项目中使用Quartz集群分享--http://hot66hot.iteye.com/blog/1726143
- 博客分类:
- Quartz
Quartz spring java thread
在公司分享了Quartz,发布出来,希望大家讨论补充.
CRM使用Quartz集群分享
一:CRM对定时任务的依赖与问题
二:什么是quartz,如何使用,集群,优化
三:CRM中quartz与Spring结合使用
1:CRM对定时任务的依赖与问题
1)依赖
(1)每天晚上的定时任务,通过sql脚本 + crontab方式执行
存在的问题:当需要跨库或许数据的,sql无能为力,引入许多中间表,完成复杂统计需求。大范围对线上热表扫描,造成锁表,延迟严重
(2)使用python(多数据源) + SQL的方式
存在的问题:直接访问数据,需要理解各系统的数据结构,无法满足动态任务问题,各系统业务接口没有重用
(3)使用spring + JDK timer方式调用接口完成定时任务
使用写死服务器Host(srv23)的方式,控制只在一台服务器上执行task
//对于srv23的重启,保存在内存中的任务将丢失,每次重启srv23重新生成定时任务
存在的问题:实现步骤复杂,分散,任务调度不能恢复,严重依赖于srv23,回调URL时可能失败等情况。
CRM定时任务走过了很多弯路:
定时任务多种实现方式,使配置和代码分散在多处,难以维护和监控
任务执行过程没有保证,没有错误恢复
任务执行异常没有反馈(邮件)
没有集群支持
CRM需要分布式的任务调度框架,统一解决问题.
JAVA可以使用的任务调度框架:Quartz , Jcrontab , cron4j , taobao-pamirs-schedule
为什么选择Quartz:
1)资历够老,创立于1998年,比struts1还早,但是一直在更新(27 April 2012: Quartz 2.1.5 Released),文档齐全.
2)完全由Java写成,设计用于J2SE和J2EE应用.方便集成:JVM,RMI.
3)设计清晰简单:核心概念scheduler,trigger,job,jobDetail,listener,calendar
4)支持集群:org.quartz.jobStore.isClustered
5)支持任务恢复:requestsRecovery
从http://www.quartz-scheduler.org 获取最新Quartz
1)学习Quartz

图1 介绍了quartz关键的组件和简单流程
(1)Quartz 的目录结构和内容
docs/api Quartz 框架的JavaDoc Api 说明文档
docs/dbTables 创建 Quartz 的数据库对象的脚本
docs/wikidocs Quartz 的帮助文件,点击 index.html 开始查看
Examples 多方面使用 Quartz 的例子Lib Quartz 使用到的第三方包
src/java/org/quartz 使用 Quartz 的客户端程序源代码,公有 API
src/java/org/quartz/core 使用 Quartz 的服务端程序源代码,私有 API
src/java/org/quartz/simpl Quartz 提供的不衣赖于第三方产品的简单实现
src/java/org/quartz/impl 依赖于第三方产品的支持模块的实现
src/java/org/quartz/utils 整个框架要用到的辅助类和工具组件
src/jboss 提供了特定于 JBoss 特性的源代码
src/oracle 提供了特定于 Oracle 特性的源代码
src/weblogic 提供了特定于 WebLogic 特性的源代码
Quartz 框架包含许多的类和接口,它们分布在大概 11 个包中。多数所要使用到的类或接口放置在 org.quartz 包中。这个包含盖了 Quartz 框架的公有 API.
(2)Quartz核心接口 Scheduler

图2
Scheduler 是 Quartz 的主要 API。与Quartz大部分交互是发生于 Scheduler 之上的。客服端与Scheduler 交互是通过org.quartz.Scheduler接口。
Scheduler的实现:对方法调用会传递到 QuartzScheduler 实例上。QuartzScheduler 对于客户端是不可见的,并且也不存在与此实例的直接交互。
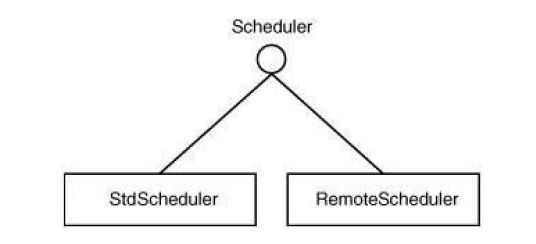
图3
创建Scheduler
Quartz 框架提供了 org.quartz.SchedulerFactory 接口。
SchedulerFactory 实例就是用来产生 Scheduler 实例的。当 Scheduler 实例被创建之后,就会存到一个仓库中(org.quartz.impl.SchedulerRepository).
Scheduler 工厂分别是 org.quartz.impl.DirectSchedulerFactory 和 org.quartz.impl.StdSchedulerFactory
DirectSchedulerFactory 是为精细化控制 Scheduler 实例产生的工厂类,一般不用,不过有利于理解quartz内部组件。
org.quartz.impl.StdSchedulerFactory 依赖于属性类(Properties)决定如何生产 Scheduler 实例
通过加载属性文件,Properties 提供启动参数:
调用静态方法 getDefaultScheduler() 方法中调用了空的构造方法。如果之前未调用过任何一个 initialize() 方法,那么无参的initialize() 方法会被调用。这会开始去按照下面说的顺序加载文件。
默认情况下,quartz.properties 会被定位到,并从中加载属性。
properties加载顺序:
1. 检查 System.getProperty("org.quartz.properties") 中是否设置了别的文件名
2. 否则,使用 quartz.properties 作为要加载的文件名
3. 试图从当前工作目录中加载这个文件
4. 试图从系统 classpath 下加载这个文件
在 Quartz Jar 包中有一个默认的 quartz.properties 文件
默认配置如下
# Default Properties file for use by StdSchedulerFactory
# to create a Quartz Scheduler Instance, if a different
# properties file is not explicitly specified.
org.quartz.scheduler.instanceName = DefaultQuartzScheduler
org.quartz.scheduler.rmi.export = false
org.quartz.scheduler.rmi.proxy = false
org.quartz.scheduler.wrapJobExecutionInUserTransaction = false
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount = 10
org.quartz.threadPool.threadPriority = 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true
org.quartz.jobStore.misfireThreshold = 60000
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
到此创建Scheduler完成
通过Scheduler理解Quartz
Scheduler 的 API 可以分组成以下三个类别:
·管理 Scheduler
(1)启动 Scheduler
start() 方法被调用,Scheduler 就开始搜寻需要执行的 Job。在你刚得到一个 Scheduler 新的实例时,或者 Scheduler
被设置为 standby 模式后,你才可以调用 start() 方法。
只要调用了 shutdown() 方法之后,你就不能再调用 Scheduler 实例的 start() 方法了。
这是因为 shutdown() 方法销毁了为 Scheduler 创建的所有的资源(线程,数据库连接等)。
你可能需要Standby 模式:设置 Scheduler 为 standby 模式会导致 Scheduler搜寻要执行的 Job 的线程被暂停下来
停止 Scheduler
其它管理Scheduler 方法见API...
管理 Job
什么是 Quartz Job?
一个Quart Job就是一个任何一个继承job或job子接口的Java类,你可以用这个类做任何事情!
org.quartz.Job 接口
当 Scheduler 调用一个 Job,一个 JobexecutionContext 传递给 execute() 方法。JobExecutionContext 对象让 Job 能
访问 Quartz 运行时候环境和 Job 本身的数据。类似于在 Java Web 应用中的 servlet 访问 ServletContext 。
通过 JobExecutionContext,Job 可访问到所处环境的所有信息,包括注册到 Scheduler 上与该 Job 相关联的 JobDetail 和 Trigger。
JobDetail
部署在 Scheduler 上的每一个 Job 只创建了一个 JobDetail实例。JobDetail 是作为 Job 实例进行定义的
// Create the JobDetail
JobDetail jobDetail = new JobDetail("PrintInfoJob",Scheduler.DEFAULT_GROUP, PrintInfoJob.class);
// Create a trigger that fires now and repeats forever
Trigger trigger = TriggerUtils.makeImmediateTrigger(
SimpleTrigger.REPEAT_INDEFINITELY, 10000);
trigger.setName("PrintInfoJobTrigger");// register with the Scheduler
scheduler.scheduleJob(jobDetail, trigger);
JobDetail 被加到 Scheduler 中了,而不是 job。Job 类是作为 JobDetail 的一部份,job直到Scheduler准备要执行它的时候才会被实例化的,因此job不存在线成安全性问题.
使用 JobDataMap 对象设定 Job 状态
在Quartz 1.5之后,JobDataMap在 Trigger 级也是可用的。它的用途类似于Job级的JobDataMap,支持在同一个JobDetail上的多个Trigger。
伴随着加入到 Quartz 1.5 中的这一增强特性,可以使用 JobExecutionContext 的一个新的更方便的方法获取到 Job 和 Trigger 级的并集的 map 中的值。
这个方法就是getMergedJobDataMap() 取job 和 Trigger级的并集map,它能够在 Job 中使用。管法推荐使用这个方法.
* 实际使用中trigger级别有时取不到map中的值, 使用getMergedJobDataMap 可以获取到(官方推荐此方法).
有状态的Job: org.quartz.StatefulJob 接口
当需要在两次 Job 执行间维护状态,使用StatefulJob 接口.
Job 和 StatefulJob 在框架中使用中存在两个关键差异。
(一) JobDataMap 在每次执行之后重新持久化到 JobStore 中。这样就确保你对 Job 数据的改变直到下次执行仍然保持着。
(二) 两个或多个有状态的 JobDetail 实例不能并发执行。保证JobDataMap线程安全
注意:实际使用时使用jobStoreTX/jobStoreCMT ,StatefulJob,大量的trigger对应一个JobDetail的情况下Mysql会产生锁超时问题.
中断 Job
Quartz 包括一个接口叫做 org.quartz.InterruptableJob,它扩展了普通的 Job 接口并提供了一个 interrupt() 方法:
没有深入研究,只知道 Scheduler会调用自定义的Job的 interrupt()方法。由用户决定 Job 决定如何中断.没有测试!!!
job的特性
易失性 volatility
一个易失性的 Job 是在程序关闭之后不会被持久化。一个 Job 是通过调用 JobDetail 的 setVolatility(true)被设置为易失.
Job易失性的默认值是 false.
注意:只有采用持久性JobStore时才有效
Job 持久性 durability
设置JobDetail 的 setDurability(false),在所有的触发器触发之后JobDetail将从 JobStore 中移出。
Job持久性默认值是false.
Scheduler将移除没有trigger关联的jobDetail
Job 可恢复性 shuldRecover
当一个Job在执行中,Scheduler非正常的关闭,设置JobDetail 的setRequestsRecovery(true) 在 Scheduler 重启之后可恢复的Job还会再次被执行。这个
Job 会重新开始执行。注意job代码事务特性.
Job可恢复性默认为false,Scheduler不会试着去恢复job操作。

图为表述没有执行完成的job数据库记录
Scheduler 中移除 Job
移除所有与这个 Job 相关联的 Trigger;如果这个 Job 是非持久性的,它将会从 Scheduler 中移出。
更直接的方式是使用 deleteJob() 方法,它还会删除所有与当前job关联的trigger
public boolean deleteJob(String jobName, String groupName) throws SchedulerException;
quartz 本身提供的 Job
org.quartz.jobs.FileScanJob 检查某个指定文件是否变化,并在文件被改变时通知到相应监听器的 Job
org.quartz.jobs.FileScanListener 在文件被修改后通知 FileScanJob 的监听器
org.quartz.jobs.NativeJob 用来执行本地程序(如 windows 下 .exe 文件) 的 Job
org.quartz.jobs.NoOpJob 什么也不做,但用来测试监听器不是很有用的。一些用户甚至仅仅用它来导致一个监听器的运行
org.quartz.jobs.ee.mail.SendMailJob 使用 JavaMail API 发送 e-mail 的 Job
org.quartz.jobs.ee.jmx.JMXInvokerJob 调用 JMX bean 上的方法的 Job
org.quartz.jobs.ee.ejb.EJBInvokerJob 用来调用 EJB 上方法的 Job
job的理解到此结束
理解quartz Trigger
Job 包含了要执行任务的逻辑,但是Job不负责何时执行。这个事情由触发器(Trigger)负责。
Quartz Trigger继承了抽象的org.quartz.Trigger 类。
目前,Quartz 有三个可用的实现
org.quartz.SimpleTrigger
org.quartz.CronTrigger
org.quartz.NthIncludeDayTrigger
使用org.quartz.SimpleTrigger
SimpleTrigger 是设置和使用是最为简单的一种 Quartz Trigger。它是为那种需要在特定的日期/时间启动,且以一个可能的间隔时间重复执行 n 次的 Job 所设计的。
SimpleTrigger 存在几个变种的构造方法。他们是从无参的版本一直到带全部参数的版本。
下面代码版断显示了一个仅带有trigger 的名字和组的简单构造方法
SimpleTrigger sTrigger = new SimpleTrigger("myTrigger", Scheduler.DEFAULT_GROUP);
这个 Trigger 会立即执行,而不重复。还有一个构造方法带有多个参数,配置 Triiger 在某一特定时刻触发,重复执行多次,和两
次触发间的延迟时间。
使用org.quartz.CronTrigger
CronTrigger 是基于 Unix 类似于 cron 的表达式触发,也是功能最强大和最常用的Trigger
Cron表达式:
使用 org.quartz.NthIncludedDayTrigger
org.quartz.NthIncludedDayTrigger是设计用于在每一间隔类型的第几天执行 Job。
例如,你要在每个月的 12 号执行发工资提醒的Job。接下来的代码片断描绘了如何创建一个 NthIncludedDayTrigger.
jobDetail + trigger组成最基本的定时任务:
特别注意:一个job可以对应多个Trgger , 一个Trigger只能对应一个job .
如:CRM中N天未拜访的job对应所有的N天未拜访商家(一个商家一个trigger) 大约1:1000的比例
job和trigger都是通过name 和 group 属性确定唯一性的.
Quartz Calendar
Quartz 的 Calendar 对象与 Java API 的 java.util.Calendar不同。
Java 的 Calender 对象是通用的日期和时间工具;
Quartz 的 Calender 专门用于屏闭一个时间区间,使 Trigger 在这个区间中不被触发。
例如,让我们假如取消节假日执行job。
Quartz包括许多的 Calender 实现足以满足大部分的需求.
org.quartz.impl.calendar.BaseCalender 为高级的 Calender 实现了基本的功能,实现了 org.quartz.Calender 接口
org.quartz.impl.calendar.WeeklyCalendar 排除星期中的一天或多天,例如,可用于排除周末
org.quartz.impl.calendar.MonthlyCalendar 排除月份中的数天,例如,可用于排除每月的最后一天
org.quartz.impl.calendar.AnnualCalendar 排除年中一天或多天
org.quartz.impl.calendar.HolidayCalendar 特别的用于从 Trigger 中排除节假日
使用Calendar,只需实例化后并加入你要排除的日期,然后用 Scheduler 注册,最后必须让Calender依附于Trigger实例。
排除国庆节实例
Quartz 监听器
Quartz 提供了三种类型的监听器:监听Job,监听Trigger,和监听Scheduler.
监听器是作为扩展点存在的.
Quartz 监听器是扩展点,可以扩展框架并定制来做特定的事情。跟Spring,Hibernate,Servlet监听器类似.
实现监听
1. 创建一个 Java 类,实现监听器接口
2. 用你的应用中特定的逻辑实现监听器接口的所有方法
3. 注册监听器
全局和非全局监听器
JobListener 和 TriggerListener 可被注册为全局或非全局监听器。一个全局监听器能接收到所有的 Job/Trigger 的事件通知。
而一个非全局监听器只能接收到那些在其上已注册了监听器的 Job 或 Triiger 的事件。
作者:James House描述全局和非全局监听器
全局监听器是主动意识的,它们为了执行它们的任务而热切的去寻找每一个可能的事件。通常,全局监听器要做的工作不用指定到特定的 Job 或 Trigger。
非全局监听器一般是被动意识的,它们在所关注的 Trigger 激发之前或是 Job 执行之前什么事也不做。因此,非全局的监听器比起全局监听器而言更适合于修改或增加 Job 执行的工作。
类似装饰设计模式
监听 Job 事件
org.quartz.JobListener 接口包含一系列的方法,它们会由 Job 在其生命周期中产生的某些关键事件时被调用

图7 job listener参与job的执行生命周期
注册全局监听器
注册非全局监听器(依次完成,顺序不能颠倒)
监听 Trigger 事件
org.quartz.TriggerListener 接口定义Trigger监听器
triggerListener的注册与jobListener相同
监听 Scheduler 事件
org.quartz.SchedulerListener 接口定义Trigger监听器
注册SchedulerListener(SchedulerListener不存在全局非全局性)
scheduler.addSchedulerListener(schedulerListener);
由于scheduler异常存在不打印问题,CRM使用监听器代码打印.
quartz与线程
主处理线程:QuartzSchedulerThread
启动Scheduler时。QuartzScheduler被创建并创建一个org.quartz.core.QuartzSchedulerThread 类的实例。
QuartzSchedulerThread 包含有决定何时下一个Job将被触发的处理循环。QuartzSchedulerThread 是一个 Java 线程。它作为一个非守护线程运行在正常优先级下。
QuartzSchedulerThread 的主处理轮循步骤:
1. 当 Scheduler 正在运行时:
A. 检查是否有转换为 standby 模式的请求。
1. 假如 standby 方法被调用,等待继续的信号
B. 询问 JobStore 下次要被触发的 Trigger.
1. 如果没有 Trigger 待触发,等候一小段时间后再次检查
2. 假如有一个可用的 Trigger,等待触发它的确切时间的到来
D. 时间到了,为 Trigger 获取到 triggerFiredBundle.
E. 使用Scheduler和triggerFiredBundle 为 Job 创建一个JobRunShell实例
F. 在ThreadPool 申请一个线程运行 JobRunShell 实例.
代码逻辑在QuartzSchedulerThread 的 run() 中,如下:
quartz工作者线程
Quartz 不会在主线程(QuartzSchedulerThread)中处理用户的Job。Quartz 把线程管理的职责委托给ThreadPool。
一般的设置使用org.quartz.simpl.SimpleThreadPool。SimpleThreadPool 创建了一定数量的 WorkerThread 实例来使得Job能够在线程中进行处理。
WorkerThread 是定义在 SimpleThreadPool 类中的内部类,它实质上就是一个线程。
要创建 WorkerThread 的数量以及配置他们的优先级是在文件quartz.properties中并传入工厂。
spring properties
主线程(QuartzSchedulerThread)请求ThreadPool去运行 JobRunShell 实例,ThreadPool 就检查看是否有一个可用的工作者线
程。假如所以已配置的工作者线程都是忙的,ThreadPool 就等待直到有一个变为可用。当一个工作者线程是可用的,
并且有一个JobRunShell 等待执行,工作者线程就会调用 JobRunShell 类的 run() 方法。
Quartz 框架允许替换线程池,但必须实现org.quartz.spi.ThreadPool 接口.

图4 quartz内部的主线程和工作者线程
Quartz的存储和持久化
Quartz 用 JobStores 对 Job、Trigger、calendar 和 Schduler 数据提供一种存储机制。Scheduler 应用已配置的JobStore 来存储和获取到部署信息,并决定正被触发执行的 Job 的职责。
所有的关于哪个 Job 要执行和以什么时间表来执行他们的信息都来存储在 JobStore。
在 Quartz 中两种可用的 Job 存储类型是:
内存(非持久化) 存储
持久化存储
JobStore 接口
Quartz 为所有类型的Job存储提供了一个接口。叫 JobStore。所有的Job存储机制,不管是在哪里或是如何存储他们的信息的,都必须实现这个接口。
JobStore 接口的 API 可归纳为下面几类:
Job 相关的 API
Trigger 相关的 API
Calendar 相关的 API
Scheduler 相关的 API
使用内存来存储 Scheduler 信息
Quartz 的内存Job存储类叫做 org.quartz.simple.RAMJobStore,它实现了JobStore 接口的。
RAMJobStore 是 Quartz 的默认的解决方案。
使用这种内存JobStore的好处。
RAMJobStore是配置最简单的 JobStore:默认已经配置好了。见quartz.jar:org.quartz.quartz.properties
RAMJobStore的速度非常快。所有的 quartz存储操作都在计算机内存中
使用持久性的 JobStore
持久性 JobStore = JDBC + 关系型数据库
Quartz 所有的持久化的 JobStore 都扩展自 org.quartz.impl.jdbcjobstore.JobStoreSupport 类。

图5
JobStoreSupport 实现了 JobStore 接口,是作为 Quartz 提供的两个具体的持久性 JobStore 类的基类。
Quartz 提供了两种不同类型的JobStoreSupport实现类,每一个设计为针对特定的数据库环境和配置:
·org.quartz.impl.jdbcjobstore.JobStoreTX
·org.quartz.impl.jdbcjobstore.JobStoreCMT
独立环境中的持久性存储
JobStoreTX 类设计为用于独立环境中。这里的 "独立",我们是指这样一个环境,在其中不存在与应用容器的事务集成。
#properties配置
org.quartz.jobStore.class = org.quartz.ompl.jdbcjobstore.JobStoreTX
依赖容器相关的持久性存储
JobStoreCMT 类设计为与程序容器事务集成,容器管理的事物(Container Managed Transactions (CMT))
crm使用JobStoreTX 因为quart有长时间锁等待情况,不参与系统本身事务(crm任务内事务与quartz本身事务分离).
Quartz 数据库结构
表名描述
QRTZ_CALENDARS 以 Blob 类型存储 Quartz 的 Calendar 信息
QRTZ_CRON_TRIGGERS 存储 Cron Trigger,包括 Cron 表达式和时区信息
QRTZ_FIRED_TRIGGERS 存储与已触发的 Trigger 相关的状态信息,以及相联 Job 的执行信息
QRTZ_PAUSED_TRIGGER_GRPS 存储已暂停的 Trigger 组的信息
QRTZ_SCHEDULER_STATE 存储少量的有关 Scheduler 的状态信息,和别的 Scheduler 实例(假如是用于一个集群中)
QRTZ_LOCKS 存储程序的非观锁的信息(假如使用了悲观锁)
QRTZ_JOB_DETAILS 存储每一个已配置的 Job 的详细信息
QRTZ_JOB_LISTENERS 存储有关已配置的 JobListener 的信息
QRTZ_SIMPLE_TRIGGERS 存储简单的 Trigger,包括重复次数,间隔,以及已触的次数
QRTZ_BLOG_TRIGGERS Trigger 作为 Blob 类型存储(用于 Quartz 用户用 JDBC 创建他们自己定制的 Trigger 类型,JobStore 并不知道如何存储实例的时候)
QRTZ_TRIGGER_LISTENERS 存储已配置的 TriggerListener 的信息
QRTZ_TRIGGERS 存储已配置的 Trigger 的信息
所有的表默认以前缀QRTZ_开始。可以通过在 quartz.properties配置修改(org.quartz.jobStore.tablePrefix = QRTZ_)。
可以对不同的Scheduler实例使用多套的表,通过改变前缀来实现。
优化 quartz数据表结构
-- 1:对关键查询路径字段建立索引
-- 2:根据Mysql innodb表结构特性,调整主键,降低二级索引的大小
Quartz集群
只有使用持久的JobStore才能完成Quqrtz集群

图6
一个 Quartz 集群中的每个节点是一个独立的 Quartz 应用,它又管理着其他的节点。
需要分别对每个节点分别启动或停止。不像应用服务器的集群,独立的 Quartz 节点并不与另一个节点或是管理节点通信。
Quartz 应用是通过数据库表来感知到另一应用。
配置集群
org.quartz.jobStore.class 属性为 JobStoreTX,
将任务持久化到数据中。因为集群中节点依赖于数据库来传播Scheduler实例的状态,你只能在使用 JDBC JobStore 时应用 Quartz 集群。
org.quartz.jobStore.isClustered 属性为 true,通知Scheduler实例要它参与到一个集群当中。
org.quartz.jobStore.clusterCheckinInterval
属性定义了Scheduler 实例检入到数据库中的频率(单位:毫秒)。
Scheduler 检查是否其他的实例到了它们应当检入的时候未检入;
这能指出一个失败的 Scheduler 实例,且当前 Scheduler 会以此来接管任何执行失败并可恢复的 Job。
通过检入操作,Scheduler 也会更新自身的状态记录。clusterChedkinInterval 越小,Scheduler 节点检查失败的 Scheduler 实例就越频繁。默认值是 15000 (即15 秒)
集群实现分析
Quartz原来码分析:
基于数据库表锁实现多Quartz_Node 对Job,Trigger,Calendar等同步机制
通过行级别锁实现多节点处理
JobStoreTX 控制并发代码
JobStoreCMT 控制并发代码
CRM中quartz与Spring结合使用
Spring 通过提供org.springframework.scheduling.quartz下的封装类对quartz支持
但是目前存在问题
1:Spring3.0目前不支持Quartz2.x以上版本
Caused by: java.lang.IncompatibleClassChangeError: class org.springframework.scheduling.quartz.CronTriggerBean
has interface org.quartz.CronTrigger as super class
原因是 org.quartz.CronTrigger在2.0从class变成了一个interface造成IncompatibleClassChangeError错误。
解决:无解,要想使用spring和quartz结合的方式 只能使用Quartz1.x版本。
2:org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean报
java.io.NotSerializableException异常,需要自己实现QuartzJobBean。
解决:spring bug己经在http://jira.springframework.org/browse/SPR-3797找到解决方案,
作者重写了MethodInvokingJobDetailFactoryBean.
3:Spring内bean必须要实现序列化接口,否则不能通过Sprng 属性注入的方式为job提供业务对象
解决:
CRM中quartz模块部分代码
1:定义所有job的父类,并负责异常发送邮件任务和日志任务
2:抽象Quartz操作接口(实现类 toSee: QuartzServiceImpl)
3:在Spring配置job,trigger,Scheduler,Listener组件
Crm目前可以做到对Quartz实例的监控,操作.动态部署Trigger


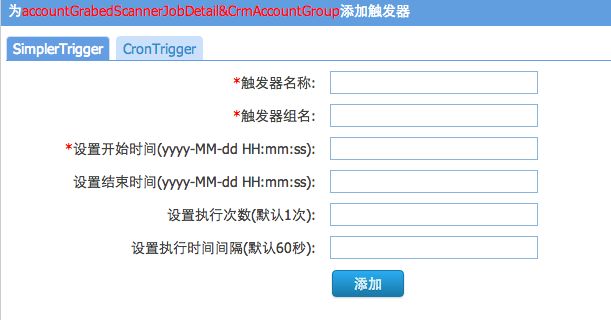
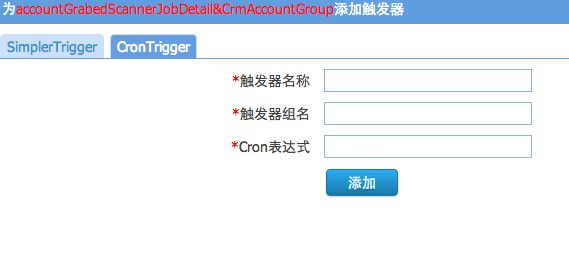
后续待开发功能和问题
1:目前实现对job,Trigger操作,动态部署Trigger,后续需要加入Calendar(排除特定日期),Listener(动态加载监控),Job的动态部署(只要bean的名称和方法名,就可完成对job生成,部署)
2:由于Quartz集群中的job目前是在任意一台server中执行,Quartz日志生成各自的系统目录中, quartz日志无法统一.
3:Quartz2.x已经支持可选节点执行job(期待Spring升级后对新Quartz支持)
4:Quartz内部的DB操作大量Trigger存在严重竞争问题,瞬间大量trigger执行,目前只能通过(org.quartz.jobStore.tablePrefix = QRTZ)分表操作,存在长时间lock_wait(新版本据说有提高);
5:如果有需要,可以抽取出Quartz,变成单独的服务,供其它系统调度使用使用
CRM使用Quartz集群分享
一:CRM对定时任务的依赖与问题
二:什么是quartz,如何使用,集群,优化
三:CRM中quartz与Spring结合使用
1:CRM对定时任务的依赖与问题
1)依赖
(1)每天晚上的定时任务,通过sql脚本 + crontab方式执行
Xml代码

- #crm
- 0 2 * * * /opt/***/javafiles/***/shell/***_daily_stat.sql
- 30 7 * * * /opt/***/javafiles/***/shell/***_data_fix
- 30 0 * * * /opt/***/javafiles/***/shell/***_sync_log
- 0 1 * * * /opt/***/javafiles/***/shell/***_clear_log
- 20 8 * * * /opt/***/javafiles/***/shell/***_daily >> /var/***/logs/***_daily.log 2>&1
- 40 1 * * * /opt/***/javafiles/***/shell/***_sync_account2
- 0 2 * * 1 /opt/***/javafiles/***/shell/***_weekly >> /var/***/logs/***_weekly.log 2>&1
存在的问题:当需要跨库或许数据的,sql无能为力,引入许多中间表,完成复杂统计需求。大范围对线上热表扫描,造成锁表,延迟严重
(2)使用python(多数据源) + SQL的方式
Python代码
- def connectCRM():
- return MySQLdb.Connection("localhost", "***", "***", "***", 3306, charset="utf8")
- def connectTemp():
- return MySQLdb.Connection("localhost", "***", "***", "***", 3306, charset="utf8")
- def connectOA():
- return MySQLdb.Connection("localhost", "***", "***", "***", 3306, charset="utf8")
- def connectCore():
- return MySQLdb.Connection("localhost", "***", "***", "***", 3306, charset="utf8")
- def connectCT():
- return MySQLdb.Connection("localhost", "***", "***", "***", 3306, charset="utf8")
存在的问题:直接访问数据,需要理解各系统的数据结构,无法满足动态任务问题,各系统业务接口没有重用
(3)使用spring + JDK timer方式调用接口完成定时任务
Xml代码
- <bean id="accountStatusTaskScanner" class="***.impl.AccountStatusTaskScanner" />
- <task:scheduler id="taskScheduler" pool-size="5" />
- <task:scheduled-tasks scheduler="taskScheduler">
- <task:scheduled ref="accountStatusTaskScanner" method="execute" cron="0 0 1 * * ?" />
- task:scheduled-tasks>
使用写死服务器Host(srv23)的方式,控制只在一台服务器上执行task
Java代码
- public abstract class SingletonServerTaskScanner implements TaskScanner {
- private final Logger logger = LoggerFactory.getLogger(SingletonServerTaskScanner.class);
- @Override
- public void execute() {
- String hostname = "";
- try {
- hostname = InetAddress.getLocalHost().getHostName();
- } catch (UnknownHostException e) {
- logger.error(e.getMessage(), e);
- }
- //判断是否为当前可执行服务器
- if (ConfigUtil.getValueByKey("core.scan.server").equals(hostname)) {
- doScan();
- }
- }
- public abstract void doScan();
- }
//对于srv23的重启,保存在内存中的任务将丢失,每次重启srv23重新生成定时任务
Java代码
- public class CrmInitializer implements InitializingBean {
- private Logger logger = LoggerFactory.getLogger(CrmInitializer.class);
- @Override
- public void afterPropertiesSet() throws Exception {
- // 扫描商家状态,创建定时任务
- logger.info("扫描商家状态,创建定时任务");
- accountStatusTaskScanner.execute();
- // 扫描N天未拜访商家,创建定时任务
- logger.info("扫描N天未拜访商家,创建定时任务");
- nDaysActivityScanner.execute();
- }
- }
Java代码
- //通过调用srv23的特定URL的方式,动态指定任务(如取消N天未拜访,私海进保护期,保护期进公海等)
- public class SingletonServerTaskController {
- @Resource
- private AccountService accountService;
- @RequestMapping(value = "/reschedule")
- public @ResponseBody
- String checkAndRescheduleAccount(Integer accountId) {
- logger.debug("reschedule task for accountId:" + accountId);
- if (isCurrentServer()) {
- accountService.checkAndRescheduleAccount(Arrays.asList(accountId));
- }
- return "ok";
- }
- private boolean isCurrentServer() {
- String hostname = "";
- try {
- hostname = InetAddress.getLocalHost().getHostName();
- } catch (UnknownHostException e) {
- logger.error(e.getMessage(), e);
- }
- if (ConfigUtil.getValueByKey("core.scan.server").equals(hostname)) {
- return true;
- } else {
- return false;
- }
- }
- }
存在的问题:实现步骤复杂,分散,任务调度不能恢复,严重依赖于srv23,回调URL时可能失败等情况。
CRM定时任务走过了很多弯路:
定时任务多种实现方式,使配置和代码分散在多处,难以维护和监控
任务执行过程没有保证,没有错误恢复
任务执行异常没有反馈(邮件)
没有集群支持
CRM需要分布式的任务调度框架,统一解决问题.
JAVA可以使用的任务调度框架:Quartz , Jcrontab , cron4j , taobao-pamirs-schedule
为什么选择Quartz:
1)资历够老,创立于1998年,比struts1还早,但是一直在更新(27 April 2012: Quartz 2.1.5 Released),文档齐全.
2)完全由Java写成,设计用于J2SE和J2EE应用.方便集成:JVM,RMI.
3)设计清晰简单:核心概念scheduler,trigger,job,jobDetail,listener,calendar
4)支持集群:org.quartz.jobStore.isClustered
5)支持任务恢复:requestsRecovery
从http://www.quartz-scheduler.org 获取最新Quartz
1)学习Quartz
图1 介绍了quartz关键的组件和简单流程
(1)Quartz 的目录结构和内容
docs/api Quartz 框架的JavaDoc Api 说明文档
docs/dbTables 创建 Quartz 的数据库对象的脚本
docs/wikidocs Quartz 的帮助文件,点击 index.html 开始查看
Examples 多方面使用 Quartz 的例子Lib Quartz 使用到的第三方包
src/java/org/quartz 使用 Quartz 的客户端程序源代码,公有 API
src/java/org/quartz/core 使用 Quartz 的服务端程序源代码,私有 API
src/java/org/quartz/simpl Quartz 提供的不衣赖于第三方产品的简单实现
src/java/org/quartz/impl 依赖于第三方产品的支持模块的实现
src/java/org/quartz/utils 整个框架要用到的辅助类和工具组件
src/jboss 提供了特定于 JBoss 特性的源代码
src/oracle 提供了特定于 Oracle 特性的源代码
src/weblogic 提供了特定于 WebLogic 特性的源代码
Quartz 框架包含许多的类和接口,它们分布在大概 11 个包中。多数所要使用到的类或接口放置在 org.quartz 包中。这个包含盖了 Quartz 框架的公有 API.
(2)Quartz核心接口 Scheduler
图2
Scheduler 是 Quartz 的主要 API。与Quartz大部分交互是发生于 Scheduler 之上的。客服端与Scheduler 交互是通过org.quartz.Scheduler接口。
Scheduler的实现:对方法调用会传递到 QuartzScheduler 实例上。QuartzScheduler 对于客户端是不可见的,并且也不存在与此实例的直接交互。
图3
创建Scheduler
Quartz 框架提供了 org.quartz.SchedulerFactory 接口。
SchedulerFactory 实例就是用来产生 Scheduler 实例的。当 Scheduler 实例被创建之后,就会存到一个仓库中(org.quartz.impl.SchedulerRepository).
Scheduler 工厂分别是 org.quartz.impl.DirectSchedulerFactory 和 org.quartz.impl.StdSchedulerFactory
DirectSchedulerFactory 是为精细化控制 Scheduler 实例产生的工厂类,一般不用,不过有利于理解quartz内部组件。
Java代码
- -- 最简单
- public void createScheduler(ThreadPool threadPool, JobStore jobStore);
- -- 最复杂
- public void createScheduler(String schedulerName, String schedulerInstanceId,ThreadPool threadPool, JobStore jobStore, String rmiRegistryHost, int rmiRegistryPort);
Java代码
- public scheduler createScheduler(){
- DirectSchedulerFactory factory=DirectSchedulerFactory.getInstance();
- try {
- //创建线程池
- SimpleThreadPool threadPool = new SimpleThreadPool(10, Thread.NORM_PRIORITY);
- threadPool.initialize();
- //创建job存储类
- JobStoreTX jdbcJobStore = new JobStoreTX();
- jdbcJobStore.setDataSource("someDatasource");
- jdbcJobStore.setPostgresStyleBlobs(true);
- jdbcJobStore.setTablePrefix("QRTZ_");
- jdbcJobStore.setInstanceId("My Instance");
- logger.info("Scheduler starting up...");
- factory.createScheduler(threadPool,jdbcJobStore);
- // Get a scheduler from the factory
- Scheduler scheduler = factory.getScheduler();
- // 必须启动scheduler
- scheduler.start();
- return scheduler;
- }
- return null;
- }
org.quartz.impl.StdSchedulerFactory 依赖于属性类(Properties)决定如何生产 Scheduler 实例
通过加载属性文件,Properties 提供启动参数:
Java代码
- public scheduler createScheduler(){
- // Create an instance of the factory
- StdSchedulerFactory factory = new StdSchedulerFactory();
- // Create the properties to configure the factory
- Properties props = new Properties();
- // required to supply threadpool class and num of threads
- props.put(StdSchedulerFactory.PROP_THREAD_POOL_CLASS,"org.quartz.simpl.SimpleThreadPool");
- props.put("org.quartz.threadPool.threadCount", "10");
- try {
- // Initialize the factory with properties
- factory.initialize(props);
- Scheduler scheduler = factory.getScheduler();
- logger.info("Scheduler starting up...");
- scheduler.start();
- } catch (SchedulerException ex) {
- logger.error(ex);
- }
- }
调用静态方法 getDefaultScheduler() 方法中调用了空的构造方法。如果之前未调用过任何一个 initialize() 方法,那么无参的initialize() 方法会被调用。这会开始去按照下面说的顺序加载文件。
默认情况下,quartz.properties 会被定位到,并从中加载属性。
properties加载顺序:
1. 检查 System.getProperty("org.quartz.properties") 中是否设置了别的文件名
2. 否则,使用 quartz.properties 作为要加载的文件名
3. 试图从当前工作目录中加载这个文件
4. 试图从系统 classpath 下加载这个文件
在 Quartz Jar 包中有一个默认的 quartz.properties 文件
默认配置如下
# Default Properties file for use by StdSchedulerFactory
# to create a Quartz Scheduler Instance, if a different
# properties file is not explicitly specified.
org.quartz.scheduler.instanceName = DefaultQuartzScheduler
org.quartz.scheduler.rmi.export = false
org.quartz.scheduler.rmi.proxy = false
org.quartz.scheduler.wrapJobExecutionInUserTransaction = false
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount = 10
org.quartz.threadPool.threadPriority = 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true
org.quartz.jobStore.misfireThreshold = 60000
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
到此创建Scheduler完成
通过Scheduler理解Quartz
Scheduler 的 API 可以分组成以下三个类别:
·管理 Scheduler
(1)启动 Scheduler
Java代码
- //Start the scheduler
- scheduler.start();
start() 方法被调用,Scheduler 就开始搜寻需要执行的 Job。在你刚得到一个 Scheduler 新的实例时,或者 Scheduler
被设置为 standby 模式后,你才可以调用 start() 方法。
Java代码
- public void standby() throws SchedulerException;
只要调用了 shutdown() 方法之后,你就不能再调用 Scheduler 实例的 start() 方法了。
这是因为 shutdown() 方法销毁了为 Scheduler 创建的所有的资源(线程,数据库连接等)。
你可能需要Standby 模式:设置 Scheduler 为 standby 模式会导致 Scheduler搜寻要执行的 Job 的线程被暂停下来
停止 Scheduler
Java代码
- //waitForJobsToComplete 是否让当前正在进行的Job正常执行完成才停止Scheduler
- public void shutdown(boolean waitForJobsToComplete) throws SchedulerException;
- public void shutdown() throws SchedulerException;
其它管理Scheduler 方法见API...
管理 Job
什么是 Quartz Job?
一个Quart Job就是一个任何一个继承job或job子接口的Java类,你可以用这个类做任何事情!
org.quartz.Job 接口
Java代码
- public void execute(JobExecutionContext context)throws JobExecutionException;
- JobExecutionContext
当 Scheduler 调用一个 Job,一个 JobexecutionContext 传递给 execute() 方法。JobExecutionContext 对象让 Job 能
访问 Quartz 运行时候环境和 Job 本身的数据。类似于在 Java Web 应用中的 servlet 访问 ServletContext 。
通过 JobExecutionContext,Job 可访问到所处环境的所有信息,包括注册到 Scheduler 上与该 Job 相关联的 JobDetail 和 Trigger。
JobDetail
部署在 Scheduler 上的每一个 Job 只创建了一个 JobDetail实例。JobDetail 是作为 Job 实例进行定义的
// Create the JobDetail
JobDetail jobDetail = new JobDetail("PrintInfoJob",Scheduler.DEFAULT_GROUP, PrintInfoJob.class);
// Create a trigger that fires now and repeats forever
Trigger trigger = TriggerUtils.makeImmediateTrigger(
SimpleTrigger.REPEAT_INDEFINITELY, 10000);
trigger.setName("PrintInfoJobTrigger");// register with the Scheduler
scheduler.scheduleJob(jobDetail, trigger);
JobDetail 被加到 Scheduler 中了,而不是 job。Job 类是作为 JobDetail 的一部份,job直到Scheduler准备要执行它的时候才会被实例化的,因此job不存在线成安全性问题.
使用 JobDataMap 对象设定 Job 状态
Java代码
- public void executeScheduler() throws SchedulerException{
- scheduler = StdSchedulerFactory.getDefaultScheduler();
- scheduler.start();
- logger.info("Scheduler was started at " + new Date());
- // Create the JobDetail
- JobDetail jobDetail = new JobDetail("PrintJobDataMapJob",Scheduler.DEFAULT_GROUP,PrintJobDataMapJob.class);
- // Store some state for the Job
- jobDetail.getJobDataMap().put("name", "John Doe");
- jobDetail.getJobDataMap().put("age", 23);
- jobDetail.getJobDataMap().put("balance",new BigDecimal(1200.37));
- // Create a trigger that fires once
- Trigger trigger = TriggerUtils.makeImmediateTrigger(0, 10000);
- trigger.setName("PrintJobDataMapJobTrigger");
- scheduler.scheduleJob(jobDetail, trigger);
- }
- //Job 能通过 JobExecutionContext 对象访问 JobDataMap
- public class PrintJobDataMapJob implements Job {
- public void execute(JobExecutionContext context)throws JobExecutionException {
- logger.info("in PrintJobDataMapJob");
- // Every job has its own job detail
- JobDataMap jobDataMap = context.getJobDetail().getJobDataMap();
- // Iterate through the key/value pairs
- Iterator iter = jobDataMap.keySet().iterator();
- while (iter.hasNext()) {
- Object key = iter.next();
- Object value = jobDataMap.get(key);
- logger.info("Key: " + key + " - Value: " + value);
- }
- }
- }
在Quartz 1.5之后,JobDataMap在 Trigger 级也是可用的。它的用途类似于Job级的JobDataMap,支持在同一个JobDetail上的多个Trigger。
伴随着加入到 Quartz 1.5 中的这一增强特性,可以使用 JobExecutionContext 的一个新的更方便的方法获取到 Job 和 Trigger 级的并集的 map 中的值。
这个方法就是getMergedJobDataMap() 取job 和 Trigger级的并集map,它能够在 Job 中使用。管法推荐使用这个方法.
* 实际使用中trigger级别有时取不到map中的值, 使用getMergedJobDataMap 可以获取到(官方推荐此方法).
有状态的Job: org.quartz.StatefulJob 接口
当需要在两次 Job 执行间维护状态,使用StatefulJob 接口.
Job 和 StatefulJob 在框架中使用中存在两个关键差异。
(一) JobDataMap 在每次执行之后重新持久化到 JobStore 中。这样就确保你对 Job 数据的改变直到下次执行仍然保持着。
(二) 两个或多个有状态的 JobDetail 实例不能并发执行。保证JobDataMap线程安全
注意:实际使用时使用jobStoreTX/jobStoreCMT ,StatefulJob,大量的trigger对应一个JobDetail的情况下Mysql会产生锁超时问题.
中断 Job
Quartz 包括一个接口叫做 org.quartz.InterruptableJob,它扩展了普通的 Job 接口并提供了一个 interrupt() 方法:
没有深入研究,只知道 Scheduler会调用自定义的Job的 interrupt()方法。由用户决定 Job 决定如何中断.没有测试!!!
job的特性
易失性 volatility
一个易失性的 Job 是在程序关闭之后不会被持久化。一个 Job 是通过调用 JobDetail 的 setVolatility(true)被设置为易失.
Job易失性的默认值是 false.
注意:只有采用持久性JobStore时才有效
Job 持久性 durability
设置JobDetail 的 setDurability(false),在所有的触发器触发之后JobDetail将从 JobStore 中移出。
Job持久性默认值是false.
Scheduler将移除没有trigger关联的jobDetail
Job 可恢复性 shuldRecover
当一个Job在执行中,Scheduler非正常的关闭,设置JobDetail 的setRequestsRecovery(true) 在 Scheduler 重启之后可恢复的Job还会再次被执行。这个
Job 会重新开始执行。注意job代码事务特性.
Job可恢复性默认为false,Scheduler不会试着去恢复job操作。
图为表述没有执行完成的job数据库记录
Scheduler 中移除 Job
移除所有与这个 Job 相关联的 Trigger;如果这个 Job 是非持久性的,它将会从 Scheduler 中移出。
更直接的方式是使用 deleteJob() 方法,它还会删除所有与当前job关联的trigger
public boolean deleteJob(String jobName, String groupName) throws SchedulerException;
quartz 本身提供的 Job
org.quartz.jobs.FileScanJob 检查某个指定文件是否变化,并在文件被改变时通知到相应监听器的 Job
org.quartz.jobs.FileScanListener 在文件被修改后通知 FileScanJob 的监听器
org.quartz.jobs.NativeJob 用来执行本地程序(如 windows 下 .exe 文件) 的 Job
org.quartz.jobs.NoOpJob 什么也不做,但用来测试监听器不是很有用的。一些用户甚至仅仅用它来导致一个监听器的运行
org.quartz.jobs.ee.mail.SendMailJob 使用 JavaMail API 发送 e-mail 的 Job
org.quartz.jobs.ee.jmx.JMXInvokerJob 调用 JMX bean 上的方法的 Job
org.quartz.jobs.ee.ejb.EJBInvokerJob 用来调用 EJB 上方法的 Job
job的理解到此结束
理解quartz Trigger
Job 包含了要执行任务的逻辑,但是Job不负责何时执行。这个事情由触发器(Trigger)负责。
Quartz Trigger继承了抽象的org.quartz.Trigger 类。
目前,Quartz 有三个可用的实现
org.quartz.SimpleTrigger
org.quartz.CronTrigger
org.quartz.NthIncludeDayTrigger
使用org.quartz.SimpleTrigger
SimpleTrigger 是设置和使用是最为简单的一种 Quartz Trigger。它是为那种需要在特定的日期/时间启动,且以一个可能的间隔时间重复执行 n 次的 Job 所设计的。
SimpleTrigger 存在几个变种的构造方法。他们是从无参的版本一直到带全部参数的版本。
下面代码版断显示了一个仅带有trigger 的名字和组的简单构造方法
SimpleTrigger sTrigger = new SimpleTrigger("myTrigger", Scheduler.DEFAULT_GROUP);
这个 Trigger 会立即执行,而不重复。还有一个构造方法带有多个参数,配置 Triiger 在某一特定时刻触发,重复执行多次,和两
次触发间的延迟时间。
Java代码
- public SimpleTrigger(String name, String group,String jobName, String jobGroup,
- Date startTime,Date endTime, int repeatCount, long repeatInterval);
使用org.quartz.CronTrigger
CronTrigger 是基于 Unix 类似于 cron 的表达式触发,也是功能最强大和最常用的Trigger
Cron表达式:
Java代码
- "0 0 12 * * ?" Fire at 12pm (noon) every day
- "0 15 10 ? * *" Fire at 10:15am every day
- "0 15 10 * * ?" Fire at 10:15am every day
- "0 15 10 * * ? *" Fire at 10:15am every day
- "0 15 10 * * ? 2005" Fire at 10:15am every day during the year 2005
- "0 * 14 * * ?" Fire every minute starting at 2pm and ending at 2:59pm, every day
- "0 0/5 14 * * ?" Fire every 5 minutes starting at 2pm and ending at 2:55pm, every day
- "0 0/5 14,18 * * ?" Fire every 5 minutes starting at 2pm and ending at 2:55pm, AND fire every 5 minutes starting at 6pm and ending at 6:55pm, every day
- "0 0-5 14 * * ?" Fire every minute starting at 2pm and ending at 2:05pm, every day
- "0 10,44 14 ? 3 WED" Fire at 2:10pm and at 2:44pm every Wednesday in the month of March.
- "0 15 10 ? * MON-FRI" Fire at 10:15am every Monday, Tuesday, Wednesday, Thursday and Friday
- "0 15 10 15 * ?" Fire at 10:15am on the 15th day of every month
- "0 15 10 L * ?" Fire at 10:15am on the last day of every month
- "0 15 10 ? * 6L" Fire at 10:15am on the last Friday of every month
- "0 15 10 ? * 6L" Fire at 10:15am on the last Friday of every month
- "0 15 10 ? * 6L 2002-2005" Fire at 10:15am on every last Friday of every month during the years 2002, 2003, 2004 and 2005
- "0 15 10 ? * 6#3" Fire at 10:15am on the third Friday of every month
使用 org.quartz.NthIncludedDayTrigger
org.quartz.NthIncludedDayTrigger是设计用于在每一间隔类型的第几天执行 Job。
例如,你要在每个月的 12 号执行发工资提醒的Job。接下来的代码片断描绘了如何创建一个 NthIncludedDayTrigger.
Java代码
- //创建每个月的12号的NthIncludedDayTrigger
- NthIncludedDayTrigger trigger = new NthIncludedDayTrigger("MyTrigger", Scheduler.DEFAULT_GROUP);
- trigger.setN(12);
- trigger.setIntervalType(NthIncludedDayTrigger.INTERVAL_TYPE_MONTHLY);
jobDetail + trigger组成最基本的定时任务:
特别注意:一个job可以对应多个Trgger , 一个Trigger只能对应一个job .
如:CRM中N天未拜访的job对应所有的N天未拜访商家(一个商家一个trigger) 大约1:1000的比例
job和trigger都是通过name 和 group 属性确定唯一性的.
Quartz Calendar
Quartz 的 Calendar 对象与 Java API 的 java.util.Calendar不同。
Java 的 Calender 对象是通用的日期和时间工具;
Quartz 的 Calender 专门用于屏闭一个时间区间,使 Trigger 在这个区间中不被触发。
例如,让我们假如取消节假日执行job。
Quartz包括许多的 Calender 实现足以满足大部分的需求.
org.quartz.impl.calendar.BaseCalender 为高级的 Calender 实现了基本的功能,实现了 org.quartz.Calender 接口
org.quartz.impl.calendar.WeeklyCalendar 排除星期中的一天或多天,例如,可用于排除周末
org.quartz.impl.calendar.MonthlyCalendar 排除月份中的数天,例如,可用于排除每月的最后一天
org.quartz.impl.calendar.AnnualCalendar 排除年中一天或多天
org.quartz.impl.calendar.HolidayCalendar 特别的用于从 Trigger 中排除节假日
使用Calendar,只需实例化后并加入你要排除的日期,然后用 Scheduler 注册,最后必须让Calender依附于Trigger实例。
排除国庆节实例
Java代码
- private void scheduleJob(Scheduler scheduler, Class jobClass) {
- try {
- // Create an instance of the Quartz AnnualCalendar
- AnnualCalendar cal = new AnnualCalendar();
- // exclude 国庆节
- Calendar gCal = GregorianCalendar.getInstance();
- gCal.set(Calendar.MONTH, Calendar.OCTOBER);
- List
mayHolidays = new ArraysList (); - for(int i=1; i<=7; i++){
- gCal.set(Calendar.DATE, i);
- mayHolidays.add(gCal);
- }
- cal.setDaysExcluded(mayHolidays);
- // Add to scheduler, replace existing, update triggers
- scheduler.addCalendar("crmHolidays", cal, true, true);
- /*
- * Set up a trigger to start firing now, repeat forever
- * and have (60000 ms) between each firing.
- */
- Trigger trigger = TriggerUtils.makeImmediateTrigger("myTrigger",-1,60000);
- // Trigger will use Calendar to exclude firing times
- trigger.setCalendarName("crmHolidays");
- JobDetail jobDetail = new JobDetail(jobClass.getName(), Scheduler.DEFAULT_GROUP, jobClass);
- // Associate the trigger with the job in the scheduler
- scheduler.scheduleJob(jobDetail, trigger);
- } catch (SchedulerException ex) {
- logger.error(ex);
- }
- }
Quartz 监听器
Quartz 提供了三种类型的监听器:监听Job,监听Trigger,和监听Scheduler.
监听器是作为扩展点存在的.
Quartz 监听器是扩展点,可以扩展框架并定制来做特定的事情。跟Spring,Hibernate,Servlet监听器类似.
实现监听
1. 创建一个 Java 类,实现监听器接口
2. 用你的应用中特定的逻辑实现监听器接口的所有方法
3. 注册监听器
全局和非全局监听器
JobListener 和 TriggerListener 可被注册为全局或非全局监听器。一个全局监听器能接收到所有的 Job/Trigger 的事件通知。
而一个非全局监听器只能接收到那些在其上已注册了监听器的 Job 或 Triiger 的事件。
作者:James House描述全局和非全局监听器
全局监听器是主动意识的,它们为了执行它们的任务而热切的去寻找每一个可能的事件。通常,全局监听器要做的工作不用指定到特定的 Job 或 Trigger。
非全局监听器一般是被动意识的,它们在所关注的 Trigger 激发之前或是 Job 执行之前什么事也不做。因此,非全局的监听器比起全局监听器而言更适合于修改或增加 Job 执行的工作。
类似装饰设计模式
监听 Job 事件
org.quartz.JobListener 接口包含一系列的方法,它们会由 Job 在其生命周期中产生的某些关键事件时被调用
Java代码
- public interface JobListener {
- //命名jobListener 只对非全局监听器有效
- public String getName();
- //Scheduler 在 JobDetail 将要被执行时调用这个方法。
- public void jobToBeExecuted(JobExecutionContext context);
- //Scheduler 在 JobDetail 即将被执行,但又被否决时调用这个方法。
- public void jobExecutionVetoed(JobExecutionContext context);
- //Scheduler 在 JobDetail 被执行之后调用这个方法。
- public void jobWasExecuted(JobExecutionContext context,JobExecutionException jobException);
图7 job listener参与job的执行生命周期
注册全局监听器
Java代码
- scheduler.addGlobalJobListener(jobListener);
注册非全局监听器(依次完成,顺序不能颠倒)
Java代码
- scheduler.addJobListener(jobListener);
- jobDetail.addJobListener(jobListener.getName());
- //如果已经存在jobDetail则覆盖.
- scheduler.addjob(jobDetail,true);
监听 Trigger 事件
org.quartz.TriggerListener 接口定义Trigger监听器
Java代码
- public interface TriggerListener {
- //命名triggerListener 只对非全局监听器有效
- public String getName();
- //当与监听器相关联的 Trigger 被触发,Job 上的 execute() 方法将要被执行时,调用这个方法。
- //在全局TriggerListener 情况下,这个方法为所有 Trigger 被调用。(不要做耗时操作)
- public void triggerFired(Trigger trigger, JobExecutionContext context);
- //在 Trigger 触发后,Job 将要被执行时由调用这个方法。
- //TriggerListener给了一个选择去否决 Job 的执行。假如这个方法返回 true,这个 Job 将不会为此次 Trigger 触发而得到执行。
- public boolean vetoJobExecution(Trigger trigger, JobExecutidonContext context);
- // Scheduler 调用这个方法是在 Trigger 错过触发时。
- // JavaDoc 指出:你应该关注此方法中持续时间长的逻辑:在出现许多错过触发的 Trigger 时,长逻辑会导致骨牌效应。你应当保持这上方法尽量的小
- public void triggerMisfired(Trigger trigger);
- //Trigger 被触发并且完成了Job的执行时调用这个方法。
- public void triggerComplete(Trigger trigger, JobExecutionContext context, int triggerInstructionCode);
- }
triggerListener的注册与jobListener相同
监听 Scheduler 事件
org.quartz.SchedulerListener 接口定义Trigger监听器
Java代码
- public interface SchedulerListener {
- //有新的JobDetail部署调用这个方法。
- public void jobScheduled(Trigger trigger);
- //卸载时调用这个方法。
- public void jobUnscheduled(String triggerName, String triggerGroup);
- //当一个Trigger到达再也不会触发时调用这个方法。
- public void triggerFinalized(Trigger trigger);
- //Scheduler 调用这个方法是发生在一个Trigger或多个Trigger被暂停时。假如是多个Trigger的话,triggerName 参数将为null。
- public void triggersPaused(String triggerName, String triggerGroup);
- //Scheduler 调用这个方法是发生成一个 Trigger 或 Trigger 组从暂停中恢复时。假如是多个Trigger的话,triggerName 参数将为 null。
- public void triggersResumed(String triggerName,String triggerGroup);
- //当一个或一组 JobDetail 暂停时调用这个方法。
- public void jobsPaused(String jobName, String jobGroup);
- //当一个或一组 Job 从暂停上恢复时调用这个方法。假如是多个Job,jobName参数将为 null。
- public void jobsResumed(String jobName, String jobGroup);
- // 在Scheduler 的正常运行期间产生一个严重错误时调用这个方法。错误的类型会各式的,但是下面列举了一些错误例子:
- // 可以使用 SchedulerException 的 getErrorCode() 或者 getUnderlyingException() 方法或获取到特定错误的更详尽的信息
- public void schedulerError(String msg, SchedulerException cause);
- //Scheduler 调用这个方法用来通知 SchedulerListener Scheduler 将要被关闭。
- public void schedulerShutdown();
- }
注册SchedulerListener(SchedulerListener不存在全局非全局性)
scheduler.addSchedulerListener(schedulerListener);
由于scheduler异常存在不打印问题,CRM使用监听器代码打印.
Java代码
- public class QuartzExceptionSchedulerListener extends SchedulerListenerSupport{
- private Logger logger = LoggerFactory.getLogger(QuartzExceptionSchedulerListener.class);
- @Override
- public void schedulerError(String message, SchedulerException e) {
- super.schedulerError(message, e);
- logger.error(message, e.getUnderlyingException());
- }
- }
Java代码
quartz与线程
主处理线程:QuartzSchedulerThread
启动Scheduler时。QuartzScheduler被创建并创建一个org.quartz.core.QuartzSchedulerThread 类的实例。
QuartzSchedulerThread 包含有决定何时下一个Job将被触发的处理循环。QuartzSchedulerThread 是一个 Java 线程。它作为一个非守护线程运行在正常优先级下。
QuartzSchedulerThread 的主处理轮循步骤:
1. 当 Scheduler 正在运行时:
A. 检查是否有转换为 standby 模式的请求。
1. 假如 standby 方法被调用,等待继续的信号
B. 询问 JobStore 下次要被触发的 Trigger.
1. 如果没有 Trigger 待触发,等候一小段时间后再次检查
2. 假如有一个可用的 Trigger,等待触发它的确切时间的到来
D. 时间到了,为 Trigger 获取到 triggerFiredBundle.
E. 使用Scheduler和triggerFiredBundle 为 Job 创建一个JobRunShell实例
F. 在ThreadPool 申请一个线程运行 JobRunShell 实例.
代码逻辑在QuartzSchedulerThread 的 run() 中,如下:
Java代码
- /**
- * QuartzSchedulerThread.run
- *
- * The main processing loop of the
QuartzSchedulerThread. - *
- */
- public void run() {
- boolean lastAcquireFailed = false;
- while (!halted.get()) {
- try {
- // check if we're supposed to pause...
- synchronized (sigLock) {
- while (paused && !halted.get()) {
- try {
- // wait until togglePause(false) is called...
- sigLock.wait(1000L);
- } catch (InterruptedException ignore) {
- }
- }
- if (halted.get()) {
- break;
- }
- }
- int availTreadCount = qsRsrcs.getThreadPool().blockForAvailableThreads();
- if(availTreadCount > 0) { // will always be true, due to semantics of blockForAvailableThreads...
- Trigger trigger = null;
- long now = System.currentTimeMillis();
- clearSignaledSchedulingChange();
- try {
- trigger = qsRsrcs.getJobStore().acquireNextTrigger(
- ctxt, now + idleWaitTime);
- lastAcquireFailed = false;
- } catch (JobPersistenceException jpe) {
- if(!lastAcquireFailed) {
- qs.notifySchedulerListenersError(
- "An error occured while scanning for the next trigger to fire.",
- jpe);
- }
- lastAcquireFailed = true;
- } catch (RuntimeException e) {
- if(!lastAcquireFailed) {
- getLog().error("quartzSchedulerThreadLoop: RuntimeException "
- +e.getMessage(), e);
- }
- lastAcquireFailed = true;
- }
- if (trigger != null) {
- now = System.currentTimeMillis();
- long triggerTime = trigger.getNextFireTime().getTime();
- long timeUntilTrigger = triggerTime - now;
- while(timeUntilTrigger > 2) {
- synchronized(sigLock) {
- if(!isCandidateNewTimeEarlierWithinReason(triggerTime, false)) {
- try {
- // we could have blocked a long while
- // on 'synchronize', so we must recompute
- now = System.currentTimeMillis();
- timeUntilTrigger = triggerTime - now;
- if(timeUntilTrigger >= 1)
- sigLock.wait(timeUntilTrigger);
- } catch (InterruptedException ignore) {
- }
- }
- }
- if(releaseIfScheduleChangedSignificantly(trigger, triggerTime)) {
- trigger = null;
- break;
- }
- now = System.currentTimeMillis();
- timeUntilTrigger = triggerTime - now;
- }
- if(trigger == null)
- continue;
- // set trigger to 'executing'
- TriggerFiredBundle bndle = null;
- boolean goAhead = true;
- synchronized(sigLock) {
- goAhead = !halted.get();
- }
- if(goAhead) {
- try {
- bndle = qsRsrcs.getJobStore().triggerFired(ctxt,
- trigger);
- } catch (SchedulerException se) {
- qs.notifySchedulerListenersError(
- "An error occured while firing trigger '"
- + trigger.getFullName() + "'", se);
- } catch (RuntimeException e) {
- getLog().error(
- "RuntimeException while firing trigger " +
- trigger.getFullName(), e);
- // db connection must have failed... keep
- // retrying until it's up...
- releaseTriggerRetryLoop(trigger);
- }
- }
- // it's possible to get 'null' if the trigger was paused,
- // blocked, or other similar occurrences that prevent it being
- // fired at this time... or if the scheduler was shutdown (halted)
- if (bndle == null) {
- try {
- qsRsrcs.getJobStore().releaseAcquiredTrigger(ctxt,
- trigger);
- } catch (SchedulerException se) {
- qs.notifySchedulerListenersError(
- "An error occured while releasing trigger '"
- + trigger.getFullName() + "'", se);
- // db connection must have failed... keep retrying
- // until it's up...
- releaseTriggerRetryLoop(trigger);
- }
- continue;
- }
- // TODO: improvements:
- //
- // 2- make sure we can get a job runshell before firing trigger, or
- // don't let that throw an exception (right now it never does,
- // but the signature says it can).
- // 3- acquire more triggers at a time (based on num threads available?)
- JobRunShell shell = null;
- try {
- shell = qsRsrcs.getJobRunShellFactory().borrowJobRunShell();
- shell.initialize(qs, bndle);
- } catch (SchedulerException se) {
- try {
- qsRsrcs.getJobStore().triggeredJobComplete(ctxt,
- trigger, bndle.getJobDetail(), Trigger.INSTRUCTION_SET_ALL_JOB_TRIGGERS_ERROR);
- } catch (SchedulerException se2) {
- qs.notifySchedulerListenersError(
- "An error occured while placing job's triggers in error state '"
- + trigger.getFullName() + "'", se2);
- // db connection must have failed... keep retrying
- // until it's up...
- errorTriggerRetryLoop(bndle);
- }
- continue;
- }
- if (qsRsrcs.getThreadPool().runInThread(shell) == false) {
- try {
- // this case should never happen, as it is indicative of the
- // scheduler being shutdown or a bug in the thread pool or
- // a thread pool being used concurrently - which the docs
- // say not to do...
- getLog().error("ThreadPool.runInThread() return false!");
- qsRsrcs.getJobStore().triggeredJobComplete(ctxt,
- trigger, bndle.getJobDetail(), Trigger.INSTRUCTION_SET_ALL_JOB_TRIGGERS_ERROR);
- } catch (SchedulerException se2) {
- qs.notifySchedulerListenersError(
- "An error occured while placing job's triggers in error state '"
- + trigger.getFullName() + "'", se2);
- // db connection must have failed... keep retrying
- // until it's up...
- releaseTriggerRetryLoop(trigger);
- }
- }
- continue;
- }
- } else { // if(availTreadCount > 0)
- continue; // should never happen, if threadPool.blockForAvailableThreads() follows contract
- }
- long now = System.currentTimeMillis();
- long waitTime = now + getRandomizedIdleWaitTime();
- long timeUntilContinue = waitTime - now;
- synchronized(sigLock) {
- try {
- sigLock.wait(timeUntilContinue);
- } catch (InterruptedException ignore) {
- }
- }
- } catch(RuntimeException re) {
- getLog().error("Runtime error occured in main trigger firing loop.", re);
- }
- } // loop...
- // drop references to scheduler stuff to aid garbage collection...
- qs = null;
- qsRsrcs = null;
- }
quartz工作者线程
Quartz 不会在主线程(QuartzSchedulerThread)中处理用户的Job。Quartz 把线程管理的职责委托给ThreadPool。
一般的设置使用org.quartz.simpl.SimpleThreadPool。SimpleThreadPool 创建了一定数量的 WorkerThread 实例来使得Job能够在线程中进行处理。
WorkerThread 是定义在 SimpleThreadPool 类中的内部类,它实质上就是一个线程。
要创建 WorkerThread 的数量以及配置他们的优先级是在文件quartz.properties中并传入工厂。
spring properties
Java代码
主线程(QuartzSchedulerThread)请求ThreadPool去运行 JobRunShell 实例,ThreadPool 就检查看是否有一个可用的工作者线
程。假如所以已配置的工作者线程都是忙的,ThreadPool 就等待直到有一个变为可用。当一个工作者线程是可用的,
并且有一个JobRunShell 等待执行,工作者线程就会调用 JobRunShell 类的 run() 方法。
Quartz 框架允许替换线程池,但必须实现org.quartz.spi.ThreadPool 接口.
图4 quartz内部的主线程和工作者线程
Quartz的存储和持久化
Quartz 用 JobStores 对 Job、Trigger、calendar 和 Schduler 数据提供一种存储机制。Scheduler 应用已配置的JobStore 来存储和获取到部署信息,并决定正被触发执行的 Job 的职责。
所有的关于哪个 Job 要执行和以什么时间表来执行他们的信息都来存储在 JobStore。
在 Quartz 中两种可用的 Job 存储类型是:
内存(非持久化) 存储
持久化存储
JobStore 接口
Quartz 为所有类型的Job存储提供了一个接口。叫 JobStore。所有的Job存储机制,不管是在哪里或是如何存储他们的信息的,都必须实现这个接口。
JobStore 接口的 API 可归纳为下面几类:
Job 相关的 API
Trigger 相关的 API
Calendar 相关的 API
Scheduler 相关的 API
使用内存来存储 Scheduler 信息
Quartz 的内存Job存储类叫做 org.quartz.simple.RAMJobStore,它实现了JobStore 接口的。
RAMJobStore 是 Quartz 的默认的解决方案。
使用这种内存JobStore的好处。
RAMJobStore是配置最简单的 JobStore:默认已经配置好了。见quartz.jar:org.quartz.quartz.properties
RAMJobStore的速度非常快。所有的 quartz存储操作都在计算机内存中
使用持久性的 JobStore
持久性 JobStore = JDBC + 关系型数据库
Quartz 所有的持久化的 JobStore 都扩展自 org.quartz.impl.jdbcjobstore.JobStoreSupport 类。
图5
JobStoreSupport 实现了 JobStore 接口,是作为 Quartz 提供的两个具体的持久性 JobStore 类的基类。
Quartz 提供了两种不同类型的JobStoreSupport实现类,每一个设计为针对特定的数据库环境和配置:
·org.quartz.impl.jdbcjobstore.JobStoreTX
·org.quartz.impl.jdbcjobstore.JobStoreCMT
独立环境中的持久性存储
JobStoreTX 类设计为用于独立环境中。这里的 "独立",我们是指这样一个环境,在其中不存在与应用容器的事务集成。
#properties配置
org.quartz.jobStore.class = org.quartz.ompl.jdbcjobstore.JobStoreTX
依赖容器相关的持久性存储
JobStoreCMT 类设计为与程序容器事务集成,容器管理的事物(Container Managed Transactions (CMT))
crm使用JobStoreTX 因为quart有长时间锁等待情况,不参与系统本身事务(crm任务内事务与quartz本身事务分离).
Quartz 数据库结构
表名描述
QRTZ_CALENDARS 以 Blob 类型存储 Quartz 的 Calendar 信息
QRTZ_CRON_TRIGGERS 存储 Cron Trigger,包括 Cron 表达式和时区信息
QRTZ_FIRED_TRIGGERS 存储与已触发的 Trigger 相关的状态信息,以及相联 Job 的执行信息
QRTZ_PAUSED_TRIGGER_GRPS 存储已暂停的 Trigger 组的信息
QRTZ_SCHEDULER_STATE 存储少量的有关 Scheduler 的状态信息,和别的 Scheduler 实例(假如是用于一个集群中)
QRTZ_LOCKS 存储程序的非观锁的信息(假如使用了悲观锁)
QRTZ_JOB_DETAILS 存储每一个已配置的 Job 的详细信息
QRTZ_JOB_LISTENERS 存储有关已配置的 JobListener 的信息
QRTZ_SIMPLE_TRIGGERS 存储简单的 Trigger,包括重复次数,间隔,以及已触的次数
QRTZ_BLOG_TRIGGERS Trigger 作为 Blob 类型存储(用于 Quartz 用户用 JDBC 创建他们自己定制的 Trigger 类型,JobStore 并不知道如何存储实例的时候)
QRTZ_TRIGGER_LISTENERS 存储已配置的 TriggerListener 的信息
QRTZ_TRIGGERS 存储已配置的 Trigger 的信息
所有的表默认以前缀QRTZ_开始。可以通过在 quartz.properties配置修改(org.quartz.jobStore.tablePrefix = QRTZ_)。
可以对不同的Scheduler实例使用多套的表,通过改变前缀来实现。
优化 quartz数据表结构
-- 1:对关键查询路径字段建立索引
Java代码
- create index idx_qrtz_t_next_fire_time on QRTZ_TRIGGERS(NEXT_FIRE_TIME);
- create index idx_qrtz_t_state on QRTZ_TRIGGERS(TRIGGER_STATE);
- create index idx_qrtz_t_nf_st on QRTZ_TRIGGERS(TRIGGER_STATE,NEXT_FIRE_TIME);
- create index idx_qrtz_ft_trig_group on QRTZ_FIRED_TRIGGERS(TRIGGER_GROUP);
- create index idx_qrtz_ft_trig_name on QRTZ_FIRED_TRIGGERS(TRIGGER_NAME);
- create index idx_qrtz_ft_trig_n_g on QRTZ_FIRED_TRIGGERS(TRIGGER_NAME,TRIGGER_GROUP);
- create index idx_qrtz_ft_trig_inst_name on QRTZ_FIRED_TRIGGERS(INSTANCE_NAME);
- create index idx_qrtz_ft_job_name on QRTZ_FIRED_TRIGGERS(JOB_NAME);
- create index idx_qrtz_ft_job_group on QRTZ_FIRED_TRIGGERS(JOB_GROUP);
-- 2:根据Mysql innodb表结构特性,调整主键,降低二级索引的大小
Java代码
- ALTER TABLE QRTZ_TRIGGERS
- ADD UNIQUE KEY IDX_NAME_GROUP(TRIGGER_NAME,TRIGGER_GROUP),
- DROP PRIMARY KEY,
- ADD ID INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST,
- ADD PRIMARY KEY (ID);
- ALTER TABLE QRTZ_JOB_DETAILS
- ADD UNIQUE KEY IDX_NAME_GROUP(JOB_NAME,JOB_GROUP),
- DROP PRIMARY KEY,
- ADD ID INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST,
- ADD PRIMARY KEY (ID);
Quartz集群
只有使用持久的JobStore才能完成Quqrtz集群
图6
一个 Quartz 集群中的每个节点是一个独立的 Quartz 应用,它又管理着其他的节点。
需要分别对每个节点分别启动或停止。不像应用服务器的集群,独立的 Quartz 节点并不与另一个节点或是管理节点通信。
Quartz 应用是通过数据库表来感知到另一应用。
配置集群
Xml代码
- <prop key="org.quartz.jobStore.class">org.quartz.impl.jdbcjobstore.JobStoreTXprop>
- <prop key="org.quartz.jobStore.isClustered">trueprop>
- <prop key="org.quartz.jobStore.clusterCheckinInterval">15000prop>
- <prop key="org.quartz.jobStore.maxMisfiresToHandleAtATime">1prop>
- <prop key="org.quartz.jobStore.dataSource">myDSprop>
- <prop key="org.quartz.dataSource.myDS.driver">${database.driverClassName}prop>
- <prop key="org.quartz.dataSource.myDS.URL">${database.url}prop>
- <prop key="org.quartz.dataSource.myDS.user">${database.username}prop>
- <prop key="org.quartz.dataSource.myDS.password">${database.password}prop>
- <prop key="org.quartz.dataSource.myDS.maxConnections">5prop>
org.quartz.jobStore.class 属性为 JobStoreTX,
将任务持久化到数据中。因为集群中节点依赖于数据库来传播Scheduler实例的状态,你只能在使用 JDBC JobStore 时应用 Quartz 集群。
org.quartz.jobStore.isClustered 属性为 true,通知Scheduler实例要它参与到一个集群当中。
org.quartz.jobStore.clusterCheckinInterval
属性定义了Scheduler 实例检入到数据库中的频率(单位:毫秒)。
Scheduler 检查是否其他的实例到了它们应当检入的时候未检入;
这能指出一个失败的 Scheduler 实例,且当前 Scheduler 会以此来接管任何执行失败并可恢复的 Job。
通过检入操作,Scheduler 也会更新自身的状态记录。clusterChedkinInterval 越小,Scheduler 节点检查失败的 Scheduler 实例就越频繁。默认值是 15000 (即15 秒)
集群实现分析
Quartz原来码分析:
基于数据库表锁实现多Quartz_Node 对Job,Trigger,Calendar等同步机制
Sql代码
- -- 数据库锁定表
- CREATE TABLE `QRTZ_LOCKS` (
- `LOCK_NAME` varchar(40) NOT NULL,
- PRIMARY KEY (`LOCK_NAME`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- -- 记录
- +-----------------+
- | LOCK_NAME |
- +-----------------+
- | CALENDAR_ACCESS |
- | JOB_ACCESS |
- | MISFIRE_ACCESS |
- | STATE_ACCESS |
- | TRIGGER_ACCESS |
- +-----------------+
通过行级别锁实现多节点处理
Java代码
- /**
- * Internal database based lock handler for providing thread/resource locking
- * in order to protect resources from being altered by multiple threads at the
- * same time.
- *
- * @author jhouse
- */
- public class StdRowLockSemaphore extends DBSemaphore {
- /*
- * Constants.
- * 锁定SQL语句
- *
- */
- public static final String SELECT_FOR_LOCK = "SELECT * FROM "
- + TABLE_PREFIX_SUBST + TABLE_LOCKS + " WHERE " + COL_LOCK_NAME
- + " = ? FOR UPDATE";
- /**
- * This constructor is for using the
StdRowLockSemaphoreas - * a bean.
- */
- public StdRowLockSemaphore() {
- super(DEFAULT_TABLE_PREFIX, null, SELECT_FOR_LOCK);
- }
- public StdRowLockSemaphore(String tablePrefix, String seletWithLockSQL) {
- super(tablePrefix, selectWithLockSQL, SELECT_FOR_LOCK);
- }
- /**
- * Execute the SQL select for update that will lock the proper database row.
- * 指定锁定SQL
- */
- protected void executeSQL(Connection conn, String lockName, String expandedSQL) throws LockException {
- PreparedStatement ps = null;
- ResultSet rs = null;
- try {
- ps = conn.prepareStatement(expandedSQL);
- ps.setString(1, lockName);
- if (getLog().isDebugEnabled()) {
- getLog().debug(
- "Lock '" + lockName + "' is being obtained: " +
- Thread.currentThread().getName());
- }
- rs = ps.executeQuery();
- if (!rs.next()) {
- throw new SQLException(Util.rtp(
- "No row exists in table " + TABLE_PREFIX_SUBST +
- TABLE_LOCKS + " for lock named: " + lockName, getTablePrefix()));
- }
- } catch (SQLException sqle) {
- if (getLog().isDebugEnabled()) {
- getLog().debug(
- "Lock '" + lockName + "' was not obtained by: " +
- Thread.currentThread().getName());
- }
- throw new LockException("Failure obtaining db row lock: "
- + sqle.getMessage(), sqle);
- } finally {
- if (rs != null) {
- try {
- rs.close();
- } catch (Exception ignore) {
- }
- }
- if (ps != null) {
- try {
- ps.close();
- } catch (Exception ignore) {
- }
- }
- }
- }
- protected String getSelectWithLockSQL() {
- return getSQL();
- }
- public void setSelectWithLockSQL(String selectWithLockSQL) {
- setSQL(selectWithLockSQL);
- }
- }
- /**
- * Grants a lock on the identified resource to the calling thread (blocking
- * until it is available).
- * 获取QRTZ_LOCKS行级锁
- * @return true if the lock was obtained.
- */
- public boolean obtainLock(Connection conn, String lockName) throws LockException {
- lockName = lockName.intern();
- Logger log = getLog();
- if(log.isDebugEnabled()) {
- log.debug(
- "Lock '" + lockName + "' is desired by: "
- + Thread.currentThread().getName());
- }
- if (!isLockOwner(conn, lockName)) {
- executeSQL(conn, lockName, expandedSQL);
- if(log.isDebugEnabled()) {
- log.debug(
- "Lock '" + lockName + "' given to: "
- + Thread.currentThread().getName());
- }
- getThreadLocks().add(lockName);
- //getThreadLocksObtainer().put(lockName, new
- // Exception("Obtainer..."));
- } else if(log.isDebugEnabled()) {
- log.debug(
- "Lock '" + lockName + "' Is already owned by: "
- + Thread.currentThread().getName());
- }
- return true;
- }
- /**
- * Release the lock on the identified resource if it is held by the calling thread.
- * 释放QRTZ_LOCKS行级锁
- */
- public void releaseLock(Connection conn, String lockName) {
- lockName = lockName.intern();
- if (isLockOwner(conn, lockName)) {
- if(getLog().isDebugEnabled()) {
- getLog().debug(
- "Lock '" + lockName + "' returned by: "
- + Thread.currentThread().getName());
- }
- getThreadLocks().remove(lockName);
- //getThreadLocksObtainer().remove(lockName);
- } else if (getLog().isDebugEnabled()) {
- getLog().warn(
- "Lock '" + lockName + "' attempt to return by: "
- + Thread.currentThread().getName()
- + " -- but not owner!",
- new Exception("stack-trace of wrongful returner"));
- }
- }
JobStoreTX 控制并发代码
Java代码
- /**
- * Execute the given callback having optionally aquired the given lock.
- * For
JobStoreTX, because it manages its own transactions - * and only has the one datasource, this is the same behavior as
- * executeInNonManagedTXLock().
- * @param lockName The name of the lock to aquire, for example
- * "TRIGGER_ACCESS". If null, then no lock is aquired, but the
- * lockCallback is still executed in a transaction.
- *
- * @see JobStoreSupport#executeInNonManagedTXLock(String, TransactionCallback)
- * @see JobStoreCMT#executeInLock(String, TransactionCallback)
- * @see JobStoreSupport#getNonManagedTXConnection()
- * @see JobStoreSupport#getConnection()
- */
- protected Object executeInLock(String lockName, TransactionCallback txCallback) throws JobPersistenceException {
- return executeInNonManagedTXLock(lockName, txCallback);
- }
- 使用JobStoreSupport.executeInNonManagedTXLock 实现:
- /**
- * Execute the given callback having optionally aquired the given lock.
- * This uses the non-managed transaction connection.
- *
- * @param lockName The name of the lock to aquire, for example
- * "TRIGGER_ACCESS". If null, then no lock is aquired, but the
- * lockCallback is still executed in a non-managed transaction.
- */
- protected Object executeInNonManagedTXLock(
- String lockName,
- TransactionCallback txCallback) throws JobPersistenceException {
- boolean transOwner = false;
- Connection conn = null;
- try {
- if (lockName != null) {
- // If we aren't using db locks, then delay getting DB connection
- // until after acquiring the lock since it isn't needed.
- if (getLockHandler().requiresConnection()) {
- conn = getNonManagedTXConnection();
- }
- //获取锁
- transOwner = getLockHandler().obtainLock(conn, lockName);
- }
- if (conn == null) {
- conn = getNonManagedTXConnection();
- }
- //回调需要执行的sql语句如:(更新Trigger为运行中(ACQUIRED),删除执行过的Trigger等)
- Object result = txCallback.execute(conn);
- //JobStoreTX自身维护事务
- commitConnection(conn);
- Long sigTime = clearAndGetSignalSchedulingChangeOnTxCompletion();
- if(sigTime != null && sigTime >= 0) {
- signalSchedulingChangeImmediately(sigTime);
- }
- return result;
- } catch (JobPersistenceException e) {
- rollbackConnection(conn);
- throw e;
- } catch (RuntimeException e) {
- rollbackConnection(conn);
- throw new JobPersistenceException("Unexpected runtime exception: " + e.getMessage(), e);
- } finally {
- try {
- //释放锁
- releaseLock(conn, lockName, transOwner);
- } finally {
- cleanupConnection(conn);
- }
- }
- }
JobStoreCMT 控制并发代码
Java代码
- /**
- * Execute the given callback having optionally acquired the given lock.
- * Because CMT assumes that the connection is already part of a managed
- * transaction, it does not attempt to commit or rollback the
- * enclosing transaction.
- *
- * @param lockName The name of the lock to acquire, for example
- * "TRIGGER_ACCESS". If null, then no lock is acquired, but the
- * txCallback is still executed in a transaction.
- *
- * @see JobStoreSupport#executeInNonManagedTXLock(String, TransactionCallback)
- * @see JobStoreTX#executeInLock(String, TransactionCallback)
- * @see JobStoreSupport#getNonManagedTXConnection()
- * @see JobStoreSupport#getConnection()
- */
- protected Object executeInLock(String lockName, TransactionCallback txCallback) throws JobPersistenceException {
- boolean transOwner = false;
- Connection conn = null;
- try {
- if (lockName != null) {
- // If we aren't using db locks, then delay getting DB connection
- // until after acquiring the lock since it isn't needed.
- if (getLockHandler().requiresConnection()) {
- conn = getConnection();
- }
- transOwner = getLockHandler().obtainLock(conn, lockName);
- }
- if (conn == null) {
- conn = getConnection();
- }
- //没有事务提交操作,与任务共享一个事务
- return txCallback.execute(conn);
- } finally {
- try {
- releaseLock(conn, LOCK_TRIGGER_ACCESS, transOwner);
- } finally {
- cleanupConnection(conn);
- }
- }
- }
CRM中quartz与Spring结合使用
Spring 通过提供org.springframework.scheduling.quartz下的封装类对quartz支持
但是目前存在问题
1:Spring3.0目前不支持Quartz2.x以上版本
Caused by: java.lang.IncompatibleClassChangeError: class org.springframework.scheduling.quartz.CronTriggerBean
has interface org.quartz.CronTrigger as super class
原因是 org.quartz.CronTrigger在2.0从class变成了一个interface造成IncompatibleClassChangeError错误。
解决:无解,要想使用spring和quartz结合的方式 只能使用Quartz1.x版本。
2:org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean报
java.io.NotSerializableException异常,需要自己实现QuartzJobBean。
解决:spring bug己经在http://jira.springframework.org/browse/SPR-3797找到解决方案,
作者重写了MethodInvokingJobDetailFactoryBean.
3:Spring内bean必须要实现序列化接口,否则不能通过Sprng 属性注入的方式为job提供业务对象
解决:
Java代码
- //使用可序列化工具类获取Spring容器对象
- @Service("springBeanService")
- public class SpringBeanService implements Serializable{private static final long serialVersionUID = -2228376078979553838L;
- public
T getBean(Class clazz,String beanName){ - ApplicationContext context = ContextLoader.getCurrentWebApplicationContext();
- return (T)context.getBean(beanName);
- }
- }
CRM中quartz模块部分代码
1:定义所有job的父类,并负责异常发送邮件任务和日志任务
Java代码
- public abstract class BaseQuartzJob implements Job, Serializable {
- private static final long serialVersionUID = 3347549365534415931L;
- private Logger logger = LoggerFactory.getLogger(this.getClass());
- //定义抽象方法,供子类实现
- public abstract void action(JobExecutionContext context);
- @Override
- public void execute(JobExecutionContext context) throws JobExecutionException {
- try {
- long start = System.currentTimeMillis();
- this.action(context);
- long end = System.currentTimeMillis();
- JobDetail jobDetail = context.getJobDetail();
- Trigger trigger = context.getTrigger();
- StringBuilder buffer = new StringBuilder();
- buffer.append("jobName = ").append(jobDetail.getName()).append(" triggerName = ")
- .append(trigger.getName()).append(" 执行完成 , 耗时: ").append((end - start)).append(" ms");
- logger.info(buffer.toString());
- } catch (Exception e) {
- doResolveException(context != null ? context.getMergedJobDataMap() : null, e);
- }
- }
- @SuppressWarnings("unchecked")
- private void doResolveException(JobDataMap dataMap, Exception ex) {
- //发送邮件实现此处省略
- //...
- }
- }
2:抽象Quartz操作接口(实现类 toSee: QuartzServiceImpl)
Java代码
- /**
- *
- * @author zhangyijun
- * @created 2012-10-22
- *
- * @version 1.0
- */
- @Service
- public interface QuartzService {
- /**
- * 获取所有trigger
- * @param page
- * @param orderName
- * @param sortType
- * @return
- */
- List
- /**
- * 获取所有jobDetail
- *
- * @return
- */
- List
- /**
- * 执行Trigger操作
- *
- * @param name
- * @param group
- * @param action
- *
- */
- void executeTriggerAction(String name, String group, Integer action);
- /**
- * 执行JobDetail操作
- *
- * @param name
- * @param group
- * @param action
- *
- */
- void executeJobAction(String name, String group, Integer action);
- /**
- * 动态添加trigger
- *
- * @param jobName
- * @param jobGroup
- * @param triggerBean
- */
- void addTrigger(String jobName, String jobGroup, TriggerViewBean triggerBean);
- /**
- * 定时执行任务
- *
- * @param jobDetail
- * @param data
- */
- void addTriggerForDate(JobDetail jobDetail, String triggerName , String
- triggerGroup , Date date, Map
- /**
- * 获取分布式Scheduler列表
- *
- * @return
- */
- List
- /**
- * 获取触发器
- * @param name
- * @param group
- * @return
- */
- public Trigger getTrigger(String name, String group);
- /**
- * 获取JobDetail
- * @param name
- * @param group
- * @return
- */
- public JobDetail getJobDetail(String name, String group);
- }
3:在Spring配置job,trigger,Scheduler,Listener组件
Xml代码
- <bean id="accountStatusTaskScannerJobDetail"
- class="org.springframework.scheduling.quartz.JobDetailBean">
- <property name="name" value="accountStatusTaskScannerJobDetail">property>
- <property name="group" value="CrmAccountGroup">property>
- <property name="jobClass" value="***.crm.quartz.job.AccountStatusTaskScannerJob">property>
- <property name="requestsRecovery" value="true"/>
- <property name="durability" value="true"/>
- <property name="volatility" value="false">property>
- bean>
- <bean id="accountStatusTaskScannerTrigger" class="org.springframework.scheduling.quartz.CronTriggerBean">
- <property name="group" value="CrmDealGroup">property>
- <property name="name" value="accountStatusTaskScannerTrigger">property>
- <property name="jobDetail" ref="accountStatusTaskScannerJobDetail">property>
- <property name="cronExpression" value="0 0 1 * * ?">property>
- bean>
- <bean id="quartzExceptionSchedulerListener"
- class="***.crm.quartz.listener.QuartzExceptionSchedulerListener">bean>
- <bean id="quartzScheduler"
- class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
- <property name="quartzProperties">
- <props>
- <prop key="org.quartz.scheduler.instanceName">CRMschedulerprop>
- <prop key="org.quartz.scheduler.instanceId">AUTOprop>
- <prop key="org.quartz.threadPool.class">org.quartz.simpl.SimpleThreadPoolprop>
- <prop key="org.quartz.threadPool.threadCount">20prop>
- <prop key="org.quartz.threadPool.threadPriority">5prop>
- <prop key="org.quartz.jobStore.class">org.quartz.impl.jdbcjobstore.JobStoreTXprop>
- <prop key="org.quartz.jobStore.isClustered">falseprop>
- <prop key="org.quartz.jobStore.clusterCheckinInterval">15000prop>
- <prop key="org.quartz.jobStore.maxMisfiresToHandleAtATime">1prop>
- <prop key="org.quartz.jobStore.dataSource">myDSprop>
- <prop key="org.quartz.dataSource.myDS.driver">${database.driverClassName}prop>
- <prop key="org.quartz.dataSource.myDS.URL">${database.url}prop>
- <prop key="org.quartz.dataSource.myDS.user">${database.username}prop>
- <prop key="org.quartz.dataSource.myDS.password">${database.password}prop>
- <prop key="org.quartz.dataSource.myDS.maxConnections">5prop>
- <prop key="org.quartz.jobStore.misfireThreshold">120000prop>
- props>
- property>
- <property name="schedulerName" value="CRMscheduler" />
- <property name="startupDelay" value="30"/>
- <property name="applicationContextSchedulerContextKey" value="applicationContextKey" />
- <property name="overwriteExistingJobs" value="true" />
- <property name="autoStartup" value="true" />
- <property name="triggers">
- <list>
- <ref bean="dailyStatisticsTrigger" />
- <ref bean="accountGrabedScannerTrigger" />
- <ref bean="syncAccountFromPOITrigger" />
- <ref bean="userSyncScannerTrigger" />
- <ref bean="syncParentBranchFromPOITrigger"/>
- <ref bean="privateReminderTrigger" />
- <ref bean="onlineBranchesScannerTrigger" />
- <ref bean="syncCtContactServiceTrigger" />
- <ref bean="dealLinkDianpingScannerTrigger" />
- <ref bean="accountStatusTaskScannerTrigger"/>
- <ref bean="nDaysActivityScannerTrigger"/>
- list>
- property>
- <property name="jobDetails">
- <list>
- <ref bean="myTestQuartzJobDetail"/>
- <ref bean="accountPrivateToProtectedJobDetail"/>
- <ref bean="accountProtectedToPublicJobDetail"/>
- <ref bean="nDaysActivityToProtectedJobDetail"/>
- list>
- property>
- <property name="schedulerListeners">
- <list>
- <ref bean="quartzExceptionSchedulerListener"/>
- list>
- property>
- bean>
Crm目前可以做到对Quartz实例的监控,操作.动态部署Trigger
后续待开发功能和问题
1:目前实现对job,Trigger操作,动态部署Trigger,后续需要加入Calendar(排除特定日期),Listener(动态加载监控),Job的动态部署(只要bean的名称和方法名,就可完成对job生成,部署)
2:由于Quartz集群中的job目前是在任意一台server中执行,Quartz日志生成各自的系统目录中, quartz日志无法统一.
3:Quartz2.x已经支持可选节点执行job(期待Spring升级后对新Quartz支持)
4:Quartz内部的DB操作大量Trigger存在严重竞争问题,瞬间大量trigger执行,目前只能通过(org.quartz.jobStore.tablePrefix = QRTZ)分表操作,存在长时间lock_wait(新版本据说有提高);
5:如果有需要,可以抽取出Quartz,变成单独的服务,供其它系统调度使用使用