网络爬虫的本质是什么?
用人工来采集数据可以吗?可以,就是太慢了。
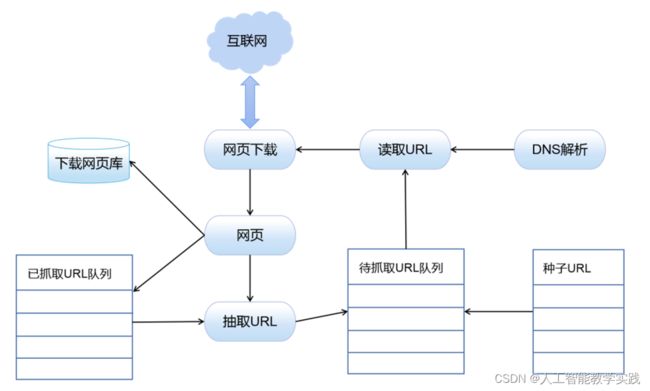
网络爬虫的本质是通过自动化程序模拟人类在互联网上的浏览行为,从而收集和提取特定网站上的信息。
具体来说,网络爬虫是一种自动化工具,它使用HTTP协议向网站发送请求,并从网站的响应中提取所需的数据。爬虫可以按照事先定义好的规则和逻辑,自动地遍历网页链接、解析HTML内容、抓取文本、图像等资源,并将这些数据提取、处理和存储下来。
网络爬虫通常由以下几个关键步骤组成:
-
发送请求:爬虫根据预设的起始URL向目标网站发送HTTP请求,并获取响应。
-
解析HTML:爬虫对返回的HTML页面进行解析,识别并提取出其中的链接、数据和其他相关信息。
-
遍历链接:爬虫根据规则从当前页面提取的链接,进一步构建新的URL列表,并继续发送请求,以便抓取更多页面。
-
数据提取与存储:对每个页面的内容进行处理和筛选,提取出所需的数据,并将其存储到数据库、文件或其他形式的存储介质中。
-
重复执行:爬虫根据设定的规则和逻辑,持续地进行上述操作,直到满足停止条件。
网络爬虫在多个领域有广泛应用,例如搜索引擎的网页索引、数据挖掘与分析、信息收集、价格比较、舆情监测等。