汇编语言——王爽
使用debug执行汇编程序的步骤:
dir进入界面
编译:masm
链接:link
执行:debug 文件名


汇编程序格式
assume cs:code cs是寄存器,code是标号;
code segment //代码段开始
... ...
mov ax,4c00h
int 21h //上两行表示程序结束,唤起中断;
code ends //代码段结束
end //程序结束
汇编语言包括代码段,数据段,栈段三部分,后两个通过预先定义数据来实现;
如何区分不同的段完全根据指令;
[bx]和内存单元的描述
用[0]表示内存单元时,0表示单元的偏移地址,段地址在ds中,单元的长度(类型)可以有具体的指令中其他的操作对象指出(如寄存器);
这段话得到,会有专门的寄存器存储内存单元的长度,放置越界;即内存单元的长度由寄存器指出。
合法指令:mov ax 1合法指令;mov ds,1是非法指令;
数据寄存器和地址寄存器:
ax,bx,cx,dx是数据寄存器,向其中写入数据是合理的,而ds,cs,ip,ss,sp则不是,它们是地址寄存器,不能直接写入数据,只能通过数据寄存器送入数据。
Loop指令
loop指令的格式
loop 标号
操作步骤
1.(cx)=(cx)-1;
2.判断cx中的值,不为0则转至标号处执行,为0则向下执行;
cx的值表示循环次数;
提前结束循环命令
p指令可以一次执行完循环所有指令,g指令可以一直执行到具体指令处,g 偏移地址;
Debug 和masm对指令的不同理解
Debug和masm对”mov ax,[0]“的理解不同,Debug将[idata]理解为一个内存单元,idata是偏移地址,masm编译器将“[idata]”解释为数据"idata";
在汇编源程序中编写如下程序。
assume cs:code
code segment
mov ax,2000
mov ds,ax
mov al,[0]
mov bl,[1]
mov cl,[2]
mov dl,[3]mov ax,4c00h
int 21hcode ends
end执行后寄存器结果如下:
可以看到,[0]被理解为0,[1]被理解为1;

因此,需要使用bx作为偏移地址,用[bx]代表偏移地址,很麻烦;可以采用ds:[0]的方式显示的指出地址:
mov ax,ds:[0]的含义就是将段地址为ds,偏移地址为0的内存出的数据送入ax中;
总结
从上面可以看出,如果要访问一个内存单元,需在指令中使用[...]来表示内存单元,如果在[]里用一个常量idata直接给出内存单元的偏移地址,就要在[]前现实的给出段地址所在的寄存器;如果[]里使用寄存器,则段地址默认在ds中,当然也可以显式的给出段地址所在的寄存器。(P112)
loop和[bx]联合使用
编写程序计算fff:0~ffff:b单元中数据的和;程序如下:
assume cs:code
code segment
mov ax,0ffffh
mov ds,ax
mov bx,0
mov dx,0
s: mov al,ds:[bx]
mov ah,0
add dx,ax
inc bx
loop smov ax,4c00h
int 21hcode ends
end
段前缀
可以显式的给出段地址所在的段寄存器,汇编语言中显式的指出内存单元段地址的:ds:,cs:,ss:,es:被称为段前缀;
mov ax,ds:[bx],段地址在ax中
mov ax,cs:[bx],段地址在cs中
mov ax,es:[0],段地址在es中
一段安全的空间(P117)
不能随意写入
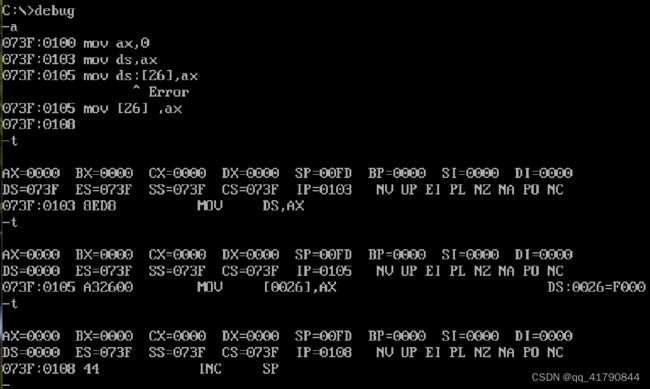
有些内存空间不能随意改写,如下面的代码在0:26处写入数据,结果引起死机。
mov ax,0
mov ds,ax
mov [26],ax
结果引发了 inc sp,系统死机;因此不能随意向内存中写入内容;
哪里有安全的空间
1.一般的PC机中,0:200~0:2ff这256个字节的内存空间是没有程序或系统使用的,是可以安全的写入数据的;
2.使用debug查看内存空间的内容,如果都是0,说明可以使用。
段前缀的使用(P120)
问题:将内存ffff:0~ffff:b单元中的数据复制到0:200~0:20b单元中
assume cs:code
code segment
mov ax,0ffffh
mov ds,ax
mov ax,0020h
mov es,ax
mov bx,0s: mov dl,[bx]
mov es:[bx],dl
inc bx
loop smov ax,4c00h
int 21hcode ends
end
包含多个段的程序(123)
assume cs:code,ss:stack,ds:data
data segment ;数据段
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
data ends
stack segment ;栈段dw 0,0,0,0, 0,0,0,0
stack endscode segment ;代码段
start: mov ax,stack
mov ss,ax
mov ax,20h
mov sp,axmov bx,0
mov cx,8
s: push cs:[bx]
add bx,2
loop s
mov bx,0
mov cx,8
s0: pop cs:[bx]
add bx,2
loop s0
mov ax,4c00h
int 21h
code ends
end start
更灵活的定位内存地址的方法
and和or指令
and:都为一才为1,否则为0;
or指令:都为0才为0,否则为1;
以字符形式给出的数据
在汇编程序中,使用'......'的方式知名数据以字符的形式给出,编译器将把他们转换为对应的ASCII码,
assume cs:code,ds:data
data segment
db 'uniX' ;定义了'uniX'的字符
db 'foRK'
data endscode segment
start: mov al,'a'
mov bl,'b'
mov ax,4c00h
int 21hcode ends
end start
大小写转换(P140)
转换方法:加减20H,或者使用and,or指令
[bx+idata]
[bx+idata]表示一个内存单元,偏移地址为(bx)+idata
mov ax,[bx+200]:将一个内存单元的内容送入ax,偏移地址为bx的数值+200,段地址在ds中;
该指令的格式:
mov ax,[bx+200]
mov ax,200[bx]
mov ax,[bx].200
三种格式都可以。
SI和DI
SI,DI是8086中和bx功能相近的寄存器,但si,di不能被分解为两个8位寄存器来使用。
[bx+si+idata],[bx+di+idata]:
格式如下:
mov ax,[bx+200+si]
mov ax,[bx].200[si]
mov ax,[bx][si].200
mov ax,200[bx][si]
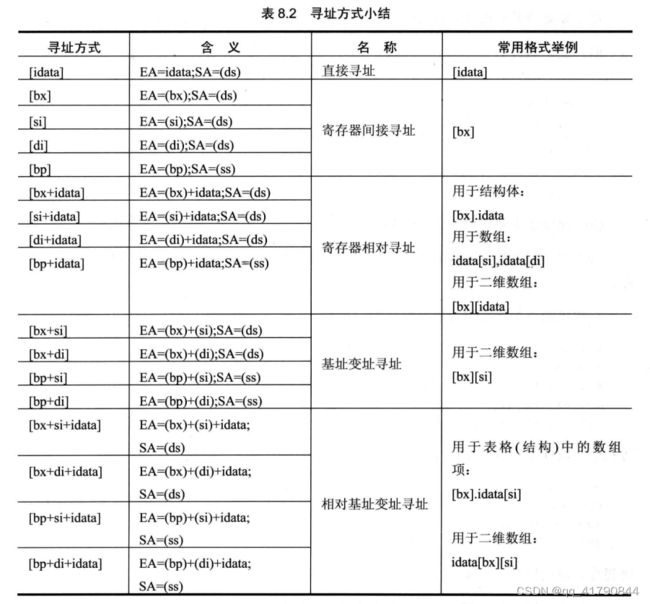
数据处理的两个基本问题-寻址方式总结
1.数据在什么地方
2.数据有多长
使用reg描述一个寄存器,使用sreg描述一个段寄存器
reg:ax,bx,cx,dx,al,ah,bl,bh,cl,ch,dl,dh,sp,si,di,bp
sreg:ds,cs,ss,es
只有bx,si,di,bp可以用于内存寻址;这四个寄存器可以单个出现,当组合出现时只能以以下四种组合出现:bx和si,bx和di,bp和si,bp和di;即有相同字母的寄存器不能同时出现;
综上,寻址方式如下:
指令处理的数据在哪里
(1)立即数
mov ax,1
(2)寄存器
mov ax,bx
(3)段地址和偏移地址
mov ax,ds:[1]
指令要处理的数据有多长
(1)通过寄存器名知名要处理的数据尺寸
mov ax,1表明数据为字
mov al,1表明数据为字节
(2)没有寄存器存在的情况下,用操作符 X ptr 指明内存单元的长度,X在汇编指令中可以为word或byte.
mov word ptr ds:[0],1 向ds:[0]处写入1(单位为字);
mov byte ptr ds:[0],1 数据长度为字节;
(3)其他方法
有些指令默认了访问的是字单元还是字节单元;如push,pop都为字操作;
寻址方式综合应用:修改结构体数据
问题:
内存中一处记录某公司的信息,要求将排名修改为40,收入修改为70,产品修改为VAX;
原信息:
代码:
assume cs:code,ds:data
data segment
db 'DEC','Ken Oslen'
dw 137,40
db 'PDP'data ends
code segmentstart: mov ax,data
mov ds,ax
mov bx,0
mov word ptr [bx].0ch,38
mov word ptr [bx].0eh,70
mov si,0
mov byte ptr [bx].10h[si],'V'
inc si
mov byte ptr [bx].10h[si],'A'
inc si
mov byte ptr [bx].10h[si],'X'
的
mov ax,4c00h
int 21h
code endsend start
div,dd,dup指令
div除法指令
除数:8位或16位,存储在reg或内存单元中;
被除数:默认在AX或DX和AX中,如果除数为8位,被除数则为16位,默认在AX中存放,如果除数为16位,被除数为32位,低位存放在AX中,高位存放在DX中,
结果:如果除数为8位,AL存储除法操作的商,AH存储除法操作的余数;
如果除数位16位,AX存储除法操作的商,DX存储除法操作的余数;
格式: div reg
div 内存单元
具体: div byte ptr ds:[0] 除数是8位
div word ptr ds:[0] 除数是16位
伪指令dd
dd可以用来定义双字数据,即占据2个字长度的数据;
dup
dup和db,dw,dd等数据定义伪指令配合使用,用来进行数据重复。
之前: db 0,0,0 db 1,2,3
现在(使用dup): db 3 dup (0) db 1 dup(1,2,3)
db 3 dup(0,1,2) :db 0,1,2,0,1,2,0,1,2
dup格式如下:
