三、人工神经网络基础
人工神经网络基础
参考:https://blog.csdn.net/weixin_39653948/article/details/105090584
1.人工神经网络(ANN)及人工智能(AI)
- 智能(Intelligence) 是个体有目的的行为,合理的思维以及有效的适应环境的综合能力。或者说智能是个体认识客观事物和运用知识解决问题的能力。
- 人工智能(Artificial Intelligence,AI) 最初在1956年被引入,它主要研究怎样让计算机模仿人脑从事准理、设计、思考、学习等思维活动,以解决和处理较复杂的问题。简单的讲,人工智能就是研究如何让计算机模仿人脑进行工作。
- 人工神经网络(Artificial Neural Network,ANN) 是一种旨在模仿人脑结构及其功能的脑式智能信息处理系统。通常以数学和物理的方法以及信息处理的角度对人脑神经网络进行抽象,并建立某种简化模型。简单的讲,它是一种数学模型,可以用电子线路来实现,也可以通过计算枧程序来模拟,是人工智能的一种研究方法。
1.1 智能(Intelligence)
**【智能(Intelligence)】**是个体有目的的行为,合理的思维以及有效的适应环境的综合能力。或者说智能是个体认识客观事物和运用知识解决问题的能力。
通常认为智能包含以下方面的能力:
- 感知与认识客观事物、客观世界和自我的能力:人类生存最基本的能力,感知是智能的基础;
- 通过学习取得知识与积累经验的能力:人类能够持续发展的最基本的能力;
理解知识,运用知识经验去分析、解决问题的能力:智能的高级形式,人类改造世界的基本能力; - 联想、推理、判断和决策的能力:智能的高级形式,人类对未来和未知的预测、应对能力;
- 运用语言进行抽象、概括的能力:是形式化描述的基础;
- “发现、发明、创造和创新的能力:是第三种能力的高级体现;
- 实时、迅速、合理地应付复杂环境的能力:实时反映能力,也是人类生存的基本能力;
- 预测、洞察事物发展、变化的能力:根据历史信息和经验,判断事物未来的发展。
1.2 人工智能(Artificial Intelligence)
【人工智能(Artificial Intelligence,AI)】 最初在1956年被引入,它主要研究怎样让计算机模仿人脑从事准理、设计、思考、学习等思维活动,以解决和处理较复杂的问题。简单的讲,人工智能就是研究如何让计算机模仿人脑进行工作。
由于研究的出发点、方法学以及应用领域的不同,有多个代表性的流派:
- 符号主义学派:Newell和Simon在1967年提出的假说,认为人工智能源于数学逻辑,通过数学逻辑来描述智能行为,后来发展了启发式算法 --> 专家系统 --> 知识工程的理论。
- 联接主义学派:代表人物为McCulloch和Pitts,认为人工智能源于仿生学,特别是人脑的研究,并提出了MP模型,后来基于该模型衍生出人工神经网络等
- 行为主义学派:认为人工智能源于控制论,Wiener等提出的控制论和自组织系统等,立足于模拟人在控制过程中的智能行为和作用,如自组织、自寻优、自适应、自学习等。
1.3 ANN的发展历史
萌芽期(?-1949)
- 1943年,心理学家McCulloch和数学家Pitts根据神经元提出M-P模型,打下坚实基础;
- 1949年,心理学家Hebb提出了人工神经网络的学习规则,称为模型的训练算法的起点。
第一高潮期(1950-1968)
- 单层感知器:研究者通过电子线路或者计算机去实现单层感知器,包括Minsky、Rosenblatt等,被用于各种问题求解,甚至某个阶段内被乐观的认为找到了智能的根源。
反思期(1969-1981)
- 1969年,Minsky和Papert发表论文《Perceptron》,从理论上严格证明了单层感知器无法解决异或问题从而引申到无法解决线性不可分的问题,由于大部分问题都是线性不可分的,所以单层感知器的能力有限,人们对ANN的研究进入反思期。
- 也取得到了一些积极成果,如Arbib的竟争模型、Kohonen的自组织映射、Grossberg的自适应共振模型(ART)、RumeIIhart等人并行分布处理模型(PDP)等。
第二高潮期(1982-90年代).
- 1982年Hopfield提出循环网络,1984年研制了HopfiIed网络,解决了TSP问题;
- 1985年,美国加州大学圣地亚哥分校的Hinton、Rumellhart等提出了Boltzmann机;
- 1986年RumeIIhart等人提出了用于多层网络训练的BP算法对ANN起到了重大的推动作用;
- 1987年,第一届神经网络国际会议在加州,1600+人参加,1990年12月,国内第一届在北京举行。
新时期(90年代至今)
- 神经网络已经成为涉及神经生理科学、认知科学、数理科学、心理学、信息科学、计算机科学、微电子学、光学、生物电子学等多学科交叉、综合的前沿学科;
- 神经网络的应用已经渗透到模式识别、图像处理、非线性优化、语音处理、自然语言理解、自动目标识别、机器人、专家系统等领域,并取得了令人瞩目的成果;
- 各种会议、论坛、刊物、活动等越来越多;
- 除了神经研究本身的突破和进展之外,相关的领域也都取得了长足的发展。
1、ANN与大数据
2、ANN的基本特征
- 结构特点
- 信息处理的并行性:单个单元处理简单,可以大规模并行处理,有较快的涑度;
- 信息存储的分布性:信息不是存储在网络中的局部,而是分布在网络所有的连接权中;
- 信息处理单元的互联性:处理单元之间互联,呈现出丰富的功能;
- 结构的可塑性:连接方式多样,结构可塑。
- 性能特点
- 高度的非线性:多个单元链接,体现出非线性;
- 良好的容错性:分布式存储的结构特点使容错性好;
- 计算的非精确性:当输入模糊信息时,通过处理连续的模拟信号及不精确的信息逼近解而非精确解。
- 能力特征
- 自学习、自组织与自适应性:根据外部环境变化通过训练或感知,能调节参数适应变化(自学习),并可按输入刺激调整构建神经网络(自组织)。
3、ANN的基本功能
2. 神经元模型
2.1 神经元结构
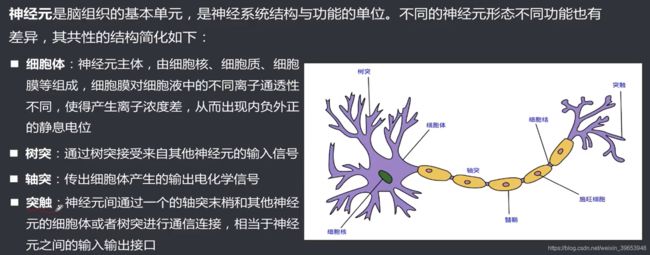
2.2 生物神经元模型
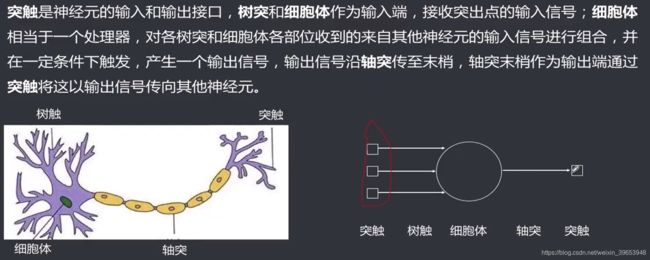
2.3 信息处理机制
生物神经元的信息的产生、传递和处理是一种电化学活动,其机制为:
- 信息产生:在某一给定时刻,神经元总是处于静息、兴奋和抑制三种状态之一。在外界的刺激下,当神经元的兴奋程度大于某个阈电位时,神经元被激发而发出神经脉冲。
- 传递与接收:神经脉冲信号沿轴突传向其末端的各个分支,通过突触完成传递与接收。突触有兴奋性突触和抑制性性突触两种,当兴奋性突触的电位超过某个阈电位时,后一个神经元就有神经脉冲输出,从而把前一个神经元的信息传递给了后一个神经元。
- **信息整合:**接收各个轴突传来的脉冲输入,根据输入可到达神经元的不同部位,输入部位不同,对神经元影响的权重也不同。在同一时刻产生的刺激所引起的电位变化大致等于各单独刺激引起的电位变化的代数和。神经元对空间和时间上对输入进行积累和整合加工,从而决定输出的时机和强弱。
- **生物神经网络:**由多个生物神经元以确定方式和拓扑结构互相连接即形成生物神经网络,是一种更为灵巧、复杂的生物信息处理系统,在宏观上呈现出复杂的信息处理能力。
2.4 M-P模型

神经元特点:
- 多个输入单个输出
- 多输入累加整合
- 不同输入仅重不同
- 阈值特性
M-P模型:是把神经元视为二值开关元件,按照不同方式组合来完成各种逻辑运算。能够构成逻辑与、非、或,理论上可以进而组成任意复杂的逻辑关系,若将M-P模型按一定方式组织起来,可以构成具有逻辑功能的神经网络。


2.5 激活函数
**激活函数 (Activation Function):**也叫连接函数、传递函数、变换函数或者激励函数。**用来模拟神经元输出与具激活状态之间的联系:输入达到某个阈值后达到激活状态,否则为抑制态。**不同的激活函数,会使神经元具有不同的信息处理特性。对于神经网络来讲,激活函数的主要作用就是进行线性变换,增加系统的非线性表达能力。常见的激活函数有:

3. 神经网络模型
3.1 神经网络模型分类
3.1.1 按照拓扑结构划分
可分为层次结构和互连结构。
- 层次结构:
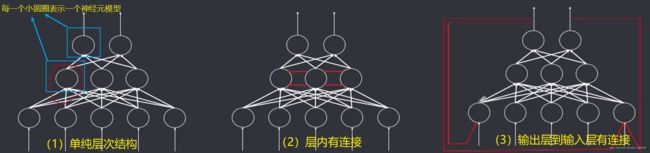
- 互连结构
-
全互连:每个节点都和其他所有节点连接
-
局部互连:每个节点只与其临近节点有连接
-
稀疏连接:节点只与少数相距较远的节点有连接

3.1.2 按照信息流向划分
可分为前馈性网络和反馈性网络
-
前馈型网络:网络信息从输入层到各隐藏层再到输出层逐层前进。
-
反馈型网络:反馈网络中所有节点都具有信息处理功能,并且每个节点既可以接收输入同时又可以进行输出。

3.2 前馈神经网络
**前馈神经网络(Feed Forward NN)**是一种最简单的神经网络,采用单向多层结构,各神经元分层排列,每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层,各层间没有反馈。
前馈网络包括三类节点:
- 输入节点(lnput Nodes):外界信息输入,不进行任何计算,仅向下一层节点传递信息;
- 隐藏节点(Hidden Nodes):接收上一层节点的输入,进行计算,并将信息传到下一层节点;
- 输出节点(OutputNodes):接收上一层节点的输入,进行计算,并将结果输出;
输入层和输出层必须有,隐藏层可以没有,即为单层感知器,隐藏层也可以不止一层,有隐藏层的前馈网络即多层感知器。

3.3 反馈神经网络
反馈神经网络(Feed Back NN):又称递归网络、回归网络,是一种将输出经过一步时移再接入到输入层的神经网络系统。这类网络中,神经元可以互连,有些神经元的输出会被反馈至同层甚至前层的神经元。常见的有HopfieId神经网络、Elman神经网络、Boltzmann机等。
3.4 前馈神经网络和反馈神经网络的主要区别
- 前馈神经网络各层神经元之间无连接,神经元只接受上层传来的数据,处理后传入下一层,数据正向流动;反馈神经网络层间神经元有连接,数据可以在同层间流动或反馈至前层。
- 前馈神经网络不考虑输出与输入在时间上的滞后效应,只表达输出与输入的映射关系;反馈神经网络考虑输出与输入之间在时间上的延迟,需要用动态方程来描述系统的模型。
- 前馈神经网络的学习主要采用误差修正法(如BP算法),计算过程一般比较慢,收敛速度也比较慢;反馈神经网络主要采用Hebb学习规则,一般情况下计算的收敛速度很快。
- 相比前馈神经网络,反馈神经网络更适合应用在联想记忆和优化计算等领域。
3.5 前馈与反馈

4.神经元网络学习规则
4.1 基本概念
学习:通过训练使个体在行为上产生较为持久改变的过程,一般来说效果随着训练了的增加而提高,即通过学习获得进步。
人工神经网络的功能由其连接的拓扑结构和网络的连接仅值决定,其全体的权值w整体反映了神经网络对于所解决问题的知识存储。即一旦拓扑结构和权值确定,该网络可以应用于新的数据得到结果。
人工神经网络的学习:通过对样本的学习训练,不断改变网络的拓扑结构及连接权值,使得输出不断的接近期望输出值。
通过训练改变权值的规则被称为学习算法或者学习规则,有时也称作训练规则或者训练算法,学习规则对人工神经网络非常重要。
4.2 学习规则类型
按照一般的分类标准,通常分为三类:
- 有监督学习:学习模式为纠错
不断的给网络提供一个输入即其期望的正确输出(称教师信号),将ANN的实际输出和期望输出作比较,不符时,按照一定规则调整权值参数,重新计算、比较,直到网络对于给定的输入均能产生期望的输出。则认为该网络训练完成,即已学会样本数据中的知识和规则。即可用于解决实际问题。 - 无监督学习:学习模式为自组织
学习时不断给网络提供动态输入信息,网络根据特有的内部结构和学习规则,在输入信息流中发现可能的模式和规律,同时根据网络功能和输入信息调整仅值(自组织)。使网络能对属于同一类的模式进行自动分类。该模式网络权值的调整不取决于教师信号,网络的学习评价标准隐含于网络内部。
4.3 赫布法则
4.3.1 由来
赫布法则(Heb’s rule):在《The Organization of Behavior》书中解释了学习过程中大脑中的神经细胞是如何改变和调整的,认为知识和学习发生在大脑主要是通过神经元间突触的形成与变化。当细胞A的轴突足以接近激发细胞B,并反复持续地对细胞B放电,一些生长过程或代谢变化将发生在某一个或这两个细胞内,以致A作为对B放电的细胞中的一个效率增加。通俗来讲就是两个神经细胞交流越多,它们连接的效率就越高,反之就越低。
McCulloch-Pitts模型缺乏一个对人工智能而言至关重要的学习机制,M-P模型很好的简化、模拟了神经元,但是无法通过学习的方式调整、优化权重,形成有效的模型。赫布法则的出现,成为神经模型训练(学习机制)的基础性工作。
巴浦洛夫的条件反射实验:每次给狗喂食前都先响铃,时间一长,狗就会将铃声和食物朕系起来。以后如果铃响但是不给食物,狗也会流口水。
受此实验启发,Hebb的理论认为在同一时间被激发的神经元间的朕系会被强化。例如,铃声响时一个神经元被激发,在同一时间食物的出现会激发附近的另一个神经元,那么这两个神经元间的联系会被强化,从而记住这两个事物之间存在着联系。相反,如果两个神经元总是不能同步激发,那么它们之间的朕系将会越来越弱。
赫布规则被作为无监督神经网络的学习规则,广泛应用于自组织神经网络、竞争网络中。
4.3.2 赫布学习规则

赫布学习规则的步骤:
- 初始化权值参数 W WW,一般赋于 0 附近的随机数;
- 初始化学习率 η;
- 对所有输入记录:根据输入记录,更新权重值;
4.3.3 赫布学习规则实例
带入第一个样本更新权重:

带入第二个样本更新权重:

带入第三个样本更新权重:

4.4 离散感知器学习规则
**感知器(Perceptron)**是由Rosenblatt定义的具有单层神经计算单元的神经网络结构。实际上为一种前馈网络,同层内无互连,不同层间无反馈,由下层向上层传递,其输入、输出均为离散值,神经元对输入加权求和后,由阈值函数(激活函数)决定其输出。
离散感知器学习规则代表一种有导师的学习方式,其规定将神经元期望输出(教师信号)与实际输出之差作为学习信号,通过训练调整权值,直到实际输出满足要求(等于或者接近于期望输出)。
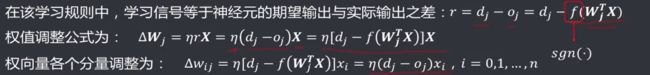
离散感知器学习规则的步骤:
- 初始化权值参数,学习速率;
- 对每一个样本,实际输出和期望输出的差满足要求:根据输入记录,更新权重值;
4.4.1 实例




验证:

4.5 连续感知器学习规则
DeIta习规则(δ LearningRule):1986年,由认知心理学家McCIeIIand和RumeIIhart在神经网络训练中引入了学习规则。一种简单的有导师学习算法,该算法根据神经元的实际输出与期望输出差别来调整连接权。
Delta学习规则的思路如下:系统首先用一个输入向量,输入网络结构,得到一个输出向量;每个输入向量都有一个对应的期望输出向量、或者称作是目标向量;比较实际输出向量与期望输出向量的差别,若没有差别,就不再继续学习;否则,连接的权重修改对应的差值(delta差)。
4.5.1 损失函数
损失函数(Loss Function):用于衡量最优的策略,通常是一个非负实值函数。机器学习试图通过不断的学习,建立一个可以很好预测现实结果的模型,损失函数则是用来衡量预测结果和真实结果之间的差距,其值越小,代表预测结果和真实结果越一致。损失函数越合适,通常模型的性能越好。通过各种方式缩小损失函数的过程被称作优化·损失函数记做 L(Y,f(x))。
0-1损失函数(0-1 LF):预测值和实际值精确相等则“没有损失”,为0,否则意味着“完全损失”,为1,预测值和实际值精确相等有些过于严格,可以采用两者的差小于某个阈值的方式:

绝对值损失函数(AbsoIuteLF):预测结果与真实结果差的绝对值。简单易懂,但是计算不方便。
L ( Y , f ( x ) ) = ∣ Y − f ( X ) ∣ L(Y,f(x))=∣Y−f(X)∣ L(Y,f(x))=∣Y−f(X)∣
平方损失函数(Quadratic LF):预测结果与真实结果差的平方。
L ( Y , f ( x ) ) = ( Y − f ( X ) ) 2 L(Y,f(x))=(Y−f(X)) ^2 L(Y,f(x))=(Y−f(X))2
平方损失函数优势有:
- 每个样本的误差都是正的,累加不会被抵消;
- 平方对于大误差的惩罚大于小误差;
- 数学计算简单、友好,导数为一次函数。

对数损失函数(Logarithmic LF) 或对数似然损失函数(log-likehood loss function)对数函数具有单调性,在求最优化问题时,结果与原始目标一致。可将乘法转化为加法,简化计算。
L ( Y , P ( Y ∣ X ) ) = − l o g P ( Y ∣ X ) L(Y,P(Y∣X))=−logP(Y∣X) L(Y,P(Y∣X))=−logP(Y∣X)
指数损失函数(ExponentiaI LF) 或对数似然损失函数(likehood loss function):单调性、非负性的优良性质,使得越接近正确结果误差越小。
L ( Y , f ( x ) ) = e − Y ∗ f ( X ) L(Y,f(x))=e^{−Y*f(X)} L(Y,f(x))=e−Y∗f(X)
折叶掼失函数(HingeLF):也称铰链损失,对于判定边界附近的点的惩罚力度较高,常见于SVM。
L ( f ( x ) ) = m a x ( 0 , 1 − f ( x ) ) L(f(x))=max(0,1−f(x)) L(f(x))=max(0,1−f(x))
不同的损失函数有不同的持点,适用于不同的场景:
- 0-1:理想状况模型
- Log:逻辑回归、交叉熵
- Squared:线性回归
- Exponential:AdaBoosting
- Hinge:SVM、soft margin
4.5.2 损失函数优化:梯度下降法

4.5.3 δ规则

4.5.4 最小均方学习规则
4.5.5 相关学习规则

4.5.6 竞争学习&胜者为王
竞争学习(Competition Learning) 是人工神经网络的一种学习方式,指网络单元群体中所有单元相互竟争对外界刺激模式响应的权利。竟争取胜的单元的连接权重向着对这一刺激有利的方向变化,相对来说竟争取胜的单元抑制了竟争失败单元对刺激模式的响应。属于自适应学习,使网络单元具有选择接受外界刺激模式的特性。竟争学习的更一般形式是不仅允许单个胜者出现,而是允许多个胜者出现,学习发生在胜者集合中各单元的连接权重上。
胜者为王学习规则(Winner-Take-All)。无导师学习,将网络的某一层设置为竞争层,对于输入 X XX 竞争层的所有 p pp 个神经元均有输出响应,响应值最大的神经元在竟争中获胜,即:
W m T X = m a x i = 1 , 2 , . . . p ( W i T X ) W^T_mX = max_{i=1,2,...p}(W^T_iX) WmTX=maxi=1,2,...p(WiTX)
获胜的神经元才有权调整其权向量Wm,调整量为:
δ W m = a ( X − W m ) , α ∈ ( 0 , 1 ] δW_m=a(X−W_m),α∈(0,1] δWm=a(X−Wm),α∈(0,1]
随着学习而减小。
在竞争学习过程中,竞争层的各神经元所对应的权向量逐渐调整为输入样本空间的聚类中心。
在实际应用中通常会定义以获胜神经元为中心的邻域,所在邻域内的所有神经元都进行权重调整。





4.5.7 外形学习规则
内星节点:总是接收其他神经元输入的加权信号,是信号的汇聚点,其对应的权值向量称作内星权向量。
外星节点:总是向其他神经元输出加权信号,是信号的发散点,其对应的权值向量称作外星权向量。

两者的更新规则:
- 内星属于无导师学习,外星属于有导师学习;
- 内星更新依赖于输入和权重的差异,外星更新依赖于输出和权重的差异。
5.BP神经网络

6.卷积神经网络

6.1卷积层

- 类似边缘滤波,区别是卷积算子是由通过反向传播算法计算的中间的值
- 一个卷积算子是一个神经元,即w1、w2、w3…
- 卷积算子可以有多层,卷积结果层数与卷积算子层数相同

- 卷积步长stride:当stride=1时每次往后移动一格,stride=2时结果如图
- padding: padding=1时代表在外面加一层

-
卷积后尺寸大小满足下面公式:
( n + 2 p − f ) / s + 1 (n+2p-f)/s+1 (n+2p−f)/s+1
n:图片大小p:padding大小
f:卷积算子大小
s:步长Stride
-
RGB3维图像卷积或更高维度矩阵卷积
m×n×3的矩阵,Stride=2,卷积结果是2×2×1的矩阵

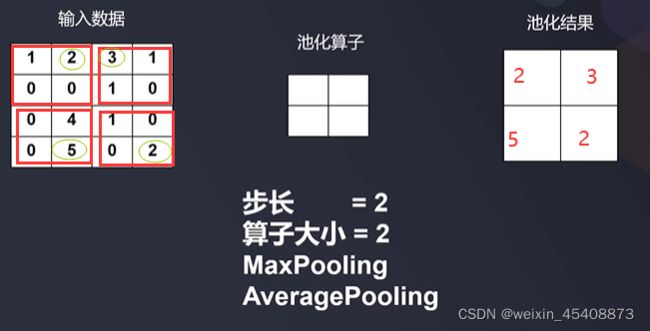
6.2池化层
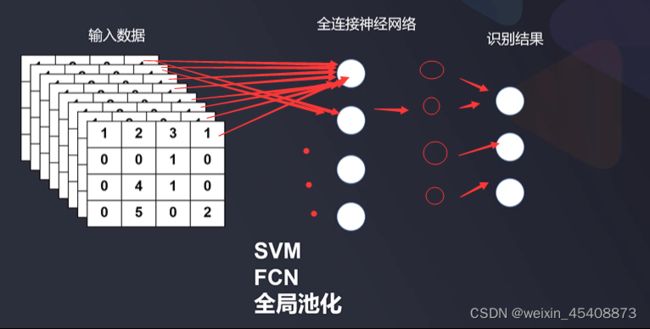
6.3全连接层
放在卷积神经的最后一个部分,用于输出和分析识别结果
相当于多层感知器,每个数据都输入到每个全连接神经网络中
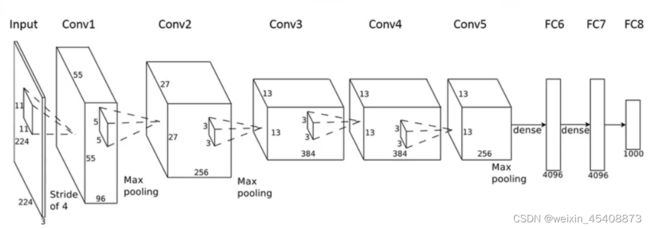
7.经典卷积神经网络结构
ALEXNET

梯度消失和梯度爆炸问题
- 随着隐藏层数量越来越多,分类准确率反而下降了,例如:210=1024(梯度爆炸),0.510=0.00097(梯度消失)
- 使用函数不当也可能梯度消失,例如Tanh函数随着x->+∞梯度趋于0,此时梯度消失
- 初始权重太大可能导致梯度爆炸,w>1时经过多层叠加就越来越大

ResNet
- 发明了快速连接,解决了梯度消失问题。即传入下一层的数据中叠加了原始数据。

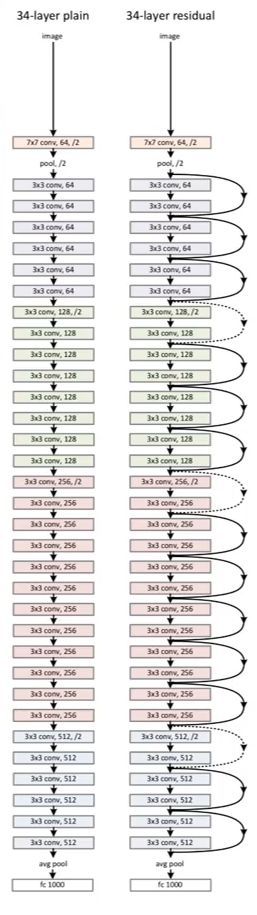
Inception
Inception是GoogleNet中的模块,它的目的是设计一种具有优良局部拓扑结构的网络,即对输入图像并行地执行多个卷积运算或池化操作,并将所有结果拼接为一个非常深地特征图。因为1×1、3×3、5×5 ,等不同卷积地运算与池化操作可以获得输入图像的不同信息,并行处理这些运算并结合所有结果将获得更好的图像表征。
