HW2: LibriSpeech phoneme classification
任务描述

音位分类预测(Phoneme classification),通过语音数据,预测音位。音位(phoneme),是人类某一种语言中能够区别意义的最小语音单位,是音位学分析的基础概念。每种语言都有一套自己的音位系统。
一帧(frame)设定为长25ms的音段,每次滑动10ms截得一个frame。每个frame经过MFCC处理,变成长度为39的向量。对于每个frame向量,数据集都提供了标签。标签有41类, 每个类代表一个phoneme
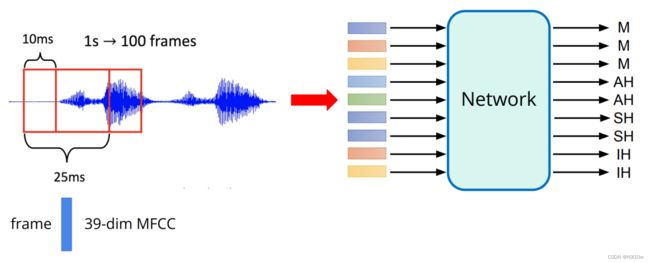
通常一个音位会跨越好几帧,所以训练时会结合前n帧和后n帧来对当前这一帧进行判断。

助教给出的代码:https://colab.research.google.com/drive/1wzeiVy2g7HpSjlidUr0Gi50NnHBWTkvN#scrollTo=KVUGfWTo7_Oj
数据(kaggle):https://www.kaggle.com/competitions/ml2023spring-hw2/data
数据说明
- train_split.txt: 其中每一行对应一个训练数据,其所对应的文件在feat/train/中
- train_labels.txt: 由训练数据和labels组成,格式为:
filename labels。其中,label 为 frame 对应的 phoneme

- test_split.txt: 其中每一行对应一个要求预测的数据,其所对应的文件在feat/test/中
feat/train/{id}.pt和feat/test/{id}.pt: 音频对应的 MFCC 文件,维度为39,这些文件可以通过torch.load()直接导入,导入后的shape为(T, 39)。
代码详解
导包
import os
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import numpy as np
from tqdm import tqdm
import random
import gc
定义数据集
class LibriDataset(Dataset):
def __init__(self, X, y=None):
self.data = X
if y is not None:
self.label = torch.LongTensor(y)
else:
self.label = None
def __getitem__(self, idx):
if self.label is not None:
return self.data[idx], self.label[idx]
else:
return self.data[idx]
def __len__(self):
return len(self.data)
torch.LongTensor将y进行转换成Long类型的
定义模型
class BasicBlock(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
# TODO: 应用 batch normalization 和 dropout
self.block = nn.Sequential(nn.Linear(input_dim, output_dim), nn.ReLU(),
nn.BatchNorm1d(output_dim), nn.Dropout(0.3))
def forward(self, x):
x = self.block(x)
return x
class Classifier(nn.Module):
def __init__(self,
input_dim,
output_dim=41,
hidden_layers=1,
hidden_dim=256):
super().__init__()
# *用于解包列表
self.fc = nn.Sequential(
BasicBlock(input_dim, hidden_dim), *[
BasicBlock(hidden_dim, hidden_dim)
for _ in range(hidden_layers)
], nn.Linear(hidden_dim, output_dim))
def forward(self, x):
x = self.fc(x)
return x
其中,BasicBlock为自定义的一个基本单元,便于Classsifier应用。
Classifier的Sequential中*[BasicBlock(hidden_dim, hidden_dim) for _ in range(hidden_layers)]利用列表生成器快速生成多个隐层,但Sequential的参数不是列表,所以用*进行解包。
一些工具函数
def load_feat(path):
feat = torch.load(path)
return feat
def shift(x, n):
if n < 0:
left = x[0].repeat(-n, 1)
right = x[:n]
elif n > 0:
right = x[-1].repeat(n, 1)
left = x[n:]
else:
return x
return torch.cat((left, right), dim=0)
def concat_feat(x, concat_n):
'''
concat_n: 连接帧数
'''
assert concat_n % 2 == 1 # n必须为奇数
if concat_n < 2:
return x
seq_len, feature_dim = x.size(0), x.size(1)
x = x.repeat(1, concat_n)
x = x.view(seq_len, concat_n,
feature_dim).permute(1, 0, 2) # concat_n, seq_len, feature_dim
mid = (concat_n // 2)
for r_idx in range(1, mid + 1):
x[mid + r_idx, :] = shift(x[mid + r_idx], r_idx)
x[mid - r_idx, :] = shift(x[mid - r_idx], -r_idx)
return x.permute(1, 0, 2).view(seq_len, concat_n * feature_dim)
def preprocess_data(split,
feat_dir,
phone_path,
concat_nframes,
train_ratio=0.8,
random_seed=1213):
'''
split:用于区分训练集、验证集、预测集
concat_nframes: 连接帧数
'''
class_num = 41 # NOTE: pre-computed, should not need change
if split == 'train' or split == 'val':
mode = 'train'
elif split == 'test':
mode = 'test'
else:
raise ValueError(
'Invalid \'split\' argument for dataset: PhoneDataset!')
label_dict = {}
if mode == 'train':
for line in open(os.path.join(phone_path,
f'train_labels.txt')).readlines():
line = line.strip('\n').split(' ')
label_dict[line[0]] = [int(p) for p in line[1:]]
# 划分训练集和验证集
usage_list = open(os.path.join(phone_path,
'train_split.txt')).readlines()
random.seed(random_seed) # 设置种子
random.shuffle(usage_list) # 打乱
train_len = int(len(usage_list) * train_ratio) #训练集大小
# 如果为训练集就分割前面的,反之则为验证集,分割后面的
usage_list = usage_list[:train_len] if split == 'train' else usage_list[
train_len:]
elif mode == 'test':
usage_list = open(os.path.join(phone_path,
'test_split.txt')).readlines()
usage_list = [line.strip('\n') for line in usage_list]
print('[Dataset] - # phone classes: ' + str(class_num) +
', number of utterances for ' + split + ': ' + str(len(usage_list)))
max_len = 3000000
X = torch.empty(max_len, 39 * concat_nframes)
if mode == 'train':
y = torch.empty(max_len, dtype=torch.long)
idx = 0
for i, fname in tqdm(enumerate(usage_list)):
feat = load_feat(os.path.join(feat_dir, mode, f'{fname}.pt'))
cur_len = len(feat)
feat = concat_feat(feat, concat_nframes)
if mode == 'train':
label = torch.LongTensor(label_dict[fname])
X[idx:idx + cur_len, :] = feat
if mode == 'train':
y[idx:idx + cur_len] = label
idx += cur_len
X = X[:idx, :]
if mode == 'train':
y = y[:idx]
print(f'[INFO] {split} set')
print(X.shape)
if mode == 'train':
print(y.shape)
return X, y
else:
return X
超参数
# 数据参数
concat_nframes = 17 # 连接帧数n必须为奇数(总共2k+1=n帧)
train_ratio = 0.9 # 用于训练的数据比例,其余将用于验证
# 训练参数
seed = 1213 # 随机数种子
batch_size = 512 # 分组大小
num_epoch = 50 # 训练轮数
learning_rate = 1e-3 # 学习率
model_path = './model.ckpt' # 模型保存的路径
# 模型参数
input_dim = 39 * concat_nframes # 模型输入维度
hidden_layers = 15 # 隐层层数
hidden_dim = 2048 # 隐层维度
读取数据
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f'DEVICE: {device}')
# 预处理数据
train_X, train_y = preprocess_data(split='train',
feat_dir='./feat',
phone_path='./',
concat_nframes=concat_nframes,
train_ratio=train_ratio,
random_seed=seed)
val_X, val_y = preprocess_data(split='val',
feat_dir='./feat',
phone_path='./',
concat_nframes=concat_nframes,
train_ratio=train_ratio,
random_seed=seed)
# 获取数据集
train_set = LibriDataset(train_X, train_y)
val_set = LibriDataset(val_X, val_y)
# 移除原始数据以节省内存
del train_X, train_y, val_X, val_y
gc.collect()
gc.collect()用于垃圾回收:对已经销毁的对象(这就是前一行del 的原因),Python不会自动释放其占据的内存空间。为了能够充分地利用分配的内存,避免程序跑到一半停止,要时不时地进行内存回收。
垃圾回收开始的时候当前所有线程都将被挂起,开始收集托管堆上的垃圾,收集完了还要压缩内存,然后等待垃圾回收结束以后再恢复这些线程,从这个角度来说,还是少调用垃圾回收,但是不是不能调,要视情况而定。
创建模型
# 获取数据加载器
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
# 创建模型,定义损失函数和优化器
model = Classifier(input_dim=input_dim,
hidden_layers=hidden_layers,
hidden_dim=hidden_dim).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
训练
best_acc = 0.0 # 最高准确率
for epoch in range(num_epoch):
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
# 训练
model.train() # 将模型设置为训练模式
for i, batch in enumerate(tqdm(train_loader)):
features, labels = batch
features = features.to(device)
labels = labels.to(device)
optimizer.zero_grad() # 梯度清零
outputs = model(features) # 获取模型输出
loss = criterion(outputs, labels) # 计算偏差
loss.backward() # 反向传播
optimizer.step() # 更新参数
_, train_pred = torch.max(outputs, 1) # 获取具有最高概率的类别索引
train_acc += (train_pred.detach() == labels.detach()).sum().item()
train_loss += loss.item()
# 验证
model.eval() # 将模型设置为评估模式
with torch.no_grad():
for i, batch in enumerate(tqdm(val_loader)):
features, labels = batch
features = features.to(device)
labels = labels.to(device)
outputs = model(features)
loss = criterion(outputs, labels)
_, val_pred = torch.max(outputs, 1)
val_acc += (
val_pred.cpu() == labels.cpu()).sum().item() # 获取具有最高概率的类别索引
val_loss += loss.item()
print(
f'[{epoch+1:03d}/{num_epoch:03d}] Train Acc: {train_acc/len(train_set):3.5f} Loss: {train_loss/len(train_loader):3.5f} | Val Acc: {val_acc/len(val_set):3.5f} loss: {val_loss/len(val_loader):3.5f}'
)
# 如果模型有改进,在此时保存一个检查点
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), model_path)
print(f'saving model with acc {best_acc/len(val_set):.5f}')
del train_set, val_set
del train_loader, val_loader
gc.collect()
预测
# 加载预测数据
test_X = preprocess_data(split='test',
feat_dir='./feat',
phone_path='./',
concat_nframes=concat_nframes)
test_set = LibriDataset(test_X, None)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
# 加载模型
model = Classifier(input_dim=input_dim,
hidden_layers=hidden_layers,
hidden_dim=hidden_dim).to(device)
model.load_state_dict(torch.load(model_path))
# 存储预测结果
pred = np.array([], dtype=np.int32)
# 预测
model.eval()
with torch.no_grad():
for i, batch in enumerate(tqdm(test_loader)):
features = batch
features = features.to(device)
outputs = model(features)
_, test_pred = torch.max(outputs, 1) # 获取具有最高概率的类别索引
pred = np.concatenate((pred, test_pred.cpu().numpy()), axis=0)
# 将预测结果写入CSV文件
with open('prediction.csv', 'w') as f:
f.write('Id,Class\n')
for i, y in enumerate(pred):
f.write('{},{}\n'.format(i, y))
运行结果
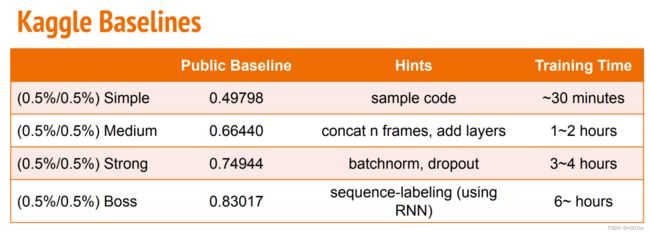
参数量上来之后自己的电脑很难跑得动了,基本就是colab+Kaggle跑
