11Spark
1.安装
anaconda
-
在官网上下载
anaconda linux后缀为.sh的安装包 -
运行
sh ./Anaconda3-2021.05-Linux-x86_64.sh -
安装过程:
输入yes后就安装完成了. -
验证:
安装完成后,
退出SecureCRT 重新进来:
看到这个base开头表明安装好了.
base是默认的虚拟环境,检查python是否安装成功

换源(推荐)
在jaken用户下:
vim ~/.condarc #新文件
#文件内容如下:
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
记得分发一下
创建并进入pyspark空间
conda create -n pyspark python=3.8

xsync /opt/module/anaconda3
Spark安装
下载
官网上下载最新的Spark3.3(hadoop最低版本为3.3)
进入pyspark空间
#解压到/opt/module/
tar -zxvf spark-3.3.0-bin-hadoop3.tgz -C /opt/module/
#由于spark目录名称很长, 给其一个软链接:
ln -s /opt/module/spark-3.3.0-bin-hadoop3/ /opt/module/spark

配置环境变量
- SPARK_HOME: 表示Spark安装路径在哪里
- PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器
- JAVA_HOME: 告知Spark Java在哪里
- HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里
- HADOOP_HOME: 告知Spark Hadoop安装在哪里
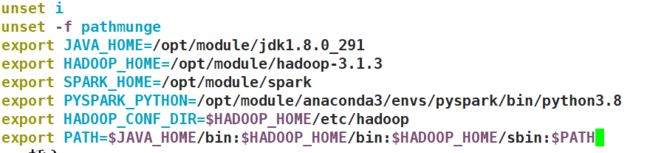
sudo vim /etc/profile
export JAVA_HOME=/opt/module/jdk1.8.0_291
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export SPARK_HOME=/opt/module/spark
export PYSPARK_PYTHON=/opt/module/anaconda3/envs/pyspark/bin/python3.8
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
注意高亮检查是否有误
PYSPARK_PYTHON和 JAVA_HOME 需要同样配置在: ~/.bashrc中
sudo vim ~/.bashrc
export JAVA_HOME=/opt/module/jdk1.8.0_291
export PYSPARK_PYTHON=/opt/module/anaconda3/envs/pyspark/bin/python3.8

分发配置文件
sudo xsync /etc/profile
xsync ~/.bashrc
修改Spark配置文件(指定worker master)
配置workers文件
# 修改文件名
mv workers.template workers
# 编辑worker文件
vim workers
# 将里面的localhost删除, 追加
hadoop102
hadoop103
hadoop104
到workers文件内
# 功能: 这个文件就是指示了 当前SparkStandAlone环境下, 有哪些worker
mv spark-env.sh.template spark-env.sh 改名
配置spark-env.sh文件
# 1. 改名
mv spark-env.sh.template spark-env.sh
# 2. 编辑spark-env.sh, 在底部追加如下内容
## 设置JAVA安装目录
JAVA_HOME=/opt/module/jdk1.8.0_291
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/opt/module/hadoop-3.1.3/etc/conf
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/conf
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=hadoop102
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的 webui端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu可用核数
SPARK_WORKER_CORES=2
# worker可用内存
SPARK_WORKER_MEMORY=6g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的 webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=false"
注意, 上面的配置的路径 要根据你自己机器实际的路径来写
在HDFS上创建程序运行历史记录存放的文件夹:
hadoop fs -mkdir /sparklog
hadoop fs -chmod 777 /sparklog
配置spark-defaults.conf文件
文件默认是注释模式,输入:set paste 在插入即可
# 1. 改名
mv spark-defaults.conf.template spark-defaults.conf
# 2. 修改内容, 追加如下内容
# 开启spark的日期记录功能
spark.eventLog.enabled true
# 设置spark日志记录的路径
spark.eventLog.dir hdfs://hadoop102:8020/sparklog/
# 设置spark日志是否启动压缩
spark.eventLog.compress true
配置log4j2.properties 文件 [不用改]
# 1. 改名
mv log4j2.properties.template log4j2.properties
# 2. 修改内容 参考下图
将Spark安装文件夹分发
注意检查
启动历史服务器
注意先在HDFS中创建日志存储的目录
sbin/start-history-server.sh
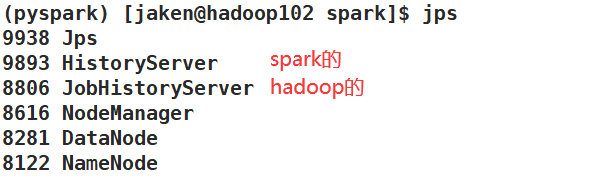
启动全部Spark集群
编写启动脚本:
# 启动全部master和worker
sbin/start-all.sh
# 或者可以一个个启动:
# 启动当前机器的master
sbin/start-master.sh
# 启动当前机器的worker
sbin/start-worker.sh
# 停止全部
sbin/stop-all.sh
# 停止当前机器的master
sbin/stop-master.sh
# 停止当前机器的worker
sbin/stop-worker.sh
结果如下:
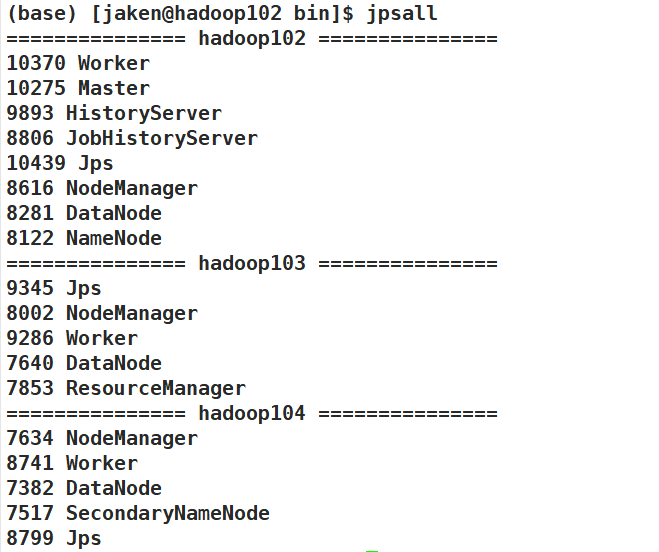
查看WEB-UI
![]()
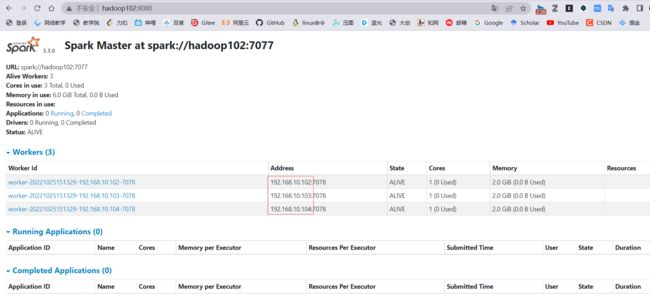
连接到StandAlone集群及测试
bin/pyspark
地址和端口号时WEB-UI中页面所显示的:
bin/pyspark --master spark://hadoop102:7077
# 通过--master选项来连接到 StandAlone集群,后面的地址为WEB-UI的地址
# 如果不写--master选项, 默认是local模式运行
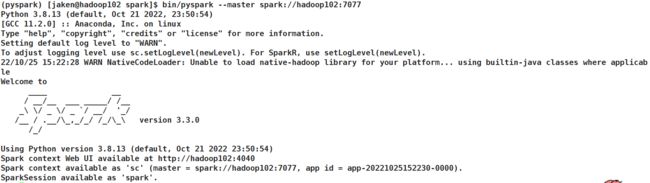
在命令行中编写Spark测试代码
sc.parallelize([1,2,3,4,5]).map(lambda x: x + 1).collect()
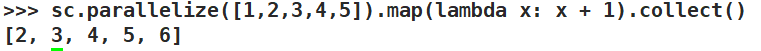
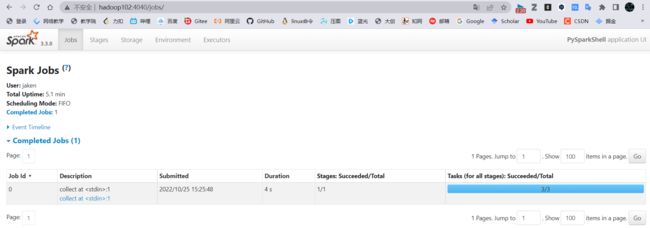
可以在APPID ->APP Detail下看到
bin/spark-submit (PI)
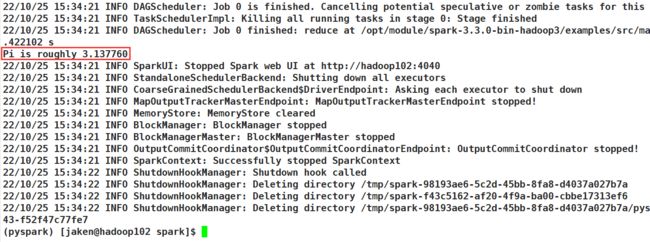
如果跑10000次,可以看到pi就十分接近了
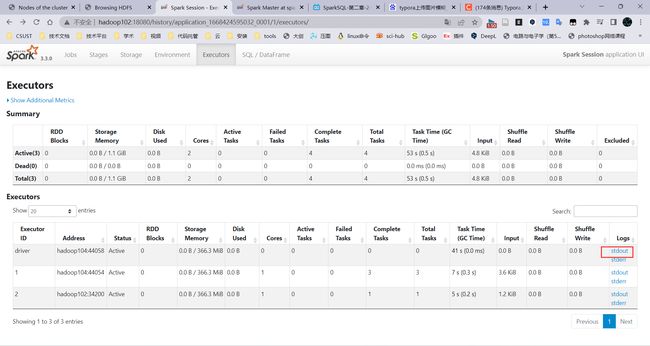
WEB-UI中:
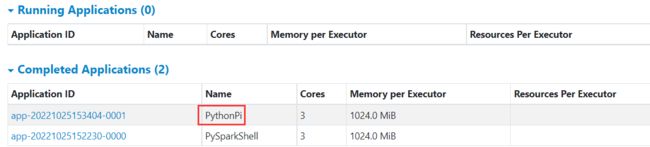
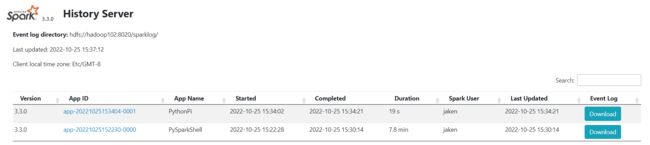
查看历史服务器WEB UI
http://hadoop102:18080
使用HDFS上的文件测试
sc.textFile("hdfs://hadoop102:8020/input/word.txt").flatMap(lambda line:line.split(" ")).map(lambda x:(x, 1)).reduceByKey(lambda a, b: a+b).collect()
注意端口号8020是沟通时的端口而不是web端口9870

2. HA模式
zookeeper环境搭建
具体可以参照CSDN教程,该教程为单个zookeeper场景:
集群环境搭建
我们搭建的是zookeeper服务器集群环境,具体客户端为spark
修改配置文件
vim /opt/module/zookeeper/conf/zoo.cfg
加入如下内容(注意每行后面没有空格):
server.102=hadoop102:2888:3888
server.103=hadoop103:2888:3888
server.104=hadoop104:2888:3888
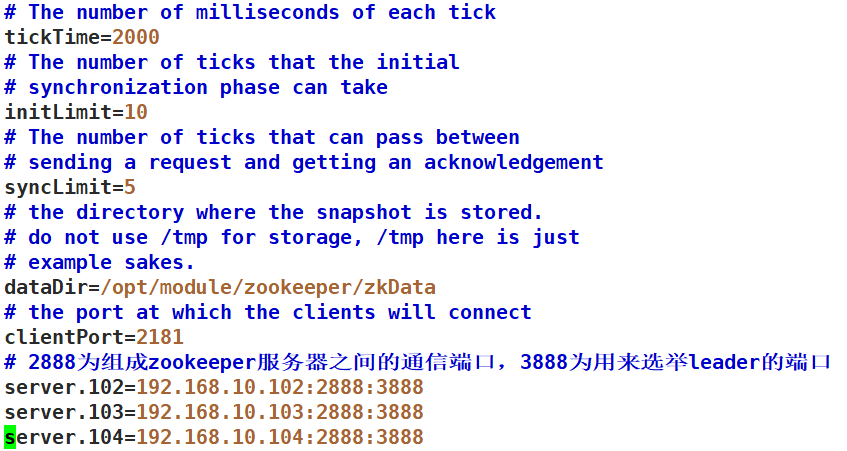
其中102,103,104为指定的机器序号,可以任意指定但必须唯一,用来标识
分发配置
修改spark配置文件
先在spark-env.sh中, 删除: SPARK_MASTER_HOST=hadoop102
原因: 配置文件中固定master是谁, 那么就无法用到zk的动态切换master功能了.
在spark-env.sh中, 增加:2181为zk的客户端端口
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop102:2181,hadoop103:2181,hadoop104:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
# spark.deploy.recoveryMode 指定HA模式 基于Zookeeper实现
# 指定Zookeeper的连接地址
# 指定在Zookeeper中注册临时节点的路径
在zkData文件夹中创建myid文件,三台虚拟机分配输入配置文件指定的机器序号
![]()
![]()
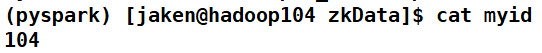
启动zookeeper集群
在每台机器zookeeper/bin路径下输入
zkServer.sh start
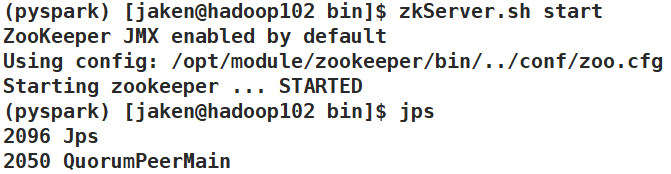
查看状态,有leader和follower:
zkServer.sh status


启动脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 Spark集群 ==================="
echo " --------------- 进入 pyspark空间 ---------------"
ssh hadoop102 "conda activate pyspark"
ssh hadoop103 "conda activate pyspark"
ssh hadoop104 "conda activate pyspark"
echo " --------------- 启动 Zookeeper ---------------"
ssh hadoop102 "/opt/module/zookeeper/bin/zkServer.sh start"
ssh hadoop103 "/opt/module/zookeeper/bin/zkServer.sh start"
ssh hadoop104 "/opt/module/zookeeper/bin/zkServer.sh start"
echo " --------------- 启动 Spark ---------------"
ssh hadoop102 "/opt/module/spark/sbin/start-all.sh"
echo " ------------- 启动 hadoop103备用master -------------"
ssh hadoop103 "/opt/module/spark/sbin/start-master.sh"
echo " --------------- 启动 Spark历史服务器 ---------------"
ssh hadoop102 "/opt/module/spark/sbin/start-history-server.sh"
echo " =================== 启动完毕 ==================="
;;
"stop")
echo " =================== 关闭 Spark集群 ==================="
echo " --------------- 关闭 Spark历史服务器 ---------------"
ssh hadoop102 "/opt/module/spark/sbin/stop-history-server.sh"
echo " ------------- 关闭 hadoop103备用master -------------"
ssh hadoop103 "/opt/module/spark/sbin/stop-master.sh"
echo " --------------- 关闭 Spark ---------------"
ssh hadoop102 "/opt/module/spark/sbin/stop-all.sh"
echo " --------------- 关闭 Zookeeper ---------------"
ssh hadoop102 "/opt/module/zookeeper/bin/zkServer.sh stop"
ssh hadoop103 "/opt/module/zookeeper/bin/zkServer.sh stop"
ssh hadoop104 "/opt/module/zookeeper/bin/zkServer.sh stop"
;;
*)
echo "Input Args Error..."
;;
esac
关机脚本
在hadoop102上执行
#!/bin/bash
echo " --------------- 关闭 hadoop104 ---------------"
ssh hadoop104 "sudo poweroff"
echo " --------------- 关闭 hadoop103 ---------------"
ssh hadoop103 "sudo poweroff"
echo " --------------- 关闭 hadoop102 ---------------"
ssh hadoop102 "sudo poweroff"
测试
zookeeper占用了端口8080,会顺延端口号到8081
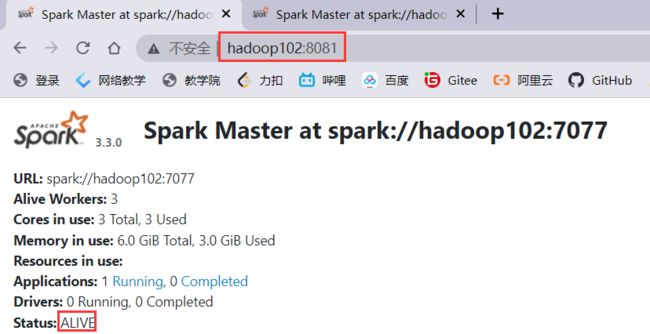
查看备用master,会被顺延到8082,处于
备用状态
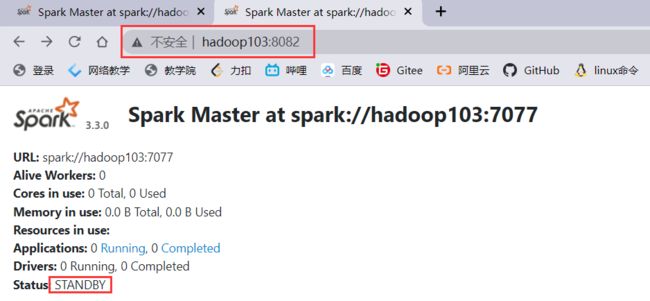
在hadoop103上提交任务后
bin/spark-submit --master spark://hadoop102:7077 /opt/module/spark/examples/src/main/python/pi.py 1000
在hadoop102上杀死master节点

可以看到
hadoop102挂了:
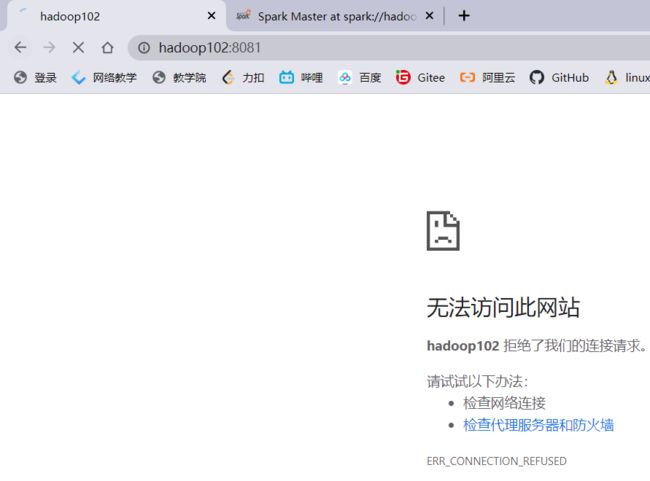
hadoop103变成活跃状态,并且顺利完成了任务
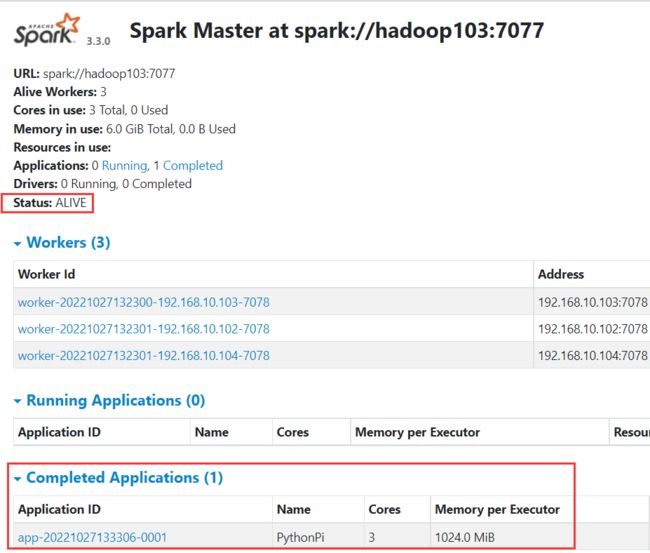
复活hadoop102 master,可以看到它现在成为备用master
/opt/module/spark/sbin/start-master.sh
3.Spark on yarn(spark-submit直接提交即可)
检查环境变量
vim /opt/module/spark/conf/spark-env.sh

虚拟内存爆满问题
在yarn上跑bin/pyspark时出现内存爆满的问题
running 24066560B beyond the 'VIRTUAL' memory limit. Current usage: 335.1 MB of 1 GB physical mem
参考博客
可以看到是虚拟内存超标了,所以可以关掉虚拟内存检查
修改hadoop中的yarn-site.xml文件
加入以下内容
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
成功!
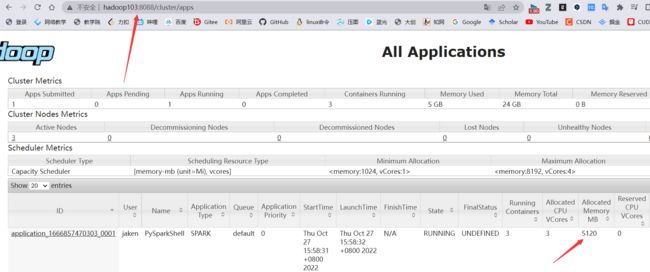
client模式
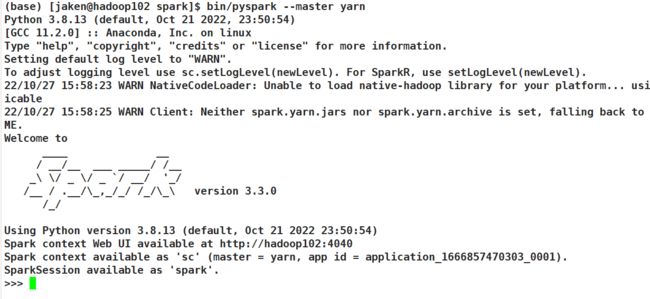
(base) [jaken@hadoop102 spark]$ bin/spark-submit --master yarn --deploy-mode client /opt/module/spark/examples/src/main/python/pi.py 100
使用client模式,在spark的历史服务器中确实是看不到日志的;日志都在shell中输出了
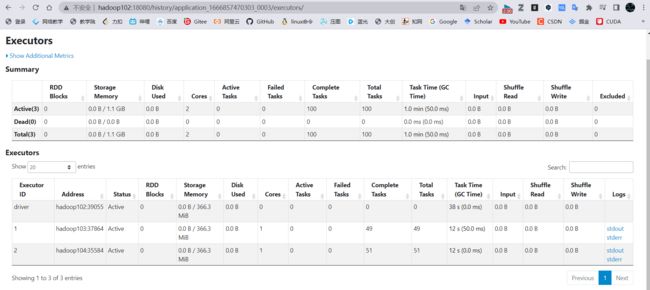
cluster模式
(base) [jaken@hadoop102 spark]$ bin/spark-submit --master yarn --deploy-mode cluster /opt/module/spark/examples/src/main/python/pi.py 100
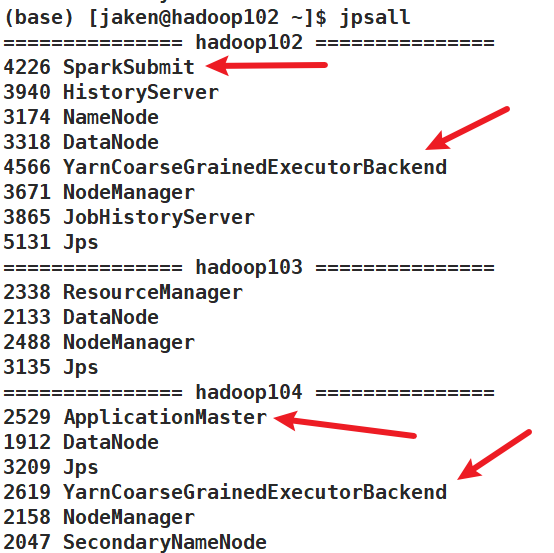
cluster模式下,是有日志记录的
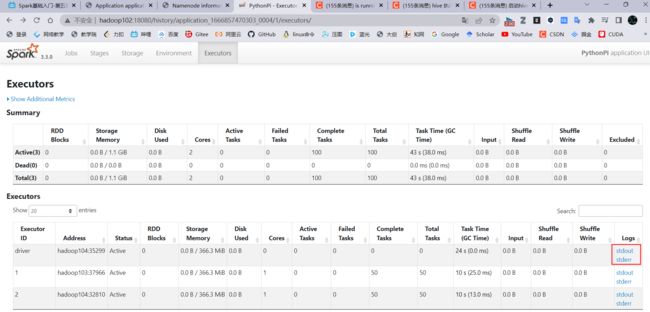
在yarn中也能看到
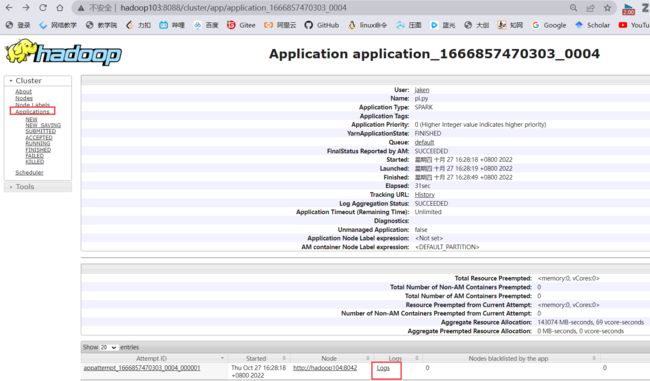
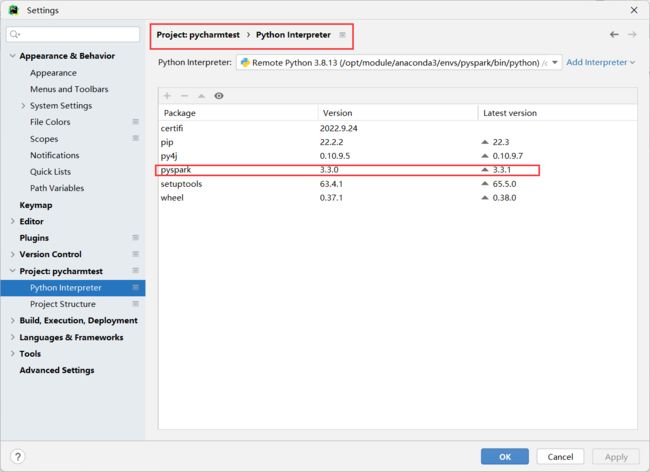
4.pyspark on pycharm
教学视频
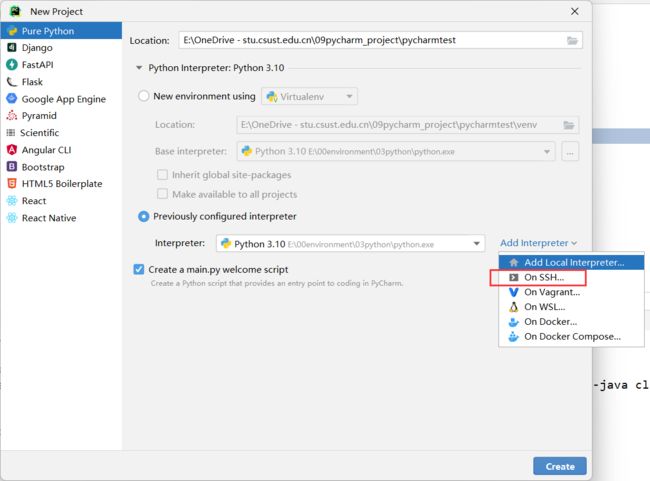
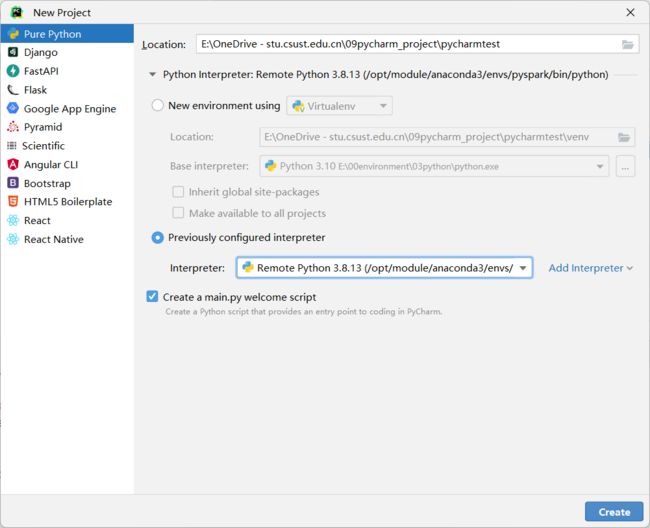
windows下的pycharm可以使用Linux中的pyspark环境,操作步骤如下:
添加接口
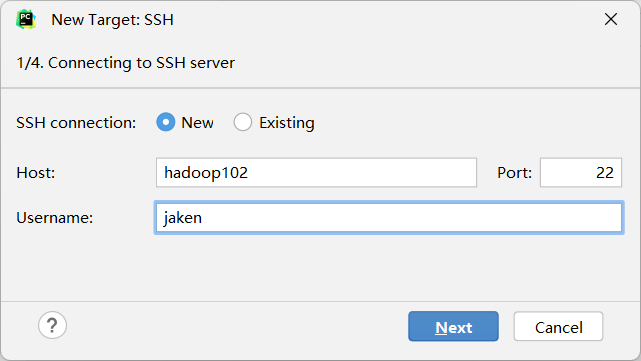
输入linux的用户名和密码
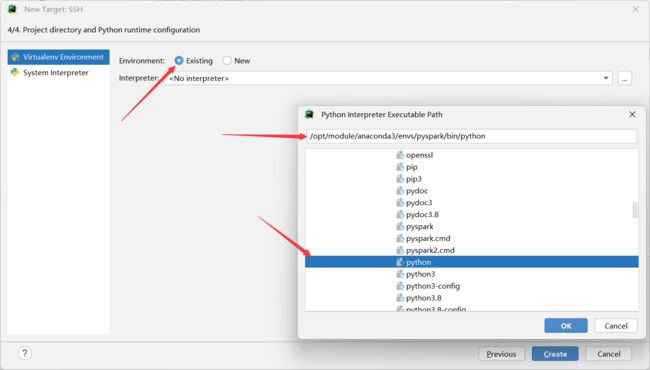
选择anaconda中的环境,点击create
就可以在页面查看刚才创建的接口环境,点击create
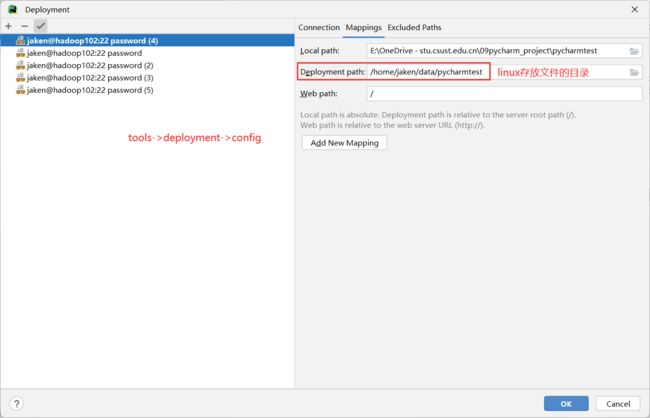
设置Linux同步的目录;开启Windows和Linux文件自动同步
也可以手动刷新
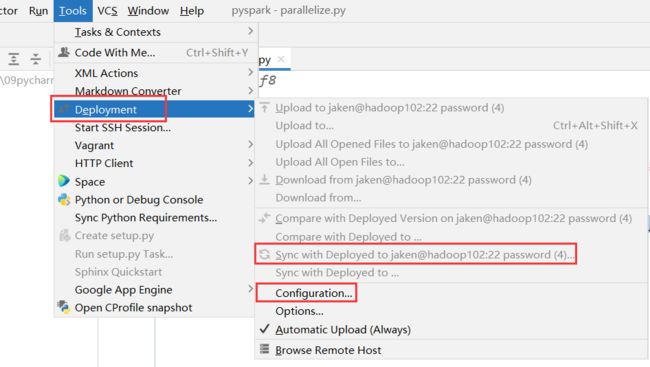
看到pyspark即可
5.Spark SQL

sparkSession入口对象
将文件传输到hdfs上,然后通过在pycharm中使用spark-submit的方式提交代码:

# coding:utf8
from pyspark.sql import SparkSession
if __name__ == '__main__':
spark = SparkSession.builder. \
appName("Spark Session").getOrCreate()
sc = spark.sparkContext
df = spark.read.csv("hdfs://hadoop102:8020/stu_score.txt", sep=',', header=False)
df2 = df.toDF("id", "name", "score")
# 打印表结构
df2.printSchema()
df2.show()
print("===========")
# 生成表
df2.createTempView("score")
#使用 SQL风格
spark.sql("""
SELECT * FROM score where name='语文' limit 5
""").show()
#DSL风格
df2.where("name='语文'").limit(5).show()
查看结果

DataFrame组成

- StructType:整个表的结构信息
- StructField:单个列的信息
- Column:StructField+单列的数据

DataFrame创建
反正记得创建DataFrame的,无论使用那种方式都需要指明DF的列名称
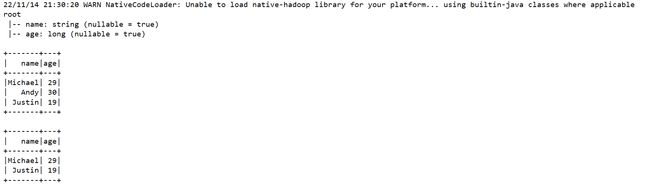
RDD_1:直接创建
#people.txt中的内容
Michael, 29
Andy, 30
Justin, 19
from pyspark.sql import SparkSession
if __name__ == '__main__':
spark = SparkSession.builder.master("local[*]").appName("create_by_RDD").getOrCreate()
sc = spark.sparkContext
rdd = sc.textFile("../sql/people.txt"). \
map(lambda x: x.split(",")). \
map(lambda x: (x[0], int(x[1]))) # 将第二个属性做类型转换
# 指定列名称
df = spark.createDataFrame(rdd, schema=['name', 'age'])
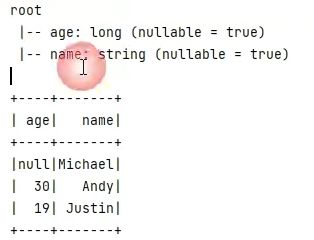
df.printSchema()
df.show()
# 创建一个临时表
df.createTempView("ttt")
spark.sql("select * from ttt where age<30").show()
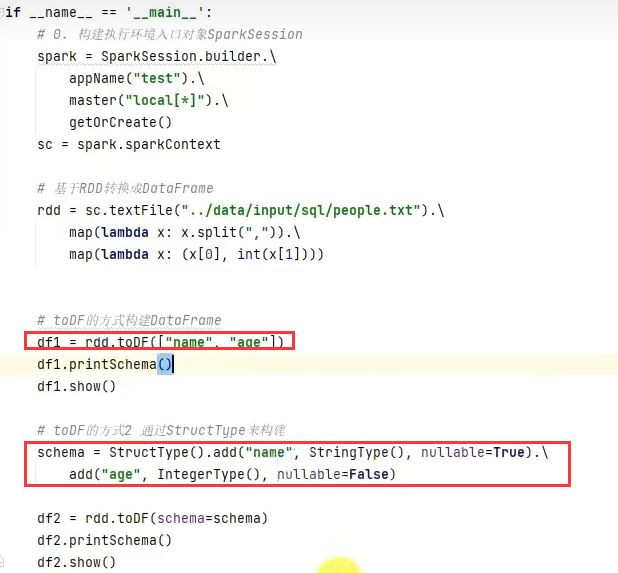
RDD_2:StructType()
from pyspark.sql import SparkSession
from pyspark.sql.types import StringType, IntegerType, StructType
if __name__ == '__main__':
spark = SparkSession.builder.master("local[*]").appName("create_by_RDD").getOrCreate()
sc = spark.sparkContext
rdd = sc.textFile("../sql/people.txt"). \
map(lambda x: x.split(",")). \
map(lambda x: (x[0], int(x[1]))) # 将第二个属性做类型转换
# 第一种构建方式,并没有指定类型
# df = spark.createDataFrame(rdd, schema=['name', 'age'])
# df.printSchema()
# df.show()
# 创建一个临时表
# df.createTempView("ttt")
# spark.sql("select * from ttt where age<30").show()
# 第二种构建方式 使用StructType类,定义整个DataFrame中的Schema
# add :列名称 列类型 是否允许为空
schema = StructType(). \
add("name", StringType(), nullable=False). \
add("age", IntegerType(), nullable=False)
df = spark.createDataFrame(rdd, schema)
df.printSchema()
df.show()
df.createTempView("ttt")
spark.sql("select * from ttt where age<30").show()
RDD_3 :toDF
pandas
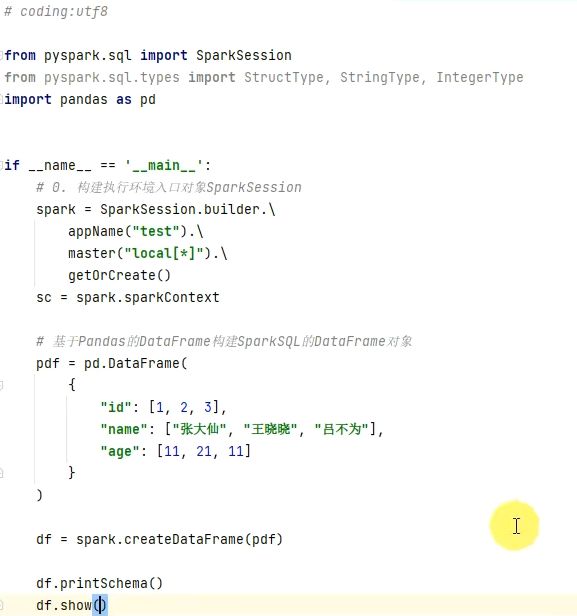
DataFrame代码构建-读取外部文件

读取tet数据源
代码
注意默认text是将一行数据只作为一列,默认列名是value
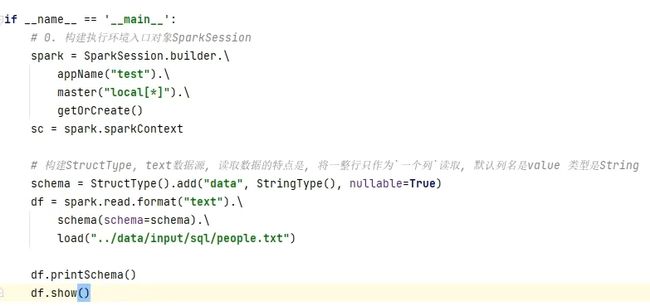
结果
读取json数据源
代码
结果
读取csv数据源

读取parquet数据源
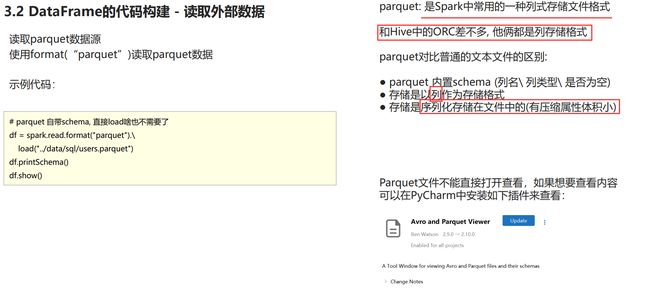
结果

插件avro and parquet viewer可以直接查看parquet文件
DataFrame入门操作

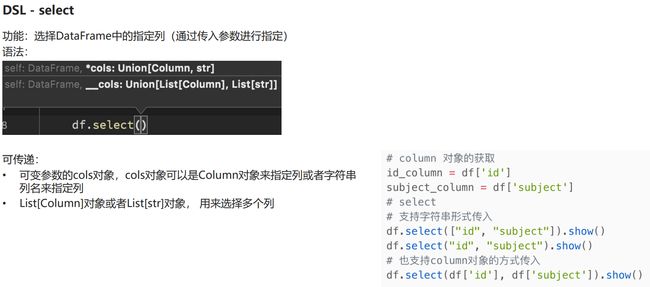
DSL风格
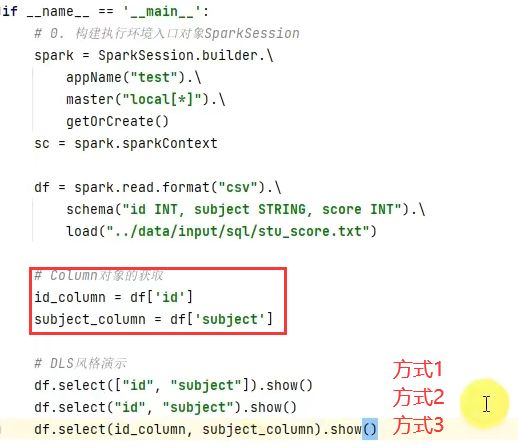
select
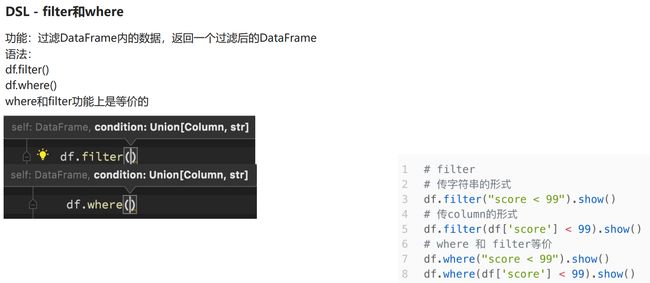
filter and where
groupBy

注意:需要在groupBy后接上 count/sum/avg/min/max聚合方法才能够转换成DataFrame对象
SQL风格

示例:注意global

WordCount案例
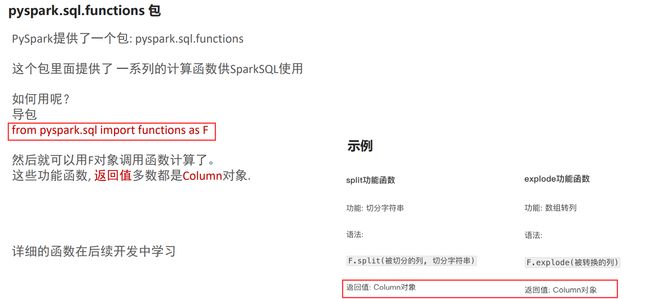
from pyspark.sql import functions as F
from pyspark.sql import SparkSession
if __name__ == '__main__':
spark = SparkSession.builder.appName("WordCount").master("local[*]").getOrCreate()
sc = spark.sparkContext
# TODO 1:使用RDD转换成DF,使用SQL风格
rdd = sc.textFile("../sql/word.txt").flatMap(lambda x: x.split(" ")). \
map(lambda x: [x])
# RDD 转 DF
df = rdd.toDF(["word"])
# 创建表格
df.createTempView("words")
spark.sql("select word , count(*) as cnt from words group by word order by cnt desc").show()
# TODO 2 : DSL风格处理
df = spark.read.format("text").load("../sql/word.txt")
# withColomn 方法对已存在的列进行操作,返回一个新的列,如果新列的名字和老列的名字一样,则替换掉老列
# text读取方式,列名默认是value,存储的数据为[word1 word2 ...]
# F.split("value", " ")将value列进行拆分,存储的数据为[word1,word2...]
# F.explode(F.split("value", " "))将数组里的数据炸出来,最终效果为
# word1
# word2
df2 = df.withColumn("value", F.explode(F.split("value", " ")))
# groupBy("value").count()会生成一个count列
df2.groupBy("value").count(). \
withColumnRenamed("value", "word").withColumnRenamed("count", "cnt"). \
orderBy("cnt", ascending=False).\
show()
结果

Movie案例
from pyspark.sql.types import StructType, StringType, IntegerType
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
if __name__ == '__main__':
spark = SparkSession.builder.appName("movie").master("local[*]").getOrCreate()
# 定义表的结构及属性
schema = StructType(). \
add("user_id", StringType(), nullable=True). \
add("movie_id", IntegerType(), nullable=True). \
add("rank", IntegerType(), nullable=True). \
add("ts", StringType(), nullable=True)
# 加载csv文件,注意option("sep", "\t"):"\t"不能有空格
df = spark.read.format("csv"). \
option("sep", "\t"). \
option("header", False). \
option("encoding", "utf-8"). \
schema(schema=schema). \
load("../sql/u.data")
df.show()
# 计算用户平均分,使用sql 很简单
df.createTempView("movie")
spark.sql("""
select user_id , round(avg(rank),2) as avg_rank from movie group by user_id order by avg_rank desc
""").show()
# 计算电影的平均分
spark.sql("""
select movie_id ,round (avg(rank),2) as avg_rank from movie group by movie_id order by avg_rank desc
""").show()
# 查询大于平均分的电影数量: select(F.avg(df['rank'])).first()取出生成的平均值,是一个row对象,它只有一列,使用['avg(rank)']取出
print(df.where(df['rank'] > df.select(F.avg(df['rank'])).first()['avg(rank)']).count())
# sql方法 使用子查询(不推荐使用,查询速度慢)
spark.sql("""
select movie_id,count(*) as upper_movie_count,avg(rank) as movie_score from movie where rank > (select avg(rank) from movie) group by movie_id order by movie_score desc
""").show()
# sql方法 使用连表查询
spark.sql("""
select movie_id,count(*) as upper_movie_count,avg(rank) as movie_score
from movie t1,
(
select avg(rank) as avg_score from movie
) t2
where t1.rank>t2.avg_score
group by t1.movie_id
order by movie_score desc
""").show()
连表查询的基本思路为:
- 第一个表为你要查询的数据
- 第二个表为你要比较的数据,实质上还是在查第一个表
结果
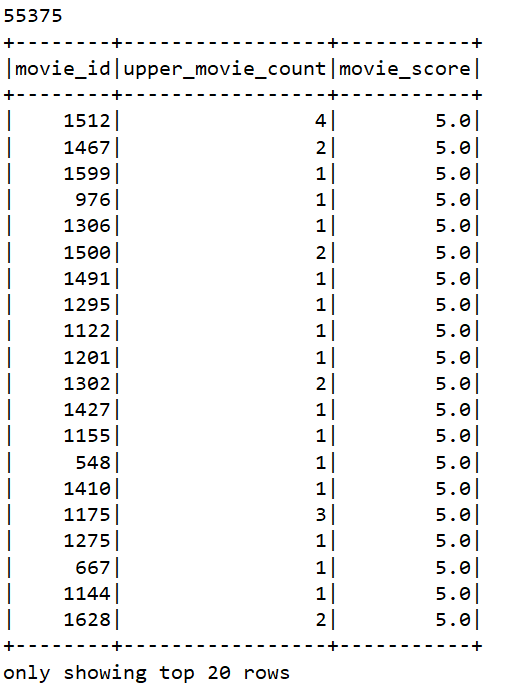
# TODO 4: 查询高分电影中(>3)打分次数最多的用户, 此人打分的平均分
# 先找出这个人
user_id = df.where("rank > 3").\
groupBy("user_id").\
count().\
withColumnRenamed("count", "cnt").\
orderBy("cnt", ascending=False).\
limit(1).\
first()['user_id']
# 计算这个人的打分平均分
df.filter(df['user_id'] == user_id).\
select(F.round(F.avg("rank"), 2)).show()
# TODO 5: 查询每个用户的平局打分, 最低打分, 最高打分
# agg的作用是可以使用多个聚合函数(avg/min/max),alias设置别名
df.groupBy("user_id").\
agg(
F.round(F.avg("rank"), 2).alias("avg_rank"),
F.min("rank").alias("min_rank"),
F.max("rank").alias("max_rank")
).show()
# TODO 6: 查询评分超过100次的电影, 的平均分 排名 TOP10
df.groupBy("movie_id").\
agg(
F.count("movie_id").alias("cnt"),
F.round(F.avg("rank"), 2).alias("avg_rank")
).where("cnt > 100").\
orderBy("avg_rank", ascending=False).\
limit(10).\
show()
"""
1. agg: 它是GroupedData对象的API, 作用是 在里面可以写多个聚合
2. alias: 它是Column对象的API, 可以针对一个列 进行改名
3. withColumnRenamed: 它是DataFrame的API, 可以对DF中的列进行改名, 一次改一个列, 改多个列 可以链式调用
4. orderBy: DataFrame的API, 进行排序, 参数1是被排序的列, 参数2是 升序(True) 或 降序 False
5. first: DataFrame的API, 取出DF的第一行数据, 返回值结果是Row对象.
# Row对象 就是一个数组, 你可以通过row['列名'] 来取出当前行中, 某一列的具体数值. 返回值不再是DF 或者GroupedData 或者Column而是具体的值(字符串, 数字等)
"""
Shuffle
我在本地运行没有出现这种情况。
分区的数量可以通过config设定
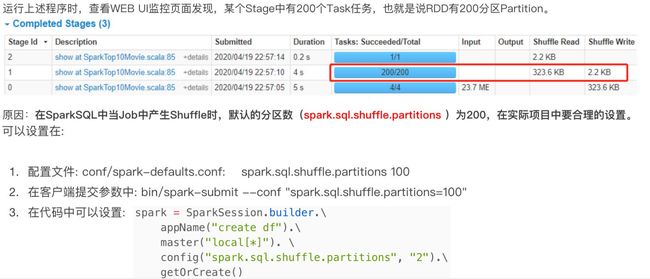
数据清洗df.dropna
# 数据清洗: 缺失值处理
# dropna api是可以对缺失值的数据进行删除
# 无参数使用, 只要列中有null 就删除这一行数据
df.dropna().show()
# thresh = 3表示, 最少满足3个有效列, 不满足 就删除当前行数据
df.dropna(thresh=3).show()
#特定列为空就清除
df.dropna(thresh=2, subset=['name', 'age']).show()
数据填充df.fillna
# DataFrame的 fillna 对缺失的列进行填充,为空的都填充为loss
df.fillna("loss").show()
# 指定列进行填充
df.fillna("N/A", subset=['job']).show()
# 设定一个字典, 对所有的列 提供填充规则
df.fillna({"name": "未知姓名", "age": 1, "job": "worker"}).show()
数据写出

# coding:utf8
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName("test").\
master("local[*]").\
config("spark.sql.shuffle.partitions", 2).\
getOrCreate()
sc = spark.sparkContext
# 1. 读取数据集
schema = StructType().add("user_id", StringType(), nullable=True). \
add("movie_id", IntegerType(), nullable=True). \
add("rank", IntegerType(), nullable=True). \
add("ts", StringType(), nullable=True)
df = spark.read.format("csv"). \
option("sep", "\t"). \
option("header", False). \
option("encoding", "utf-8"). \
schema(schema=schema). \
load("../../sql/u.data")
# Write text 写出, 只能写出一个列的数据, 需要将df转换为单列df
# 通过分割符---将这四个列拼接成一个列
df.select(F.concat_ws("---", "user_id", "movie_id", "rank", "ts")).\
write.\
mode("overwrite").\
format("text").\
save("../../sql/text")
# Write csv
df.write.mode("overwrite").\
format("csv").\
option("sep", ";").\
option("header", True).\
save("../../sql/csv")
# Write json
df.write.mode("overwrite").\
format("json").\
save("../../sql/json")
# Write parquet
df.write.mode("overwrite").\
format("parquet").\
save("../../sql/parquet")
结果
将远程的文件下载到本地:

DataFrame使用JDBC(mysql)
安装mysql for linux
参考博客
加入连接jar包
在linux运行环境进入这个目录,导入mysql的链接jar包:
/opt/module/anaconda3/envs/pyspark/lib/python3.8/site-packages/pyspark/jars
![]()
编写代码
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName("test").\
master("local[*]").\
config("spark.sql.shuffle.partitions", 2).\
getOrCreate()
sc = spark.sparkContext
# 1. 读取数据集
schema = StructType().add("user_id", StringType(), nullable=True). \
add("movie_id", IntegerType(), nullable=True). \
add("rank", IntegerType(), nullable=True). \
add("ts", StringType(), nullable=True)
df = spark.read.format("csv"). \
option("sep", "\t"). \
option("header", False). \
option("encoding", "utf-8"). \
schema(schema=schema). \
load("../../sql/u.data")
# 1. 写出df到mysql数据库中
df.write.mode("overwrite").\
format("jdbc").\
option("url", "jdbc:mysql://hadoop102:3306/bigdata?useSSL=false&useUnicode=true").\
option("dbtable", "movie_data").\
option("user", "root").\
option("password", "05200570").\
save()
#2. 从mysql中读入
df2 = spark.read.format("jdbc"). \
option("url", "jdbc:mysql://hadoop102:3306/bigdata?useSSL=false&useUnicode=true"). \
option("dbtable", "movie_data"). \
option("user", "root"). \
option("password", "05200570"). \
load()
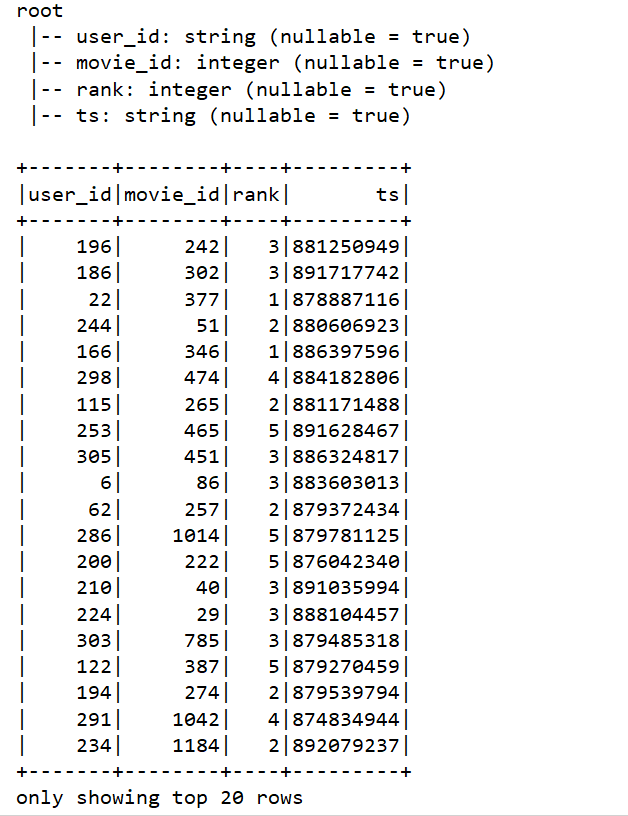
df2.printSchema()
df2.show()
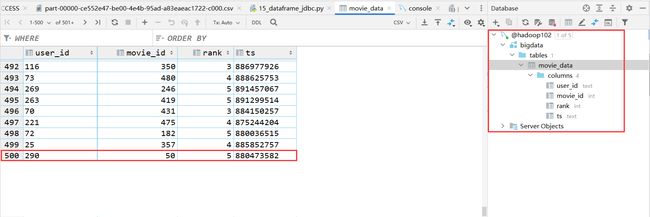
结果
- 写出
- 读入
UDF 自定义函数一对一

示例1:返回值IntegerType
# coding:utf8
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder. \
appName("test"). \
master("local[*]"). \
config("spark.sql.shuffle.partitions", 2). \
getOrCreate()
sc = spark.sparkContext
# 构建一个RDD
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7]).map(lambda x: [x])
df = rdd.toDF(["num"])
# TODO 1: 方式1 sparksession.udf.register(), DSL和SQL风格均可以使用
# UDF的处理函数
def num_ride_10(num):
return num * 10
# 参数1: 注册的UDF的名称, 这个udf名称, 仅可以用于 SQL风格
# 参数2: UDF的处理逻辑, 是一个单独的方法
# 参数3: 声明UDF的返回值类型, 注意: UDF注册时候, 必须声明返回值类型, 并且UDF的真实返回值一定要和声明的返回值一致
# 返回值对象: 这是一个UDF对象, 仅可以用于 DSL 语法
# 当前这种方式定义的UDF, 可以通过参数1的名称用于SQL风格, 通过返回值对象用户DSL风格
# 注意================================
# 一般`变量名`=`udf名称`,这里只是为了区别是要使用返回值对象才可以是用DSL风格
udf2 = spark.udf.register("udf1", num_ride_10, IntegerType())
# SQL风格中使用
# selectExpr 以SELECT的表达式执行, 表达式 SQL风格的表达式(字符串)
# select方法, 接受普通的字符串字段名, 或者返回值是Column对象的计算
df.selectExpr("udf1(num)").show()
# DSL 风格中使用
# 返回值UDF对象 如果作为方法使用, 传入的参数 一定是Column对象
df.select(udf2(df['num'])).show()
# TODO 2: 方式2注册, 仅能用于DSL风格
udf3 = F.udf(num_ride_10, IntegerType())
df.select(udf3(df['num'])).show()
# 下面调用失败
# df.selectExpr("udf3(num)").show()
示例2:返回值ArrayType
# coding:utf8
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, ArrayType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName("test").\
master("local[*]").\
config("spark.sql.shuffle.partitions", 2).\
getOrCreate()
sc = spark.sparkContext
# 构建一个RDD
rdd = sc.parallelize([["hadoop spark flink"], ["hadoop flink java"]])
df = rdd.toDF(["line"])
# 注册UDF, UDF的执行函数定义
def split_line(data):
return data.split(" ") # 返回值是一个Array对象
# TODO1 方式1 构建UDF
udf2 = spark.udf.register("udf1", split_line, ArrayType(StringType()))
# DLS风格
df.select(udf2(df['line'])).show()
# SQL风格,首先需要创建临时表
df.createTempView("lines")
# truncate=False表示表格有多长就显示多长
spark.sql("SELECT udf1(line) FROM lines").show(truncate=False)
# TODO 2 方式2的形式构建UDF
udf3 = F.udf(split_line, ArrayType(StringType()))
df.select(udf3(df['line'])).show(truncate=False)
示例3:返回值字典(dictionary)
# coding:utf8
import string
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, ArrayType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder. \
appName("test"). \
master("local[*]"). \
config("spark.sql.shuffle.partitions", 2). \
getOrCreate()
sc = spark.sparkContext
# 假设 有三个数字 1 2 3 我们传入数字 ,返回数字所在序号对应的 字母 然后和数字结合形成dict返回
# 比如传入1 我们返回 {"num":1, "letters": "a"}
rdd = sc.parallelize([[1], [2], [3]])
df = rdd.toDF(["num"])
# 注册UDF
# string.ascii_letters[data]返回的是数字对应的字母
def process(data):
return {"num": data, "letters": string.ascii_letters[data]}
"""
UDF的返回值是字典的话, 需要用StructType来接收,相当于把上述的字典看成一个两列的表
"""
udf1 = spark.udf.register("udf1", process, StructType().add("num", IntegerType(), nullable=True). \
add("letters", StringType(), nullable=True))
df.selectExpr("udf1(num)").show(truncate=False)
df.select(udf1(df['num'])).show(truncate=False)
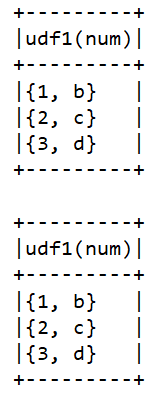
UDAF自定义聚合函数多对一
note
python 目前并不能直接定义UDAF,只能通过RDD的mapPartitions算子定义
# coding:utf8
import string
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, ArrayType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder. \
appName("test"). \
master("local[*]"). \
config("spark.sql.shuffle.partitions", 2). \
getOrCreate()
sc = spark.sparkContext
# rdd 的分区数为3
rdd = sc.parallelize([1, 2, 3, 4, 5], 3)
df = rdd.map(lambda x: [x]).toDF(['num'])
# 折中的方式 就是使用RDD的mapPartitions 算子来完成聚合操作
# 如果用mapPartitions API 完成UDAF聚合, 一定要单分区,且该rdd中存放的是一个个row对象
single_partition_rdd = df.rdd.repartition(1)
def process(iter):
sum = 0
for row in iter:
# rdd中存放的是一个个row对象,所以需要使用row将数据取出来
sum += row['num']
return [sum] # 一定要嵌套list, 因为mapPartitions方法要求的返回值是list对象
print(single_partition_rdd.mapPartitions(process).collect())
窗口函数

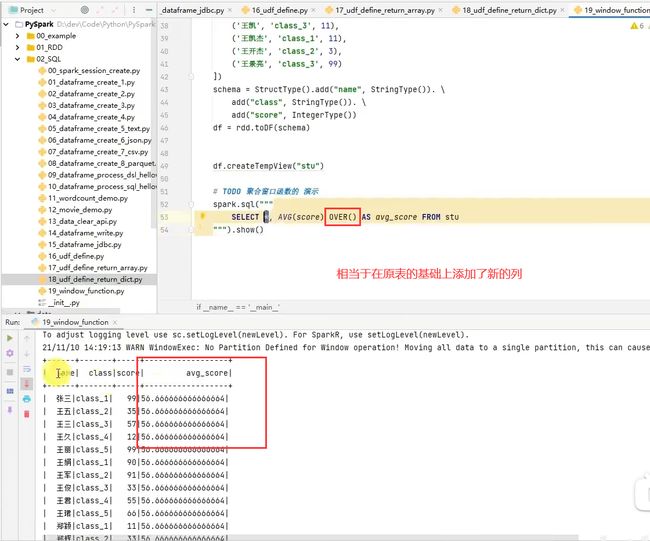
聚合窗口函数
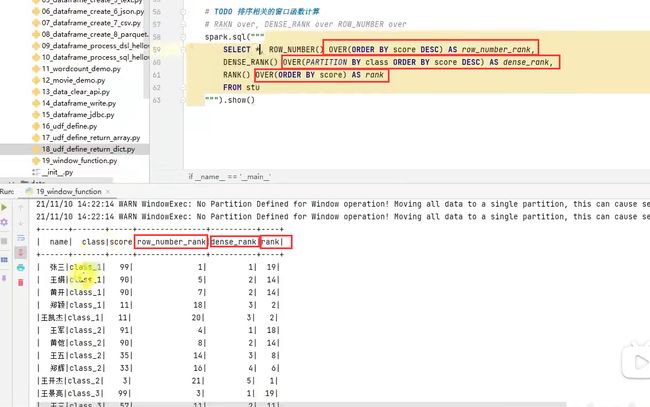
排序窗口函数
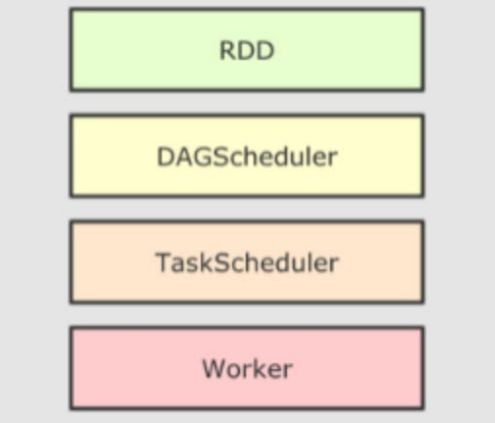
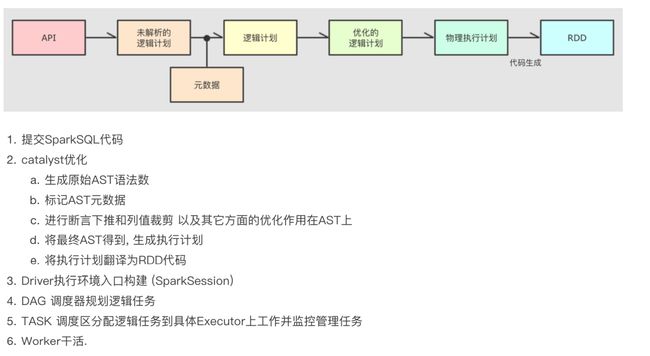
Spark SQL运行流程
RDD回顾
DAG调度器生成内存管道、DAG流程图等逻辑视图
任务调度器生成实际的任务分配给TaskScheduler
SparkSQL自动优化

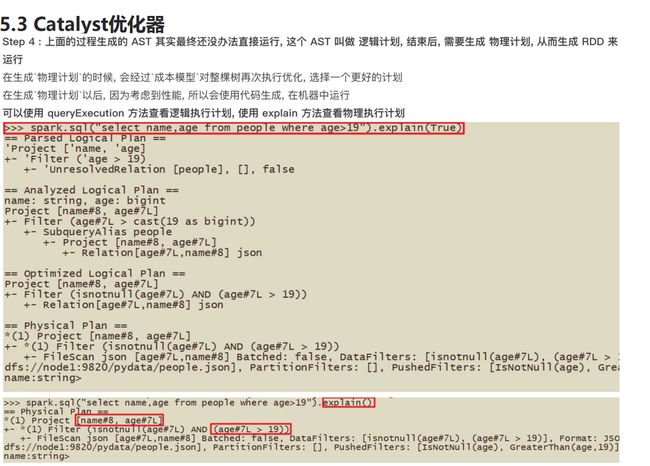
Catalyst优化器
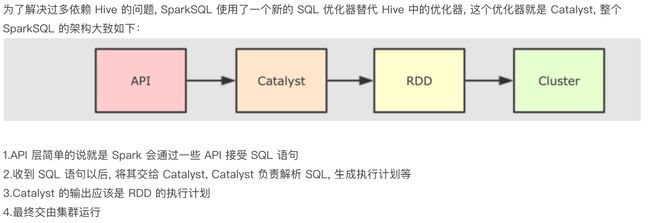
具体流程
语法树从下往上看,SQL的执行顺序为:
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
- LIMIT
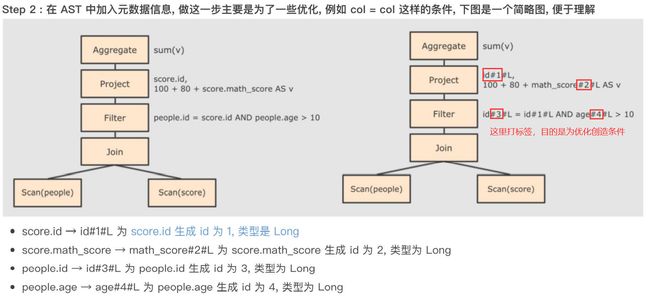
断言下推与列值裁剪
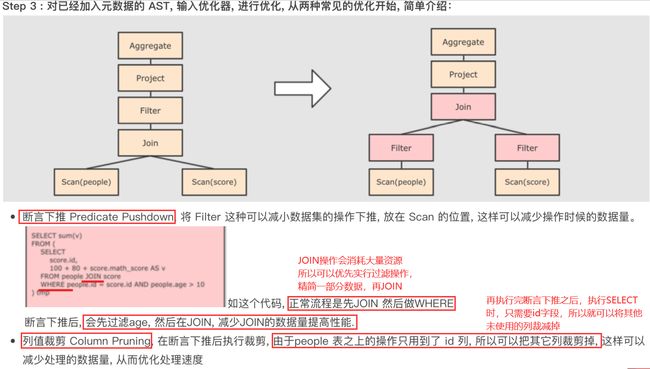
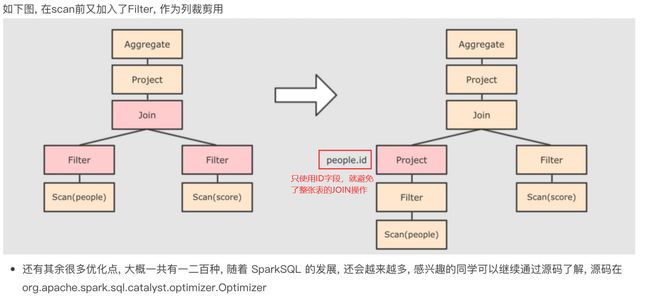

流程详解

Spark On Hive
Hive执行流程
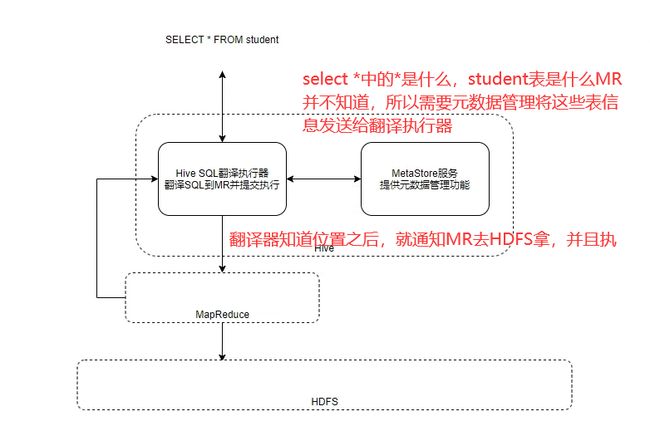
架构说明
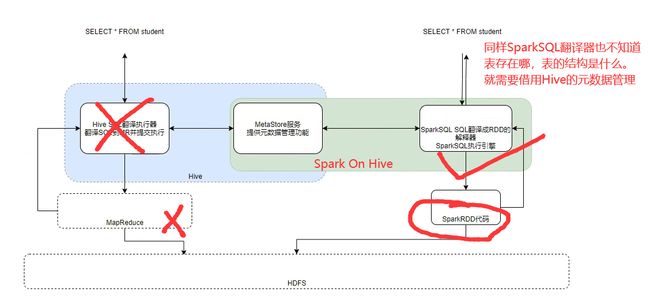
配置ing(用到再说)
视频

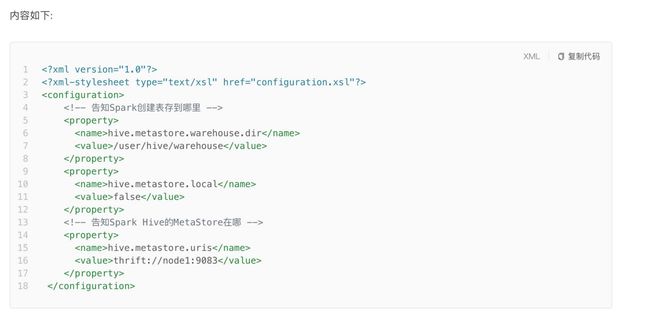
1. 在spark的conf目录中创建hive-site.xml
Spark 分布式SQL执行引擎
Spark ThriftServer服务存在的目的就是将SparkSQL的执行过程透明化,就算开发人员不懂得Spark的相关知识,只需要知道SQL语句的书写,就可以得到SparkSQL的执行结果。
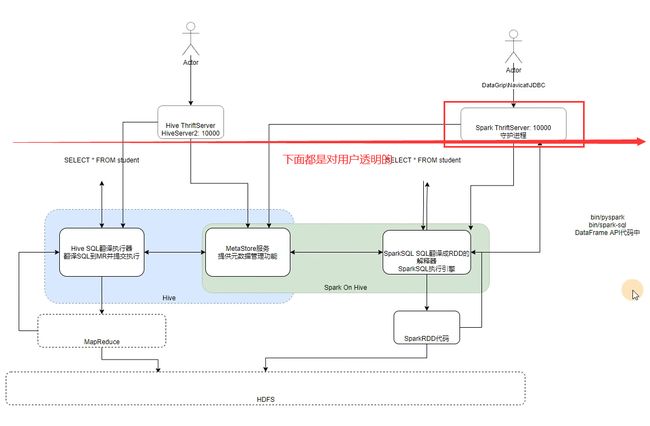
配置ing
视频地址
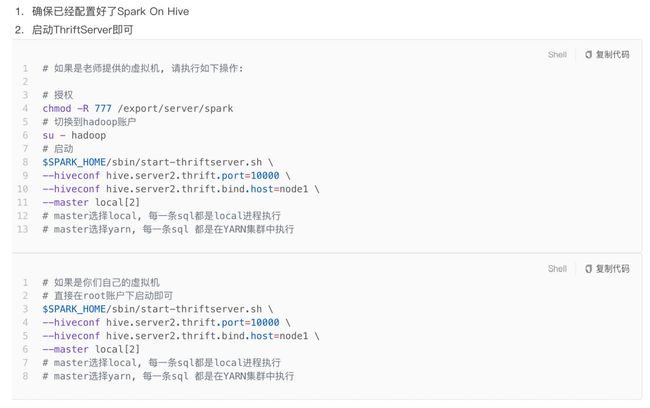
然后可以通过Navicat等数据库工具可以连接到SparkSQL
Spark Shuffle
Spark 提供两种Shuffle管理器:HashShuffleManager 和 SortShuffleManager
未经优化的HashShuffleManager
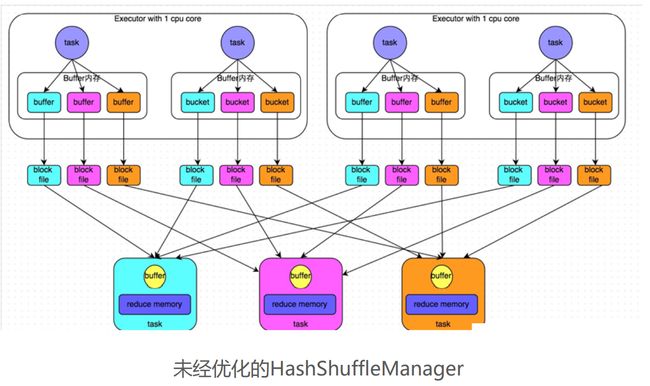
每一个task将要处理的数据按照hash值进行分组,如上图中分成了三组,分别是蓝色、粉色、橙色.
首先放在内存中,然后以块文件的方式放在磁盘中,然后通过网络发送到对应的接收端;中途产生了大量的磁盘文件和网络开销
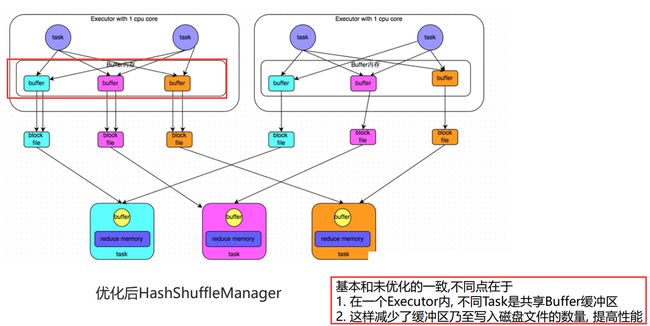
优化的HashShuffleManager
上述未优化的HashShuffleManager,每一个task都会产生一类块文件,可以通过优化完成块文件在内存中的的合并。如图每一个executor产生一个一类块文件,这就减少了网络的开销
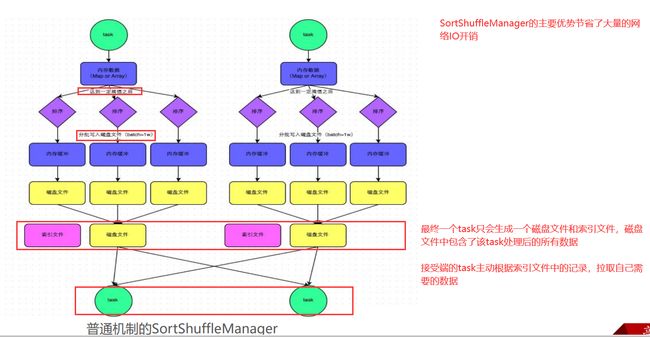
普通运行机制的SortShuffleManager
bypass机制的SortShuffleManager

可以看到bypass机制省去了排序的过程,那么又是如何将同一分区的数据写到一个内存缓冲区呢?
该机制下,当前 stage 的每个 task 会将数据的 key 进行
hash,然后将相同hash的 key 锁对应的数据写入到同一个内存缓冲区,缓冲写满后会溢写到磁盘文件,这里和HashShuffleManager一致。然后会进入 merge 阶段,将所有的磁盘文件合并成一个磁盘文件,并创建一个索引文件。
总结
shuffle是造成性能瓶颈的最主要的原因,所以要尽量避免无意义的shuffle操作!
Spark3.0的优化
自适应查询AQE(SparkSQL)

动态合并
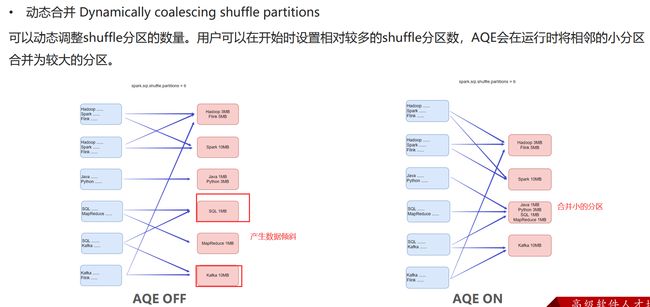
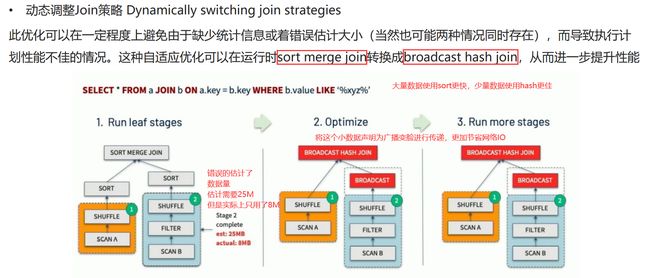
动态调整join策略
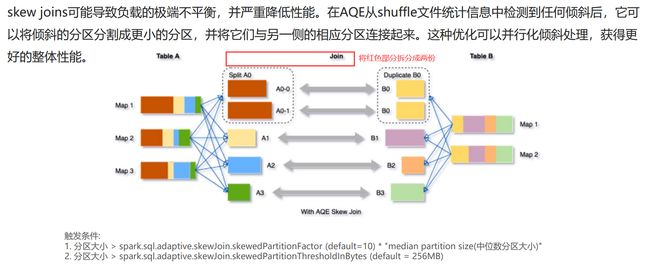
动态优化倾斜join
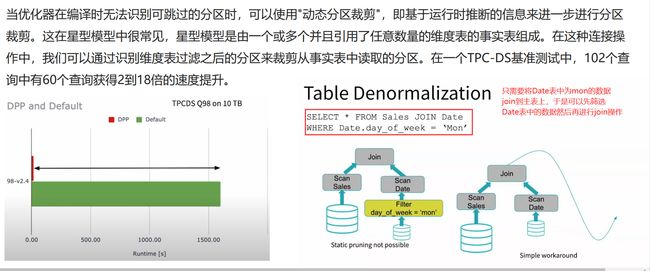
动态分区裁剪DPP(SparkSQL)
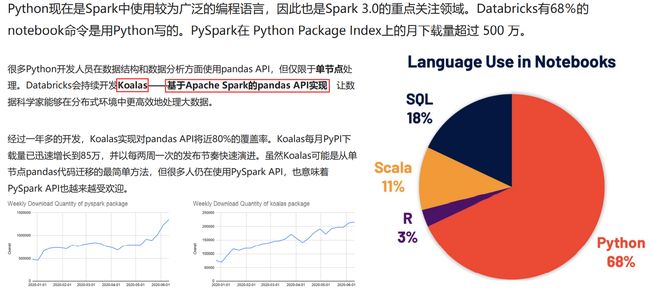
增强的Python API:PySpark和Koalas
Koalas入门
视频地址

6.Spark性能测试
6.1 配置详解
官方文档中Execution Behavior
| Property Name | Default | Meaning |
|---|---|---|
| spark.executor.cores | yarn: 1|| standalone&mesos:节点上所有可用的核 | 每个executor的核心数 |
| spark.default.parallelism | 对于分布式的shuffle操作,比如join,reduceByKey,表示父RDD的最大分区数,而对于没有父RDD的算子(parallelize来说) - 本地模式:本地机器上的核心数 -Mesos 细粒度模式:8 - 其他:所有执行器节点上的核心总数或2,以较大者为准 | transformation算子(eg:join,reduceByKey)返回的RDD中的默认分区数 |
| spark.cores.max | 没有设置 | 在standalone:将会使用spark.deploy.defaultCores||mesos的粗粒度模式下使用集群所有cores |
| spark.scheduler.mode | 先进先出 | 提交到同一个 SparkContext 的作业之间 的调度方式可以设置为FAIR 使用公平共享而不是一个接一个地排队作业。对多用户服务很有用。 |
| spark.dynamicAllocation.enabled | false | 是否使用动态资源分配,这会根据工作负载上下调整注册到此应用程序的执行程序的数量。有关详细信息,请参阅 此处的说明。 |
| spark.dynamicAllocation.executorIdleTimeout | 60s | 如果启用了动态分配并且执行程序空闲时间超过此持续时间,则执行程序将被删除。有关详细信息,请参阅此 说明。 |
| spark.dynamicAllocation.cachedExecutorIdleTimeout | 无穷 | 如果启用了动态分配并且具有缓存数据块的执行器空闲时间超过此持续时间,则该执行器将被删除。有关详细信息,请参阅此 说明。 |
7. 相关知识
6.1 名词大全
运行相关
| 名称 | 解释 |
|---|---|
| RDD | 弹性分布式数据集,是一个分区的集合 |
| 作业(Job) | 由多个任务组成的并行计算,这些任务是为响应 Spark 操作而产生的(例如save,collect) |
| 任务(Task) | 将发送给一个执行者的工作单元 |
| 阶段(Stage) | 每个作业被分成更小的任务集,称为阶段,这些任务相互依赖(similar to the map and reduce stages in MapReduce) |
| DAG图 | 一个有向无环图,表示代码的逻辑执行流程,基于宽窄依赖包含多个阶段 |
| DAG调度器 | 将DAG图进行处理,最终得到逻辑上Task的划分 |
| Task调度器 | 基于DAG调度器的产出,将逻辑上的Task分配到物理的excutor上运行,并监控管理 |
| 并行度 | 在同一时间内,有多少task任务同时运行,并行度直接影响RDD的分区数,比如并行度设置为6,那么RDD就被划分成6个分区 |
层级关系

部署相关
| 名称 | 解释 |
|---|---|
| 应用(Application) | 基于 Spark 构建的用户程序。由集群上的*驱动程序(driver program)和执行程序(executor)*组成。 |
| 应用 jar包(Application jar) | 包含用户的 Spark 应用程序的 jar。在某些情况下,用户会希望创建一个包含他们的应用程序及其依赖项的“uber jar”。用户的 jar 不包含 Hadoop 或 Spark 库,但是,这些将在运行时添加。 |
| 驱动程序(Driver program) | 运行应用程序的 main() 函数并创建 SparkContext 的进程 |
| 集群管理器(Cluster manager) | 用于获取集群上资源的外部服务(例如独立管理器、Mesos、YARN、Kubernetes) |
| 部署模式(Deploy mode) | 区分驱动程序进程(driver process)运行的位置。在集群(cluster)模式下,框架在集群内部启动驱动程序。在客户端(client)模式下,提交者在集群外部启动驱动程序。 |
| 工作节点(Worker node) | 任何可以在集群中运行应用程序代码的节点 |
| 执行者(Executor) | 为工作节点上的应用程序启动的进程,它运行任务并将数据保存在内存或磁盘存储中。每个应用程序都有自己的执行器。 |
6.2 RDD容错性
RDD的容错性是基于其记录操作的变换历史的能力,也就是只记录,但是不做。每个RDD都有一组变换(例如,map、filter等)应用于其源数据集,这些变换以一种不可变的方式存储在RDD的元数据中。如果一个节点故障了,Spark可以重新计算该节点上的变换历史,以确保新的节点与原始节点上的结果一致。
此外,RDD的容错性还与其惰性计算有关。RDD的操作并不立即执行,而是延迟到需要返回结果时才进行计算。这意味着Spark可以在RDD被持久化(将数据保留下来)之前自动记录所有的变换操作,并在需要时重新计算它们,从而保证计算的正确性和数据的完整性。
6.3 DAG宽窄依赖划分
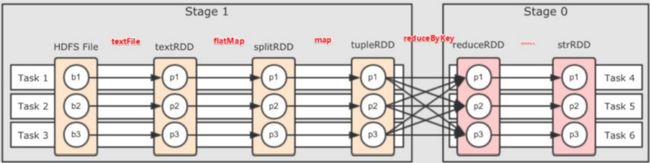
一个任务是一个线程,注意分区和任务之间的关系
6.4 资源分配机制
默认资源分配
当应用程序在Spark集群中提交时,它被使用,而没有指定任何资源分配细节。在这种方法中,所有的应用程序将以先进先出的方式运行,每个应用程序都会消耗所有的工作节点。因此,应用程序一个接一个地运行,当一个应用程序运行时,它将用尽所有的工作节点来创建执行器。
静态资源分配
当一个应用程序被提交时,用户会指定一个应用程序可以有多少个执行器、核心、内存等。因此,资源可以在一个或多个用户的多个应用程序之间共享。
动态资源分配
应用程序可以释放空闲的执行器,把一些资源还给集群,如果需要的话,这些资源也可以在将来收回。
什么时候申请executor
参考链接
Spark按轮增加executor,如果在spark.dynamicAllocation.schedulerBacklogTimeout秒内有任务请求则申请,此后,如果有任务在任务队列中持续了spark.dynamicAllocation.sustainedSchedulerBacklogTimeout秒,则继续申请
申请多少executor
每一轮申请的executor是上一轮的2倍,即1,2,4,8……
申请的executor放在哪
有两种策略:SpreadOut(负载均衡放在每台机器上)和noSpreadOut(首先集中放在一台机器上)
什么时候回收executor
如果任务队列中有未完成的任务,就不回收(基于原则:任务队列中有任务,则executor就不应当空闲)
如果executor闲置时间超过spark.dynamicAllocation.executorIdleTimeout秒,则回收
6.5 Stage
每个应用程序中的每个阶段都是一个接一个执行
6.6 Spark调优
链接
由于大多数Spark计算的内存性质,Spark程序可能受到集群中任何资源的瓶颈限制: CPU,网络带宽,或内存。大多数情况下,如果数据适合内存,瓶颈就是网络带宽,但有时也需要做一些调整,比如以序列化的形式存储RDD,以减少内存的使用。本指南将涵盖两个主要话题:数据序列化,这对良好的网络性能至关重要,也可以减少内存的使用;以及内存调整。我们还将简要介绍几个小的主题。
数据序列化
序列化在任何分布式应用的性能中起着重要作用。如果对象的序列化速度很慢,或者消耗大量的字节,将大大降低计算的速度。通常情况下,这将是你应该调整的第一件事,以优化Spark应用程序。Spark的目标是在便利性(允许你在操作中使用任何Java类型)和性能之间取得平衡。它提供了两个序列化库:
Java序列化: 默认情况下,Spark使用Java的ObjectOutputStream框架来序列化对象,并且可以与你创建的任何实现java.io.Serializable的类一起工作。你也可以通过扩展java.io.Externalizable来更紧密地控制你的序列化的性能。Java的序列化很灵活,但往往相当慢,而且导致许多类的序列化格式很大。
Kryo序列化: Spark也可以使用Kryo库(版本4)来更快地序列化对象。Kryo明显比Java序列化更快、更紧凑(通常高达10倍),但不支持所有的Serializable类型,并且需要你提前注册你将在程序中使用的类以获得最佳性能。
你可以通过用SparkConf初始化你的作业并调用conf.set(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”)切换到使用Kryo。这个设置配置了序列化器,它不仅用于在工作节点之间洗数据,而且在将RDD序列化到磁盘时也使用。Kryo不是默认值的唯一原因是自定义注册要求,但我们建议在任何网络密集型应用中尝试它。从Spark 2.0.0开始,我们在内部使用Kryo序列化器来洗刷带有简单类型、简单类型数组或字符串类型的RDD。
Spark自动包含了Twitter chill库中AllScalaRegistrar所涵盖的许多常用的核心Scala类的Kryo序列器。
要用Kryo注册你自己的自定义类,请使用registerKryoClasses方法。
val conf = new SparkConf().setMaster(...).setAppName(...)
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
val sc = new SparkContext(conf)
Kryo文档描述了更多的高级注册选项,比如添加自定义序列化代码。
如果你的对象很大,你可能还需要增加 spark.kryoserializer.buffer 的配置。这个值需要大到足以容纳你要序列化的最大对象。
最后,如果你不注册你的自定义类,Kryo仍然可以工作,但它将不得不在每个对象中存储完整的类名,这很浪费。
内存调优
在调整内存使用方面有三个考虑因素:你的对象所使用的内存量(你可能希望你的整个数据集都能放在内存中),访问这些对象的成本,以及垃圾收集的开销(如果你的对象周转率很高)。
默认情况下,Java对象的访问速度很快,但其消耗的空间很容易比其字段内的 "原始 "数据多2-5倍。这是由几个原因造成的:
- 每个不同的Java对象都有一个 “对象头”,大约有16个字节,包含诸如指向其类的指针等信息。对于一个数据量很小的对象(比如一个Int字段),它可能比数据还要大。
- Java字符串在原始字符串数据上有大约40个字节的开销(因为它们将其存储在一个Chars数组中,并保留额外的数据,如长度),并且由于字符串内部使用UTF-16编码,每个字符存储为两个字节。因此,一个10个字符的字符串可以很容易地消耗60个字节。
- 常见的集合类,如HashMap和LinkedList,使用链接数据结构,其中每个条目都有一个 "包装 "对象(如Map.Entry)。这个对象不仅有一个头,而且还有指向列表中下一个对象的指针(通常每个8字节)。
- 原始类型的集合通常将它们存储为 "盒式 "对象,如java.lang.Integer。
本节将首先概述Spark的内存管理,然后讨论用户可以采取的具体策略,以便在其应用程序中更有效地使用内存。特别是,我们将描述如何确定你的对象的内存使用情况,以及如何改善它–通过改变你的数据结构,或者通过以序列化的格式存储数据。然后,我们将介绍如何调整Spark的缓存大小和Java垃圾收集器。
内存管理概述
Spark的内存使用主要分为两类:执行和存储。执行内存指的是在洗牌、连接、排序和聚合中用于计算的内存,而存储内存指的是在集群中用于缓存和传播内部数据的内存。在Spark中,执行和存储共享一个统一的区域(M)。当不使用执行内存时,存储可以获得所有可用的内存,反之亦然。如果有必要,执行可以驱逐存储,但只有在存储内存的总使用量下降到一定的阈值(R)之下。换句话说,R描述了M中的一个子区域,在这个区域中,缓存的块永远不会被驱逐。由于执行中的复杂性,存储可能不会驱逐执行。
这种设计确保了几个理想的特性。
- 不使用缓存的应用程序可以使用整个空间来执行,避免了不必要的磁盘溢出。
- 使用缓存的应用程序可以保留一个最小的存储空间(R),其数据块不会被驱逐。
- 这种方法为各种工作负载提供了合理的开箱即用的性能,而不需要用户对内存的内部划分方式有专业的了解。
虽然有两个相关的配置,但典型的用户应该不需要调整它们,因为默认值适用于大多数工作负载:
- spark.memory.fraction将M的大小表示为(JVM堆空间-300MiB)的一部分(默认为0.6)。其余的空间(40%)保留给用户数据结构、Spark的内部元数据,以及在记录稀少和异常大的情况下对OOM错误的保护。
- spark.memory.storageFraction将R的大小表示为M的一部分(默认为0.5)。R是M中的存储空间,其中的缓存块对执行的驱逐有免疫力。
spark.memory.fraction的值应该被设置为能够在JVM的老一代或 "终身 "中舒适地容纳这一数量的堆空间。详情请见下面关于高级GC调整的讨论。
确定内存消耗
确定一个数据集所需的内存消耗量的最佳方法是创建一个RDD,将其放入缓存,并查看Web UI中的"storage"页面。该页面将告诉你该RDD占用了多少内存。
要估计一个特定对象的内存消耗,可以使用SizeEstimator的估计方法。这对于试验不同的数据布局以减少内存的使用,以及确定一个广播变量在每个执行器堆上所占用的空间是很有用的。
数据结构调优
减少内存消耗的第一个方法是避免增加开销的Java特性,如基于指针的数据结构和包装对象。有几种方法可以做到这一点:
- 将你的数据结构设计成
倾向于对象的数组和原始类型,而不是标准的Java或Scala集合类(例如HashMap)。fastutil库为原始类型提供了方便的集合类,与Java标准库兼容。 - 尽可能避免使用带有大量小对象和指针的嵌套结构。
- 考虑使用数字ID或枚举对象而不是字符串作为键。
- 如果你的RAM少于32GiB,设置JVM标志-XX:+UseCompressedOops,使指针为四字节而不是八字节。你可以在 spark-env.sh 中添加这些选项。
序列化的RDD存储
当你的对象仍然太大,无法有效地存储时,减少内存使用的一个更简单的方法是以序列化的形式存储它们,使用RDD持久化API中的序列化存储级别,如MEMORY_ONLY_SER。然后,Spark将把每个RDD分区存储为一个大的字节数组。以序列化形式存储数据的唯一缺点是访问时间较慢,因为必须对每个对象进行反序列化。如果你想以序列化的形式缓存数据,我们强烈建议你使用Kryo,因为它导致的大小比Java序列化小得多(当然也比原始Java对象小)。
垃圾收集的调整
当你的程序所存储的RDDs有很大的 "流失 "时,JVM的垃圾收集可能是一个问题。(在只读取一次RDD,然后对其进行许多操作的程序中,这通常不是一个问题)。当Java需要驱逐旧对象为新对象腾出空间时,它将需要追踪你所有的Java对象并找到未使用的对象。这里需要记住的要点是,垃圾收集的成本与Java对象的数量成正比,所以使用对象较少的数据结构(例如,用Ints数组代替LinkedList)可以大大降低这一成本。一个更好的方法是以序列化的形式持久化对象,如上所述:现在每个RDD分区将只有一个对象(一个字节数组)。在尝试其他技术之前,如果GC是一个问题,首先要尝试的是使用序列化的缓存。
由于你的任务的工作内存(运行任务所需的空间量)和你的节点上缓存的RDD之间的干扰,GC也可能成为一个问题。我们将讨论如何控制分配给RDD缓存的空间以缓解这一问题。
测量GC的影响
GC调优的第一步是收集关于垃圾收集发生频率和GC花费时间的统计数据。这可以通过在Java选项中添加-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps来完成。(关于向Spark作业传递Java选项的信息,请参见配置指南。) 下次运行Spark作业时,你会看到每次发生垃圾收集时,工作者的日志中都会打印出信息。请注意,这些日志将出现在集群的工作节点上(在其工作目录的stdout文件中),而不是你的驱动程序上。
高级GC调整
为了进一步调整垃圾收集,我们首先需要了解一些关于JVM中内存管理的基本信息:
-
Java的堆空间被分为两个区域 Young和Old。Young代是用来存放短期的对象的,而Old代是用来存放长期的对象的。
-
Young又被划分为三个区域[Eden, Survivor1, Survivor2]。
-
对垃圾收集程序的简化描述: 当Eden满的时候,在Eden上运行一个小的GC,Eden和Survivor1中活着的对象被复制到Survivor2。Survivor区域被交换。如果一个对象足够老或者Survivor2已经满了,它就会被移到Old。最后,当Old接近满的时候,一个完整的GC被调用。
Spark中GC调整的目标是确保只有长寿命的RDD被存储在Old代,并且Young代的大小足以存储短寿命的对象。这将有助于避免全面的GC来收集任务执行过程中创建的临时对象。一些可能有用的步骤是:
-
通过收集GC的统计数据来检查是否有太多的垃圾回收。如果一个完整的GC在任务完成之前被调用多次,这意味着没有足够的内存可用于执行任务。
-
如果有太多的小集合但没有太多的大GC,为Eden分配更多的内存会有帮助。你可以将Eden的大小设置为对每个任务所需内存的高估。如果Eden的大小被确定为E,那么你可以使用选项-Xmn=4/3*E来设置Young代的大小。(按4/3的比例增加是为了考虑Survivor区域所使用的空间)。
-
在打印的GC统计中,如果OldGen接近满了,通过降低spark.memory.fraction来减少用于缓存的内存量;缓存更少的对象比减慢任务执行要好。另外,也可以考虑减少Young代的大小。这意味着降低-Xmn,如果你已经如上设置。如果没有,试着改变JVM的NewRatio参数值。许多JVM将其默认为2,这意味着老一代占据了2/3的堆。它应该足够大,以至于这个分数超过了spark.memory.fraction。
-
尝试用-XX:+UseG1GC垃圾收集器。在垃圾收集是一个瓶颈的情况下,它可以提高性能。注意,对于大的执行器堆大小,用-XX:G1HeapRegionSize增加G1区域大小可能很重要。
-
举个例子,如果
你的任务是从HDFS读取数据,任务使用的内存量可以通过从HDFS读取的数据块的大小来估计。请注意,解压后的块的大小往往是块的2或3倍。因此,如果我们希望有3或4个任务的工作空间,而HDFS块的大小是128MiB,我们可以估计Eden的大小是 4 ∗ 3 ∗ 128 4*3*128 4∗3∗128MiB。 -
监视垃圾收集的频率和时间在新的设置下如何变化。
我们的经验表明,GC调整的效果取决于你的应用程序和可用的内存量。还有许多在线描述的调整选项,但在高水平上,管理完全GC发生的频率可以帮助减少开销。
可以通过在作业的配置中设置 spark.executor.defaultJavaOptions 或 spark.executor.extraJavaOptions 来指定执行器的 GC 调整标记。
其他考虑因素
并行度
除非你把每个操作的平行度设置得足够高,否则集群不会得到充分的利用。Spark会根据文件的大小自动设置在每个文件上运行的 "map "任务的数量(尽管你可以通过SparkContext.textFile等的可选参数来控制),而对于分布式的 "reduce "操作,比如groupByKey和reduceByKey,它会使用最大的父RDD的分区数量。你可以把并行程度作为第二个参数传递(见spark.PairRDDFunctions文档),或者设置配置属性spark.default.parallelism来改变默认值。一般来说,我们建议在你的集群中每个CPU核有2-3个任务。
输入路径上的并行列表
有时,当作业输入有大量的目录时,你可能还需要增加目录列表的并行性,否则这个过程可能会花费很长的时间,尤其是针对S3这样的对象存储时。如果你的作业在具有Hadoop输入格式的RDD上工作(例如,通过SparkContext.sequenceFile),则通过spark.hadoop.mapreduce.input.fileinputformat.list-status.num-reads(目前默认为1)控制并行性。
对于具有基于文件的数据源的Spark SQL,你可以调整spark.sql.sources.parallelPartitionDiscovery.threshold和spark.sql.sources.parallelPartitionDiscovery.parallelism,以提高列举并行性。更多细节请参考Spark SQL性能调优指南。
Reduce任务的内存使用情况
有时,你会得到OutOfMemoryError,不是因为你的RDDs不适合在内存中,而是因为你的某个任务的工作集,比如groupByKey中的一个Reduce任务,太大。Spark的shuffle操作(sortByKey、groupByKey、reduceByKey、join等)在每个任务中建立一个哈希表来进行分组,而这个哈希表往往会很大。这里最简单的解决方法是提高并行化水平,使每个任务的输入集更小。Spark可以有效地支持短至200毫秒的任务,因为它在许多任务中重复使用一个执行器JVM,而且它的任务启动成本很低,所以你可以安全地将并行化水平提高到超过集群中的核心数量。
广播大型变量
使用SparkContext中的广播功能可以大大减少每个序列化任务的大小,以及在集群上启动作业的成本。如果你的任务中使用了驱动程序中的任何大型对象(例如静态查询表),可以考虑将其变成一个广播变量。Spark在主服务器上打印每个任务的序列化大小,所以你可以看一下,以决定你的任务是否太大;一般来说,大于20KB的任务可能值得优化。
数据位置
数据定位可以对Spark作业的性能产生重大影响。如果数据和对其进行操作的代码在一起,那么计算往往会很快。但如果代码和数据是分开的,一个必须移动到另一个。通常情况下,将序列化的代码从一个地方运送到另一个地方要比运送一大块数据快,因为代码的大小比数据小得多。Spark围绕这个数据定位的一般原则建立了它的调度机制。
数据定位是指数据离处理它的代码有多近。根据数据的当前位置,有几个级别的定位。按照从近到远的顺序:
PROCESS_LOCAL:数据与运行的代码在同一个JVM中。这是可能的最佳位置性NODE_LOCAL:数据在同一个节点上。例如,可能在同一节点的HDFS中,或者在同一节点的另一个执行器中。这比PROCESS_LOCAL要慢一些,因为数据必须在进程之间传输NO_PREF:数据从任何地方访问都是一样快的,而且没有位置偏好。RACK_LOCAL:数据在同一个服务器机架上。数据在同一机架上的不同服务器上,因此需要通过网络发送,通常是通过一个交换机。ANY:数据在网络上的其他地方,不在同一个机架上
Spark更倾向于将所有任务安排在最佳定位水平,但这并不总是可能的。在任何空闲的执行器上没有未处理的数据的情况下,Spark会切换到较低的定位水平。有两种选择:
a)等到繁忙的CPU腾出手来,在同一服务器上的数据上启动一个任务(计算向数据靠拢)
b)立即在更远的地方启动一个新的任务,需要把数据移到那里(数据向计算靠拢)
Spark通常的做法是等待一下,希望有一个繁忙的CPU腾出手来(计算向数据靠拢)。一旦超时,它就开始把数据从远处移到空闲的CPU上(数据向计算靠拢)。每个级别之间的回退等待超时可以单独配置,也可以在一个参数中全部配置;详见配置页面的spark.locality参数。如果你的任务较长,并且发现定位性较差,你应该增加这些设置,但默认的设置通常效果不错。
总结
这已经是一个简短的指南,指出了你在调整Spark应用程序时应该了解的主要问题–最重要的是数据序列化和内存调整。对于大多数程序来说,切换到Kryo序列化并以序列化的形式持久化数据将解决大多数常见的性能问题。欢迎在Spark邮件列表中询问有关其他调优的最佳实践。
8. 源码编译
控制台乱码
https://www.bilibili.com/video/BV1Hh411H75R/?spm_id_from=333.337.search-card.all.click&vd_source=53171a72dace3eeb3954e16d40432281
第1:0:0处开始
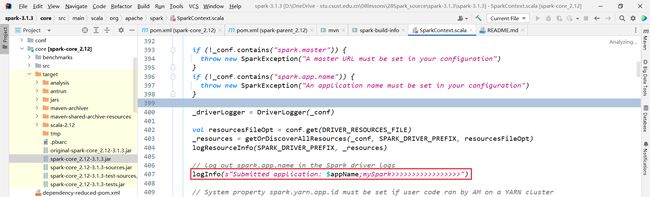
8.1 修改源码
8.2 修改pom文件
只要修改大pom文件
255
![]()
<spark.test.home>D:\OneDrive - stu.csust.edu.cn\08lessons\28Spark_source\spark-3.1.3\testspark.test.home>

![]()


修改scala-maven-plugin的版本

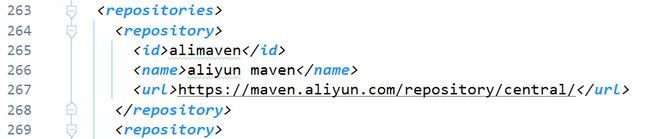
添加aliyun库地址
<repository>
<id>alimavenid>
<name>aliyun mavenname>
<url>https://maven.aliyun.com/repository/central/url>
repository>
注释有关git的命令

由于我们只修改了spark-core的代码,所以只需要编译以下模块
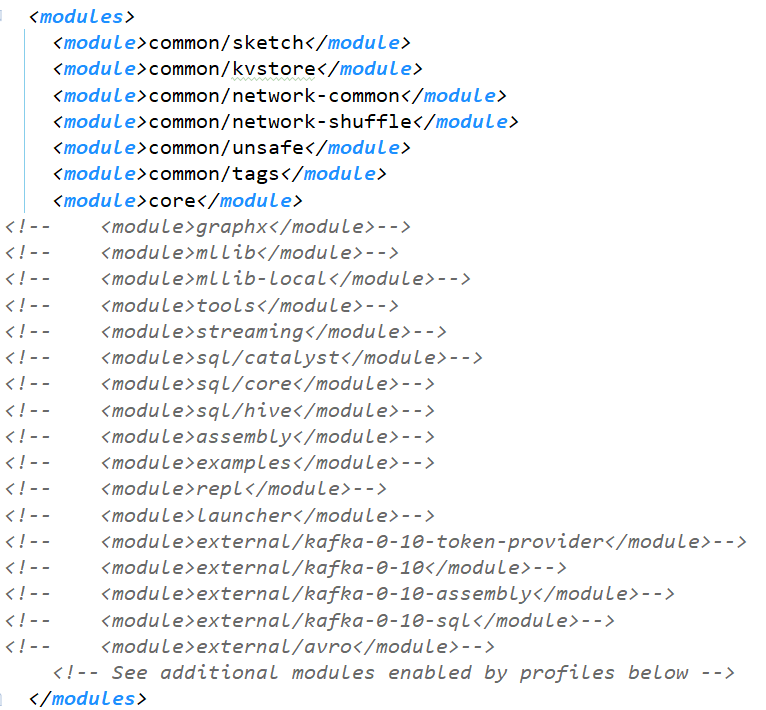
修改或者注释其他报错信息
反正会跳过test,其实这些东西配不配置都一样
这里随便选个路径
![]()
其他的相关test的报错信息就全部注释掉
修改scala插件版本

<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
保持scala的编译版本和本机环境一致

注释linux环境下的编译加速
![]()
设置编译参数
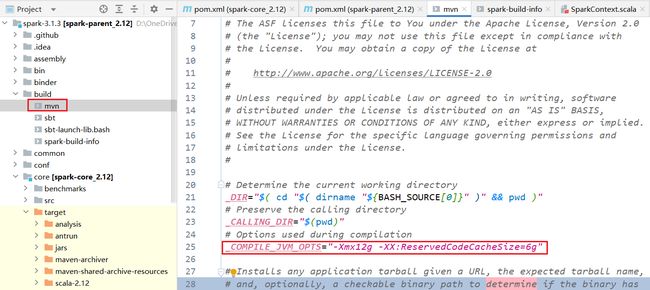
8.3 执行命令
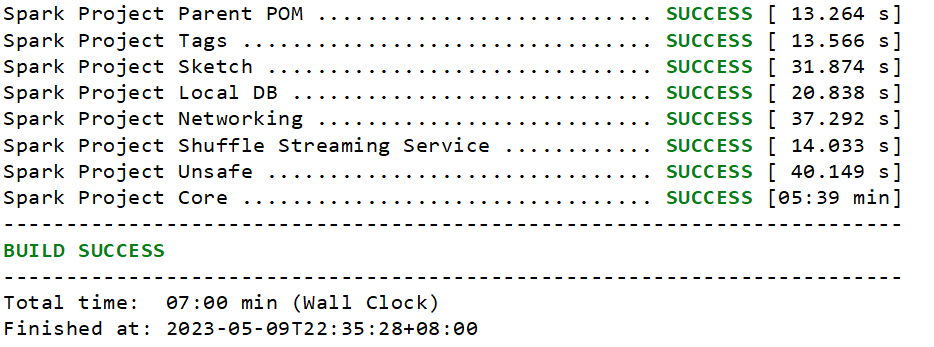
可以先试着compile一下 如果没有编译错误就可以package
![]()
![]()
编译成功
8.4 替换jar包
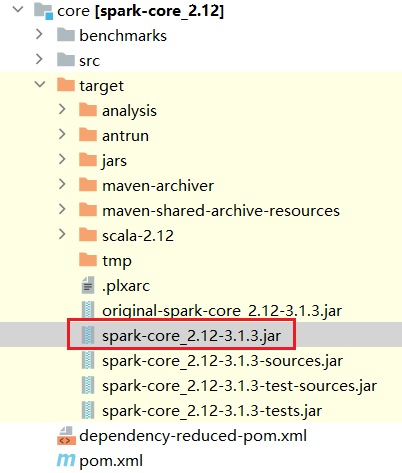
替换linux中对应的jar包
原来的输出结果
/opt/module/spark3.1/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --executor-memory 2G --executor-cores 2 /opt/module/spark3.1/examples/jars/spark-examples_2.12-3.1.3.jar 1000
/opt/module/spark3.1/bin/spark-submit --master local[*] --deploy-mode client /opt/module/spark3.1/examples/src/main/python/pi.py 10
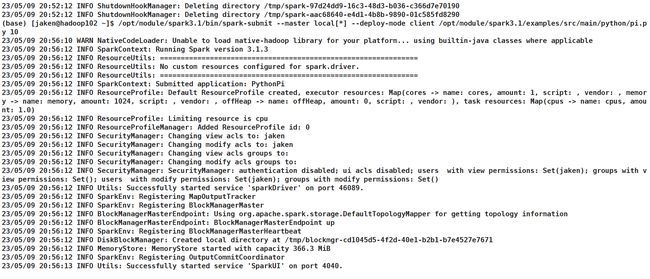
8.5 报错

23/05/09 22:41:13 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Traceback (most recent call last):
File "/opt/module/spark3.1/examples/src/main/python/pi.py", line 29, in <module>
spark = SparkSession\
File "/opt/module/spark3.1/python/lib/pyspark.zip/pyspark/sql/session.py", line 228, in getOrCreate
File "/opt/module/spark3.1/python/lib/pyspark.zip/pyspark/context.py", line 384, in getOrCreate
File "/opt/module/spark3.1/python/lib/pyspark.zip/pyspark/context.py", line 146, in __init__
File "/opt/module/spark3.1/python/lib/pyspark.zip/pyspark/context.py", line 209, in _do_init
File "/opt/module/spark3.1/python/lib/pyspark.zip/pyspark/context.py", line 321, in _initialize_context
File "/opt/module/spark3.1/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py", line 1568, in __call__
File "/opt/module/spark3.1/python/lib/py4j-0.10.9-src.zip/py4j/protocol.py", line 326, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling None.org.apache.spark.api.java.JavaSparkContext.
: java.lang.ExceptionInInitializerError
at org.apache.spark.package$.<init>(package.scala:93)
at org.apache.spark.package$.<clinit>(package.scala)
at org.apache.spark.SparkContext.$anonfun$new$1(SparkContext.scala:193)
at org.apache.spark.internal.Logging.logInfo(Logging.scala:57)
at org.apache.spark.internal.Logging.logInfo$(Logging.scala:56)
at org.apache.spark.SparkContext.logInfo(SparkContext.scala:82)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:193)
at org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:58)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:238)
at py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80)
at py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.spark.SparkException: Could not find spark-version-info.properties
at org.apache.spark.package$SparkBuildInfo$.<init>(package.scala:62)
at org.apache.spark.package$SparkBuildInfo$.<clinit>(package.scala)
... 19 more
23/05/09 22:41:14 INFO ShutdownHookManager: Shutdown hook called
23/05/09 22:41:14 INFO ShutdownHookManager: Deleting directory /tmp/spark-bd3df362-39da-417e-aa44-e572e4278867
他说无法找到
spark-version-info.properties
分析原因:应该是我们自己编译的版本号并不是官方的3.1.3的版本号,所以需要重新设置spark编译后的版本号
解决
https://blog.csdn.net/xw486223221/article/details/124772541
打开git bash,执行以下命令
./build/spark-build-info ./core/target/scala-2.12/classes/ 3.1.3

将生成的文件拷贝到core下的目录
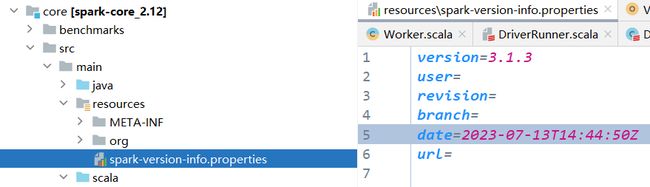
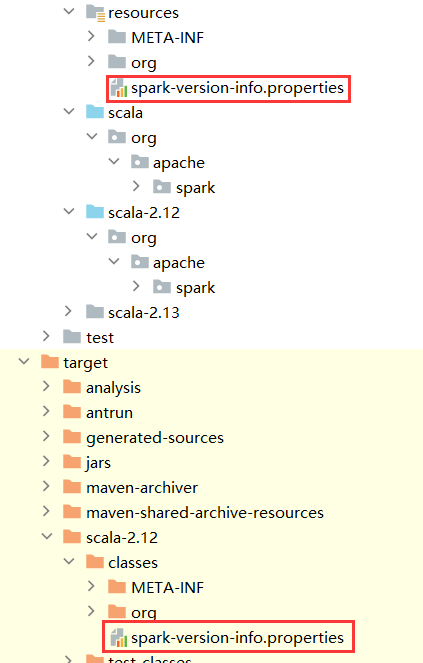
8.6 编译成功
再次运行,执行成功!

8.7 编译其他模块
报错
![]()
https://blog.csdn.net/xw486223221/article/details/124772541
安装antlr插件
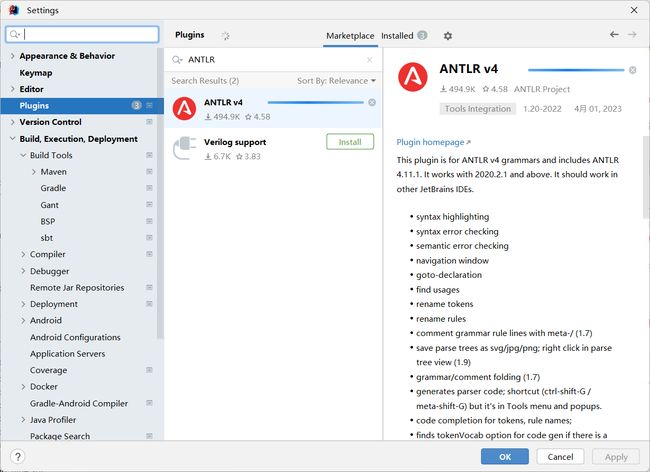
放开之前模块的注释
mvn -T 8 clean package -DskipTests
执行命令开始编译
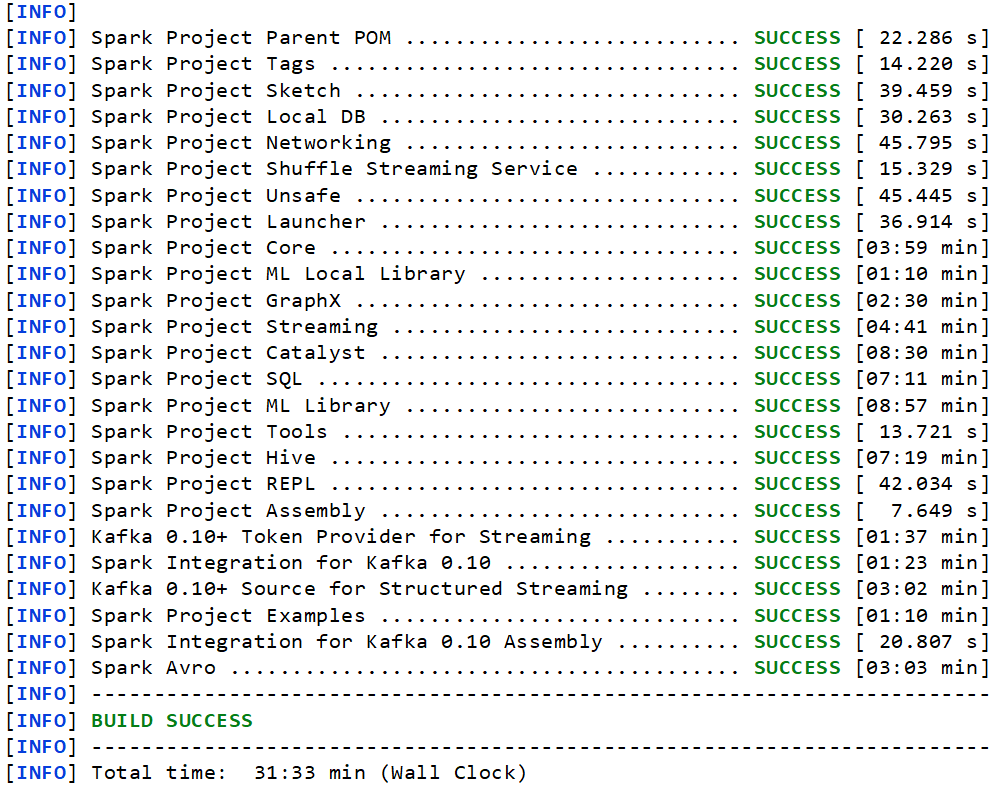
9. 运行测试样例
报错
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/sql/SparkSession$
at ScalaStudy.nian.studySpark$.main(studySpark.scala:10)
at ScalaStudy.nian.studySpark.main(studySpark.scala)
添加配置选项
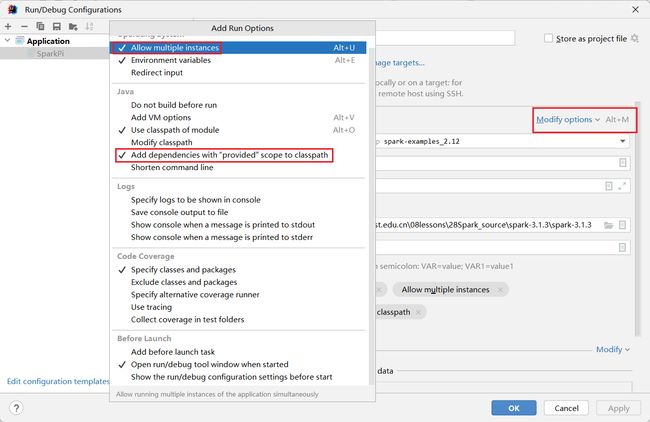
再次运行 报错
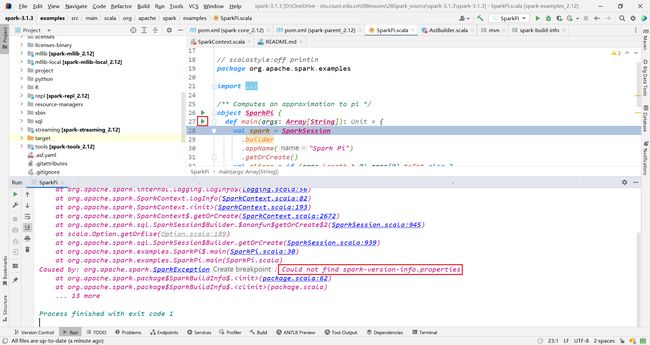
和上面的报错一样,执行下面命令
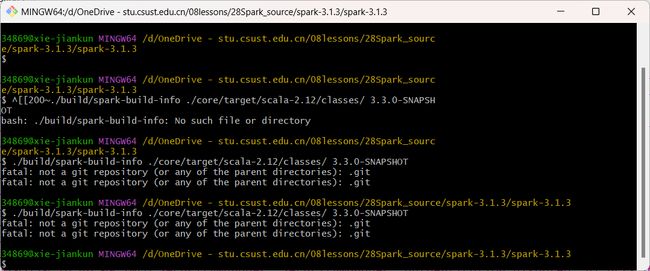
修改example目录下的pow.xml
将所有的provided替换成compile
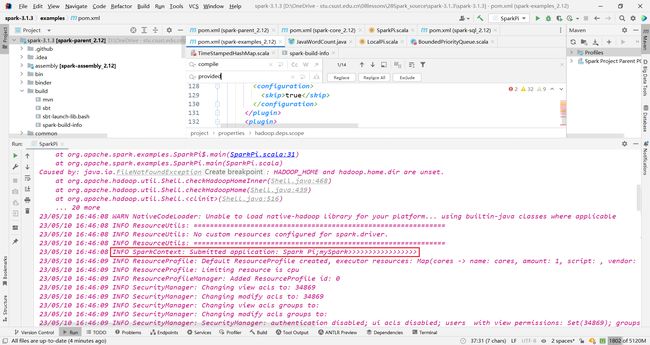
noClassDefFoundError
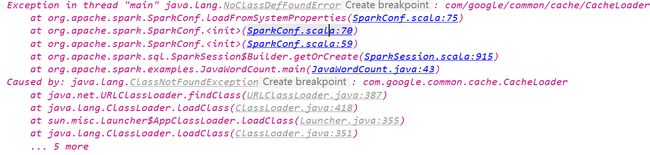
将所有包的scope由provided改成compile


9. 源码调试
9.1 日志输出
此方法不可取 debug的日志信息太多太多了
vim log4j.properties
改为DEBUG
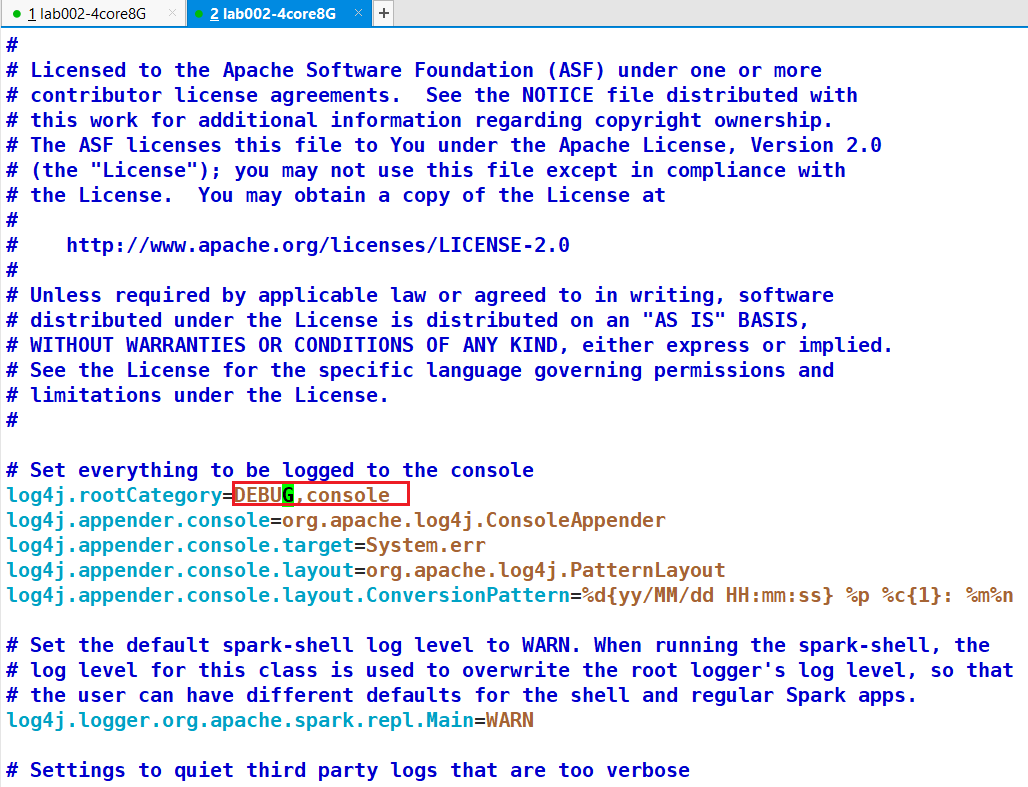
建议还是修改源码
将logDebug 改成logInfo

9.2 查看详细日志
/opt/module/spark3.1/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --executor-memory2G --executor-cores 2 /opt/module/spark3.1/examples/jars/spark-examples_2.12-3.1.3.jar 10
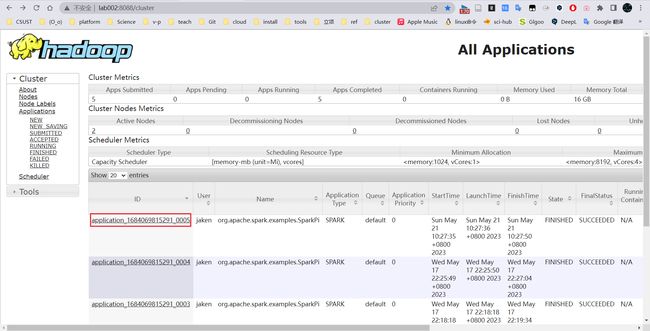
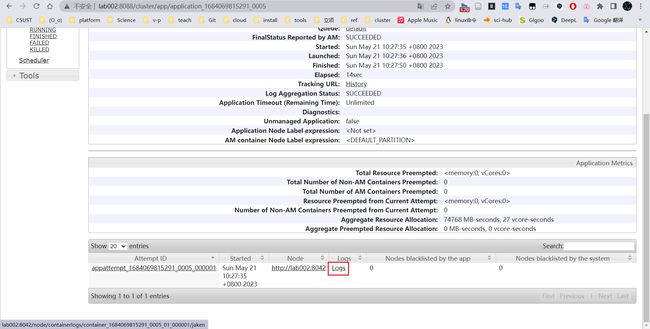
最终的详细日志
10. BUG
10.1 RDD location
现象
从HDFS读文件时,初始化的stage获取的数据本地性为ANY
pendingTasks.forHost存的是别名,而hostToExecutor存的是真实IP地址,导致计算数据本地性等级的时候,hostToExecutors.get(host)=None
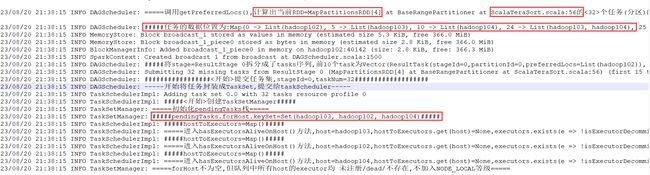

当不是从hdfs读取数据从而计算分区时,就不会存在记录的host为hostname的情况
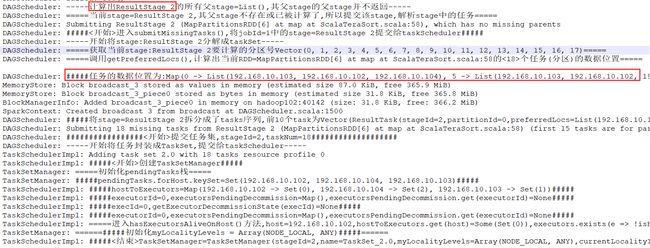
定位
DAGScheduler中在使用getPreferredLocs()计算partition的位置时,使用的是hostname
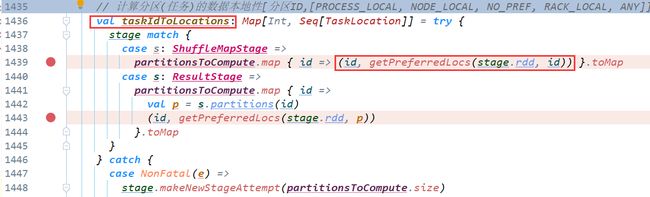


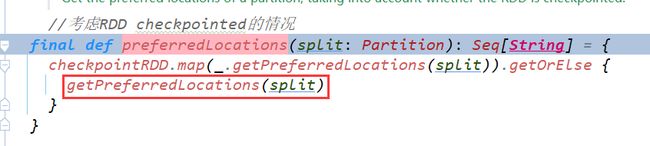
寻找代码对应的子类RDD,从而找到getPreferredLocations
以第二个stage为例(job1中的第一个stage)
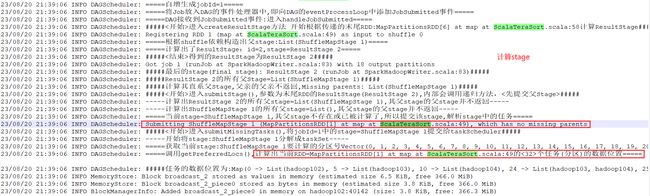
跳转到hibench对应的代码处
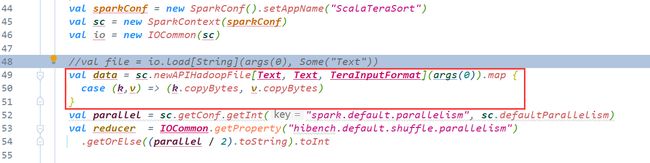
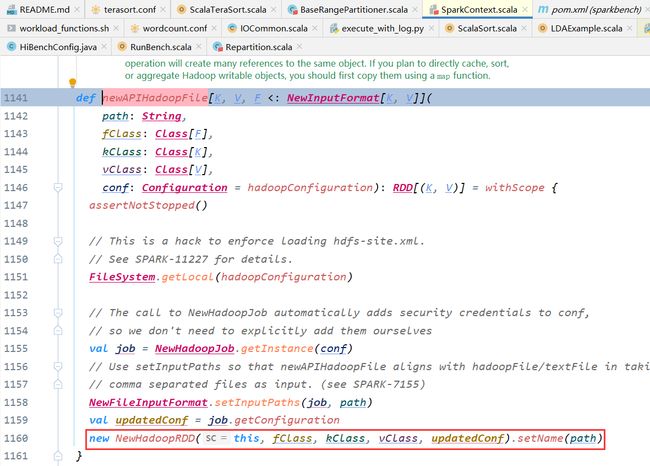

打印输出一下结果

果然 计算位置的时候使用的是hostname

进入getLocationInfo()方法
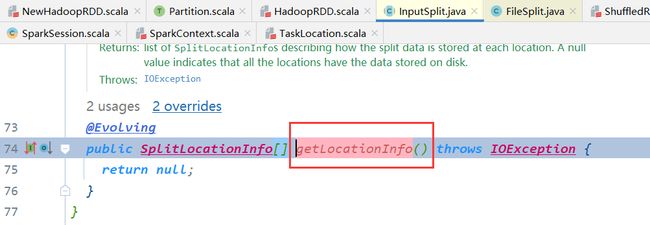
这边都是hadoop的源码了,无法修改
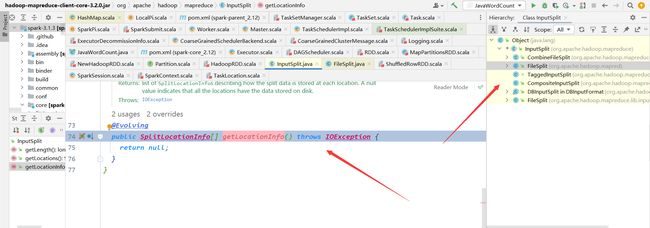
既然无法在hadoop端修改,可不可以在spark端改呢?
并是由于hdfs的配置问题,不要使用hostname
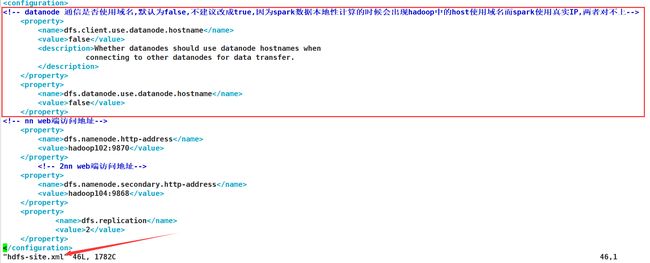
解决
https://issues.apache.org/jira/browse/SPARK-10149?jql=project%20%3D%20SPARK%20AND%20text%20~%20%22hostname%22

11. 源码修改
11.1 数据位置和大小
定位
DAGScheduler.submitMissingTasks
11.1.1 RDD所有窄依赖祖先
val narrowAncestors = stage.rdd.getNarrowAncestors
logInfo(s"#####getNarrowAncestors=\n${narrowAncestors} #####")
// 过滤出shuffleRDD和hadoopRDD
val shuffledRDDs = narrowAncestors.filter(_.isInstanceOf[ShuffledRDD[_, _, _]])
val hadoopRDDs = narrowAncestors.filter {
case _: HadoopRDD[_, _] | _: NewHadoopRDD[_, _] => true
case _ => false
}
11.1.2 shuffleDependency和shuffleId
val inputShuffleDependency: Option[ShuffleDependency[_, _, _]] = inputShuffledRDD match {
// 注意使用的是dependencies,来获取当前RDD的依赖 而不是getDependencies去获取所有父RDD的依赖
case Some(rdd) => Some(rdd.asInstanceOf[ShuffledRDD[_, _, _]].dependencies.head.asInstanceOf[ShuffleDependency[_, _, _]])
case None => None
}
// 根据shuffleDenpendency获得shuffleId
logInfo(s"#####inputShuffledRDD=${inputShuffledRDD},inputShuffleId=${inputShuffleDependency.map(_.shuffleId).getOrElse(-1)}#####")
11.1.3 MapOutputTracker和shuffleStatus
val tracker = SparkEnv.get.mapOutputTracker.asInstanceOf[MapOutputTrackerMaster]
// val dep = rdd.dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
logInfo(s"#####tracker.shuffleStatuses=\n${tracker.shuffleStatuses.mkString("\n")} #####")
// 根据shuffle依赖获得下游任务的位置和大小
sizes = Seq(tracker.getPreferredLocationsAndSizesForShuffle(inputShuffleDependency.get, partitionId)._2.sum)
11.1.4 blockManager、blockManagerMaster
val blockManager = SparkEnv.get.blockManager
logInfo(s"#####blockManager.blockManagerId.host=${blockManager.blockManagerId.host}#####")
val blockManagerMaster = blockManager.master
11.1.5 blockLocation、blockSize
// 获得RDD的所有分区对应的blockId
val hadoopRDDBlockIds: Array[BlockId] = inputHadoopRDD.get.partitions.indices.map(index => RDDBlockId(inputHadoopRDD.get.id, index)).toArray[BlockId]
logInfo(s"#####hadoopRDDBlockIds=${hadoopRDDBlockIds.mkString(",")}#####")
val hadoopRDDBlockSize = hadoopRDDBlockIds.map {
blockId =>
val blockStatus=
// 获得block对应的位置和大小
blockManagerMaster.getLocationsAndStatus(blockId, blockManager.blockManagerId.host).map(_.status)
// 根据blockStatus获得block的内存/磁盘占用/当然也有位置信息
if(blockStatus.isDefined) (blockStatus.get.memSize, blockStatus.get.diskSize)
else (0,0)
}
logInfo(s"#####hadoopBlockSize=${hadoopRDDBlockSize.mkString(",")}#####")
logInfo(s"#####getNarrowAncestors=\n${narrowAncestors} #####")
// 过滤出shuffleRDD和hadoopRDD
val shuffledRDDs = narrowAncestors.filter(_.isInstanceOf[ShuffledRDD[_, _, _]])
val hadoopRDDs = narrowAncestors.filter {
case _: HadoopRDD[_, _] | _: NewHadoopRDD[_, _] => true
case _ => false
}
### 11.1.2 shuffleDependency和shuffleId
```scala
val inputShuffleDependency: Option[ShuffleDependency[_, _, _]] = inputShuffledRDD match {
// 注意使用的是dependencies,来获取当前RDD的依赖 而不是getDependencies去获取所有父RDD的依赖
case Some(rdd) => Some(rdd.asInstanceOf[ShuffledRDD[_, _, _]].dependencies.head.asInstanceOf[ShuffleDependency[_, _, _]])
case None => None
}
// 根据shuffleDenpendency获得shuffleId
logInfo(s"#####inputShuffledRDD=${inputShuffledRDD},inputShuffleId=${inputShuffleDependency.map(_.shuffleId).getOrElse(-1)}#####")
11.1.3 MapOutputTracker和shuffleStatus
val tracker = SparkEnv.get.mapOutputTracker.asInstanceOf[MapOutputTrackerMaster]
// val dep = rdd.dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
logInfo(s"#####tracker.shuffleStatuses=\n${tracker.shuffleStatuses.mkString("\n")} #####")
// 根据shuffle依赖获得下游任务的位置和大小
sizes = Seq(tracker.getPreferredLocationsAndSizesForShuffle(inputShuffleDependency.get, partitionId)._2.sum)
11.1.4 blockManager、blockManagerMaster
val blockManager = SparkEnv.get.blockManager
logInfo(s"#####blockManager.blockManagerId.host=${blockManager.blockManagerId.host}#####")
val blockManagerMaster = blockManager.master
11.1.5 blockLocation、blockSize
// 获得RDD的所有分区对应的blockId
val hadoopRDDBlockIds: Array[BlockId] = inputHadoopRDD.get.partitions.indices.map(index => RDDBlockId(inputHadoopRDD.get.id, index)).toArray[BlockId]
logInfo(s"#####hadoopRDDBlockIds=${hadoopRDDBlockIds.mkString(",")}#####")
val hadoopRDDBlockSize = hadoopRDDBlockIds.map {
blockId =>
val blockStatus=
// 获得block对应的位置和大小
blockManagerMaster.getLocationsAndStatus(blockId, blockManager.blockManagerId.host).map(_.status)
// 根据blockStatus获得block的内存/磁盘占用/当然也有位置信息
if(blockStatus.isDefined) (blockStatus.get.memSize, blockStatus.get.diskSize)
else (0,0)
}
logInfo(s"#####hadoopBlockSize=${hadoopRDDBlockSize.mkString(",")}#####")