Efficient Net_V2
目录
0.论文地址
1.引言
2.EfficientNetV1中存在的问题
3. EfficientNetV2的创新点
4.NSA搜索
5.EfficientNetV2网络框架
6.Progressive Learning渐进学习策略
0.论文地址
https://arxiv.org/abs/2104.00298 https://arxiv.org/abs/2104.00298
https://arxiv.org/abs/2104.00298
1.引言
EfficientNetV2网络不仅Accuracy达到了当前的SOTA(State-Of-The-Art)最前沿水平,而且训练速度更快参数数量更少(比当前火热的Vision Transformer还要强)。

V2-M与V1-B7相比,准确率几乎一致,参数减少了17%,理论计算量FLOPs减少了37%,训练时间TrainTime减少了76%,推理时间InferTime减少了66%!
2.EfficientNetV1中存在的问题
1. 训练图像的尺寸很大时,训练速度非常慢。B7(img_size=600)时基本训练不动,而且非常吃显存。针对这个问题一个比较好想到的办法就是降低训练图像的尺寸,之前也有一些文章这么干过。降低训练图像的尺寸不仅能够加快训练速度,还能使用更大的batch_size。
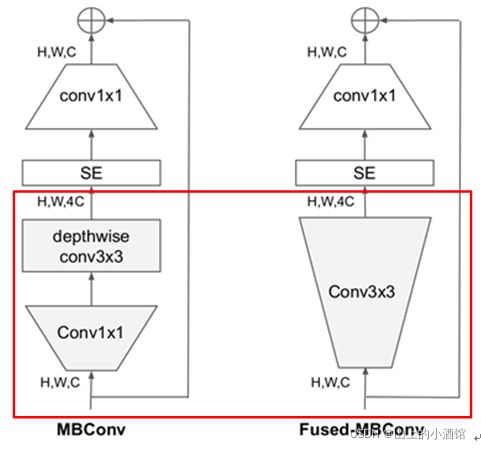
2.在网络浅层中使用Depthwise convolutions速度会很慢。 虽然Depthwise convolutions结构相比普通卷积拥有更少的参数以及更小的FLOPs,但通常无法充分利用现有的一些加速器(虽然理论上计算量很小,但实际使用起来并没有想象中那么快)。Fused-MBConv结构也非常简单,即将原来的MBConv结构(之前在将EfficientNetv1时有详细讲过)主分支中的expansion conv1x1和depthwise conv3x3替换成一个普通的conv3x3,如图2所示。作者也在EfficientNet-B4上做了一些测试,发现将浅层MBConv结构替换成Fused-MBConv结构能够明显提升训练速度。再使用NAS技术去搜索MBConv和Fused-MBConv的最佳组合。

3.同等的放大每个stage是次优的。 在EfficientNetV1中,每个stage的深度和宽度都是同等放大的。但每个stage对网络的训练速度以及参数数量的贡献并不相同,所以直接使用同等缩放的策略并不合理。在这篇文章中,作者采用了非均匀的缩放策略来缩放模型。
3. EfficientNetV2的创新点
同时关注训练速度以及参数数量。
However, their training speed often comes with the cost of more paramters. This paper aims to significantly imporve both training and parameter efficiency than prior art.
1.引入新的网络(EfficientNetV2),该网络在训练速度以及参数数量上都优于先前的一些网络。
2.提出了改进的渐进学习方法,该方法会根据训练图像的尺寸动态调节正则方法(例如dropout、data augmentation和mixup)。通过实验展示了该方法不仅能够提升训练速度,同时还能提升准确率。
3.通过实验与先前的一些网络相比,训练速度提升11倍,参数数量减少为1/6.8。
4.NSA搜索
这里采用的是trainning-aware NAS framework,搜索工作主要还是基于之前的Mnasnet以及EfficientNet. 但是这次的优化目标联合了accuracy、parameter efficiency以及trainning efficiency三个维度。这里是以EfficientNet作为backbone,设计空间包含:
convolutional operation type(MBConv、Fused-MBConv)
kernel_size(3*3、5*5)
expansion ratio(1、4、6)
在搜索空间中随机采样了1000个模型,并针对每个模型训练10个epochs(使用较小的图像尺度)。搜索奖励结合了模型准确率A,标准训练一个step所需时间S以及模型参数大小P,奖励函数可写成:
![]() 其中,w = − 0.07,v = − 0.05
其中,w = − 0.07,v = − 0.05
目标:准确率高、每个step训练时间短、模型参数少。
5.EfficientNetV2网络框架
第一个不同点在于EfficientNetV2中除了使用到MBConv模块外,还使用了Fused-MBConv模块(主要是在网络浅层中使用)。
第二个不同点是EfficientNetV2会使用较小的expansion ratio(MBConv中第一个expand conv1x1或者Fused-MBConv中第一个expand conv3x3)比如4,在EfficientNetV1中基本都是6,这样的好处是能够减少内存访问开销。
第三个不同点是EfficientNetV2中更偏向使用更小(3x3)的kernel_size,在EfficientNetV1中使用了很多5x5的kernel_size。通过下表可以看到使用的kernel_size全是3x3的,由于3x3的感受野是要比5x5小的,所以需要堆叠更多的层结构以增加感受野。
最后一个不同点是移除了EfficientNetV1中最后一个步距为1的stage(就是EfficientNetV1中的stage8,可能是因为它的参数数量过多并且内存访问开销过大。

stage0:Conv3x3就是普通的3x3卷积 + 激活函数(SiLU)+ BN
stage1-6:

注意当expansion ratio等于1时是没有expand conv的,还有这里是没有使用到SE结构的(原论文图中有SE)。注意当stride=1且输入输出Channels相等时才有shortcut连接。还需要注意的是,当有shortcut连接时才有Dropout层,而且这里的Dropout层是Stochastic Depth,即会随机丢掉整个block的主分支(只剩捷径分支,相当于直接跳过了这个block)也可以理解为减少了网络的深度

MBConv模块和EfficientNetV1中是一样的,其中模块名称后跟的4,6表示expansion ratio,SE0.25表示使用了SE模块,0.25表示SE模块中第一个全连接层的节点个数是输入该MBConv模块特征矩阵channels的1/4。注意当stride=1且输入输出Channels相等时才有shortcut连接。同样这里的Dropout层是Stochastic Depth。

配置表中,r2_k3_s1_e1_i24_o24_c1代表:Operator重复堆叠2次,kernel_size=3,stride=1,expansion=1,input_channels=24,output_channels=24,conv_type为Fused-MBConv。
EfficientNetV2-M的详细参数:在baseline(EfficientNetV1-B5)的基础上采用了width倍率因子1.6,depth倍率因子2.2得到。
EfficientNetV2-L的详细参数:在baseline(EfficientNetV1-B7)的基础上采用了width倍率因子2.0, depth倍率因子3.1得到。
6.Progressive Learning渐进学习策略
训练图像的尺寸对训练模型的效率有很大的影响。所以在之前的一些工作中很多人尝试使用动态的图像尺寸(比如一开始用很小的图像尺寸,后面再增大)来加速网络的训练,但通常会导致Accuracy降低。作者提出了一个猜想:Accuracy的降低是不平衡的正则化unbalanced regularization导致的。在训练不同尺寸的图像时,应该使用动态的正则方法(之前都是使用固定的正则方法)。训练过程中尝试使用不同的图像尺寸以及不同强度的数据增强data augmentations。当训练的图片尺寸较小时,使用较弱的数据增强augmentation能够达到更好的结果;当训练的图像尺寸较大时,使用更强的数据增强能够达到更好的接果。如下表所示,当Size=128,RandAug magnitude=5时效果最好;当Size=300,RandAug magnitude=15时效果最好:

基于以上实验,作者就提出了渐进式训练策略Progressive Learning。如上图所示,在训练早期使用较小的训练尺寸以及较弱的正则方法weak regularization,这样网络能够快速的学习到一些简单的表达能力。接着逐渐提升图像尺寸,同时增强正则方法adding stronger regularization。这里所说的regularization包括dropout rate,RandAugment magnitude以及mixup ratio。

python的学习还是要多以练习为主,想要练习python的同学,推荐可以去看,他们现在的IT题库内容很丰富,属于国内做的很好的了,而且是课程+刷题+面经+求职+讨论区分享,一站式求职学习网站,最最最重要的里面的资源全部免费。
牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网求职之前,先上牛客,就业找工作一站解决。互联网IT技术/产品/运营/硬件/汽车机械制造/金融/财务管理/审计/银行/市场营销/地产/快消/管培生等等专业技能学习/备考/求职神器,在线进行企业校招实习笔试面试真题模拟考试练习,全面提升求职竞争力,找到好工作,拿到好offer。https://www.nowcoder.com/link/pc_csdncpt_ssdxjg_python
他们这个python的练习题,知识点编排详细,题目安排合理,题目表述以指导的形式进行。整个题单覆盖了Python入门的全部知识点以及全部语法,通过知识点分类逐层递进,从Hello World开始到最后的实践任务,都会非常详细地指导你应该使用什么函数,应该怎么输入输出。
牛客网(牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网)还提供题解专区和讨论区会有大神提供题解思路,对新手玩家及其友好,有不清楚的语法,不理解的地方,看看别人的思路,别人的代码,也许就能豁然开朗。
快点击下方链接学起来吧!
牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网
参考自:
强烈推荐:10.1 EfficientNetV2网络详解_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV19v41157AU?spm_id_from=333.999.0.0
EfficientNetV2网络详解_太阳花的小绿豆的博客-CSDN博客_efficientnetv2https://blog.csdn.net/qq_37541097/article/details/116933569