阿里系常用代码规范及工具

1. 前言
1.1 为什么需要代码规范
可能有同学觉得代码需要突出个人的特点,需要特异化,但是这样就会造成别人阅读起来很困难
代码不仅仅是交给机器来执行的,同时代码也是让其他同事来阅读的,如果代码不规范就会出现各种各样的问题,写多了代码只是觉得代码规范化是一件很自然的事,代码写多了,自然代码规范化咯,地球人都会。
其实不然,我们是不是缺少了小时候,十万个为什么的那种精神,为什么要这样做?为什么要那样做?那么我们为什么要做代码规范化?
1.1.1 不规范的案例
下面程序员在修复 bug 时可能会说的一些话或者想法 ,你占了几条?赶紧一起来看看。

1.1.1.1 就因为忘记加个分号,整个程序都崩溃了
如果你忘记添加结束分号,只是一个无心的错误,但解析器不理解这一点,它会无情地抛出一个致命错误。然后,你必须再花 20 分钟来查看代码,最后你发现缺少了一个分号,也许这就是调试的“乐趣”。
1.1.1.2 我为什么没写注释?
但对于复杂一些的脚本和程序,就需要某种类型的注释,以便你在几个月后甚至几年后回过头来查看。
有时候你会忘记给函数及其参数、输出格式和其他基本数据添加注释,当出现错误时,你需要调试整个脚本才能找到解决方案时,这无疑会给你添乱,这个时候你就会想,如果当初加一些有用的注释就好了
1.1.1.3 谁动了我的代码?
听起来就像是一种妄想症,但有时你不得不怀疑,正当你忙着补觉时,是谁在写了这些代码
过去几周或几个月忙的项目让你感到沮丧,有时候你会不记得自己往代码库里添加过东西——甚至是上周刚刚查看过的项目!
1.1.1.4 半小时写的代码,花两个小时调试
你一股脑儿写了一个函数,然后函数输出了一个致命的错误
为了找到问题所在,你不得不把其他代码删掉,只留下出问题的那几行代码,当你最终找到问题并把它修复,你会感到筋疲力尽,但同时也松了一口气。
1.1.2 代码编写
美观,排着整整齐齐的一行一行,看着就舒服;
要是不使用代码编写规范,每个方法的实现写一遍,相同的函数也不合并,在做重复的事情就是浪费时间的一件事情,而且在修改上也照成一定的困难,所以对于变量、类、接口、事件等都要有一定的规范;
如果是团队开发的话,没有规范更为混乱,要不就你有你的方法,我有我的接口,一个人来一套,那就真的乱套了,写有好味道的代码,我相信是每一个程序员的乐趣。
1.1.3 在项目架构
条理清晰,对于整个的项目,我们也需要一定的规范,项目多了,是采用三层、四层还是n层架构,对于开发的分工、项目的扩展性有很大的帮助,并且使用各种的设计模式,使得代码设计更加合理。
1.1.4 数据库设计
表以及视图的命名需要规范,不要将业务写进存储过程或者函数里面,我们应该都遇到过,一个SQL几千行的代码,修改阅读起来非常的痛苦。
1.1.5 编写文档
编写文档,比较相当枯燥一点,但是对于整个开发的指引也相对重要,要整个团队都要看明白你写的东西,当然也是需要规范化的,如果文档编写的符合规范并且清晰明了,对于后面交接或者问题问题排查都是大有好处的。
1.2 需要代码规范的原因
编码规范对程序员非常重要的若干原因
- 软件的80%时间都是处于维护
- 几乎没有那个软件的维护是由原编写者进行的
- 编码规范可以改善软件的可读性,使工程师理解新的代码更快速,更彻底。
- 源代码开源出来后不至于像垃圾一样被人嫌弃
1.3 代码规范的重要性
几乎每个项目,每家公司都会定义自己的编码规范,但在真正实施时,却在有意或无意地违背编码规范
程序员不喜欢改变自己的编程习惯,加之,管理者对质量控制不足,导致编码规范往往形同虚设。
有些人会认为:遵守编码规范不能给项目带来利益,也不能让客户看到我们为此付出的努力,其完全是团队自发的行为,没有必要做硬性的要求。
还有些人有更好的理由:编码规范会破坏创造性和程序质量
1.3.1 代码规范的好处
编码规范,在软件构件以及项目管理中,甚至是个人成长方面,都发挥着重要的作用,好的编码规范是提高我们代码质量的最有效的工具之一
1.3.1.1 规范的代码可以促进团队合作
一个项目大多都是由一个团队来完成,如果没有统一的代码规范,那么每个人的代码必定会风格迥异。
且不说会存在多个人同时开发同一模块的情况,即使是分工十分明晰的,等到要整合代码的时候也有够头疼的了。
大多数情况下,并非程序中有复杂的算法或是复杂的逻辑,而是去读别人的代码实在是一件痛苦的事情,统一的风格使得代码可读性大大提高了,人们看到任何一段代码都会觉得异常熟悉,显然的,规范的代码在团队的合作开发中是非常有益而且必要的。
1.3.1.2 规范的代码可以减少bug处理
很多IT人士将程序员比做民工,这也的确非常的形象,就像刚才提到的,复杂的算法或逻辑只占项目中很小的比例,大多仅仅是垒代码的工作。
可是越是简单,测试的bug反而是越多,而且是无穷无尽的bug,这里很大的程度上是由于代码不规范所致。 没有规范的对输入输出参数的规范,没有规范的异常处理,没有规范的日志处理等等,不但导致了我们总是出现类似空指针这样低级的bug而且还很难找到引起bug的原因,相反,在规范的开发中,bug不但可以有效减少,查找bug也变得轻而易举, 规范不是对开发的制约,而确实是有助于提高开发效率的。
1.3.1.3 规范的代码可以降低维护成本
随着我们项目经验的累积,会越来越重视后期维护的成本,而开发过程中的代码质量直接影响着维护的成本,因此,我们不得不从开发时便小心翼翼。
在第一点中曾提到,规范的代码大大提高了程序的可读性,几乎所有的程序员都曾做过维护的工作,不用多说,可读性高的代码维护成本必然会大大降低。
但是,维护工作不仅仅是读懂原有代码,而是需要在原有代码基础上作出修改,我们可以先想像没有统一风格的情况下,A完成开发以后,B进行维护加一段代码,过一段时间C又加一段代码。。。。。。直到有一天X看到那一大堆乱码想死的心都有了,维护也就进行不下去了。
因此,统一的风格有利于长期的维护,另外,好的代码规范会对方法的度量、类的度量以及程序耦合性作出约束,这样不会出现需要修改一个上千行的方法或者去扩展一个没有接口的类的情况,规范的代码对程序的扩展性提高,无疑也是对维护人员的一个奖励。
1.3.1.4 规范的代码有助于代码审查
一些公司里面会定期进行代码审查的,这样可以及时纠正一些错误,而且可以对开发人员的代码规范作出监督
团队的代码审查同时也是一个很好的学习机会,对成员的进步也是很有益的,但是,开发随意,加重的代码审查的工作量及难度,并且使得代码审查工作没有根据,浪费了大量的时间却收效甚微,代码规范不仅使得开发统一,减少审查监督,而且让代码审查有据可查,大大提高了审查效率和效果,同时代码审查也有助于代码规范的实施,一举多得,何乐而不为呢。
1.3.1.5 规范代码有助于养成代码规范的习惯
有助于程序员自身的成长 即使明白代码规范的好处,但是有的迫于项目压力,有的因为繁琐的规范作出很多额外的工作,更有的不重视维护的问题,而很难贯彻代码规范。
那么,我们需要了解,规范开发最大的受益人其实是自己!你有没有花费很多的时候查找自己的代码呢?尤其是出现bug的时候需要逐行的debug?自己写的代码乱了头绪的确实也见了不少,我们应该做的就是规范开发,减少自己出现的错误,很多时候项目的压力一部分也是由于前期开发中遗留的众多的问题。
还有的人觉得自己可以完成高难度的算法,就认为自己能力很强,不把规范放在眼里,很多人确实是这样,追求个性,大概让别人看他的代码一头雾水更觉得得意,殊不知复杂的算法确实可以体现你个人的逻辑能力,但是绝不代表你的开发水平,我们知道一些开源项目,一些大师级人物写得程序都是极其规范的,并非规范了就代表高水平,实际上是规范的代码更有利于帮助你理解开发语言理解模式理解架构,能够帮助你快速提升开发水平,不明白这点,即使你写的再高明的算法,没准哪天也被当作乱码别处理掉。
1.4 如何规范代码
如果代码不规范写的时间长了,在写规范的代码是很痛苦的,并且我们不清楚什么样的代码是规范的(每个公司的规范不一样),可能到一个公司就需要新学习一套规范
我们可用借助一些权威的规范文档以及借助一些权威的工具让我们的代码更加规范,按照这些权威的文档或者工具的规范写出来的代码规范也是其他人能够认同的,下面我们介绍一些文档或者工具
1.4.1 阿里巴巴代码规范
业界公认的代码规范手册(国内)当属阿里巴巴旗下出版的《Java 开发手册》,经过几个版本的迭代,最新手册为《Java开发手册(黄山版)》,更新时间为2022年2月3号
手册以 Java 开发者为中心视角,划分为编程规约、异常日志、 单元测试、 安全规约、 MySQL 数据库、 工程结构、 设计规约七个维度,再根据内容特征,细分成若干二级子目录,根据约束力强弱及故障敏感性,规约依次分为强制、推荐、参考三大类。对于规约条目的延伸信息中,“说明” 对规约做了适当扩展和解释;“正例” 提倡什么样的编码和实现方式;“反例”说明需要提防的雷区, 以及真实的错误案例。
1.4.2 代码规范工具
在软件研发过程中,bug越早发现,成本越低
代码扫描和单元测试,就是在早期帮我们发现程序中问题的有效手段,代码扫描不仅能帮我们发现程序的漏洞,也能督促开发人员更规范优雅地写代码。
但是如何培养好的代码规范呢,刚开始是可能对于很多代码规范不太了解,就可以采用一些代码规范工具帮助我们更好的培养好的代码规范,比如《阿里巴巴java开发手册》,sonar等代码质量管理平台等。
1.4.2.1 阿里规范插件
为了让开发者更加方便、快速将规范推动并实行起来,阿里巴巴基于手册内容,研发了一套自动化的IDE检测插件,于是在云栖大会上,发布了阿里人经过247天持续研发的阿里巴巴JAVA规约扫描插件——Alibaba Java Coding Guidelines.
该插件就是《阿里巴巴Java开发规约》的扩展,为了方便开发者,该插件作为一个IDE的插件形式,支持 IDEA 和Eclipse,当然也支持Android Studio( Android Studio是基于IDEA的)。
1.4.2.2 sonar
sonar是一款静态代码质量分析工具,支持Java、Python、PHP、JavaScript、CSS等25种以上的语言,而且能够集成在IDE、Jenkins、Git等服务中,方便随时查看代码质量分析报告。
1.4.2.3 两个工具对比
-
Alibaba代码规范插件:比较关心的是代码规范,编码风格上的,例如,命名规范,注释,代码行数等。
-
SonarLint:比较关心代码正确性,存在的问题,风险,漏洞等,例如,重复代码,空指针,安全漏洞等。
所以,一般建议结合使用,使用前者来规范代码,使用后者来提前发现代码的问题,配合起来提高工程整体的代码质量,并且能够在编码阶段规避风险,提高程序的健壮性。
2. 阿里巴巴代码规范
上面我们介绍了让代码规范的方案,下面我们就来说一下阿里的代码规范文档

业界公认的代码规范手册(国内)当属阿里巴巴旗下出版的《Java 开发手册》,经过几个版本的迭代,最新手册为《Java 开发手册》,更新时间为2022年2月3号。
手册以 Java 开发者为中心视角,划分为编程规约、异常日志、 单元测试、 安全规约、 MySQL 数据库、 工程结构、 设计规约七个维度,再根据内容特征,细分成若干二级子目录。根据约束力强弱及故障敏感性,规约依次分为强制、推荐、参考三大类。对于规约条目的延伸信息中,“说明” 对规约做了适当扩展和解释;“正例” 提倡什么样的编码和实现方式;“反例”说明需要提防的雷区, 以及真实的错误案例。
2.1 编程规约
2.1.1 方法参数类型必须一致,不要出现自动装箱拆箱操作
2.1.1.1 反例
这种操作很容易产生难以排查的NPE异常
/**
* 反例
* 容易出现空指针异常,如果参数为null就会拆箱失败空指针错误
* 排查的时候很难排查,因为直接看代码看起来不会出现空指针的。
* @param value
* @return
*/
public static int handel(Integer value) {
return value;
}
2.1.1.2 正例
入参以及出参,和参数传递类型是一致的
public static Integer handel(Integer value) {
return value;
}
2.1.2 SimpleDateFormat是线程不安全的
SimpleDateFormat 是线程不安全的类,一般不要定义为 static 变量,如果定义为 static, 必须加锁,或者使用 DateUtils 工具类
2.1.2.1 反例
使用这种方式在多线程的情况下会报错,或者出现数据不一致的情况
private static final SimpleDateFormat dateFormate = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
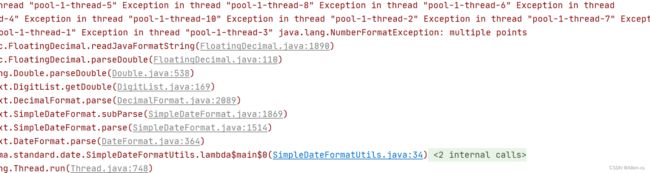
2.1.2.2 正例
使用ThreadLocal的方式保证线程安全,或者使用
DateTimeFormatter代替SimpleDateFormat
private static final ThreadLocal<SimpleDateFormat> threadLocal = new ThreadLocal<SimpleDateFormat>() {
@Override
protected SimpleDateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
}
};
2.1.3 使用equals方法应该注意空指针
2.1.3.1 反例
如果object为null就会抛出NPE异常
object.equals("test");
2.1.3.2 正例
应该使用常量或者确定的值来进行判断equals
"test".equals(object);
或者使用
Objects.equals
Objects.equals(object1,object2)
2.2 异常日志
2.2.1 事务场景中如果异常被被捕获要注意回滚
2.2.1.1 反例
@Service
@Transactional(rollbackFor = Exception.class)
public class UserServiceImpl implements UserService {
@Override
public void save(User user) {
try{
//some code
//db operation
}catche(Exception e){
}
}
}
2.2.1.2 正例
@Service
@Transactional(rollbackFor = Exception.class)
public class UserServiceImpl implements UserService {
@Override
public void save(User user) {
try{
//some code
//db operation
}catche(Exception e){
//捕获处理后需要再将异常抛出
throw e;
}
}
}
2.2.2 不要在 finally 块中使用 return
try 块中的 return 语句执行成功后,并不马上返回,而是继续执行 finally 块中的语句,如果此处存 在 return 语句,则在此直接返回,无情丢弃掉 try 块中的返回点。
2.2.2.1 反例
这种情况下结果永远返回的都是true,fanally中不要做返回操作
public static boolean getValue(String text) {
try {
return text.equals("123");
} finally {
return true;
}
}
2.2.2.2 正例
public static boolean getValue(String text) {
return "123".equals(text);
}
2.2.3 应用中不可直接使用日志系统(Log4j、Logback)中的 API
在Java生态体系中,围绕着日志,有很多成熟的解决方案,关于日志输出,主要有两类工具。
一类是日志框架,主要用来进行日志的输出的,比如输出到哪个文件,日志格式如何等,另外一类是日志门面,主要一套通用的API,用来屏蔽各个日志框架之间的差异的。
所以,对于Java工程师来说,关于日志工具的使用,最佳实践就是在应用中使用如Log4j + SLF4J 这样的组合来进行日志输出。
这样做的最大好处,就是业务层的开发不需要关心底层日志框架的实现及细节,在编码的时候也不需要考虑日后更换框架所带来的成本,这也是门面模式所带来的好处。
请不要在你的Java代码中出现任何Log4j等日志框架的API的使用,而是应该直接使用SLF4J这种日志门面。
2.2.4 所有日志文件至少保存15天
所有日志文件至少保存15天,因为有些异常具备以“周”为频次发生的特点,网络运行状态、安全相关信息、系统监测、管理后台操作、用户敏感操作需要留存相关的网络日志不少于6个月。
2.3 单元测试
2.3.1 好的单元测试必须遵守 AIR 原则
单元测试在线上运行时,感觉像空气(AIR)一样并不存在,但在测试质量的保障上,却是非常关键的,好的单元测试宏观上来说,具有自动化、独立性、可重复执行的特点。
2.3.2 单元测试应该是全自动执行的,并且非交互式的
- 测试用例通常是被定期执行的,执行过程必须完全自动化才有意义。
- 输出结果需要人工检查的测试不是一个好的单元测试。
- 单元测试中不准使用
System.out来进行人肉验证,必须使用assert来验证。
2.3.3 单元测试是可以重复执行的,不能受到外界环境的影响
单元测试通常会被放到持续集成中,每次有代码check in时单元测试都会被执行,如果单测对外部环境(网络、服务、中间件等)有依赖,容易导致持续集成机制的不可用,为了不受外界环境影响,要求设计代码时就把SUT的依赖改成注入,在测试时用spring 这样的DI框架注入一个本地(内存)实现或者Mock实现。
2.4 安全规约
2.4.1 用户敏感数据禁止直接展示,必须对展示数据进行脱敏
中国大陆个人手机号码显示为:137****0969,隐藏中间 4 位,防止隐私泄露,以及用户的身份证号码,银行卡号码,用户姓名等都需要进行脱敏处理
2.4.2 用户请求传入的任何参数必须做有效性验证
说明:忽略参数校验可能导致:
- page size 过大导致内存溢出
- 恶意 order by 导致数据库慢查询
- 缓存击穿
- 服务器端请求伪造(SSRF)
- 任意重定向
- SQL 注入,Shell 注入,反序列化注入
- 正则输入源串拒绝服务 ReDoS
2.5 MySQL 数据库
2.5.1 表明命名规范
表名、字段名必须使用小写字母或数字,禁止出现数字开头,禁止两个下划线中间只出现数字。
数据库字段名的修改代价很大,因为无法进行预发布,所以字段名称需要慎重考虑,MySQL 在 Windows 下不区分大小写,但在 Linux 下默认是区分大小写,因此,数据库名、表名、 字段名,都不允许出现任何大写字母,避免节外生枝
- 一般以t_xxx来作为表名
- 一般以v_xxx来作为视图名称
2.5.2 表必备的几个字段
- 创建人:标记记录的初始创建人
- 创建时间:标记初始的创建人
- 修改人:标记修改人
- 修改时间:标记最后修改日期
- 版本号:用于统一化的乐观锁
2.6 工程结构
2.6.1 线上应用不要依赖 SNAPSHOT 版本
正式发布的类库必须先去中央仓库进行查证,使 RELEASE 版本号有延续性,且版本号不允许覆盖升级。
2.6.2 注意POM坐标冲突
禁止在子项目的 pom 依赖中出现相同的 GroupId,相同的 ArtifactId,但是不同的Version。
在本地调试时会使用各子项目指定的版本号,但是合并成一个 war,只能有一个版本号出现在最后的lib 目录中,曾经出现过线下调试是正确的,发布到线上却出故障的先例。
2.7 阿里规范插件安装
这里面只列出来了几个比较重要的,很有很多的规约没有写出来,为了让大家码代码的效率更高,可以安装阿里的代码规范插件来约束自己凌乱的代码
阿里规范插件GitHub地址:https://github.com/alibaba/p3c
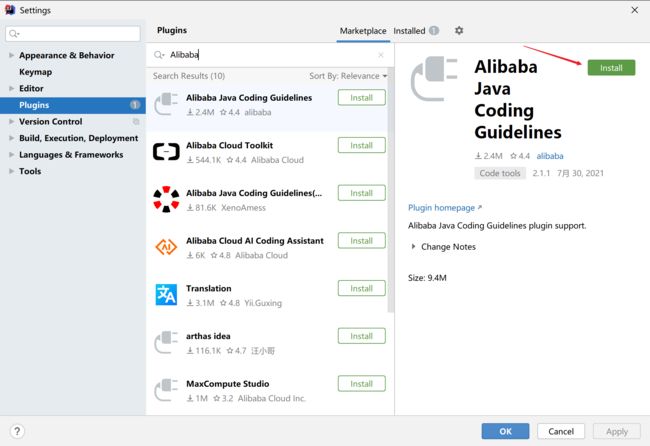
2.7.1 IDEA安装该插件步骤
打开IDEA,File-> Setteings->Plugins,在搜索栏搜索Alibaba,然后安装,安装完后点击Restart IntelliJ IDEA重启idea
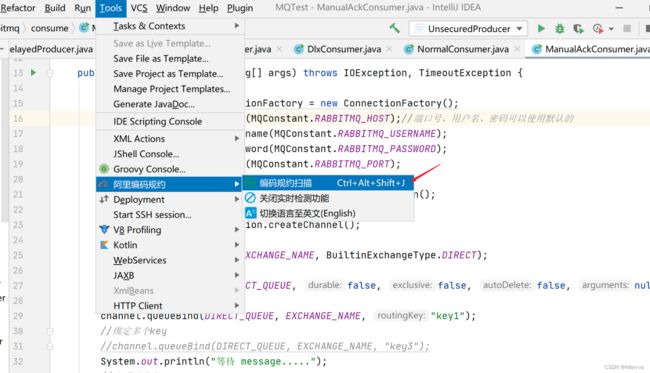
2.7.2 使用
安装好了,使用方法是:打开IDEA,点击tools—>安装的阿里编码规约,可以选择中英文切换,项目右键选择编码规约扫描就可以进行查看自己编码哪些地方不够好
2.7.3 检查等级
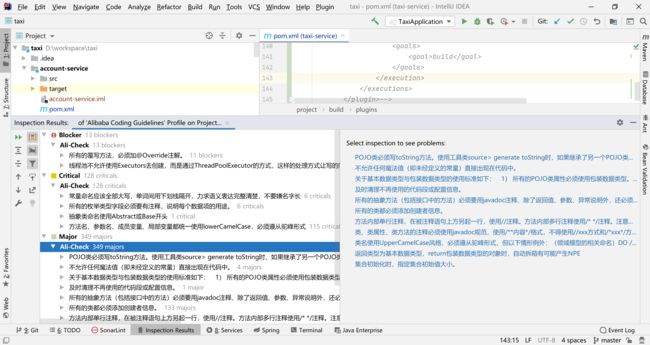
检查结果一共分三个等级
| 等级 | 验证程度 | 备注 |
|---|---|---|
| Blocker | 严重 | 有明显问题,影响功能以及性能 |
| Critical | 危险 | 一般问题,遵循标准 |
| Major | 主要 | 一般为建议 |
2.7.4 查看结果
可以通过结果查看一般存在的问题
3. sonar安装
3.1 简介
sonar是一款静态代码质量分析工具,支持Java、Python、PHP、JavaScript、CSS等25种以上的语言,而且能够集成在IDE、Jenkins、Git等服务中,方便随时查看代码质量分析报告。
通过插件机制,Sonar 可以集成不同的测试工具,代码分析工具,以及持续集成工具,比如findbugs、Jenkins,通过不同的插件对这些结果进行再加工处理,通过量化的方式度量代码质量的变化,从而可以方便地对不同规模和种类的工程进行代码质量管理。
简单来说,SonarQube是一个质量平台,用于收集质量数据(代码扫描结果、测试覆盖率等),并对数据进行各维度的统计分析。

3.1.1 客户端
Sonar的客户端共有四种
- Sonar-Scanner:一个独立的扫描器,通过简单的命令就能对项目进行静态扫描,并将扫描结果上传至SonarQube
- sonar maven:一个maven插件,能通过maven命令执行静态扫描。
- sonar ant插件:ant上的插件。
- sonar IDE插件:可以直接集成到IDE中(比如IntelliJ)。
3.1.2 sonar 版本区分
SonarQube除了开源的社区版之外,还有开发者版、企业版和数据中心版等不同的发行版本,以满足不同类型的客户需求,以下是根据SonarSource官网整理的各个版本之间的差异。
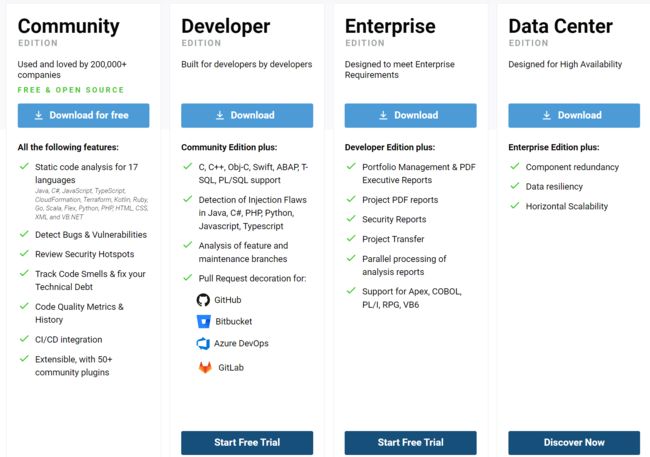
3.1.2.1 社区版
社区版就是通常大家所说的开源版本的SonarQube,通过其核心的代码质量和安全问题的扫描能力,以及质量门禁的功能,成为了目前代码静态扫描事实上的标准。
据有以下功能
- 60多个插件
- DevOps工具链集成
- 代码质量和安全
- 支持15种语言
- 支持5种IDE
此外,开源版支持15种常见的开发语言,尤其是在互联网行业中广泛使用Java和JavaScript的情况下,通过与构建工具(如maven/gradle插件)以及持续集成工具(如Jenkins)的集成,基本能满足个人和团队的日常代码扫描所需。
3.1.2.2 开发者版
当然,在开源社区版本的基础上,SonarQube还提供了开发者版。在全部社区版功能的基础上,新增了以下的功能
- Branch analysis(分支分析)
- Pull Request decoration(PR/MR注释)
- Detection of injection vulnerabilities(注入漏洞探测)
- SonarLint notifications(SonarLint通知)
- 22 Programming Languages Covered(尤其新增了c/c++/plsql)
- Developer Edition is available up to 20M Lines of Code.
对于金融行业来说,开发者版本支持了C/C++以及Oracle PL/SQL这三种语言,这样就为核心交易类系统以及遗留的业务系统展开代码扫描扫清了障碍。
另外一个非常有用的功能是多分支分析,社区版主要适合主干开发的团队,而目前Gitlab/Github-Flow以及特性分支等也非常流行,具备多分支分析能力,让SonarQube与现有团队的工作模式更加贴合。
3.1.2.3 企业版
对于大型跨国公司或者是集团性企业来说,开发者版就有些不够用了。当然,只要肯花钱,SonarQube也还有适用的版本。
- Portfolio Management(项目集管理)
- Executive Reporting(管理层报告)
- Security Reports(安全报告)
- Project Transfer(项目汇聚)
- 27 Programming Languages Covered
- Enterprise Edition is available up to 100M Lines of Code.
从上述特性清单来看,企业版主要是关注于管理层面的增强了。例如,多个应用可以汇聚成一条产品线或者事业部,通过其项目集管理也可以把若干个SonarQube项目汇聚到一个统计口径之下。
3.2 安装部署
3.2.1 修改文件句柄数
系统配置,避免启动问题
# 系统配置,避免启动问题
echo "vm.max_map_count=262144" >> /etc/sysctl.conf
sysctl -p
3.2.2 创建挂载目录
mkdir -p ~/sonarqube && cd ~/sonarqube
# 创建所有的sonarqube映射文件
mkdir -p ~/sonarqube/postgres && \\
mkdir -p ~/sonarqube/data && \\
mkdir -p ~/sonarqube/extensions && \\
mkdir -p ~/sonarqube/logs && \\
mkdir -p ~/sonarqube/conf
# 创建数据库挂载
mkdir -p ~/sonarqube/postgresql &&\\
mkdir -p ~/sonarqube/datasql
# 目录设置为 777 权限,避免权限问题
chmod 777 ~/sonarqube/*
3.2.3 创建docker-compose.yml
vi ~/sonarqube/docker-compose.yml
version: '3'
services:
postgres:
image: postgres:9.6.24
restart: always
container_name: sonarqube_postgres
ports:
- 5432:5432
volumes:
- ~/sonarqube/postgresql/:/var/lib/postgresql
- ~/sonarqube/datasql/:/var/lib/postgresql/data
environment:
TZ: Asia/Shanghai
POSTGRES_USER: sonar
POSTGRES_PASSWORD: sonar
POSTGRES_DB: sonar
networks:
- sonar-network
sonar:
image: sonarqube:8.9.9-community
restart: always
container_name: sonarqube
depends_on:
- postgres
volumes:
- ~/sonarqube/extensions:/opt/sonarqube/extensions
- ~/sonarqube/logs:/opt/sonarqube/logs
- ~/sonarqube/data:/opt/sonarqube/data
- ~/sonarqube/conf:/opt/sonarqube/conf
ports:
- 9000:9000
environment:
SONARQUBE_JDBC_USERNAME: sonar
SONARQUBE_JDBC_PASSWORD: sonar
SONARQUBE_JDBC_URL: jdbc:postgresql://postgres:5432/sonar
networks:
- sonar-network
networks:
sonar-network:
driver: bridge
3.2.4 启动
docker-compose up -d
3.2.4.1 访问测试
浏览器访问:ip+端口,如:192.168.245.139:9000,账号密码都是
admin
登录后进入项目页面
3.2.5 安装插件
可以进入应用市场下载一些常见的插件,一般是通过github下载,可能出现现在不下来的情况,可以手动下载后将jar包放进对应的
extensions/downloads下载目录就可以,然后点击install就可以进行安装了

3.2.5.1 汉化插件
Chinese Pack是一个sonar的汉化插件,安装后就可以体验中文界面了,以下是各版本的对应关系
| SonarQube | 9.0 | 9.1 | 9.2 | |||||||
| sonar-l10n-zh | 9.0 | 9.1 | 9.2 | |||||||
| SonarQube | 8.0 | 8.1 | 8.2 | 8.3 | 8.4 | 8.5 | 8.6 | 8.7 | 8.8 | 8.9 |
| sonar-l10n-zh | 8.0 | 8.1 | 8.2 | 8.3 | 8.4 | 8.5 | 8.6 | 8.7 | 8.8 | 8.9 |
| SonarQube | 7.0 | 7.1 | 7.2 | 7.3 | 7.4 | 7.5 | 7.6 | 7.7 | 7.8 | 7.9 |
| sonar-l10n-zh | 1.20 | 1.21 | 1.22 | 1.23 | 1.24 | 1.25 | 1.26 | 1.27 | 1.28 | 1.29 |
| SonarQube | 6.0 | 6.1 | 6.2 | 6.3 | 6.4 | 6.5 | 6.6 | 6.7 | ||
| sonar-l10n-zh | 1.12 | 1.13 | 1.14 | 1.15 | 1.16 | 1.17 | 1.18 | 1.19 | ||
| SonarQube | 5.4 | 5.5 | 5.6 | |||||||
| sonar-l10n-zh | 1.9 | 1.10 | 1.11 | |||||||
| SonarQube | 4.0 | 4.1 | ||||||||
| sonar-l10n-zh | 1.7 | 1.8 | ||||||||
| SonarQube | 3.1 | 3.2 | 3.3 | 3.4 | 3.5 | 3.6 | 3.7 | |||
| sonar-l10n-zh | 1.0 | 1.1 | 1.2 | 1.3 | 1.4 | 1.5 | 1.6 |
下载地址:https://github.com/xuhuisheng/sonar-l10n-zh,找到对应的版本下载后上传到dowload文件夹

在应用市场进行重启即可
再次访问就变成了中文界面了
3.3 静态分析插件介绍
3.3.1 什么是静态代码分析
静态代码分析是指无需运行被测代码,仅通过分析或检查源程序的语法、结构、过程、接口等来检查程序的正确性,找出代码隐藏的错误和缺陷,如参数不匹配,有歧义的嵌套语句,错误的递归,非法计算,可能出现的空指针引用等等。
在软件开发过程中,静态代码分析往往先于动态测试之前进行,同时也可以作为制定动态测试用例的参考。统计证明,在整个软件开发生命周期中,30% 至 70% 的代码逻辑设计和编码缺陷是可以通过静态代码分析来发现和修复的。
但是,由于静态代码分析往往要求大量的时间消耗和相关知识的积累,因此对于软件开发团队来说,使用静态代码分析工具自动化执行代码检查和分析,能够极大地提高软件可靠性并节省软件开发和测试成本。
3.3.1.1 静态代码分析优势
- 帮助程序开发人员自动执行静态代码分析,快速定位代码隐藏错误和缺陷。
- 帮助代码设计人员更专注于分析和解决代码设计缺陷。
- 显著减少在代码逐行检查上花费的时间,提高软件可靠性并节省软件开发和测试成本。
3.3.2 java静态分析插件
3.3.2.1 Checkstyle
Checkstyle 是 SourceForge 的开源项目,通过检查对代码编码格式,命名约定,Javadoc,类设计等方面进行代码规范和风格的检查,从而有效约束开发人员更好地遵循代码编写规范。
此外,Checkstyle 支持用户根据需求自定义代码检查规范,在配置面板中,用户可以在已有检查规范如命名约定,Javadoc,块,类设计等方面的基础上添加或删除自定义检查规范。
检查内容
- Javadoc 注释:检查类及方法的 Javadoc 注释
- 命名约定:检查命名是否符合命名规范
- 标题:检查文件是否以某些行开头
- Import 语句:检查 Import 语句是否符合定义规范
- 代码块大小,即检查类、方法等代码块的行数
- 空白:检查空白符,如 tab,回车符等
- 修饰符:修饰符号的检查,如修饰符的定义顺序
- 块:检查是否有空块或无效块
- 代码问题:检查重复代码,条件判断,魔数等问题
- 类设计:检查类的定义是否符合规范,如构造函数的定义等问题
3.3.2.2 FindBugs
FindBugs 是由马里兰大学提供的一款开源 Java 静态代码分析工具,FindBugs 通过检查类文件或 JAR 文件,将字节码与一组缺陷模式进行对比从而发现代码缺陷,完成静态代码分析,FindBugs 既提供可视化 UI 界面,同时也可以作为 Idea 插件使用。
检查内容
- Bad practice 坏的实践:常见代码错误,用于静态代码检查时进行缺陷模式匹配
- Correctness 可能导致错误的代码,如空指针引用等
- 国际化相关问题:如错误的字符串转换
- 可能受到的恶意攻击,如访问权限修饰符的定义等
- 多线程的正确性:如多线程编程时常见的同步,线程调度问题。
- 运行时性能问题:如由变量定义,方法调用导致的代码低效问题。
3.3.2.3 PMD
PMD 是由 DARPA 在 SourceForge 上发布的开源 Java 代码静态分析工具,PMD 通过其内置的编码规则对 Java 代码进行静态检查,主要包括对潜在的 bug,未使用的代码,重复的代码,循环体创建新对象等问题的检验。
检查内容
- 可能的 Bugs:检查潜在代码错误,如空 try/catch/finally/switch 语句
- 未使用代码(Dead code):检查未使用的变量,参数,方法
- 复杂的表达式:检查不必要的 if 语句,可被 while 替代的 for 循环
- 重复的代码:检查重复的代码
- 循环体创建新对象:检查在循环体内实例化新对象
- 资源关闭:检查 Connect,Result,Statement 等资源使用之后是否被关闭掉
3.3.3 几种插件对比
3.3.3.1 技术对比
| Java 静态分析工具 | 分析对象 | 应用技术 |
|---|---|---|
| Checkstyle | Java 源文件 | 缺陷模式匹配 |
| FindBugs | 字节码 | 缺陷模式匹配;数据流分析 |
| PMD | Java 源代码 | 缺陷模式匹配 |
3.3.3.2 分析对比
| 代码缺陷分类 | 示例 | Checkstyle | FindBugs | PMD |
|---|---|---|---|---|
| 引用操作 | 空指针引用 | √ | √ | √ |
| 对象操作 | 对象比较(使用 == 而不是 equals) | √ | √ | |
| 表达式复杂化 | 多余的 if 语句 | √ | ||
| 数组使用 | 数组下标越界 | |||
| 未使用变量或代码段 | 未使用变量 | √ | √ | |
| 资源回收 | I/O 未关闭 | √ | ||
| 方法调用 | 未使用方法返回值 | √ | ||
| 代码设计 | 空的 try/catch/finally 块 | √ |
4. Sonar使用
4.1 Maven代码扫描
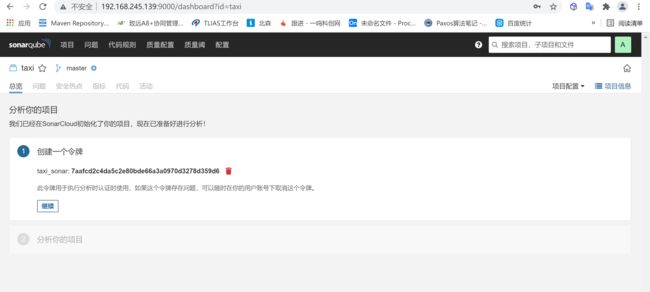
4.1.1 创建项目
点击创建项目就可以创建一个项目,为项目创建令牌
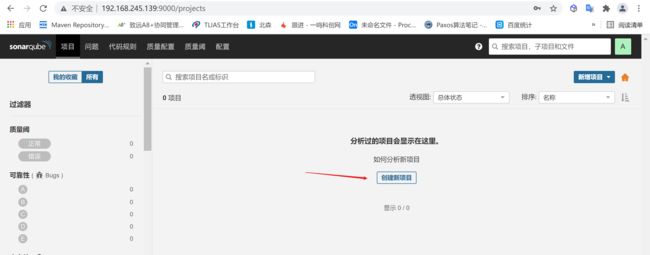
选择手工创建项目即可
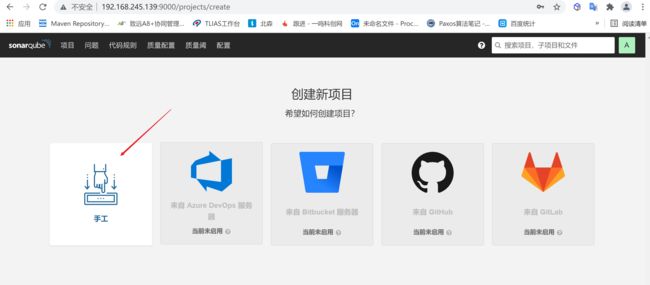
点击手工后,输入项目标识符以及项目名称,标识符是为了区分不同的项目,输入完成后,在输入令牌点击创建即可
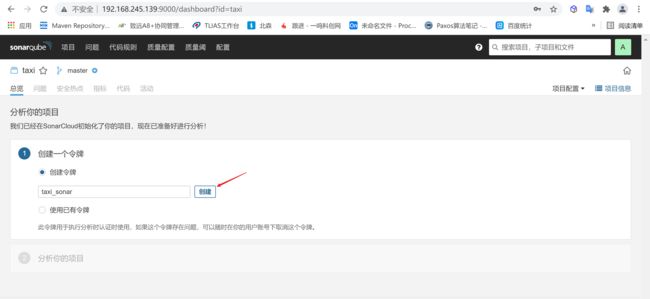
创建令牌后,会生成一个token,这个token是需要保存的,只会在这里显示一次
4.1.2 Maven 分析项目
4.1.2.1 生成sonar分析的命令
点击后面的
Maven分析项目,会生成一个maven分析项目的命令保存下来
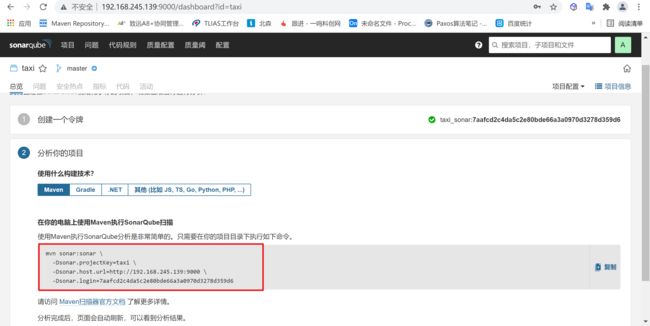
mvn sonar:sonar \\
-Dsonar.projectKey=taxi \\
-Dsonar.host.url=http://192.168.245.139:9000 \\
-Dsonar.login=7aafcd2c4da5c2e80bde66a3a0970d3278d359d6
4.1.2.2 项目配置 Sonar
我们需要配置 Maven 的 setting.xml文件,增加 sonarQube 配置
com.spotify
org.sonarsource.scanner.maven
sonar
true
http://192.168.245.139:9000
4.1.2.3 单元测试覆盖率
项目中一般要求需要编写测试用例,可以使用sonar统计单元测试的覆盖率,需要在maven项目由以下配置
org.jacoco
jacoco-maven-plugin
0.8.8
prepare-agent
prepare-agent
report
prepare-package
report
post-unit-test
test
report
target/jacoco.exec
target/jacoco-reports
target/jacoco.exec
4.1.3 执行扫描任务
4.1.3.1 没有单元测试覆盖率
配置完成setting.xml后就可以到项目中执行maven的执行命令了,可以执行以下命令
mvn sonar:sonar -Dsonar.projectKey=hitch -Dsonar.login=7c73f9b0176966c98ae9f52f129a3123227af29e
然后在项目中执行相关命令
执行后就可以等待sonar扫描即可
扫描完成后就可以看到分析的项目问题了
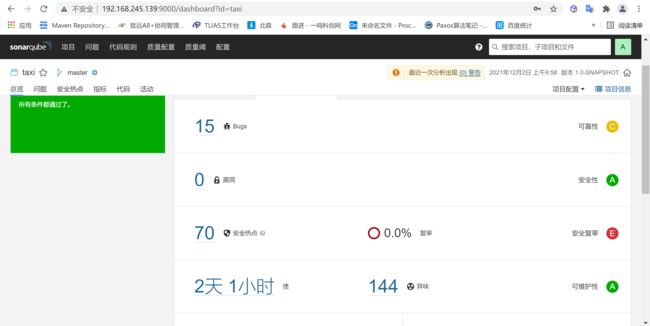
4.1.3.1 单元测试覆盖率
配置完成项目后,就需要执行sonar扫描命令了,如果需要单元测试执行如下命令
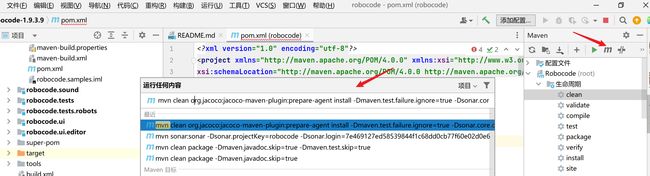
mvn clean org.jacoco:jacoco-maven-plugin:prepare-agent install -Dmaven.test.failure.ignore=true -Dsonar.core.codeCoveragePlugin=jacoco -Dsonar.projectKey=robocode -Dsonar.login=7e469127ed58539844f1c68dd0cb77f60e02d0e6 sonar:sonar
在项目中执行maven命令
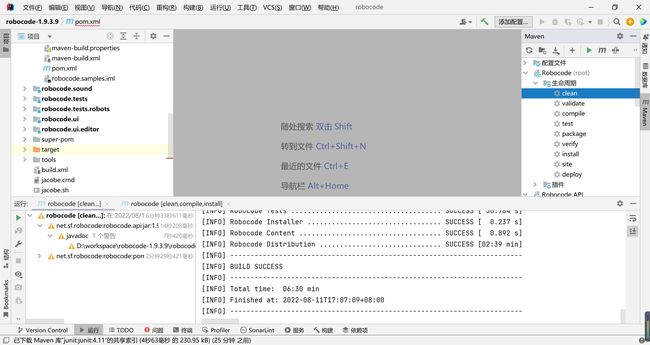
执行后就可以等待sonar扫描完成即可
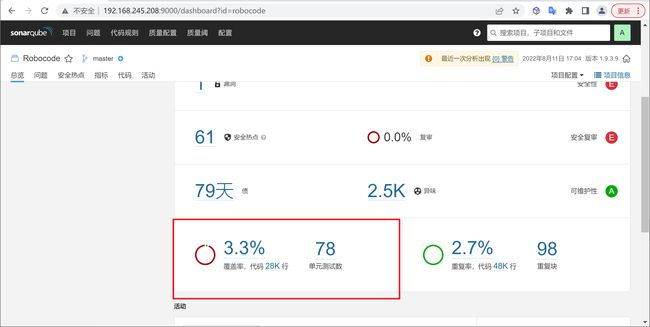
扫描完成后就可以看到分析的项目问题了
4.2 使用SonarLint
SonarLint是一款强大快速的能帮助开发者发现代码里的bug或是代码质量优化点的扩展工具。支持很多主流的语言:JAVA、js、PHP、Python,也支持主流的IDE们,idea、Eclipse、vs。在idea里更是以插件的形式无缝接入。
4.2.1 扫描模式区别
4.2.1.1 独立模式
使用插件内置规则进行检查,由于刚安装完插件之后设置是默认打开自动检测的,所以现在你的最底层工具栏里应该会多一项sonarlint,你打开不同的Java文件,检测会自动进行 ,检测结果也会直接展示在那里。
- 优点:无须配置,开箱即用,检查速度快;
- 缺点:内置规则与SonarQube服务器规则的不一致,会造成检查结果的不一致。
使用
4.2.1.2 连接模式
需连接SonarQube服务器
- 优点:简单配置后,即可使用SonarQube服务器的规则和配置项进行检查,检查结果保持最大一致。
- 缺点:项目需先接入SonarQube。
4.2.2 安装插件
打开IDEA,File-> Setteings->Plugins,在搜索栏搜索SonarLint,然后安装,安装完后点击Restart IntelliJ IDEA重启idea
4.2.3 配置SonarLint
对于企业级的开发,很多企业可能对代码风格和检查项有自己的要求。这就可以为公司的开发者提供sonarqube服务器,在其上进行配置,然后开发者连接以后就可以让sonarlint按照公司的定义来进行检查了。
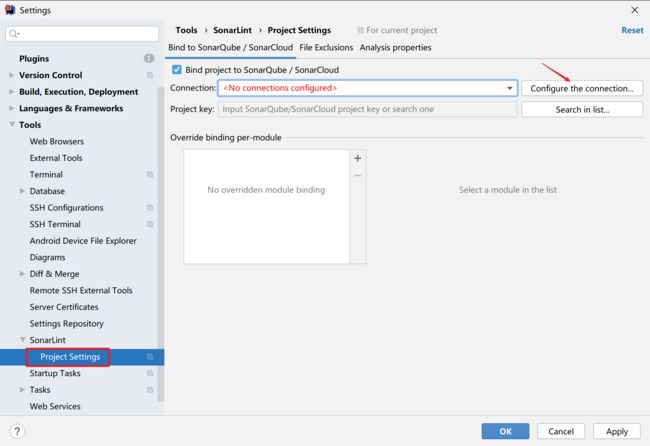
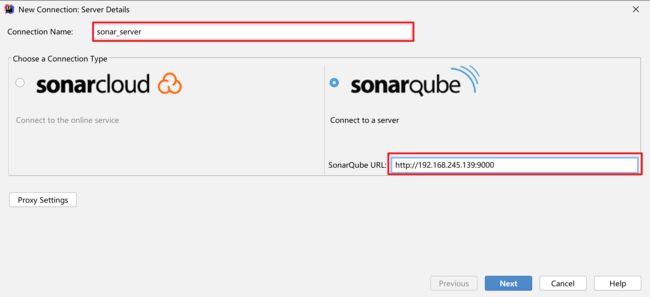
4.2.3.1 添加sonarqube server
依次点击File–>Settings–>Other Settings–>SonarLint General Settings,并进行如下操作:
配置本地nodejs.exe,然后添加
sonarqube服务器
4.2.3.2 配置项目
输入刚刚创建的Token
最后选择对应的projectKey即可
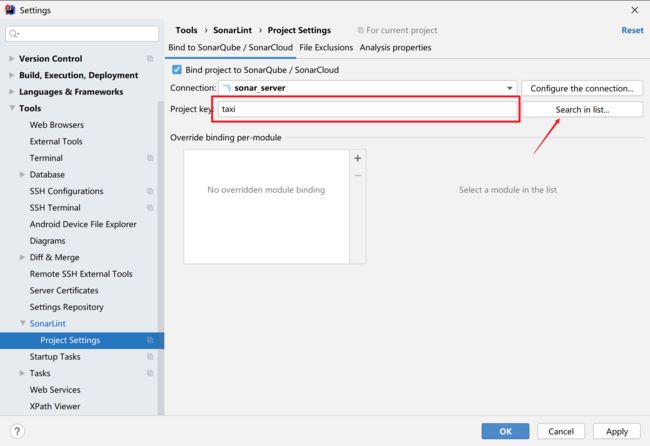
可以配置响应的模块来查看进行检测项目
4.2.4 联动测试
使用了连接模式后,我们对于
sonarqube服务求上面的规则变更会反映到我们的本地sonarlint插件上
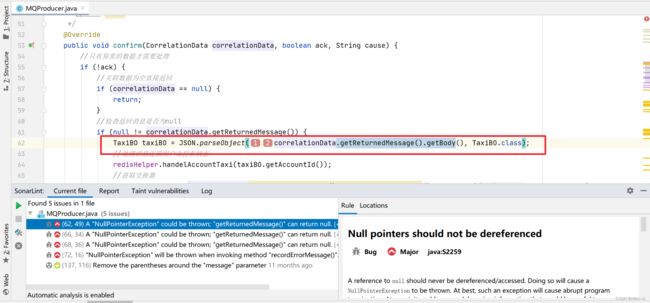
4.2.4.1 分析代码
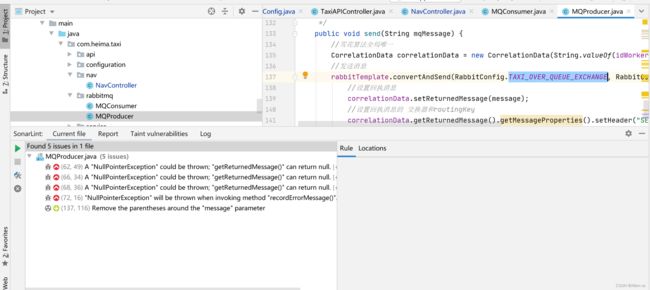
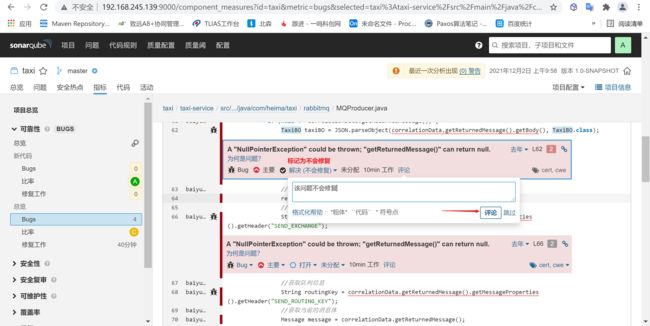
该类存在四个空指针的问题,我们假设改代码不会出现空指针问题
4.2.4.2 关闭服务器bug
我们到
sonarqube将该问题给改为不会修复,并点击评论即可
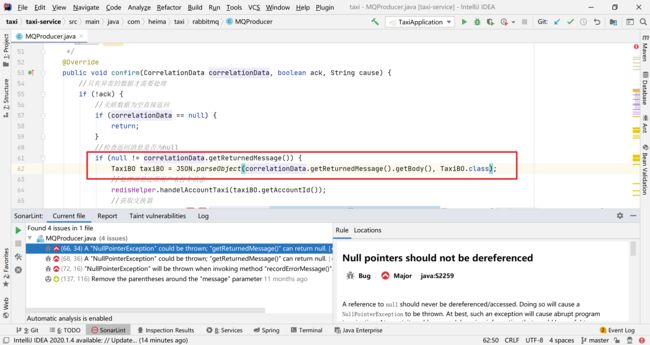
4.2.4.3 查看本地扫描结果
再次来查看下本地的扫描结果,发现该bug提示已经消失。
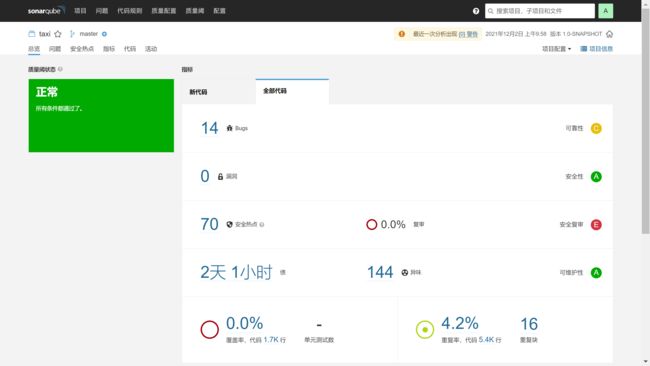
4.3 指标分析
4.3.1 总览
4.3.2 质量阈值
表示扫描是否通过,如果没有通过会显示失败,就需要进行修改代码了
4.3.3 可靠性
可靠性主要反应代码的bug数量,分为A-E五个等级,计算规则如下
- A :0 Bug 最高等级A,表示代码无bug
- B :at least 1 Minor Bug 代码只要有一个次要bug,等级就为B
- C:at least 1 Major Bug 只要包含一个重要bug,等级将为C
- D:at least 1 Critical Bug 只要有一个严重bug,等级评估为D
- E:at least 1 Blocker Bug 只要有一个最高等级的阻断级别的bug,可靠性评估为E,最低级别
4.3.4 漏洞严重级别
4.3.4.1 阻断
直接获取重要服务器(客户端)权限的漏洞。
包括但不限于远程任意命令执行、上传 webshell、可利用远程缓冲区溢出、可利用的 ActiveX 堆栈溢出、可利用浏览器 use after free 漏洞、可利用远程内核代码执行漏洞以及其它因逻辑问题导致的可利用的远程代码执行漏洞; 直接导致严重的信息泄漏漏洞,包括但不限于重要系统中能获取大量信息的SQL注入漏洞; 能直接获取目标单位核心机密的漏洞。
4.3.4.2 严重
直接获取普通系统权限的漏洞
包括但不限于远程命令执行、代码执行、上传webshell、缓冲区溢出等; 严重的逻辑设计缺陷和流程缺陷。包括但不限于任意账号密码修改、重要业务配置修改、泄露; 可直接批量盗取用户身份权限的漏洞。包括但不限于普通系统的SQL注入、用户订单遍历; 严重的权限绕过类漏洞。包括但不限于绕过认证直接访问管理后台、cookie欺骗。 运维相关的未授权访问漏洞,包括但不限于后台管理员弱口令、服务未授权访问
4.3.4.3 重要
需要在一定条件限制下,能获取服务器权限、网站权限与核心数据库数据的操作
包括但不限于交互性代码执行、一定条件下的注入、特定系统版本下的getshell等; 任意文件操作漏洞。包括但不限于任意文件写、删除、下载,敏感文件读取等操作; 水平权限绕过,包括但不限于绕过限制修改用户资料、执行用户操作。
4.3.4.4 次要
能够获取一些数据,但不属于核心数据的操作
在条件严苛的环境下能够获取核心数据或者控制核心业务的操作, 需要用户交互才可以触发的漏洞,包括但不限于XSS漏洞、CSRF漏洞、点击劫持。
4.3.5 安全性
安全性主要反应代码中可能存在的漏洞的数量
4.3.5.1 热点和漏洞
热点和漏洞之间的主要区别:在决定是否应用修复之前需要进行审查
4.3.5.2 安全热点
可以突出显示安全敏感的一段代码,但可能不会影响整体应用程序安全性。由开发人员审查代码以确定是否需要修复以保护代码。
4.3.5.3 漏洞
已发现需要立即修复的影响应用程序安全性的问题
5. 日志打印规范(自学)
5.1 为什么需要日志
通常,Java程序员在开发项目时都是依赖Eclipse/IDEA等集成开发工具的Debug 调试功能来跟踪解决Bug,但项目发布到了测试、生产环境怎么办?你有可能会说可以使用远程调试,但实际并不能允许让你这么做。
所以,日志的作用就是在测试、生产环境没有 Debug 调试工具时开发和测试人员定位问题的手段,日志打得好,就能根据日志的轨迹快速定位并解决线上问题,反之,日志输出不好,不仅无法辅助定位问题反而可能会影响到程序的运行性能和稳定性。
很多介绍 AOP 的地方都采用日志来作为介绍,实际上日志要采用切面的话是极其不科学的!对于日志来说,只是在方法开始、结束、异常时输出一些什么,那是绝对不够的,这样的日志对于日志分析没有任何意义。
如果在方法的开始和结束整个日志,那方法中呢?如果方法中没有日志的话,那就完全失去了日志的意义!如果应用出现问题要查找由什么原因造成的,也没有什么作用,这样的日志还不如不用!
5.2 日志有什么用
不管是使用何种编程语言,日志输出几乎无处不再,总结起来,日志大致有以下几种用途:
- 问题追踪:辅助排查和定位线上问题,优化程序运行性能。
- 状态监控:通过日志分析,可以监控系统的运行状态。
- 安全审计:审计主要体现在安全上,可以发现非授权的操作。
5.3 日志框架选择
5.3.1 常用的日志框架
log4j、Logging、commons-logging、slf4j、logback,这些都经常用的,为什么有这么多日志技术,它们都是什么区别和联系呢
5.3.1.1 Logging
这是 Java 自带的日志工具类,在 JDK 1.5 开始就已经有了,在 java.util.logging 包下,通常情况下,这个基本没什么人用了,了解一下就行。
5.3.1.2 commons-logging
commons-logging 是日志的门面接口,它也是Apache 最早提供的日志门面接口,用户可以根据喜好选择不同的日志实现框架,而不必改动日志定义,这就是日志门面的好处,符合面对接口抽象编程。现在已经不太流行了,了解一下就行。
5.3.1.3 Slf4j
slf4j,英文全称为“Simple Logging Facade for Java”,为java提供的简单日志Facade。
Facade门面,更底层一点说就是接口,它允许用户以自己的喜好,在工程中通过slf4j接入不同的日志系统。
因此slf4j入口就是众多接口的集合,它不负责具体的日志实现,只在编译时负责寻找合适的日志系统进行绑定。具体有哪些接口,全部都定义在slf4j-api中,查看slf4j-api源码就可以发现,里面除了public final class LoggerFactory类之外,都是接口定义,因此slf4j-api本质就是一个接口定义。
5.03.1.4 Log4j
Log4j 是 Apache 的一个开源日志框架,也是市场占有率最多的一个框架。
注意:log4j 在 2015.08.05 这一天被 Apache 宣布停止维护了,用户需要切换到 Log4j2上面去。
5.3.1.5 Log4j2
Apache Log4j 2是apache开发的一款Log4j的升级产品。
Log4j2与Log4j1发生了很大的变化,log4j2不兼容log4j1。
5.3.1.6 Logback
Logback 是 Slf4j 的原生实现框架,同样也是出自 Log4j 一个人之手,但拥有比 log4j 更多的优点、特性和更做强的性能,现在基本都用来代替 log4j 成为主流。
Logback相对于log4j拥有更快的执行速度。基于我们先前在log4j上的工作,logback 重写了内部的实现,在某些特定的场景上面,甚至可以比之前的速度快上10倍,在保证logback的组件更加快速的同时,同时所需的内存更加少。
5.3.2 日志框架怎么选
选项太多了的后果就是选择困难症,我的看法是没有最好的,只有最合适的
- commons-loggin、slf4j 只是一种日志抽象门面,不是具体的日志框架,log4j、logback 是具体的日志实现框架。
- 在比较关注性能的地方,选择Logback或自己实现高性能Logging API可能更合适,推荐:
slf4j + logback. - 在已经使用了Log4j的项目中,如果没有发现问题,继续使用可能是更合适的方式:推荐组合为:
slf4j + log4j2。 - 如果不想有依赖则使用java.util.logging或框架容器已经提供的日志接口。
5.3.3 记录日志的时机
在看线上日志的时候,我们可曾陷入到日志泥潭?该出现的日志没有,无用的日志一大堆,或者需要的信息分散在各个角落,特别是遇到紧急的在线bug时,有效的日志被大量无意义的日志信息淹没,焦急且无奈地浪费大量精力查询日志。那什么是记录日志的合适时机呢?
5.3.3.1 编程语言提示异常
今各类主流的编程语言都包括异常机制,业务相关的流行框架有完整的异常模块,这类捕获的异常是系统告知开发人员需要加以关注的,是质量非常高的报错,应当适当记录日志,根据实际结合业务的情况使用warn或者error级别。
5.3.3.2 业务流程预期不符
除开平台以及编程语言异常之外,项目代码中结果与期望不符时也是日志场景之一,简单来说所有流程分支都可以加入考虑,取决于开发人员判断能否容忍情形发生,常见的合适场景包括外部参数不正确,数据处理问题导致返回码不在合理范围内等等。
5.3.3.3 系统核心角色,组件关键动作
系统中核心角色触发的业务动作是需要多加关注的,是衡量系统正常运行的重要指标,建议记录INFO级别日志,比如电商系统用户从登录到下单的整个流程;微服务各服务节点交互;核心数据表增删改;核心组件运行等等,如果日志频度高或者打印量特别大,可以提炼关键点INFO记录,其余酌情考虑DEBUG级别。
5.3.3.4 系统初始化
系统或者服务的启动参数。核心模块或者组件初始化过程中往往依赖一些关键配置,根据参数不同会提供不一样的服务。务必在这里记录INFO日志,打印出参数以及启动完成态服务表述。
5.4 日志打印
5.4.1 日志变量定义
日志变量往往不变,最好定义成final static,变量名用大写。
private static final Logger logger = LoggerFactory.getLogger(BatchPullConsumer.class);
通常一个类只有一个 logger 对象,如果有父类可以将 logger 定义在父类中。
日志变量类型定义为门面接口(如 slf4j 的 Logger),实现类可以是 Log4j、Logback 等日志实现框架,不要把实现类定义为变量类型,否则日志切换不方便,也不符合抽象编程思想。
5.4.2 参数占位格式
使用参数化形式{}占位,[]进行参数隔离
logger.debug("Save order with order no:[{}], and order amount:[{}]");
logger.debug("Save order with order no:[{}], and order amount:[{}]");
这种可读性好,这样一看就知道[]里面是输出的动态参数,{}用来占位类似绑定变量,而且只有真正准备打印的时候才会处理参数,方便定位问题。
如果日志框架不支持参数化形式,且日志输出时不支持该日志级别时会导致对象冗余创建,浪费内存,此时就需要使用 isXXEnabled 判断,如:
if(logger.isDebugEnabled()){
// 如果日志不支持参数化形式,debug又没开启,那字符串拼接就是无用的代码拼接,影响系统性能
logger.debug("Save order with order no:" + orderNo + ", and order amount:" + orderAmount);
}
至少 debug 级别是需要开启判断的,线上日志级别至少应该是 info 以上的。
5.4.3 日志的基本格式
日志输出主要在文件中,应包括以下内容:
- 日志时间
- 日志级别主要使用
- 调用链标识(可选)
- 线程名称
- 日志记录器名称
- 日志内容
- 异常堆栈(不一定有)
5.4.3.1 日志时间
作为日志产生的日期和时间,这个数据非常重要,一般精确到毫秒,由于线上一般配置为按天滚动日志文件,日期标识在文件名上,所以可以不放在这个时间中,使用 HH:mm:ss.SSS 格式即可,非要加上也未尝不可,格式推荐:yyyy-MM-dd HH:mm:ss.SSS。
5.4.3.2 日志级别
日志的输出都是分级别的,不同的设置不同的场合打印不同的日志。
- DEBUG:DEUBG 级别的主要输出调试性质的内容,该级别日志主要用于在开发、测试阶段输出。
- INFO:INFO日志主要记录系统关键信息,旨在保留系统正常工作期间关键运行指标。
- WARN:WARN 级别的主要输出警告性质的内容,这些内容是可以预知且是有规划的。
- ERROR:ERROR 级别主要针对于一些不可预知的信息,诸如:错误、异常等。
5.4.4 日志文件
日志文件放置于固定的目录中,按照一定的模板进行命名,推荐的日志文件名称:
当前正在写入的日志文件名:<应用名>[-<功能名>].log
需要保留历史的日志文件名:<应用名>[-<功能名>].log.