【浅记】分而治之
归并排序
算法流程:
- 将数组
A[1,n]排序问题分解为A[1,n/2]和A[n/2+1,n]排序问题 - 递归解决子问题得到两个有序的子数组
- 将两个子数组合并为一个有序数组
符合分而治之的思想:
- 分解原问题
- 解决子问题
- 合并问题解
递归式求解
递归树法
用树的形式表示抽象递归
T ( n ) = { 2 T ( n 2 ) + O ( n ) , i f n > 1 O ( 1 ) , i f n = 1 T(n)=\begin{cases} 2T(\frac{n}{2})+O(n), &if&n>1\\ O(1),&if&n=1 \end{cases} T(n)={2T(2n)+O(n),O(1),ififn>1n=1
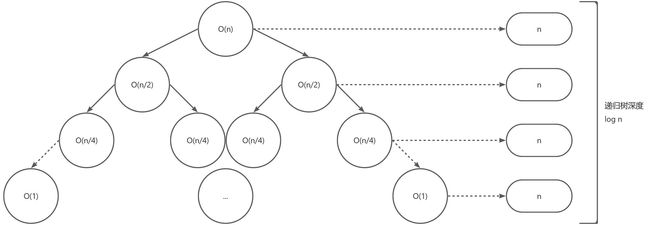
树的深度通常从0开始计,故层数等于n+1,后续统一用深度
可以得到,这个算法的时间复杂度是: T ( n ) = O ( n log n ) T(n)=O(n\log n) T(n)=O(nlogn)
主定理法
对形如 T ( n ) = a T ( n b ) + f ( n ) T(n)=aT(\frac{n}{b})+f(n) T(n)=aT(bn)+f(n)的递归式:
- 每个节点共
a个分支 - 每层以因子
b速度下降 - n log b a n^{\log_ba} nlogba代表每层叶子节点代价之和
可以得到如下公式:
KaTeX parse error: {align} can be used only in display mode.
当 f ( n ) f(n) f(n)形式为 n k n^k nk时,可简化主定理公式:
KaTeX parse error: {align} can be used only in display mode.
例: T ( n ) = 5 T ( n 2 ) + n 3 T(n)=5T(\frac{n}{2})+n^3 T(n)=5T(2n)+n3
- k = 3 k=3 k=3
- a = 5 , b = 2 , log b a = log 2 5 a=5,b=2,\log_ba=\log_25 a=5,b=2,logba=log25
- k > log b a k>\log_ba k>logba
- T ( n ) = Θ ( n 3 ) T(n)=\Theta(n^3) T(n)=Θ(n3)
最大子数组
基于枚举策略
蛮力枚举:枚举所有可能的情况
枚举 n + C n 2 n+C_n^2 n+Cn2种可能的区间 [ l , r ] , ( l < r ) [l,r],(l
优化枚举:蛮力枚举存在重复计算
S ( l , r ) = Σ i = 1 r X [ i ] = S ( l , r − 1 ) + X [ r ] S(l,r)=\Sigma_{i=1}^rX[i]=S(l,r-1)+X[r] S(l,r)=Σi=1rX[i]=S(l,r−1)+X[r],时间复杂度为 O ( n 2 ) O(n^2) O(n2)
分而治之
- 将数组 X [ 1.. n ] X[1..n] X[1..n]分为 X [ 1.. n / 2 ] X[1..n/2] X[1..n/2]和 X [ n / 2 + 1.. n ] X[n/2+1..n] X[n/2+1..n]
- 递归求解子问题:
- S 1 S_1 S1:数组 X [ 1.. n / 2 ] X[1..n/2] X[1..n/2]的最大子数组
- S 2 S_2 S2:数组 X [ n / 2 + 1.. n ] X[n/2+1..n] X[n/2+1..n]的最大子数组
- 合并子问题,得到 S m a x S_{max} Smax
- S 3 S_3 S3:跨中点的最大子数组
- 数组 X X X的最大子数组之和 S m a x = m a x { S 1 , S 2 , S 3 } S_{max}=max\{S_1,S_2,S_3\} Smax=max{S1,S2,S3}
问题在于,如何高效地求解 S 3 S_3 S3
- 记 m i d = n 2 mid=\frac n2 mid=2n
- S 3 S_3 S3可以分为左右两部分:
- L e f t Left Left:以 X [ m i d ] X[mid] X[mid]为结尾的最大子数组之和
- R i g h t Right Right:以 X [ m i d + 1 ] X[mid+1] X[mid+1]为开头的最大子数组之和
- S 3 = L e f t + R i g h t S_3=Left+Right S3=Left+Right
求解 S 3 S_3 S3的时间复杂度分析:
- 求解 L e f t Left Left:从 X [ m i d ] X[mid] X[mid]向前遍历求和,并记录最大值,时间复杂度为 O ( m i d ) O(mid) O(mid)
- 求解 R i g h t Right Right:从 X [ m i d + 1 ] X[mid+1] X[mid+1]向后遍历求和,并记录最大值,时间复杂度为 O ( n − m i d ) O(n-mid) O(n−mid)
- 求解 S 3 S_3 S3的时间复杂度: O ( n ) O(n) O(n)
伪代码:
输入:数组X,数组下标low,high
输出:最大子数组之和Smax
if low=high then
| return X[low]
end
else
| mid <- (low+high)/2
| S1 <- MaxSubArray(X,low,mid)
| S2 <- MaxSubArray(X,mid+1,high)
| S3 <- CrossingSubArray(X,low,mid,high)
| Smax <- Max(S1,S2,S3)
| return Smax
end
时间复杂度分析
$T(n)=
\left{
\begin{align}
&1,\quad&n=1\
&2T(\frac n2)+O(n),\quad&n>1
\end{align}
\right.
\$
按照上面提到的递归树求解的方法,可以得到: T ( n ) = n log n T(n)=n\log n T(n)=nlogn
逆序对计数
逆序对:当 i < j i
蛮力枚举
对于数组的每个元素 A [ i ] A[i] A[i],枚举 j ( j > i ) j(j>i) j(j>i),并统计逆序对数目。
伪代码:
输入:一个大小为n的数组A[1..n]
输出:数组A[1..n]中逆序对数目Sum
Sum <- 0
for i <- 1 to n do
| for j <- i+1 to n do
| | if A[i]>A[j] then
| | | Sum <- Sum+1
| | end
| end
end
return Sum
这一算法时间复杂度为 O ( n 2 ) O(n^2) O(n2)
分而治之
- 将数组 A [ 1.. n ] A[1..n] A[1..n]分为 A [ 1.. n 2 ] A[1..\frac n2] A[1..2n]和 A [ n 2 + 1.. n ] A[\frac n2+1..n] A[2n+1..n]
- 递归求解子问题
- S 1 S_1 S1:仅在 A [ 1.. n 2 ] A[1..\frac n2] A[1..2n]中的逆序对数目
- S 2 S_2 S2:仅在 A [ n 2 + 1.. n ] A[\frac n2+1..n] A[2n+1..n]中的逆序对数目
- 合并 A [ 1.. n ] A[1..n] A[1..n]分为 A [ 1.. n 2 ] A[1..\frac n2] A[1..2n]和 A [ n 2 + 1.. n ] A[\frac n2+1..n] A[2n+1..n]的解
- S 3 S_3 S3:跨越子数组的逆序对数目
- S = S 1 + S 2 + S 3 S=S_1+S_2+S_3 S=S1+S2+S3
策略一:直接求解
对每个 A [ j ] ∈ A [ m + 1 , n ] A[j]\in A[m+1,n] A[j]∈A[m+1,n],枚举 A [ i ] ∈ A [ 1.. m ] A[i]\in A[1..m] A[i]∈A[1..m]并统计逆序对数目。
求解 S 3 S_3 S3的算法运行时间: O ( n 2 ) O(n^2) O(n2)
分而治之框架的运行时间: T ( n ) = 2 T ( n 2 ) + O ( n 2 ) T(n)=2T(\frac n2)+O(n^2) T(n)=2T(2n)+O(n2)
直接求解的分而治之较蛮力枚举并未提高算法运行时间。
- 运行时间受制于跨越子数组的逆序对计数方法
- 数组的有序性通常有助于提高算法的运行时间
策略二:排序求解
- 分别对数组 A [ 1.. m ] A[1..m] A[1..m]和 A [ m + 1.. n ] A[m+1..n] A[m+1..n]进行排序
- 对于每个 A [ j ] ∈ A [ m + 1.. n ] A[j]\in A[m+1..n] A[j]∈A[m+1..n],采用二分查找为其在 A [ 1.. m ] A[1..m] A[1..m]中定位
- A [ j ] A[j] A[j]在 A [ 1.. m ] A[1..m] A[1..m]定位点右侧的元素均可与 A [ j ] A[j] A[j]构成逆序对
求解 S 3 S_3 S3的算法运行时间: O ( n log 2 n ) O(n\log^2 n) O(nlog2n)
分治框架的算法运行时间: T ( n ) = 2 T ( n 2 ) + O ( n log n ) T(n)=2T(\frac n2)+O(n\log n) T(n)=2T(2n)+O(nlogn)
算法优化
合并问题解的同时对数组进行排序
- 归并过程中可同时计算逆序对数目
策略三:归并求解
- 从左到右扫描有序子数组: A [ i ] ∈ A [ 1.. m ] , A [ j ] ∈ A [ m + 1.. n ] A[i]\in A[1..m],A[j]\in A[m+1..n] A[i]∈A[1..m],A[j]∈A[m+1..n]
- 如果 A [ i ] > A [ j ] A[i]>A[j] A[i]>A[j],统计逆序对, j j j向右移
- 如果 A [ i ] < A [ j ] A[i]
- 利用归并排序框架保证合并后数组的有序性
伪代码:
输入:数组A[1..n],数组下标left,right
输出:数组A[left..right]的逆序对数,递增数组A[left..right]
if left >= right then
| return A[left..right]
end
mid <-(left+right)/2
S1 <- CountInver(A,left,mid)
S2 <- CountInver(A,mid+1,right)
S3 <- MergeCount(A,left,mid,right)
S <- S1+S2+S3
return S,A[left..right]
时间复杂度: T ( n ) = O ( n log n ) T(n)=O(n\log n) T(n)=O(nlogn)
快速排序
归并排序:简化分解,侧重合并
快速排序:侧重分解,简化合并
数组划分
- 任选 x x x作为分界线,称为主元
- 交换重排,满足 x x x左侧元素小于右侧
实现方法:
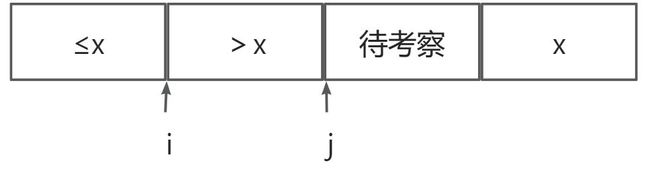
- 选取固定位置主元 x x x,如尾元素
- 维护两个指针变量,分别指向两个部分的右端点
- 考察数组元素 A [ j ] A[j] A[j],只和主元比较
- 若 A [ j ] ≤ x A[j]\leq x A[j]≤x,则交换 A [ j ] A[j] A[j]和 A [ i ] + 1 A[i]+1 A[i]+1, i i i与 j j j右移
- 若 A [ j ] > x A[j]> x A[j]>x,则 j j j右移
- 把主元放在中间作分界线
伪代码
Partition(A,p,r)
输入:数组A,起始位置p,终止位置r
输出:划分位置q
x <- A[r]//选取主元
i <- p-1
for j <- p to r-1 do
| if A[j] <= x then
| | exchange A[i+1] with A[j]
| | i <- i+1
| end
end
exchange A[i+1] with A[r]
q <- i+1
return q
快速排序的伪代码
输入:数组A,起始位置p,终止位置r
输出:有序数组A
if p最好情况: O ( n log n ) O(n\log n) O(nlogn)
最坏情况: O ( n 2 ) O(n^2) O(n2)
快速排序看似不优于归并排序。
次序选择问题
输入:
- 包含 n n n个不同元素的数组 A [ 1.. n ] A[1..n] A[1..n]
- 整数 k k k
输出:
- 数组 A [ 1.. n ] A[1..n] A[1..n]中第 k k k小的元素 ( 1 ≤ k ≤ n ) (1\leq k\leq n) (1≤k≤n)
固定位置划分求解
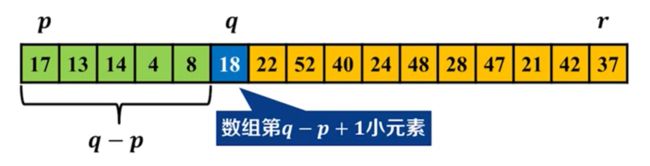
选取固定位置主元,小于主元的元素个数 q − p q-p q−p:
- 情况1: k = q − p + 1 k=q-p+1 k=q−p+1, A [ q ] A[q] A[q]为数组第 k k k小元素
- 情况2: k < q − p + 1 k
- 情况3: k > q − p + 1 k>q-p+1 k>q−p+1,在 A [ q + 1.. r ] A[q+1..r] A[q+1..r]中寻找第 k − ( q − p + 1 ) k-(q-p+1) k−(q−p+1)小元素
子问题始终唯一,无需合并问题解。
伪代码
输入:数组A,起始位置p,终止位置r,元素次序k
输出:第k小元素x
q <- Partition(A,p,r)
if k=(q-p+1) then
| x <- A[q]
end
if k<(q-p+1) then
| x <-Selection(A,p,q-1,k)
end
if k>(q-p+1) then
| x <- Selection(A,q+1,r,k-(q-p+1))
end
return x
复杂度分析:
最好情况: T ( n ) = Ω ( n ) T(n)=\Omega(n) T(n)=Ω(n)
期望时间复杂度: T ( n ) = Θ ( n ) T(n)=\Theta(n) T(n)=Θ(n)
最坏情况: T ( n ) = O ( n 2 ) T(n)=O(n^2) T(n)=O(n2)