专题五:优先级队列

"你了解我,最干净的轮廓, 握住小小风车和放肆的梦~"
堆是一个不错的数据结构,而在计算机中,无法表示二叉分支结构,因此我们经常会看到使用线性表来作为堆的存储容器。在接触堆的时候,我们是把它拿来同其他排序算法来看待的,但其实我们经常使用的是快排或者归并亦或者性能更加优越的"选择快排"。堆的应用场景,实质上转移到了查找问题,例如TopK等。很多语言也提供了以堆为底层的数据结构,例如C++中的priority_queue,Java中的PriorityQueue……
如何实现一个堆排序?
我们对任意一个堆的定义是一个完全二叉树,当一个父节点的值,大于左右子节点的值,则称为大堆,反之如果一个父节点的值,小于左右节点的值,则被称之为小堆。
建堆的方法有两种,一种是"向上调整法",一种是"向下调整法"。前者的思想是着眼于整个数组,后者的思想着眼于分治,先将最小的子树进行一次堆排序,再不停向上迭代。因为"向下调整法"实现起来更为简单,并且效率更高,所以我们选择后者。
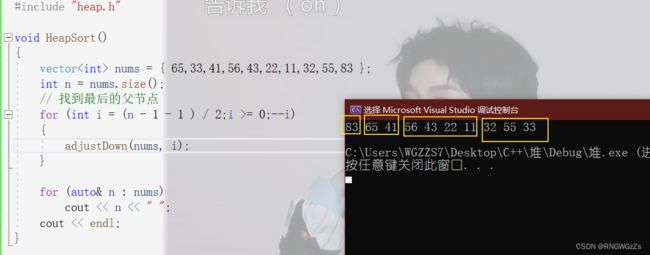
(1) 构建一个堆(大堆)
// 找到最后的父节点
for (int i = (n - 1 - 1 ) / 2;i >= 0;--i)
{
adjustDown(nums, i);
}
void adjustDown(vector& nums,int parent)
{
// 控制下标
int n = nums.size();
int child = parent * 2 + 1;
while (child < n)
{
// 把更大的换上去
if (child+1 < n && nums[child] < nums[child + 1]) child++;
// 比较
if (nums[parent] < nums[child]) {
swap(nums[parent], nums[child]);
// 更新
parent = child;
child = parent * 2 + 1;
}
else {
// 结束
break;
}
}
}
(2) 堆排序
要实现"升序排序,构建大堆,反之构建小堆"(因为本篇不是着眼于堆排序,不解释)。
void adjustDown(vector& nums,int parent,int end)
{
// 控制下标
int child = parent * 2 + 1;
while (child < end)
{
// 把更大的换上去
if (child+1 < end && nums[child] < nums[child + 1]) child++;
// 比较
if (nums[parent] < nums[child]) {
swap(nums[parent], nums[child]);
// 更新
parent = child;
child = parent * 2 + 1;
}
else {
// 结束
break;
}
}
}
void HeapSort(vector& nums)
{
// 建堆
int n = nums.size();
// 找到最后的父节点
for (int i = (n - 1 - 1 ) / 2;i >= 0;--i)
{
adjustDown(nums, i,n);
}
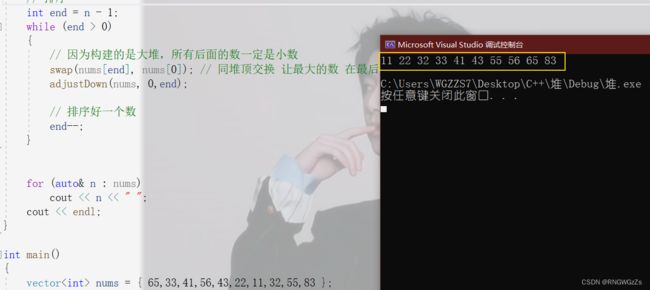
// 排序
int end = n - 1;
while (end > 0)
{
// 因为构建的是大堆,所有后面的数一定是小数
swap(nums[end], nums[0]); // 同堆顶交换 让最大的数 在最后一个
adjustDown(nums, 0,end);
// 排序好一个数
end--;
}
for (auto& n : nums)
cout << n << " ";
cout << endl;
} 
——前言
1、最后一块石头的重量
(1) 题目解析 
(2) 算法原理 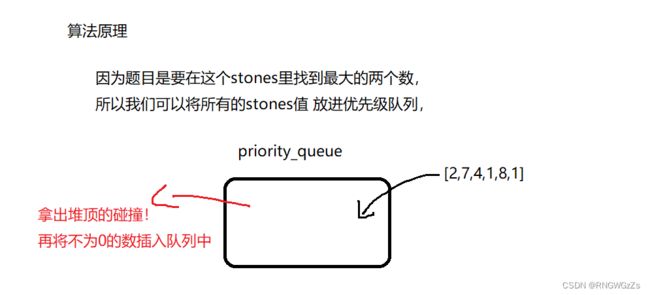
C++:
class Solution {
public:
int lastStoneWeight(vector& stones) {
// 寻找大数,构建大堆
priority_queue,less> heap;
// 入队列
for(auto& n:stones) heap.push(n);
// 模拟出队列
while(heap.size() > 1)
{
int x = heap.top();
heap.pop();
int y = heap.top();
heap.pop();
// 插入差值
heap.push(x-y);
}
return heap.size() == 0 ? 0:heap.top();
}
}; Java:
class Solution {
public int lastStoneWeight(int[] stones) {
PriorityQueue heap = new PriorityQueue<>((a, b) -> b - a);
for(int n:stones) heap.offer(n);
// 模拟
while(heap.size() > 1)
{
int a = heap.poll();
int b= heap.poll();
heap.offer(a-b);
}
return heap.isEmpty() ? 0 : heap.peek();
}
} 2、数据流中的第K大元素
(1) 题目解析
 这也是一个经典的topK问题,对于要找第K大的数,我们需要构建是小堆,而不是大堆。反之,要查找第K小的数,我们需要构建的是大堆,而不是小堆。
这也是一个经典的topK问题,对于要找第K大的数,我们需要构建是小堆,而不是大堆。反之,要查找第K小的数,我们需要构建的是大堆,而不是小堆。
(2) 算法原理

c++:
class KthLargest {
public:
// 构建小堆
priority_queue,greater> _heap;
int _k; // 构建多大的k
KthLargest(int k, vector& nums) {
_k = k;
// 入队列
for(auto& n:nums)
{
_heap.push(n);
if(_heap.size() > _k) _heap.pop(); // 剔除多余数
}
}
int add(int val) {
_heap.push(val);
if(_heap.size() > _k) _heap.pop();
return _heap.top();
}
}; java:
class KthLargest {
PriorityQueue heap;
int _k;
public KthLargest(int k, int[] nums) {
_k = k;
heap = new PriorityQueue<>(); // 默认是小堆
for(int x:nums){
heap.offer(x);
if(heap.size() > _k) heap.poll();
}
}
public int add(int val) {
heap.offer(val);
if(heap.size() > _k) heap.poll();
return heap.peek();
}
} 3、前K个高频单词
(1) 题目解 
(2) 算法原理

class Solution {
public:
typedef pair PSI; // 频次与字符串 用于比较
struct cmp
{
template
bool operator()(T& t1,T& t2)
{
return (t1.first > t2.first) || (t1.first == t2.first) && (t1.second < t2.second);
}
};
vector topKFrequent(vector& words, int k) {
unordered_map hash; // 统计频次
for(auto& str:words) hash[str]++;
// 普通的比较函数: less\greater 不能满足我们的要求
// 所以我们得更换比较函数: 这里我们采用的是 仿函数
priority_queue,cmp> heap;
for(auto& n:hash)
{
heap.push({n.second,n.first});
if(heap.size() > k) heap.pop();
}
// 倒序
vector ret(k);
for(int i=k-1;i>=0;--i)
{
ret[i] = heap.top().second;
heap.pop();
}
return ret;
}
}; 4、数据流中的中位数
(1) 题目解析

前两者解法都是很好想的,前提就是保证数组有序,再来找中位数。但,我们这里选择的解法不是其中的任意一种。
(2) 算法原理 
class MedianFinder {
public:
priority_queue,less> _left;
priority_queue,greater> _right;
MedianFinder() {}
void addNum(int num) {
if(_left.size() == _right.size())
{
if(_left.empty() || num <= _left.top())
{
// 直接进入
_left.push(num);
}
else
{
// 替换
_right.push(num);
_left.push(_right.top());
_right.pop();
}
}
else
{
if(num <= _left.top())
{
_left.push(num);
_right.push(_left.top());
_left.pop();
}
else
{
_right.push(num);
}
}
}
double findMedian() {
if(_left.size() == _right.size()) return (_left.top() + _right.top()) / 2.0;
return _left.top(); // m=n+1
}
}; 本篇到此结束,感谢你的阅读。
祝你好运,向阳而生~
