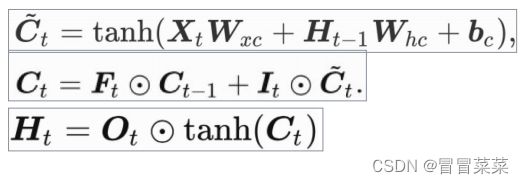深度学习(2)---循环神经网络(RNN)
文章目录
- 一、序列数据和语言模型
-
- 1.1 序列数据
- 1.2 语言模型
- 二、循环神经网络(RNN)
-
- 2.1 概述
- 2.2 门控循环单元(GRU)
- 2.3 长短期记忆网络(LSTM)
一、序列数据和语言模型
1.1 序列数据
1. 在深度学习中,序列数据(Sequence data)是指具有前后顺序关联的数据。常见的时间序列数据、文本数据(单词序列或字符序列)、语音数据等。这种数据不仅十分常见,而且往往具有很高的应用价值,比如我们可以通过过去的天气数据来预测未来的天气状况,通过以往的股票波动数据来推测股票的涨跌等。
比如:Cats average 15 hours of sleep a day.
其中第一个元素 “Cats” 和第三个元素 “15” 就具有关联性。
2. 序列数据的特点主要有以下两点:
- 时序关系:序列数据中的元素之间存在着时间上的依赖关系,每个元素都与其前面或后面的元素有关联。
- 变长性:序列数据的长度是可变的,不同序列可能包含不同数量的元素。
1.2 语言模型
1. 在自然语言处理中,语言模型是一种重要的技术,它的主要任务是估测一些词的序列的概率,即预测给定一个词的序列后,接下来可能出现的词的概率。
2. 自然语言处理中最常见的数据是文本数据。我们可以把一段自然语言文本看做一段离散的时间序列。假设一段长度为T的文本中的词依次为w1, w2, …, wT,那么在离散的时间序列中,wt(1 ≤ t ≤ T)可看做在时间步t的输出或者标签。
3. 给定一个长度为T的词的序列w1, w2, …, wT,语言模型将计算该序列的概率,即P(w1, w2, …, wT)。这个概率可以用来评估该词序列出现的可能性,从而在语言识别和机器翻译等任务中起到重要作用。
比如说一句话:“ chu fang li de shi you yong wan le ”。
那这句话是 “ 厨房里的石油用完了 ”还是 “ 厨房里的食油用完了 ”?
那语言模型要做的事是计算这两句序列的概率大小,比较并输出。即:P ( 厨 , 房 , 里 , 的 , 石 , 油 , 用 , 完 , 了 ) < P ( 厨 , 房 , 里 , 的 , 食 , 油 , 用 , 完 , 了)。
4. 语言模型计算序列概率的公式:

例如,一段含有4个词的文本序列的概率:

例如:P (我 , 在 , 听 , 课) = P (我) * P (在 | 我) * P (听 | 我 , 在) * P (课 | 我 , 在 , 听)
5. 语言模型缺点:时间步 t 的词需要考虑 t - 1步的词,其计算量随 t 呈指数增长。那我们可以利用循环神经网络来解决这一缺点。
二、循环神经网络(RNN)
2.1 概述
1. 循环神经网络(Recurrent neural networks,简称RNN)是针对序列数据而生的神经网络结构,核心在于循环使用网络层参数,避免时间步增大带来的参数激增,并引入隐藏状态(Hidden State)用于记录历史信息,有效的处理数据的前后关联性。
考虑这样一个问题,如果要预测句子的下一个单词是什么,一般需要用到当前单词以及前面的单词,因为句子中前后单词并不是独立的。比如,当前单词是“很”,前一个单词是“天空”,那么下一个单词很大概率是“蓝”。
循环神经网络的来源就是为了刻画一个序列当前的输出与之前信息的关系。从网络结构上,循环神经网络会记忆之前的信息,并利用之前的信息影响后面结点的输出。也就是说,循环神经网络的隐藏层之间的结点是有连接的,隐藏层的输入不仅包括输入层的输出,还包括上时刻隐藏层的输出。
2. 一个简单的循环神经网络如下所示,它由输入层、一个隐藏层和一个输出层组成:

3. 如果我们把上面的图展开,循环神经网络也可以画成下面这个样子:

现在看上去就比较清楚了,这个网络在t时刻接收到输入Xt之后,隐藏层的值是St,输出值是Ot。关键一点是,St的值不仅仅取决于Xt,还取决于St-1。
4. 我们可以用下面的公式来表示循环神经网络的计算方法:
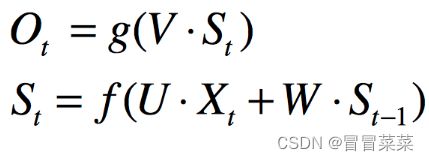
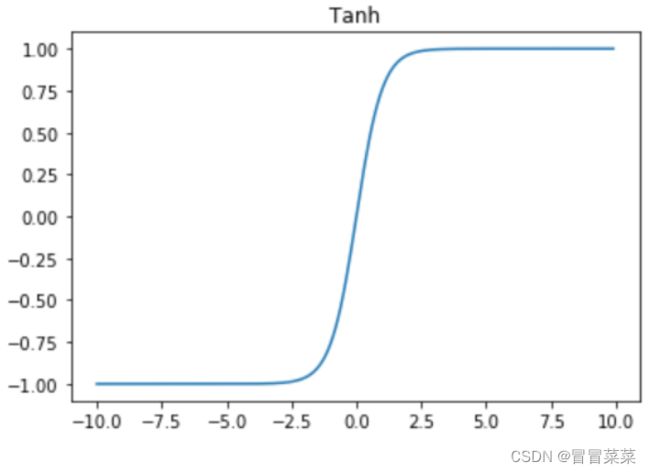
这里的激活函数通常选择Tanh函数,Tanh函数公式和图像如下所示,它解决了Sigmoid函数的不以0为中心输出问题。
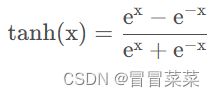
5. 用一个具体案例来看看RNN如何工作:
(1)用户说了一句“what time is it?”,我们的神经网络会先将这句话分为五个基本单元(四个单词+一个问号),如下所示:

(2)然后,按照顺序将五个基本单元输入RNN网络,先将 “what”作为RNN的输入,得到输出01:

(3)随后,按照顺序将“time”输入到RNN网络,得到输出02:
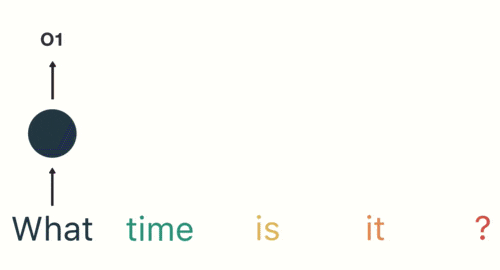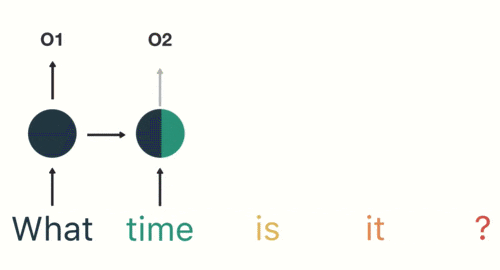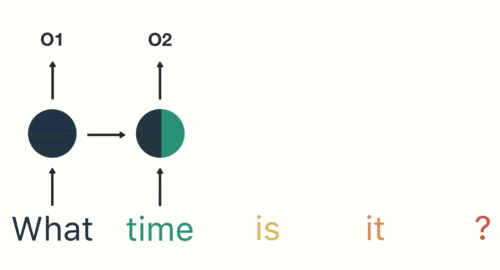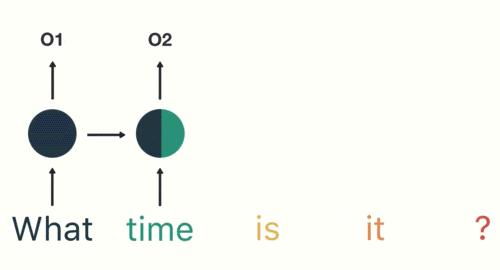
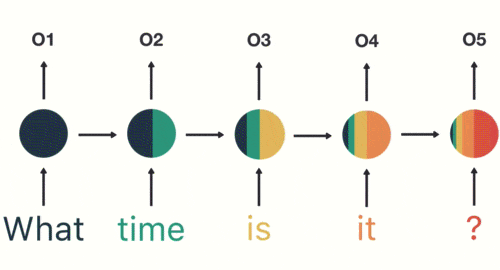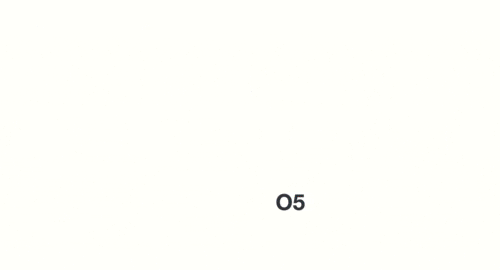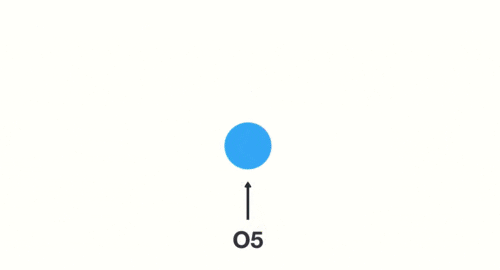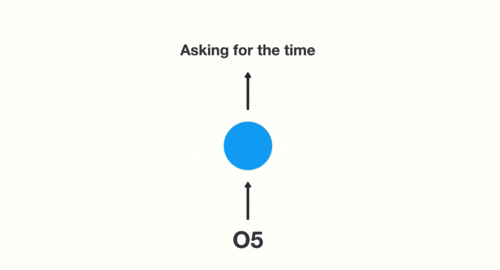
(4)以此类推,我们可以看到,前面所有的输入产生的结果都对后续的输出产生了影响(可以看到圆形中包含了前面所有的颜色):

(5)当神经网络判断意图的时候,只需要最后一层的输出05,如下图所示:
2.2 门控循环单元(GRU)
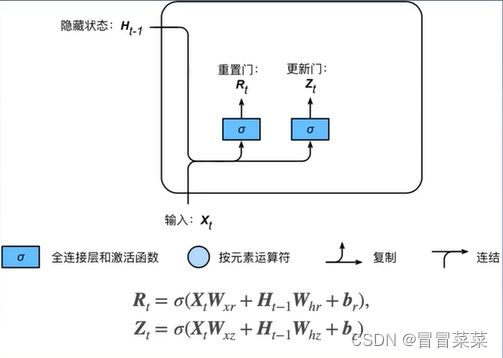
1. 门控循环单元(Gate Recurrent Unit)是引入门的循环网络,用来缓解RNN梯度消失带来的问题。引入门的概念,来控制信息流动,使模型更好的记住长远时期的信息,并缓解梯度消失。
- 重置门:哪些信息需要遗忘,用于遗忘上一时间步隐藏状态。
- 更新门:哪些信息需要注意,用于更新当前时间步隐藏状态。
- 激活函数为:Sigmoid,值域为( 0 , 1 ),0表示遗忘,1表示保留。
2. 候选隐藏状态:输入与上一时间步隐藏状态共同计算得到候选隐藏状态,用于隐藏状态计算。通过重置门,对上一时间步隐藏状态进行选择性遗忘,可以对历史信息更好地选择。
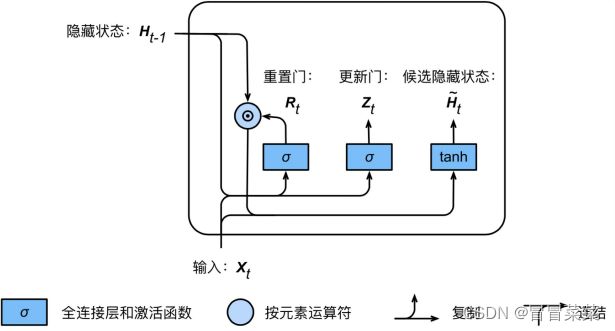
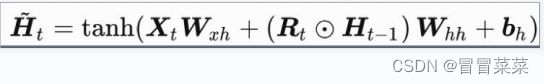
圆圈里加一点符号这里表示逐个元素相乘。
3. 隐藏状态由候选隐藏状态及上一时间步隐藏状态组合得来。
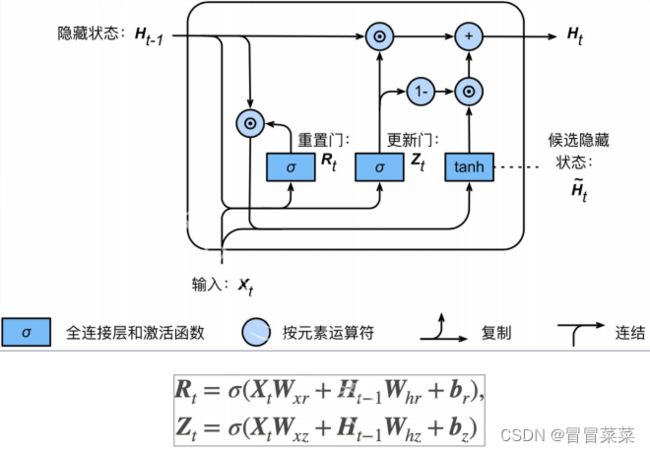

4. GRU特点:(1)门机制采用Sigmoid激活函数,使门值为(0,1),0表示遗忘,1表示保留。(2)若更新门自第一个时间步到t-1时间过程中,一直保持为1,则信息可有效传递到当前时间步。
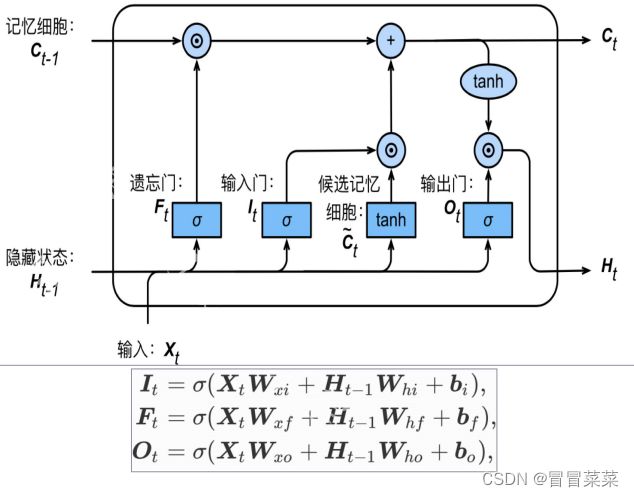
2.3 长短期记忆网络(LSTM)
1. 长短期记忆网络(Longshort-termmemory,简称LSTM)引入3个门和记忆细胞,控制信息传递。
- 遗忘门:哪些信息需要遗忘。
- 输入门:哪些信息需要流入当前记忆细胞。
- 输出门:哪些记忆信息流入隐藏状态。
- 记忆细胞:特殊的隐藏状态,记忆历史信息。
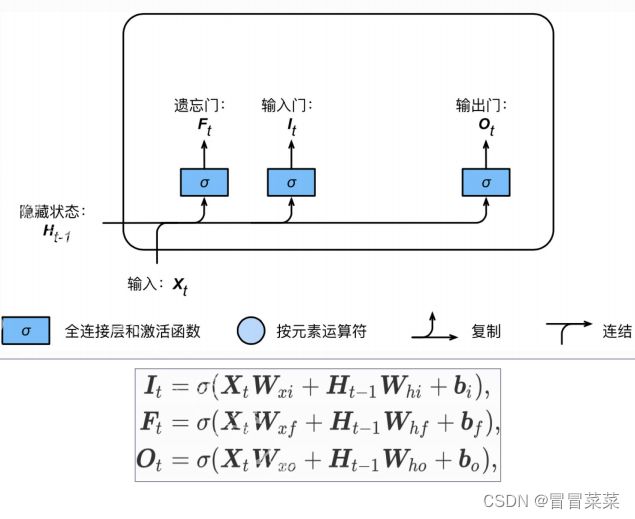
2. 候选记忆细胞:可理解为特殊隐藏状态,存储历史时刻信息。
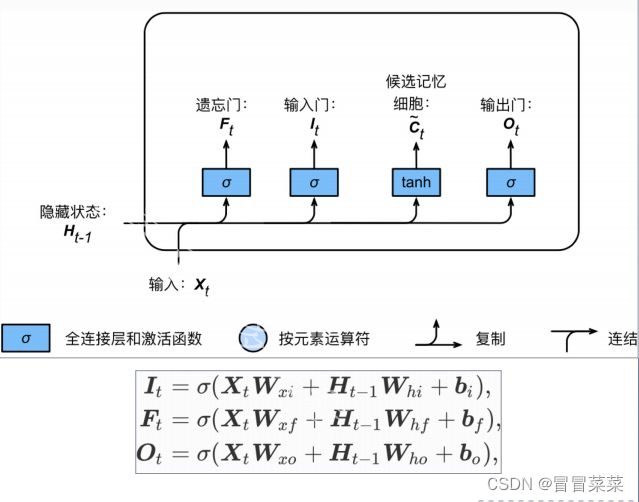
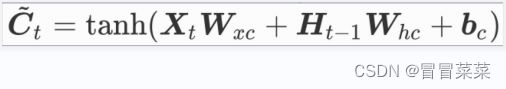
3. 记忆细胞由候选记忆细胞及上一时间步记忆细胞组合得来。输出门控制记忆细胞信息流入隐藏状态。

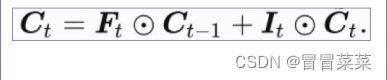

4. 总结:LSTM引入3个门和记忆细胞,控制信息传递。