DeepSpeed官方教程(huggingface DeepSpeed文档翻译)
- DeepSpeed github地址、DeepSpeed 官网 、DeepSpeed API文档、
- huggingface DeepSpeed文档、知乎deepspeed入门教程、微软deepspeed博客
- 示例代码:《Using DeepSpeed with HF Trainer》、 BLOOM_LORA(运行示例见《Running_Deepspeed》)、 DeepSpeedExamples
文章目录
-
- 一、DeepSpeed简介和安装
-
- 1.1 `ZREO`简介
- 1.2 `DeepSpeed`简介
- 1.3 `DeepSpeed`安装
- 二、使用DeepSpeed启动训练
-
- 2.1 命令行参数配置
- 2.2 多GPU部署
- 2.3 josn配置文件
- 2.4 单GPU部署
- 2.5 多节点部署
- 2.6 不使用json配置文件
- 三、使用transformers启动训练
-
- 3.1 单节点部署
- 3.2 多节点部署
- 四、在Jupyter Notebook中使用DeepSpeed
- 五、配置
-
- 5.1 共享配置(重要)
- 5.2 ZeRO stage 0 、ZeRO stage 1
- 5.3 ZeRO stage 2
- 5.4 ZeRO stage 3
-
- 5.3.1 stage 3基本配置:
- 5.3.2 NVMe Support
- 5.3.3 stage 3 CPU offload完整配置
- 六、如何选择最佳配置
-
- 6.1 如何选择不同的Zero stage和offload策略
- 6.2 优化器
- 6.3 调度器
- 6.4 训练精度
-
- 6.4.1 fp32和fp16
- 6.4.2 fp16
- 6.4.3 bp16
- 6.4.4 NCCL Collectives
- 6.5 `zero.Init()`
- 七、Model Weights
-
- 7.1 保存模型参数及恢复训练
- 7.2 HF预训练模型启用deepspseed方法
- 八、推理
- 九、内存估算
- 十、故障排除
- 十一、Non-Trainer Deepspeed(有空再补)
- 十二、示例代码
一、DeepSpeed简介和安装
1.1 ZREO简介
ZeRO论文:《ZeRO:Memory Optimizations Toward Training Trillion Parameter Models》ZeRO-Offload论文:《ZeRO-Offload:Democratizing Billion-Scale Model Training.》NVMe技术论文:《 ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning》
ZeRO(Zero Redundancy Optimizer)是一种用于优化大规模深度学习模型训练的技术。它的主要目标是降低训练期间的内存占用、通信开销和计算负载,从而使用户能够训练更大的模型并更高效地利用硬件资源。
ZERO论文首先分析了模型训练中内存主要消耗在两个方面:
model states:模型状态,包括包括优化器参数(例如Adam的动量和方差)、梯度、模型参数residual states:剩余状态,包括包括激活函数、临时缓冲区、内存碎片

参数解释:
Baseline:未优化的基线Ψ:模型大小,上图假设模型参数为Ψ=75亿K:存储优化器状态要消耗的内存倍数,上一节讲过,对于混合精度的Adam优化器而言,K=12- N d N_d Nd:数据并行度。基于Adam优化器的混合精度训练,数据并行度为Nd=64(即64个GPU)
ZERO分别使用ZeRO-DP和ZeRO-R来优化model states和residual states。如上图所示,ZeRO-DP包括三个阶段:
-
优化器状态分割( P o s P_{os} Pos):
在每个gpu中保存全部的参数和梯度,但是只保存1/Nd的优化器状态变量。通过将优化器状态进行分割,实现4倍的内存减少,同时保持与DP相同的通信量。 -
梯度分割( P o s + g P_{os+g} Pos+g):
每个gpu中只保存1/Nd的梯度,实现8倍的内存减少,并保持与DP相同的通信量。 -
参数分割( P o s + g + p P_{os+g+p} Pos+g+p):
每个gpu中只保存1/Nd的参数 ,实现64倍的内存减少,通信量会略微增加50%。作者通过用少量的计算的成本和通信成本换来了大幅的内存节省。
ZeRO-Infinity是ZeRO的一个扩展版本,它允许将模型参数存储在CPU内存或NVMe存储上,而不是全部存储在GPU内存中,最终在有限资源下能够训练前所未有规模的模型(在单个NVIDIA DGX-2节点上微调具有1万亿参数的模型),而无需对模型代码进行重构。与此同时,它实现了出色的训练吞吐量和可扩展性,不受有限的CPU或NVMe带宽的限制。
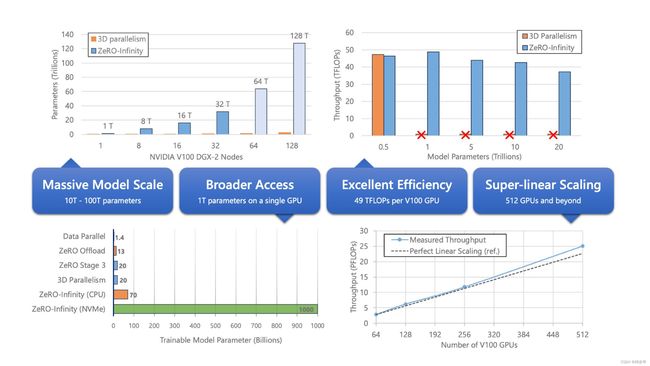
更多详情请参考我的另一篇笔记《大模型分布式训练策略:ZeRO、FSDP》。
1.2 DeepSpeed简介
2020年3月Microsoft Research首次开源了DeepSpeed ,是一个用于训练大规模深度学习模型的优化工具和,它实现了 ZeRO 论文中描述的所有内容,可以提高训练速度和内存效率,并降低资源需求。目前它提供以下支持:
- Optimizer state partitioning (ZeRO stage 1):优化器状态分区
- Gradient partitioning (ZeRO stage 2):梯度划分。
DeepSpeed ZeRO-2主要仅用于训练,因为其功能对推理没有用处。 - Parameter partitioning (ZeRO stage 3):参数划分。
DeepSpeed ZeRO-3也可用于推理,因为它允许在多个 GPU 上加载大型模型,而这在单个 GPU 上是不可能的。 - Custom mixed precision training handling:混合精确训练
- A range of fast CUDA-extension-based optimizers:一系列基于 CUDA 扩展的快速优化器
- ZeRO-Offload to CPU and NVMe:数据卸载到 CPU 和 NVMe。
DeepSpeed有两种启动方式:
-
使用PyTorch启动器:保持PyTorch的训练流程,只在其中使用DeepSpeed的一些配置文件和设置来改进训练速度和内存效率。好处是更容易集成到现有的PyTorch代码中,因为它不需要你改变整个训练流程。
torch.distributed.run --nproc_per_node=2 your_program.py <normal cl args> --deepspeed ds_config.json -
使用DeepSpeed提供的启动器:DeepSpeed提供了自己的启动器,它是一个独立的命令行工具,用于配置和启动DeepSpeed训练。这种方式适用于需要更高度自定义控制的情况,可以轻松在不同环境中部署。
deepspeed --num_gpus=2 your_program.py <normal cl args> --deepspeed ds_config.json
上述命令中,各个字段的含义如下:
-
deepspeed: DeepSpeed启动器(launcher) -
--num_gpus=2(可选): 指定要使用的GPU数量,如果要启用所有的GPU,可以省略此参数。 -
your_program.py: 用户的训练脚本。在训练脚本中使用DeepSpeed提供的优化器、分布式训练支持和其他功能来优化您的训练任务。(DeepSpeed通常被集成到用户的自定义脚本中,以提供更高效的训练和更好的硬件资源利用率,所以DeepSpeed库本身没有训练代码。) -
-
--deepspeed ds_config.json: 使用DeepSpeed的配置文件ds_config.json来配置训练过程。
1.3 DeepSpeed安装
DeepSpeed有两种安装方式:pip安装和本地构建。
- pip安装
# 两种方式任选其一
pip install deepspeed # 安装deepspeed库
pip install transformers[deepspeed] # 通过transformers的extras选项安装
- 本地构建
pip安装通常会使用默认配置,适合绝大多数用户。如果您需要自定义DeepSpeed的配置,比如修改全局配置文件或在代码中进行相应的配置更改,可以克隆DeepSpeed项目到本地来自定义构建。
git clone https://github.com/microsoft/DeepSpeed/
cd DeepSpeed
rm -rf build # 移除旧的构建目录
# 针对所需GPU架构进行本地构建:(需替换相应GPU架构)
TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 pip install . \
--global-option="build_ext" --global-option="-j8" --no-cache -v \
--disable-pip-version-check 2>&1 | tee build.log
有关这部分详细内容,请查看官方文档。
二、使用DeepSpeed启动训练
DeepSpeed开源项目、DeepSpeed 官网
2.1 命令行参数配置
命令行参数是一些经常需要更改的、运行时可灵活配置的参数。你可以通过DeepSpeed的add_config_arguments来添加这些参数,以便在命令行调用。例如:
import deepspeed
import argparse
# 创建命令行参数解析器
parser = argparse.ArgumentParser(description="GPT-2 Training Script")
# 使用DeepSpeed的add_config_arguments添加DeepSpeed配置参数
deepspeed.add_config_arguments(parser)
# 添加其他训练参数
parser.add_argument("--model_name_or_path", type=str, default="gpt2", help="Model name or path")
parser.add_argument("--per_device_train_batch_size", type=int, default=4, help="Batch size per device")
args = parser.parse_args()
# 使用DeepSpeed配置参数初始化DeepSpeed引擎
model, optimizer, _, _ = deepspeed.initialize(model=your_gpt2_model,
optimizer=your_optimizer,
model_parameters=your_model_parameters,
training_data=your_data_loader,
config_params=args)
在上面的示例中,您可以在命令行中指定DeepSpeed的配置参数:
deepspeed train_gpt2.py --deepspeed ds_config_stage3.json --model_name_or_path gpt2-medium --per_device_train_batch_size 2
2.2 多GPU部署
以下是用 DeepSpeed 运行 run_translation.py 并使用所有 GPU 进行部署的示例,在run_translation.py 中我们配置了更多的命令行参数:
# 运行DeepSpeed示例脚本
deepspeed examples/pytorch/translation/run_translation.py \
--do_train \
--deepspeed tests/deepspeed/ds_config_zero3.json \
--model_name_or_path t5-small \
--per_device_train_batch_size 1 \
--output_dir output_dir \
--overwrite_output_dir \
--fp16 \
--max_train_samples 500 \
--num_train_epochs 1 \
--dataset_name wmt16 \
--dataset_config "ro-en" \
--source_lang en \
--target_lang ro
- overwrite_output_dir:如果存在目标文件,则覆盖
- fp16:开启混合精度训练
- dataset_name、dataset_config:数据集名称和配置
- source_lang、target_lang:源语言、目标语言
有关配置参数的完整文档,请参考API doc。
2.3 josn配置文件
上述代码中的ds_config_zero3.json就是DeepSpeed的配置文件,通常用于设置较为复杂的优化策略,例如ZeRO的阶段配置、分层参数分组等,一般不会经常修改。比如你要进行DeepSpeed ZeRO Stage 3的训练,其训练优化配置就可以写在一个json文件中,例如:
{
"optimizer": {
"type": "Adam",
"params": {
"lr": 3e-4
}
},
"fp16": {
"enabled": true
},
"zero_optimization": {
"allgather_partitions": true,
"allgather_partitions_freq": 1,
"allgather_partitions_size": 5e8,
"reduce_scatter": true,
"reduce_scatter_reduce": "mean",
"reduce_scatter_enablewa": true,
"reduce_scatter_num_buckets": 3,
"reduce_scatter_bucket_size": 5e8,
"reduce_scatter_allgather": true,
"reduce_scatter_allgather_size": 5e8,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
}
}
}
然后,你可以使用deepspeed来应用这些配置并启动训练:
# 使用deepspeed启动训练
ds_config_file = "ds_config_zero3.json"
# 使用DeepSpeed配置文件初始化DeepSpeed引擎
model, optimizer, _, _ = deepspeed.initialize(model=your_gpt2_model,
optimizer=your_optimizer,
model_parameters=your_model_parameters,
training_data=your_data_loader,
config_path=ds_config_file)
也可以使用Trainer来启动,只需要在TrainingArguments中传递deepspeed参数:
TrainingArguments(..., deepspeed="/path/to/ds_config.json")
一般情况下,命令行参数和配置文件只启用一个,以避免冲突。当需要自定义DeepSpeed的设置时,可以选择先加载配置文件,然后根据需要使用 config_params 来覆盖特定的设置。有关此部分内容以及各阶段的json配置文件,详见本文第五章节。
2.4 单GPU部署
如果是使用一个 GPU 部署 DeepSpeed,只需要设置 --num_gpus=1,明确告诉 DeepSpeed 仅使用一个 GPU。
deepspeed --num_gpus=1 examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero2.json \
......
如果要在GPU0之外的特定GPU上运行,可以运行以下代码:
# 使用GPU 1(第二个 GPU)进行训练
deepspeed --include localhost:1 examples/pytorch/translation/run_translation.py \
...
为什么一个GPU也可以使用DeepSpeed?
-
ZeRO-offload特性: DeepSpeed具备ZeRO-offload功能,它可以将一些计算和内存操作卸载到主机的CPU和NVMe内存,从而为节省更多的GPU资源。然后你就可以使用更大的batch_ size来训练模型,或者训练更大规模的模型。
-
智能GPU内存管理: DeepSpeed提供了智能的GPU内存管理系统,可最大限度地减少内存碎片,从而再次允许您适应更大的模型和batch_ size。
因此,即使只有一块GPU,使用DeepSpeed仍然有效。另外要实现上面所说的功能,在定义配置文件中,至少需要包含以下内容:
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"overlap_comm": true,
"contiguous_gradients": true
}
}
具体参数含义请参考本文5.3章节。
2.5 多节点部署
假设有 2 个节点,每个节点有 8 个 GPU,你可以分别使用 ssh hostname1 和 ssh hostname2 来访问这两个节点,且两者都必须能够通过本地 ssh 相互访问而无需密码。
hostname1和hostname2是你的主机名
要使用 deepspeed 启动器,必须首先创建一个 hostfile 文件:
hostname1 slots=8
hostname2 slots=8
然后执行以下代码:
deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 --master_port=9901 \
your_program.py <normal cl args> --deepspeed ds_config.json
deepspeed 将在两个节点上自动启动此命令!
在
hostfile中列出了两个不同的主机名,每个主机上都有指定数量的GPU槽位。DeepSpeed会自动启动并协调这两个节点上的训练任务,实现分布式训练。
2.6 不使用json配置文件
然而,如果你不想使用命令行界面来配置训练,那么可以直接实例化Trainer对象,然后不再使用json文件传递DeepSpeed的配置信息,而是使用一个嵌套的字典(dict)来将其传递给TrainingArguments。例如:
ds_config_dict = dict(scheduler=scheduler_params, optimizer=optimizer_params)
TrainingArguments(..., deepspeed=ds_config_dict)
这样做的好处是不需要创建一个独立的JSON配置文件,而是在代码中动态创建DeepSpeed配置。
三、使用transformers启动训练
3.1 单节点部署
huggingface DeepSpeed文档、知乎deepspeed入门教程
huggingface的transformers库已经集成了DeepSpeed功能,你可以使用两种方式来调用:
-
Trainer调用:transformers的Trainer类已经集成了DeepSpeed,您可以直接传递DeepSpeed配置参数来启用DeepSpeed功能,而无需太多自定义配置。 -
自定义集成DeepSpeed:如果你想要更大的自由度和自定义控制流程,也可以不使用Trainer,而是手动集成DeepSpeed。对此,Transformers库仍然提供了一些功能,如
from_pretrained和from_config,你只需要按照相关文档进行配置。
具体来说,transformers集成了DeepSpeed ZeRO training和DeepSpeed ZeRO Inference:
DeepSpeed ZeRO training:通过 ZeRO-Infinity(CPU 和 NVME 卸载)支持完整的 ZeRO stages 1, 2 and 3 。DeepSpeed ZeRO Inference:与训练不同,推断时只需要做前向传播,所以不需要优化器、lr调度器和梯度。DeepSpeed ZeRO Inference只使用ZeRO stage 3(参数划分),专注于模型的前向传播,这使得推断更轻量且更快速。
使用Trainer部署DeepSpeed训练示例:
# 在training_args中添加DeepSpeed配置文件
training_args = TrainingArguments(
output_dir="./bert_model",
overwrite_output_dir=True,
num_train_epochs=2,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
save_steps=1000,
logging_steps=500,
save_total_limit=2,
learning_rate=0.00005,
lr_scheduler_type="cosine",
deepspeed="ds_config.json", # DeepSpeed配置文件
)
# 使用Trainer集成DeepSpeed
trainer = Trainer(
model=model,
args=training_args,
data_collator=None, # 可以根据需要自定义数据收集器
train_dataset=train_dataset,
eval_dataset=val_dataset,
tokenizer=tokenizer,
deepspeed="ds_config.json", # DeepSpeed配置文件
)
# 训练模型
trainer.train()
# 保存最终模型
trainer.save_model()
# 使用Trainer进行推理
results = trainer.predict(test_dataset)
你也可以参照上一节DeepSpeed启动训练一样,在命令行中启动训练。只需要给Trainer命令行参数中配置 --deepspeed ds_config.json参数,其它DeepSpeed训练参数依旧可以使用add_config_arguments 添加。
3.2 多节点部署
要使用 torch.distributed.run ,您可以执行以下操作:
python -m torch.distributed.run --nproc_per_node=8 --nnode=2 --node_rank=0 --master_addr=hostname1 \
--master_port=9901 your_program.py <normal cl args> --deepspeed ds_config.json
python -m torch.distributed.run:分布式训练的Python命令,可以在多个节点上并行运行Python脚本。- –
node_rank=0:指定当前节点的排名,这个节点的排名为0。 - –
master_addr=hostname1:指定主节点的地址,即执行此命令的节点的主机名或IP地址。 - –
master_port=9901:指定主节点的端口号,用于协调分布式训练。
你需通过SSH登录到每个节点并运行该命令,torch.distributed.run会等待直到两个节点都启动并同步后才开始执行训练任务,以确保协调整个分布式训练过程。
在多节点环境中,默认情况下,DeepSpeed假定所有节点都可以访问共享存储,这意味着它们可以在不同节点之间共享model checkpoint和其他训练数据。然而,有些情况下,每个计算节点只能访问本地文件系统,而不能共享存储。这时候需要在配置文件中添加以下部分,告诉DeepSpeed在多节点环境中只使用本地节点来保存checkpoint和其他相关数据:
{
"checkpoint": {
"use_node_local_storage": true
}
}
如果你希望更简便一些,你也可以使用Trainer的--save_on_each_node参数,这会自动为你添加上述的配置,达到同样的效果。
四、在Jupyter Notebook中使用DeepSpeed
通常,在Notebook中运行单元格(cell)作为脚本时,没有像DeepSpeed的标准启动器(launcher)可供使用,因此需要在Notebook中模拟一个启动器。
- 单GPU情况
如果你只有一个GPU,你需要在Notebook中设置一些环境变量,模拟分布式环境,并将DeepSpeed的配置文件传递给训练参数。例如:
# 即使只使用一个GPU,DeepSpeed也需要分布式环境。下面代码在notebook中模拟了启动器
import os
# 设置环境变量,模拟分布式环境
os.environ["MASTER_ADDR"] = "localhost" # 主节点地址(本地主机)
os.environ["MASTER_PORT"] = "9994" # 主节点端口号(如果出现地址已被占用的错误,请进行修改)
os.environ["RANK"] = "0" # 当前节点的排名,这里设置为0
os.environ["LOCAL_RANK"] = "0" # 当前节点的本地排名,同样设置为0
os.environ["WORLD_SIZE"] = "1" # 总共的节点数,这里设置为1,表示只有一个节点
# 设置训练参数,包括DeepSpeed的配置文件
training_args = TrainingArguments(
..., # 普通训练参数
deepspeed="ds_config_zero3.json" # DeepSpeed的配置文件路径
)
# 创建训练器对象,开始训练
trainer = Trainer(...)
trainer.train()
-
多GPU情况
在多GPU情况下,通常需要使用专门的启动器来管理多个进程,以便DeepSpeed能够正常工作,而不能只是用os模拟分布式环境。 -
在notebook中动态创建配置文件
配置文件一般是json格式,需要打开才可以修改。在notebook中,你可以使用以下代码在cell中写入配置文件,这样方便修改:
%%bash
cat <<'EOT' > ds_config_zero3.json
... # 具体的配置文件内容,以字典格式
EOT
- 在文件中运行DeepSpeed
上面都是在notebook的cell中直接运行训练代码。如果训练代码保存在py文件中,可以通过Notebook中的Shell命令来运行:
!git clone https://github.com/huggingface/transformers
!cd transformers; deepspeed examples/pytorch/translation/run_translation.py ...
或者是使用%%bash 魔法命令来运行:
%%bash
git clone https://github.com/huggingface/transformers
cd transformers
deepspeed examples/pytorch/translation/run_translation.py ...
在Jupyter Notebook中使用
%%bash魔法命令时,命令的输出通常会被缓冲,即输出结果不会立即显示而是在命令执行完毕之后才会显示出来。
五、配置
- 官方配置文档DeepSpeed Configuration JSON、配置样例DeepSpeedExamples
- 卸载优化器状态和参数的详细文档请参考optimizer states 和parameters.
零冗余优化器 (ZeRO) 是 DeepSpeed库的主要功能,它支持 3 个不同阶段的优化。通常情况下,不同阶段的配置信息被保存在一个JSON文件中,并通过命令行接口传递给训练脚本,例如:
TrainingArguments(..., deepspeed="/path/to/ds_config.json")
你可以在 DeepSpeedExamples 存储库中找到数十个可满足各种实际需求的 DeepSpeed 配置示例:
git clone https://github.com/microsoft/DeepSpeedExamples
cd DeepSpeedExamples
find . -name '*json'
例如你要配置 Lamb 优化器,可以使用以下命令来搜索:
grep -i Lamb $(find . -name '*json')
5.1 共享配置(重要)
在使用Trainer和DeepSpeed进行深度学习训练时,有一些注意事项:
-
共享配置值: 有些配置值在Trainer和DeepSpeed中都需要,为了避免配置值的冲突,从而导致难以检测的错误,应该通过Trainer的命令行参数来配置这些共享的值,确保二者的配置值一致。
-
自动配置值: 有些配置值可以根据模型的配置自动计算,而无需手动设置(例如
scheduler.params.total_num_steps),这种自动配置值就是"auto"。当设为"auto"时,Trainer会将其自动替换为正确或最有效的值,这能减少手动配置的复杂性和错误的可能性。手动设置配置值,需要非常小心,以确保Trainer的参数和DeepSpeed的配置是一致的(比如学习率、批次大小、梯度累积等),否则训练可能会以难以检测的方式失败。
-
DeepSpeed-only : 有一些配置值只在DeepSpeed中使用的,它们需要手动设置,例如
zero_optimization。 -
自定义配置流程: 如果你想自己创建一个主配置(master configuration)来修改DeepSpeed的配置,你可以这样做:
- 首先,创建或加载用作主配置的DeepSpeed配置
- 然后基于这些值创建TrainingArguments对象。
-
zero_optimization:配置文件的 zero_optimization 部分是最重要的,它定义了要启用ZeRO的哪些阶段,以及如何配置它们。所以这部分内容是
DeepSpeed-only,你无法通过Trainer来设置。
目前 DeepSpeed 不验证参数名称,因此如果您拼写错误,它将使用拼写错误的参数的默认设置。在 DeepSpeed 引擎启动日志消息中会打印出具体的内。
ZeRO stage 1优化不大,因此下面重点介绍stage 2和stage3,以及融合了 ZeRO-Infinity 的stage3。
5.2 ZeRO stage 0 、ZeRO stage 1
- stage 0会禁用所有的分片,即把DeepSpeed当作时Pytorch DDP来使用。
{
"zero_optimization": {
"stage": 0
}
}
- stage 1仅对优化器状态进行分片,可以尝试它来稍微加快速度:
{
"zero_optimization": {
"stage": 1
}
}
5.3 ZeRO stage 2
stage 2基本配置:
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu", // 将优化器操作卸载到CPU上执行,以减少GPU内存使用。如果不想启用CPU卸载,设为none
"pin_memory": true // 确保在GPU和CPU之间高效传输数据
},
"allgather_partitions": true, // 启用 allgather 操作,用于收集梯度分区的信息
"allgather_bucket_size": 5e8, // 设置 allgather 操作的桶大小,以控制通信内存占用
"overlap_comm": true, // 启用通信重叠,通过增加内存使用降低通信延迟
"reduce_scatter": true, // 启用 reduce_scatter 操作,用于梯度分散
"reduce_bucket_size": 5e8, // 设置 reduce_scatter 操作的桶大小,以控制通信内存占用
"contiguous_gradients": true // 确保梯度数据在内存中是连续的,以优化性能
}
}
参数解析:
-
offload_optimizer:用于将一部分计算任务从GPU转移到CPU,从而减少GPU内存的使用。启用此选项需要stage 2; -
pin_memory:从CPU到GPU的数据传输速度相对较慢。启用此功能后,将尝试锁定数据在CPU内存中,以提高数据传输效率 -
overlap_comm:减少通信延迟,消耗更多内存。
启用此选项时会使用4.5倍的allgather_bucket_size和reduce_bucket_size值,即增这两个阶段中梯度桶的大小。梯度被分片的次数减少,梯度通信次数减少,所以通信延迟降低了。然而,这也会占用更多的GPU内存,因此需要权衡内存使用和通信速度。比如:- 显存大小:如果如果显存是
8G,而这两个梯度桶都设置为5e8,那么需要9GB的GPU内存空间来执行这个操作(5e8 x 2字节 x 2 x 4.5),这会导致OOM(显存溢出)。将其减少至2e8,则占用的显存是3.6G。 - batch size:如果训练中某些参数对你很重要,比如你需要更大的batch size,那么也可以设置较小的梯度桶,已分配给其它任务更多的显存,即使这会导致训练时间变慢。
- 显存大小:如果如果显存是
在数据并行中,训练数据被分成多个批次,并分配给不同的设备。每个设备上的模型副本独立处理自己的数据批次,并计算梯度(因为是在本设备上计算,所以叫本地梯度)。然后,通过
All-Reduce(全体度求和),这些梯度被聚合到一个global gradients中,然后用于更新模型参数。这种通信和梯度聚合的方式确保了所有设备上的模型保持同步。
all-reduce包含两个操作,reduce-scatter和all-gather,都是在各设备之间进行梯度分桶、广播和聚合操作。之所以要分桶,是因为在大规模训练中,GPU的数量可能非常大,一次性将不同GPU的本地梯度广播给所有GPU可能导致大量的数据流通信,也会占用大量的GPU内存。通过分桶操作,每次只传递local gradients的部分数据,可以减轻网络负载和内存压力,这样训练可以扩展到更多的GPU或更大的模型规模。
round_robin_gradients: 优化CPU offload性能。通过细粒度的梯度划分将梯度复制到CPU内存中,以实现CPU和GPU之间的并行处理。CPU offload性能随着梯度累积步骤和CPU数量的增加而增加。
下面是一个更完整的配置文件,包括优化器状态卸载到CPU、使用 AdamW 优化器和 WarmupLR 调度器,并使用--fp16来启动混合精度训练:
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
-
gradient_accumulation_steps:梯度累积 -
train_micro_batch_size_per_gpu:单个GPU上每次处理的micro_batch_size大小 -
train_batch_size:全局batch size,它等于train_micro_batch_size_per_gpu*gradient_accumulation_steps*GPUs number。也就是你可以只设置train_micro_batch_size_per_gpu,它会根据GPU数量和梯度累积值,自动算出全局batch size。 -
wall_clock_breakdown:默认关闭。开启时,DeepSpeed会详细记录以下每个训练步的时间:Step Time Breakdown: fp: 0.096s bp: 1.065s comm: 0.000s misc: 0.001s Total Time: 1.162s其中,各字段含义如下:
- fp: 前向传播时间
- bp: 反向传播时间
- optimizer: 优化器更新时间
- fp_comm: 前向传播的通信时间
- bp_comm: 反向传播的通信时间
- misc: 其他杂项时间
5.4 ZeRO stage 3
5.3.1 stage 3基本配置:
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu", // 将优化器状态卸载到CPU内存中
"pin_memory": true // 启用钉住内存,以提高数据传输效率
},
"offload_param": {
"device": "cpu", // 将模型参数卸载到CPU内存中
"pin_memory": true // 启用钉住内存,以提高数据传输效率
},
"overlap_comm": true, // 启用通信重叠,以减少通信延迟
"contiguous_gradients": true, // 确保梯度数据在内存中是连续的
"sub_group_size": 1e9, // 控制参数更新的粒度,防止内存不足
"reduce_bucket_size": "auto", // 自动设置 reduce_bucket_size
"stage3_prefetch_bucket_size": "auto", // 自动设置 stage3_prefetch_bucket_size
"stage3_param_persistence_threshold": "auto", // 自动设置 stage3_param_persistence_threshold
"stage3_max_live_parameters": 1e9, // GPU上保留的参数数量上限
"stage3_max_reuse_distance": 1e9, // 参数重用的距离阈值
"stage3_gather_16bit_weights_on_model_save": true // 在模型保存时启用16位权重的收集
}
}
以下是对上述JSON配置中各个参数的具体含义的解释:
-
"sub_group_size":控制参数更新的粒度,防止由于内存不足而导致训练中断。 -
"stage3_max_live_parameters":GPU上保留的参数数量的上限。如果超过这个数量,一些参数可能会被卸载到CPU内存中。 -
"stage3_max_reuse_distance":参数重用的距离阈值。如果一个参数在不久的将来要再次使用(小于 stage3_max_reuse_distance),可以将其保留以减少通信开销。 使用activation checkpointing时,这一点非常有用。如果遇到OOM,可以减少
stage3_max_live_parameters和stage3_max_reuse_distance,除非正在使用activation checkpointing。这两个值设为1e9时,二者一共消耗2GB内存。 -
"stage3_gather_16bit_weights_on_model_save":允许在模型保存时以16位精度收集并保存权重,以减少内存占用和加速训练,特别适用于大型模型和多GPU训练的情况,但可能会导致一定的精度损失。 -
sub_group_size:控制在optimizer steps中更新参数的粒度。
参数被分组到 sub_group_size 的桶中,每个桶一次更新一个。 当与 ZeRO-Infinity 中的 NVMe offload一起使用时,sub_group_size 控制模型状态在optimizer steps期间从 NVMe 移入和移出 CPU 内存的粒度, 防止超大模型耗尽 CPU 内存。
不使用NVMe offload时,使其保持默认值。出现OOM时,减小sub_group_size。当优化器迭代很慢时,可以增大sub_group_size 。
5.3.2 NVMe Support
deepspeed支持ZeRO-Infinity技术,该技术通过利用NVMe存储器来扩展GPU和CPU的内存,即使用NVMe存储器来存储模型的参数和优化器状态,以减轻内存压力,从可以处理更大的模型和数据集。以下是使用NVMe卸载优化器状态和参数的stage 3 配置:
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "nvme",
"nvme_path": "/local_nvme",
"pin_memory": true,
"buffer_count": 4,
"fast_init": false
},
"offload_param": {
"device": "nvme",
"nvme_path": "/local_nvme",
"pin_memory": true,
"buffer_count": 5,
"buffer_size": 1e8,
"max_in_cpu": 1e9
},
"aio": {
"block_size": 262144,
"queue_depth": 32,
"thread_count": 1,
"single_submit": false,
"overlap_events": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
}
上述配置中,你需要确保nvme_path填入的确实是NVMe存储器,如果使用普通的硬盘或SSD将会导致速度大幅降低(ZeRO-Infinity`技术考虑了现代NVMe的传输速度,可以达到约3.5GB/s的读取速度和3GB/s的写入速度)。
5.3.3 stage 3 CPU offload完整配置
如果你拥有大量的CPU内存可用,你可以选择只将它们卸载到CPU内存,因为这可能会更快。以下是stage 3完整配置:
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
卸载优化器状态和参数的详细文档请参考optimizer states 和parameters.
正如之前所讲的,stage3相比stage2,加入了参数分区,通信成本增加,所以训练会更慢。如果使用stage2已经是有足够的内存进行训练,那么不需要使用stage3。或者是在stage3配置中关闭 offload_params ,性能也可能会显着提高。
六、如何选择最佳配置
deepspeed优化器文档、调度器文档
6.1 如何选择不同的Zero stage和offload策略
下面是不同的训练策略,从左到右训练速度越来越慢,而GPU显存占用越来越低:
Stage 0 (DDP) , Stage 1 , Stage 2 , Stage 2 + offload , Stage 3 , Stage 3 + offloads
要确认如何选择Zero stage和offload策略,可以尝试以下步骤:
根据上述内容,以下是选择训练阶段的具体步骤:
-
设置初始条件:
- 首先将
batch_size设为1。 - 启用梯度累积,可以实现任意的有效batch_size。
- 首先将
-
首先尝试stage 2:
- 如果OOM则启用梯度检查点(Gradient Checkpointing)功能。你可以通过设置
--gradient_checkpointing 1来启用此功能,或者在模型中直接使用model.gradient_checkpointing_enable()方法。
梯度检查点允许在反向传播过程中计算部分梯度,并在需要时重新计算其余部分。这有助于降低内存占用,但是会减慢训练速度。
- 继续检查GPU内存,如果没有出现OOM,则可以继续提高
batch_size,否则逐步尝试以下阶段。
- 如果OOM,尝试
stage 2 + offload_optimizer。 - 如果OOM,尝试
ZeRO stage 3。 - 如果OOM,尝试offload_param到CPU。
- 如果OOM,尝试offload_optimizer到CPU。
- 如果OOM则,尝试降低一些默认参数。比如使用generate时,减小beam search的搜索范围,或者是启用混合精度训练
- 如果仍然OOM,则使用ZeRO-Infinity ,offload_param和offload_optimizer到NVMe。
- 如果OOM则启用梯度检查点(Gradient Checkpointing)功能。你可以通过设置
-
优化配置:一旦某个阶段使用batch_size=1时,没有导致OOM,可以优化以下参数
- 尽可能增大batch_size
- 关闭一些offload功能,或者降低ZeRO stage
- 继续调整batch_size,测量吞吐量,直到性能比较满意(调参可以增加66%的性能)
其他建议:如果从头开始训练模型,hidden size最好可以被16整除。另外batch_size最好可以被2整除。
6.2 优化器
当不启用offload_optimizer(优化器卸载)功能时,可以混合使用HF和DS的优化器和迭代器,组合情况如下:(只是不能同时使用deepspeed 优化器和huggingface的调度器)
| 组合 | HF Scheduler | DS Scheduler |
|---|---|---|
| HF Optimizer | Yes | Yes |
| DS Optimizer | No | Yes |
DeepSpeed 的主要优化器是 Adam、AdamW、OneBitAdam 和 Lamb。 这些已通过 ZeRO 进行了彻底测试,建议使用。但如果您有特殊需求,并且希望尝试其他优化器,需要添加以下内容到顶层配置:
{
"zero_allow_untested_optimizer": true
}
你也可以从 torch 导入其他优化器,详见文档。
如果没有在配置文件中配置优化器参数,Trainer 将自动将其设置为 AdamW,并将使用命令行参数的默认值:--learning_rate,--adam_beta1,--adam_beta2, --adam_epsilon , --weight_decay。默认配置如下:
{
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
}
}
也可以显式设置这些值:
{
"optimizer": {
"type": "AdamW",
"params": {
"lr": 0.001,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
}
}
需要注意的是,命令行参数将覆盖配置文件中的相应参数值(命令行参数优先),这是为了确保有一个明确定义的参数值来源,并避免在不同地方设置不同值时难以发现的错误。所以上面配置文件中的参数lr,batas,eps,weight_decay将被命令行参数--learning_rate,--adam_beta1,--adam_beta2, --adam_epsilon , --weight_decay覆盖。
你也可以使用其它官方优化器,例如使用Adam,这需要将 weight_decay 设置为 0.01 左右。
启用offload功能时,搭配 Deepspeed 的 CPU Adam 优化器一起使用时效果最佳。 但如果想对offload使用不同的优化器,在deepspeed==0.8.3 以后的版本需要添加以下内容到顶层配置:
{
"zero_force_ds_cpu_optimizer": false
}
6.3 调度器
DeepSpeed 支持 LRRangeTest、OneCycle、WarmupLR 和 WarmupDecayLR 学习率调度器,详细说明见文档。
Transformers和DeepSpeed之间存在一些学习率调度器的重叠,它们共享一些相同的调度器类型和配置参数。
WarmupLR使用--lr_scheduler_type constant_with_warmupWarmupDecayLR使用--lr_scheduler_type linear
如果没有在配置文件中配置调度器,Trainer 将使用默认的WarmupDecayLR 调度器:
{
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"last_batch_iteration": -1,
"total_num_steps": "auto",
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
}
}
这对应了默认的命令行参数--lr_scheduler_type, --learning_rate , --warmup_steps or --warmup_ratio。
以下是 配置WarmupLR 示例:
{
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
}
}
你也可以显示的设置这些值:
{
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.001,
"warmup_num_steps": 1000
}
}
}
6.4 训练精度
6.4.1 fp32和fp16
Deepspeed支持两种精度模式:fp32和fp16混合精度。通常情况下,fp16混合精度具有更小的内存需求和更快的训练速度。然而,有些模型可能不适合在fp16混合精度下训练,特别是那些没有在fp16混合精度下进行预训练的模型,因为会数据溢出,导致loss为NaN。 如果是这种情况,请使用完整的 fp32 模式。
PyTorch的训练精度有两种默认值:
- 通常情况下默认启用
fp16混合精度。如果此时需要启用 fp32 模式,需要显式禁用默认的 fp16 混合精度模式:// 显式禁用默认的 fp16 混合精度模式 { "fp16": { "enabled": false, } } - 对于基于
Ampere架构的GPU,在PyTorch 1.7及更高版本会默认选择tf32格式进行某些操作,以提高性能,最终的结果是fp32。 - 在 Trainer中,可以使用
--tf32启用它,或使用--tf32 0或--no_tf32禁用它。
Ampere是Nvidia在2020年推出的GPU架构,用于数据中心和工作站级GPU,也用于部分消费级GPU。Ampere架构相比前代Turing架构,在性能和功耗效率上都有显著提升,是Nvidia目前的主流GPU架构,其主要GPU产品有:
- A100 - 用于数据中心和高性能计算的旗舰GPU,采用8nm制程,具有最大6912个CUDA核心。
- RTX 3090/3080 - 消费级旗舰GPU,采用8nm制程,CUDA核心数分别为10496和8704。
- RTX 3070/3060 Ti - 中阶消费级GPU,CUDA核心数在3584到4864之间。
- RTX 3060/3050 - 入门级消费级GPU,CUDA核心数在2560到3584之间。
- A40 - 数据中心和工作站级GPU,采用8nm制程,CUDA核心数为10752。
- A30 - 数据中心和云游戏GPU,采用8nm制程,CUDA核心数为6144。
- A10 - 入门级数据中心和云游戏GPU,采用8nm制程,CUDA核心数为2560。
6.4.2 fp16
deepspeed fp16模式文档、deepspeed amp文档
fp16混合精度训练有两种调用方式:
-
Pytorch-like AMP:PyTorch从1.6版本开始内置的混合精度训练功能,可以通过torch.cuda.amp接口使用:import torch from torch.cuda.amp import GradScaler # 模型和优化器等定义 ... # 使用AMP scaler = GradScaler() for epoch in epochs: for input, target in data: optimizer.zero_grad() with torch.cuda.amp.autocast(): output = model(input) loss = loss_fn(output, target) scaler.scale(loss).backward() scaler.step(optimizer) scaler.update()当使用这种方式进行fp16训练时,需要在json文件中进行如下配置:
{ "fp16": { "enabled": "auto", "loss_scale": 0, "loss_scale_window": 1000, "initial_scale_power": 16, "hysteresis": 2, "min_loss_scale": 1 } }其中,
enabled=auto,所以Trainer会根据args.fp16_backend的值自动启用或禁用它,也就是在命令行参数中传入-fp16,--fp16_backend amp或--fp16_full_eval的时候启用它。你也可以将enabled参数设为true,这时候Trainer 命令行参数和 DeepSpeed 配置要与其保持一致。 -
apex-like:第三方库NVIDIA Apex也提供混合精度训练,你可以通过apex.amp接口使用:from apex import amp # 定义模型、优化器 model, optimizer = amp.initialize(model, optimizer, opt_level="O1") for epoch in epochs: for input, target in data: optimizer.zero_grad() with amp.scale_loss(loss, optimizer) as scaled_loss: output = model(input) loss = loss_fn(output, target) scaled_loss.backward() optimizer.step()此时,你需要在json文件中配置:
"amp": { "enabled": "auto", "opt_level": "auto" }Trainer会根据args.fp16_backend和args.fp16_opt_level的值自动配置,也就是命令行参数中传入--fp16,–fp16_backend apex,--fp16_opt_level时,会启用此功能。你也可以显式配置此模式,只是要保证Trainer 命令行参数和 DeepSpeed 配置与其一致。{ "amp": { "enabled": true, "opt_level": "O1" } }
6.4.3 bp16
bf16 和 fp16都是半精度浮点数格式, 主要区别如下:
- bf16:
- 可以表示更广的数值范围。但尾数只有7位,所以精度较低
- 更适合深度学习领域,可以减少模型大小,加速计算,同时保持足够的精度
- Ampere架构的Tensor Core支持bp16。
- fp16:
- 数值范围窄,但尾数有10位,精度较高。
- 更适合图形渲染等需要高精度的场景
- 大多数GPU架构都支持
如果希望启用bp16模型,配置如下:
{
"bf16": {
"enabled": "auto"
}
}
当命令行参数中传入 --bf16 或 --bf16_full_eval 时,会启用此模式。
6.4.4 NCCL Collectives
bf16模式 是从deepspeed==0.6.0 开始支持的。如果在启用 bf16 的情况下使用梯度累积,由于这种格式的精度较低,可能会导致梯度的有损累积。你可以使用更高精度 (fp16 或 fp32)。
另外,通信操作(All gather/scatter等)默认使用和模型训练相同的dtype,比如bf16训练则通信也用bf16。因为低精度加法结果不精确,会导致结果的损失,其中fp16损失较小,bf16损失更大。你可以设置为fp32通信来回避损失,代价是增加一些通信开销。 设置如下:
// communication_data_type参数控制通信dtype,可选fp16、bf16、fp32。
{
"communication_data_type": "fp32"
}
6.5 zero.Init()
DeepSpeed ZeRO-Infinity可以处理具有数万亿参数的模型,这可能超过当前硬件的内存容量。这种情况下,可以使用 deepspeed.zero.Init() 上下文管理器(这也是一个函数装饰器)来初始化模型而无需等待加载预训练权重。如果模型的 fp16 权重无法适应单个 GPU 的内存,则必须使用此功能。
from transformers import T5ForConditionalGeneration, T5Config
import deepspeed
with deepspeed.zero.Init():
config = T5Config.from_pretrained("t5-small")
model = T5ForConditionalGeneration(config)
另外,如果你需要从头开始训练一个模型,或者是单纯想加速模型的初始化速度,都可以使用此功能。
七、Model Weights
7.1 保存模型参数及恢复训练
- deepspeed会在优化器参数中存储模型的主参数,存储在
global_step*/*optim_states.pt文件中,数据类型为fp32。因此,想要从checkpoint中恢复训练,则保持默认即可 ZeRO-2模式下,模型参数会以fp16的形式存储在pytorch_model.bin中ZeRO-3模式下,需要设置如下参数,否则pytorch_model.bin将不会被创建
{
"zero_optimization": {
"stage3_gather_16bit_weights_on_model_save": true
}
}-
虽然FP16权重足以用于恢复训练,但如果想将训练好的模型上传到model hub或传给别人,最好能够获取FP32权重。这一过程最好在训练结束后离线进行,因为需要大量内存。训练结束后离线导出fp32权重,可以使用DeepSpeed 创建的一个特殊的转换脚本 zero_to_fp32.py,并将其放置在检查点文件夹的顶层。
假设你的检查点文件夹为:
$ ls -l output_dir/checkpoint-1/
-rw-rw-r-- 1 stas stas 1.4K Mar 27 20:42 config.json
drwxrwxr-x 2 stas stas 4.0K Mar 25 19:52 global_step1/
-rw-rw-r-- 1 stas stas 12 Mar 27 13:16 latest
-rw-rw-r-- 1 stas stas 827K Mar 27 20:42 optimizer.pt
-rw-rw-r-- 1 stas stas 231M Mar 27 20:42 pytorch_model.bin
-rw-rw-r-- 1 stas stas 623 Mar 27 20:42 scheduler.pt
-rw-rw-r-- 1 stas stas 1.8K Mar 27 20:42 special_tokens_map.json
-rw-rw-r-- 1 stas stas 774K Mar 27 20:42 spiece.model
-rw-rw-r-- 1 stas stas 1.9K Mar 27 20:42 tokenizer_config.json
-rw-rw-r-- 1 stas stas 339 Mar 27 20:42 trainer_state.json
-rw-rw-r-- 1 stas stas 2.3K Mar 27 20:42 training_args.bin
-rwxrw-r-- 1 stas stas 5.5K Mar 27 13:16 zero_to_fp32.py*
上述示例中,只有一个 DeepSpeed 检查点子文件夹 global_step1。因此,要重建 fp32 权重,只需运行:
python zero_to_fp32.py . pytorch_model.bin
7.2 HF预训练模型启用deepspseed方法
如果你想使用Hugging Face Transformers库中的预训练模型来进行DeepSpeed训练,要确保在创建模型之前设置了DeepSpeed配置。具体来说,需要先创建一个TrainingArguments对象(training_args),并在其中指定包括DeepSpeed配置(ds_config)在内的训练参数。然后再加载与训练模型,最后创建Trainer对象,加载模型传递训练参数,开始训练。整个顺序如下所示(官方的示例脚本就是这种代码顺序):
from transformers import AutoModel, Trainer, TrainingArguments
training_args = TrainingArguments(..., deepspeed=ds_config)
model = AutoModel.from_pretrained("t5-small")
trainer = Trainer(model=model, args=training_args, ...)
ds_config一般是json格式的配置文件,但也可以是嵌套的字典(dict),详见本文第二章
加载
fp16预训练模型时,from_pretrained需要设置torch_dtype=torch.float16,有关信息详见pretrained文档。
八、推理
正如之前3.1章节所说,推断时只需要做前向传播,所以不需要优化器、lr调度器和梯度,所以只使用ZeRO stage 3(参数划分),这使得推断更轻量且更快速。另外正因为不需要优化器、lr调度器和梯度,内存需求减少,推理时可以使用更大的batch_size和更长的序列长度。
deepspeed --num_gpus=2 your_program.py <normal cl args> --do_eval --deepspeed ds_config.json
九、内存估算
可以通过下面的代码,先估算不同配置需要的显存数量,从而决定开始尝试的ZeRO stage。
$ python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("bigscience/T0_3B"); \
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)'
[...]
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 1 GPU per node.
SW: Model with 2783M total params, 65M largest layer params.
per CPU | per GPU | Options
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=1
62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=0
0.37GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=1
15.56GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=0
例子中分析了bigscience/T0_3B模型在1个GPU上微调时的内存需求:
- HW" 表示硬件设置,即使用了 1 个节点(node)和每个节点上有 1 个 GPU。
- “SW” 表示软件设置,即模型的总参数数量为 2783M(百万)个,其中最大的单个层有 65M 个参数。
offload_param=cpu , offload_optimizer=cpu , zero_init=1表示参数和优化器状态都被分配到CPU内存,且启用ZeRO初始化。
结论:
-
如果你有一块拥有至少 80GB 显存的GPU,并且不需要在CPU上进行参数和优化器状态的内存分配,你可以训练该模型。(如果显存足够,禁用 CPU/NVMe offload,训练会更快)
-
如果你只有一块较小的GPU(例如8GB),则需要大约60GB的CPU内存,以便在CPU上存储参数和优化器状态,才能训练该模型。
如果我们使用两个GPU进行相同的操作:
$ python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("bigscience/T0_3B"); \
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=2, num_nodes=1)'
[...]
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 2 GPUs per node.
SW: Model with 2783M total params, 65M largest layer params.
per CPU | per GPU | Options
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
62.23GB | 2.84GB | offload_param=none, offload_optimizer=cpu , zero_init=1
62.23GB | 2.84GB | offload_param=none, offload_optimizer=cpu , zero_init=0
0.74GB | 23.58GB | offload_param=none, offload_optimizer=none, zero_init=1
31.11GB | 23.58GB | offload_param=none, offload_optimizer=none, zero_init=0
可以看出,如果不想使用CPU offload,那么这两个GPU至少需要32GB的显存。
注意,这些内存估算仅考虑了参数、优化器状态和梯度的内存需求,而没有考虑到CUDA核心、激活和临时内存等其他内存需求。
十、故障排除
- DeepSpeed进程在启动时被终止,且没有详细的错误追踪信息
这通常是程序尝试分配比系统实际可用的CPU内存更多的内存,或者因为超出了进程被允许分配的内存限制,导致进程被操作系统内核终止。出现此问题,一般是stage3 中配置项offload_optimizer和offload_param都设为卸载到CPU,建议改为 NVMe。详细的内存估算可参考文档:estimate how much memory is needed for a specific model。
- loss为NaN
bf16 混合精度模式下预训练的模型,在fp16精度下使用时,会导致此问题。一些由Google发布的模型,例如基于t5的模型,通常是在TPU上训练的,都使用了bf16混合精度模式,容易导致此类问题。解决办法是使用fp32精度或者bf16精度。
另外,如果出现以下情况(此处的日志经过修改以使其更具可读性):
0%| | 0/189 [00:00<?, ?it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144, reducing to 262144
1%|▌ | 1/189 [00:00<01:26, 2.17it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144, reducing to 131072.0
1%|█▏
[...]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
14%|████████████████▌ | 27/189 [00:14<01:13, 2.21it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
15%|█████████████████▏ | 28/189 [00:14<01:13, 2.18it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
15%|█████████████████▊ | 29/189 [00:15<01:13, 2.18it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
[...]
这通常是loss scaler导致的。在使用DeepSpeed的loss scaler进行混合精度训练时,它需要自动调整一个缩放因子来防止损失溢出。如果loss scaler始终无法找到一个合适的缩放因子,就会出现损失依然溢出变成NaN。
initial_scale_power控制loss scaler的初始缩放范围,将其设定为更大的值(例如32)将允许更大的初始缩放因子,就可以增加缩放的范围,从而解决这个问题。
// 尝试提高initial_scale_power以增加loss_scale的缩放范围
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
最后,HuggingFace Trainer 仅集成 DeepSpeed,如果您对 DeepSpeed 使用有任何问题或疑问,请向 DeepSpeed GitHub 提交问题。
十一、Non-Trainer Deepspeed(有空再补)
十二、示例代码
可参考:
- 《Using DeepSpeed with HF Trainer》
- BLOOM_LORA(运行示例见《Running_Deepspeed》)