Swin Transformer
Swin Transformer
-
- 1. 网络架构
- 2. 参数意义与设置
- 3. 将图像分割成不重叠的图像块(split image into non-overlapping patches)
1. 网络架构
先放一张网络架构图,看着方便!
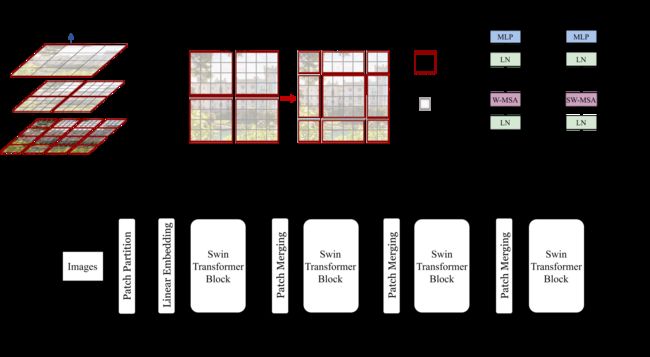
2. 参数意义与设置
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
class SwinTransformer(nn.Module):
r""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
img_size (int | tuple(int)): Input image size. Default 224 // 224
patch_size (int | tuple(int)): Patch size. Default: 4 // 4
in_chans (int): Number of input image channels. Default: 3 // 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96 //128
depths (tuple(int)): Depth of each Swin Transformer layer. //[ 2, 2, 18, 2 ]
num_heads (tuple(int)): Number of attention heads in different layers. //[ 4, 8, 16, 32 ]
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
初始化:swin_base_patch4_window7_224为例
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, **kwargs):
super().__init__()
self.num_classes = num_classes #1000
self.num_layers = len(depths) #4
self.embed_dim = embed_dim #128
self.ape = ape #false
self.patch_norm = patch_norm #true
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1)) #1024
self.mlp_ratio = mlp_ratio #4
3. 将图像分割成不重叠的图像块(split image into non-overlapping patches)
self.patch_embed = PatchEmbed(
img_size=img_size, #图像尺寸,224
patch_size=patch_size, #分割的图像块尺寸4,即 4*4
in_chans=in_chans, #图像的输入通道,3
embed_dim=embed_dim, #线性投影输出的通道数,128
norm_layer=norm_layer if self.patch_norm else None) #使用layer_norm
下面来看一下具体实现:
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size) # 输入是int类型可转为元组tuple类型,to_2tuple()中间的数字表示新元组的长度,(224, 224)
patch_size = to_2tuple(patch_size) # (4, 4)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]] #'//'先做除法,然后向下取整,224//4=56
self.img_size = img_size #(224, 224)
self.patch_size = patch_size #(4, 4)
self.patches_resolution = patches_resolution #(56,56), 每个patch的实际尺寸
self.num_patches = patches_resolution[0] * patches_resolution[1] #这个命名不好,因为这个数值表示的是每个图像块的实际像素数3136
self.in_chans = in_chans # 3
self.embed_dim = embed_dim # 线性投影输出维度 128
# nn.Conv2d(3, 128, (4, 4), (4, 4))
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim) # LayerNorm((128, ), eps=1e-05, elementwise_affine=True
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape # torch.Size[8, 3, 224, 224]
# 查看放宽尺寸限制(FIXME look at relaxing size constraints)
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x_tmp = self.proj(x)
x_tmp = x_tmp.flatten(2)
x_tmp = x_tmp.transpose(1, 2)
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
输入3维图像示例,每个图像是单个通道的成像
B, C, H, W = x.shape (4, 3, 224, 224)
