大话领域驱动设计中的贫血模型和充血模型
一、前言
领域驱动设计(DDD)作为一种软件设计思想,在近几年日益复杂的系统架构演变中重新被人拿出来讨论,特别是在当下非常流行的微服务架构中,DDD的价值更加突显出来。大部分人对DDD的认识,都是来自于Eric Evans在2004年出版的《领域驱动设计——软件核心复杂性应对之道》,可以说这本书为DDD在整个业界奠定了基础,十几年后的今天大家依然在这个基础上沿用了很多概念,只是在一些细节上不断进行改进,可见Eric Evans大师的远见。
DDD虽然给人们提供了一种以领域为中心来设计的原则性指导,但具体的分层和实现,会因不同的团队的理解和习惯、先进技术的出现而不断演进。就如最早的分层架构是领域层依赖基础设施层的,但最新流行的分层架构是通过领域层的抽象接口来实现对基础设施层的依赖反转,实现领域层作为最核心最稳定的层次不依赖于其他的层次。
话不多说,先呈上经典的领域分层架构图。
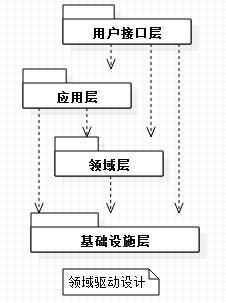
讨论领域分层架构的文章有很多,DDD经典四层架构、改进后的五层架构、六边形架构,我们团队也结合团队自身的情况对领域分层架构展开了多轮讨论,最终一致决定选择在经典四层架构基础上,将领域层对基础设施层依赖反转,作为我们的初版分层架构,以后再按需演进。讨论过程中,针对领域模型应该使用贫血模型还是充血模型的问题,是我们形成两种意见的最大分歧点,这里整理了一下对这两种模式的模型的思考,分享给大家。所以这篇文章只探讨领域模型的模式问题。
二、领域模型的四种模式
在讨论领域模型的模式问题前,我们先简单定义一下失血、贫血、充血、胀血这四种实体模式,因为我曾看到有人把失血模式的模型也称之为贫血,然后尽数贫血模式的各种危害。我们也不是定义标准的人,只是想在本文章讨论范围先有一个统一的认知。
失血模型
失血模型简单来说就是模型中只有属性的setter和getter方法,并且只是简单的赋值或直接返回属性值,是对一个实体类最简单的封装,其他所有的业务行为和数据存储由专门的服务类和DAO来完成。以一个Person类为例,包含姓名、生日、年龄的简单属性,只有判断今天是否生日和过生日(过生日后年龄会+1)两个行为。
public class Person extends Entity {
/**
* 姓名
*/
private String name;
/**
* 生日
*/
private Date birthday;
/**
* 年龄
*/
private Integer age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Date getBirthday() {
return birthday;
}
public void setBirthday(Date birthday) {
this.birthday = birthday;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
public interface PersonService {
/**
* 判断今天是否生日
*/
boolean isTodayBirthday(Long personId);
/**
* 生日快乐,长一岁,age+1
*/
void happyBirthday(Long personId);
}
贫血模型
贫血模型是在失血模型的基础上聚合了对应领域范畴的业务领域行为,不仅仅是简单的setter/getter,但在行为过程中对领域对象的状态发生的变化只停留在内存层面,不关心其数据的持久化,即不依赖Repository/DAO,把数据持久化放在service中按需处理。
public class Person extends Entity {
/**
* 姓名
*/
private String name;
/**
* 生日
*/
private Date birthday;
/**
* 年龄
*/
private Integer age;
/**
* 判断今天是否生日
*/
public boolean isTodayBirthday() {
SimpleDateFormat sdf = new SimpleDateFormat("MM-dd");
return sdf.format(birthday).equals(sdf.format(new Date()));
}
/**
* 生日快乐,长一岁,age+1
*/
public void happyBirthday() {
age++;
}
public String getName() {
return name;
}
public void setName(String name) {
if (StringUtils.isBlank(name)) {
// throw a exception
}
this.name = name;
}
public Date getBirthday() {
return birthday;
}
public void setBirthday(Date birthday) {
if (birthday == null) {
// throw a exception
}
this.birthday = birthday;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
if (age == null || age < 0) {
// throw a exception
}
this.age = age;
}
}
充血模型
充血模型是在贫血模型的基础上,依赖repository,在业务领域行为执行过程中也负责数据的持久化存储。
public class Person extends Entity {
@Autowired
private PersonRepository personRepository;
/**
* 姓名
*/
private String name;
/**
* 生日
*/
private Date birthday;
/**
* 年龄
*/
private Integer age;
/**
* 判断今天是否生日
*/
public boolean isTodayBirthday() {
SimpleDateFormat sdf = new SimpleDateFormat("MM-dd");
return sdf.format(birthday).equals(sdf.format(new Date()));
}
/**
* 生日快乐,长一岁,age+1
*/
public void happyBirthday() {
age++;
// 数据持久化
personRepository.update(this);
}
public String getName() {
return name;
}
public void setName(String name) {
if (StringUtils.isBlank(name)) {
// throw a exception
}
this.name = name;
}
public Date getBirthday() {
return birthday;
}
public void setBirthday(Date birthday) {
if (birthday == null) {
// throw a exception
}
this.birthday = birthday;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
if (age == null || age < 0) {
// throw a exception
}
this.age = age;
}
}
胀血模型
这种模式下连service都不需要了,所有的业务逻辑、数据存储都放到一个类中。
public class Person extends Entity {
@Autowired
private PersonMapper personMapper;
/**
* 姓名
*/
private String name;
/**
* 生日
*/
private Date birthday;
/**
* 年龄
*/
private Integer age;
/**
* 判断今天是否生日
*/
public boolean isTodayBirthday() {
SimpleDateFormat sdf = new SimpleDateFormat("MM-dd");
return sdf.format(birthday).equals(sdf.format(new Date()));
}
/**
* 生日快乐,长一岁,age+1
*/
public void happyBirthday() {
age++;
modify();
}
/**
* 查询
*/
public static Person getById(Long id) {
PersonDO personDO = personMapper.selectById(id);
Person person = PersonConvertor.toPerson(personDO);
return person;
}
/**
* 新增
*/
public static Person create(String name, Date birthday, Integer age) {
// 这里省略了事务管理,入参校验等,相当于service层需要做的都在这里处理
Person person = new Person();
person.setName(name);
person.setBirthday(birthday);
person.setAge(age);
personMapper.insert(person);
return person;
}
/**
* 修改
*/
public void modify() {
// 这里省略了事务管理,入参校验等,相当于service层需要做的都在这里处理
personMapper.update(this);
}
public String getName() {
return name;
}
public void setName(String name) {
if (StringUtils.isBlank(name)) {
// throw a exception
}
this.name = name;
}
public Date getBirthday() {
return birthday;
}
public void setBirthday(Date birthday) {
if (birthday == null) {
// throw a exception
}
this.birthday = birthday;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
if (age == null || age < 0) {
// throw a exception
}
this.age = age;
}
}
对于DDD来说,失血模型和胀血模型无疑是不合适的,一个太轻没有聚合领域行为又回到以前的数据驱动,一个太重导致领域模型变得极不稳定,失去了领域模型的意义。而贫血模型和充血模型更加符合面向对象,把领域中核心的业务逻辑聚合在领域模型中高度复用,只是需要合理划分哪些业务逻辑放在模型中,哪些业务逻辑放在业务逻辑层中,这是这两种模型共同存在着的一个大挑战,需要开发团队有统一合理的业务认知并且守住底线,持续严格遵守。这个不在本文的讨论范围就不多说了。
三、贫血 or 充血?
那贫血模型和充血模型之间到底选择哪种模式?我们从以下四个维度来讨论。
缩小依赖范围
对于业务复杂的系统来说,维护一个大而全的领域模型是非常不明智的,从单体架构到微服务架构,都是一个不断缩小依赖范围的过程,这是一个很好的思路。DDD体系就是这种思想的驱动者,甚至细致到每一个微服务的内部的编码层面,倡导明确划分界限上下文,尽量以最小单元各司其职。
我们很容易可以看出,贫血模型和充血模型最显而易见的区别就是数据存储在不在领域模型里面完成,换言之就是领域模型有没有依赖Repository。所以从依赖范围来看,贫血模型的依赖范围是更小的。当然在这里也要为充血模型打抱不平一下,在最早的DDD架构中,Repository的接口是定义在基础设施层,如果领域模型中依赖了Repository,就相当于最核心的领域模型直接依赖了基础设施层,甚至形成双向依赖,这个肯定是不能接受的。但是现在通过依赖反转,Repository的接口定义在领域层,实现在基础设施层再通过依赖注入到领域模型中,所以充血模型即使依赖了Repository也只是依赖了同一层内部的接口,层与层之间不至于会形成双向依赖。但是相比之下,还是贫血模型更加简单,更加能体现领域模型是在最核心最底层的模块。
另外,贫血模型不依赖Repository,对于单元测试更加有优势,连Repository接口都不需要mock了,更加可以脱离框架容器来进行测试,因为剩下的都是最纯粹的可测试的领域逻辑。
关注点分离
关注点分离有时候会和单一职责原则一起拿出来说,关注点分离是对处理软件复杂性的指导原则,而单一职责是细致到指导如何面向对象设计一个类时的原则,他们都有一个共同的思想,就是解耦和增强内聚性,也就是我们经常说的“高内聚,低耦合”。
回到领域模型,领域模型的最主要职责应该是对一个业务领域的逻辑抽象,它应该是可以独立不依赖任何技术框架而存在的。贫血模型和充血模型的区别是数据的持久化存储,如果是最纯粹的业务逻辑为什么要关心数据的存储呢?假设系统的运行内存是无限大的话,是不是不持久化存储也可以照常运行呢?可能有人会说这是在脱离实际说话,不过我是想说我们只是在用一个极端条件来探讨一个理论概念,从而明确理论指导的正确性。我们实际开发中当然需要考虑数据的持久化存储,但我们是否可以把数据存储从领域模型中分离出来呢?我认为是可以的。
我们先明确一点,与领域模型相关的数据操作应该是与其领域对象的状态相关并只与这一个对象相关(如修改这个对象本身的信息/状态/包含的关系等),充血模型依赖的Repository做的也应该是这里业务相关的存储。而与这单个对象状态不相关的数据操作,如查询、跨多个模型的数据操作、对同一个模型的一批对象的数据操作,是不应该放在充血模型依赖的Repository里面的。这么看来,如果使用充血模型,我们对数据的操作是既要落在领域模型里面,也要落在模型之外的各种服务方法里,而且这些地方都要关注事务管理的问题,这就变得关注点比较杂多了。这样是不是使用贫血模型,只对数据操作停留在内存状态层面,输出有状态的对象,由专门处理事务的服务方法去进行数据存储好一些呢?
可复用性
DDD在统一领域语言、明确划分界限上下文、领域之间尽量避免存在重复的业务逻辑这些方面就充分体现了可复用性这一点。
在可复用的角度来看贫血模型和充血模型,更纯粹的贫血模型无疑是可复用性更高的,如果我想复用领域模型中的某个修改状态的方法,只是想获取变更后的状态,并不想将它持久化,那么对于充血模型的这个方法就不能复用了。
一般来说,职责过多、关注点过多的方法,都不利于提高可复用性,这点与上面讨论的关注点分离也是能相呼应的。
向稳定的方向依赖
无论是哪个版本的DDD分层架构图,领域层都是最核心最底层的,而领域模型则是核心中的核心,因为领域模型应该是整个系统中最稳定的一块,这也是它的价值所在。所以我们才会在一开始花大量的时间对领域建模,就是希望设计出稳定健壮的、可以应对后面各种业务变化的领域模型。试问如果一个软件系统,最核心的业务也扛不住变化的话,这个系统还有什么意义?
既然领域模型是我们系统的最核心模块,那么所有的依赖方向都应该是指向它的,否则无法保证它的稳定性。而充血模型依赖了Repository接口,还是会有破坏稳定性的风险。有人会提出,只是依赖了同一层中的接口,又不是实现,应该还好吧。即使是接口,这个调用过程的入参出参也无形让他们之间建立了各种联系,而Repository接口的入参出参是与数据存储结构密切相关的,而我理解领域模型可以不一定与数据存储结构紧密相关,最好是可以脱离数据存储结构,因为在系统演进过程中,数据存储结构有一些小调整是常有的事情。
到这里,我们最终在贫血模型和充血模型之间的选择已经很明显了,但是这是不是最好的选择呢?不一定,有很多结论还是要通过大量的实践、架构的演进、技术的改进中,一一去论证。但是,我们必须找到当下认为的最优解去实施落地,开始旅程,否则都是无尽的讨论。