【统计学】stata 梳理输出命令逻辑关系 asdoc outreg2 logout esttab区别 优劣势
一、概述
初学stata的时候对于stata输出的逻辑颇为疑惑, 因为学python和cpp的时候输出函数就是那几个非常的简单,而statac的asdoc、outreg2、logout 和 esttab 这些常见的命令在跳出来的时候往往分不清楚,也不知道为什么代码里要这么用。
本文就是梳理常见的一些输出命令,在平时学习尤其是计量经济学这样的学科时能够降低理解难度。
本文主要梳理的命令包括但不限于 asdoc、outreg2、logout 和 esttab ,主要介绍其用法。以上命令都可以通过 ssc install 命令名称, replace 安装更新
二、结果输出的各种命令
一般来说,outreg2 只支持描述性统计输出和回归结果输出,logout 支持分组 T 均值检验和相关系数矩阵的输出,tabstat一般用于输出基本统计量,asdoc支持描述性统计输出,局限性较大;esttab在回归结果、描述性统计、分组T均值检验和相关系数矩阵的输出都较为实用,运用范围比较广。
总的来说就是 初学stata可以多关注关注logout和asdoc,注重研究的可以多学习esttab和outreg2。
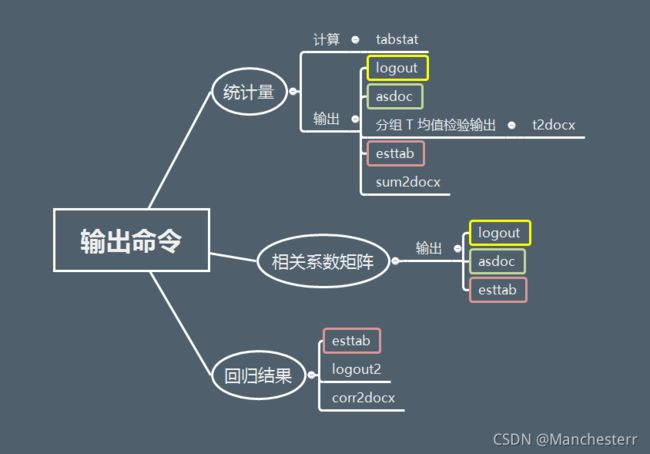
三、统计量
- 计算(想要得到多个数据的基本统计量)
tabstat

从初学角度,stats是statistics的缩写,代表设置输出格式 - statistics():可以输入的全部统计量有:N mean sd min median max p1 p5 p10 p25 p75 p90 p95 p99。若为空,则默认输入N mean sd min median max。
- 上述命令的意思是输出这几个维度的mean sd min p50 和max几个统计量 数据格式为f(%6.2f)

- 输出
logout将上述基本统计量表格输出至Word/EXCEL
*输出至word
logout ,save(table) word replace: ///
tabstat price wei len mpg rep78, ///
stats(mean sd min p50 max) c(s) f(%6.2f)
*输出至excel
logout ,save(table) excel replace: ///
tabstat price wei len mpg rep78, ///
stats(mean sd min p50 max) c(s) f(%6.2f)
asdoc是另外一个很有力的输出方法,sum代表summarize,像summarize、correlate、tabstat、cross-tabs、regressions、t-tests等命令的结果输出都可以通过这种方法,只要在前面加一个"asdoc“就可以了
asdoc也可以将多个回归结果融合成一个表格,不断滚雪球;也可以按照分类进行分组描述性统计
想了解更多的asdoc命令或者有看不懂的地方可以戳这个链接asdoc:Stata 结果输出又一利器!
local varlist "wage age race married grade collgrad south union occupation"
///这里你们要自己试验的话就把varlist里字符替换成自己的变量好了
asdoc sum `varlist', save(Myfile.rtf) replace ///
stat(N mean sd min p50 max) dec(3) ///
title(asdoc_Table: Descriptive statistics)
esttab能分别设置每个统计量的小数点位数,通过在相应的统计量后面加(fmt(n))来实现控制n位小数位数
local varlist "wage age race married grade collgrad south union occupation"
estpost summarize `varlist', detail
esttab using Myfile.rtf, ///
cells("count mean(fmt(2)) sd(fmt(2)) min(fmt(4)) p50(fmt(4)) max(fmt(4))") ///
noobs compress replace title(esttab_Table: Descriptive statistics)
如果变量名字想用中文的可以试试sum2docx,它也可以像esttab一样控制小数位数,但是缺点在于没办法在命令界面看到结果。
local varlist "wage age race married grade collgrad south union occupation"
sum2docx `varlist' using Myfile.docx,replace ///
stats(N mean(%9.2f) sd(%9.3f) min(%9.2f) median(%9.2f) max(%9.2f)) ///
title(sum2docx_Table: Descriptive statistics)
以上命令在自己运行时将varlist局部变量""中的变量替换成自己的变量即可。
例如:
local varlist " prate mrate totpart totelg"
estpost summarize `varlist', detail
esttab using Myfile.rtf, ///
cells("count mean(fmt(2)) sd(fmt(2))") ///
noobs compress replace title(esttab_Table: My Descriptive statistics)
四、相关系数矩阵
asdoc命令比较简单,但是局限性很多,没办法自定义星号和p值输出,适合初学使用
local varlist "wage age race married grade collgrad"
asdoc cor `varlist', save(Myfile.doc) replace nonum dec(3) ///
title(asdoc_Table: correlation coefficient matrix)
corr2docx支持中文,而其他命令不行。
local varlist "wage age race married grade collgrad"
corr2docx `varlist' using Myfile.docx, replace spearman(ignore) pearson(pw) ///
star title(corr2docx_Table: correlation coefficient matrix)
在输出时logout会出现串行问题,也没办法输出标题,所以比较麻烦,不推荐使用
local varlist "wage age race married grade collgrad"
logout, save(Myfile) word replace : pwcorr_a `varlist', ///
star1(0.01) star5(0.05) star10(0.1)
可以自定义星号的方法:pwcorr_a和esttab(esttab的使用和引申可以具体看一下这篇文章,解释了一下命令的理解方法和逻辑)
pwcorr_a price weight mpg displ, star1(0.01) star5(0.05) star10(0.1)
sysuse auto, clearlogout, save(数量经济学) word replace: ///
pwcorr_a price wei len mpg displ, star1(0.01) star5(0.05) star10(0.1)
///
///esttab
///
local varlist "wage age race married grade collgrad"
estpost correlate `varlist', matrix
esttab using Myfile.rtf, ///
unstack not noobs compress nogaps replace star(* 0.1 ** 0.05 *** 0.01) ///
b(%8.3f) p(%8.3f) title(esttab_Table: correlation coefficient matrix)
五、回归结果
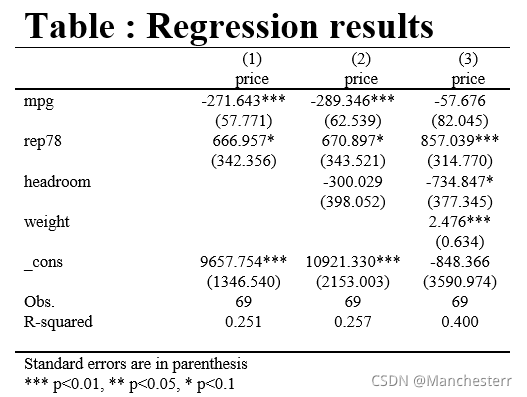
最符合一般投稿、研究、各种文献的图表格式的命令esttab,做出的图是这样的(注意统计量和变量在表中的位置)

命令如下:
reg wage age married occupation
est store r1
reg wage age married collgrad occupation
est store r2
reg wage age married collgrad occupation race_num*
est store r3
esttab r1 r2 r3 using Myfile.rtf, ///
replace star( * 0.10 ** 0.05 *** 0.01 ) nogaps compress ///
order(married) drop(occupation) b(%20.3f) se(%7.2f)
///按married排序,同时舍弃occupation
r2(%9.3f) ar2 aic bic obslast scalars(F) ///
indicate("race=race_num*") mtitles("OLS -1" "OLS-2" "OLS-3") ///
title(esttab_Table: Regression result)
asdoc命令输出的图片不如前者正规,且不能对变量排序,可理解为”滚雪球多次"
asdoc reg wage age married occupation, save(Myfile.doc) nest replace ///
cnames(OLS-1) rep(se) add(race, no)
asdoc reg wage age married collgrad occupation, save(Myfile.doc) nest append ///
cnames(OLS-2) add(race, no)
asdoc reg wage age married collgrad occupation race_num*, save(Myfile.doc) nest append ///
add(race, yes) cnames(OLS-3) dec(3) drop(occupation race_num*) ///
stat(r2_a, F, rmse, rss) title(asdoc_Table: regression result)
但是如果研究仅仅需要输出R^2,不需要F统计量不需要在第三次回归后增添统计量,可以使用asdoc,比较方便,结果如图。(详细请看asdoc:Stata 结果输出又一利器!
)
参考:
Stata:毕业论文大礼包 A——实证结果输出命令大比拼
Stata结果输出:logout、esttab、logout2