笔试编程ACM模式JS(V8)、JS(Node)框架、输入输出初始化处理、常用方法、技巧
目录
考试注意事项
先审完题意,再动手
在本地编辑器(有提示)
简单题5+15min
通过率0%,有额外log
常见输入处理
str-> num arr:line.split(' ').map(val=>Number(val))
初始化数组
new Array(length).fill(value)
new Array(length).fill(0).map((_,idx)=> Number(idx))
二维数组
new Array(row).fill(null).map(() => new Array(col).fill(0));
常见输出处理
arr->srting
arr.toString()//"1,2"
arr.join(separator) arr.toString()
num->x进制:Number.toString(radix)
不够len补0:str.padStart(len, '0'),str.padStart(len, '0')
考核方式:ACM模式
JavaScript(V8)
单行readline()(1024)/gest(n)(回车)
输出printsth/log/print(sth,...)(回车)
JavaScript(Node)
while(line = await readline()){ }
rl.on('line', function(line){...}).on('close', function(){...})
常用方法/值
交换变量:[x,y]=[y,x]
Math
Number
数字字面量:浮点数值
BigInt 抛出 TypeError,以防止意外的强制隐式转换导致精度损失
Symbol 抛出 TypeError
空字符串或仅包含空格的字符串转换为 0
前导和尾随的空格/换行符会被忽略
前导的数字 0 不会导致该数值成为八进制字面量
+ 和 - 是独立的一元运算符,后面不能跟空格
不允许使用数字分隔符
parseInt(string[,radix]):基数radix是2-36之间的整数
parseFloat(string)
解析一个参数并返回一个浮点数,无法识别 0x 前缀
isNaN(string/Number/boolean/null)
NaN=超出范围的情况+不能强制转换为数值
因为 NaN == NaN 和 NaN === NaN 为 false
Map(set\delete\get\has\size)
set重设/新建:键唯一
Set(add/delete/has/size)
Array(join/splice/slice/indexOf/includes)
增删:arr.(un)shift/pop/splice(start,delCnt,item...)
arr.includes()
array.findIndex(item => item >30);
array.find(item => item> 30);
String(split/concat/substring/indexOf/includes)
输入str->arr:str.split(separator/reg).map(e=>Number(e))
str.substring(indexStart[, indexEnd])
str.indexOf(searchString[, position])
str.includes()
正则表达式Regular Expression(RegExp)
reg
reg.match(str): [values]
string
str.search(regexp): idx
str.replace(regexp|substr, newSubStr|function)
修饰符:i大小写不敏感
边界量词:^首$尾
技巧
不用顺着题目思路来
输出为值(eg:Yes/No)
时间复杂度
logN,二分查找
MN,嵌套 for 循环/二维动态规划
数据规模
一维数据:哈希/双指针/滑动窗口
树/图:遍历/递归(子树)
选择:回溯/动态规划/贪心
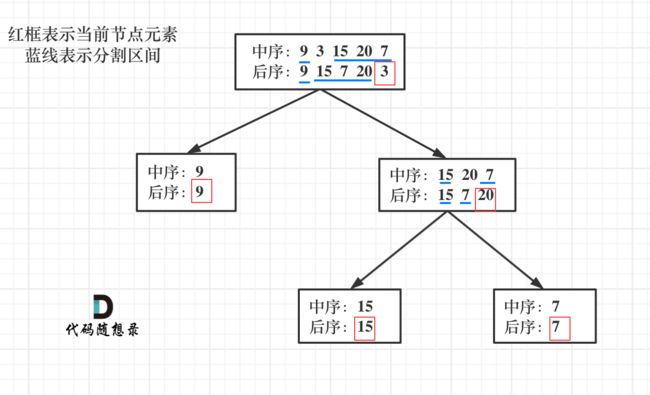
中序构建二叉树:递归
从前序与中序遍历序列构造二叉树
考试注意事项
先审完题意,再动手
在本地编辑器(有提示)
简单题5+15min
通过率0%,有额外log
常见输入处理
str-> num arr:line.split(' ').map(val=>Number(val))
初始化数组
new Array(length).fill(value)
new Array(length).fill(0).map((_,idx)=> Number(idx))
二维数组
new Array(row).fill(null).map(() => new Array(col).fill(0));
常见输出处理
arr->srting
arr.toString()//"1,2"
arr.join(separator) arr.toString()
num->x进制:Number.toString(radix)
不够len补0:str.padStart(len, '0'),str.padStart(len, '0')
考核方式:ACM模式
自己构造输入格式,控制返回格式,OJ不会给任何代码,不同的语言有不同的输入输出规范。
通过率0%时,检查是否有额外log
JavaScript(V8)
ACMcoder OJ
单行readline()(1024)/gest(n)(回车)
输出printsth/log/print(sth,...)(回车)
key:
read_line()//将读取至多1024个字符,一定注意看题目字符上限
gets(n)//将读取至多n个字符,当还未达到n个时如果遇到回车或结束符,回车符可能会包含在返回值中。
printsth(sth, ...)//多个参数时,空格分隔;最后不加回车。
console.log(sth, ...)、print(sth, ...)//多个参数时,空格分隔;最后加回车
line.split(' ').map(e=>Number(e));//str->arr
arr.push([]);//arr[]->arr[][]//单行输入
while(line=readline()){
//字符数组
var lines = line.split(' ');
//.map(Number)可以直接将字符数组变为数字数组
var lines = line.split(' ').map(Number);
var a = parseInt(lines[0]);//效果等同下面
var b = +lines[1]; //+能将str转换为num
print(a+b);
}
//矩阵的输入
while (line = readline()) {
let nums = line.split(' ');//读取第一行
var row = +nums[0];//第一行的第一个数为行数
var col = +nums[1];//第一行的第二个数为列数
var map = [];//用于存放矩阵
for (let i = 0; i < row; i++) {
map.push([]);
let mapline = readline().split(' ');
for (let j = 0; j < col; j++) {
map[i][j] = +mapline[j];
}
}
}
JavaScript(Node)
华为只可以采用Javascript(Node)
校招笔试真题_C++工程师、golang工程师_牛客网
while(line = await readline()){ }
rl.on('line', function(line){...}).on('close', function(){...})
模板1
var readline = require('readline')
// 创建读取行接口对象
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
})
单行
//监听换行,接受数据
rl.on('line', function(line) {
//line为输入的单行字符串,split函数--通过空格将该行数据转换为数组。
var arr= line.split(' ')
//数组arr的每一项都是字符串格式,如果我们需要整型,则需要parseInt将其转换为数字
console.log(parseInt(arr[0]) + parseInt(arr[1]));
})
多行
const inputArr = [];//存放输入的数据
rl.on('line', function(line){
//line是输入的每一行,为字符串格式
inputArr.push(line.split(' '));//将输入流保存到inputArr中(注意为字符串数组)
}).on('close', function(){
console.log(fun(inputArr))//调用函数并输出
})
//解决函数
function fun() {
xxxxxxxx
return xx
}
模板2
const rl = require("readline").createInterface({ input: process.stdin });
//比模版1多的:
var iter = rl[Symbol.asyncIterator]();
const readline = async () => (await iter.next()).value;
void async function () {
// Write your code here
while(line = await readline()){
let tokens = line.split(' ');
let a = parseInt(tokens[0]);
let b = parseInt(tokens[1]);
console.log(a + b);
}
}()常用方法/值
交换变量:[x,y]=[y,x]
Math
//e=2.718281828459045
Math.E;
//绝对值
Math.abs()
//基数(base)的指数(exponent)次幂,即 base^exponent。
Math.pow(base, exponent)
//max,min不支持传递数组
Math.max(value0, value1, /* … ,*/ valueN)
Math.max.apply(null,array)
//apply会将一个数组装换为一个参数接一个参数
//null是因为没有对象去调用这个方法,只需要用这个方法运算
//取整
Math.floor() 向下取一个整数(floor地板)
Math.ceil() 向上取一个整数(ceil天花板)
Math.round() 返回一个四舍五入的值
Math.trunc() 直接去除小数点后面的值Number
数字字面量:浮点数值
像 37 这样的数字字面量是浮点数值,而不是整数。JavaScript 没有单独的整数类型。
BigInt 抛出 TypeError,以防止意外的强制隐式转换导致精度损失
Symbol 抛出 TypeError
空字符串或仅包含空格的字符串转换为 0
Number(new Date("December 17, 1995 03:24:00"));//819199440000前导和尾随的空格/换行符会被忽略
前导的数字 0 不会导致该数值成为八进制字面量
Number("0x11"); // 17
Number("0b11"); // 3
Number("0o11"); // 9+ 和 - 是独立的一元运算符,后面不能跟空格
不允许使用数字分隔符
Number.MAX_VALUE
Number.MIN_VALUE;parseInt(string[,radix]):基数radix是2-36之间的整数
console.log(parseInt('123'));
// 123 (default base-10)
console.log(parseInt('123', 10));
// 123 (explicitly specify base-10)
console.log(parseInt(' 123 '));
// 123 (whitespace is ignored)
console.log(parseInt('077'));
// 77 (leading zeros are ignored)
console.log(parseInt('1.9'));
// 1 (decimal part is truncated)
console.log(parseInt('ff', 16));
// 255 (lower-case hexadecimal)
console.log(parseInt('0xFF', 16));
// 255 (upper-case hexadecimal with "0x" prefix)
console.log(parseInt('xyz'));
// NaN (input can't be converted to an integer)
console.log(parseInt(' x1'));
//NaN,如果第一个字符不能转换为数字,parseInt 会返回 NaN。
console.log(parseInt(' 1x2'));
//1,如果 parseInt 遇到的字符不是指定 radix 参数中的数字,它将忽略该字符以及所有后续字符,并返回到该点为止已解析的整数值。
parseFloat(string)
解析一个参数并返回一个浮点数,无法识别 0x 前缀
isNaN(string/Number/boolean/null)
如果isNaN(x)返回 false,那么 x 在任何算数表达式中都不会使表达式等于 NaN;
NaN=超出范围的情况+不能强制转换为数值
因为 NaN == NaN 和 NaN === NaN 为 false
isNaN(NaN); // true
isNaN(undefined); // true
isNaN({}); // true
isNaN(true); // false
isNaN(null); // false
isNaN(37); // false
// strings
isNaN("37"); // false: 可以被转换成数值 37
isNaN("37.37"); // false: 可以被转换成数值 37.37
isNaN("37,5"); // true
isNaN("123ABC"); // true: parseInt("123ABC") 的结果是 123,但是 Number("123ABC") 结果是 NaN
isNaN(""); // false: 空字符串被转换成 0
isNaN(" "); // false: 包含空格的字符串被转换成 0
// dates
isNaN(new Date()); // false
isNaN(new Date().toString()); // true
isNaN("blabla"); // true: "blabla"不能转换成数值
// 转换成数值失败,返回 NaN
Map(set\delete\get\has\size)
set重设/新建:键唯一
保存键值对,
任何值(函数、对象、基本类型)都可以作为键/值。
object的键必须是一个String或是Symbol 。
const contacts = new Map()
contacts.set('Jessie', {phone: "213-555-1234", address: "123 N 1st Ave"})
contacts.has('Jessie') // true
contacts.get('Hilary') // undefined
contacts.delete('Jessie') // true
console.log(contacts.size) // 1
function logMapElements(value, key, map) {
console.log(`m[${key}] = ${value}`);
}
new Map([['foo', 3], ['bar', {}], ['baz', undefined]])
.forEach(logMapElements);
// Expected output: "m[foo] = 3"
// Expected output: "m[bar] = [object Object]"
// Expected output: "m[baz] = undefined"
Set(add/delete/has/size)
值的集合,且值唯一
let setPos = new Set();
setPos.add(value);//Boolean
setPos.has(value);
setPos.delete(value);
function logSetElements(value1, value2, set) {
console.log(`s[${value1}] = ${value2}`);
}
new Set(['foo', 'bar', undefined]).forEach(logSetElements);
// Expected output: "s[foo] = foo"
// Expected output: "s[bar] = bar"
// Expected output: "s[undefined] = undefined"Array(join/splice/slice/indexOf/includes)
增删:arr.(un)shift/pop/splice(start,delCnt,item...)
arr.includes()
array.findIndex(item => item >30);
array.find(item => item> 30);
查询(时间复杂度和手动遍历一样)
//创建字符串
//join() 方法将一个数组(或一个类数组对象)的所有元素连接成一个字符串并返回这个字符串,
//用逗号或指定的分隔符字符串分隔。如果数组只有一个元素,那么将返回该元素而不使用分隔符。
Array.join()//如果省略,数组元素用逗号(,)分隔。
Array.join(separator)//如果 separator 是空字符串(""),则所有元素之间都没有任何字符
//################创建数组:
//伪数组转成数组
Array.from(arrayLike, mapFn)
console.log(Array.from('foo'));
// Expected output: Array ["f", "o", "o"]
console.log(Array.from([1, 2, 3], x => x + x));
// Expected output: Array [2, 4, 6]
console.log( Array.from({length:3},(item, index)=> index) );// 列的位置
// Expected output:Array [0, 1, 2]
//################原数组会改变:
arr.reverse()//返回翻转后的数组
// 无函数
//即升序
arr.sort()//默认排序顺序是在将元素转换为字符串,然后比较它们的 UTF-16
// 比较函数
arr.sort(compareFn)
function compareFn(a, b) {
if (在某些排序规则中,a 小于 b) {
return -1;
}
if (在这一排序规则下,a 大于 b) {
return 1;
}
// a 一定等于 b
return 0;
}
//升序
function compareNumbers(a, b) {
return a - b;
}
//固定值填充
arr.fill(value)
arr.fill(value, start)
arr.fill(value, start, end)
//去除
array.shift() //从数组中删除第一个元素,并返回该元素的值。
array.pop() //从数组中删除最后一个元素,并返回该元素的值。
array.push() //将一个或多个元素添加到数组的末尾,并返回该数组的新长度
//unshift() 方法将一个或多个元素添加到数组的开头,并返回该数组的新长度
array.unshift(element0, element1, /* … ,*/ elementN)
//粘接,通过删除或替换现有元素或者原地添加新的元素来修改数组,并以数组形式返回被修改的内容。
array.splice(start)
array.splice(start, deleteCount)
array.splice(start, deleteCount, item1)
array.splice(start, deleteCount, item1, item2...itemN)
//################原数组不会改变:
//切片,浅拷贝(包括 begin,不包括end)。
array.slice()
array.slice(start)
array.slice(start, end)
//展平,按照一个可指定的深度递归遍历数组,并将所有元素与遍历到的子数组中的元素合并为一个新数组返回。
array.flat()//不写参数默认一维
array.flat(depth)
//过滤器,函数体 为 条件语句
// 箭头函数
filter((element) => { /* … */ } )
filter((element, index) => { /* … */ } )
filter((element, index, array) => { /* … */ } )
array.filter(str => str .length > 6)
//遍历数组处理
// 箭头函数
map((element) => { /* … */ })
map((element, index) => { /* … */ })
map((element, index, array) => { /* … */ })
array.map(el => Math.pow(el,2))
//map和filter同参
//接收一个函数作为累加器,数组中的每个值(从左到右)开始缩减,最终计算为一个值。
// 箭头函数
reduce((previousValue, currentValue) => { /* … */ } )
reduce((previousValue, currentValue, currentIndex) => { /* … */ } )
reduce((previousValue, currentValue, currentIndex, array) => { /* … */ } )
reduce((previousValue, currentValue) => { /* … */ } , initialValue)
reduce((previousValue, currentValue, currentIndex) => { /* … */ } , initialValue)
array.reduce((previousValue, currentValue, currentIndex, array) => { /* … */ }, initialValue)
//一个“reducer”函数,包含四个参数:
//previousValue:上一次调用 callbackFn 时的返回值。
//在第一次调用时,若指定了初始值 initialValue,其值则为 initialValue,
//否则为数组索引为 0 的元素 array[0]。
//currentValue:数组中正在处理的元素。
//在第一次调用时,若指定了初始值 initialValue,其值则为数组索引为 0 的元素 array[0],
//否则为 array[1]。
//currentIndex:数组中正在处理的元素的索引。
//若指定了初始值 initialValue,则起始索引号为 0,否则从索引 1 起始。
//array:用于遍历的数组。
//initialValue 可选
//作为第一次调用 callback 函数时参数 previousValue 的值。
//若指定了初始值 initialValue,则 currentValue 则将使用数组第一个元素;
//否则 previousValue 将使用数组第一个元素,而 currentValue 将使用数组第二个元素。
const array1 = [1, 2, 3, 4];
// 0 + 1 + 2 + 3 + 4
const initialValue = 0;
const sumWithInitial = array1.reduce(
(accumulator, currentValue) => accumulator + currentValue,
initialValue
);
console.log(sumWithInitial);
// Expected output: 10String(split/concat/substring/indexOf/includes)
输入str->arr:str.split(separator/reg).map(e=>Number(e))
str.substring(indexStart[, indexEnd])
str.indexOf(searchString[, position])
str.includes()
str.charAt(index)//获取第n位字符
str.charCodeAt(n)//获取第n位字符的UTF-16字符编码 (Unicode)A是65,a是97
String.fromCharCode(num1[, ...[, numN]])//根据UTF编码创建字符串
String.fromCharCode('a'.charCodeAt(0))='a'
str.trim()//返回去掉首尾的空白字符后的新字符串
str.split(separator)//返回一个以指定分隔符出现位置分隔而成的一个数组,数组元素不包含分隔符
const str = 'The quick brown fox jumps over the lazy dog.';
const words = str.split(' ');
console.log(words[3]);
// Expected output: "fox"
str.toLowerCase( )//字符串转小写;
str.toUpperCase( )//字符串转大写;
str.concat(str2, [, ...strN])
str.substring(indexStart[, indexEnd]) //提取从 indexStart 到 indexEnd(不包括)之间的字符。
str.substr(start[, length]) //没有严格被废弃 (as in "removed from the Web standards"), 但它被认作是遗留的函数并且可以的话应该避免使用。它并非 JavaScript 核心语言的一部分,未来将可能会被移除掉。
str.indexOf(searchString[, position]) //在大于或等于position索引处的第一次出现。
str.match(regexp)//找到一个或多个正则表达式的匹配。
const paragraph = 'The quick brown fox jumps over the lazy dog. It barked.';
let regex = /[A-Z]/g;
let found = paragraph.match(regex);
console.log(found);
// Expected output: Array ["T", "I"]
regex = /[A-Z]/;
found = paragraph.match(regex);
console.log(found);
// Expected output: Array ["T"]
//match类似 indexOf() 和 lastIndexOf(),但是它返回指定的值,而不是字符串的位置。
var str = '123123000'
str.match(/\w{3}/g).join(',') // 123,123,000
str.search(regexp)//如果匹配成功,则 search() 返回正则表达式在字符串中首次匹配项的索引;否则,返回 -1
const paragraph = '? The quick';
// Any character that is not a word character or whitespace
const regex = /[^\w\s]/g;
console.log(paragraph.search(regex));
// Expected output: 0
str.repeat(count)//返回副本
str.replace(regexp|substr, newSubStr|function)//返回一个由替换值(replacement)替换部分或所有的模式(pattern)匹配项后的新字符串。
const p = 'lazy dog.Dog lazy';//如果pattern是字符串,则仅替换第一个匹配项。
console.log(p.replace('dog', 'monkey'));
// "lazy monkey.Dog lazy"
let regex = /dog/i;//如果非全局匹配,则仅替换第一个匹配项
console.log(p.replace(regex, 'ferret'));
//"lazy ferret.Dog lazy"
regex = /d|Dog/g;
console.log(p.replace(regex, 'ferret'));
//"lazy ferretog.ferret lazy"
//当使用一个 regex 时,您必须设置全局(“g”)标志, 否则,它将引发 TypeError:“必须使用全局 RegExp 调用 replaceAll”。
const p = 'lazy dog.dog lazy';//如果pattern是字符串,则仅替换第一个匹配项。
console.log(p.replaceAll('dog', 'monkey'));
// "lazy monkey.monkey lazy"
let regex = /dog/g;//如果非全局匹配,则仅替换第一个匹配项
console.log(p.replaceAll(regex, 'ferret'));
//"lazy ferret.ferret lazy"正则表达式Regular Expression(RegExp)
RegExp 的 exec 和 test 方法,以及 String 的 match、matchAll、replace、search 和 split
reg
reg.match(str): [values]
let reg = /\d/g; // 定义正则表达式reg匹配字符"a",带有全局标志"g"
let str = "1b2"; // 定义字符串str为"aba"
let match;
while ((match = reg.exec(str)) !== null) {
console.log(match); // 输出匹配到的结果
}
> Array ["1"]
> Array ["2"]string
str.search(regexp): idx
str.replace(regexp|substr, newSubStr|function)
修饰符:i大小写不敏感
边界量词:^首$尾
技巧
不用顺着题目思路来
输入的是一个单链表,让我分组翻转链表,而且还特别强调要用递归实现,就是我们旧文K 个一组翻转链表的算法。嗯,如果用数组进行翻转,两分钟就写出来了,嘿嘿。
还有我们前文扁平化嵌套列表讲到的题目,思路很巧妙,但是在笔试中遇到时,输入是一个形如 [1,[4,[6]]] 的字符串,那直接用正则表达式把数字抽出来,就是一个扁平化的列表了
输出为值(eg:Yes/No)
时间复杂度
logN,二分查找
MN,嵌套 for 循环/二维动态规划
数据规模
0 < n < 10,那很明显这个题目的复杂度很高,可能是指数或者阶乘级别的,因为数据规模再大一点它的判题系统就算不过来了嘛,这种题目十有八九就是回溯算法暴力穷举就完事。
一维数据:哈希/双指针/滑动窗口
树/图:遍历/递归(子树)
选择:回溯/动态规划/贪心
中序构建二叉树:递归