领域驱动设计

1. DDD概述
1.1 软件开发的困境
- “随着业务的扩展,软件开发投资越来越大” 团队的规模也开始变得越来越大,软件系统的投资和维护的成本变得越来越高。
- “业务人员不懂架构,架构师不懂代码,开发人员不懂业务模型” 当团队中的关键角色谁也不懂谁的时候,问题来了
- “重构是好的,但什么时候要重构?重构到什么样的架构就是够⽤的了?” 每个有追求的团队都在做重构,但管理者更关心,什么时间必须要重构?重构的目标在哪
1.2 DDD的来源及简介
2004年Eric Evans 发表Domain-Driven Design –Tackling Complexity in the Heart of Software (领域驱动设计),简称DDD,DDD是一套综合软件系统分析和设计的面向对象建模方法。
1.2.1 DDD设计方法
领域驱动设计分为两个阶段:
- 第一以一种领域专家、设计人员、开发人员都能理解的通用语言作为相互交流的工具,在交流的过程中发现领域概念,然后将这些概念设计成一个领域模型;
- 第二个阶段是由领域模型驱动软件设计,用代码来实现该领域模型。
1.3 DDD解决了什么问题
1.3.1 沟通问题

开发小伙伴在开需求梳理会的时候经常听到一些名词,比如某某表,某某字段等,领域专家(指精通业务的人,比如测试人员就是领域专家),听不懂也不关心这些,他们经常说领域内的名词,就是他们擅长的"行话",大家言语不统一,鸡同鸭讲,沟通成本太高,更恐怖的是有时候技术人员偏偏把某些概念理解偏了,结果九牛二虎之力码出来的代码,验收时根本不是别人想要的,有时候会出现技术人员和产品的深入交流。
所以DDD要求大家(领域专家和技术人员)都是用一套术语,不要说某某表,某某字段,也不要把定好的术语口头上改成自己理解的术语。
统一术语,要求每个人都使用这一套术语,各方面都不会理解错误,最终代码实现的时候,术语在代码中也要有体现,整个代码看起来就是用代码把术语给翻译了一遍。
1.3.2 代码质量问题
这里代码质量问题不是指代码是否规范,而是代码是否如实的实现了业务,实现的好不好,不是指代码跑的有多快,而是业务是否清晰,业务术语,业务规则,业务流程在代码中是否有清晰的对应关系,如果一个新的小伙伴加入项目组,要改一个需求,能否通过已有的代码将业务梳理清楚,到这里大家可能想,可能吗?痴人说梦
1.4 模型和建模
1.4.1 什么是模型
- 模型是对客观世界事物的一种抽象和简化。
- 它是从某个角度反映人对客观世界事物的一种认识。
- 它用于对事物的本质进行深入细致的研究。
1.5 统一语言(UBIQUITOUS LANGUAGE)
解决问题从理解问题入手,很多事情的难点不在于解决问题,而在于认知问题
关于统一语言必要性,有一个经典的通天塔故事,人类想建一座通天塔,进度很快,上帝害怕了,于是上帝让建造者说不通的语言,这样通天塔就再也没有能建起来了,统一语言是一件事情能顺利开展的基础。
由于语言上的存在鸿沟,领域专家只能模糊的描述他们想要的东西,开发人员虽然努力的去理解一个自己不熟悉的领域,但是也只能形成模糊的认识,结果是各说各话,或者一知半解,最后上线才发现漏掉了这个那个,更有甚者,上下发现需求根本不是客户所需要的。
通用语言也并不是像UML,XML Schema或Java这样的语言,它是一种自然的但经过浓缩的领域语言,它是一种开发与用户共享的语言,用来描述问题和领域模型,通用语言不是把从用户那里听到的内容翻译为开发的语言,而是为了减少误解,让用户更容易理解的草图,从而可以真正的帮助纠正错误,帮助开发获取有关的领域新知识。
1.6 什么是DDD
DDD将一个软件系统的核心业务功能集中在一个子域里面,其中包含实体,值对象,领域服务领域事件,资源库,工厂,聚合等概念,再此基础上DDD提出了一套完整的支撑这样的核心领域的基础设施,此时,DDD已经不再是“面向对象进阶”这样简单,而是一个系统性工程。
所谓领域就是业务开展的方式,业务价值便体现在其中,程序员都是喜欢技术性思维,总是从技术的角度来解决问题,但是一个软件是否真正的可用好用,是同过软件提供的业务价值来体现出来的,因此,于其每天钻在永远学不完的技术中,不如将我们的关注点向软件所提供的业务价值方向思考,这也是DDD所要解决的问题。
DDD中代码就是设计本身,你不在需要那些繁文缛节的并且永远也无法得到实时更新的设计文档,编码者和领域专家再也不需要翻译才能理解对方所表达的意思。
2. 传统开发模式
很多业务都是基于传统的MVC三层架构来实现的,更具体一点就是基于贫血模型的MVC三层架构开发模式
虽然这一种开发模式已经成为了行业标准但是他违反了面向对象的编程风格,是彻彻底底的一种面向过程的编程编程风格,因此有些人成为反模式。
特别是领域驱动设计(Domain Driven Design,简称 DDD)盛行后,这种基于贫血模型传统开发模型遭到更多人的诟病,而基于充血模型的DDD受到更多人的推荐。
2.1 基础知识回顾
2.1.1 面向对象编程
一种编程范式或编程风格,以类或对象作为组织代码的基本单元,并将封装、抽象、继承、多态四个特性,作为代码设计和实现的基石。
2.1.2 MVC架构
MVC三层架构是一种比较笼统的分层方式,落实到具体开发层面,很多项目不会100%的遵循MVC的分层方式,而是根据需要做相应的变动。
一般在前后端分离的项目中,后端负责接口的调用,这种情况下我们一般将后端项目分为Repository 层、Service 层、Controller 层。
2.1.3 贫血模型
所谓贫血模型,是指model中,只包含状态(属性),不包含行为(方法),也就是model只有数据没有业务逻辑,就成为贫血模型,实际上,目前几乎所有的业务后端系统,都是基于贫血模型的。
数据和业务逻辑被分隔到不同的类中,数据与操作分离,破坏了面向对象的封装特性,是典型的面向过程的编程风格。
2.1.3.1 开发流程
SQL驱动
我们接到一个开发需求的时候,先要去看接口所需要的数据如何对应到数据库中,需要那些表,那些字段,然后思考如何使用SQL来获取这些数据。
之后定义BO、VO、然后模板也对应相应的Repository、Service、Controller 类中添加相应的业务逻辑,业务逻辑包含在一个大SQL中,而Service做的事情很少
SQL 都是针对特定的业务功能编写的,复用性差,当我要开发另一个业务功能的时候,只能重新写个满足新需求的 SQL 语句,这就可能导致各种长得差不多、区别很小的 SQL 语句满天飞。
所以,在这个过程中,很少有人会应用领域模型、OOP 的概念,也很少有代码复用意识,对于简单业务系统来说,这种开发方式问题不大,但对于复杂业务系统的开发来说,这样的 开发方式会让代码越来越混乱,最终导致无法维护。
2.1.3.2 示例代码
//userController
@RestController("/user")
public class UserController {
//通过注解注入Service
@Autowired
private UserService userService;
/**
* 查询用户基本信息
*
* @param id
* @return
*/
@RequestMapping("/find/{id}")
public UserVO findById(@PathVariable("id") String id) {
UserBO userBO = userService.findById(id);
return ModuleUtils.toVO(userBO);
}
/**
* 修改密码
*
* @param userVO
* @return
*/
@RequestMapping("/changPhone")
public UserVO changPhone(UserVO userVO) {
UserBO bo = ModuleUtils.toBO(userVO);
UserBO userBO = userService.changPhone(bo);
return ModuleUtils.toVO(userBO);
}
}
//UserVO
public class UserVO {
//用户ID
private String id;
//用户姓名
private String name;
//用户手机号
private String telephone;
//忽略setter和getter方法
}
//UserServiceImpl
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserRepository userRepository;
@Override
public UserBO findById(String id) {
return userRepository.findById(id);
}
@Override
public UserBO changPhone(UserBO bo) {
//校验参数
checkUserBOPhone(bo);
UserBO userBO = new UserBO();
userBO.setId(bo.getId());
userBO.setTelephone(bo.getTelephone());
return userRepository.changPhone(userBO);
}
/**
* 校验参数
*
* @param bo
*/
private void checkUserBOPhone(UserBO bo) {
//参数验证
if (null == bo) {
throw new RuntimeException("BO对象不能为空");
}
//验证对象ID不为空
if (StringUtils.isEmpty(bo.getId())) {
throw new RuntimeException("用户ID不能为空");
}
//验证手机号码不能为空
if (StringUtils.isEmpty(bo.getTelephone())) {
throw new RuntimeException("手机号码不能为空");
}
if (!VerifyUtils.verifyPhone(bo.getTelephone())) {
throw new RuntimeException("手机号码格式错误");
}
}
}
//UserBO
public class UserBO {
//用户ID
private String id;
//用户姓名
private String name;
//用户手机号
private String telephone;
//忽略setter和getter方法
}
//UserRepository
public class UserRepositoryImpl implements UserRepository {
@Override
public UserBO findById(String id) {
//todo DAO具体实现
return new UserBO();
}
@Override
public UserBO changPhone(UserBO userBO) {
//todo DAO具体实现
return new UserBO();
}
}
我们平时开发代码基本上都是以上面的代码形式组织的,其中UserRepository是数据库访问层,UserService是业务操作层,UserController是控制器层。
在这里我们发现UserVO和UserBO是一个纯粹的数据结构,只包含业务不包含任意业务逻辑,业务逻辑都是在UserService中的,我们通过UserService来操作UserBO,具体一点就是我们的业务逻辑分离到了BO和Service的两个类中了,就像UserBO一样只包含数据不包含业务逻辑的类就叫做贫血模型。
这种贫血模式将数据与逻辑分离,这种分离直观上就是两个或者更多个不同的类,这个就像电车,没有电,只能看不能开一样,破坏了面向对象的封装特性,是一种面向过程或者面向数据的编程风格。
2.1.4 充血模式
数据和对应的业务逻辑被封装到同一个类(领域模型)中,满足面向对象的封装特性,是典型的面向对象编程风格,Model中既包含数据又包含行为,是最符合面向对象的设计方式
2.1.4.1 开发流程
在这种开发模式下,我们需要先梳理相应的业务,定义领域模型所包含的属性和方法,领域模型相当于可复用的业务中间层,新功能需求的开发,都基于之前定义好的这些领域模型来完成。
2.1.4.2 代码示例
比如上面的更新手机号码,我们是基于面向过程的,数据和业务分离,而改为充血模型则是将数据和业务结合在一起
//UserService
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserRepository userRepository;
@Override
public UserBO findById(String id) {
return userRepository.findById(id);
}
@Override
public UserBO changPhone(UserBO bo) {
//校验参数
UserBO userBO = new UserBO();
userBO.changePhone(bo.getId(), bo.getTelephone());
return userRepository.save(userBO);
}
}
//UserBO
public class UserBO {
//用户ID
private String id;
//用户姓名
private String name;
//用户手机号
private String telephone;
/**
* 修改手机号码
*
* @param telephone
*/
public void changePhone(String id, String telephone) {
if (StringUtils.isEmpty(id)) {
throw new RuntimeException("BO对象不能为空");
}
VerifyUtils.verifyPhone(telephone);
this.id = id;
this.telephone = telephone;
}
public String getId() {
return id;
}
public String getTelephone() {
return telephone;
}
}
3. 转账业务
在金融行业转账是一个很基本的操作,将用户A中的钱转给B用户,需要在一个事务中在A账户中扣款,并且在B账户中加款
3.1 业务流程
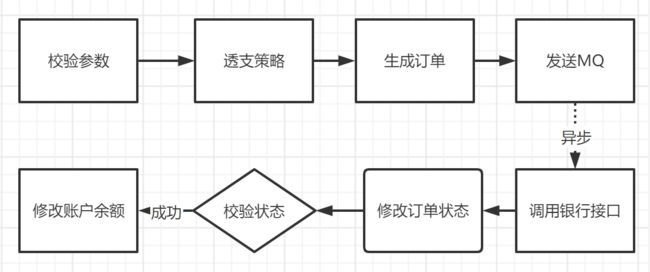
3.1.1 业务分析
转账业务相对来说还是比较简单的,我们分析发现明显是面向过程的
- 进行账户参数校验,校验参数是否合法
- 透支策略校验,有些账户是不允许透支,而有一些是可以进行透支的,并且有透支额度的
- 生成订单,并且设置订单处于处理中的中间状态
- 发送订单信息到MQ进行异步处理
- 业务服务接收到订单信息后调用银行接口
- 获取银行相应结果后修改订单状态是成功还是失败
- 根据订单状态修改相应账户余额信息
3.2 传统代码
代码位于项目中,参考代码
3.2.1 存在的问题
3.2.1.1 可维护性能差
- 数据结构的不稳定性:VO、BO、DO类是一个纯数据结构,映射了数据库中的一个表,这里的问题是数据库的表结构和设计是应用的外部依赖,长远来看都有可能会改变,比如数据库要做Sharding,或者换一个表设计,或者改变字段名。
- 第三方服务依赖的不确定性:第三方服务的变化:轻则API签名变化,重则服务不可用需要寻找其他可替代的服务,在这些情况下改造和迁移成本都是巨大的,同时,外部依赖的兜底、限流、熔断等方案都需要随之改变。
- 中间件更换:今天我们用Kafka发消息,明天如果要上阿里云用RocketMQ该怎么办?后天如果消息的序列化方式从String改为Binary该怎么办?如果需要消息分片该怎么改?
3.2.1.2 可拓展性差
可扩展性 = 做新需求或改逻辑时,需要新增/修改多少代码
- 业务逻辑无法复用:数据格式不兼容的问题会导致核心业务逻辑无法复用,每个用例都是特殊逻辑的后果是最终会造成大量的if-else语句,而这种分支多的逻辑会让分析代码非常困难,容易错过边界情况,造成bug。
- 逻辑和数据存储的相互依赖:当业务逻辑增加变得越来越复杂时,新加入的逻辑很有可能需要对数据库schema或消息格式做变更,而变更了数据格式后会导致原有的其他逻辑需要一起跟着动,在最极端的场景下,一个新功能的增加会导致所有原有功能的重构,成本巨大。
3.2.1.3 可测试性能差
可测试性 = 运行每个测试用例所花费的时间 * 每个需求所需要增加的测试用例数量
- 设施搭建困难:当代码中强依赖了数据库、第三方服务、中间件等外部依赖之后,想要完整跑通一个测试用例需要确保所有依赖都能跑起来,这个在项目早期是及其困难的,在项目后期也会由于各种系统的不稳定性而导致测试无法通过。
- 运行耗时长:大多数的外部依赖调用都是I/O密集型,如跨网络调用、磁盘调用等,而这种I/O调用在测试时需要耗时很久,另一个经常依赖的是笨重的框架如Spring,启动Spring容器通常需要很久,当一个测试用例需要花超过10秒钟才能跑通时,绝大部分开发都不会很频繁的测试。
- 耦合度高:假如一段脚本中有A、B、C三个子步骤,而每个步骤有N个可能的状态,当多个子步骤耦合度高时,为了完整覆盖所有用例,最多需要有N N N个测试用例,当耦合的子步骤越多时,需要的测试用例呈指数级增长。
3.3 领域驱动架构
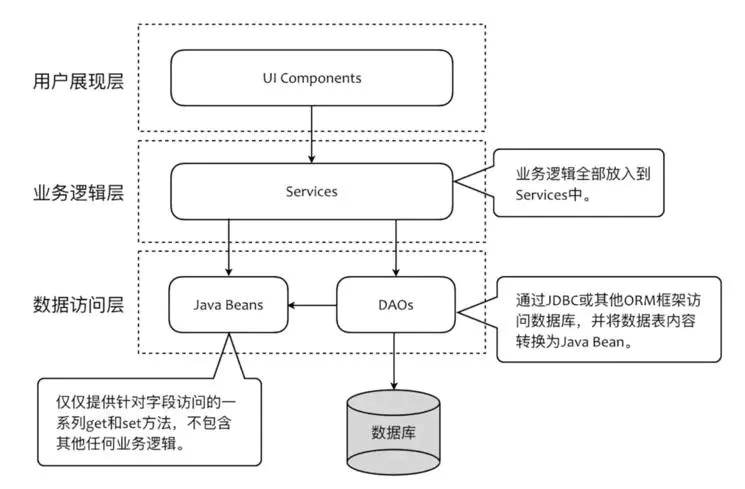
3.3.1 传统的三层架构
最经典也是最常用的就是三层架构,分别是UI层,Service层,以及DAO层,在这种架构中业务逻辑位于被定义到业务逻辑层,也就是Service层,数据模型则是被定义为了Java Bean,这些Java Bean中不包含任何业务逻辑,因此放在了DAO层
3.3.2 四层架构
领域驱动设计将软件系统分为四层:基础构架层、领域层、应用层和表现层,与上述三层相比,数据访问层已经不在了,它被移动到了基础构架层。
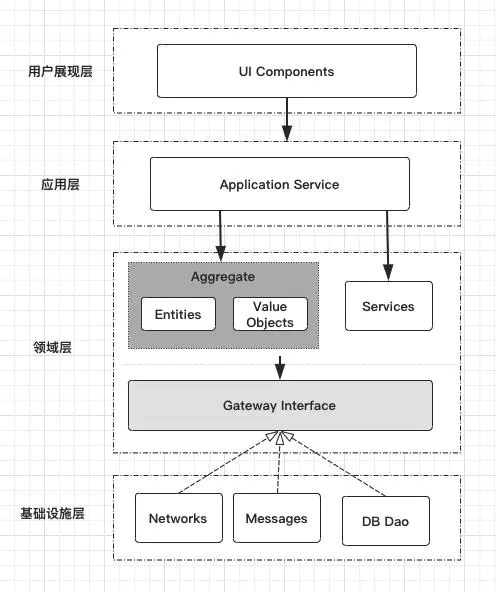
3.3.2.1 展现层
这个好理解,跟三层里的表现层意思差不多,但请注意,”web服务“虽然是服务,但它是表现层的东西
负责向用户显示和解释用户指令,完成前端界面逻辑,这里的用户可以指使用用户界面的人,也可以是另一套计算机系统
表现层于应用层之间是通过数据传输对象(DTO)进行交互的,数据传输对象是没有行为的POJO对象,他的目的只是为了对领域对象进行数据封装,实现层与层之间的数据传递,为何不能直接将领域对象用于数据传递?因为领域对象更注重领域对象,而DTO更注重数据,不仅如此,由于”富领域模型“的特点,这样做会直接将领域对象的行为暴露给表现层。
3.3.2.2 应用层
它是很薄的一层,负责展现层与领域层之间的协调,也是与其它系统应用层进行交互的必要渠道
主要负责服务的组合编排以及转发,负责业务用例的执行顺序以及业务拼装,拼装完成,拼装完成的领域服务后,以粗粒度的服务通过API网关向前台应用发布。
该层不包含任何领域逻辑,但它会对任务进行协调,并可以维护应用程序的状态,因此,它更注重流程性的东西,在某些领域驱动的实践中,也会将其称为”工作流层“,应用层是领域驱动中最争议的一个层次,也会很多对其职责感模糊不清。
通过这一种方式,屏蔽了领域层内部复杂的业务实现,应用层除了定义应用服务外,还可以进行安装认证、权限校验、持久化事务控制或向其他系统发送基于事件的消息通知。
本层代码主要通过调用领域层服务,完成服务组合和编排形成粗粒度的服务,为前台提供API 服务,本层代码可进行业务逻辑数据的校验、权限认证、服务组合和编排、分布式事务管理等工作。
3.3.2.3 领域层
领域层是业务软件的核心所在,包含了业务所涉及到的领域对象,领域服务,以及他们之间的关系,负责表达业务概念,业务状态信息以及业务规则,具体表现形式就是领域模型
领域驱动设计提倡富领域模型,尽量将业务归属于领域对象上,实在无法归属的部分则以领域服务的形式进行定义
本层代码主要实现核心的业务领域逻辑,需要做好领域代码的分层以及聚合之间代码的逻辑隔离
3.3.2.4 基础设施层
一个系统的基础不仅限于对数据库的访问,还包括访问网络、文件、消息队列或者其他的硬件设施,因此本层叫“基础设施层”很合理
该层专为其它各层提供技术框架支持,注意,这部分内容不会涉及任何业务知识,众所周知的数据访问的内容,也被放在了该层当中,应为数据的读写是业务无关的
基础设施层向其他层提供通用的技术能力,为应用层传递消息(API 网关等),为领域层提供持久化就机制(数据库资源)等
根据依赖倒置原则,封装基础资源服务,实现资源层与应用层和领域层调用的依赖反转,为应用层和领域层提供基础资源服务(数据库、缓存),实现各层的结构,降低外部资源的变化对于核心业务逻辑的影响
本层主要包含两类适配代码:主动适配和被动适配
- 主动适配代码主要面向前端应用提供 API 网关服务,进行简单的前端数据校验、协议以及格式转换适配等工作
- 被动适配主要面向后端基础资源(如数据库、缓存等),通过依赖反转为应用层和领域层提供数据持久化和数据访问支持,实现资源层的解耦。
3.3.3 六边形架构
DDD并不要求采用特定的架构风格,因为它对架构中立,你可以采用传统的三层架构,也可以采用Rest架构和事件驱动架构等,但是在《实现领域驱动设计》中,作者比较推崇事件驱动架构和六边形架构。
六边形架构又称“端口和适配器模式”,是Alistair Cockburn提出的一种具有对称性特征的架构风格,在这种架构中,系统通过适配器的方式与外部交互,将应用服务于领域服务封装在系统内部。
六边形架构将系统分为内部和外部两层六边形,内部六边形代表了应用的核心业务逻辑,外部六边形代表外部应用、驱动和基础资源等,内部通过端口和适配器与外部通信,对应用以API主动适配的方式提供服务,对资源通过依赖反转被动适配资源的形式呈现,一个端口可能对应多个外部系统,不同的外部系统使用不同的适配器,适配器负责对协议进行转换,这就使得应用程序能够以一致的方式被用户、程序、自动化测试、批处理脚本所驱动。
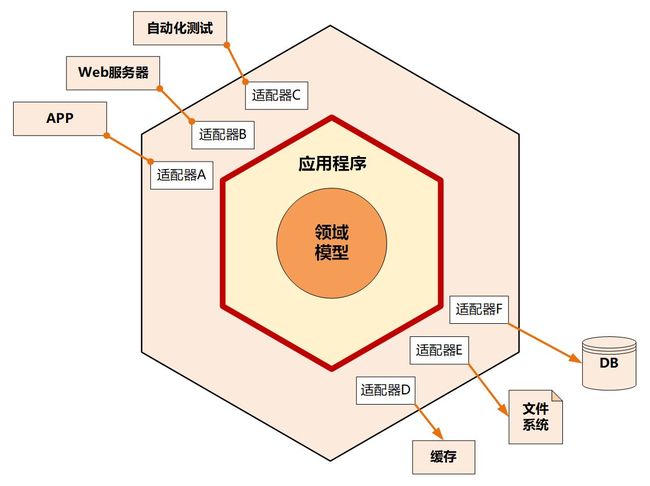
六边形架构还是一种分层架构,如上图所示,它被分为了三层:端口适配器、应用层与领域层,而端口又可以分为输入端口和输出端口。
3.3.3.1 输入端口
用于系统提供服务时暴露API接口,接受外部客户系统的输入,并客户系统的输入转化为程序内部所能理解的输入,系统作为服务提供者是对外的接入层可以看成是输入端口,比如Controller,Servlet可以作为输入端口
3.3.3.2 输出端口
为系统获取外部服务提供支持,如获取持久化状态、对结果进行持久化,或者发布领域状态的变更通知(如领域事件)系统作为服务的消费者获取服务是对外的接口(数据库、缓存、消息队列、RPC调用)等都可以看成是输出端口。
3.3.3.3 应用层
定义系统可以完成的工作,很薄的一层,它并不处理业务逻辑通过协调领域对象或领域服务完成业务逻辑,并通过输入端口输出结果,也可以在这一层进行事物管理。
3.3.3.4 领域层
负责表示业务概念、规则与状态,属于业务的核心。
应用层与领域层的不变性可以保证核心领域不受外部的干扰,而端口的可替换性可以很方便的对接不用的外部系统。
3.3.3.5 特点
六边形架构的重点体现在以下几个方面:
- 外部可替换 一个端口对应多个适配器,是对一类外部系统的归纳,它体现了对外部的抽象。应用通过端口为外界提供服务,这些端口需要被良好的设计和测试。内部不关心外部如何使用端口,从一开始就要假定外部使用者是可替换的。六边形的六并没有实质意义,只是为了留足够的空间放置端口和适配器,一般端口数不会超过4个。适配器可以分为2类,“主”、“从”适配器,也可称为“驱动者”和“被驱动者”。
- 自动测试 在六边形架构中,自动化测试和用户具有同等的地位,在实现用户界面的同时就需要考虑自动化测试。它们对应相同的端口。六边形架构不仅让自动化测试这件事情成为设计第一要素,同时自动化测试也保证应用逻辑不会泄露到用户界面,在技术上保证了层次的分界。
- 依赖倒置 六边形架构必须遵循如下规则:内部相关的代码不能泄露到外部,所谓的泄露是指不能出现内部依赖外部的情况,只能外部依赖内部,这样才能保证外部是可以替换的,对于驱动者适配器,就是外部依赖内部的。但是对于被驱动者适配器,实际是内部依赖外部,这时需要使用依赖倒置,由驱动者适配器将被驱动者适配器注入到应用内部,这时端口的定义在应用内部,但是实现是由适配器实现。
4. DDD业务分析
DDD分为战术设计和战略设计,战略设计主要从高层“俯视"我们的软件系统,帮助我们精准的划分领域以及处理各个领域之间的关系,而战术层面则是从技术实现层面教会我们如何具体的实施DDD
下面我们就分析下如何使用DDD来设计我们的转账服务
4.1 战略层面
DDD绝非一套单纯的框架或者技术工具集,但是很多程序员确实这样认为的,并且怀揣者这样的想法来使用DDD,就像使用Spring框架一样的期待,过于拘泥于技术的实现将导致DDD-Lite(关于技术实现层面,忽略了战略层面),DDD-Lite将导致劣质的领域对象,因为我们忽略了DDD所带来的好处。
DDD战略设计主要包括领域/子域、通用语言、限界上下文和架构风格等概念
4.1.1 领域(Domain)
《领域驱动设计》中领域指的是一个特定的业务范围,大家在这个业务域范围内开展工作。
领域模型是对领域内的概念类或者显示世界中对象的可视化表示,又称为概念模型,领域对象模型,分析对象模型等,关注于分析问题领域本身,发掘重要的业务领域概念,并建立起业务领域概念之间的关系
既然是领域驱动设计,那么我们主要的关注点理所当然应该放在如何设计领域模型上面,以及对领域模型的划分
在日常开发中,我们通常将一个大型软件系统拆分成若干个子系统,这种划分可能基于架构层面,也可能基于基础设施层面,但是DDD中我们针对系统的划分是基于领域的,也就是基于业务。
领域并不是一个很高深的概念,比如我们的转账系统,可以划分为帐户域、订单域、流水子域、银行域,每一个域都有相应的业务逻辑,一个系统可能有一个或者多个领域组成
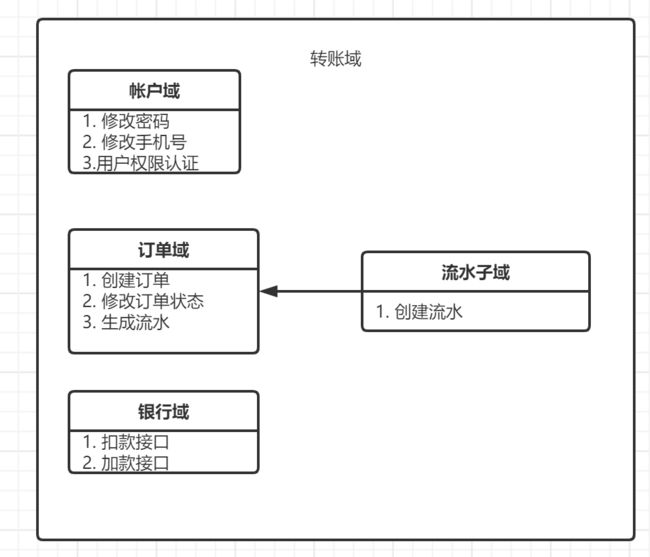
4.1.1.1 子域(Subdomain)
领域和子域是一个包含关系,一个领域中可能包含多个子域
在初识子域概念时,可能会认为子域与领域的是父子关系,其实他们并不是父子关系,而是包含关系,当多个业务域(领域)的组合形成了一个更大的业务域(领域)时,其中每一个领域(业务域)是这个更大的业务域的一部分,每一个业务域相对于这个更大地业务域称之为这个更大领域的子业务域,简称子域,组合而成的这个更大地业务域统称为领域。
子域并不是一定要做得很大,并且包含很多功能,有时子域可以简单到只包含一套算法,但并不包含在核心域之中,简单的子域可以以模块的形式从核心域中分离出来,而不需要包含在笨重的子系统组件中。
比如相对于转账域来说、账户域、订单域、银行域都属于子域,而相对于订单域,流水域则是订单域的子域,领域和子域是一个相对的关系
4.1.1.2 核心域
核心域是整个业务系统的核心,在一个领域中只能由一个核心域,其他的子域都是围绕着这个核心域而展开的
因为作为一个业务的核心存在,它最能体现系统的核心价值,也是核心竞争力,如果要最大化系统的价值,我们必然要在核心域的设计上更胜一筹。
确定核心域后,我们在进行开发设计的时候就有了主次之分。
订单系统是转账系统的核心,所以转账域中的核心域就是订单域,其他的领域都是服务于核心域的。
4.1.1.3 支撑域
支撑子域的作用于业务系统的某些重要业务而非核心业务,它关注于业务的某一方面,来支撑完善业务系统。
我们的流水子域,帐户子域就是为了支撑我们转账服务的,以及银行域。
4.1.1.4 通用域
通用域就是服务于整个业务系统的领域
比如我们的日志子域就是一个通用域,不仅仅只能记录转账的业务,还能帮助其他领域来记录日志
4.1.1.5 小结
本小节简要梳理了DDD中领域、核心域、通用子域、支撑子域的定义
- 领域是有范围界限的,也可以说是有边界的。
- 核心域是业务系统的核心价值所在,承载着一个系统的重中之重。
- 通用子域可以理解为业务系统所有子域的消费者,提供着通用服务。
- 支撑子域专注于业务系统的某一重要的业务,来支撑和完善业务系统
4.1.2 限界上下文(Bounded Context)
在一个领域子域中,我们会创建一个概念上的领域边界,在这个边界上,任何一个领域对象都只表示特定于该领域边界内部的确切含义,这样的边界就称为限界上下文,限界上下文和领域是一对一的关系。
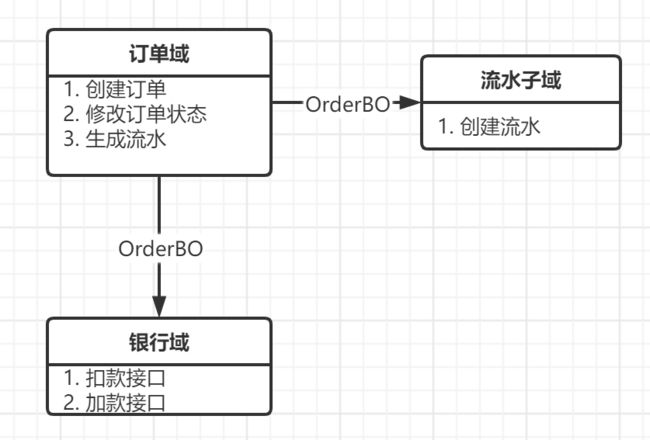
在上面转账分析中,涉及到帐户域、订单域、银行域等,因为各个域是需要打交道的,一般开发的思路是共享一个上下文对象,比如Order对象,不管是订单域还是转账域以及流水子域共享一个Order对象,这样可能会造成一旦Order对象进行变更需要对银行以及流水域的业务做变更,并且都共享同一个对象会造成Order对象内部出现很多其他领域用不到但是不得不存在的属性,造成代码冗余
在DDD的思想下,当划分了上下文后,每一个子域都有相应的界限以及上下文,订单就是订单,流水就是流水,没有二义性,在订单中就是订单对象,而到了流水子域中就转换成了对应的订单流水对象
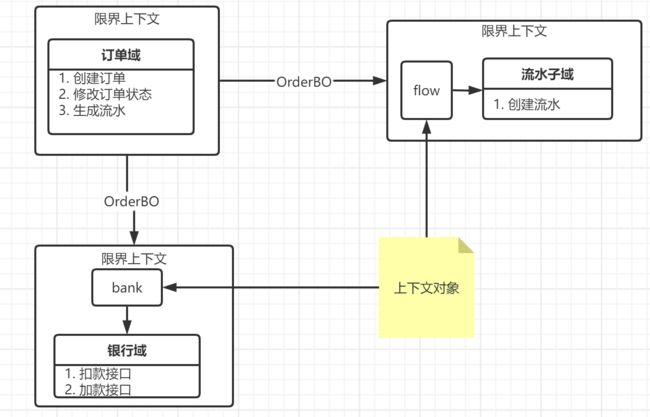
从物理上来说,一个上下文最终是一个java文件,甚至可以是一个包中的所有对象,但是技术本身不应该用来区分限界上下文。
将一个限界上下文中所有的概念,包括名词、形容歌、动词全部集中在一起,我们便为现接上下文创建了一套通用语言,通用语言是团队交流所使用的语言,业务人员,编码人员,测试人员都可以通过一套通用语言进行交流。
一般微服务也是按照限界上下文来进行拆分的,多个限界上下文之间通讯可以使用防腐层来实现。
4.2 战术层面
战略设计提供了一种高层视野来审视我们的软件系统,从上层来分析以及规划我们的业务,划分领域,以及上下文边界,这些都是逻辑层面的,具体到代码层面,如果将逻辑转换为代码呢?
战术设计是一组在实施中使用的技术资源域模型,这些资源必须应用在一个单一的有界上下文中,如果正确使用战术设计标准,您实际上可以丰富您的领域模型,从而清晰地反映您的业务。
4.2.1 实体
在DDD的领域模型中,实体应该是富有业务行为且具有唯一标识符的对象,在不同的设计阶段实体是可以改变的,但是根据唯一标识符始终能定位到这个唯一对象。
一个实体是一个潜在的可变对象,它具有一个唯一的标识符,实体在其域模型中具有自己的生命周期,这使您可以获取此实体的整个变化的历史记录。
唯一标识符可以是用户指定的,也可以是通过应用程序生成的UUID或者通过持久化机制生成的序列值(Sequence),当然也可以是限界上下文中传递的过来的,但无论是哪一种生产方式都要具备全局唯一性(比如订单的流水号,一些电商场景订单的流水号是通过专门的工具生产全局唯一的)。
4.2.1.1 特点
- 有 ID 标识,聚合内唯一
- 这些实体类通常采用充血模型
- 依附于聚合根,其生命周期由聚合根管理
- 与数据库持久化对象不一定是 一对一的关系
- 可以引用聚合内的聚合根、实体和值对象
4.2.1.2 代码案例
这里就拿我们的核心域OrderBO对象,来说明我们的实体
/**
* 订单实体
*/
public class OrderBO {
//订单ID
private String id;
//转储账户
private String fromAccountId;
//来源银行
private Bank fromBank;
//转入账户
private String toAccountId;
//转账银行
private Bank toBank;
//金额
private long amount;
//转账时间
private Date transferDate;
//订单状态
private TransferState transferState;
//响应结果业务
public void response(boolean flag) {
if (flag) {
this.transferState = TransferState.SUCCESS;
} else {
this.transferState = TransferState.FAIL;
}
}
//省略setget方法
}
该实体中有一个对于订单转账结果的响应,用来区分是否是同一个订单只能通过订单ID来进行区分,而不能根据订单的属性来进行区分
4.2.2 值对象
值对象的唯一性是通过属性值去判断的,在建模时我们应该尽可能的将模型建为值对象,使我们更少的进行职责。
区分值对象与实体的区别在于,值对象是不可变的,并且没有唯一标识,仅由其属性的值定义,这种不变性的结果是,为了更新值对象,您必须创建一个新实例来替换旧实例。
我们发现多数领域对象都可以建模成值对象,而非实体,值对象就像软件系统中的过客一样,据有”创建而不管“的特性,因此我们不需要像关心实体一样关心值对象的生命周期以及持久化
4.2.2.1特性
- 不可变,无生命周期,用完即弃
- 通过对象属性值来识别的对象,它将多个相关属性组合为一个概念整体
- 简单来说,值对象本质上就是一个集合,由若干个用于描述目的、具有整体概念和不可修改的属性组成
- 值对象尽量只引用值对象
4.2.2.2 代码案例
在转账订单中有银行的概念,而在订单中我们只关注于银行的编码,以及银行的名词,其他的不需要过多关注,我们可以将有银行在这里进行抽象,用一个值对象进行表示。
public class Bank {
public Bank(String code, String name) {
this.code = code;
this.name = name;
}
/**
* 银行编码
*/
private String code;
/**
* 银行名词
*/
private String name;
public String getCode() {
return code;
}
public String getName() {
return name;
}
}
4.2.3 聚合(Aggregate)
聚合可能是DDD中最难理解的概念,之所以成为聚合是因为聚合之中包含的对象是密不可分的联系,他们内聚在一起,聚合在领域模型里是个业务边界。
它是战术设计中最重要和最复杂的模式之一,聚合基于另外两个战术标准,即实体和值对象,聚合是一种或多种的群集实体,并且还可以包含值对象,此群集的父实体接收聚合根的名称
它通过定义对象间清晰的所属关系和边界来实现领域模型的高内聚,避免了错综复杂难以维护的关系网形成,聚合定义了一组具有内聚关系的相关对象的集合,我们把聚合看作一个修改数据的单元
多个聚合在同一个限界上下文和微服务内,在聚合中有个聚合根和上下文边界,这个边界比限界上下文要小,主要是根据业务的单一职责和高内聚设计原则,把涉及到这部分单一职责的实体和值对象聚合到一起,完成业务逻辑。
4.2.3.1 聚合的特性
- 每一个聚合都有一个根和边界,边界定义了聚合内部有哪些实体和值对象,跟是聚合内的某个实体
- 聚合内部的对象之间可以互相引用,但是聚合外部的对象访问聚合内部的对象时,必须通过聚合跟开始导航,绝不可以绕过聚合根直接访问聚合内部的对象,也就是说聚合根是外部可以访问以及引用的唯一元素
- 聚合内除根以外的其他实体的唯一标识都是本地标识,也就是只要在聚合内保持唯一即可,因为他们都是从属于这个集合
- 聚合根负责与外部的对象打交道,并维护自己内部的业务规则
- 基于聚合的以上概念,我们可以推论出从数据库中查询出的单元也是以聚合为一个单元,也就是说我们不能直接查询聚合内部某个非根的对象。
- 聚合内部的对象可以保持对其他聚合根的引用
4.2.3.2 代码举例
比如我们订单域就可以设计成一个聚合,它包含了订单(Order)实体,流水(Flow)实体,以及银行(Bank)值对象,他们共同组成了订单域,我们就可以将这些对象组合成一个聚合
/**
* 订单实体(聚合)
*/
public class OrderBO {
//订单ID
private String id;
//转储账户
private String fromAccountId;
//来源银行 值对象
private Bank fromBank;
//转入账户
private String toAccountId;
//转账银行 值对象
private Bank toBank;
//金额
private long amount;
//转账时间
private Date transferDate;
//订单状态
private TransferState transferState;
//流水实体
private List flowList;
//省略setget方法
}
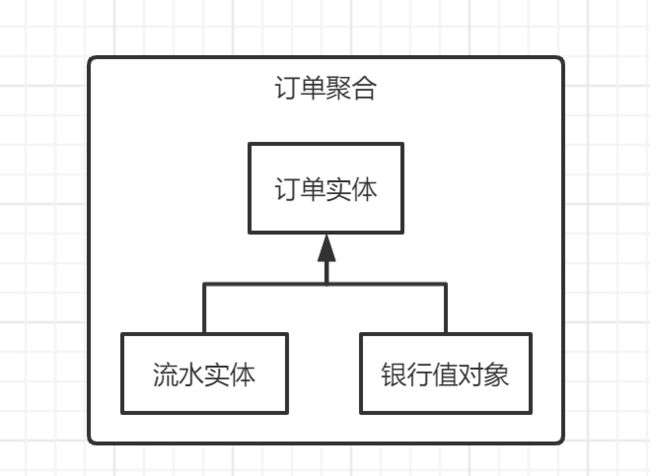
4.2.4 聚合根
如果聚合只有一个实体,那么这个聚合就是聚合根;如果是多个实体,我们可以思考聚合内的那个对象有独立存在的意义并且可以和外界直接进行交互
聚合根和领域里的各种对象都是有各自独立属性的,比如男人的属性(养家,买车,买房),女人(教育,生小孩,持家)同时他们是相互依赖,不可分离的,聚合根不能离开他的子对象,而领域里的子对象也不能离开他的聚合根,否则就玩不下去了
在我们订单系统中,订单实体就是我们的聚合根,根据订单实体我们可以导航得到银行值对象以及流水实体,他们属于一个业务模型
4.2.4.1 聚合的特性
- 聚合根是实体,拥有实体的业务属性和行为,同时也是聚合的管理者,负责协调聚合内的实体和值对象,按照固定的业务规则,完成业务逻辑。
- 聚合根是聚合对外唯一的接口人,聚合之间以聚合根ID关联的方式接受聚合的外部任务和请求,聚合外不能通过对象引用的方式访问聚合内的对象,需要将关联的聚合根ID作为入参,先访问聚合根,再通过聚合根导航到聚合内部实体。
- 如果聚合根被删除了,他引用的实体和值对象就不会存在了
- 聚合根和聚合根所在层的领域服务都可以组合多个实体完成领域逻辑,但为了DDD分层架构的职责单一,聚合根最好只承担聚合管理职能,只实现聚合内实体和聚合根本身相关的业务逻辑,而跨多个实体的复杂领域逻辑统一放到领域服务中实现。
4.2.5 领域服务(Domain Service)
在建立模型的时候,有时候将他放在实体或者值对象中都不太合适的时候,我们可以使用领域服务(Domain Service)
比如银行转账,从Account-A账户转账到Account-B账户,这个操作涉及到两个不同的Account实体,将转账放在Account领域中是不合适的,因为这样会造成在一个领域引用另一个领域,所有将操作转账操作放到领域服务是比较合适的。
领域中一些概念不太适合建模为对象,即归类于实体或者值对象,因为他们本质就是一些操作,一些动作而不是事物,比如创建订单,他就是一个动作,而放在订单实体中是不合适的,而创建订单又属于订单域中的基本操作,是可以放在订单领域中的
这些操作往往涉及到多个领域对象,并且协调这些领域对象共同完成这些操作或者动作,如果强行将这些操作职责分配给任何一个对象,则被分配的对象将会承担一些不该承担的职责,从而导致对象的职责不明确很混乱。
但是基于类的面向对象语言规定任何属性或行为必须放在对象里面,所以我们需要寻找一种新的模式来表示这种跨越多个对象的操作,DDD任务服务是一种很自然的范式,用来对于这种跨越多个对象的操作,所以就有了领域服务这个模式。
4.2.5.1 领域和对象的区别
领域服务一般以动词开头来命名的,比如资金转帐服务可以命名为MoneyTransferService,也可以将理解为一个对象,但是和一般意义上的对象是有区别的,因为一般领域对象都是由状态和行为的,而领域服务没有状态只有行为,需要强调的是领域服务是无状态的,它存在的意义就是协调领域对象共同完成某个操作,所有的状态还都保存在相应的领域对象中。
模型和服务是对领域的一种划分,模型关注的是个体行为,服务关注的是领域的群体行为,模型关注的是领域的静态结构,服务关注的是领域的动态功能,这也符合现实中的各种现象,有动有静,有独立有协作。
领域服务还有一个很重要的功能就是可以避免领域逻辑泄漏到应用层,如果没有领域服务,那么应用层会直接调用领域对象完成本属于领域服务该有的操作,这样一来,领域层可能会把一些领域知识泄漏到应用层,因为应用层需要了解每个领域对象的业务功能,具体哪些信息,以及它可能与其他那些领域对象交互,怎么交互等一系列领域知识。
因此引入领域服务可以有效防止领域层的逻辑泄漏到应用层,对于应用层来说,从可理解的角度来说,通过调用领域服务简单易懂却意义明确接口肯定也比直接操作领域对象简单的多,从这里也可以看到领域服务具有Façade的功能
注意的是领域服务和应用服务是不同的,领域服务是领域的一部分,而应用服务不是,应用服务是领域服务的客户,应用服务是将领域模型编程外部可以访问的软件系统。
领域服务不可用滥用,因为太多的业务放在领域服务上,实体和值对象就变成了贫血对象了。
4.2.5.2 代码案例
领域服务还属于领域内,负责一些业务范围内的一些操作,无法放在实体中的一些操作交由领域服务来完成,比如我们案例中,创建订单处理转账结果就放在领域服务中就比较合适
/**
* 订单领域服务
*/
public class OrderDomainService {
@Autowired
private OrderRepository orderRepository;
/**
* 创建订单业务
*
* @param amount
*/
public OrderBO generate(String formAccountId, String toAccountId, long amount) {
OrderBO orderBO = OrderFactory.createOrder(formAccountId, toAccountId, amount);
orderRepository.save(orderBO);
return orderBO;
}
/**
* 处理转账结果
*
* @param flag
*/
public void handlerResult(String orderId, boolean flag) {
OrderBO orderBO = orderRepository.get(orderId);
orderBO.response(flag);
orderRepository.save(orderBO);
}
}
4.2.6 工厂(Factory)
领域驱动设计中工厂是一种体现封装思想的模式
创建领域对象是一件比较复杂的事情,不仅仅是简单的new对象,和对象封装一样,我们无需知道对象内部的实现细节,只需要调用的方法即可,同样工厂是用来封装创建一个复杂的对象尤其是聚合的时候所需要的知识,工厂的作用是将创建领域的或者聚合的细节隐藏起来。
客户端只需要传递一些简单的参数,复杂的创建过程交给工厂来完成,并将创建好的对象返回给客户端,领域模型中的其他元素都适合做这件事情,所以需要引入工厂模式。
工厂是对领域知识的封装,不让领域知识泄漏到外部客户端,创建一个复杂的对象时,应该满足相关的业务规则,如果传递的参数不满足业务规则,应该抛出异常,不应该创建一个错误的领域。
大部分的场景我们不需要创建复杂的领域对象,简单的new一般就可以满足了,这种情况下我们可以使用简单的new来创建对象,但是隐藏创建对象的好处显而易见的,不会让领域中的逻辑泄漏到应用层中,同时减轻了应用层的负担,只需要调用工厂创建出来期望的对象即可,如果后需要修改业务规则,只需要在工厂中进行修改即可,整体的流程逻辑不需要变更,符合开闭原则。
4.2.6.1 代码案例
这里我们就是使用订单工程来看下,代码相对简单,封装了详细的创建过程
/**
* 订单工厂
*/
public class OrderFactory {
//创建订单聚合,封装创建细节
public static OrderBO createOrder(String formAccountId, String toAccountId, long amount) {
OrderBO orderBO = new OrderBO();
orderBO.setId("xxx");
orderBO.setFromAccountId(formAccountId);
orderBO.setToAccountId(toAccountId);
orderBO.setAmount(amount);
orderBO.setFromBank(new Bank("ICBC", "这个工商银行"));
orderBO.setToBank(new Bank("ICBC", "这个工商银行"));
orderBO.setTransferDate(new Date());
orderBO.setTransferState(TransferState.PROGRESS);
return orderBO;
}
}
4.2.7 资源库(Repository)
领域对象创建出来后就是有状态的,如果临时不使用,为节省内存资源需要持久化到硬盘中,如果后期用到了再从磁盘中查询出来
资源仓储封装了基础设施来提供查询和持久化聚合操作,这样让我们只需要关注模型层面把对象存储和访问都委托给资源库来实现,他不是数据库的封装,而是领域层和基础层的桥梁,DDD关注的时领域内的模型,而不是数据库操作。
领域中的对象创建出来后就不会一直留在内存中,当领域对象不活动时会被持久化到数据库中,然后当需要的时候我们就要重建该领域对象,重建对象就是根据数据库中已存储的对象的状态重新创建对象的过程。
仓储存放的对象一定是聚合,原因是之前提到的领域模型是以聚合的概念来划分边界的,聚合是我们更新对象的一个边界,事实上,我们把聚合看成一个整体的概念,要莫一起创建或者重建出来,要莫一起被删除,我们永远不会单独对某个聚合子对象进行单独的查询或者更新操作。
仓库还有一个重要的特征是面向接口编程,定义仓储接口以及定义是实现类,在领域模型中定义仓储接口,而在基础设施层实现具体仓储操作。
因为仓储背后实现的都是和数据库打交道,我们又不希望应用层把放在如何从数据库获取数据的问题上,因为这样做会导致应用层代码混乱,和可能忽略了领域模型的存在
4.2.7.1 DAO和资源库的区别
DAO主要是从数据库表的角度来看待问题的,操作的对象是DO类,并且提供CRUD操作,是一种面向数据处理的风格(事务脚本);
Repository对应的是Entity对象读取储存的抽象,在接口层面做统一,不关注底层实现。比如,通过 save 保存一个Entity对象,但至于具体是 insert 还是 update 并不关心。Repository的具体实现类通过调用DAO来实现各种操作,通过Builder/Factory对象实现AccountDO 到 Account之间的转化。
4.2.7.2 代码案例
基于六边形架构,依赖倒置原则,上层是不需要知道下层具体实现细节,也就是我们的领域层使用资源库进行保存或者获取对象的时候是不需要知道具体底层是什么数据库,我们可以使用适配器模式来实现
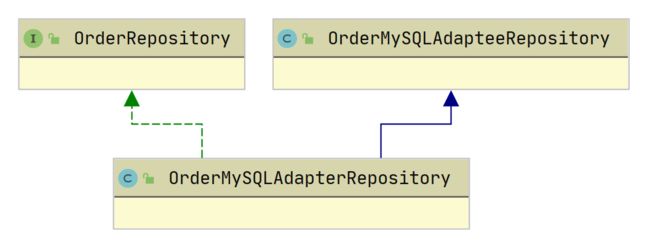
创建资源库接口
/**
* 创建资源库接口,抽象资源库
*/
public interface OrderRepository {
OrderBO get(String id);
void save(OrderBO bo);
}
MySQL具体存储实现类
/**
* Mysql具体实现类
*/
public class OrderMySQLAdapteeRepository {
public static final Map accountMap = new ConcurrentHashMap<>();
public OrderBO findById(String id) {
return accountMap.get(id);
}
public OrderBO insert(OrderBO orderBO) {
return accountMap.put(orderBO.getId(), orderBO);
}
public OrderBO update(OrderBO orderBO) {
return accountMap.put(orderBO.getId(), orderBO);
}
}
适配器类,负责对具体实现类的转换调用
/**
* Mysql 适配器模式,对具体实现的调用
*/
@Repository
public class OrderMySQLAdapterRepository extends OrderMySQLAdapteeRepository implements OrderRepository {
@Override
public OrderBO get(String id) {
return findById(id);
}
@Override
public void save(OrderBO orderBO) {
if (null == orderBO) {
return;
}
if (StringUtils.isEmpty(orderBO.getId())) {
insert(orderBO);
} else {
update(orderBO);
}
}
}
4.2.8 防腐层
很多时候我们的系统会去依赖其他的系统,而被依赖的系统可能包含不合理的数据结构、API、协议或技术实现,如果对外部系统强依赖,会导致我们的系统被”腐蚀“。
这个时候,通过在系统间加入一个防腐层,能够有效的隔离外部依赖和内部逻辑,无论外部如何变更,内部代码可以尽可能的保持不变。
如果没有使用防腐层,我们上面的数据仓库的保存中,如果没有防腐层,则是我们的领域模型直接调用MySql存储服务

这样一旦我们更换数据库,或者加入一些非业务领域的功能,比如缓存,我们可能需要直接更改领域层的代码,而引入防腐层可以避免这些问题产生,保持业务领域的干净。
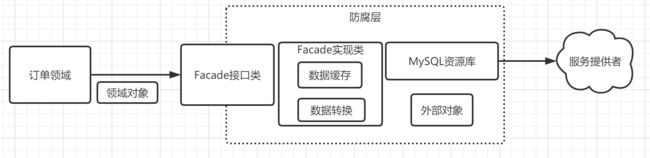
4.2.8.1 防腐层作用
ACL不仅仅只是多了一层调用,在实际开发中ACL能够提供更多强大的功能:
- 适配器:很多时候外部依赖的数据、接口和协议并不符合内部规范,通过适配器模式,可以将数据转化逻辑封装到ACL内部,降低对业务代码的侵入。在这个案例里,我们通过封装了ExchangeRate和Currency对象,转化了对方的入参和出参,让入参出参更符合我们的标准。
- 缓存:对于频繁调用且数据变更不频繁的外部依赖,通过在ACL里嵌入缓存逻辑,能够有效的降低对于外部依赖的请求压力。同时,很多时候缓存逻辑是写在业务代码里的,通过将缓存逻辑嵌入ACL,能够降低业务代码的复杂度。
- 兜底:如果外部依赖的稳定性较差,一个能够有效提升我们系统稳定性的策略是通过ACL起到兜底的作用,比如当外部依赖出问题后,返回最近一次成功的缓存或业务兜底数据。这种兜底逻辑一般都比较复杂,如果散落在核心业务代码中会很难维护,通过集中在ACL中,更加容易被测试和修改。
- 易于测试:类似于之前的Repository,ACL的接口类能够很容易的实现Mock或Stub,以便于单元测试。
- 功能开关:有些时候我们希望能在某些场景下开放或关闭某个接口的功能,或者让某个接口返回一个特定的值,我们可以在ACL配置功能开关来实现,而不会对真实业务代码造成影响。同时,使用功能开关也能让我们容易的实现Monkey测试,而不需要真正物理性的关闭外部依赖。
4.2.9 领域事件
4.2.9.1 什么是领域事件
一个领域事件可以理解为是发生在一个特定领域中的事件,是你希望在同一个领域中其他部分知道并产生后续动作的事件
在我们的领域活动(实体、Manager 等操作)中会出现一系列的重要的事件,而这些事件的订阅者,往往需要对这些事件作出响应(例如,新增用户后,可能会触发一系列动作:发送欢迎信息、发放优惠券等等),领域事件可以简单地理解为是发布订阅模式在 DDD 中的一种运用。
领域事件可以是业务流程中的一个步骤,比如转账,下单成功后需要后需要的银行端调用处理以及对银行调用结果回写到订单中,这里调用银行端就可以使用领域事件来实现。
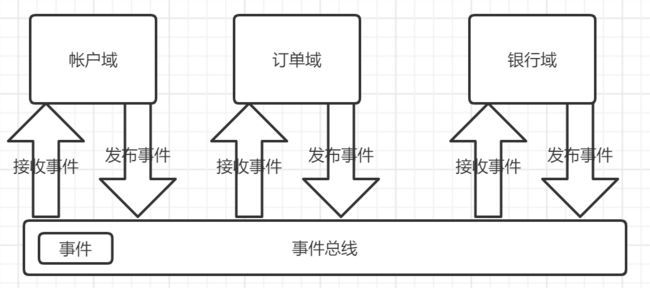
4.2.9.2 代码实现
为了防止事件总线的具体实现方式和业务解耦,这里还需要引入防腐层解耦具体的技术底层
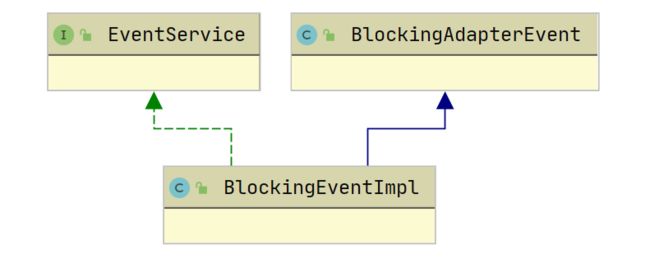
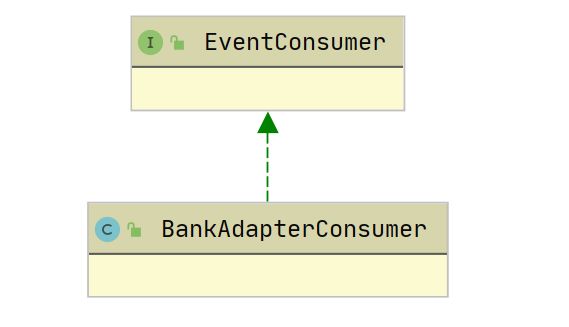
消息接收方也需要使用防腐层,防止消息领域模型被污染
5. DDD的常见问题
5.1 DDD的困境
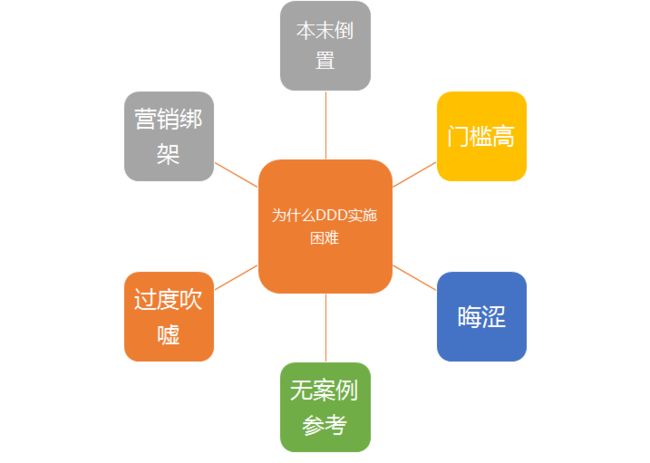
DDD 真正的困境是在技术之外的
5.1.1 本末倒置
技术人员喜欢将精力放在战术而忽略了战略,喜欢讨论各类设计模式、框架,部分个体系统设计的相当不错,整个系统确是千疮百孔,而DDD更关键的是在于战略层面,而非战术层面,如果战略规划乱七八糟,纵然使用DDD也很难收到成效。
过度关注技术使得系统的好坏完全依赖程序员的个人素质,而战略好的程序员都去搞管理了,没有时间和精力把控整个项目的细节,DDD难以落地的真正原因实在技术之外的
5.1.2 门槛高
即便DDD的战术部分对于开发人员的要求也很高,数据库设计,代码规范,设计模式,全局业务的理解,系统优化策略等都是需要掌握的。
过去面向过程编程,只需要考虑数据库优化,SQL优化等,现在转向DDD需要考虑模型设计,以及模型间的关系,如果优雅实现等,增加了很大的难度并且对于程序员的要求提高了很多
并且DDD需要统一语言,一般需要头脑风暴(开会讨论),而实际国内程序员内卷这么严重,每天一堆程序员开会讨论,基本上就被上层pass了
5.1.3 晦涩
DDD的一些概念比较晦涩难懂,比如限界上下文,领域等,这些都是对业务抽象在抽象得到的,很难理解,并且从代码上很难来体现,因为这些战略概念他是一种指导思想,具体到了实施层面,可能有各种不同的实现方案,所以如果不理解这些概念,从代码层面反推这些概念很容易被各家之言弄得头昏脑胀
5.1.4 无案例参考
比如微服务,你可以找到大量的落地方案,对于DDD有价值的参考非常少,大部分的案例都脱离了实际的业务,离开领域谈设计也不能说没意义,现实中计划使用DDD的业务场景可能非常复杂,一个小细节都可能阻碍工作的进展。
5.1.5 过度吹嘘
分文章和书籍过分的夸大某些战术架构的优势而忽略了其缺点,甚至对于DDD本身也做了夸大,造成开发与运维成本的成倍增长及至于系统无法快速扩容甚于不得不重写。
5.1.6 营销绑架
互联网行业喜欢制造概念,把简单的东西搞得很复杂,让认听上去很高大上,比如中台、低代码、DDD,这样的系统据有很高的营销价值,但是落地非常困难,尤其是在资源方面无法与理论对齐的时候,销售拉项目时通常会竖立各种Flag,可只要项目一到手就由不得客户了。