pwn 入门基础
《web狗的pwn生之路》系列文章目录
第一章 pwn 入门基础
第二章 pwn 栈题基础
待更新…………
文章目录
- 《web狗的pwn生之路》系列文章目录
-
- 一、汇编基础
-
- 重点
- 笔记
- 二、Linux 基础
-
- 重点
- 笔记
- 三、调用约定
-
- 重点
- 笔记
- 四、ELF 文件结构
-
- 重点
- 笔记
- 五、延迟绑定
-
- 重点
- 笔记
- 六、Linux 保护机制
-
- 重点
- 笔记
- 七、常用工具的使用
-
- 重点
- 笔记
- 总结
一、汇编基础
重点
各寄存器的作用
常用汇编指令的使用
各寄存器的作用
笔记
主流操作系统中,都是以字节(B)为寻址单位
计算机真正能运行的是二进制形式的机器码,一般以16进制呈现
汇编语言就是机器码的助记符
通用寄存器:
RAX、RBX、RCX、RDX、RDI、RSI、R8、R9、R10、R11、R12、R13、R14、R15
RAX(RBX、RCX、RDX)向下兼容规则:
低 32 位:EAX
低 16 位:AX
低 16 位中的高 8 位:AH
低 8 位:AL
RDI(RSI、RSP)向下兼容规则:
低 32 位:EDI
R8(R9、R10、R11、R12、R13、R14、R15)向下兼容规则:
低 32 位:R8d
低 16 位:R8W
低 8 位:R8B
栈顶指针:RSP
栈底指针:RBP
栈顶指针 与 栈底指针 用于维护程序运行时的函数栈
标志寄存器:EFLAGS
包括:AF、PF、SF、ZF、OF、CF 等标识位
指令寄存器:RIP
正常情况下,不能直接修改,每次运行一条指令自增一条指令长度
若要修改,可通过 call、jmp、ret 等跳转指令
汇编寻址(加中括号的是地址)
| 寻址方式 | 表示 | 含义 |
|---|---|---|
| 立即寻址 | 1234h | 1234h数值本身 |
| 直接寻址 | [1234h] | 地址1234h |
| 寄存器寻址 | RAX | RAX寄存器存的值 |
| 寄存器间接寻址 | [RAX] | RAX存的地址 |
| 变址寻址 | [RAX + 1234h] | RAX存的值 + 1234h 这个地址 |
汇编指令(分为 intel 和 AT&T)
| 指令 | 含义 |
|---|---|
| mov rax rbx | 将 rbx 的值赋给 rax |
| lea rax [rbx] | 将 rbx 这个地址赋给 rax,同上 |
| add rax rbx | rax + rbx |
| sub rax rbx | rax - rbx |
| and rax rbx | rax & rbx |
| xor rax rbx | rax ^ rbx |
| call 1234h | 执行地址 1234h 处的函数 |
| ret | 函数返回 |
| cmp rax rbx | 比较 rax 与 rbx,保存至 EFLAGS 寄存器 |
| jmp 1234h | 使 rip = 1234h,无条件跳转到 1234h |
| push rax | 将 rax 存储到栈顶 |
| pop rax | 将栈顶的值赋给 rax,rsp+8 |
| xchg rax rbx | 交换 rax、rbx 的值 |
call 与 jmp 的异同:
call 与 jmp 都是跳转到一个地址
但是 call 会执行该地址处的函数,jmp 只跳转
二、Linux 基础
重点
大端序、小端序在计算机中的存储方式
理解栈的结构
笔记
虚拟内存是物理内存经过MUU(内存转换单元)转换后的地址(页表)
文件偏移地址 = 虚拟内存地址(VA)- 装载基址(Image Base)- 节偏移
节偏移 = 虚拟偏移 - 原始偏移
小端序
记忆口诀:高高低低
数据高位存储在计算机地址的高位
大端序
记忆口诀:高低低高
数据高位存储在计算机地址的低位
Linux 数据存储的格式是 小端序
文件描述符:
Linux 中,一切都是文件
0:标准输入、1:标准输出、2:标准错误
栈
栈是一种先进后出的数据结构,只有 push(压栈)和 pop(弹栈)两种操作
由于函数调用顺序也是 LIFO,所以我们能接触到的绝大多数系统都是通过栈来维护函数调用关系
在 Linux 中,系统为每个进程都安排了一个栈,进程中每一个调用的函数都有自己独立的栈帧
栈由高地址向低地址生长
三、调用约定
重点
了解函数调用相关的汇编指令
理解是函数调用过程中是如何维护栈平衡的
笔记
pop:
pop 指令的作用是弹栈,将栈顶的数据弹出到寄存器,然后栈顶的指针向下移动一个单位
pop rax =========> mov rax [rsp]; add rsp 8
push:
push 指令的作用是压栈,将栈顶指针向上移动一个单位,然后将一个寄存器的值存放在栈顶
push rax =========> sub rsp 8; mov [rsp] rax;
jmp:
立即跳转,不涉及函数调用,用于循环,类似高级语言 if 产生的跳转
jmp 123h =========> mov rip 123h
call:
函数调用,需要保存返回地址
call 123h =========> push rip; mov rip 123h
ret:
用于函数返回
ret =========> pop rip
leave:
作用是维护栈帧,通常出现在函数的结尾。与 ret 连用
leve =========> mov rsp rbp; pop rbp
在调用函数的时候,rip 指针指向调用函数的下一条指令
被调用函数需要维护栈帧
push rbp
mov rbp rsp
sub rsp xxx # 开启被调用函数的栈帧,xxx 为栈帧的大小
栈帧的维护就是维护 rbp 和 rsp 两个指针
rsp 永远指向栈顶
rbp 用来定位局部变量
函数的返回值会存储到 rax 寄存器
64 程序传参规则:
从左至右参数依次传递给 rdi、rsi、rdx、rcx、r8、r9
多于6个参数,后面的参数 从右至左依次压入栈中传递
syscall:
用于调用系统函数,调用时需要指明系统调用号
将系统调用号保存在 rax 寄存器中,然后布置好参数,即可执行 syscall

如:调用 read(0, buf, size)
mov rax 0;
mov rdi 0;
mov rsi buf;
mov rdx size;
syscall;
函数的调用图:

函数调用返回图:
四、ELF 文件结构
重点
了解 elf 文件的节信息
笔记
elf 是 Linux 中的二进制可执行文件
elf 的基本信息存在与 elf 的头部信息中,这些信息包括指令的允许架构、程序的入口等内容
通过 readelf -h 来查看头部信息
elf 包括许多节,各节存放不同数据,这些节的信息存放在节头表中,可以通过 readelf -s 查看
| 节名 | 存放的数据 |
|---|---|
| .text | 存放程序运行的代码 |
| .rdata | 存放一些如字符串等不可修改的数据 |
| .data | 存放一些已经初始化的可修改的数据 |
| .bss | 存放未被初始化的程序可修改的数据 |
| .plt 与 .got | 程序动态链接函数地址 |
elf 文件的节会被映射进内存中的段,映射机制是根据节的权限来进行映射的,可读可写的节被映射入一个段,只读的节被映射入一个段
五、延迟绑定
重点
了解什么是延迟绑定机制
了解 plt 与 got 的表的结构与作用
笔记
一个程序运行过程中可能会调用很多函数,但是在一次运行中并不能保证全部被调用
静态编译:
将所有可能运行到的库函数一同编译到可执行文件中
优点:不需要依赖动态链接库,适用于程序使用的动态链接库比较特殊
缺点:体积很大,编译速度很慢
动态编译:
遇到需要调用的库函数时再去动态链接库中寻找
优点:缩小了文件体积,加快了编译速度
缺点:会附带庞大的链接库;若计算机没安装对应库,则程序不能正常运行
PLT:
程序链接表,用于延迟绑定
GOT:
全局偏移表
ELF 中有两个 got 表,分别为 .got 和 .plt.got,前者用于全局变量的引用地址,后者用于保存函数的引用地址
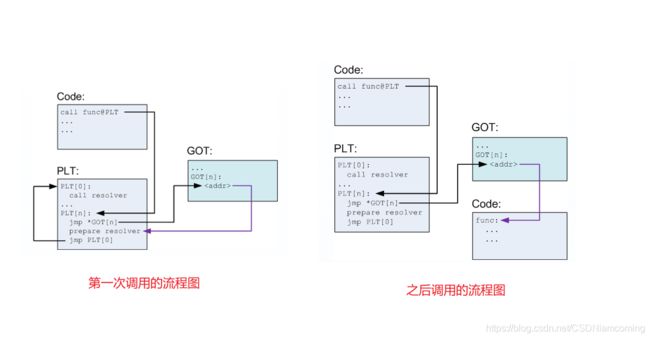
不管是程序第几次调用外部函数,程真正调用的是 plt 表
第一次调用:
plt 表会跳到对应的 got 表
此时 got 表存的是 plt 表的一段指令的地址,其作用是准备一些参数进行动态解析
之后会跳到 plt 的表头,表头的内容是动态解析函数,将目标地址存入 got 表
之后的调用
plt 表跳到对应的 got 表
got 表存的是目标地址,直接跳转到该地址
六、Linux 保护机制
重点
了解各种保护机制的实现方式和产生的效果
学会各种保护机制的基本绕过方式
笔记
canary:
用来判断程序的执行环境,主要针对栈溢出
开头为 \x00 的八字节随机数,随机数本体会存放于 fs 段偏移为 0x28 的区域
在函数调用中,程序都会将这段随机数存放于栈底,每次运行结束返回时,都会将这一随机数与本体进行对比
绕过方式:
修改 canary
泄露 canary
NX(Not Executable):
使程序中的堆、栈、bss段 等可写的段不可执行,导致不能执行我们自己编写的 shellcode
绕过方式:
用 mprotect 函数来改写段的权限
对于 rop 或 劫持got表 等利用方式不受影响
PIE 和 ASLR:
PIE 指的是 程序内存加载基地址随机化,不能一下子确定程序的基地址
ASLR 是 使程序运行动态链接库、栈等地址随机化
绕过方式:
- 泄露函数地址,通过偏移确定基地址
RELRO:
主要针对延迟绑定机制,使 got 表这种和函数动态链接相关的内存地址,对用户只读,意味着不能劫持 got 表中的函数指针
gcc 编译时关闭程序保护:
PIE: gcc -no-pie
ASLR:
查看:cat /proc/sys/kernel/randomize_va_space
关闭: echo 0 > /proc/sys/kernel/randomize_va_space
RELRO: -z norelro
canary: -fno-stack-protector
NX: -z execstack
七、常用工具的使用
重点
了解 IDA 静态调试的基本技巧
了解 gdb 动态调试的基本技巧
掌握 pwnttools 的使用
笔记
IDA:
start 是程序真正的入口,它调用了 \_\_libc_start_main,而 \_\_libc_start_main 的第一个参数正是我们的 main 函数
如果 IDA 没有识别出 main 函数,可以先找到 start,start 一定可以识别出来
遇到不明白的函数,可以在 linux 中使用 man 命令查看函数的使用手册
快键键:
| 快键键 | 作用 |
|---|---|
| h | 转 10 进制与 16 进制 |
| r | 转字符 |
| x | 查看交叉引用 |
| y | 改变变量和函数返回值的类型 |
| 选择一段数据,按 shift + e | dump 出一段字符串 |
| TAB | 转换汇编窗口和伪代码窗口 |
| 空格 | 转换两种汇编显示形式 |
gdb:
使用 gdb file_name 启动 gdb 或者 进入 gdb 后使用 file file_name 加载程序
| 命令 | 作用 |
|---|---|
| b *地址 | 在该地址处下断点 |
| info b | 查看断点信息 |
| info r | 查看寄存器的值 |
| vmmap | 查看内存的布局 |
| x/100gx 地址 | 以 16 进行格式查看 100 个四字数据(w 字、g 四字) |
| x/8i 地址 | 以指令的形式打印内存数据 |
| x/s 地址 | 以字符串的形式查看地址存的数据 |
| p &__malloc_hook | 查看 __malloc_hook 的地址 |
| p __malloc_hook | 查看 __malloc_hook 的数据 |
| p/x 0x100 - 20 | 计算 0x100-20 并以 16 进制打印 |
| search ‘/bin/sh’ | 查看内存的字符串 |
| stack 20 | 查看栈上20个数据 |
| bt 或 backtrace | 函数调用栈 |
| si | 单步步入 |
| ni | 单步不过 |
| c | 从当前位置执行到断点处 |
| r | 从程序开始执行到断点处 |
| finish | 执行到当前函数的完 |
pwntools:
| 命令 | 描述 |
|---|---|
| from pwn import * | 导入 pwntools 的包 |
| p = process(‘file’, env={‘LD_PRELOAD’: ‘libc’}) | 加载本地程序,并指定程序使用的 libc |
| r = remote(‘ip’, port) | 加载远程程序 |
| p.recv() | 接收程序传回的数据,可以添加整数参数,表示接收数据的大小 |
| p.recvuntil(‘str’) | 接收数据,直到接收完出现所给字符串为止,如果没有出现,程序会挂起 |
| p.send(‘str’) | 发送数据,末尾没有结束符 |
| p.sendline(‘str’) | 发送数据,末尾有结束符 |
| p.sendafter(‘str1’, ‘str2’) | recvuntil(‘str1’) 与 send(‘str2’) 的合体版 |
| gdb.attach(p, ‘指令’) | 启动 gdb 调试程序,并且启动前执行指令,多条指令可以使用 \n 分隔 |
| p.interactive() | 启动交互模式,可以使脚本执行完程序不退出 |
| p64、32、16、8 | 将数据转为8、4、2、1字节的机器码 |
| u64、32、16、8 | 将机器码进行解码 |
脚本模板:
from pwn import *
context(log_level='debug', os='linux', binary='file', arch='i386', terminal=['tmux', 'sp', '-h']) # arch 为文件的架构,分为 amd64 和 i386
p = process('file', env={'LD_PRELOAD': 'libc.so'})
p.recv()
p.sendline(payload)
p.interactive()
总结
最近开始比较系统的学习 pwn 知识,总结了一些基础知识的笔记,分享给师傅们,同时也希望师傅们来补充