mmdet3d使用waymo数据集训练及可视化
一、mmdet3d环境搭建
参考:
Ubuntu22.04安装mmdet 2.25.1+ mmdet3d 1.0.0rc6 https://blog.csdn.net/weixin_44013732/article/details/130675061
https://blog.csdn.net/weixin_44013732/article/details/130675061
二、Waymo数据集
1、下载Waymo数据集
注:在下载数据集前请配置好科学上网。
官网下载地址:
https://waymo.com/open/download/https://waymo.com/open/download/进入页面如下图所示

由于1.4.0及以上版本仅是对3D语义分割有所改动,所以对于3D目标检测来说,无需考虑这些版本问题。这里我们以1.4.1版本为例:

进入页面后,我们看到有archived_files/以及individual_files/,区别是,上面的archived_files/用压缩包将数据文件打包好了。下面的individual_files/是将数据文件一个一个分开的。下面是archived_files解压后的结果,和individual_files/下载的结果一样。

这里选择individual_files/作为例子,接下来会有两种下载方式:
1、gsutil

我们在这里选择testing,training和validation进行下载,会弹出以下的指令:

通过调用以上gsutil命令就可下载数据集,但是需要注意的几点是:
①配置ubuntu科学上网:gsutil需要提前配置好代理相关服务,否则会显示链接不上网络。
②网络需要畅通:下载时需要保持网络畅通,否则中间掉线需要重新开始下。
2、手动下载
这个方法也是我推荐的方法,虽然过程繁琐但是不会出错。
进入到需要下载的文件夹下:testing/,一个一个进行下载,这样就不会弹出gsutil命令界面。

training和validation也是同样的下载方式,下载下来的格式是*.tfrecord二进制文件,接下来需要对其进行数据格式转换。
2、Waymo数据集转换成KITTI数据集
官方教程:
Dataset Preparation — MMDetection3D 1.2.0 documentationhttps://mmdetection3d.readthedocs.io/en/latest/user_guides/dataset_prepare.html
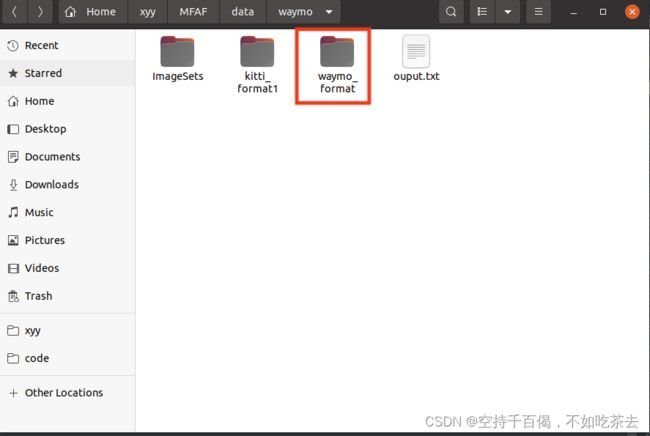
1、 数据集存放
将数据集copy到/mmmdet3d-master/data/waymo/waymo_format中,其中waymo_format文件需要自己新建,转换时会自动检索到waymo_format文件夹。整体结构如下:
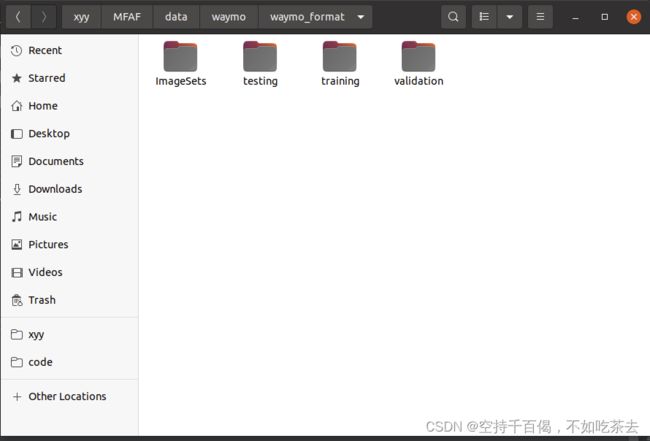
进入到文件夹内,文件如下:
2、更改源代码:create.py
位置:mmdetection3d-master/tools/create_data.py
转换过程需要更改部分源代码,以生成正确的ImageSets/training.txt等,将自动生成ImageSet的函数放到create.py里,
def create_ImageSets_img_ids(root_dir):
names_dict=dict()
save_dir = osp.join(root_dir, 'ImageSets/')
if not osp.exists(save_dir): os.mkdir(save_dir)
load_01 =osp.join(root_dir, 'training/calib')
load_2 = osp.join(root_dir, 'testing/calib')
RawNames = os.listdir(load_01) + os.listdir(load_2)
split = [[],[],[]]
for name in RawNames:
if name.endswith('.txt'):
idx = name.replace('.txt', '\n')
split[int(idx[0])].append(idx)
for i in range(3):
split[i].sort()
open(save_dir+'train.txt','w').writelines(split[0])
open(save_dir+'val.txt','w').writelines(split[1])
open(save_dir+'trainval.txt','w').writelines(split[0]+split[1])
open(save_dir+'test.txt','w').writelines(split[2])
同时通过waymo_data_prep函数进行调用:
def waymo_data_prep(root_path,
info_prefix,
version,
out_dir,
workers,
max_sweeps=5):
"""Prepare the info file for waymo dataset.
Args:
root_path (str): Path of dataset root.
info_prefix (str): The prefix of info filenames.
out_dir (str): Output directory of the generated info file.
workers (int): Number of threads to be used.
max_sweeps (int, optional): Number of input consecutive frames.
Default: 5. Here we store pose information of these frames
for later use.
"""
from tools.data_converter import waymo_converter as waymo
splits = ['training', 'validation', 'testing']
for i, split in enumerate(splits):
load_dir = osp.join(root_path, 'waymo_format', split)
if split == 'validation':
save_dir = osp.join(out_dir, 'kitti_format', 'training')
else:
save_dir = osp.join(out_dir, 'kitti_format', split)
converter = waymo.Waymo2KITTI(
load_dir,
save_dir,
prefix=str(i),
workers=workers,
test_mode=(split == 'testing'))
converter.convert()
# Generate waymo infos
out_dir = osp.join(out_dir, 'kitti_format')
create_ImageSets_img_ids(out_dir)
kitti.create_waymo_info_file(
out_dir, info_prefix, max_sweeps=max_sweeps, workers=workers)
GTDatabaseCreater(
'WaymoDataset',
out_dir,
info_prefix,
f'{out_dir}/{info_prefix}_infos_train.pkl',
relative_path=False,
with_mask=False,
num_worker=workers).create()最后附上完整代码:
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
from os import path as osp
from tools.data_converter import indoor_converter as indoor
from tools.data_converter import kitti_converter as kitti
from tools.data_converter import lyft_converter as lyft_converter
from tools.data_converter import nuscenes_converter as nuscenes_converter
from tools.data_converter.create_gt_database import (
GTDatabaseCreater, create_groundtruth_database)
import os
def kitti_data_prep(root_path,
info_prefix,
version,
out_dir,
with_plane=False):
"""Prepare data related to Kitti dataset.
Related data consists of '.pkl' files recording basic infos,
2D annotations and groundtruth database.
Args:
root_path (str): Path of dataset root.
info_prefix (str): The prefix of info filenames.
version (str): Dataset version.
out_dir (str): Output directory of the groundtruth database info.
with_plane (bool, optional): Whether to use plane information.
Default: False.
"""
kitti.create_kitti_info_file(root_path, info_prefix, with_plane)
kitti.create_reduced_point_cloud(root_path, info_prefix)
info_train_path = osp.join(root_path, f'{info_prefix}_infos_train.pkl')
info_val_path = osp.join(root_path, f'{info_prefix}_infos_val.pkl')
info_trainval_path = osp.join(root_path,
f'{info_prefix}_infos_trainval.pkl')
info_test_path = osp.join(root_path, f'{info_prefix}_infos_test.pkl')
kitti.export_2d_annotation(root_path, info_train_path)
kitti.export_2d_annotation(root_path, info_val_path)
kitti.export_2d_annotation(root_path, info_trainval_path)
kitti.export_2d_annotation(root_path, info_test_path)
create_groundtruth_database(
'KittiDataset',
root_path,
info_prefix,
f'{out_dir}/{info_prefix}_infos_train.pkl',
relative_path=False,
mask_anno_path='instances_train.json',
with_mask=(version == 'mask'))
def nuscenes_data_prep(root_path,
info_prefix,
version,
dataset_name,
out_dir,
max_sweeps=10):
"""Prepare data related to nuScenes dataset.
Related data consists of '.pkl' files recording basic infos,
2D annotations and groundtruth database.
Args:
root_path (str): Path of dataset root.
info_prefix (str): The prefix of info filenames.
version (str): Dataset version.
dataset_name (str): The dataset class name.
out_dir (str): Output directory of the groundtruth database info.
max_sweeps (int, optional): Number of input consecutive frames.
Default: 10
"""
nuscenes_converter.create_nuscenes_infos(
root_path, info_prefix, version=version, max_sweeps=max_sweeps)
if version == 'v1.0-test':
info_test_path = osp.join(root_path, f'{info_prefix}_infos_test.pkl')
nuscenes_converter.export_2d_annotation(
root_path, info_test_path, version=version)
return
info_train_path = osp.join(root_path, f'{info_prefix}_infos_train.pkl')
info_val_path = osp.join(root_path, f'{info_prefix}_infos_val.pkl')
nuscenes_converter.export_2d_annotation(
root_path, info_train_path, version=version)
nuscenes_converter.export_2d_annotation(
root_path, info_val_path, version=version)
create_groundtruth_database(dataset_name, root_path, info_prefix,
f'{out_dir}/{info_prefix}_infos_train.pkl')
def lyft_data_prep(root_path, info_prefix, version, max_sweeps=10):
"""Prepare data related to Lyft dataset.
Related data consists of '.pkl' files recording basic infos.
Although the ground truth database and 2D annotations are not used in
Lyft, it can also be generated like nuScenes.
Args:
root_path (str): Path of dataset root.
info_prefix (str): The prefix of info filenames.
version (str): Dataset version.
max_sweeps (int, optional): Number of input consecutive frames.
Defaults to 10.
"""
lyft_converter.create_lyft_infos(
root_path, info_prefix, version=version, max_sweeps=max_sweeps)
def scannet_data_prep(root_path, info_prefix, out_dir, workers):
"""Prepare the info file for scannet dataset.
Args:
root_path (str): Path of dataset root.
info_prefix (str): The prefix of info filenames.
out_dir (str): Output directory of the generated info file.
workers (int): Number of threads to be used.
"""
indoor.create_indoor_info_file(
root_path, info_prefix, out_dir, workers=workers)
def s3dis_data_prep(root_path, info_prefix, out_dir, workers):
"""Prepare the info file for s3dis dataset.
Args:
root_path (str): Path of dataset root.
info_prefix (str): The prefix of info filenames.
out_dir (str): Output directory of the generated info file.
workers (int): Number of threads to be used.
"""
indoor.create_indoor_info_file(
root_path, info_prefix, out_dir, workers=workers)
def sunrgbd_data_prep(root_path, info_prefix, out_dir, workers, num_points):
"""Prepare the info file for sunrgbd dataset.
Args:
root_path (str): Path of dataset root.
info_prefix (str): The prefix of info filenames.
out_dir (str): Output directory of the generated info file.
workers (int): Number of threads to be used.
"""
indoor.create_indoor_info_file(
root_path,
info_prefix,
out_dir,
workers=workers,
num_points=num_points)
def create_ImageSets_img_ids_1(root_dir):
names_dict=dict()
save_dir = osp.join(root_dir, 'ImageSets/')
if not osp.exists(save_dir): os.mkdir(save_dir)
load_01 =osp.join(root_dir, 'training/calib')
load_2 = osp.join(root_dir, 'testing/calib')
RawNames = os.listdir(load_01) + os.listdir(load_2)
split = [[],[],[]]
for name in RawNames:
if name.endswith('.txt'):
idx = name.replace('.txt', '\n')
split[int(idx[0])].append(idx)
for i in range(3):
split[i].sort()
open(save_dir+'train.txt','w').writelines(split[0])
open(save_dir+'val.txt','w').writelines(split[1])
open(save_dir+'trainval.txt','w').writelines(split[0]+split[1])
open(save_dir+'test.txt','w').writelines(split[2])
def create_ImageSets_img_ids(root_dir):
names_dict = dict()
save_dir = osp.join(root_dir, 'ImageSets/')
if not osp.exists(save_dir): os.mkdir(save_dir)
load_01 = osp.join(root_dir, 'training/calib')
load_2 = osp.join(root_dir, 'testing/calib')
RawNames = os.listdir(load_01) + os.listdir(load_2)
split = [[], [], []]
for name in RawNames:
if name.endswith('.txt'):
idx = name.replace('.txt', '\n')
split[int(idx[0])].append(idx)
for i in range(3):
split[i].sort()
open(save_dir + 'train.txt', 'w').writelines(split[0])
open(save_dir + 'val.txt', 'w').writelines(split[1])
open(save_dir + 'trainval.txt', 'w').writelines(split[0] + split[1])
open(save_dir + 'test.txt', 'w').writelines(split[2])
def waymo_data_prep(root_path,
info_prefix,
version,
out_dir,
workers,
max_sweeps=5):
"""Prepare the info file for waymo dataset.
Args:
root_path (str): Path of dataset root.
info_prefix (str): The prefix of info filenames.
out_dir (str): Output directory of the generated info file.
workers (int): Number of threads to be used.
max_sweeps (int, optional): Number of input consecutive frames.
Default: 5. Here we store pose information of these frames
for later use.
"""
from tools.data_converter import waymo_converter as waymo
splits = ['training', 'validation', 'testing']
for i, split in enumerate(splits):
load_dir = osp.join(root_path, 'waymo_format', split)
if split == 'validation':
save_dir = osp.join(out_dir, 'kitti_format', 'training')
else:
save_dir = osp.join(out_dir, 'kitti_format', split)
converter = waymo.Waymo2KITTI(
load_dir,
save_dir,
prefix=str(i),
workers=workers,
test_mode=(split == 'testing'))
converter.convert()
# Generate waymo infos
out_dir = osp.join(out_dir, 'kitti_format')
create_ImageSets_img_ids(out_dir)
kitti.create_waymo_info_file(
out_dir, info_prefix, max_sweeps=max_sweeps, workers=workers)
GTDatabaseCreater(
'WaymoDataset',
out_dir,
info_prefix,
f'{out_dir}/{info_prefix}_infos_train.pkl',
relative_path=False,
with_mask=False,
num_worker=workers).create()
parser = argparse.ArgumentParser(description='Data converter arg parser')
parser.add_argument('dataset', metavar='kitti', help='name of the dataset')
parser.add_argument(
'--root-path',
type=str,
default='./data/kitti',
help='specify the root path of dataset')
parser.add_argument(
'--version',
type=str,
default='v1.0',
required=False,
help='specify the dataset version, no need for kitti')
parser.add_argument(
'--max-sweeps',
type=int,
default=10,
required=False,
help='specify sweeps of lidar per example')
parser.add_argument(
'--with-plane',
action='store_true',
help='Whether to use plane information for kitti.')
parser.add_argument(
'--num-points',
type=int,
default=-1,
help='Number of points to sample for indoor datasets.')
parser.add_argument(
'--out-dir',
type=str,
default='./data/kitti',
required=False,
help='name of info pkl')
parser.add_argument('--extra-tag', type=str, default='kitti')
parser.add_argument(
'--workers', type=int, default=4, help='number of threads to be used')
args = parser.parse_args()
if __name__ == '__main__':
if args.dataset == 'kitti':
kitti_data_prep(
root_path=args.root_path,
info_prefix=args.extra_tag,
version=args.version,
out_dir=args.out_dir,
with_plane=args.with_plane)
elif args.dataset == 'nuscenes' and args.version != 'v1.0-mini':
train_version = f'{args.version}-trainval'
nuscenes_data_prep(
root_path=args.root_path,
info_prefix=args.extra_tag,
version=train_version,
dataset_name='NuScenesDataset',
out_dir=args.out_dir,
max_sweeps=args.max_sweeps)
test_version = f'{args.version}-test'
nuscenes_data_prep(
root_path=args.root_path,
info_prefix=args.extra_tag,
version=test_version,
dataset_name='NuScenesDataset',
out_dir=args.out_dir,
max_sweeps=args.max_sweeps)
elif args.dataset == 'nuscenes' and args.version == 'v1.0-mini':
train_version = f'{args.version}'
nuscenes_data_prep(
root_path=args.root_path,
info_prefix=args.extra_tag,
version=train_version,
dataset_name='NuScenesDataset',
out_dir=args.out_dir,
max_sweeps=args.max_sweeps)
elif args.dataset == 'lyft':
train_version = f'{args.version}-train'
lyft_data_prep(
root_path=args.root_path,
info_prefix=args.extra_tag,
version=train_version,
max_sweeps=args.max_sweeps)
test_version = f'{args.version}-test'
lyft_data_prep(
root_path=args.root_path,
info_prefix=args.extra_tag,
version=test_version,
max_sweeps=args.max_sweeps)
elif args.dataset == 'waymo':
waymo_data_prep(
root_path=args.root_path,
info_prefix=args.extra_tag,
version=args.version,
out_dir=args.out_dir,
workers=args.workers,
max_sweeps=args.max_sweeps)
elif args.dataset == 'scannet':
scannet_data_prep(
root_path=args.root_path,
info_prefix=args.extra_tag,
out_dir=args.out_dir,
workers=args.workers)
elif args.dataset == 's3dis':
s3dis_data_prep(
root_path=args.root_path,
info_prefix=args.extra_tag,
out_dir=args.out_dir,
workers=args.workers)
elif args.dataset == 'sunrgbd':
sunrgbd_data_prep(
root_path=args.root_path,
info_prefix=args.extra_tag,
num_points=args.num_points,
out_dir=args.out_dir,
workers=args.workers)
参考博客:mmdet3d纯视觉baseline之数据准备:处理waymo dataset v1.3.1_ZLTJohn的博客-CSDN博客在waymo上测纯视觉baseline(多相机模式),分很多步:处理数据集为kitti格式修改dataloader代码修改模型config修改模型target和loss修改eval pipeline的代码mmdet3d官网的waymo dataset教程过于简略,处理的结果只能给pointpillar用,而且是旧版的数据集。对初学者的我非常不友好。下面基于mmdet的教程(以下简称教程),简要归纳一下具体流程,并解释如何修改mmdet3d的代码,使得detr3d在处理waymo的道路上,迈出https://blog.csdn.net/ZLTJohn/article/details/125010804
3、开始转换
进入到mmdet3d-master/文件夹下,执行指令:
python ./tools/create_data.py waymo --root-path ./data/waymo --out-dir ./data/waymo --extra-tag waymo这里需要注意两点,第一个是在create_data.py后面加上waymo,表示转换waymo数据集;第二个加上extra-tag waymo用于将最后的pkl重新命名。
指令格式为:python ./tools/create_data.py waymo --root-path +waymo数据集所在的文件(tf文件) --out-dir +数据集输出位置 --extra-tag waymo
执行结果出现如下界面,就是开始转换:

最后,查看./data/waymo/文件夹下的kitti_format:

生成好waymo的pkl文件就算是转换完成了。
4、开始训练
以pointpillars为例:
python ./tools/train.py ./configs/pointpillars/hv_pointpillars_secfpn_sbn_2x16_2x_waymo-3d-car.py指令格式为:python ./tools/train.py + 模型文件(config)
执行结果为:

5、推理及可视化
以pointpillars为例:
python ./tools/test.py ./configs/pointpillars/hv_pointpillars_secfpn_sbn_2x16_2x_waymo-3d-car.py ./work_dirs/hv_pointpillars_secfpn_sbn_2x16_2x_waymo-3d-car/pv_rcnn.pth --eval 'kitti' --eval-options 'show=True' 'out_dir=./test_results/pointpillars_test_result'
指令格式为:python ./tools/test.py + 模型文件(config)+权重文件pth --eval 'kitti' --eval-options 'show=True' + 输出位置
评价指标用的是kitti,对应指令的:--eval 'kitti',你也可以选择waymo的评价方式,但是安装过程较为麻烦,需要自己尝试去安装一下。
执行结果如下:
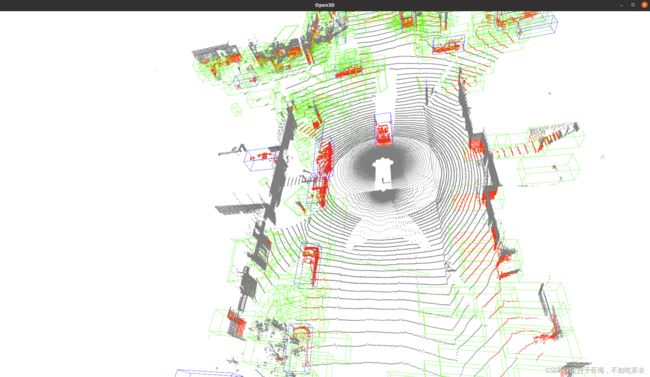
a.推理结果

b.可视化结果