CDA Level Ⅲ 模拟题(二)
1/20
进入21世纪,数据挖掘已经成为一门比较成熟的交叉学科,并且数据挖掘技术也伴随着信息技术的发展日益成熟起来。关于数据挖掘,下列说法不正确的是()
A.数据挖掘把大型数据集转化成知识
B.数据挖掘是信息技术的进步
C.数据挖掘不可以用于任何类型的数据,即使数据对目标应用有意义
D.从海量数据中发现有价值的信息、把这些数据转化成有组织的知识,这种需求导致了数据挖掘的诞生
C作为一种通用技术,数据挖掘可以用于任何类型的数据,只要数据对目标应用是有意义的。
2/20
数据挖掘融合了数据库、人工智能、机器学习、统计学、高性能计算、模式识别、神经网络、数据可视化、信息检索和空间数据分析等多个领域的理论和技术。下列哪选项不属于数据挖掘
A.亚马逊网站中所做的图书推荐
B.淘宝平台的“猜你喜欢”
C.预测一位客户是否会在某家旗舰店购买某件商品
D.在中国铁路12306平台购买某次列车在某段运行区间的车票
D
选项D中的场景并没有体现从数据集合中自动抽取隐藏在数据中的有价值信息的过程。
3/20
缺失值是指粗糙数据中由于缺少信息而造成的数据删失或截断等问题。缺失值(NULL Value)的处理是在知识发掘处理(Knowledge Discovery Process)中的那一个阶段?
A.数据清洗
B.字段选择
C.数据编码
D.字段扩充
A缺失值处理是数据清洗工作的一环。
4/20
知识发掘处理(Knowledge Discovery Process)是从海量数据中获得知识的过程,关于其执行顺序,下列何者是正确的(A:数据清洗;B:数据选择;C:数据编码;D:数据扩充;E:数据挖掘;F:结果呈现)?
A.D→C→A→B→E→F
B.A→B→C→D→E→F
C.D→A→C→B→E→F
D.B→A→D→C→E→F
D
知识发掘处理包含了数据选择、数据清洗、数据扩充、数据编码、数据挖掘和结果呈现。
5/20
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一种理论上比较成熟的,也是最简单的机器学习算法之一。以下哪个场景不适合使用K最近邻分类算法?
A.根据喉咙痛、发烧、淋巴腺肿胀、充血、头痛等疾病特征,以及诊断结果,建立K最近邻模型,预测新患者所患疾病。
B.根据客户的收入、性别、学历等特征,以及购买的保险类型,建立K最近邻模型,预测新客户是否会购买保险。
C.根据商场客户年龄、收入、学历等特征,建立K最近邻模型,预测新客户所属的群体。
D.根据电影网站用户的年龄、收入、学历等特征,以及用户最终选择观看的电影类型,建立K最近邻模型,预测新用户喜欢的电影类型。
C
K最近邻算法属于有监督学习算法,C选项适合使用无监督学习算法
6/20
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法。在k均值聚类算法里,当邻近度函数采用以下哪种距离的时候,合适的质心是簇中各点的中位数?
A.曼哈顿距离
B.平方欧几里德距离
C.余弦距离
D.Bregman散度
A
当K均值的目标函数是曼哈顿距离表示的误差时候,最小化目标函数的质心是中位数。
7/20
AprioriAll算法的本质上是Apriori算法思想的扩张,而AprioriAll算法可用来解决何种问题?
A.分类(Classification)
B.聚类(Clustering)
C.关联(Association)
D.序列(Sequence)
D
AprioriAll 算法是序列模式的两种算法之一
8/20
亚马逊(Amazon)作为推荐引擎的鼻祖,其推荐的核心是通过数据挖掘算法和比较用户的消费偏好与其他用户进行对比,借以预测用户可能感兴趣的商品。亚马逊网站中所做的书籍推荐(Also Bought),是利用下列何种算法?
A.分类(Classification)
B.聚类(Clustering)
C.关联(Association)
D.预测(Prediction)
C为正确选项
9/20
和决策树模型相比,朴素贝叶斯分类器(Naive Bayes Classifier 或 NBC)发源于古典数学理论,有着坚实的数学基础。朴素贝叶斯分类器是属于数据挖掘中的什么方法?
A.聚类
B.分类
C.时间序列
D.关联规则
B
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法
10/20
数据填充常见算法有KNN、贝叶斯网络、神经网络等。KNN填补缺失值利用的是什么原理
A.将数据进行聚类并计算出每群的众数或均值来协助进行填补
B.利用数据在各个维度上的相关性去找出相关数据以便对数据中的缺失值进行填补
C.KNN最近邻算法是计算每个字段的均值或众数并利用计算的结果进行填补
D.KNN填补是用树模型将数据划分到一个假设空间中进行填补
B选项就是KNN填补的思路
11
在数据缺失值的填补工作中,除了可以使用特征统计量来填补,还可以合理使用算法来进行填补。以下关于K最近邻算法(KNN)缺失值填补的描述中,正确的是
A.利用的是特征之间的互信息进行填补的
B.假设我们没有获得某个数据点,利用这个数据点周围若干测量值的加权均值进行填补
C.将数据聚合成K个簇,然后利用每个簇计算该簇中的缺失样本的缺失值
D.填补速度通常比均值填补快
B
KNN填补的思路就是利用某个数据点的邻居点进行填补
12/20
缺失值从缺失的分布来讲可以分为完全随机缺失,随机缺失和完全非随机缺失。随机缺失指的是:
A.缺失数据与该变量的真实值无关,与其他变量的数值也无关。
B.缺失数据与其他变量有关
C.缺失数据依赖于该变量本身
D.数据集中不含缺失值
B
随机缺失就是指这个缺失值是和其他变量有关的,而不是完全随机的
13/20
在数据科学过程中的有效属性(或字段)的形式称为特征 ,以下不属于数据科学中常用特征的为:
A.语音识别中的MFCC
B.自然语言处理中的文档频率
C.计算机视觉中的图像边缘
D.语音识别中的一段音频
D一段音频属于一个样本,不算是特征
14/20
在百万歌曲数据集中(Million Song Dataset)包含某个用户对某一首歌的听歌次数,如果我们将超过1的数值转换成1,否则转换为0,这属于特征处理中的什么方案:
A.区间化
B.二值化
C.分箱
D.特征编码
B
0-1转换属于典型的二值化处理
14/20
在特征工程里,特征编码是占比很重的一块。在特征编码时,会将一列特征变成多列的方法是:
A.one-hot编码(独热编码)
B.映射有序特征
C.特征二值化
D.特征离散化
A
one-hot编码会将一列变成多列
16/20
Filter过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法。以下哪个方法属于过滤式特征选择
A.递归特征消除法
B.方差选择
C.随机森林进行特征选择
D.逻辑回归特征选择
B方差选择属于filter过滤式,其他不属于
17/20
在sklearn中,有很多API可以用来进行特征选择,下面不属于用于特征选择的API的是?
A.RFE
B.SelectFromModel
C.SelectKBest
D.Binarizer
D
Binarizer是特征二值化的API,不能用于特征选择
18/20
如果想要使用方差选择法,选择所有方差大于1的特征,要求代码能直接返回结果,以下代码中正确的是:
A.VarianceThreshold(threshold = 1).fit(X)
B.VarianceThreshold(threshold = 1).fit_transform(X)
C.VarianceThreshold(variances = 1).fit_transform(X)
D.VarianceThreshold(variances = 1).fit(X)
B选项是正确的代码
19/20
PCA是一种常用的降维方法,以下关于PCA的描述中错误的是
A.PCA的名称是主成分分析
B.PCA降维后的特征之间都是相互独立的
C.PCA降维的本质是通过线性变换将数据投影到低维空间中去
D.PCA保留下来的都是原数据特征中方差比较大的特征
D
PCA转换出来的不是原数据中的特征,是新的特征
20/20
特征降维一般有两类:特征选择和特征抽取。以下不属于常用的特征降维方法的有
A.PCA主成分分析
B.Kernel PCA核主成分分析
C.EmbeddedPCA嵌入式主成分分析
D.NMF非负矩阵分解法
D
A,B,C选项是常用的降维方法
单选2
1/20
PCA即主成分分析技术,又称主分量分析技术,其原理中第一步应该做的是:
A.对样本数据进行中心化处理
B.对协万差矩阵进行特征值分解, 将特征值从大到小排列
C.求样本协方差矩阵
D.取特征值前 d 大对应的特征向量
A
PCA转换中的第一步需要去中心化
2/20
关于多层神经网络特征学习,以下描述错误的是
A.多隐层的神经网络可以学习到能刻画数据本质属性的特征
B.它们可以学习在隐藏层中的输出表示
C.在神经网络中通常不用过多的特征工程
D.神经网络中的输出层的权重就是学习到的特征
D
中间层的权重相当与学习到的特征,输出层的不是
3/20
神经网络的特点是端到端的学习,以下对于神经网络和特征工程的描述错误的是
A.神经网络一般不需要过多的特征工程
B.神经网络中可以自动进行特征学习
C.神经网络将会淘汰特征工程
D.所谓端到端就是直接将原始数据输入到模型中即可
C
神经网络需要的特征工程比较少,但不会淘汰特征工
4/20
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。关于CNN网络的优点,说法不正确的是?
A.参数共享
B.捕捉长期信息
C.稀疏交互
D.平移等价性
B暂无答案解析
5/20
"从众多的文档中把一些内容相似的文档聚为一类的技术,同类的文本相似度较大,而不同类的文本相似度较小"以上描述的是什么自然语言处理方法?
A.文本分类
B.文本关联
C.文本聚类
D.文本摘要
C暂无答案解析
6/20
关于统计式分词,以下说法正确的是?
A.利用语料库归纳出统计数据作为凭断标准
B.以构词规则为出发点
C.主要有全切分以及FMM/BMM方法
D.能非常好地处理新词以及新词带来的歧义问题
A
统计式分词的优缺点: 优点: • 能够处理大多数常用词带来的歧义问题 • 在训练语料规模足够大和覆盖领域足够多的情况下,可以获得较高的切分正确率 (>=95%) 缺点: • 不能处理新词以及新词带来的歧义问题 • 需要很大的训练语料 • 分词速度相对较慢
7/20
关于统计式分词的缺点,以下说法错误的是?
A.不能处理新词以及新词带来的歧义问题
B.需要很大的训练语料
C.分词速度相对较慢
D.不能够处理大多数常用词带来的歧义问题
D
统计式分词的优缺点: 优点: • 能够处理大多数常用词带来的歧义问题 • 在训练语料规模足够大和覆盖领域足够多的情况下,可以获得较高的切分正确率 (>=95%) 缺点: • 不能处理新词以及新词带来的歧义问题 • 需要很大的训练语料 • 分词速度相对较慢
8/20
信息检索技术中的全文扫描(Full-Text Scanning)技术的缺点,说法正确的是?
A.检索反应时间缓慢
B.全文扫描需要建索引
C.需要额外的空间来储存索引
D.数据库中数据的增删与更新的工作变得繁琐
A
全文扫描不需要建索引。 全文扫描之优点: • 简化数据库中数据的增删与更新的工作 • 不需额外的空间来储存索引 全文扫描之缺点 : • 检索反应时间缓慢
9/20
自然语言处理工作中,在关键词提取的时候,有一类叫“Stop Words”的词语,其含义是什么?
A.停留词
B.停用词
C.留存词
D.停顿词
B
在信息检索中Stop Words对应的中文翻译为“停用词”,一般是文中“的,了,啊,这,那,和,因为,所以”等等这些在人类的语言中极其普通,没有什么实际含义的词。为了提高搜索效率,而人为过滤掉的词。
10/20
词频(Term Frequency)是自然语言处理算法中非常常见的一个概念。关于词频(Term Frequency)的说法,以下错误的是?
A.TF衡量一个词在文档中出现的频率
B.TF越大证明这个词越重要
C. T F = 词在文档中出现的次数 文档总词数 TF=\frac{词在文档中出现的次数}{文档总词数} TF=文档总词数词在文档中出现的次数
D.TF表示一个词在文档中的分布状况
D
TF(Term Frequency)表示词条在文档d中出现的频率,简称词频
11/20
TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)。关于TF与IDF,以下说法正确的是?
A.TF×IDF值越大,则该词成为关键词的概率就越大
B.TF/IDF值越大,则该词成为关键词的概率就越大
C.TF/IDF值越越小,则该词成为关键词的概率就越大
D.TF×IDF值越大,则该词成为关键词的概率就越小
A
词频(Term Frequency,TF) = (某个词w在di 篇文章中出现的次数) /(di 篇文章的总词数),值域范围[0,1)。例如,假设文档di 由1000个词组成,其中词w共出现了3次,那么这个词的词频就等于3/1000。 逆向文档频率 (Inverse Document Frequency,IDF) = log(总的文档数N / (1+出现词w的文档数n)) 。 IDF其实衡量了词w在每篇文档中提供的信息量。即IDF可以反映w的独特性 。 TF-IDF实际上是TF*IDF,可以得到词的重要性。可以看出TF-IDF是一种统计方法,用以评估某一字词对于一个文件集或一个语料库的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
12/20
词袋模型(Bag-of-words model)是个在自然语言处理和信息检索(IR)下被简化的表达模型。以下关于词袋模型的说法错误的是?
A.该模型将词编码为独热向量(One-hot Vector)
B.这种建模方式忽略了词之间的内在联系
C.这种建模方式丢失了词的顺序信息
D.词袋模型属于词嵌入模型的一种
D
几种文本特征向量化方法: 词集模型:One-Hot编码向量化文本(统计各词在文本中是否出现) 词袋模型:CountVectorizer文本向量化(考虑了词频) 词袋模型+IDF:基于TF-IDF方法向量化文本(考虑了词的重要性,但是会出现词表膨胀的问题) 词嵌入模型:将各词映射为实数域上的向量,词向量之间的几何关系表示词之间的语义关系。以Word2Vec为典型代表。
13/20
Glove模型表示的语义词向量相似度尽可能接近在统计共现矩阵中统计相似度,并且不同共现的词有不同权值。关于GloVe模型的描述,以下正确的是?
A.基于全局词频统计的词表征算法
B.基于"文档-词"矩阵分解
C.属于神经网络模型
D.基于词预测的词嵌入模型
A
参见上题的解析,Word2Vec和GloVe模型是词嵌入模型的两个流行方法。
14/20
Word2Vec 是Google在2013年开源的一款词向量化的高效工具,主要包含两个模型:连续词袋模型(continuous bag of words,简称CBOW)跳字模型(skip-gram)。关于CBOW模型,以下说法错误的是?
A.属于浅层神经网络
B.属于词嵌入模型
C.模型的目标是最大化通过上下文的词预测当前词生成概率
D.模型的目标是最大化用当前的词预测上下文的词的生成概率
D暂无答案解析
15/20
CBOW模型根据某个中心词前后A个连续的词,来计算该中心词出现的概率,即用上下文预测目标词,模型结构简易。CBOW模型不包含以下哪一项?
A.输入层
B.池化层
C.输出层
D.隐藏层
B

CBOW考虑的主要思想是要P( w | Context(w) )的概率最大化,所以接下来看CBOW模型主要就是看如何定义和计算这个概率。(当然对于语言模型来说,实际的目标函数通常是对语料库中的每个词的概率P( w | Context(w) )取对数再累加)
输入层:词w前后c个,共2c个词的词向量 投影层(隐藏层):对这2c个词向量求和. 因为CBOW使用的是词袋模型,因此这2c个词都是平等的,也就是不考虑他们和我们关注的词之间的距离大小,只要在我们上下文之内即可。 输出层:以语料库出现的词为叶子节点,以词在语料库中出现的次数为权重,构造Huffman树。这颗Huffman树的叶子节点共有D个(语料库中词的个数), 非叶子节点共有(D-1)个。
结论:CBOW模型的一次更新是:输入2c个词向量的累加,然后对中心词w上的路径节点系数进行更新,然后对所有的上下文词的词向量进行整体一致更新。
16/20
CBOW和Skip-Gram都是在word2vec中用于将文本进行向量表示的实现方法,关于Skip-Gram模型与CBOW模型的描述,以下正确的是?
A.Skip-Gram模型输入的是当前词的词向量
B.CBOW模型输入的是当前词的词向量
C.Skip-Gram模型输出的是当前词的词向量
D.CBOW模型输出的是周围词的词向量
A
见上题解析
17
朴素贝叶斯(Naive Bayes)是一种特殊的Bayes分类器,特征变量是X,类别标签是C,它的一个假定是:
A.各类别的先验概率P©是相等的
B.以0为均值,sqr(2)/2为标准差的正态分布
C.特征变量X的各个维度是类别条件独立随机变量
D.P(X|C)是高斯分布
C暂无答案解析
18/20
朴素贝叶斯(Naive Bayes)是基于贝叶斯定理与特征条件独立假设的分类方法,可以用来预测何种数据型态?
A.数值
B.类别
C.时间
D.以上皆是
B
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法
19/20
在决策树算法的学习过程中,信息增益(Information Gain)是特征选择的一个重要指标,它定义为一个特征能够为分类系统带来多少信息,决策树中的信息增益的计算是用来?
A.剪枝
B.使树成长
C.处理空值
D.避免树过度成长
B暂无答案解析
20/20
下列哪个决策树的算法采用盆栽法 (Bonsai Technique)由上而下(Top-Down)的方式来剪枝?
A.CHAID
B.CART
C.C4.5
D.以上皆是
A暂无答案解析
单选3
1/20
决策树建模时一个必要的步骤是决策树的修剪,下列哪个选项不是决策树需要修剪的原因?
A.为避免数据中的噪声影响建树的结果
B.为了得到较一般化的决策规则
C.为了节省建模所需的时间
D.为了能在测试数据集中得到较好的预测结果
C暂无答案解析
逻辑回归Logistic Regression)和神经网络都可以进行多类别分类,那么如何以类神经网络仿真逻辑回归?
A.输入层节点个数设定为3
B.隐藏层节点个数设定为0
C.输出层节点个数设定为3
D.隐藏层节点个数设定为1
B暂无答案解析
3/20
BP神经网络是一种多层的前馈神经网络,其主要的特点是:信号是前向传播的,而误差是反向传播的。BP神经网络可以有几层隐藏层?
A.1层
B.2层
C.3层
D.以上皆可
D暂无答案解析
4/20
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。卷积神经网络中Dropout层的作用是?
A.加快收敛速度
B.防止过拟合
C.丰富训练样本
D.增强正样本
B暂无答案解析
5/20
可解释性是指人类能够理解决策原因的程度。机器学习模型的可解释性越高,人们就越容易理解为什么做出某些决定或预测。下列哪种算法的可解释性最差?
A.线性回归
B.逻辑回归
C.回归树
D.XGBoost
D集成算法的可解释性相对较低。
6/20
假如我们使用非线性可分的SVM目标函数作为最优化对象,我们怎么保证模型线性可分?
A.设C=1
B.设C=0
C.设C=无穷大
D.以上都不对
C暂无答案解析
7/20
随机森林(Random Forest)是一种集成算法(Ensemble Learning),它属于Bagging类型,通过组合多个弱分类器,最终结果通过投票或取均值,使得整体模型的结果具有较高的精确度和泛化性能。集成方法中的随机森林,是下列哪个方法的延伸?
A.决策树
B.神经网络
C.贝叶斯分类法
D.以上均可
A随机森林指的是利用多棵树对样本进行训练并预测的一种分类器
8/20
多层感知器和单层感知器一样,是一种人工神经网络,多层感知机解决了单层感知机不能解决的什么问题?
A.与
B.或
C.非
D.异或
D暂无答案解析
9/20
以下文本特征向量化的方法中属于词嵌入模型的是?
A.One-Hot编码
B.TF-IDF模型
C.CBOW模型
D.以上皆是
C暂无答案解析
10/20
系统聚类法(hierarchical cluster method)又称“分层聚类法”,是聚类分析的一种方法。而在系统聚类中R2是指?
A.组内离差平方和除以组间离差平方和
B.组间离差平方和除以组内离差平方和
C.组间离差平方和除以总离差平方和
D.组间均方除以总均方。
C暂无答案解析
11/20
BIRCH是以下哪种算法的简称?
A.分类器
B.聚类算法
C.关联分析算法
D.特征选择算法
B暂无答案解析
12/20
聚类分析是指将数据对象的集合分组为由类似的对象组成的多个类的分析过程。以下哪个是聚类分析所关心的重点?
A.如何以数字来表示成员间的相似性
B.如何根据相似性将类似的成员分在同一群
C.所有成员分群完毕后,对每一群的特征应如何描述
D.以上皆是
D暂无答案解析
13/20
关联分析又称关联挖掘,就是在交易数据、关系数据或其他信息载体中,查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构。以下属于关联分析的是:
A.CPU性能预测
B.购物篮分析
C.自动判断鸢尾花类别
D.股票趋势建模
B暂无答案解析
14/20
有一条关联规则为A → B,此规则的置信水平(confidence)为60%,则代表:
A.买B商品的顾客中,有60%的顾客会同时购买A
B.买A商品的顾客中,有60%的顾客会同时购买B
C.同时购买A,B两商品的顾客,占所有顾客的60%
D.两商品A,B在交易数据库中同时被购买的机率为60%
B暂无答案解析
15/20
假设{BCE}为一频繁项目集(Frequent Itemset),则根据Apriori Principle以下何者不是子频繁项目?
A.BC
B.CE
C.C
D.CD
D暂无答案解析
16/20
序列模式挖掘 (sequence pattern mining )是指挖掘相对时间或其他模式出现频率高的模式,典型的应用还是限于离散型的序列。序列模式中关于序列的说法不正确的是?
A.一般地,序列是元素(element)的有序列表
B.序列的长度对应于出现在序列中的元素个数
C.序列可以用它的长度和出现事件的个数刻画
D.序列模式的讨论主要考虑时间事件,不可以将它推广到事件具有空间次序的情况
D暂无答案解析
17/20
关于序列模式的说法,下列选项不正确的是?
A.给定数据集D和用户指定的最小支持度阈值minsup,序列模式发现的任务是找出支持度大于或等于minsup的所有序列。
B.候选序列的个数比候选项集的个数大的多
C.序列模式的每个元素都与一个时间窗口[L,u]相关联,其中L是该时间窗口内事件的最晚发生时间,而u是该时间窗口内事件的最早发生时间。
D.序列s的支持度是包含s的所有数据序列所占的比例。如果序列s的支持度大于或等于用户指定的阈值minsup,则称s是一个序列模式(或频繁序列)。
C暂无答案解析
18/20
机器学习中的分类模型有逻辑回归、朴素贝叶斯、决策树、支持向量机、随机森林、梯度提升树等分类算法。一般情况下,以下哪些指标不用于分类模型中的模型评价:
A.正确率Accuracy
B.查全率Recall
C.命中率Precision
D.轮廓系数Silhouette Coefficient
D轮廓系数Silhouette Coefficient一般用作评价聚类效果
19/20
ROC曲线一般指接受者操作特征曲线。接受者操作特性曲线是指在特定刺激条件下,以被试在不同判断标准下所得的虚报概率P(y/N)为横坐标,以击中概率P(y/SN)为纵坐标,画得的各点的连线。在使用ROC曲线判断模型的优劣时,以下哪个叙述是正确的?
A.ROC曲线下方的面积越大,说明模型效果越好
B.ROC曲线下方的面积越小,说明模型效果越好
C.ROC曲线越靠近45度斜线,说明模型效果越好
D.ROC曲线一般在45度斜线下方
A暂无答案解析
20/20
以下哪个指标不能用于线性回归中的模型比较:
A.F-measure
B.调整R方
C.AIC
D.BIC
A暂无答案解析
【多选题】1/30
目前流行众多的数据挖掘工具,具有不同的特点,能够满足不同人群的工作需求。以下哪些数据挖掘的工具,在数据处理及建立模型时是不需要编程?
A.IBM SPSS Modeler
B.Python
C.SAS Enterprise Miner
D.Weka
ACD暂无答案解析
2/30
无监督算法(unsupervised learning)属于机器学习(machine learning)的一种,下列哪些算法为无监督机器学习法?
A.关联规则
B.决策树
C.序列分析
D.聚类
ACD暂无答案解析
3/30
如果整个数据分析模型完成后,发现效果不良,考虑从哪些步骤入手改进?
A.数据清洗是否到位
B.数据理解是否有偏差
C.模型选择是否合适
D.参数调整是否合理
ABCD暂无答案解析
4/30
对于随机缺失和非随机缺失,直接删除记录是不合适的。而对于离散型变量使用以下哪个统计量进行缺失值填补较合适?
A.均值
B.最大值
C.中位数
D.众数
CD暂无答案解析
5/30
机器学习算法有很多,有分类、回归、聚类、推荐、图像识别领域等等,下列哪些算法可用于分类问题?
A.Regression Tree
B.SVM
C.Random Forest
D.Apriori
BC暂无答案解析
6/30
数据缺失是众多影响数据质量的因素中最常见的一种.如果处理不好缺失数据,就会直接影响分析结果的可靠性,进而达不到分析的目的。以下可用作缺失值填补的模型是:
A.随机森林(Random Fores)
B.极端梯度提升(Xgboost)
C.K最近邻(KNN)分类算法
D.主成分分析(PCA)
ABC暂无答案解析
7/30
假设我们要做一个图像识别工作,以下哪个属于特征
A.图像颜色
B.图像纹理
C.图像角点
D.图像格式
ABC图像颜色,纹理,角点都属于特征,格式不属于
8/30
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。tf-idf中的tf和idf分别代表了什么含义?
A.逆词频对数
B.词频
C.词向量
D.逆文本频率指数
BD
tf代表词频,idf代表逆文本频率指数
9/30
无量纲化,也称为数据的规范化,是指不同指标之间由于存在量纲不同致其不具可比性,故首先需将指标进行无量纲化,消除量纲影响后再进行接下来的分析。sklearn中一些无量纲化的常见操作方法有:
A.StandardScaler()
B.Binarizer()
C.MinMaxScaler()
D.Normalizer()
ACD都是标准化方法,B是二值化方法
10/30
特征选择(Feature Selection)和特征提取(Feature Extraction)是特征工程(Feature Engineering)的两个重要子内容。需要做特征选择工作的两个主要原因是:
A.解决维度灾难问题
B.防止模型过拟合
C.将相关的特征压缩成更少的特征
D.降低学习难度
AD是特征选择的两个主要原因
11/30
包裹式特征选择法的特征选择过程与学习器相关,使用学习器的性能作为特征选择的评价准则,选择最有利于学习器性能的特征子集。以下对于包裹式特征选择中正确的是?
A.包裹式从初始特征集合中不断的选择特征子集
B.包裹式特征选择的计算开销通常比过滤式大
C.包裹式特征选择常用互信息法
D.从最终学习器的性能来看,包裹式一般比过滤式更好
ABD包裹式特征选择不能用互信息法
12/30
在机器学习中,特征学习或表征学习是学习一个特征的技术的集合:将原始数据转换成为能够被机器学习来有效开发的一种形式。特征学习主要可以分成两类,是哪两类?
A.强化特征学习
B.监督特征学习
C.无监督特征学习
D.迁移特征学习
BC暂无答案解析
13/30
自然语言处理(NLP)是计算机科学,人工智能,语言学关注计算机和人类(自然)语言之间的相互作用的领域。以下选项属于自然语言处理方法的是?
A.文本分类
B.文本关联
C.文本聚类
D.文本摘要
ABCD文本分类 : 在给定已知的分类体系下,根据文本特征构建有监督机器学习模型,达到识别文本类型或内容主旨的目的. 文本关联 : 它是传统关联规则方法在文本挖掘上的应用,包含文档类型关联、词汇关联、实体关联等内容. 文本聚类: 就是从众多的文档中把一些内容相似的文档聚为一类的技术,同类的文本相似度较大,而不同类的文本相似度较小,是一种无监督的机器学习方法. 文本摘要: 就是对数据内容进行提炼与总结,以简洁、直观的摘要来概括所关注的主要内容,方便我们快速地了解与浏览内容.
14/30
法则式分词是一种机械分词方法,主要通过维护词典,在切分语句时,将语句的每个字符串与词典中的词进行逐一匹配,找到则切分,否则不切分。在分词技术中,关于法则式分词法的说法正确的是?
A.该方法分词精度很高,能很好处理歧义
B.法则式分词法强调的是语言现象
C.该方法程序简单易行,开发周期短
D.该方法不能识别新词
BCD
法则式分词法强调的是语言现象。C选项是其优点,D选项是其缺点。法则式分词处理歧义的方式太过简单,这是A表述不对的原因。
15/30
以下该关于自然语言处理的逐项反转法的说法,正确的是?
A.逐项反转 (Inversion of Terms)法一般称为Inverted File
B.其主要精神是利用繁复的索引来提高检索的效率
C.该方法使得每一文件皆可利用反转其本身文件的内容, 记录这些文字的位置
D.该方法利用重迭编码的技巧, 将文件转换成一固定长度的签名以加速字符串比对
ABC
全文扫描、逐项反转、签名文件是信息检索技术中的基本检索法。向量空间模型、概率式检索模型、神经网络模型都属于信息检索技术中的进阶检索法。 逐项反转 (Inversion of Terms)法一般称为Inverted File,其主要思想是利用繁复的索引来提高检索的效率。该方法在文件搜寻时仅需比对索引, 无需进一步比对文件内容;每一文件皆可利用反转其本身文件的内容, 记录这些文字的位置, 以表达文件的内涵。 签名文件是逐项反转法和全文扫瞄的综合体,利用重迭编码(Superimposed Coding)的技巧, 将文件转换成一固定长度的签名(Signature)以加速字符串比。
16/30
在中文的自然语言处理工作中,以下属于建立关键词的程序是?
A.读取文献
B.分词
C.利用 Suffix String 将 Word 重整至最基本字型
D.计算每个Word的IDF
ABCD
关键词是能够表达文档中心内容的词语,常用于计算机系统标引论文内容特征、信息检索、系统汇集以供读者检阅。关键词提取是文本挖掘领域的一个分支,是文本检索、文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作 建立关键词的程序(抽取层次:词) - 读取文献 - 分词(中文需要) - 利用 Suffix String 将 Word 重整至最基本字型(Stem Word)(英文需要) - 计算每个 Word 的IDF - 利用一个阀值(Threshold) - 选出代表文献的关键词及其IDF - 产生Stop Words
17/30
文件语意的抽取层次可以是以什么为单位?
A.字
B.词
C.词组
D.N-Gram
ABCD字、词、词组、概念 (Single Term or Phrase Term)或N-Gram都是文件语意的抽取层次的单位
18/30
奇异值分解(Singular Value Decomposition,以下简称SVD)是在机器学习领域广泛应用的算法。以下关于奇异值分解算法的说法,正确的是?
A.SVD无法用作降维
B.一个常见的矩阵分解算法
C.SVD经常拿来做损失较小的有损压缩
D.奇异值类似主成分,我们往往取Top K个奇异值就能够表示绝大部分信息量
BCD奇异值分解(SVD)是一个常见的矩阵分解算法。奇异值类似主成分分析,也是一种常用的降维方式,我们往往取Top K个奇异值就能够表示绝大部分信息量,因此SVD经常拿来做损失较小的有损压缩。
19/30
有监督学习是从标签化训练数据集中推断出函数的机器学习任务。以下算法中,属于有监督算法的是()
A.朴素贝叶斯
B.线性回归
C.卷积神经网络
D.因子分析
ABC暂无答案解析
20/30
朴素贝叶斯分类器是一系列以假设特征之间强(朴素)独立下运用贝叶斯定理为基础的简单概率分类器。朴素贝叶斯分类器一般具有以下特点。
A.输入属性的独立性假设
B.它是以概率模型为基础
C.它可以处理数值型的输入属性
D.输入属性独立性的假设是正确的
ABC暂无答案解析
21/30
决策树(Decision Tree)算法,通常可以用来解决何种问题?
A.分类(Classification)
B.聚类(Clustering)
C.回归(Regression)
D.关联(Association)
AC暂无答案解析
22/30
决策树归纳算法可为哪种类型的属性提供表示属性测试条件和其对应输出的方法。
A.二元属性
B.标称属性
C.序数属性
D.连续属性
ABCD暂无答案解析
23/30
决策树建模时一个必要的步骤是决策树的修剪,下列选项是决策树需要修剪原因的有?
A.为避免数据中的噪声影响建树的结果
B.为了得到较一般化的决策规则
C.为了节省建模所需的时间
D.为了能在测试数据集中得到较好的预测结果
ABD暂无答案解析
24/30
以下哪些算法,可以用神经网络去构造?
A.KNN
B.线性回归
C.逻辑回归
D.K-Means
BC暂无答案解析
25/30
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛。下列有关K-means算法的叙述何者有误?
A.运行速度较一些聚类方法(例如,PAM)慢
B.离群值将影响聚类的结果
C.起始群中心的选择将影响聚类的结果
D.能接受类别型的字段
AD暂无答案解析
26/30
Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策。Apriori算法的计算复杂度受()影响
A.支持度阀值
B.项数(维度)
C.事务数
D.事务平均宽度
ABCD暂无答案解析
27/30
请问要符合什么条件才可被称为关联规则 ?
A.最小支持度(Minimum Support)
B.最小置信度(Minimum Confidence)
C.最大规则数(Maximum Rule Number)
D.以上皆非
AB暂无答案解析
28/30
可以降低产生频繁项集计算复杂度的方法有?
A.减少候选项集的数目
B.增加候选项集的数目
C.减少比较次数
D.增加比较次数
AC暂无答案解析
29/30
在整个随机森林的算法过程中,以下哪两个随机过程可使随机森林很大程度上避免了过拟合现象的出现
A.构建决策树输入数据的随机选取
B.构建决策树分裂节点的随机选取
C.构建决策树树的数量的随机选取
D.构建决策树所需特征的随机选取
AD暂无答案解析
30/30
支持向量机是在统计学习理论的基础上发展起来的一种机器学习方法,它基于结构风险最小化原则,能有效地解决学习问题,具有良好的推广性能和较好的分类精确性,通常可以用来解决何种问题
A.分类(Classification)
B.聚类(Clustering)
C.回归(Regression)
D.关联(Association)
AC暂无答案解析
1/12
由于竞争加剧,某电信公司用户流失情况日趋严重,为了更好的预测用户的未来流失的可能性,数据分析团队准备建立客户流失的预测模型,用于提前了解用户流失的倾向,进行提前挽留和客户关怀,结合客户流失建模过程中的具体问题,请回答:建模过程中,X变量的设计非常重要,在流失模型中常用的RFM变量是指以下哪几个常用变量:
A.最近一次消费(Recency) 消费频率(Frequency) 消费金额(Monetary)
B.循环消费情况(Revolving) 消费频率(Frequency) 消费金额(Monetary)
C.最近一次奖励(Rewarding) 消费频率(Frequency) 消费金额(Monetary)
D.帐户注册时间(Recuriment) 消费频率(Frequency) 消费金额(Monetary)
A暂无答案解析
2/12
由于竞争加剧,某电信公司用户流失情况日趋严重,为了更好的预测用户的未来流失的可能性,数据分析团队准备建立客户流失的预测模型,用于提前了解用户流失的倾向,进行提前挽留和客户关怀,结合客户流失建模过程中的具体问题,请回答以下2道题目。
以下关于数据诊断清洗的说法哪些是正确的:
A.数据在人工输入时是会出现数据错误,比如年龄,性别等数据项
B.python数据清洗中,对于二分类的分类变量0-1数值化后可以不用再做get_dummies处理,同理多分类变量也只需数值化即可
C.数据误差不会影响模型建立的准确性,因为预测是概率性的
D.线性回归建模,一般不用关注异常值
A暂无答案解析
3/12
在乳腺癌数据集当中有30个数值型特征,分别代表了30个光片上面的特征,其中包含平均半径,平均光滑度,平均紧凑度等,但数据的量纲不同,请回答以下问题:
以下模型中有哪一个是不需要统一量纲的?
A.KNN
B.SVM
C.随机森林
D.Kmeans
C暂无答案解析
4/12
在乳腺癌数据集当中有30个数值型特征,分别代表了30个光片上面的特征,其中包含平均半径,平均光滑度,平均紧凑度等,但数据的量纲不同,请回答以下问题:
在L2归一化方法中,以下描述不正确的是:
A.经过L2范数归一化,特征列的范数变成1
B.L2范数就是一个特征列所有值的平方和再算出平方根
C.L2范数又称为欧几里得范数
D.缩放后的标准差的平方为1
D暂无答案解析
5/12
在一组学校学生信息数据当中,有一列数据是血型,如图所示:

如果我们直接将某列有序变量进行顺序数值编码,存在的问题是:
A.特征信息损失
B.特征增加原来不存在的信息
C.特征信息完全改变
D.特征分布改变
B暂无答案解析
为了解决有序编码中存在的问题,我们可以采用one-hot编码方式,one-hot编码中,原来一共有4个不同的血型,那么编码之后一般来说会拆分成几列
A.1列
B.2列
C.3列
D.4列
C暂无答案解析
7/12
假设有句子"他说的确实在理",对这句话进行分词。
中文分词是NLP任务中重要的一步,如果对“他说的确实在理”利用结巴进行全切分,其的结果为?
A.{他,说,的确,确实,实在,理}
B.{他,说,的,确实,在理}
C.{他,说,的确,实在,理}
D.{他,说,的确,实,在理}
A
全切分:获得文本所有可能的切分结果。所以选A。
8/12
假设有句子"他说的确实在理",对这句话进行分词。
如果第二步选择Viterbi动态规划,那么第三步如果使用统计式分词方法,将会选择以下什么作为切分结果?
A.选择TF最大的路径为切分结果
B.选择概率最大的路径为切分结果
C.选择TF*IDF最大的路径为切分结果
D.选择IDF最大的路径为切分结果
B
统计式分词的步骤: 第一步:全切分 第二步:Viterbi动态规划,找到贯穿句子的路径并计算每条路径的概率 第三步:选择概率最大的路径 为切分结果
9/12
给定以下的便利商店选点数据集,并采用CART的分类树算法建构分类树(目标字段为最后一个字段)时,请回答以下题目:
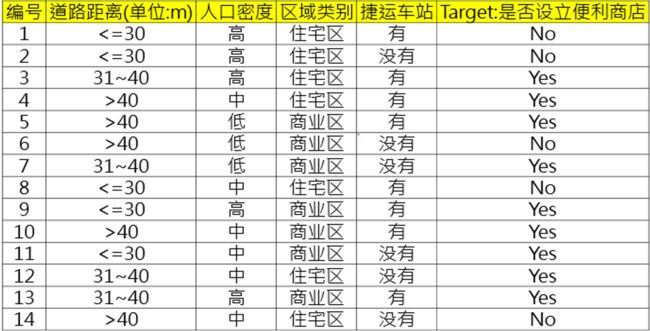
当左子树是道路距离<=30,右子树是道路距离31~40或>40时,请计算此树的Gini值为何?
A.0.335
B.0.247
C.0.249
D.0.394
D暂无答案解析
当左子树是人口密度=中,右子树是人口密度=高或人口密度=低时,请计算此树的Gini值为何?
A.0.378
B.0.398
C.0.102
D.0.458
D暂无答案解析
当左子树是区域类别=住宅区,右子树是区域类别=商业区时,请计算此树的Gini值为何?
A.0.457
B.0.367
C.0.459
D.0.347
B暂无答案解析
当左子树是捷运车站=有,右子树是捷运车站=没有时,请计算此树的Gini值为何?
A.0.398
B.0.489
C.0.429
D.0.217
C暂无答案解析