MySQL-慢sql优化思路
目录
1、开启Mysql慢查询
1.1、查看慢查询相关配置
1.2、查询慢查询sql耗时临界点
1.3、开启Mysql慢查询
2、explain查看SQL执行计划
2.1、Select_type
2.2、Type
2.3、Possible_keys
2.4、Key
2.5、Key_len
2.6、Rows
2.7、Extra
3、profile 分析执行耗时
3.1、查询profile开启状态
3.2、开启profiling
3.3、查看最近运行的SQL
3.3.1、show profiles
3.3.2、show profile for query id
4、Optimizer Trace分析详情
4.1、分析流程
4.2、结果分析
5、慢查询经典案例总结
5.1、隐式类型转换
5.2、最左匹配
5.3、limit深分页问题
5.4、in元素过多
5.5、order走文件排序导致的慢查询
5.6、索引字段使用is null 或 is not null可能导致索引失效
5.7、索引字段上使用(!= 或者 < >, not in)可能导致索引失效
5.8、左右连接,关联的字段编码格式不一致
5.9、delete + in子查询不走索引
1、开启Mysql慢查询
1.1、查看慢查询相关配置
show variables like 'slow_query_log%'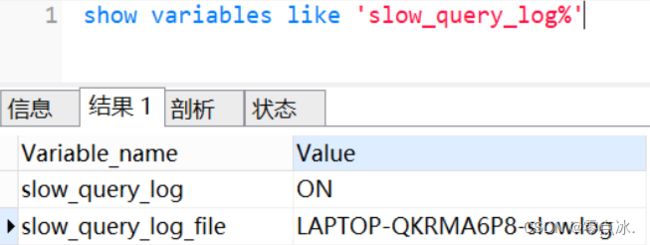
-
slow_query_log 表示慢查询开启的状态
-
slow_query_log_file 表示慢查询日志存放的位置
1.2、查询慢查询sql耗时临界点
show variables like 'long_query_time'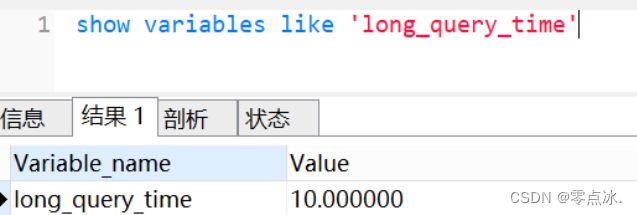
-
long_query_time 表示查询超过多少秒才记录到慢查询日志。
1.3、开启Mysql慢查询
- 方式一:修改配置文件开启慢查询
在my.ini增加如下配置
# 定义sql耗时多少秒就算是慢查询,记录慢查询日志
long_query_time=2
# 开启慢查询
slow_query_log=on
# 定义慢查询日志文件名
slow_query_log_file=/usr/local/mysql/mysql-slow-query.log- 方式二:通过命令开启慢查询
set global slow_query_log=ON # 开启慢查询日志
set global long_query_time=2 # SQL查询时间大于2秒,则记录慢查询日志2、explain查看SQL执行计划
explain + SQL,查看SQL的执行计划。重点关注type、rows、extra、key指标。

2.1、Select_type
查询类型:
- SIMPLE : 表示查询语句不包含子查询或union
- PRIMARY:表示此查询是最外层的查询
- UNION:表示此查询是UNION的第二个或后续的查询
- DEPENDENT UNION:UNION中的第二个或后续的查询语句,使用了外面查询结果
- UNION RESULT:UNION的结果
- SUBQUERY:SELECT子查询语句
- DEPENDENT SUBQUERY:SELECT子查询语句依赖外层查询的结果
2.2、Type
存储引擎查询数据时采用的方式:
性能:NULL > const > eq_ref > ref > range > index > ALL
- ALL:表示全表扫描,性能最差。
- index:表示基于索引的全表扫描,先扫描索引再扫描全表数据。
- range:表示使用索引范围查询。使用>、>=、<、<=、in等等。
- ref:表示使用非唯一索引进行单值查询。
- eq_ref:一般情况下出现在多表join查询,表示前面表的每一个记录,都只能匹配后面表的一行结果。
- const:表示使用主键或唯一索引做等值查询,常量查询。
- NULL:表示不用访问表,速度最快。
2.3、Possible_keys
表示查询时可能使用到的索引。
2.4、Key
查询时真正使用到的索引。
2.5、Key_len
表示查询使用了索引的字节数量。可以判断是否全部使用了组合索引。
- 字符串类型
字符串长度跟字符集有关:latin1=1、gbk=2、utf8=3、utf8mb4=4
char(n):n*字符集长度
varchar(n):n * 字符集长度 + 2字节
- 数值类型
TINYINT:1个字节 SMALLINT:2个字节 MEDIUMINT:3个字节
INT、FLOAT:4个字节 BIGINT、DOUBLE:8个字节
- 时间类型
DATE:3个字节 TIMESTAMP:4个字节 DATETIME:8个字节
- 字段属性
NULL属性占用1个字节,如果一个字段设置了NOT NULL,则没有此项
2.6、Rows
SQL查询扫描的行数,行数越小越好。MySQL查询优化器会根据统计信息,估算SQL要查询到结果需要扫描多少行记录。
2.7、Extra
额外信息。
- Using where:表示查询需要通过索引回表查询数据。
- Using index:表示查询需要通过索引,索引就可以满足所需数据。
- Using filesort:表示查询出来的结果需要额外排序,数据量小在内存,大的话在磁盘,因此有Using filesort建议优化。
- Using temprorary:查询使用到了临时表,一般出现于去重、分组等操作。
-
Using index condition:MySQL5.6之后新增的索引下推。在存储引擎层进行数据过滤,而不是在服务层过滤,利用索引现有的数据减少回表的数据。
3、profile 分析执行耗时
观测SQL真正的执行线程状态及消耗的时间。
3.1、查询profile开启状态
show variables like '%profil%'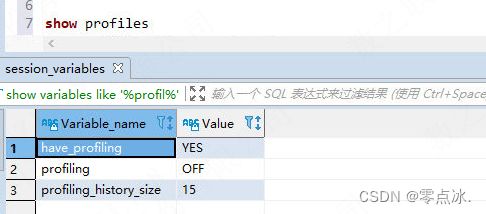
- have_profiling:确定是否支持 profile
- profiling:是否开启profiling
- profiling_history_size:定义MySQL服务器最近接收到的SQL条数。
3.2、开启profiling
执行如下SQL:
set profiling=ON
set profiling_history_size=303.3、查看最近运行的SQL
3.3.1、show profiles
查询最近SQL的执行耗时。
-- 查询最近profiling_history_size条SQL
show profiles;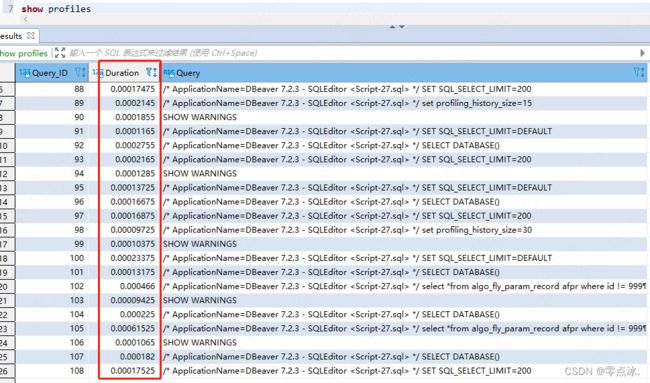
3.3.2、show profile for query id
查询一条SQL从开始到结束整个生命周期各个阶段的执行耗时。
-- 根据query_id查询指定SQL执行耗时
show profile for query id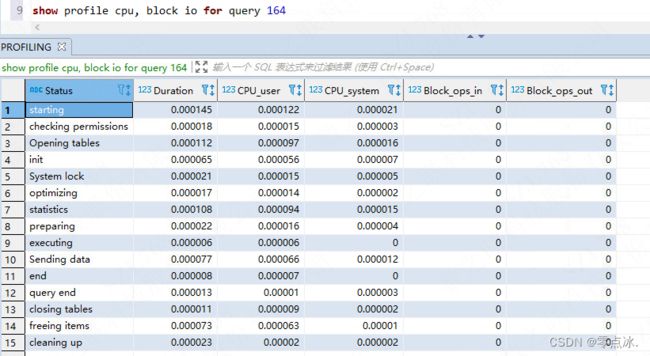
4、Optimizer Trace分析详情
profile只能查询SQL执行耗时,无法看到SQL具体的执行信息。
Optimizer Trace:可以跟踪执行语句的解析优化执行的全过程。
4.1、分析流程
- 打开开关
set optimizer_trace="enabled=on"- 执行需要分析的SQL
- 执行跟踪
select * from information_schema.optimizer_trace4.2、结果分析
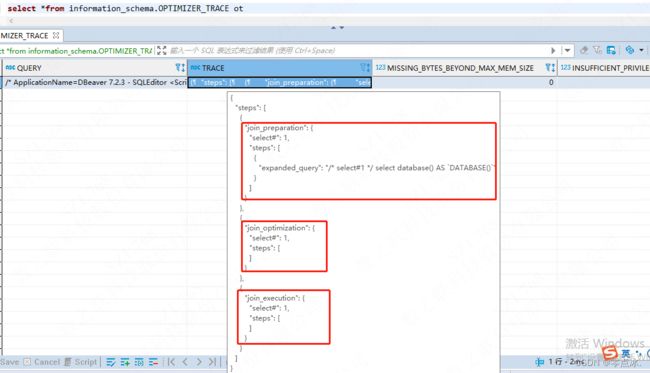
-
join_preparation:准备阶段
-
join_optimization:分析阶段
-
join_execution:执行阶段
5、慢查询经典案例总结
以user表为例举例说明:
CREATE TABLE user (
id int(11) NOT NULL AUTO_INCREMENT,
user_id varchar(32) NOT NULL,
age varchar(16) NOT NULL,
name varchar(255) NOT NULL,
PRIMARY KEY (id),
KEY idx_userid (userId) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;5.1、隐式类型转换
把userId设为索引,如果在查询条件中把一个数字传给user_id,则索引失效。
# user_id索引失效,传的是数字123,索引user_id类型为字符串,两者类型不匹配
# MySql会将user_id转换为字符串再进行比较。
select *from user where user_id = 123
# 走userId索引
select *from user where user_id = '123'5.2、最左匹配
不满足最左匹配原则,索引不生效。
5.3、limit深分页问题
MySql会查询满足条件的100010行,然后丢弃前100000行,返回最后10行。
select *from user where age > 20 limit 100000,10解决方案:减少回表
- 标签记录法:
标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描。
# 标签记录法:局限是要求id连续
select *from user where id > 100000 limit 10- 延迟关联法:
把条件转移到主键索引树,减少回表。
# 为age字段创建索引,通过age索引查询到满足条件的id,再与原表通过id内连接
select user1.id, user1.age, user1.name
FROM user user1
INNER JOIN (
SELECT u.id FROM user u WHERE u.age > 20 limit 100000, 10
) AS user2 on user1.id= user2.id;5.4、in元素过多
如果in中的元素过多,建议分组查询,一次200个。
select * from user where user_id in (1,2,3...200)
union all
select * from user where user_id in (201,202,203...400)5.5、order走文件排序导致的慢查询
执行计划如下,Extra中包含了Using filesort(文件排序)。

-
因为数据是无序的,所以就需要排序。如果数据本身是有序的,那就不会再用到文件排序啦。而索引数据本身是有序的,我们通过建立索引来优化
order by语句。 -
我们还可以通过调整
max_length_for_sort_data、sort_buffer_size等参数优化;
5.6、索引字段使用is null 或 is not null可能导致索引失效
有时可能因为数据量问题,导致MySQL优化器放弃走索引。另外,用explain分析SQL的时候,需要注意type=range时,可能会因为数据量问题,导致索引无效。
5.7、索引字段上使用(!= 或者 < >, not in)可能导致索引失效
如果优化器觉得即使走了索引,还是需要扫描很多很多行的哈,它觉得不划算,不如直接不走索引。
5.8、左右连接,关联的字段编码格式不一致
select u.name, j.name, j.job
from user u
left join user_job j on u.name = j.name将user表的name字段以及user_job表的name字段均设置索引
- 假设user表的name字段编码为utf8,user_job表的name字段编码为utf8mb4,则上述sql查询不走索引。
- 假设user表的name字段编码和user_job表的name字段编码均为utf8,则上述sql查询走索引。
5.9、delete + in子查询不走索引
delete from user where name in (select name from old_user)- delete + in子查询不走索引
- select + in子查询走索引
这是因为,实际执行的时候,MySQL对select in子查询做了优化,把子查询改成join的方式,所以可以走索引。但是对于delete in子查询,MySQL却没有对它做这个优化。
以上内容为个人学习理解,如有问题,欢迎在评论区指出。
部分内容截取自网络,如有侵权,联系作者删除。