Python函数基础介绍——函数定义和调用
文章目录
- Python函数基础介绍
-
- 函数定义
-
- 函数参数
-
- 位置参数
- 关键字参数
- 特殊参数
- 默认参数
- 变长参数
- 参数拆分
- 函数文档字符串
- 函数注解
Python函数基础介绍
函数定义
函数可用于将相关功能打包并参数化,能提高应用的模块性,和代码的重复利用率。Python提供了很多内置函数,其标准库和第三方库又增加了数百个函数。可以通过查阅Python在线文档来了解有哪些内置函数和标准库函数可以使用和怎么使用。
同时Python也可以自定义函数,自定义函数的语法如下:
# 函数定义
def functionName(parameters):
suite
其中,parameters是可选的,如果有多于一个的参数,就可以写成逗号分隔的标识符序列。比如,下面是一个计算梯形面积函数定义的实例:
def trapezoid_area(a, b, h):
print((a + b) * h / 2)
定义完函数后,函数是不会自动执行的,需要调用它才可以。调用函数很简单的,通过函数名(参数) 即可完成调用。比如,下面是对计算梯形面积函数的调用:
trapezoid_area(3,4,5) # 调用后打印17.5
Python中的每个函数都有一个返回值,尽管忽略返回值是完全可以的。返回值的类型没有限制,可以是单独的一个值,也可以是一组值,还可以是组合类型的值。可以在任意位置使return语句返回,如果return不带参数或者根本没有return语句,那么函数将返回None。比如,上面的梯形面积函数的返回值就是None。下面是几个返回值不是None的实例:
# 返回值不是None的梯形面积版本
def trapezoid_area(a, b, h):
return (a + b) * h / 2
# 返回a和b的较大值
def max_value(a, b):
if a > b:
return a
else:
return b
函数参数
函数参数有两个重要概念:形参和实参。形参是定义时的参数,用来接收参数用的。实参是调用时的参数,用来传递给函数用的。
位置参数
调用函数向形参传递值,依靠参数位置来传递,因此位置参数须以正确的顺序传入函数。比如,下面是一个删除字符串中的指定字符的函数:
# 删除字符串中的指定字符
def remove_character(text, characters):
characters = frozenset(characters)
res = []
for character in text:
if character not in characters:
res.append(character)
return "".join(res)
# string.ascii_letters是由ASCII字母组成的字符串
import string
# 删除 "你好Python"里的ASCII字母
# 正确顺序的调用,输出你好
print(remove_character("你好Python", string.ascii_letters))
# 错误顺序的调用,输出abcdefgijklmpqrsuvwxzABCDEFGHIJKLMNOQRSTUVWXYZ
print(remove_character(string.ascii_letters, "你好Python"))
关键字参数
调用函数向形参传递值,依靠参数名字来传递参数,因此关键字参数允许函数调用时参数的顺序与声明时不一致。比如,下面是一个计算字符串中指定字符出现次数的函数:
def character_count(text, characters):
characters = frozenset(characters)
count = 0
for character in text:
if character in characters:
count+=1
return count
import string
# 计算 "你好Python"里的ASCII字母数
# 可以使用如下四种方式调用
# 第一种,两个实参都是位置参数,输出6
print( character_count("你好Python", string.ascii_letters) )
# 第二种,第一个实参是位置参数,第二个参数是关键字参数,输出6
print( character_count("你好Python",characters=string.ascii_letters) )
# 第三种,两个都是关键字参数,并且位置一一对应,输出6
print( character_count(text="你好Python",characters=string.ascii_letters) )
# 第四种,两个都是关键字参数,并且位置不一致,输出6
print( character_count(characters=string.ascii_letters, text="你好Python") )
但是,关键字参数必须在位置参数的后面,否则会产生语法错误SyntaxError,如下:
# 下面两个调用都会产生SyntaxError错误
# 输出SyntaxError: positional argument follows keyword argument
print( character_count(text = "你好Python",string.ascii_letters) )
print( character_count(characters=string.ascii_letters,"你好Python") )
特殊参数
Python在定义函数时,可以将/作为形参,用于表明函数调用时/前面的实参必须是位置参数,但是/本身并不需要实参对应,如下一个计算ax+b的实例:
def liner(x, /, a, b):
return a * x + b
# 以下几种调用都是可行的,输出都是10
print(liner(2, 3, 4))
print(liner(2, a=3, b=4))
print(liner(2, b=4, a=3))
# 下面的调用产生TypeError异常
# TypeError: liner() got some positional-only arguments passed as keyword arguments: 'x'
print(liner(x=2, a=3, b=4))
Python在定义函数时,可以将*作为形参,用于表明函数调用时*后面的实参必须是关键字参数,同样的*本身并不需要实参对应。注意*只要求这个位置之后的实参必须是关键字参数。如下计算三角形面积的实例:
import math
def heron(a, b, c, *, unit):
s = (a + b + c) / 2
area = math.sqrt(s * (s - a) * (s - b) * (s - c))
print("{}{}".format(area, unit))
# 以下几种调用都是可行的,输出6.0meters
heron(3, 4, 5, unit="meters")
heron(3, 4, c=5, unit="meters")
heron(a=3, b=4, c=5, unit="meters")
heron(c=3, a=4, b=5, unit="meters")
heron(3, 4, unit="meters", c=5) # *号后面的关键字参数不一定要求是unit,可以是其他的关键字参数
# 下面的调用产生TypeError异常
# TypeError: heron() takes 3 positional arguments but 4 were given
heron(3, 4, 5, "meters")
默认参数
Python在定义函数时,可以给形参设置默认值,这样调用函数时,如果没有传递相应的实参,则会使用默认参数。比如下面这个将超过指定长度的字符串缩减的实例:
def shorten(text, length=25, indicator="..."):
if len(text) > length:
text = text[:length - len(indicator)] + indicator
return text
print(shorten("The Road")) # 输出The Road
print(shorten(indicator="&", text="The Road")) # 输出The Road
print(shorten("The Road", 7, "&")) # 输出The ...
print(shorten(length=7, text="The Road")) # 输出The Ro&
print(shorten("The Road", indicator="&", length=7)) # 输出The Ro&
但是,定义函数时,带默认值的形参必须在不带默认值形参的后面,否则会产生语法错误SyntaxError,如下:
# SyntaxError: non-default argument follows default argument
def shorten(length=25, text, indicator="..."):
if len(text)>length:
text = text[:length-len(indicator)]+indicator
return text
注意:给定默认值时,实际上是在执行def语句时创建的(也就是说,在创建函数时创建的),而不是在调用该函数时创建的。对固定变量,如数字和字符串没有什么区别,但是对于可变的参数,就存在一个陷阱。比如下面的几个实例:
# 在定义函数时lst引用的列表已经被创建,后续的调用都不会创建 def append_lst(x, lst=[]): lst.append(x) print(lst) other_lst = [] append_lst(1) # 输出[1] append_lst(1, other_lst) # 输出[1] append_lst(2) # 输出[1, 2] # 即使是元组这种固定序列也要小心,注意元组的元素不能是可变的 def append_tuple_lst(x, t=([],)): t[0].append(x) print(t) append_tuple_lst(1) # ([1],) append_tuple_lst(2) # ([1, 2],)上面这种用法往往不是我们所期待的,因此对于默认的可变参数,往往是在函数体里面创建默认值,如下:
def append_lst(x, lst=None): lst = [] if lst is None else lst lst.append(x) print(lst) other_lst = [] append_lst(1) # 输出[1] append_lst(1, other_lst) # 输出[1] append_lst(2) # 输出[2]
变长参数
形参里使用*args变长参数,这样args就会存放所有其他的位置参数,并且args是一个元组。args只是一个标识,可以用其他的标识名。如下计算所有变量的和的实例:
def sum_value1(*args):
print(type(args)) # 如果传递实参后args不是空元组,那么说明args前面的参数已经用位置参数传递了,就不能用关键字参数传递了。如下求和实例:
def sum_value(base, *args):
print(type(args)) # 默认参数既可以在*args的前面,也可以在*args的后面。但往往放在后面,前面的意义不大,甚至不是预期的效果或抛出异常。如下计算幂运算后求和实例:
def sum_of_power1(power=1, *args):
res = 0
for arg in args:
res += arg ** power
return res
print(sum_of_power1(2, 3, 4, 5)) # 输出 50,power是2
# 抛出TyperError异常,TypeError: sum_of_power1() got multiple values for argument 'power'
print(sum_of_power1(2, 3, 4, 5, power=1))
def sum_of_power2(*args, power=1):
res = 0
for arg in args:
res += arg ** power
return res
print(sum_of_power2(2, 3, 4, 5)) # 输出 14,power是1
print(sum_of_power2(2, 3, 4, 5, power=1)) # 输出 14,power是1
形参里可以使用**kwargs,这样kwargs就会存放所有其他的关键字参数,并且kwargs是一个元组。kwargs只是一个标识,可以用其他的标识名。如下一个输出用户信息的实例:
def print_user_info(username, sex, address="China", **kwargs):
print(type(kwargs)) # **kwargs如果存在只能放在形参的最后,否则会抛出异常SyntaxError,如下
# SyntaxError: invalid syntax
def print_user_info1(username, sex, **kwargs, address="China"):
print(type(kwargs)) # 参数拆分
传递实参时可以使用序列拆分和映射拆分语法来传递,如下几个实例:
# 序列拆分
def product(*args):
res = 1
for arg in args:
res *= arg
return args
print(product(*[1, 2, 3, 4, 5])) # 输出720
import math
def heron(a, b, c):
s = (a + b + c) / 2
return math.sqrt(s * (s - a) * (s - b) * (s - c))
t = (3, 4, 5)
print(heron(*t)) # 输出6.0
print(heron(3, *(4, 5))) # 输出6.0
# 映射拆分
def print_info(**kwargs):
for k in kwargs:
print(f"{k}: {kwargs[k]}")
info = {
"username": "Tom",
"address": "China"
}
print_info(**info)
def print_user(username, address):
print(f"username: {username}")
print(f"address: {address}")
print_user(**info)
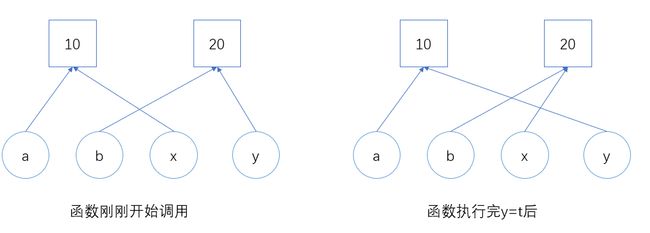
注意:由于Python的变量可以理解为都是对象引用,而不是对象本身。因此实参传递给形参时,也只是传递的引用,也就是形参和实参引用同一对象。因此形参引用其他对象后,并不影响实参引用的对象。如下几个实例:
# 下面的交换函数并不能起到作用 def swap(x, y): t = x x = y y = t a = 10 b = 20 print(a, b) # 输出10 20 swap(a, b) print(a, b) # 输出10 20
函数文档字符串
通过使用函数文档字符串(DocStrings),我们可以为任何函数添加文档信息。文档字符串可以是定义在def行之后,函数代码开始之前的字符串,如下使用heron公式计算三角形面积的实例:
import math
def heron(a, b, c):
""" 返回heron公式计算的三角形面积
"""
s = (a + b + c) / 2
return math.sqrt(s * (s - a) * (s - b) * (s - c))
也可以使用__doc__属性来访问和修改函数文档字符串,如下所示:
print(heron.__doc__) # 返回heron公式计算的三角形面积
heron.__doc__ = """返回a, b, c三边组成三角形的面积
通过heron公式计算a, b, c三个边组成的三角形的面积,并返回
"""
print(heron.__doc__)
函数文档字符串常用的做法是:第一行只是一个简短的描述,之后是一个空白行,再之后跟随的就是完整的描述信息,如下:
import math
def heron(a, b, c):
"""返回a, b, c三边组成三角形的面积
通过heron公式计算a, b, c三个边组成的三角形的面积,并返回
"""
s = (a + b + c) / 2
return math.sqrt(s * (s - a) * (s - b) * (s - c))
除此之外,文档字符串还可以给出一些实例用于单元测试和文档测试,这些实例在形式上应该像在交互式环境中输入一样(模仿交互式环境的过程)。可以导入doctest模块,doctest.testmod()函数用Python的内省功能来发现函数的文档字符串,并尝试执行其发现的代码段进行验证。默认情况下只有发生错误的情况才会产生输出信息,或者加上命令行标记-v,会输出成功和失败的测试信息,如下几个实例:
import math
def heron(a, b, c):
"""返回a, b, c三边组成三角形的面积
通过heron公式计算a, b, c三个边组成的三角形的面积,并返回
>>> heron(3,4,5)
6.0
>>> a,b,c = 7,24,25
>>> heron(a,b,c)
84.0
"""
s = (a + b + c) / 2
return math.sqrt(s * (s - a) * (s - b) * (s - c))
if __name__ == '__main__':
import doctest
doctest.testmod()
将上面的代码保存到任意一个文件,如test.py文件,然后控制台输入python test.py会产生测试信息,输出:

控制台输入python test.py -v则会产生详细的测试信息,如下:

文档字符串的实例也可以添加异常信息,通过使用Traceback行来告知doctest模块此处期待看到异常,然后使用省略号表示中间的一些代码行,最后以我们期待捕获的异常行结束,如下:
import math
def heron(a, b, c):
"""返回a, b, c三边组成三角形的面积
通过heron公式计算a, b, c三个边组成的三角形的面积,并返回
>>> heron(3,4,5)
6.0
>>> a,b,c = 7,24,25
>>> heron(a,b,c) # 正确情况是84.0
0.0
>>> heron(0,1,0)
Traceback (most recent call last):
...
ValueError: math domain error
"""
s = (a + b + c) / 2
return math.sqrt(s * (s - a) * (s - b) * (s - c))
if __name__ == '__main__':
import doctest
doctest.testmod()
注意文档字符串不是函数特有的,任何对象都有文档字符串,如模块,整数,字符串等等,都可以通过使用__doc__属性来获取和修改,比如可以用如下方法输出整数的文档字符串:
a = 1
print(a.__doc__)
函数注解
函数可以在定义时带有注解,用于记录帮助信息或标注类型,大部分时候用于标注类型,语法如下:
def functionName(par1: exp1, par2:exp2, ..., parN:expN) -> rexp:
suite
每个冒号表达式部分:expX时一个可选的注解,箭头返回表达式部分->rexp也是可选的注解。注解对Python没有特别的意义,Python唯一要做的就是将其放到__annotations__字典中。如下几个实例:
def max_value(a: int, b: int) -> int:
if a > b:
return a
else:
return b
# {'a': , 'b': , 'return': }
print(max_value.__annotations__)
print(max_value(1, 2))
print(max_value('a', 'b')) # 虽然注解要求是整型,但是也可以传递字符串 输出b
print(max_value(1.5, 2.0)) # 虽然注解要求是整型,但是也可以传递浮点型 输出2.0
虽然Python不对注解做更多的处理,但是注解可以给阅读代码的人提示,也可以用于类型检查器、IDE、静态检查器等第三方工具。以Pycharm为例,上面的代码会如下图出现提示:

Pycharm该功能默认是开启的,如过没有开启依次选择File->Settings->Editor->Inspections->Python->Type checker,勾上后点击Apply应用后,再点击OK退出,如下图所示:

Python的标准库typing模块提供了类型提示支持功能,可以用于注解的类型标注,详细的功能可以参考typing文档,下面是几个例子:
import typing
# typing.Union: 参数必须是某种类型的一个。
# typing.Sequence: 序列类型
def index(lst: list, idx: typing.Union[int, typing.Sequence[int]]) -> list:
if type(idx) == int:
return lst[idx:idx + 1]
else:
return lst[idx[0]:idx[1]]
lst = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(index(lst, 5))
print(index(lst, (5, 7)))
同样的,注解也不是函数独有的,任何变量在定义时,都可以添加注解用于记录帮助信息,如下:
a:str = "123"
b:int = 123