字符串函数(二)—— 长度受限制的字符串函数

✨博客主页:小钱编程成长记
博客专栏:进阶C语言
相关博文:字符串函数(一)
字符串函数(二)—— 长度受限制的字符串函数
- 3.长度受限制的字符串函数
-
- 3.1 strncpy(指定操作长度的拷贝字符串)
- 3.2 strncat(指定操作长度的字符串追加)
- 3.3 strncmp(指定操作长度的字符串比较)
- 3.4 strstr(查找子字符串 / 在字符串中找字符串)
- 3.5 strtok(字符串切割 / 分隔)
- 3.6 strerror(翻译错误码)
- 总结
3.长度受限制的字符串函数
要指定操作长度,思考的更多,相对更安全
3.1 strncpy(指定操作长度的拷贝字符串)
具体介绍链接
char * strncpy ( char * destination, const char * source, size_t num );
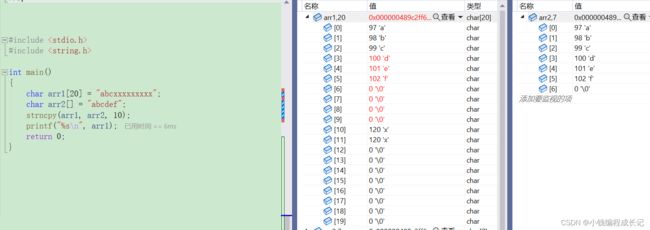
注:将源字符串的第一个字符拷贝到目标字符串。如果在拷贝完 num 个字符之前找到源 C
字符串的末尾(由’\0’表示),则目标将填充0,直到总共写入 num 个字符为止。
-
从源字符串拷贝num个字符到目标空间。
-
如果源字符串的长度小于num,则拷贝完源字符串之后,在目标的后边追加0,直到num个。
-
源字符串(字符数组) 不需要一定以’\0’结束。(因为操作数不同,新的目标字符串末尾会自动补充’\0’)。
-
目标空间必须足够大,以确保能存放源字符串。(否则会报错)
-
目标空间必须可变。(因为要把另一个字符串拷贝到这里)
-
返回值是目标空间的起始地址,然后通过%s来打印,%s是从给的地址开始 *解引用打印,遇到’\0’结束。
-
学会模拟实现。
模拟实现strncpy :
//模拟strncpy
#include 
3.2 strncat(指定操作长度的字符串追加)
具体介绍链接
char * strncat ( char * destination, const char * source, size_t num );
-
从目标空间的第一个 ‘\0’ 开始('\0’被覆盖),追加规定的字符个数,追加完后还会在后面补充一个 ‘\0’ ,这样才构成了一个完整的字符串。

-
如果指定追加的字符个数 > 源字符串的字符个数,则在实际追加时只追加现有源字符串 ‘\0’ 之前的全部内容。

-
源字符串(字符数组) 不需要一定以’\0’结束。(因为操作数不同,新的目标字符串末尾会自动补充’\0’)。

-
目标空间必须要有’\0’,保证能找到目标空间的末尾,进行追加。(编译器认为从左到右第一个’\0’是字符串的末尾)
-
目标空间必须有足够的大,能容纳下源字符串的内容。
-
目标空间必须可修改。
-
strncat返回的是目标空间的起始地址。
-
学会模拟实现。
模拟实现strncpy :
//模拟实现strncat
#include 3.3 strncmp(指定操作长度的字符串比较)
具体介绍链接
int strncmp ( const char * str1, const char * str2, size_t num );
C语言标准规定:
- 此函数开始比较每个字符串的第一个字符,如果它们相等,则继续向下比较,直到字符不同 或 达到终止空字符(‘\0’) 或 拷贝完num个字符 停止。
- 比较的不是长度,而是对应位置上字符的大小(ASCII码,因为字符在内存中是以ASCII码的形式存储的)
| 返回值(整型) | 解释 |
|---|---|
| 大于 0 | 第一个字符串大于第二个字符串 |
| 0 | 第一个字符串等于第二个字符串 |
| 小于 0 | 第一个字符串小于第二个字符串 |
不同的编译器具体返回的值不同
3.4 strstr(查找子字符串 / 在字符串中找字符串)
具体介绍链接
const char * strstr(const char *str1, const char *str2);
在str1中查找str2,strstr会返回str1中str2第一次出现的位置的第一个字符的地址;如果str1中没str2,则返回NULL(空指针)。
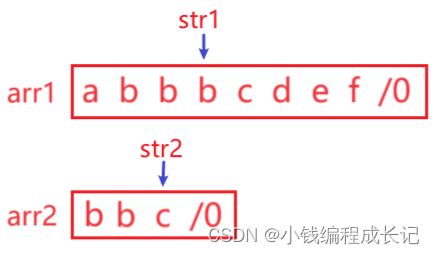
若在arr1上用str1遍历,如图第二次遍历时没找到子字符串,那就需要从第3个字符处再遍历,但是唯一的一个指针被我们用来遍历了,我们现在连首字符都不知道在哪了,所以我们要提前保留初始指针,创建一个专门用来对比遍历的指针,arr2也是一样。在arr1中也可以再创建个指针用来指向每次遍历的第一个字符,将初始指针保存起来,在遇到复杂问题时会更加方便,更加得心应手。
因此:
当出现需要多个指针、指针需要移动等比较复杂的情况时,原始的指针最好不要移动或改变。
第一次遍历时,a与b不相同,第二次遍历从a后面一个字符再开始遍历。

b和c不同,
开始第三次遍历:

当s2指向’\0’时,说明在arr1中能找到arr2,查找结束。
//模拟实现strstr
#include 这种模拟实现是一种暴力求解,算法不够高效,后期会用KMP算法实现,更高效。
3.5 strtok(字符串切割 / 分隔)
具体介绍链接
char * strtok(char *str, const char *sep);
strtok是个有点奇怪的函数,它和之前见过的函数都不一样。 是用来拆分字符串的,比如:

-
参数sep是个字符串,定义了用作分隔符的字符集合。分隔符在字符串中的顺序无所谓。
-
第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或多个分隔符分割的标记。
-
strtok找到str中的下一个标记,并将其用 \0 结尾(替换掉原来的分隔符),返回一个指向这个标记首字符的指针。若下一个标记的结尾是\0,则也返回这个标记的首字符地址。
( 注:strtok函数会改变被操作的字符串,所以使用strtok函数切分的字符串一般都是临时拷贝的并且可修改的。)

-
若strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置 或者说是保存这个标记末尾 \0 的位置。
-
若strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。(有记忆功能(static))
-
如果字符串中不存在更多的标记或查找到了 \0,则返回 NULL 指针。
//strtok
#include 在未来真正使用这个函数时,并不是这样使用的,应该是这样:
//strtok函数的正确使用方式1:
#include 若出现两个分隔符连在一起了,则第二个分隔符直接被跳过,如图:

3.6 strerror(翻译错误码)
具体介绍链接
char * strerror ( int errnum );
注:将错误码翻译成错误信息,返回错误信息的字符串的起始地址。
(只能将C语言标准库中的错误码翻译成错误信息)
C语言中使用库函数的时候,如果发生错误,就会将错误码放在errno的变量中;errno是个全局的变量,可直接使用,需要头文件errno.h。
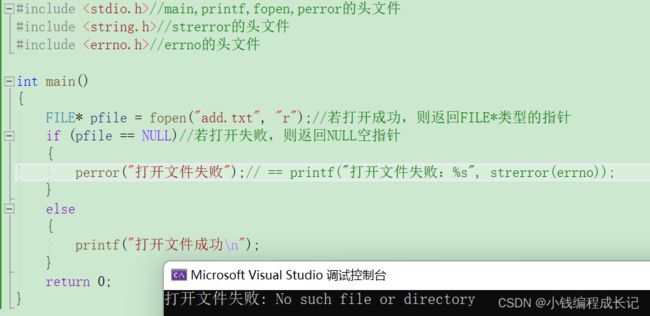
》打开文件的例子:
fopen以读的形式打开文件(头文件stdio.h),
如果文件存在,则打开成功;
如果文件不存在,则打开失败;
//strerror
#include 
若在此源文件所在的文件夹中有add.txt这个文件,则打开文件成功,否则失败。

补充小知识:
perror可直接打印错误码所对应的错误信息。
perror == printf + strerror
总结
我们一起学习了长度受限制的字符串函数。
感谢大家的阅读,大家一起进步!
点赞收藏加关注,C语言学习不迷路!
