浏览器执行原理、V8引擎
前言
对一个前端而言,思考JS在浏览器中如何被执行非常重要。笔者是通过codewhy的课程进行学习的,首先感谢codewhy。
浏览器的功能
浏览器的主要功能就是向服务器发出请求,在浏览器窗口中展示您选择的网络资源。这里所说的资源一般是指 HTML 文档,也可以是图片或其他的类型。资源的位置由用户使用 URI(统一资源标示符)指定。浏览器解释并显示 HTML ,文件的方式是在 HTML 和 CSS 规范中指的。这些规范由网络标准化组织 W3C(万维网联盟)进行维护。多年以来,各浏览器都没有完全遵从这些规范,同时还在开发自己独有的扩展程序,这给网络开发人员带来了严重的兼容性问题。如今,大多数的浏览器都是或多或少地遵从规范。
来自https://zhuanlan.zhihu.com/p/99777087?utm_source=wechat_session
浏览器执行的过程
输入URL
当我们从网页中输入某一个URL的时候比如www .xxx.com,它会被DNS协议解析成一个具体的ip地址。(找到服务器的地址),此时服务器会给我们返回一个Index.html的网页。
我们看到的也就是那个index.html网页。
随后浏览器便会帮我们来解析这个网页。
解析网页
当浏览器解析网页时,遇到link标签里的css文件它就会向服务器请求并下载css文件。同理,遇到script标签页它也会从服务器里下载js文件。
这样当前浏览器就把js代码下载下来了。这就有一个问题了?谁来帮我们解析js代码呢?怎么执行呢?
了解浏览器内核
其实解析是依靠浏览器内核来完成的。经过浏览器内核就会变成我们用户能看到的网页了。基本上不同的浏览器是由不同内核来组成的,内核也是浏览器的重要组成部分。
常见的浏览器内核:
- Trident:IE的内核,也就是国内双核浏览器的内核之一,此内核只能用于Windows平台,且不是开源的。Trident内核一直延续到IE11,IE11的后继者Edge采用了新内核,已经转向Blink了。(早期比如世界之窗什么)
- Gecko:Gecko是Netscape6开始采用的内核,后来的Mozilla FireFox (火狐浏览器) 也采用了该内核,Gecko的特点是代码完全公开,因此,其可开发程度很高,全世界的程序员都可以为其编写代码,增加功能。
- Webkit:开源内核,苹果基于KHTML开发的内核。它最早被运用在Safari上(苹果的浏览器),曾经的Chrome用的也是Webkeit。
- Presto:Opera Software开发的浏览器排版引擎,它是世界公认最快的渲染速度的引擎,Opera7.0开始使用。13年2月后为了减少研发成本,Opera放弃Presto宣布加入谷歌阵营,采用chromium,之后也紧跟Blink的脚步。
- Blink:王炸!它是webkit的一个分支,是由Google和Opera Software开发的浏览器排版引擎(基于webkit开发的),2013年4月发布。现在Chrome内核是Blink。目前运用在chrome、edge、opera等浏览器上。
浏览器内核也被叫做:Layout engine(排版引擎) 等等,社区里有很多叫法。
浏览器渲染的过程

浏览器将css和js文件下载下来以后,就要进行如上图的操作了。
- HTML:(一般情况下为index.html)浏览器内核里有个东西叫做HTML Parser,它先将HTML转换为一个DOM树,在这个过程当中如果有编写JS代码,例如
document.createELementById('xxxx')
它也可以对DOM树进行操作。不过作为一门高级语言,CPU是识别不了JS代码的,所以JS代码会由JS引擎来负责解释.(后文我们会聊到这个js引擎)
- CSS:CSS代码会被浏览器内核里面的CSS Parser转换为一个样式规则(Style Rules)
HTML与CSS相结合,会形成一个RenderTree(渲染树),有了渲染树以后,再将渲染树交给Layout(布局引擎),将页面做布局自适应化。形成最终的RenderTree.
完成上述操作,经过浏览器绘制并展示,用户就能浏览页面,并做相关操作了。
这里有个问题?大量的js代码也需要被执行,那它由谁来执行呢?
Javascript引擎
认识JS引擎
实际上我们编写的JS代码,无论我们把它交给浏览器还是Node,最后其实都是cpu来执行的。
可是CPU是无法直接识别高级语言的。在计算机里所有的高级语言都需要转换为机器语言(二进制那种01010101的代码)才能被CPU识别。JS引擎就是帮助我们将JS代码翻译成CPU所能认识的机器语言的。
常见的JS引擎
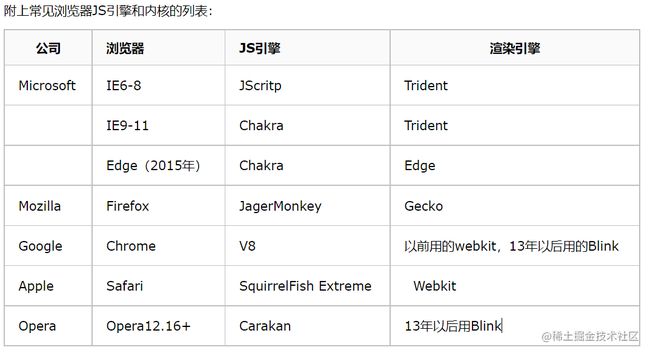
(来自https://www.cnblogs.com/guanguan-/p/9771515.html)
浏览器内核与JS引擎的关系
浏览器的内核是指支持浏览器运行的最核心的程序,分为两个部分的,一是渲染引擎,另一个是JS引擎。渲染引擎在不同的浏览器中也不是都相同的。
- 渲染引擎:他负责解析HTML,布局,渲染等工作……
- JS引擎:解析并且执行JS代码
V8引擎
上面的JS引擎很多,我们重点关注V8这个引擎。它是由谷歌开发的。
V8引擎V8使用C++开发,并在谷歌浏览器中使用。在运行JavaScript之前,相比其它的JavaScript的引擎转换成字节码或解释执行,V8将其编译成原生机器码(IA-32, x86-64, ARM, or MIPS CPUs),并且使用了如内联缓存(inline caching)等方法来提高性能。有了这些功能,JavaScript程序在V8引擎下的运行速度媲美二进制程序。(来自百度百科)
V8可以独立运行,也可以嵌入到任何C++ 应用程序当中。
很有意思,V8这个引擎的名字其实是来自于超跑品牌保时捷。给它命名为V8足以见得谷歌公司对这个引擎多么自信!而V8也确实是现在最快的浏览器引擎,很多人选择chrome浏览器也是这个原因。
V8引擎的底层原理图:

- 第一步,JS代码会经过parse功能模块。(解析,解析其实包括词法分析和语法分析)分析完了,会将其生成为AST抽象语法树。这里给大家提供了一个AST语法树转换网站 ,AST语法树在babel里也有被使用,学过vue的小伙伴应该很亲切。通过AST我们可以将ES6代码转换为ES5代码,也可以转换为字节码(通过ignition功能模块)
为什么一定要转换为字节码而不是机器指令?那是因为不同CPU架构,机器指令是不同的,而字节码是跨平台的,它就方便多了。
- 为了更加的优化,我们可以转换一些用的比较多的函数为字节码,也是上面图片的一个模块功能TurboFan,热函数功能。他可以将一些用的比较多的函数标记为热函数。方便提高效率。
但是我们可以看下面的代码
function sum(n1,n2){
n1 + n2
}
sum(20,30) //1
sum('aaa','bbb') //2
由于js是个动态语言,没有做类型限制,我们本想做一个数值的相加(并将其标记为热函数),可是阴差阳错,做成了字符串的拼接)(代码中标记为2处)。那咋解决呢?这个热函数是不是就不能用了呢?当然不是!引擎V8有个Deoptimization功能,它可以再将这种特殊情况转换为字节码。(其实就是处理一个特殊情况)。
由此我们可以推出,若使用Typescript开发,运行效率就会提高不少。
V8引擎是采用C++代码开发的,用了超过100W行的C++代码。
官方V8引擎的解析图

过程跟我们上述的流程基本上差不多。
要了解的是,内核(blink)会将我们的js代码以流的方式传递给V8引擎。然后将代码的编码传入Scanner转换器、后续操作跟上文描述的基本上差不多。
我们要注意到这个Preparser(预解析)
为什么我们需要预解析?举个栗子
function eat(){
function eatFood(){
.... //代码片段
}
}
eat()
我们看上面的函数,其实完全没有必要对eatFood那个方法进行解析。因为我们没有调用过它。如果每次都要对它转换成AST,bytecode真的很浪费性能!
所以V8会采用一个Preparser(预解析)功能,以此来提高性能。(引擎只需要知道有这个函数就行了,不需要阅读它里面具体的代码片段)
这有点类似于C语言里面的函数声明。他有个专有名词叫做Lazy Parsing(延迟解析)方案
这些是一些理论的部分,后续我也会结合代码,介绍具体一个代码的运行过程。
通过代码来描述
我们不采用ES6语法,使用var来定义变量。
var name = "name"
var num1 = 20
var num2 = 30
var result = num1 + num2
这段代码在V8引擎中运行的时候到底发生了什么样的过程?
-
代码被解析时(从JS代码到AST抽象语法树的过程),V8引擎会帮我们创建一个对象名为GlobalObject。它会包含我们很多的全局对象,比如一些包装类(Math,String,Date…),setTimeout;window属性。要注意解析的时候,V8也会将上述代码的变量(name,num1,num2),写进这个GlobalObject,值为undefined 4.
-
运行代码!为了运行代码,V8内部有一个执行上下文栈(Excution context Stack)。并且为了执行全局代码,V8还要创建全局执行上下文(Global context Stack)将它放入执行上下文栈中。
全局执行上下文中维护了一个东西名为VO,它维护了全局对象GO(GlobalObject),所有要准备的东西都准备好了,就可以开始执行代码了。

var name = "why"
var num1 = 20
console.log(num2); //A处,这个代码的值是undefined
var num2 = 30
var result = num1 + num2
这里我们在A处打印num2,会发现结果为undefined(不是null,不会说找不到)。这很好理解,因为在GO中num2这个变量已经给它赋值成了undefined。
这就是我们经常说的作用域提升(将变量放到GO里面),当我们没给GO里的变量赋值的时候打印,它的结果是undefined。
转自本人掘金