就直接dp[1]=1,dp[2]=2,然后直接向后递推就是了;
- 同样的,这一题只需要维护两个数据来递推就可以了。
下面贴出代码:
CPP版本
class Solution {
public:
int climbStairs(int n) {
if (n <= 2) {return n;}
int dp[2] = {1};
dp[1] = 2;
for (int i = 3; i <= n; i++)
{
int sum = dp[0] + dp[1];
dp[0] = dp[1];
dp[1] = sum;
}
return dp[1];
}
};
C版本
int climbStairs(int n){
if (n <= 1) {return n;}
int* dp = (int* )malloc(sizeof(int) * (n + 1));
dp[1] = 1, dp[2] = 2;
for (int i = 3; i <= n; i++)
{
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
使用最小花费爬楼梯
例题746(简单)使用最小花费爬楼梯
注意要点:
- 首先根据题意,当前台阶的花费只取决于前两个台阶的花费,可以得到递推公式:dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]);
- 根据题意,可以从第0个或第1格开始爬起,所以初始化dp[0]=0,dp[1]=0;
- 同样的,可以只维护两个数据。
下面贴出代码:
CPP版本
class Solution {
public:
int minCostClimbingStairs(vector<int>& cost) {
int dp[2] = {0};
for (int i = 2; i <= cost.size(); i++)
{
int now = min(dp[0] + cost[i - 2], dp[1] + cost[i - 1]);
dp[0] = dp[1];
dp[1] = now;
}
return dp[1];
}
};
C版本
int minCostClimbingStairs(int* cost, int costSize){
int* dp = (int* )malloc(sizeof(int) * (costSize + 1));
dp[0] = 0, dp[1] = 0;
for (int i = 2; i <= costSize; i++)
{
dp[i] = fmin((dp[i - 1] + cost[i - 1]), (dp[i - 2] + cost[i - 2]));
}
return dp[costSize];
}
不同路径
例题62(中等)不同路径
注意要点:
- 从题目中可以看出,当前格子的路径就是左边和上边路径之和,也就是说如果是一个二维dp,递推公式为:dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
- 初始化,则需要最左边的列以及左上边的行一起初始化,他们都只有1条路径可以达到;
- 因为只需要左边和上边的元素,那么可以采用滚动数组的方式,用一维dp来做,递推公式变为:dp[i]+=dp[i-1];
- 不用动规划也可以做,相当于排列组合,一共m+n-2个路线,取出m-1个,直接计算就可以得到结果。
下面贴出代码:
CPP版本
class Solution {
public:
int uniquePaths(int m, int n) {
vector<int> dp(n);
for (int i = 0; i < n; i++) {dp[i] = 1;}
for (int i = 1; i < m; i++)
{
for (int j = 1; j < n; j++) {dp[j] += dp[j - 1];}
}
return dp[n - 1];
}
};
C版本
int uniquePaths(int m, int n){
//开辟二维数组空间
int** dp = (int** )malloc(sizeof(int* ) * m);
for (int i = 0; i < m; i++)
{
dp[i] = (int* )malloc(sizeof(int) * n);
}
//初值
for (int i = 0; i < m; i++)
{
dp[i][0] = 1;
}
for (int i = 0; i < n; i++)
{
dp[0][i] = 1;
}
//动态规划
for (int i = 1; i < m; i++)
{
for (int j = 1; j < n; j++)
{
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m - 1][n - 1];
}
例题63(中等)不同路径II
注意要点:
- 障碍物,实际上就是对应的dp=0,没有可行的路径;
- 初始化时也要注意保持有障碍物的地方dp=0;
- 同样可以用一维数组来完成,但是为了逻辑更清晰我是写了二维的dp。
下面贴出代码:
CPP版本
class Solution {
public:
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
int m = obstacleGrid.size();
int n = obstacleGrid[0].size();
if (obstacleGrid[m - 1][n - 1] || obstacleGrid[0][0]) {return 0;}
vector<vector<int>> dp(m, vector<int>(n, 0));
for (int i = 0; i < m && !obstacleGrid[i][0]; i++) {dp[i][0] = 1;}
for (int j = 1; j < n && !obstacleGrid[0][j]; j++) {dp[0][j] = 1;}
for (int i = 1; i < m; i++)
{
for (int j = 1; j < n; j++)
{
if (obstacleGrid[i][j]) {continue;}
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m - 1][n - 1];
}
};
C版本
int uniquePathsWithObstacles(int** obstacleGrid, int obstacleGridSize, int* obstacleGridColSize){
//开辟二维数组空间
int m = obstacleGridSize;
int n = obstacleGridColSize[0];
int** dp = (int** )malloc(sizeof(int* ) * m);
for (int i = 0; i < m; i++)
{
dp[i] = (int* )malloc(sizeof(int) * n);
}
//初值
//先将第一行第一列设为0
for(int i = 0; i < m; i++)
{
dp[i][0] = 0;
}
for(int j = 0; j < n; j++)
{
dp[0][j] = 0;
}
//若碰到障碍,之后的都走不了。退出循环
for(int i = 0; i < m; i++)
{
if(obstacleGrid[i][0]) {break;}
dp[i][0] = 1;
}
for(int j = 0; j < n; j++)
{
if(obstacleGrid[0][j]) {break;}
dp[0][j] = 1;
}
//动态规划
for (int i = 1; i < m; i++)
{
for (int j = 1; j < n; j++)
{
if (obstacleGrid[i][j]) {dp[i][j] = 0;}
else dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m - 1][n - 1];
}
整数拆分
例题343(中等)整数拆分
注意要点:
- 这道题难一些,dp定义为当前数字为i时,dp[i]就是i拆分后的最大乘积;
- 那么递推公式就清晰了起来,i要么拆分成j和i-j,要么就是j和i-j继续拆分,那么递推公式就是:dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
- 根据常识,和相等,那么两数越接近乘积越大,所以j遍历到i/2即可。
下面贴出代码:
CPP版本
class Solution {
public:
int integerBreak(int n) {
vector<int> dp(n + 1);
dp[2] = 1;
for (int i = 3; i <= n; i++)
{
for (int j = 1; j <= i / 2; j++)
{
dp[i] = max(max(j * (i - j), j * dp[i - j]), dp[i]);
}
}
return dp[n];
}
};
C版本
int integerBreak(int n){
int* dp = (int* )malloc(sizeof(int) * (n + 1));
dp[2] = 1;
for (int i = 3; i <= n; i++)
{
for (int j = 1; j < i - 1; j++)
{
int now = fmax(j * (i - j), j * dp[i - j]);
dp[i] = fmax(dp[i], now);
}
}
return dp[n];
}
不同的二叉搜索树
例题96(中等)不同的二叉搜索树
注意要点:
- dp可以定义为i为头结点的所有二叉搜索树的个数;
- 递推公式也可以想出来,相当于遍历所有的元素,以他为头结点,左侧作为左子树的个数+右侧作为右子树的个数全部加一起,就是总的个数,也就是说递推公式可写成:dp[i] += dp[j - 1] * dp[i - j],j-1就是左子树,i-j就是右子树;
- 初始化dp[0],可理解为空节点也是一颗二叉搜索树,所以dp[0]=1。
下面贴出代码:
CPP版本
class Solution {
public:
int numTrees(int n) {
vector<int> dp(n + 1);
dp[0] = 1;
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= i; j++)
{
dp[i] += dp[j - 1] * dp[i - j];
}
}
return dp[n];
}
};
C版本
int numTrees(int n){
int* dp = (int* )malloc(sizeof(int) * (n + 1));
dp[0] = 1;
for (int i = 1; i <= n; i++) {dp[i] = 0;}
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= i; j++)
{
dp[i] += dp[j - 1] * dp[i - j];
}
}
return dp[n];
}
0-1背包理论基础
这是动态规划的经典题型,一般而言,应对求职掌握01背包和完全背包就够用了,最多再加上多重背包;以下图是总结了所有的背包问题:
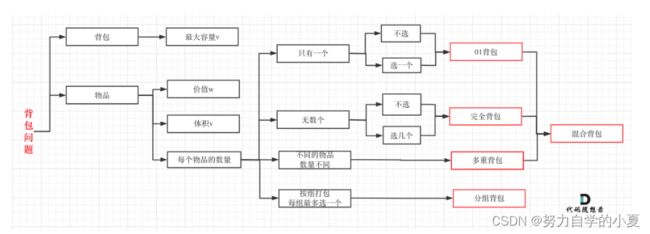
leetcode上连多重背包的题目都没有,所以题库也告诉我们,01背包和完全背包就够用了。
而完全背包问题,就是从01背包上进行扩展,即:完全背包的物品数量是无限的。
所以可以说,背包问题的理论基础重中之重就是01背包!
01背包
有n件物品和一个最多能背重量为w的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。
当然这一类问题可以回溯法保利求解,毕竟只有取/不取两种情况,但是暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!
举一个例子:背包最大重量为4;物品为:
| 重量 | 价值 | |
|---|---|---|
| 物品0 | 1 | 15 |
| 物品1 | 3 | 20 |
| 物品2 | 4 | 30 |
求解背包能装下的物品最大价值。这就是一个典型的01背包问题。
二维dp数组01背包
动规的五部曲来进行分析。
- 确定dp数组和下标含义
对于背包问题,有一种写法, 是使用二维数组,即dp[i][j] 表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。

- 确定递推公式
可以有两个方向来进行递推dp[i][j]:
- 不放物品i:由dp[i - 1][j]推出,即背包容量为j,里面不放物品i的最大价值,此时dp[i][j]就是dp[i - 1][j]。(其实就是当物品i的重量大于背包j的重量时,物品i无法放进背包中,所以背包内的价值依然和前面相同。)
- 放物品i:由dp[i - 1][j - weight[i]]推出,dp[i - 1][j - weight[i]] 为背包容量为j - weight[i]的时候不放物品i的最大价值,那么dp[i - 1][j - weight[i]] + value[i] (物品i的价值),就是背包放物品i得到的最大价值。
所以可以得到递推公式:
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
- dp数组的初始化
关于初始化,一定要和dp数组的定义吻合,否则到递推公式的时候就会越来越乱。
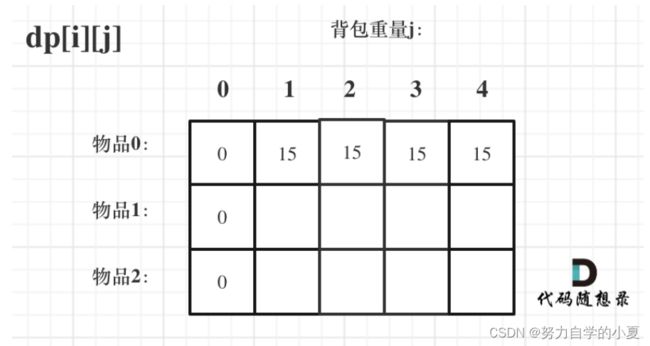
首先从dp[i][j]的定义出发,如果背包容量j为0的话,即dp[i][0],无论是选取哪些物品,背包价值总和一定为0。
再看其他情况。状态转移方程 dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); 可以看出i是由 i-1 推导出来,那么i为0的时候就一定要初始化。
dp[0][j],即:i为0,存放编号0的物品的时候,各个容量的背包所能存放的最大价值。
那么很明显当 j < weight[0]的时候,dp[0][j] 应该是 0,因为背包容量比编号0的物品重量还小。
当j >= weight[0]时,dp[0][j] 应该是value[0],因为背包容量放足够放编号0物品。
所以初始化情况应如下图所示:
再看递推公式,可以看出dp[i][j]就是通过左上方的元素进行推导的,所以其他下标可以随意初始化,为了简便可以初始化为0,那么最终的初始化如下:
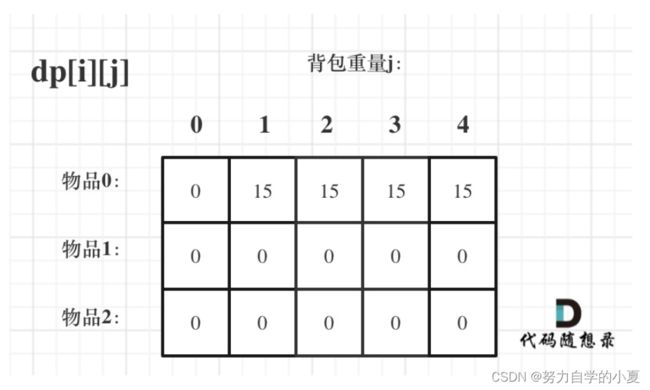
初始化的代码如下:
// 初始化 dp
vector<vector<int>> dp(weight.size(), vector<int>(bagweight + 1, 0));
for (int j = weight[0]; j <= bagweight; j++) {
dp[0][j] = value[0];
}
- 确定遍历顺序
从题目中就可以看出,有两个遍历方向,一个是背包,一个是物品。
先后的遍历情况是都可以的!!但是先遍历物品更好理解。
先遍历物品,然后遍历背包的代码如下:
// weight数组的大小 就是物品个数
for(int i = 1; i < weight.size(); i++) { // 遍历物品
for(int j = 0; j <= bagweight; j++) { // 遍历背包容量
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
之所以遍历顺序是都可以的,是因为递归的本质和递推的方向,从递推公式出发进行推导,可以看出**虽然两个for循环遍历的次序不同,但是dp[i][j]所需要的数据就是左上角,根本不影响dp[i][j]公式的推导!**但是先遍历物品再遍历背包会更容易理解。
其实背包问题里,两个for循环的先后循序是非常有讲究的,理解遍历顺序其实比理解推导公式难多了。
- 举例推导dp数组
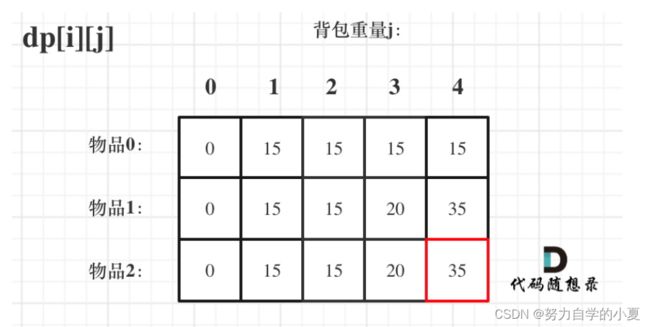
根据计算推导就可以得到上图,最终的结果就是dp[2][4]。
所以说,这道例题最终可以通过如下代码解决:
void test_2_wei_bag_problem1() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
int bagweight = 4;
// 二维数组
vector<vector<int>> dp(weight.size(), vector<int>(bagweight + 1, 0));
// 初始化
for (int j = weight[0]; j <= bagweight; j++) {
dp[0][j] = value[0];
}
// weight数组的大小 就是物品个数
for(int i = 1; i < weight.size(); i++) { // 遍历物品
for(int j = 0; j <= bagweight; j++) { // 遍历背包容量
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
cout << dp[weight.size() - 1][bagweight] << endl;
}
int main() {
test_2_wei_bag_problem1();
}
二维dp总结
讲了这么多才刚刚把二维dp的01背包讲完,这里大家其实可以发现最简单的是推导公式了,推导公式估计看一遍就记下来了,但难就难在如何初始化和遍历顺序上。
一维dp数组(滚动数组)
在使用二维数组的时候,递推公式:dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
其实可以发现如果把dp[i - 1]那一层拷贝到dp[i]上,表达式完全可以是:dp[i][j] = max(dp[i][j], dp[i][j - weight[i]] + value[i]);
与其把dp[i - 1]这一层拷贝到dp[i]上,不如只用一个一维数组了,只用dp[j](一维数组,也可以理解是一个滚动数组)。
这就是滚动数组的由来,需要满足的条件是上一层可以重复利用,直接拷贝到当前层。
既然如此,动规五部曲重新来进行一维dp分析:
- 确定dp数组定义
一维dp数组中,dp[j]表示:容量为j的背包,所背的物品价值可以最大为dp[j]。
- 一维dp数组的递推公式
dp[j]可以通过dp[j - weight[i]]推导出来,dp[j - weight[i]]表示容量为j - weight[i]的背包所背的最大价值。
dp[j - weight[i]] + value[i] 表示容量为 j - 物品i重量 的背包加上物品i的价值。(也就是容量为j的背包,放入物品i了之后的价值即:dp[j])
此时dp[j]有两个选择,一个是取自己dp[j] 相当于二维dp数组中的dp[i-1][j],即不放物品i,一个是取dp[j - weight[i]] + value[i],即放物品i,指定是取最大的,毕竟是求最大价值;那么可以有如下的递推公式:
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
- 一维dp数组初始化
关于初始化,一定要和dp数组的定义吻合,否则到递推公式的时候就会越来越乱。
dp[j]表示:容量为j的背包,所背的物品价值可以最大为dp[j],那么dp[0]就应该是0,因为背包容量为0所背的物品的最大价值就是0。
再从递推公式出发:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]); 从中进行推理可以看出,dp推导过程中一定是取价值最大的,那么非0下标在价值均为正整数时直接都给0就可以了。这样才能让dp数组在递归公式的过程中取的最大的价值,而不是被初始值覆盖了。
- 一维dp数组遍历顺序
与二维dp不同的是,一维dp一定要**倒序遍历!倒序遍历是为了保证物品i只被放入一次!**如果一旦正序遍历了,那么物品0就会被重复加入多次!
遍历的代码如下:
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
二维dp不需要倒序遍历,是因为二维dp,dp[i][j]都是通过上一层即dp[i - 1][j]计算而来,本层的dp[i][j]并不会被覆盖!
一维dp的写法,背包容量一定是要倒序遍历(原因上面已经讲了),如果遍历背包容量放在上一层,那么每个dp[j]就只会放入一个物品,即:背包里只放入了一个物品。所以不可以先遍历背包再遍历物品!
倒序遍历的原因是,本质上还是一个对二维数组的遍历,并且右下角的值依赖上一层左上角的值,因此需要保证左边的值仍然是上一层的,从右向左覆盖。
- 举例推导dp数组
一维dp,分别用物品0,物品1,物品2 来遍历背包,最终得到结果如下:
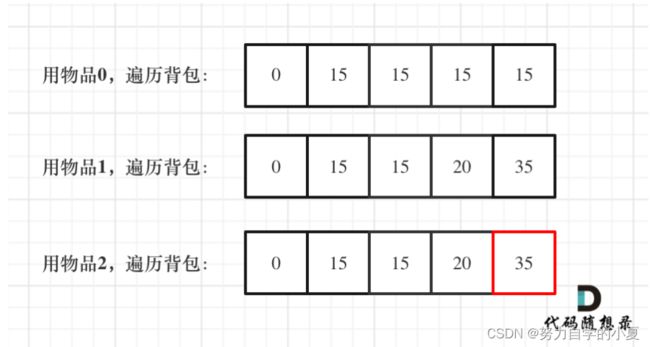
最终可写出如下代码:
void test_1_wei_bag_problem() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
int bagWeight = 4;
// 初始化
vector<int> dp(bagWeight + 1, 0);
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
cout << dp[bagWeight] << endl;
}
int main() {
test_1_wei_bag_problem();
}
01背包变种问题
例题416(中等)分割等和子集
注意要点:
- 对问题进行分析,这就是一个01背包的变种问题:背包体积为sum/2;背包放入的物品就是nums的元素,物品价值就是nums的值;
- 正确与否就是说判断背包是否能够正好装满,正好装满就是找到了,返回true,同时每个元素只能使用一次;
- 01背包递推公式就是dp[j] = max(dp[j], dp[j - weight[i]] + value[i]); 这其中的weight就是nums,value同样是nums;
- 遍历顺序,就是按照代码模板,先遍历物品,在倒序遍历背包(j从尾部开始遍历,减到当前的元素重量即可)。
下面贴出代码:
CPP版本
class Solution {
public:
bool canPartition(vector<int>& nums) {
int sum = 0;
vector<int> dp(200 * 100 / 2 + 1, 0);
for (int i = 0; i < nums.size(); i++) {sum += nums[i];}
if (sum % 2) {return 0;}
int target = sum / 2;
// 相当于背包容量为sum/2,背包的大小就是nums.size,物品的重量和价值都是nums[i]
for (int i = 0; i < nums.size(); i++)
{
for (int j = target; j >= nums[i]; j--)
{
dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);
}
}
if (dp[target] == target) {return 1;}
return 0;
}
};
C版本
bool canPartition(int* nums, int numsSize){
int sum = 0;
for (int i = 0; i < numsSize; i++)
{
sum += nums[i];
}
if (sum % 2) {return false;}
int target = sum / 2;
int* dp = (int* )malloc(sizeof(int) * 10001);
memset(dp, 0, sizeof(int) * 10001);
for (int i = 0; i < numsSize; i++)
{
for (int j = target; j >= nums[i]; j--)
{
dp[j] = fmax(dp[j], dp[j - nums[i]] + nums[i]);
}
}
if (dp[target] == target) {return true;}
return false;
}
例题1049(中等)最后一块石头的重量II
注意要点:
- 分析题意,其实就是石头分成两堆,然后差值要尽量小,就变成了典型的01背包问题;
- 递推公式以及初始化等都没有区别,与上一题也很类似;
- 最后的返回值,根据定义,就是把总和减去dp[target] * 2;
下面贴出代码:
CPP版本
class Solution {
public:
int lastStoneWeightII(vector<int>& stones) {
int sum = 0;
for (int stone : stones) {sum += stone;}
int target = sum / 2;
vector<int> dp(target + 1, 0);
for (int i = 0; i < stones.size(); i++)
{
for (int j = target; j >= stones[i]; j--)
{
dp[j] = max(dp[j], dp[j - stones[i]] + stones[i]);
}
}
return sum - 2 * dp[target];
}
};
C版本
int lastStoneWeightII(int* stones, int stonesSize){
int sum = 0;
for (int i = 0; i < stonesSize; i++)
{
sum += stones[i];
}
int target = sum / 2;
int* dp = (int* )malloc(sizeof(int) * 15001);
memset(dp, 0, sizeof(int) * 15001);
for (int i = 0; i < stonesSize; i++)
{
for (int j = target; j >= stones[i]; j--)
{
dp[j] = fmax(dp[j], dp[j - stones[i]] + stones[i]);
}
}
return sum - 2 * dp[target];
}
例题494(中等)目标和
注意要点:
- 通过分析可知,我们的目标其实就是(sum+target)/2;
- 递推公式,我们所求是所有的排列组合,所以dp[j]应该进行累加,只要满足条件就都要加进去,故递推公式为:dp[j]+=dp[j-nums[i]];
- 初始化,根据递推公式可知,只有dp[0]=1才能推导下去,否则就全是0;
- 还需要注意,如果sum+target除不尽,那么就不存在满足条件的组合,且sum如果达不到target,同样不可能存在。
下面贴出代码:
CPP版本
class Solution {
public:
int findTargetSumWays(vector<int>& nums, int target) {
int sum = 0;
for (int num : nums) {sum += num;}
if (abs(target) > sum) {return 0;}
if ((sum + target) % 2) {return 0;}
int bagWeight = (target + sum) / 2;
vector<int> dp(bagWeight + 1, 0);
dp[0] = 1;
for (int i = 0; i < nums.size(); i++)
{
for (int j = bagWeight; j >= nums[i]; j--)
{
dp[j] += dp[j - nums[i]];
}
}
return dp[bagWeight];
}
};
C版本
int findTargetSumWays(int* nums, int numsSize, int target){
int sum = 0;
for (int i = 0; i < numsSize; i++)
{
sum += nums[i];
}
if (abs(target) > sum) return 0;
if ((sum + target) % 2) return 0;
int tar = (sum + target) / 2;
int* dp = (int* )malloc(sizeof(int) * (tar + 1));
//这里初始化dp=1
memset(dp, 0, sizeof(int) * (tar + 1));
dp[0] = 1;
for (int i = 0; i < numsSize; i++)
{
for (int j = tar; j >= nums[i]; j--)
{
dp[j] += dp[j-nums[i]];
}
}
return dp[tar];
}
例题474(中等)一和零
注意要点:
- 本题中strs 数组里的元素就是物品,每个物品都是一个!而m 和 n相当于是一个背包,两个维度的背包;
- 需要二维dp来针对两个背包进行计算;
- 递推公式也很好理解,把0和1用掉之后,背包数就能+1,所以递推公式为:dp[i][j] = max(dp[i][j], dp[i - zeroNum][j - oneNum] + 1);
- 本题的区别就是,需要对每一个str进行0和1的数量统计,然后才去进行01背包计算;而01背包的遍历都需要倒序从而不会产生覆盖问题。
下面贴出代码:
CPP版本
class Solution {
public:
int findMaxForm(vector<string>& strs, int m, int n) {
vector<vector<int>> dp(m + 1, vector<int> (n + 1, 0));
for (string str : strs)
{
int zeroNum = 0, oneNum = 0;
for (char c : str)
{
if (c == '0') {zeroNum++;}
else {oneNum++;}
}
for (int i = m; i >= zeroNum; i--)
{
for (int j = n; j >= oneNum; j--)
{
dp[i][j] = max(dp[i][j], dp[i-zeroNum][j-oneNum] + 1);
}
}
}
return dp[m][n];
}
};
C版本
int findMaxForm(char ** strs, int strsSize, int m, int n){
//相当于1和0两个背包
int** dp = (int** )malloc(sizeof(int* ) * (m + 1));
for (int i = 0; i <= m; i++)
{
dp[i] = (int* )malloc(sizeof(int) * (n + 1));
}
for (int i = 0; i <= m; i++)
{
for (int j = 0; j <= n; j++)
{
dp[i][j] = 0;
}
}
for (int i = 0; i < strsSize; i++)
{
int zero_num = 0, one_num = 0;
char* str = strs[i];
for (int j = 0; j < strlen(str); j++)
{
if (str[j] == '0') zero_num++;
else one_num++;
}
for (int i = m; i >= zero_num; i--)
{
for (int j = n; j >= one_num; j--)
{
dp[i][j] = fmax(dp[i][j], dp[i - zero_num][j - one_num] + 1);
}
}
}
return dp[m][n];
}
完全背包理论基础
有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。
完全背包和01背包问题唯一不同的地方就是,每种物品有无限件。
以下的学习依然举出一个例子:
背包最大重量为4;物品为:
| 重量 | 价值 | |
|---|---|---|
| 物品0 | 1 | 15 |
| 物品1 | 3 | 20 |
| 物品2 | 4 | 30 |
每件商品有无限个!
01背包和完全背包唯一不同就是体现在遍历顺序上,所以这里就跳过动规五部曲的分析了,与之前的分析大同小异!
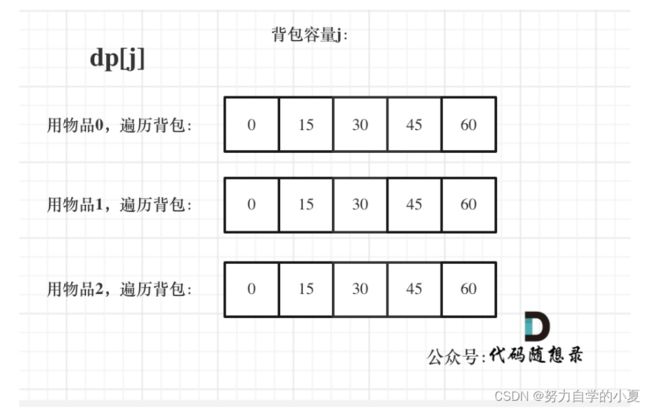
我们知道01背包内嵌的循环是从大到小遍历,为了保证每个物品仅被添加一次;而完全背包的物品是可以添加多次的,所以要从小到大去遍历,即:
// 先遍历物品,再遍历背包
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = weight[i]; j <= bagWeight ; j++) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
根据递推公式以及以上代码计算,可以得到dp状态图如下:
关于遍历顺序
01背包中二维dp数组的两个for遍历的先后循序是可以颠倒,一维dp数组的两个for循环先后循序一定是先遍历物品,再遍历背包容量。
在完全背包中,对于一维dp数组来说,其实两个for循环嵌套顺序是无所谓的!
因为dp[j]是根据下标j之前所对应的dp[j]计算出来的,只要保证下标j之前的dp[j]都是经过计算的就可以了。
当然了,对于我们这种应试者,我就记住一种遍历的模板就好了嘛,所以我就全部是先遍历物品,在遍历背包!
完整的完全背包实现的代码如下:
// 先遍历物品,在遍历背包
void test_CompletePack() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
int bagWeight = 4;
vector<int> dp(bagWeight + 1, 0);
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = weight[i]; j <= bagWeight; j++) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
cout << dp[bagWeight] << endl;
}
int main() {
test_CompletePack();
}
完全背包变种问题
例题518(中等)零钱兑换II
注意要点:
- 可以看出,coins[i]就是物品的重量,题目需要求的是组合数而不是排列数;
- 求取的是装满背包的方法,所以递推公式为:dp[j]+=dp[j-coins[i]];
- 初始化,dp[0]=1(物理意义比较难以理解,但其实也不需要完全理解,毕竟初始化为0那么所有dp就都是0)
- 因为求取的是组合数,所以遍历顺序是有讲究的!外层for循环遍历物品(钱币),内层for遍历背包(金钱总额)的情况就是求组合数的;但是两个遍历交换一下,就会变成排列数。
下面贴出代码:
CPP版本
class Solution {
public:
int change(int amount, vector<int>& coins) {
vector<int> dp(amount + 1, 0);
dp[0] = 1;
for (int i = 0; i < coins.size(); i++)
{
for (int j = coins[i]; j <= amount; j++)
{
dp[j] += dp[j - coins[i]];
}
}
return dp[amount];
}
};
C版本
int change(int amount, int* coins, int coinsSize){
int* dp = (int* )malloc(sizeof(int) * (amount + 1));
memset(dp, 0, sizeof(int) * (amount + 1));
dp[0] = 1;
for (int i = 0; i < coinsSize; i++)
{
for (int j = coins[i]; j <= amount; j++)
{
dp[j] += dp[j - coins[i]];
}
}
return dp[amount];
}
例题377(中等)组合总和Ⅳ
注意要点:
- 题目明确说了是求排列情况,所以要先遍历背包再遍历物品;
- 递推公式因为是求装满背包的方法,所以一样也是:dp[j]+=dp[j-nums[i]];
- 初始化也是同理,初始dp[0]=1;
下面贴出代码:
CPP版本
class Solution {
public:
int combinationSum4(vector<int>& nums, int target) {
vector<int> dp(target + 1, 0);
dp[0] = 1;
for (int j = 0; j <= target; j++)
{
for (int i = 0; i < nums.size(); i++)
{
if (j - nums[i] >= 0 && dp[j] <= INT_MAX - dp[j - nums[i]])
dp[j] += dp[j - nums[i]];
}
}
return dp[target];
}
};
C版本
int combinationSum4(int* nums, int numsSize, int target){
int* dp = (int* )malloc(sizeof(int) * (target + 1));
memset(dp, 0, sizeof(int) * (target + 1));
dp[0] = 1;
for (int j = 0; j <= target; j++)
{
for (int i = 0; i < numsSize; i++)
{
if (j >= nums[i] && dp[j] < INT_MAX - dp[j - nums[i]])
{
dp[j] += dp[j - nums[i]];
}
}
}
return dp[target];
}
例题70(简单)爬楼梯
注意要点:
- 这道题可以作为完全背包来做,相当于求排列数的个数;
- 需要注意的是,根据题意这里i和j都需要从1开始遍历;
这里比较简单,我就只把C++代码贴出来,C就是vector换成int的一维数组指针就可以了:
CPP版本
class Solution {
public:
int climbStairs(int n) {
vector<int> dp(n + 1, 0);
int m = 2;
dp[0] = 1;
for (int j = 1; j <= n; j++)
{
for (int i = 1; i <= m; i++)
{
if (j - i >= 0) {dp[j] += dp[j - i];}
}
}
return dp[n];
}
};
例题322(中等)零钱兑换
注意要点:
- 根据题目的假设,所需要的是最少的钱币数量,所以可以得到如下的递推公式:dp[j]=min(dp[j],dp[j-coins[i]]+1);
- 因为是求最小值,所以应该初始化为INT_MAX,而dp[0]根据定义就可以理解,凑满0元所需钱币个数为0,故dp[0]=0;
- 本题求最少的个数,所以遍历顺序不会影响结果,只是具体代码实现上会有微小区别。
下面贴出代码:
CPP版本
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
vector<int> dp(amount + 1, INT_MAX);
dp[0] = 0;
for (int i = 0; i < coins.size(); i++)
{
for (int j = coins[i]; j <= amount; j++)
{
if (dp[j - coins[i]] != INT_MAX)
dp[j] = min(dp[j], dp[j - coins[i]] + 1);
}
}
if (dp[amount] == INT_MAX) {return -1;}
return dp[amount];
}
};
C版本
int coinChange(int* coins, int coinsSize, int amount){
int* dp = (int* )malloc(sizeof(int) * (amount + 1));
for (int i = 0; i <= amount; i++) {dp[i] = INT_MAX;}
dp[0] = 0;
for (int i = 0; i < coinsSize; i++)
{
for (int j = coins[i]; j <= amount; j++)
{
if (dp[j - coins[i]] != INT_MAX)
{
dp[j] = fmin(dp[j], dp[j - coins[i]] + 1);
}
}
}
return dp[amount] == INT_MAX ? -1: dp[amount];
}
例题279(中等)完全平方数
注意要点:
- 相当于背包容量为n,物品重量为i而价值为i*i;
- 所求是最少数量,所以递推公式为:dp[j] = min(dp[j - i * i] + 1, dp[j]);
- 初始化,看题目举例并不包含0,所以dp[0]=0;
- 遍历顺序无所谓,只是具体实现的细节比如for的参数有所区别。
下面贴出代码:
CPP版本
class Solution {
public:
int numSquares(int n) {
vector<int> dp(n + 1, INT_MAX);
dp[0] = 0;
for (int i = 1; i * i <= n; i++)
{
for (int j = i * i; j <= n; j++)
{
dp[j] = min(dp[j], dp[j - i * i] + 1);
}
}
return dp[n];
}
};
C版本
int numSquares(int n){
int* dp = (int* )malloc(sizeof(int) * (n + 1));
for (int i = 0; i <= n; i++) {dp[i] = INT_MAX;}
dp[0] = 0;
for (int i = 1; i * i <= n; i++)
{
for (int j = i * i; j <= n; j++)
{
if (dp[j - i * i] < INT_MAX)
{
dp[j] = fmin(dp[j], dp[j - i * i] + 1);
}
}
}
return dp[n];
}
例题139(中等)单词拆分
注意要点:
- 这道题比较难,首先确定dp的意义,dp[i]表示字符串长度为i的话,dp[i]为true,表示可以拆分为一个或多个在字典中出现的单词;
- 确定递推公式,如果dp[i]=1且[i,j]区间的子字符串出现在字典中,则dp[j]=1;
- 初始化,dp[0]=1,可以理解为字典中一定包含空字符串;非0下标的dp全初始化为0;
- 本题相当于求排列数,单词的排列顺序是有要求的,所以要先遍历背包再遍历物品。
这题还涉及对字符串的匹配,所以比较难,C++可以用unordered_set完成哈希匹配,C的话就要用strcmp来进行比较。
下面贴出代码:
CPP版本
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
vector<bool> dp(s.size() + 1, 0);
dp[0] = 1;
unordered_set<string> hash(wordDict.begin(), wordDict.end());
for (int j = 1; j <= s.size(); j++)
{
for (int i = 0; i < j; i++)
{
string word = s.substr(i, j - i);
if (hash.find(word) != hash.end() && dp[i]) {dp[j] = 1;}
}
}
return dp[s.size()];
}
};
C版本
bool find(char* s, char** wordDict, int wordDictSize)
{
for (int i = 0; i < wordDictSize; i++)
{
if (!strcmp(s, wordDict[i])) {return 1;}
}
return 0;
}
bool wordBreak(char * s, char ** wordDict, int wordDictSize){
bool* dp = (bool* )malloc(sizeof(bool) * (strlen(s) + 1));
memset(dp, 0, sizeof(bool) * (strlen(s) + 1));
dp[0] = 1;
for (int j = 1; j <= strlen(s); j++)
{
for (int i = 0; i < j; i++)
{
char* str = (char* )malloc(sizeof(char) * (j - i + 1));
for (int k = 0; k < j - i; k++) {str[k] = s[i + k];}
str[j - i] = '\0';
if (find(str, wordDict, wordDictSize) && dp[i])
{
dp[j] = 1;
}
}
}
return dp[strlen(s)];
}
多重背包理论基础
有N种物品和一个容量为V的背包。第i种物品最多有Mi件可用,每件耗费的空间是Ci,价值是Wi 。求解将哪些物品装入背包可使这些物品的耗费的空间总和不超过背包容量,且价值总和最大。
多重背包和01背包是非常像的, 为什么和01背包像呢?
每件物品最多有Mi件可用,把Mi件摊开,其实就是一个01背包问题了。
例如:背包最大重量为10,物品为:
| 重量 | 价值 | 数量 | |
|---|---|---|---|
| 物品0 | 1 | 15 | 2 |
| 物品1 | 3 | 20 | 3 |
| 物品2 | 4 | 30 | 2 |
如果把数量展开,如下所示,就相当于一个01背包:
| 重量 | 价值 | 数量 | |
|---|---|---|---|
| 物品0 | 1 | 15 | 1 |
| 物品0 | 1 | 15 | 1 |
| 物品1 | 3 | 20 | 1 |
| 物品1 | 3 | 20 | 1 |
| 物品1 | 3 | 20 | 1 |
| 物品2 | 4 | 30 | 1 |
| 物品2 | 4 | 30 | 1 |
那么就可以像01背包一样来实现求解,代码如下:
void test_multi_pack() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
vector<int> nums = {2, 3, 2};
int bagWeight = 10;
for (int i = 0; i < nums.size(); i++) {
while (nums[i] > 1) { // nums[i]保留到1,把其他物品都展开
weight.push_back(weight[i]);
value.push_back(value[i]);
nums[i]--;
}
}
vector<int> dp(bagWeight + 1, 0);
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
for (int j = 0; j <= bagWeight; j++) {
cout << dp[j] << " ";
}
cout << endl;
}
cout << dp[bagWeight] << endl;
}
int main() {
test_multi_pack();
}
这里只要知道,多重背包可以展开然后变成01背包,类比的写出代码就可以了,leetcode暂时也没有相关的题目。
打家劫舍
例题198(中等)打家劫舍
注意要点:
- 当前房屋偷不偷,只取决于前两间房间的状态;
- dp[i]是指考虑i在内最多可以偷窃的金额为dp[i];
- 初始化,**dp[0]=nums[0]**是显然的,而第2个房间的金额,明显是0和1偷一个最大的,即:dp[1]=max(dp[0],dp[1]);
- 递推公式,起始也不需要记录是否偷过前一个屋子,可以直接写出来,如果i要偷,就是dp[i]=dp[i-2]+nums[i]; **如果i不偷,那么久可以考虑i-1,即dp[i]=dp[i-1];**所以可以得到递推公式:dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
下面贴出代码:
CPP版本
class Solution {
public:
int rob(vector<int>& nums) {
if (nums.size() == 1) {return nums[0];}
vector<int> dp(nums.size(), 0);
dp[0] = nums[0];
dp[1] = max(nums[0], nums[1]);
for (int i = 2; i < nums.size(); i++)
{
dp[i] = max(dp[i - 1], dp[i - 2] + nums[i]);
}
return dp[nums.size() - 1];
}
};
C版本
int rob(int* nums, int numsSize){
if (numsSize == 1) {return nums[0];}
else if (numsSize == 2) {return fmax(nums[0], nums[1]);}
int* dp = (int* )malloc(sizeof(int) * numsSize);
dp[0] = nums[0];
dp[1] = fmax(nums[0], nums[1]);
for (int i = 2; i < numsSize; i++)
{
dp[i] = fmax(dp[i - 2] + nums[i], dp[i - 1]);
}
return dp[numsSize - 1];
}
例题213(中等)打家劫舍II
注意要点:
- 因为成环,所以对头尾结点需要分类讨论,可分成不偷头部和不偷尾部两种情况;
- 递推公式以及初始化与上一题是类似的,这里不做赘述。
下面贴出代码:
CPP版本
class Solution {
private:
int robRange(const vector<int>& nums, int start, int end)
{
if (end - start == 1) {return nums[start];}
vector<int> dp(end - start, 0);
dp[0] = nums[start];
dp[1] = max(nums[start], nums[start + 1]);
for (int i = 2; i < end - start; i++)
{
dp[i] = max(dp[i - 1], dp[i - 2] + nums[i - start]);
}
return dp[end - start - 1];
}
public:
int rob(vector<int>& nums) {
if (nums.size() == 1) {return nums[0];}
int ret1 = robRange(nums, 0, nums.size() - 1);
int ret2 = robRange(nums, 1, nums.size());
return max(ret1, ret2);
}
};
C版本
int robRange(int* nums, int numsSize, int start, int end)
{
int* dp = (int* )malloc(sizeof(int) * numsSize);
dp[start] = nums[start];
dp[start + 1] = fmax(nums[start], nums[start + 1]);
for (int i = start + 2; i <= end; i++)
{
dp[i] = fmax(dp[i - 2] + nums[i], dp[i - 1]);
}
return dp[end];
}
int rob(int* nums, int numsSize){
if (numsSize == 1) {return nums[0];}
else if (numsSize == 2) {return fmax(nums[0], nums[1]);}
int ret1 = robRange(nums, numsSize, 0, numsSize - 2);
int ret2 = robRange(nums, numsSize, 1, numsSize - 1);
return fmax(ret1, ret2);
}
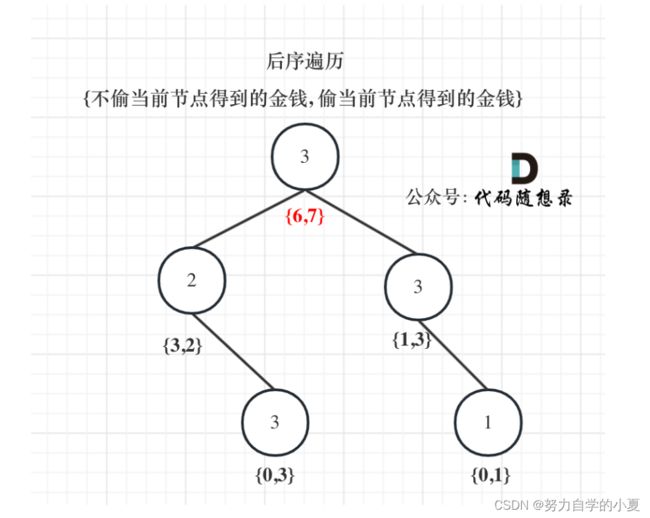
例题337(中等)打家劫舍III
注意要点:
- 首先要确定树的遍历顺序,这里要根据子节点判断父节点,所以肯定是后序遍历;
- 需要确定dp数组的定义:下标为0记录不偷该节点所得到的的最大金钱,下标为1记录偷该节点所得到的的最大金钱;
- 递推公式:如果要偷当前节点比较简单,dp[1]= cur->val + left[0] + right[0]; 如果不偷的话,意味着左右子节点都可以偷,那么就是取一个更大的情况:dp[0]=max(left[0], left[1]) + max(right[0], right[1]);
这道题是树形dp的比较典型的题目,可以好好钻研一下,下面就是推导的情况,老样子我白嫖了代码随想录的图:
下面贴出代码:
CPP版本
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
vector<int> traversal(TreeNode* cur)
{
//下标0就是不偷,下标1就是偷
if (!cur) {return vector<int> {0, 0};}
vector<int> left = traversal(cur->left);
vector<int> right = traversal(cur->right);
//不偷
int val1 = max(left[0], left[1]) + max(right[0], right[1]);
//偷
int val2 = cur->val + left[0] + right[0];
return vector<int> {val1, val2};
}
public:
int rob(TreeNode* root) {
vector<int> ret = traversal(root);
return max(ret[0], ret[1]);
}
};
C版本
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* };
*/
int* robTree(struct TreeNode* root)
{
int* ans = (int* )malloc(sizeof(int) * 2);
memset(ans, 0, sizeof(int) * 2);
if (!root) {return ans;}
int* left = robTree(root->left);
int* right = robTree(root->right);
//当前节点要偷
ans[1] = root->val + left[0] + right[0];
//当前节点不偷
ans[0] = fmax(left[0], left[1]) + fmax(right[0], right[1]);
return ans;
}
int rob(struct TreeNode* root){
int* ret = (int* )malloc(sizeof(int) * 2);
ret = robTree(root);
return fmax(ret[0], ret[1]);
}
买卖股票
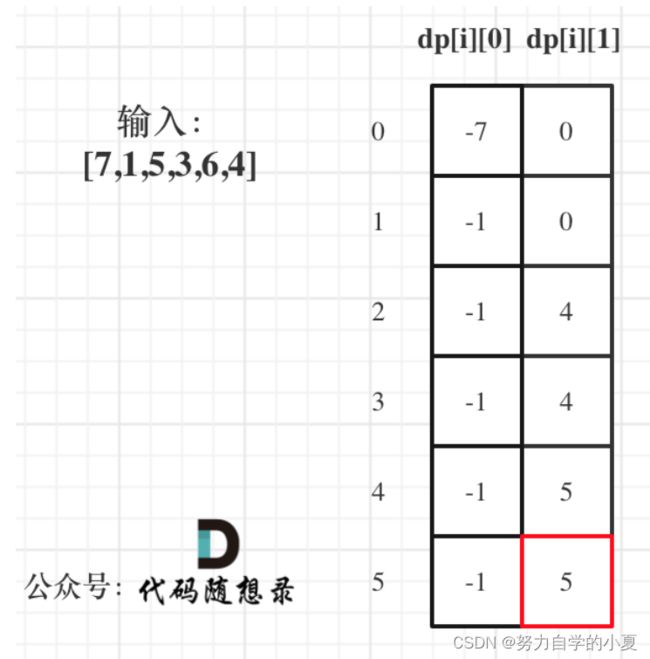
例题121(简单)买卖股票的最佳时机
注意要点:
- 可以直接贪心法,找到左边最小然后右边最大就可以了;
- 动态规划就需要定义一个二维dp,dp[i][0]表示第i天持有股票所得最多现金,而dp[i][1]表示第i天不持有股票所得最多现金;
- 由于一共只能交易一次,所以递推公式也比较好推导,我放在下面来写,看起来比较清晰;
- 初始化也比较好理解,dp[0][0]相当于直接持有股票,那么就是-prices[0],其余全部初始化为0即可。
关于递推公式,为了详尽一点记录,我放在这里给出:
dp[i][0]可以如此推导:
- 第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:dp[i - 1][0];
- 第i天买入股票,所得现金就是买入今天的股票后所得现金即:-prices[i];
dp[i][1]可以如此推导:
- 第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:dp[i - 1][1];
- 第i天卖出股票,所得现金就是按照今天股票价格卖出后所得现金即:prices[i] + dp[i - 1][0]。
下面给出推理的过程图,白嫖了代码随想录,可以跟着图推理一下,比较方便写代码进行理解:
下面贴出代码:
CPP版本
class Solution {
public:
int maxProfit(vector<int>& prices) {
int len = prices.size();
vector<vector<int>> dp(len, vector<int>(2, 0));
dp[0][0] -= prices[0];
for (int i = 1; i < len; i++)
{
dp[i][0] = max(dp[i - 1][0], -prices[i]);
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i]);
}
return dp[len - 1][1];
}
};
C版本
int maxProfit(int* prices, int pricesSize){
int** dp = (int** )malloc(sizeof(int* ) * pricesSize);
for (int i = 0; i < pricesSize; i++)
{
dp[i] = (int* )malloc(sizeof(int) * 2);
}
//列为0代表持有股票,列为1代表不持有
dp[0][0] = -prices[0];
dp[0][1] = 0;
for (int i = 1; i < pricesSize; i++)
{
dp[i][0] = fmax(dp[i - 1][0], -prices[i]);
dp[i][1] = fmax(dp[i - 1][0] + prices[i], dp[i - 1][1]);
}
return dp[pricesSize - 1][1];
}
例题122(中等)买卖股票的最佳时机II
注意要点:
- 本题和上一题基本一样,区别点就是能够多次交易,所以递推公式有所改变,其余均一样;
- 递推公式中,只有dp[i][0]有所改变,因为可以多次买卖,所以涉及买入,会变成dp[i][0]=dp[i-1][1]-prices[i]。
下面贴出代码:
CPP版本
class Solution {
public:
int maxProfit(vector<int>& prices) {
int len = prices.size();
vector<vector<int>> dp(len, vector<int>(2, 0));
dp[0][0] -= prices[0];
for (int i = 1; i < len; i++)
{
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i]);
}
return dp[len - 1][1];
}
};
C版本
class Solution {
public:
int maxProfit(vector<int>& prices) {
int ans = 0;
for (int i = 0; i < prices.size() - 1; i++)
{
int now = prices[i + 1] - prices[i];
ans += now > 0 ? now : 0;
}
return ans;
}
};
例题123(困难)买卖股票的最佳时机III
注意要点:
- 本题和上一题的区别点,就是上一题可以多次交易,但是本题限制了交易次数最多为两次;
- 交易两次,需要记录的就是五种状态,所以dp数组可以定义成如下:0表示没有操作,1表示第一次持有股票,2表示第一次不持有股票,3表示第二次持有股票,4表示第二次不持有股票;
- 递推公式我放在下面进行详述;
- 初始化其实跟之前是一样的,只不过第二次持有有点绕,可以理解为我当天完成了一次买卖然后再次买进,所以dp[0][3]和dp[0][1]是一样的,dp[0][1]=dp[0][3]=-prices[0];
递推公式的推导如下所示:
达到dp[i][1]状态,有两个具体操作:
- 操作一:第i天买入股票了,那么dp[i][1] = dp[i-1][0] - prices[i];
- 操作二:第i天没有操作,而是沿用前一天买入的状态,即:dp[i][1] = dp[i - 1][1];
而为了利益最大化,一定是取两者的最大值,所以 dp[i][1] = max(dp[i-1][0] - prices[i], dp[i - 1][1]);
同理dp[i][2]也有两个操作:
- 操作一:第i天卖出股票了,那么dp[i][2] = dp[i - 1][1] + prices[i];
- 操作二:第i天没有操作,沿用前一天卖出股票的状态,即:dp[i][2] = dp[i - 1][2];
所以dp[i][2] = max(dp[i - 1][1] + prices[i], dp[i - 1][2]);
同理可推出剩下状态部分:
dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] - prices[i]);
dp[i][4] = max(dp[i - 1][4], dp[i - 1][3] + prices[i]);
为了更好的便于理解,我把推导图也偷过来了,如下所示:以输入[1,2,3,4,5]为例

函数的返回值就是最右下角的值,原因就是,假设第一次卖出是最大值,那么完全可以最后一天再次进行买进卖出,这样最大值就会记录在第二次卖出之中。
下面贴出代码:
CPP版本
class Solution {
public:
int maxProfit(vector<int>& prices) {
int len = prices.size();
vector<vector<int>> dp(len, vector<int>(5, 0));
dp[0][1] -= prices[0];
dp[0][3] -= prices[0];
//分成五种状态,0就是无操作,1就是第一次卖出,2是第一次买进
//3是第二次卖出,4是第二次买进
for (int i = 1; i < len; i++)
{
dp[i][0] = dp[i - 1][0];
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] - prices[i]);
dp[i][2] = max(dp[i - 1][2], dp[i - 1][1] + prices[i]);
dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] - prices[i]);
dp[i][4] = max(dp[i - 1][4], dp[i - 1][3] + prices[i]);
}
return dp[len - 1][4];
}
};
C版本
int maxProfit(int* prices, int pricesSize){
int** dp = (int** )malloc(sizeof(int* ) * pricesSize);
for (int i = 0; i < pricesSize; i++)
{
dp[i] = (int* )malloc(sizeof(int) * 5);
}
dp[0][0] = 0;
dp[0][1] = -prices[0];
dp[0][2] = 0;
dp[0][3] = -prices[0];
dp[0][4] = 0;
for (int i = 1; i < pricesSize; i++)
{
dp[i][0] = dp[i - 1][0];
dp[i][1] = fmax(dp[i - 1][0] - prices[i], dp[i - 1][1]);
dp[i][2] = fmax(dp[i - 1][1] + prices[i], dp[i - 1][2]);
dp[i][3] = fmax(dp[i - 1][2] - prices[i], dp[i - 1][3]);
dp[i][4] = fmax(dp[i - 1][3] + prices[i], dp[i - 1][4]);
}
return dp[pricesSize - 1][4];
}
例题188(困难)买卖股票的最佳时机IV
注意要点:
- 本题是上一题的再次升级版,从最多交易2次升级到最多交易k次;
- 初始化以及递推逻辑是一样的,只不过具体实现要嵌套一个for循环。
下面贴出代码:
CPP版本
class Solution {
public:
int maxProfit(int k, vector<int>& prices) {
int len = prices.size();
vector<vector<int>> dp(len, vector<int>(2 * k + 1, 0));
for (int i = 1; i < 2 * k; i += 2) {dp[0][i] -= prices[0];}
for (int i = 1; i < len; i++)
{
dp[i][0] = dp[i - 1][0];
for (int j = 1; j < 2 * k + 1; j += 2)
{
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - 1] - prices[i]);
dp[i][j + 1] = max(dp[i - 1][j + 1], dp[i - 1][j] + prices[i]);
}
}
return dp[len - 1][2 * k];
}
};
C版本
int maxProfit(int k, int* prices, int pricesSize){
int** dp = (int** )malloc(sizeof(int* ) * pricesSize);
for (int i = 0; i < pricesSize; i++)
{
dp[i] = (int* )malloc(sizeof(int) * (2 * k + 1));
}
dp[0][0] = 0;
for (int i = 1; i < 2 * k + 1; i++)
{
if (i % 2) {dp[0][i] = -prices[0];}
else {dp[0][i] = 0;}
}
for (int i = 1; i < pricesSize; i++)
{
dp[i][0] = dp[i - 1][0];
for (int j = 1; j < 2 * k + 1; j++)
{
if (j % 2) {dp[i][j] = fmax(dp[i - 1][j - 1] - prices[i], dp[i - 1][j]);}
else {dp[i][j] = fmax(dp[i - 1][j - 1] + prices[i], dp[i - 1][j]);}
}
}
return dp[pricesSize - 1][2 * k];
}
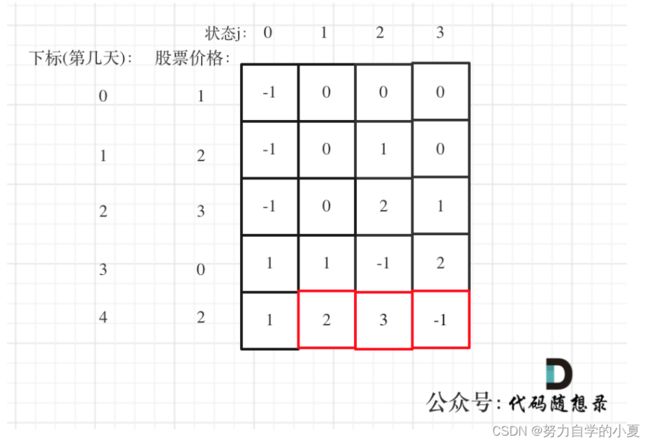
例题309(中等)最佳买卖股票时机含冷冻期
注意要点:
这道题跟执勤的相比,多了一个冷冻期,所以复杂了许多,我按照动规五部曲来记录解题笔记:
- dp数组的定义:可以分为四个状态,一个持有状态,两个不持有状态以及一个冷冻状态,不持有状态可以分为保持不持有和今天卖出不持有;
- 这里主要比较困难的是持有状态应该怎么递推,可以分为两种,一个是一直持有,一个是今天买入,而买入也可以分为两种,一个是冷冻结束买入,一个是不持有买入;
- 另外几个递推比较好理解,这里就不赘述,可以直接看代码;
- dp的初始化,只要初始化持有为dp[0][0]=-prices[0]即可;
这里光看文字还是有些晦涩,我把推导图白嫖来了,以[1,2,3,0,2]为例:
下面贴出代码:
CPP版本
class Solution {
public:
int maxProfit(vector<int>& prices) {
int len = prices.size();
vector<vector<int>> dp(len, vector<int>(4, 0));
dp[0][0] -= prices[0];
for (int i = 1; i < len; i++)
{
dp[i][0] = max(dp[i - 1][0], max(dp[i - 1][1], dp[i - 1][3]) - prices[i]);
dp[i][1] = max(dp[i - 1][1], dp[i - 1][3]);
dp[i][2] = dp[i - 1][0] + prices[i];
dp[i][3] = dp[i - 1][2];
}
return max(dp[len - 1][1], max(dp[len - 1][2], dp[len - 1][3]));
}
};
C版本
int maxProfit(int* prices, int pricesSize){
int** dp = (int** )malloc(sizeof(int* ) * pricesSize);
for (int i = 0; i < pricesSize; i++)
{
dp[i] = (int* )malloc(sizeof(int) * (4));
}
//0代表保持持有,1代表保持不持有,2代表卖出,3代表冻结
dp[0][0] = -prices[0];
dp[0][1] = dp[0][2] = dp[0][3] = 0;
for (int i = 1; i < pricesSize; i++)
{
dp[i][0] = fmax(dp[i - 1][0], fmax(dp[i - 1][1], dp[i - 1][3]) - prices[i]);
dp[i][1] = fmax(dp[i - 1][1], dp[i - 1][3]);
dp[i][2] = dp[i - 1][0] + prices[i];
dp[i][3] = dp[i - 1][2];
}
return fmax(dp[pricesSize-1][1], fmax(dp[pricesSize-1][2], dp[pricesSize-1][3]));
}
例题714(中等)买卖股票的最佳时机含手续费
注意要点:
- 能多次买卖,只不过增加了一个手续费,再递推的完成卖出位置减去fee就可以了。
下面贴出代码:
CPP版本
class Solution {
public:
int maxProfit(vector<int>& prices, int fee) {
int len = prices.size();
vector<vector<int>> dp(len, vector<int>(2, 0));
dp[0][0] -= prices[0];
for (int i = 1; i < len; i++)
{
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i] - fee);
}
return max(dp[len - 1][0], dp[len - 1][1]);
}
};
C版本
int maxProfit(int* prices, int pricesSize, int fee){
int** dp = (int** )malloc(sizeof(int* ) * pricesSize);
for (int i = 0; i < pricesSize; i++)
{
dp[i] = (int* )malloc(sizeof(int) * 2);
}
dp[0][0] = -prices[0];
dp[0][1] = 0;
for (int i = 1; i < pricesSize; i++)
{
dp[i][0] = fmax(dp[i - 1][0], dp[i - 1][1] - prices[i]);
dp[i][1] = fmax(dp[i - 1][0] + prices[i] - fee, dp[i - 1][1]);
}
return fmax(dp[pricesSize - 1][0], dp[pricesSize - 1][1]);
}
子序列
例题300(中等)最长递增子序列
这道题是我二刷现在做笔记的时候没啥思路的题目,要好好看一下!
注意要点:
- 需要明确dp的定义,这样题就会好做很多,这里dp[i]定义为i之前包括i的以nums[i]结尾的最长递增子序列的长度;
- 根据dp的定义,就可以知道需要两层for循环,再内部的嵌套循环比较i与其前方的j的大小来完成递推;
- 递推公式就是:位置i的最长升序子序列等于j从0到i-1各个位置的最长升序子序列 + 1 的最大值;
- dp的初始化,都可以初始化为1。
下面贴出代码:
CPP版本
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
int len = nums.size();
if (len <= 1) {return len;}
vector<int> dp(len, 1);
int result = 0;
for (int i = 1; i < len; i++)
{
for (int j = 0; j < i; j++)
{
if (nums[i] > nums[j]) {dp[i] = max(dp[i], dp[j] + 1);}
}
result = max(result, dp[i]);
}
return result;
}
};
C版本
int lengthOfLIS(int* nums, int numsSize){
if (numsSize == 1) {return 1;}
int* dp = (int* )malloc(sizeof(int) * numsSize);
for (int i = 0; i < numsSize; i++) {dp[i] = 1;}
int ret = 0;
for (int i = 1; i < numsSize; i++)
{
for (int j = 0; j < i; j++)
{
if (nums[i] > nums[j])
{
dp[i] = fmax(dp[i], dp[j] + 1);
}
}
ret = fmax(ret, dp[i]);
}
return ret;
}
例题674(简单)最长连续递增序列
注意要点:
- 这一题比上一题简单,因为只需要循环中与上一个进行比较就可以了。
下面贴出代码:
CPP版本
class Solution {
public:
int findLengthOfLCIS(vector<int>& nums) {
int len = nums.size();
if (len <= 1) {return len;}
vector<int> dp(len, 1);
int result = 0;
for (int i = 1; i < len; i++)
{
if (nums[i] > nums[i - 1]) {dp[i] = dp[i - 1] + 1;}
result = max(result, dp[i]);
}
return result;
}
};
C版本
int findLengthOfLCIS(int* nums, int numsSize){
if (numsSize == 1) {return 1;}
int* dp = (int* )malloc(sizeof(int) * numsSize);
for (int i = 0; i < numsSize; i++) {dp[i] = 1;}
int ret = 0;
for (int i = 1; i < numsSize; i++)
{
if (nums[i] > nums[i - 1])
{
dp[i] = fmax(dp[i], dp[i - 1] + 1);
}
ret = fmax(dp[i], ret);
}
return ret;
}
例题718(中等)最长重复子数组
注意要点:
- 确定dp定义:dp[i][j] :以下标i - 1为结尾的A,和以下标j - 1为结尾的B,最长重复子数组长度为dp[i][j]; (特别注意: “以下标i - 1为结尾的A” 标明一定是 以A[i-1]为结尾的字符串 )
- 以上定义可知,所有的循环比较都是从i,j=1开始的;
- 递推公式比较简单,i-1和j-1的字符一样,dp[i][j]=dp[i-1][j-1]+1;
- 根据dp[i][j]的定义,dp[i][0] 和dp[0][j]其实都是没有意义的!但是为了简便计算,可以都初始化为0。
下面贴出代码:
CPP版本
class Solution {
public:
int findLength(vector<int>& nums1, vector<int>& nums2) {
int len1 = nums1.size(), len2 = nums2.size();
vector<vector<int>> dp(len1 + 1, vector<int>(len2 + 1, 0));
int result = 0;
for (int i = 1; i <= len1; i++)
{
for (int j = 1; j <= len2; j++)
{
if (nums1[i - 1] == nums2[j - 1]) {dp[i][j] = dp[i - 1][j - 1] + 1;}
result = max(result, dp[i][j]);
}
}
return result;
}
};
C版本
int findLength(int* nums1, int nums1Size, int* nums2, int nums2Size){
int m = nums1Size, n = nums2Size;
int** dp = (int** )malloc(sizeof(int* ) * (m + 1));
for (int i = 0; i < m + 1; i++)
{
dp[i] = (int* )malloc(sizeof(int) * (n + 1));
}
for (int i = 0; i < m + 1; i++)
{
for (int j = 0; j < n + 1; j++) {dp[i][j] = 0;}
}
int ret = 0;
for (int i = 1; i < m + 1; i++)
{
for (int j = 1; j < n + 1; j++)
{
if (nums1[i - 1] == nums2[j - 1])
{
dp[i][j] = dp[i - 1][j - 1] + 1;
}
ret = fmax(ret, dp[i][j]);
}
}
return ret;
}
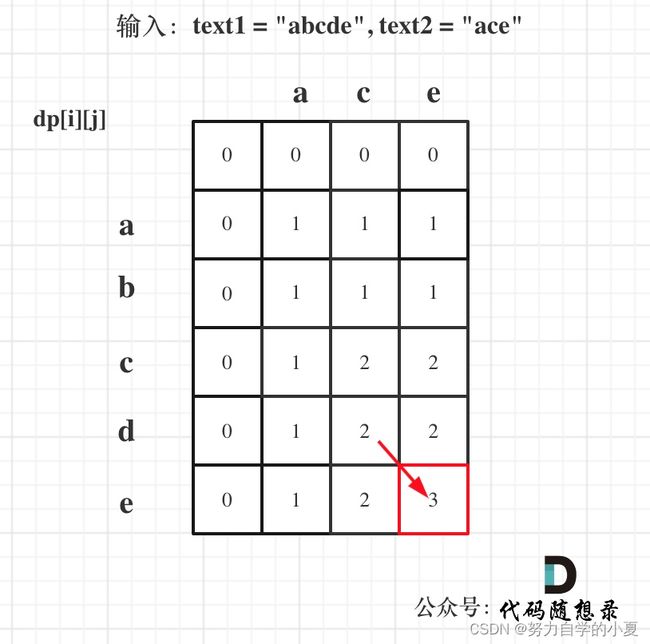
例题1143(中等)最长公共子序列
注意要点:
- dp数组的定义,在公共子序列中是一样的,这里就不再赘述,只要记住为了初始化方便都是dp[i][j[对应的i-1和j-1处的比较就可以了;
- 递推公式也很好理解,如果相等那就+1:dp[i][j]=dp[i-1][j-1]+1;与上一题的区别在于,如果不相等,那就看看text1[0, i - 2]与text2[0, j - 1]的最长公共子序列 和 text1[0, i - 1]与text2[0, j - 2]的最长公共子序列,取最大的。
这一题不是那么好想,总的来说就是**dp[i][j]的递推是通过其左上角的三个元素来决定的!**以输入:text1 = “abcde”, text2 = “ace” 为例,dp状态如图:
下面贴出代码:
CPP版本
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
int len1 = text1.size(), len2 = text2.size();
vector<vector<int>> dp(len1 + 1, vector<int>(len2 + 1, 0));
for (int i = 1; i <= len1; i++)
{
for (int j = 1; j <= len2; j++)
{
if (text1[i - 1] == text2[j - 1]) {dp[i][j] = dp[i - 1][j - 1] + 1;}
else dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
return dp[len1][len2];
}
};
C版本
int longestCommonSubsequence(char * text1, char * text2){
int m = strlen(text1), n = strlen(text2);
int** dp = (int** )malloc(sizeof(int* ) * (m + 1));
for (int i = 0; i < m + 1; i++)
{
dp[i] = (int* )malloc(sizeof(int) * (n + 1));
}
//全部初始化为0
for (int i = 0; i < m + 1; i++)
{
for (int j = 0; j < n + 1; j++)
{
dp[i][j] = 0;
}
}
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
if (text1[i - 1] == text2[j - 1])
{
dp[i][j] = dp[i - 1][j - 1] + 1;
}
else
{
dp[i][j] = fmax(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[m][n];
}
例题1035(中等)不相交的线
注意要点:
- 直线不能相交,这就是说明在字符串A中 找到一个与字符串B相同的子序列,且这个子序列不能改变相对顺序,只要相对顺序不改变,链接相同数字的直线就不会相交;
- 求的是直线的数量,其实可以发现,**就是在求最长公共子序列!**直接拷贝过来就可以了。
下面贴出代码:
CPP版本
class Solution {
public:
int maxUncrossedLines(vector<int>& nums1, vector<int>& nums2) {
int len1 = nums1.size(), len2 = nums2.size();
vector<vector<int>> dp(len1 + 1, vector<int>(len2 + 1, 0));
for (int i = 1; i <= len1; i++)
{
for (int j = 1; j <= len2; j++)
{
if (nums1[i - 1] == nums2[j - 1]) {dp[i][j] = dp[i - 1][j - 1] + 1;}
else dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
return dp[len1][len2];
}
};
C版本
int maxUncrossedLines(int* nums1, int nums1Size, int* nums2, int nums2Size){
int m = nums1Size, n = nums2Size;
int** dp = (int** )malloc(sizeof(int* ) * (m + 1));
for (int i = 0; i <= m; i++)
{
dp[i] = (int* )malloc(sizeof(int) * (n + 1));
}
for (int i = 0; i <= m; i++)
{
for (int j = 0; j <= n; j++)
{
dp[i][j] = 0;
}
}
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
if (nums1[i - 1] == nums2[j - 1])
{
dp[i][j] = dp[i - 1][j - 1] + 1;
}
else
{
dp[i][j] = fmax(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[m][n];
}
例题53(中等)最大子序列和
注意要点:
- dp的数组定义为:dp[i]是包括下标i的最大连续子序列和;
- 递推公式还是比较好想的,要么就加入之前的序列,要么就从头重新开始一个序列,故:dp[i] = max(dp[i - 1] + nums[i], nums[i]);
- 根据定义就可以知道,直接初始化dp[0]=nums[0]即可。
下面贴出代码:
CPP版本
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int len = nums.size();
vector<int> dp(len, 0);
dp[0] = nums[0];
int result = dp[0];
for (int i = 1; i < len; i++)
{
dp[i] = max(dp[i - 1] + nums[i], nums[i]);
result = max(result, dp[i]);
}
return result;
}
};
C版本
int maxSubArray(int* nums, int numsSize){
int* dp = (int* )malloc(sizeof(int) * numsSize);
dp[0] = nums[0];
int ret = nums[0];
for (int i = 1; i < numsSize; i++)
{
dp[i] = fmax(dp[i - 1] + nums[i], nums[i]);
ret = fmax(dp[i], ret);
}
return ret;
}
编辑距离
例题392(简单)判断子序列
这道题可以直接双指针做,所以是一道简单题,思路我也不写了,直接贴一版代码,一看就懂了:
class Solution {
public:
bool isSubsequence(string s, string t) {
int ptr_s = 0, ptr_t = 0;
while (ptr_t < t.size())
{
if (s[ptr_s] == t[ptr_t]) {ptr_s++;}
if (ptr_s == s.size()) {break;}
ptr_t++;
}
if (ptr_s == s.size()) {return 1;}
return 0;
}
};
这是编辑距离的动规基础,这里按照动规五部曲来进行分析:
- 确定dp数组定义
dp[i][j] 表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]。
需要注意的是,判断s是否为t的子序列。即t的长度是大于等于s的。
- 确定递推公式
在确定递推公式的时候,首先要考虑如下两种操作,整理如下:
- if (s[i - 1] == t[j - 1])
- t中找到了一个字符在s中也出现了
- if (s[i - 1] != t[j - 1])
- 相当于t要删除元素,继续匹配
if (s[i - 1] == t[j - 1]),那么dp[i][j] = dp[i - 1][j - 1] + 1;,因为找到了一个相同的字符,相同子序列长度自然要在dp[i-1][j-1]的基础上加1;
if (s[i - 1] != t[j - 1]),此时相当于t要删除元素,t如果把当前元素t[j - 1]删除,那么dp[i][j]的数值就是看s[i - 1]与 t[j - 2]的比较结果了,即:dp[i][j] = dp[i][j - 1];
- dp初始化
从递推公式可以看出dp[i][j]都是依赖于dp[i - 1][j - 1] 和 dp[i][j - 1],所以**dp[0][0]和dp[i][0]**是一定要初始化的,直接都给0就可以了。
这里就可以知道,定义dp[i][j]使用的是i-1的s和j-1的t就是为了方便我们的初始化!
- 确定遍历顺序
从递推公式可以看出,左上角和左侧元素来进行当前状态的推导,所以从上到下,从左到右遍历。
- 举例推导dp
输入:s = “abc”, t = “ahbgdc”,dp状态转移图如下:

下面贴出代码:
CPP版本
class Solution {
public:
bool isSubsequence(string s, string t) {
int lens = s.size(), lent = t.size();
vector<vector<int>> dp(lens + 1, vector<int>(lent + 1, 0));
for (int i = 1; i <= lens; i++)
{
for (int j = 1; j <= lent; j++)
{
if (s[i - 1] == t[j - 1]) {dp[i][j] = dp[i - 1][j - 1] + 1;}
else dp[i][j] = dp[i][j - 1];
}
}
return dp[lens][lent] == lens;
}
};
C版本
bool isSubsequence(char * s, char * t){
int m = strlen(s), n = strlen(t);
int** dp = (int** )malloc(sizeof(int* ) * (m + 1));
for (int i = 0; i <= m; i++)
{
dp[i] = (int* )malloc(sizeof(int) * (n + 1));
}
for (int i = 0; i <= m; i++)
{
for (int j = 0; j <= n; j++)
{
dp[i][j] = 0;
}
}
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
if (s[i - 1] == t[j - 1]) {dp[i][j] = dp[i - 1][j - 1] + 1;}
else {dp[i][j] = dp[i][j - 1];}
}
}
if (dp[m][n] == m) {return true;}
return false;
}
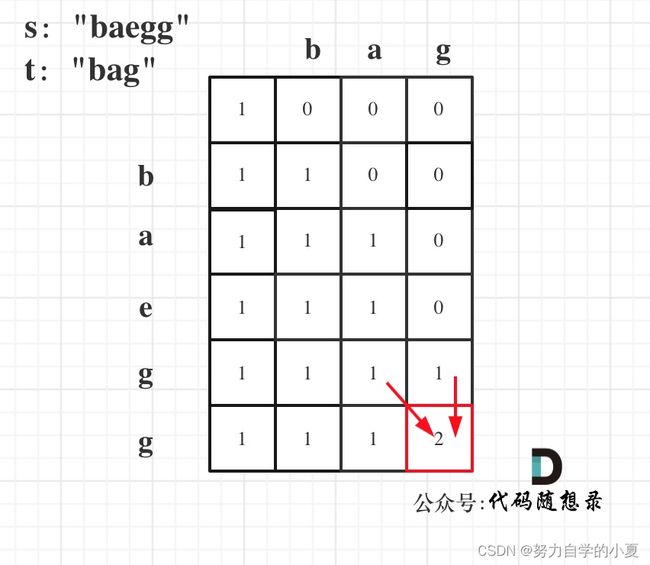
例题115(困难)不同的子序列
这一题的大致思路与上一题类似:
- dp的定义有所改变:dp[i][j]表示以i-1为结尾的s子序列中包含以j-1结尾的t子序列的个数;
- 递推公式中,根据题目要求也有所改变:
- 如果s[i-1]==t[j-1],那么就可以从两个方向进行推导,一个是用s[i-1]来匹配,那么个数就是dp[i-1][j-1];另一个就是不用s[i-1]匹配,那么个数就是dp[i-1][j];
- 如果s[i-1]!=t[j-1],dp[i][j]只有一部分组成,不用s[i - 1]来匹配(就是模拟在s中删除这个元素),即:dp[i - 1][j];
- dp数组的定义变了,所以初始化也需要重新考虑;因为递推公式可以看出递推是根据左上角和上方元素进行推导的,所以我们需要初始化的就是dp[i][0]以及dp[0][j];
- dp[i][0] 表示:以i-1为结尾的s可以随便删除元素,出现空字符串的个数,所以dp[i][0]都是1;dp[0][j]:空字符串s可以随便删除元素,出现以j-1为结尾的字符串t的个数,所以dp[0][j]都是0;
- 初始化还需要注意特殊位置,dp[0][0]应该是1,空字符串s,可以删除0个元素,变成空字符串t;
- 最后可以举例推导一下。
以s:“baegg”,t:"bag"为例,推导dp数组状态如下:
下面贴出代码:
CPP版本
class Solution {
public:
int numDistinct(string s, string t) {
int lens = s.size(), lent = t.size();
vector<vector<uint64_t>> dp(lens + 1, vector<uint64_t>(lent + 1, 0));
for (int i = 0; i < lens; i++) {dp[i][0] = 1;}
for (int i = 1; i <= lens; i++)
{
for (int j = 1; j <= lent; j++)
{
if (s[i - 1] == t[j - 1]) {dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];}
else dp[i][j] = dp[i - 1][j];
}
}
return dp[lens][lent];
}
};
C版本
int numDistinct(char * s, char * t){
int m = strlen(s), n = strlen(t);
double** dp = (int** )malloc(sizeof(double* ) * (m + 1));
for (int i = 0; i <= m; i++)
{
dp[i] = (double* )malloc(sizeof(double) * (n + 1));
}
//初始化,根据dp定义,dp[i][0] = 1,除了dp[0][0]外dp[0][j] = 0;
for (int i = 0; i <= m; i++) {dp[i][0] = 1;}
for (int i = 1; i <= n; i++) {dp[0][i] = 0;}
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
if (s[i - 1] == t[j - 1])
{
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
}
else
{
dp[i][j] = dp[i - 1][j];
}
}
}
return dp[m][n];
}
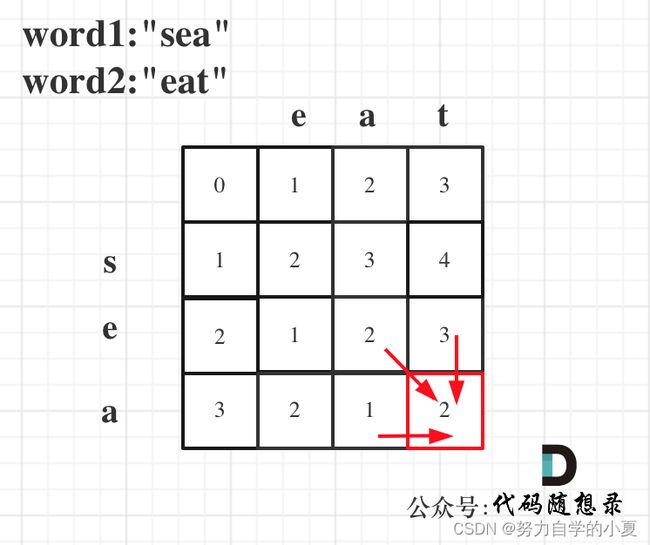
例题583(中等)两个字符串的删除操作
注意要点:
- dp定义:dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数;
- 递推公式
- 当word1[i - 1] 与 word2[j - 1]相同的时候;
- 当word1[i - 1] 与 word2[j - 1]不相同的时候;
相等的时候很好理解,就不需要删除,所以dp[i][j]=dp[i-1][j-1];
不相等的时候,就有三种删除情况:
情况一:删word1[i - 1],最少操作次数为dp[i - 1][j] + 1;
情况二:删word2[j - 1],最少操作次数为dp[i][j - 1] + 1;
情况三:同时删word1[i - 1]和word2[j - 1],操作的最少次数为dp[i - 1][j - 1] + 2;
因为 dp[i][j - 1] + 1 = dp[i - 1][j - 1] + 2,所以递推公式可简化为:dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);(相等是因为同时删word1[i - 1]和word2[j - 1],dp[i][j-1] 本来就不考虑 word2[j - 1]了,那么我在删 word1[i - 1],就达到两个元素都删除的效果)
- 初始化倒是好理解,需要初始化最左侧和最上方,要删除成与空字符串相同,所以dp[i][0] = i,dp[0][j]=j;
最后可以举例推导一下,以word1:“sea”,word2:"eat"为例,推导dp数组状态图如下:
下面贴出代码:
CPP版本
class Solution {
public:
int minDistance(string word1, string word2) {
int len1 = word1.size(), len2 = word2.size();
vector<vector<int>> dp(len1 + 1, vector<int>(len2 + 1, 0));
for (int i = 0; i <= len1; i++) {dp[i][0] = i;}
for (int j = 0; j <= len2; j++) {dp[0][j] = j;}
for (int i = 1; i <= len1; i++)
{
for (int j = 1; j <= len2; j++)
{
if (word1[i - 1] == word2[j - 1]) {dp[i][j] = dp[i - 1][j - 1];}
else dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
}
}
return dp[len1][len2];
}
};
C版本
int minDistance(char * word1, char * word2){
int m = strlen(word1), n = strlen(word2);
int** dp = (int** )malloc(sizeof(int* ) * (m + 1));
for (int i = 0; i < m + 1; i++)
{
dp[i] = (int* )malloc(sizeof(int) * (n + 1));
}
for (int i = 0; i <= m; i++) {dp[i][0] = i;}
for (int j = 0; j <= n; j++) {dp[0][j] = j;}
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
if (word1[i - 1] == word2[j - 1]) {dp[i][j] = dp[i - 1][j - 1];}
else dp[i][j] = fmin(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
}
}
return dp[m][n];
}
当然我感觉这种解题不是特别好理解,我把题目理解成求最长公共子序列不就好了嘛,对于要删除的元素不就是总长度-2*最长公共子序列就完事了。
下面贴出代码:
CPP版本
class Solution {
public:
int minDistance(string word1, string word2) {
int len1 = word1.size(), len2 = word2.size();
vector<vector<int>> dp(len1 + 1, vector<int>(len2 + 1, 0));
for (int i = 1; i <= len1; i++)
{
for (int j = 1; j <= len2; j++)
{
if (word1[i - 1] == word2[j - 1]) {dp[i][j] = dp[i - 1][j - 1] + 1;}
else dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
return len1 + len2 - 2 * dp[len1][len2];
}
};
C版本
int minDistance(char * word1, char * word2){
int m = strlen(word1), n = strlen(word2);
int** dp = (int** )malloc(sizeof(int* ) * (m + 1));
for (int i = 0; i < m + 1; i++)
{
dp[i] = (int* )malloc(sizeof(int) * (n + 1));
}
//全部初始化为0
for (int i = 0; i < m + 1; i++)
{
for (int j = 0; j < n + 1; j++)
{
dp[i][j] = 0;
}
}
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
if (word1[i - 1] == word2[j - 1])
{
dp[i][j] = dp[i - 1][j - 1] + 1;
}
else
{
dp[i][j] = fmax(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return m + n - 2 * dp[m][n];
}
例题72(困难)编辑距离
本题是上一题的再进阶版,因为增、删、改都可以,所以递推公式还要改变,其余的操作都是类似的,就不再赘述了。
如果当前字符相等,这个简单,就是dp[i][j]=dp[i-1][j-1];
如果不相等:
-
操作一:word1删除一个元素,那么就是以下标i - 2为结尾的word1 与 j-1为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i - 1][j] + 1; -
操作二:word2删除一个元素,那么就是以下标i - 1为结尾的word1 与 j-2为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i][j - 1] + 1;
word2添加一个元素,相当于word1删除一个元素,同理反过来也是一样,所以增删是可以写在一起的;
- 操作三:替换元素,word1替换word1[i - 1],使其与word2[j - 1]相同,此时不用增删加元素,那么只需要一次替换的操作,就可以让 word1[i - 1] 和 word2[j - 1] 相同。
所以 dp[i][j] = dp[i - 1][j - 1] + 1;
基于以上分析,可以给出输入:word1 = “horse”, word2 = "ros"为例,dp矩阵状态图如下:
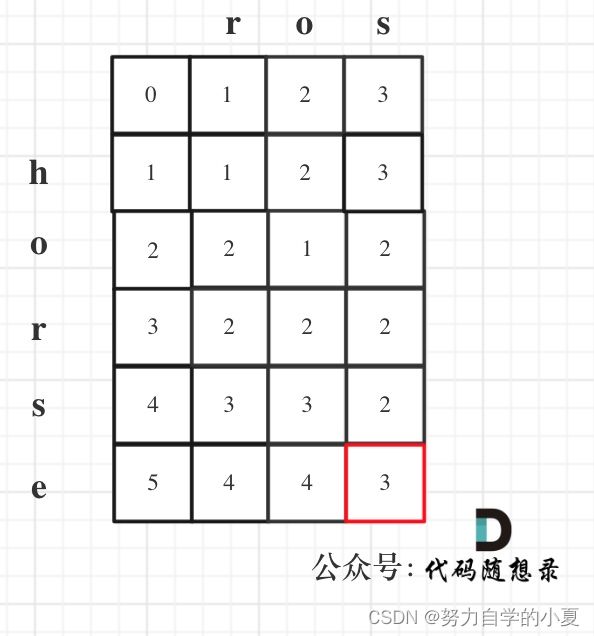
下面贴出代码:
CPP版本
class Solution {
public:
int minDistance(string word1, string word2) {
int len1 = word1.size(), len2 = word2.size();
vector<vector<int>> dp(len1 + 1, vector<int>(len2 + 1, 0));
for (int i = 0; i <= len1; i++) dp[i][0] = i;
for (int j = 0; j <= len2; j++) dp[0][j] = j;
for (int i = 1; i <= len1; i++)
{
for (int j = 1; j <= len2; j++)
{
if (word1[i - 1] == word2[j - 1]) {dp[i][j] = dp[i - 1][j - 1];}
else dp[i][j] = min({dp[i - 1][j], dp[i][j - 1], dp[i - 1][j - 1]}) + 1;
}
}
return dp[len1][len2];
}
};
C版本
int minDistance(char * word1, char * word2){
int m = strlen(word1), n = strlen(word2);
int** dp = (int** )malloc(sizeof(int* ) * (m + 1));
for (int i = 0; i < m + 1; i++)
{
dp[i] = (int* )malloc(sizeof(int) * (n + 1));
}
for (int i = 0; i <= m; i++) {dp[i][0] = i;}
for (int j = 0; j <= n; j++) {dp[0][j] = j;}
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
if (word1[i - 1] == word2[j - 1]) {dp[i][j] = dp[i - 1][j - 1];}
else
{
dp[i][j] = fmin(dp[i-1][j], fmin(dp[i][j - 1], dp[i - 1][j - 1])) + 1;
}
}
}
return dp[m][n];
}
回文相关
这类题目如果用动态规划,dp的定义就不是那么直接了,所以有空还是要多看看,温故知新。
例题647(中等)回文子串
因为二刷的时候,只记得遍历顺序其他都记不清了,所以还是动规五部曲走起,加深印象。
- 确定dp定义
布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如果是dp[i][j]为true,否则为false;
- 确定递推公式
当s[i]与s[j]不相等,那没啥好说的了,dp[i][j]一定是false。
当s[i]与s[j]相等时,这就复杂一些了,有如下三种情况:
- 情况一:下标i 与 j相同,同一个字符例如a,当然是回文子串;
- 情况二:下标i 与 j相差为1,例如aa,也是回文子串;
- 情况三:下标:i 与 j相差大于1的时候,看i到j区间是不是回文子串就看区间 i+1 与 j-1区间,这个区间是不是回文就看dp[i + 1][j - 1]是否为true。
- 初始化
这个简单,肯定是全部初始化为false
- 确定遍历顺序
本题的遍历顺序是很有技巧的:首先从递推公式可以看到,我们的元素是否true都是根据左下角来判断的,如果这矩阵是从上到下,从左到右遍历,那么会用到没有计算过的dp[i + 1][j - 1],也就是根据不确定是不是回文的区间[i+1,j-1],来判断了[i,j]是不是回文,那结果一定是不对的。
所以一定要从下到上,从左到右遍历,这样保证dp[i + 1][j - 1]都是经过计算的。
最后可以举例推导一下,输入:“aaa”,dp[i][j]状态如下: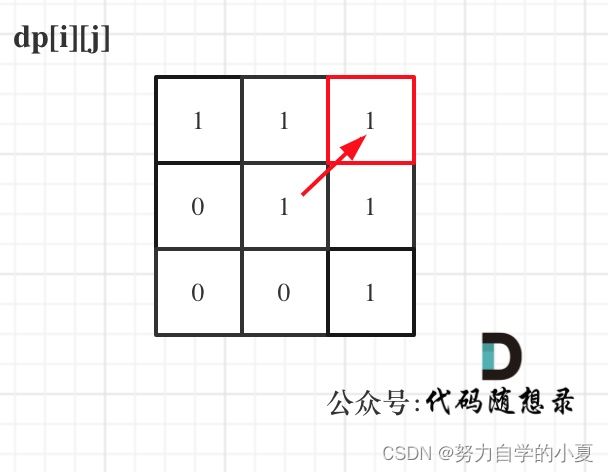
下面贴出代码:
CPP版本
class Solution {
public:
int countSubstrings(string s) {
vector<vector<bool>> dp(s.size(), vector<bool>(s.size(), 0));
int ret = 0;
for (int i = s.size() - 1; i >= 0; i--)
{
for (int j = i; j < s.size(); j++)
{
if (s[i] == s[j])
{
if (j - i <= 1) {ret++;dp[i][j] = 1;}
else if (dp[i + 1][j - 1]) {ret++;dp[i][j] = 1;}
}
}
}
return ret;
}
};
C版本
int countSubstrings(char * s){
int n = strlen(s);
bool** dp = (int** )malloc(sizeof(bool* ) * n);
for (int i = 0; i < n; i++) {dp[i] = (bool* )malloc(sizeof(bool) * n);}
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++) {dp[i][j] = 0;}
}
int ret = 0;
for (int i = n; i >= 0; i--)
{
for (int j = i; j < n; j++)
{
if (s[i] == s[j])
{
if (j - i <= 1 || dp[i + 1][j - 1])
{
ret++;
dp[i][j] = 1;
}
}
}
}
return ret;
}
例题516(中等)最长回文子序列
由于不熟悉,还是看了看解答才有的思路,所以依然动规五部曲。
- dp定义
dp[i][j]:字符串s在[i, j]范围内最长的回文子序列的长度为dp[i][j]。
- 确定递推公式
这道题的递推公式,只要dp定义好还是比较好推的:
如果s[i]与s[j]相同,那么dp[i][j] = dp[i + 1][j - 1] + 2;
如果s[i]与s[j]不相同,说明s[i]和s[j]的同时加入并不能增加[i,j]区间回文子序列的长度,那么分别加入s[i]、s[j]看看哪一个可以组成最长的回文子序列。
加入s[j]的回文子序列长度为dp[i + 1][j]。
加入s[i]的回文子序列长度为dp[i][j - 1]。
- dp初始化
首先要考虑当i 和j 相同的情况,从递推公式:dp[i][j] = dp[i + 1][j - 1] + 2; 可以看出递推公式是计算不到 i 和j相同时候的情况;所以需要手动初始化一下,当i与j相同,那么dp[i][j]一定是等于1的,即:一个字符的回文子序列长度就是1;其他情况dp[i][j]初始为0就行。
- 遍历顺序
从递推公式可以看出,当前元素依赖于左侧、下方以及左下角元素,所以遍历i的时候一定要从下到上遍历,这样才能保证下一行的数据是经过计算的;j就从左往右遍历就可以了。
最后可以举例推导一下dp,输入s:“cbbd” 为例,dp数组状态如图: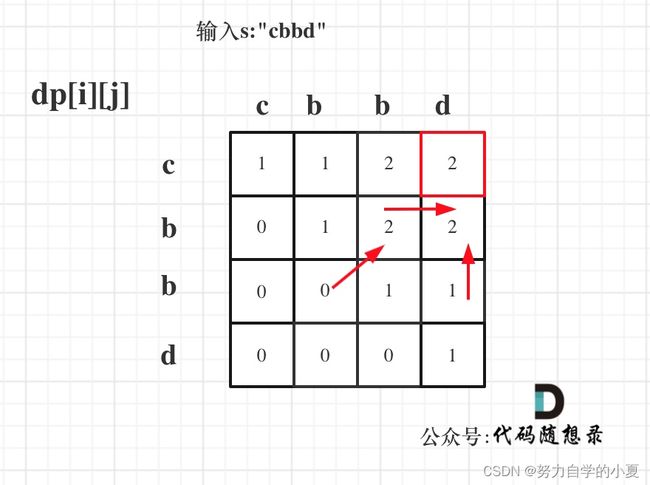
下面贴出代码:
CPP版本
class Solution {
public:
int longestPalindromeSubseq(string s) {
vector<vector<int>> dp(s.size(), vector<int>(s.size(), 0));
for (int i = 0; i < s.size(); i++) dp[i][i] = 1;
for (int i = s.size() - 1; i >= 0; i--)
{
for (int j = i + 1; j < s.size(); j++)
{
if (s[i] == s[j]) dp[i][j] = dp[i + 1][j - 1] + 2;
else dp[i][j] = max(dp[i][j - 1], dp[i + 1][j]);
}
}
return dp[0][s.size() - 1];
}
};
C版本
int longestPalindromeSubseq(char * s){
int n = strlen(s);
int** dp = (int** )malloc(sizeof(int* ) * n);
for (int i = 0; i < n; i++) {dp[i] = (int* )malloc(sizeof(int) * n);}
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++) {dp[i][j] = 0;}
}
for (int i = 0; i < n; i++) {dp[i][i] = 1;}
for (int i = n - 1; i >= 0; i--)
{
for (int j = i + 1; j < n; j++)
{
if (s[i] == s[j]) {dp[i][j] = dp[i + 1][j - 1] + 2;}
else {dp[i][j] = fmax(dp[i][j - 1], dp[i + 1][j]);}
}
}
return dp[0][n - 1];
}
总结
背包问题总结
- 递推公式
问能否能装满背包(或者最多装多少):dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);
问装满背包有几种方法:dp[j] += dp[j - nums[i]];
问背包装满最大价值:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
问装满背包所有物品的最小个数:dp[j] = min(dp[j - coins[i]] + 1, dp[j]); - 遍历顺序
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
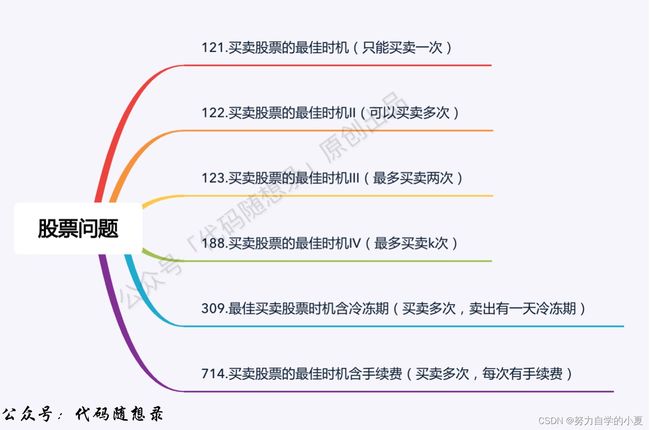
股票问题总结
具体的递推公式,可以对着笔记来进行查阅,基本都不是特别难推导,主要是dp的定义,即状态的分类要搞清楚,比如含冷冻期就要分成四种(两种不持有状态)。
下面是问题的总结,可以对应去leetcode看看原题和曾经自己刷过的解析:
打家劫舍总结
需要判断的只有前两家是否偷过,所以递推公式为: dp[i] = max(dp[i - 1], dp[i - 2] + nums[i]);
成环就去掉头算一次,去掉尾算一次;树形就后序遍历从下往上算,用两个状态记录偷和不偷的最大值。
子序列问题
该类问题代码随想录讲了已下的一些leetcode题目:
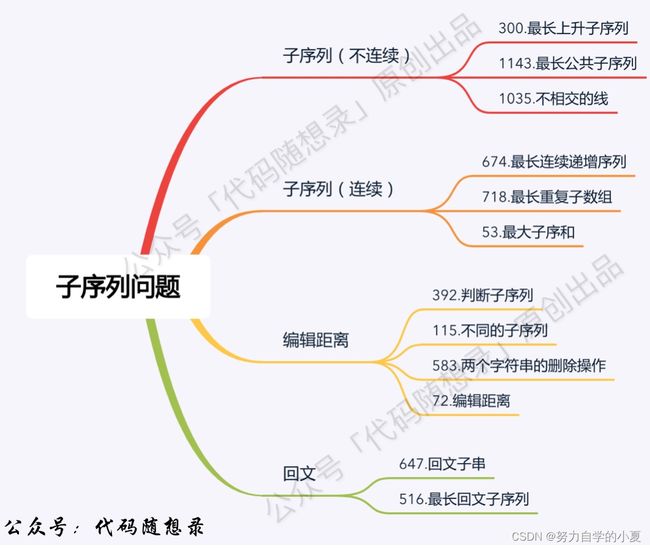
基本都会涉及i和j的元素是否相等的判断,然后有不同的推理方法;
重复子序列中dp[i][j]都是代表的i-1处和j-1处的元素,这一点要记一下;回文中是左下向右上遍历,其他问题基本都是左上往右下遍历。
动规大集合
这里贴出来代码随想录的一个总结图,好好研究一下:
二刷的时候其实动规都忘的差不多了,这几个大类要时常看一看,温故知新。
一些函数API
474题中,涉及vector的二维数组初始化定义问题,需要记住格式:
vector<vector<int>> dp(m + 1, vector<int> (n + 1, 0));
139题中,可以用unordered_set直接进行字符串匹配:
unordered_set<string> hash(wordDict.begin(), wordDict.end());
string word = s.substr(i, j - i);
if (hash.find(word) != hash.end() && dp[i]) {dp[j] = 1;}
如果是C版本的话,就是用strcmp进行比较:
bool find(char* s, char** wordDict, int wordDictSize)
{
for (int i = 0; i < wordDictSize; i++)
{
if (!strcmp(s, wordDict[i])) {return 1;}
}
return 0;
}