【C进阶】第十三篇——指针详解
指针的基本概念
指针类型的参数和返回值
指针与数组
指针与const限定符
指针与结构体
指向指针的指针与指针数组
指向数组的指针与多维数组
函数类型和函数指针类型
不完全类型和复杂声明
指针的基本概念
堆栈有栈顶指针,队列有头指针和尾指针,这些概念中的"指针"本质上是一个整数,是数组的索引,通过指针访问数组中的某个元素,经过学习我们在间接寻址那里看到了另一个指针的概念,把一个变量所在的内存单元的地址保存在另外一个内存单元中,保存地址的这个内存单元称为指针,通过指针和间接寻址访问变量,这种指针在C语言中可以用一个指针类型的变量表示,例如某程序中定义了以下全局变量:
int i;
int *pi = &i;
char c;
char *pc = &c;这几个变量的内存布局如下图所示,在初学阶段经常要借助于这样的图来理解指针。
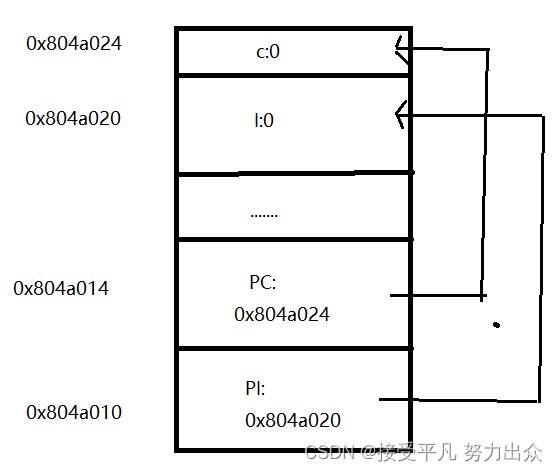
这里的&是取地址运算符,&i表示取变量i的地址,int *pi=&i;表示定义一个指向int型的指针变量pi,并用i的地址来初始化pi.我们讲过全局变量只能用常量表达式初始化,如果定义int p=i;就错了,因为i不是常量表达式,然而用i的地址来初始化一个指针却没有错,因为i的地址是在编译链接时能确定的,而不需要运行时才知道,&i是常量表达式。后面两行代码定义了一个字符型变量c和一个指向c的字符型指针pc,注意pi和pc虽然是不同类型的指针变量,但它们的内存单元都占4个字节,因为要保存32位的虚拟地址,同理,在64位平台上指针变量都占8个字节。
我们知道,在同一个语句中定义多个数组,每一个都要有[]号:int a[5],b[5];同样道理,在同一个语句中定义多个指针变量,每一个都要有*号,例如:
int *p, *q;如果写成int* p,q;就错了,这样是定义了一个整型指针p和一个整型变量q,定义数组的[]号写在变量后面,而定义指针的*号写在变量前面,更容易看错。定义指针的*号前后空格都可以省,写成int*p,*q;也算对,但*号通常和类型int之间留空格而和变量名写在一起,这样看int *p, q;就很明显是定义一个指针和一个整型变量,就不容易看错了。
如果要让pi指向另一个整型变量j,可以重新对pi赋值:
pi = &j;如果要改变pi所指向的整型变量的值,比如把变量j的值增加10,可以写:
*pi = *pi + 10;这里的*号是指针间接寻址运算符,*pi表示取指针pi所指向的变量的值,也称为Dereference操作,指针有时称为变量的引用,所以根据指针找到变量称为Dereference.
&运算符的操作数必须是左值,因为只有左值才表示一个内存单元,才会有地址,运算结果是指针类型。*运算符的操作数必须是指针类型,运算结果可以做左值。所以,如果表达式E可以做左值,*&E和E等价,如果表达式E是指针类型,&*E和E等价。
指针之间可以相互赋值,也可以用一个指针初始化另一个指针,例如:
int *ptri=pi;或者:
int *ptri;
ptri=pi;表示pi指向哪就让ptri也指向哪,本质上就是把变量pi所保存的地址值赋给变量ptri.用一个指针给另一个指针赋值时要注意,两个指针必须是同一类型的。在我们的例子中,pi是int*型的,pc是char*型的,pi=pc;这样赋值就是错误的。但是可以先强制类型转换然后赋值:
pi = (int *)pc;把char *指针的值赋给int *指针
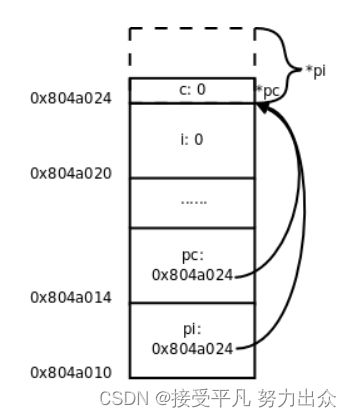
现在pi指向的地址和pc一样,但是通过*pc只能访问到一个字节,而通过*pi可以访问到4个字节,后3个字节已经不属于变量c了,除非你很确定变量c的一个字节和后面3个字节组合而成的int值是有意义的,否则就不应该给pi这么赋值。因此使用指针要特别小心,很容易将指针指向错误的地址,访问这样的地址可能导致段错误,可能读到无意义的值,也可能意外改写了某些数据,使得程序在随后的运行中出错。有一种情况需要特别注意,定义一个指针类型的局部变量而没有初始化:
int main(void)
{
int *p;
...
*p = 0;
...
}我们知道,在堆栈上分配的变量初始值是不确定的,也就是说指针p所指向的内存地址是不确定的,后面用*p访问不确定的地址就会导致不确定的后果,如果导致段错误还比较容易改正,如果意外改写了数据而导致随后的运行中出错,就很难找到错误原因了。像这种指向不确定地址的指针称为"野指针",为了避免野指针,在定义指针变量时就应该给它明确的初值,或者把它初始化位NULL:
int main(void)
{
int *p = NULL;
...
*p = 0;
...
}NULL在C标准库的头文件stddef.h中定义:
#define NULL ((void *)0)就是把地址0转换成指针类型,称为空指针,它的特殊之处在于,操作系统不会把任何数据保存在地址0及其附近,也不会把地址0-0xfff的页面映射到物理内存,所以任何对地址0的访问都会立刻导致段出错。*p=0;会导致段错误,就像放在眼前的炸弹一样很容易被找到,相比之下,野指针的错误就像埋下地雷一样,更难发现和排除,这次走过去没事,下次走过去就有十。
讲到这里就该讲一下void*类型了。在编程时经常需要一种通用指针,可以转换为任意其他类型的指针,任意其他类型的指针也可以转换为通用指针,最初C语言中没有void*类型,就把char*当通用指针,需要转换时就用类型转换运算符(),ANSI在将C语言标准化时引入了void*类型,void*指针与其他类型的指针之间可以隐式转换,而不必用类型转换运算符。注意,只能定义void*指针,而不能定义void型的变量,因为void*指针和别的指针一样都占4个字节,而如果定义void型变量,编译器不知道该分配几个字节给变量。同样道理,void*指针不能直接Dereference,而必须先转换成别的类型的指针再做Dereference.void*指针常用于函数接口。比如:
void func(void *pv)
{
/* *pv = 'A' is illegal */
char *pchar = pv;
*pchar = 'A';
}
int main(void)
{
char c;
func(&c);
printf("%c\n", c);
...下一章讲函数接口时再详细介绍void *指针的用处。
指针类型的参数和返回值
首先看以下程序:
指针参数和返回值
#include
int *swap(int *px, int *py)
{
int temp;
temp = *px;
*px = *py;
*py = temp;
return px;
}
int main(void)
{
int i = 10, j = 20;
int *p = swap(&i, &j);
printf("now i=%d j=%d *p=%d\n", i, j, *p);
return 0;
} 我们知道,调用函数的传参过程相当于用实参定义并初始化形参,swap(&i,&j)这个调用相当于:
int *px = &i;
int *py = &j;所以px和py分别指向main函数的局部变量i和j,在swap函数中读写*px和*py其实是读写main函数的i和j。尽管在swap函数的作用域中访问不到j和j这两个变量名,却可以通过地址访问它们,最终swap函数将i和j的值做了交换。
int *tmp = px;int *p=tmp;最后的结果是swap函数的px指向哪就让main函数的p指向哪。我们知道px指向i,所以p也指向i.
指针与数组
先看个例子,有如下语句:
int a[10];
int *pa = &a[0];
pa++;首先指针pa指向a[0]的地址,注意后缀运算符的优先级高于单目运算符,所以是取a[0]的地址,而不是取a的地址。然后pa++让pa指向下一个元素(也就是a[1]),由于pa是int *指针,一个int型元素占4个字节,所以pa++使pa所指向的地址加4,注意不是加1.
下面画图理解。从前面的例子我们发现,地址的具体数值其实无关紧要,关键是要说明地址之间的关系(a[1]位于a[0]之后4个字节处)以及指针与变量之间的关系(指针保存的是变量的地址),现在我们换一种画法,省略地址的具体数值,用方框表示存储空间,用箭头表示指针和变量之间的关系。
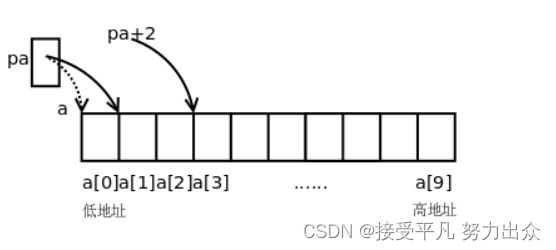
既然指针可以用++运算符,当然也可以用+,-运算符,pa+2这个表达式也是有意义的,如上图所示,pa指向a[1],那么pa+2指向a[3]。事实上,E1[E2]这种写法和(*((E1)+(E2)))是等价的,*(pa+2)也可以写成pa[2],pa就像数组名一样,其实数组名也没有什么特殊的,a[2]之所以能取数组的第2个元素,是因为它等价于*(a+2),在数组那里讲过数组名做右值时自动转换成指向首元素的指针,所以a[2]和pa[2]本质上是一样的,都是通过指针间接寻址访问元素。由于(*((E1)+(E2)))显然可以写成(*((E2)+(E1))),所以E1[E2]也可以写成E2[E1],这意味着2[a],2[pa]这种写法也是对的,但一般不这么写。另外,由于a做右值使用时和&a[0]是一个意思,所以int *pa=&a[0];通常不这么写,而是写成更简单的形式int *pa=a;。
在数组那里讲过C语言允许数组下标是负数,现在你该明白为什么这样规定了。在上面的例子中,表达式pa[-1]是合法的,它和a[0]表示同一个元素。
现在猜一下,两个指针变量做比较运算表示什么意义?两个指针变量做减法运算又有什么什么意义?
你理解了指针和常数的加减的概念,再根据以往使用比较运算的经验,就应该猜到pa+2>pa,pa-1==a,所以指针指针的比较运算比的是地址,C语言正是这样规定的,不过C语言的规定更为严谨,只有指向同一个数组中元素的指针之间相互比较才有意义,否则没有意义。那么两个指针相减表示什么?pa-a等于几?因为pa-1==a,所以pa-a显然等于1,指针相减表示两个指针之间相差的元素的个数,同样只有指向同一个数组中的元素的指针之间相减才有意义。两个指针相加表示什么?想不出来它能有什么意义,因此C语言也规定两个指针不能相加。
在取数组元素时用数组名和用指针的语法一样,但如果把数组名做左值使用,和指针又有区别。例如pa++合法,但a++就不合法,pa=a+1是合法的,但是a=pa+1是不合法的。数组名做右值时转换成指向首元素的指针,但做左值仍然表示整个数组的存储空间,而不是首元素的存储空间,数组名做左值时还有一点特殊之处,不支持++,赋值这些运算符,但支持取地址运算符&,所以&a是合法的。
在函数原型中,如果参数是数组,则等价于参数是指针的形式,例如:
void func(int a[10])
{
...
}等价于:
void func(int *a)
{
...
}第一种形式方括号中的数字可以不写,仍然是等价的:
void func(int a[])
{
...
}参数写成指针形式还是数组形式对编译器来说没区别,都表示这个参数是指针,之所以规定两种形式是为了给读代码的人提供有用的信息,如果这个参数指向一个元素,通常写成指针的形式,如果这个参数指向一串元素的首元素,则经常写成数组的形式。
指针与const限定符
const限定符和指针结合起来常见的情况有以下几种:
const int *a;
int const *a;这两种写法是一样的,a是一个指向const int型的指针,a所指向的内存单元不可改写,所以(*a)++是不允许的,但a可以改写,所以a++是允许的。
int * const a;a是一个指向int型的const指针,*a是可以改写的,但a不允许改写。
int const* const a;a是一个指向const int型的const指针,因此*a和a都不允许改写。
指向非const变量的指针或者非const变量的地址可以传给指向const变量的指针,编译器可以做隐式类型转换,例如:
char c = 'a';
const char *pc = &c;但是,指向const变量的指针或者const变量的地址不可以传给指向非const变量的指针,以免投过后者意外改写了前者所指向的内存单元,例如对下面的代码编译器会报警告:
const char c = 'a';
char *pc = &c;即使不用const限定符也能写出正确的程序,但良好的编程习惯应该尽可能多的使用const,因为:
1.const给读代码的人传达非常有用的信息。比如一个函数的参数是const char *,你在调用这个函数时就可以放心地传给它char *或const char *指针,而不必担心指针所指的内存单元被改写。
2.尽可能多地使用const限定符,把不该变的都声明成只读,这样可以依靠编译器检查程序中的Bug,防止意外改写数据。
3.const对编译器优化是一个有用的提示,编译器也许会把const变量优化成常量。
字符串字面值通常分配在.rodata段,字符串字面值类似于数组名,做右值使用时自动转换成指向首元素的指针,这种指针应该是const char *型。我们知道printf函数原型的第一个参数是const char *型,可以把char *或const char *指针传给它,所以下面这些调用都是合法的:
const char *p = "abcd";
const char str1[5] = "abcd";
char str2[5] = "abcd";
printf(p);
printf(str1);
printf(str2);
printf("abcd");注意上面第一行,如果要定义一个指针指向字符串字面值,这个指针应该是const char*型,如果写成char *p="abcd";就不好了,有隐患,例如:
int main(void)
{
char *p = "abcd";
...
*p = 'A';
...
}*p指向.rodata段,不允许改写,但编译器不会报错,在运行时会出现段错误。
指针与结构体
首先定义一个结构体类型,然后定义这种类型的变量和指针:
struct unit {
char c;
int num;
};
struct unit u;
struct unit *p = &u;要通过指针p访问结构体成员可以写成(*p).c和(*p).num,为了书写方便,C语言提供了->运算符,可以写成p->c和p->num。
指向指针的指针与指针数组
指针可以指向基础类型,也可以指向符合类型,因此也可以指向另外一个指针变量,称为指向指针的指针。
int i;
int *pi = &i;
int **ppi = π这样定义之后,表达式*ppi取pi的值,表达式**ppi取i的值。请读者自己画图理解i,pi,ppi这三个变量之间的关系。
很自然地,也可以定义指向"指向指针的指针"的指针,但是很少用到:
int ***p;数组中的每个元素可以是基本类型,也可以复合类型,因此也可以是指针类型。例如定义一个数组a由10个元素组成,每个元素都是int *指针:
int *a[10];这称为指针数组。int *a[10]和int **pa;之间的关系类似于int a[10]和int *pa之间的关系;a是由一种元素组成的数组,pa则是指向这种元素的指针。所以,如果pa指向a的首元素:
int *a[10];
int **pa = &a[0];则pa[0]和a[0]取的是同一个元素,唯一比原来复杂的地方在于这个元素是一个int *指针,而不是基本类型。
我们知道main函数的标准原型应该是int main(int argc,char *argv[]);argc是命令行参数的个数,而argv是一个指向指针的指针,为什么不是指针数组?因为前面讲过,函数原型中的[]表示指针而不表示数组,等价于char **argv.那为什么要写成char *argv[]而不写成char **argv?这样写给读代码的人提供了有用的信息,argv不是指向单个指针,而是指向一个指针数组的首元素。数组中每个元素都是char *指针,指向一个命令行参数字符串。
打印命令行参数
#include
int main(int argc, char *argv[])
{
int i;
for(i = 0; i < argc; i++)
printf("argv[%d]=%s\n", i, argv[i]);
return 0;
} 编译执行:
$ gcc main.c
$ ./a.out a b c
argv[0]=./a.out
argv[1]=a
argv[2]=b
argv[3]=c
$ ln -s a.out printargv
$ ./printargv d e
argv[0]=./printargv
argv[1]=d
argv[2]=e注意程序名也算一个命令行参数,所以执行./a.out a b c这个命令时,argc是4,argv如下图所示:
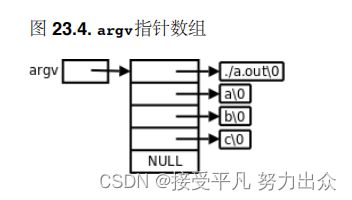
由于argv[4]是NULL,我们也可以这样循环遍历argv:
for(i=0; argv[i] != NULL; i++)NULL标识着argv的结尾,这个循环碰到NULL就结束,因而不会访问越界,这种用法很形象地称为Sentinel,NULL就像一个哨兵守卫着数组的边界。
在这个例子中我们还看到,如果给程序建立符号链接,然后通过符号链接运行这个程序,就可以得到不同的argv[0].通常,程序会根据不同的命令行参数做不同的事情,例如ls -l和ls -R打印不同的文件列表,而有些程序会根据不同的argv[0]做不同的事情,例如专门指针嵌入式系统的开源项目Busybox,将各种Linux命令裁剪后集于一身,编译成一个可执行文件busybox,安装时将busybox程序拷到嵌入式系统的/bin目录下,同时在/bin,/sbin,/usr/bin,/usr/sbin等目录下创建很多指向/bin/busybox的符号链接,命名为cp,ls,mv,ifconfig等等,不管执行哪个命令其实最终都是在执行/bin/busybox,它会根据argv[0]来区分不同的命令。
指向数组的指针与多维数组
指针可以指向复合类型,上一节讲了指向指针的指针,这一节学习指向数组的指针,以下定义一个指向数组的指针,该数组有10个int元素:
int (*a)[10];和上一节指针数组的定义int *a[10];相比,仅仅多了一个()括号,如何记住和区分这两种定义?我们可以认为[]比*有更高的优先级,如果a先和*结合则表示a是一个指针,如果a先和[]结合则表示a是一个数组。int *a[10];这个定义可以拆成两句:
typedef int *t;
t a[10];t代表int *类型,a则是由这种类型的元素组成的数组。int (*a)[10];这个定义也可以拆成两句:
typedef int t[10];
t *a;t代表由10个int组成的数组类型,a则是指向这种类型的指针。
现在看指向数组的指针如何使用:
int a[10];
int (*pa)[10] = &a;a是一个数组,在&a这个表达式中,数组名做左值,取整个数组的首地址赋给指针pa。注意,&a[0]表示数组a的首元素的首地址,而&a表示数组a的首地址,显然这两个地址的数值是相同的,但这两个表达式的类型是两种不同的指针类型,前者的类型是int *,而后者的类型是int(*)[10]。*pa就表示pa所指向的数组a,所以取数组的a[0]元素可以用表达式(*pa)[0]。注意到*pa可以写成pa[0],所以(*pa)[0]这个表达式也可以改写成pa[0][0],pa就像一个二维数组的名字,它表示什么含义?下面把pa和二维数组放在一起做个分析。
int a[5][10];和int(*pa)[10];之间的关系同样类似于int a[10];和int *pa;之间的关系:a是由一种元素组成的数组,pa则是指向这种元素的指针。所以,如果pa指向a的首元素:
int a[5][10];
int (*pa)[10] = &a[0];则pa[0]和a[0]取得是同一个元素,唯一比原来复杂的地方在于这个元素是由10个int组成的数组,而不是基本类型。这样我们可以把pa当成二维数组名来使用,pa[1][2]和a[1][2]取得也是同一个元素,而且pa比a用起来更灵活,数组名不支持赋值自增等运算,而指针可以支持,pa++使pa跳过二维数组的一行(40个字节),指向a[1]的首地址。
函数类型和函数指针类型
在C语言中,函数也是一种类型,可以定义指向函数的指针。我们知道,指针变量的内存单元存放一个地址值,而函数指针存放的就是函数的入口地址(位于.text段)。下面看一个简单的例子:
函数指针
#include
void say_hello(const char *str)
{
printf("Hello %s\n", str);
}
int main(void)
{
void (*f)(const char *) = say_hello;
f("Guys");
return 0;
} 分析一下变量f的类型声明void(*f)(const char *),f首先跟*号结合在一起,因此是一个指针。(*f)外面是一个函数原型的格式,参数是const char *,返回值是void,所以f是指向这种函数的指针。而say_hello的参数是const char *,返回值是void,正好是这种函数,因此f可以指向say_hello。注意,say_hello是一种函数类型,而函数类型和数组类型类似,做右值使用时自动转换成函数指针类型,所以可以直接赋给f,当然也可以写成void (*f)(const char *) =&say_hello;,把函数say_hello先取地址再赋给f,就不需要自动类型转换了。
可以直接通过函数指针调用函数,如上面的f("Guys"),也可以先用*f取出它所指的函数类型,再调用函数,即(*f)("Guys")。可以这么理解:函数调用运算符()要求操作数是函数指针,所以f("Guys")是最直接的写法,而say_hello("Guys")或(*f)("Guys")则是把函数类型自动转换成函数指针然后做函数调用。
下面再举几个例子区分函数类型和函数指针类型。首先定义函数类型F:
typedef int F(void);这种类型的函数不带参数,返回值是int。那么可以这样声明f和g:
F f, g;相当于声明:
int f(void);
int g(void);下面这个函数声明是错误的:
F h(void);因为函数可以返回void类型、标量类型、结构体、联合体,但不能返回函数类型,也不能返回数组
F *e(void);F *((e))(void);int (*fp)(void);F *fp;double real_part(struct complex_struct z)
{
if (z.t == RECTANGULAR)
return z.a;
else
return z.a * cos(z.b);
}double rect_real_part(struct complex_struct z)
{
return z.a;
}
double rect_img_part(struct complex_struct z)
{
return z.b;
}
double rect_magnitude(struct complex_struct z)
{
return sqrt(z.a * z.a + z.b * z.b);
}
double rect_angle(struct complex_struct z)
{
double PI = acos(-1.0);
if (z.a > 0)
return atan(z.b / z.a);
else
return atan(z.b / z.a) + PI;
}
double pol_real_part(struct complex_struct z)
{
return z.a * cos(z.b);
}
double pol_img_part(struct complex_struct z)
{
return z.a * sin(z.b);
}
double pol_magnitude(struct complex_struct z)
{
return z.a;
}
double pol_angle(struct complex_struct z)
{
return z.b;
}
double (*real_part_tbl[])(struct complex_struct) = { rect_real_part,
pol_real_part };
double (*img_part_tbl[])(struct complex_struct) = { rect_img_part,
pol_img_part };
double (*magnitude_tbl[])(struct complex_struct) = { rect_magnitude,
pol_magnitude };
double (*angle_tbl[])(struct complex_struct) = { rect_angle,
pol_angle };
#define real_part(z) real_part_tbl[z.t](z)
#define img_part(z) img_part_tbl[z.t](z)
#define magnitude(z) magnitude_tbl[z.t](z)
#define angle(z) angle_tbl[z.t](z)不完全类型和复杂声明

C语言的类型分为函数类型、对象类型和不完全类型三大类。对象类型又分为标量类型和非标量类 型。指针类型属于标量类型,因此也可以做逻辑与、或、非运算的操作数和if、for、while的控制表达式,NULL指针表示假,非NULL指针表示真。不完全类型是暂时没有完全定义好的类型,编译器 不知道这种类型该占几个字节的存储空间,例如:
struct s;
union u;
char str[];char str[];
char str[10];struct s {
struct t *pt;
};
struct t {
struct s *ps;
};struct s {
struct t ot;
};
struct t {
struct s os;
};struct s {
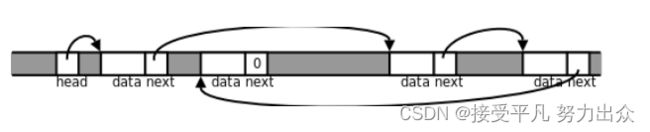
char data[6];
struct s* next;
};
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);void (*signal(int signum, void (*handler)(int)))(int);-
T *p; , p 是指向 T 类型的指针。
-
T a[]; , a 是由 T 类型的元素组成的数组,但有一个例外,如果 a 是函数的形参,则相当于 T*a;T1 f(T2, T3...); , f 是一个函数,参数类型是 T2 、 T3 等等,返回值类型是 T1 。
我们分解一下这个复杂声明:
int (*(*fp)(void *))[10];1.fp和*号括在一起,说明fp是一个指针,指向T1类型:
typedef int (*T1(void *))[10];
T1 *fp;2.T1应该是一个函数类型,参数是void *,返回值是T2类型:
typedef int (*T2)[10];
typedef T2 T1(void *);
T1 *fp;3.T2和*号括在一起,应该也是个指针,指向T3类型:
typedef int T3[10];
typedef T3 *T2;
typedef T2 T1(void *);
T1 *fp;