MySql笔记
mysql5.7版本在公司中主流使用
mariadb为mysql的分支free版本,在centos7中默认安装(mysql被oracle收购)
1.mysql初始
启动mysql:
systemctl start mysqld连接mysql
无密码则直接用mysql命令连接
若有密码则用下列命令行
mysql -u 用户名 -p此时会要求输入密码
![]()
输入正确密码后可以看到连接成功
1.1客户端与服务端
mysql服务端:数据库管理软件
mysql客户端:程序员使用的和数据库服务交互的软件
linux命令行中使用的mysql指令为mysql的客户端,mysqld为服务端,通过mysql命令与服务端交互
服务端会有两个进程:mysqld与mysql_safe
mysql_safe:守护进程,守护mysqld,当mysqld挂掉时,快速拉起
1.2启动服务端
启动:systemctl start mysqld
关闭:systemctl stop mysqld
重启:systemctl restart mysqld
自启动:systemctl enable mysqld
开机不启动:systemctl disable mysqld
1.3连接mysql服务端
mysql -h [服务端所在地址] -P [端口号] -u [用户名] -p在连接服务端(mysqld)时,mysqld会针对连接上来的客户端所在的ip进行校验,因此,上述命令中的u代表的是客户端(mysql)的用户名(非linux中的用户)
mysqld会先判断-u是否能够从地址为ip的机器进行登录,若可以则校验密码。
1.4mysql服务端、数据库、表的关系
mysql服务端是数据库管理软件
服务端(msyqld)可以管理多个数据库,是个进程
每个数据库中有多个表
数据库相当于文件夹,表相当于一个个文件
my.cnf为数据库的配置文件,在/etc中,datadir代表了数据库的位置路径:默认为/var/lib/mysql,这下面的每个文件夹代表一个数据库,其中的每个文件代表一个表
1.5mysql服务端分层认识
服务端可分为4层,自上至下分别为:连接层、服务层、存储引擎、磁盘。
连接层:
1.用于建立连接,跨网络,TCP;同一台机器则通过套接字AF_UNIX(进程间通信)
2.检验用户名和密码:连接服务端时,-u输入的是Mysql的一个用户,不是Linux的root用户
3.校验客户端ip地址:一般mysql默认创建的用户不支持跨网络连接
服务层
1.sql语法语义检测
2.优化sql
3.将sql交给存储引擎进行执行
存储引擎
1.执行sql
2.获取执行结果
3.结果返回给服务层
1.6建立数据库demo测试
创建数据库: create database 数据库名; 相当于创建文件夹
使用数据库:use 数据库名;
创建表:create table 表名(自定义名称 类型,....);若类型为varchar,需要给出有几个字符例如varchar(2)代表两个
插入数据:insert into 表名(自定义名称,....) values (值,...);如果值是字符串,需要用" ' ' "包围
插入数据时,若带有中文,可能会报错(1366),此时可以更改数据库、表、字段的字符集
alter database mydb character set gbk;
alter table department character set gbk;
alter table department modify dname varchar(20) character set gbk;查询数据:select * from 表名;查找某个表中的所有数据
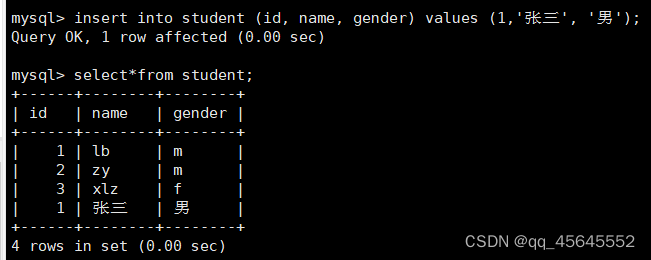
如该图所示,id、name、gender被称作表字段(列字段),其存储了字段名以及属性
表的下半部分为表数据,一行为一个表数据(表记录),逻辑存储时是行列存储
1.7sql语言分类
DDL(data definition language)数据定义语言,用于维护存储数据的结构,create,drop,alter
DML(data manipulation language)数据操纵语言,用于对数据进行操作,insert,delete,update
DCL(data control language)数据控制语言,负责权限管理与事务,grant,revoke,commit
2.数据库的操作
2.1创建数据库
create database 【数据库名】【字符集】【校对规则】;
字符集:charset
校对规则:collation
eg:
创建数据库时指定字符集
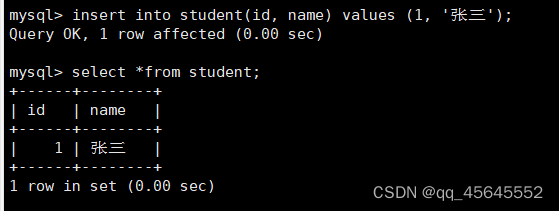
create database test3 charset utf8;此时向其中创建一个student表,并插入带有中文的数据不会报错
2.2数据库字符集
系统默认的字符集可通过以下语句查看
show variables like 'character_set_database';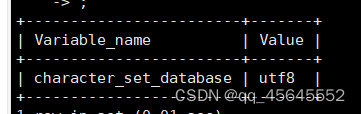
可通过以下语句查看系统支持的字符集
show charset;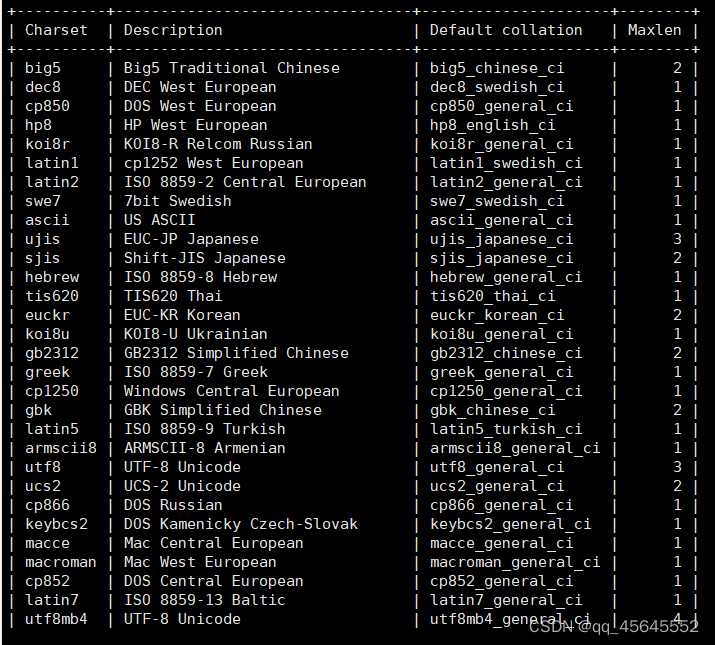
字符集的选择决定了数据库能够存储的字符范围
2.3数据库校对规则
校对规则决定当前数据库是否大小写敏感,会对查询的排序有影响
后缀为_ci的不区分大小写,后缀为_bin的区分大小写
默认不敏感。
例如,若数据中有'a'和'A',则在查找'a'时,如果不敏感则会返回'a'与'A',否则只返回'a'
2.4操纵数据库
查看有多少数据库:
show databases;
查看某个数据如何创建:
show create database 数据库名;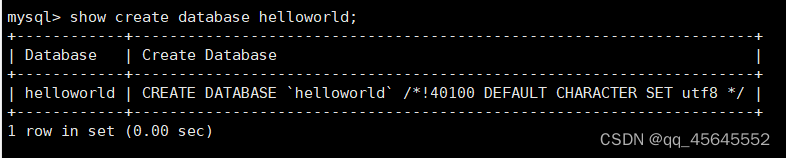
修改数据库属性:
alter database [数据库名] [属性]=[新属性];
此时已经将数据库test3的字符集更改为utf8
删除数据库:
drop database [数据库名]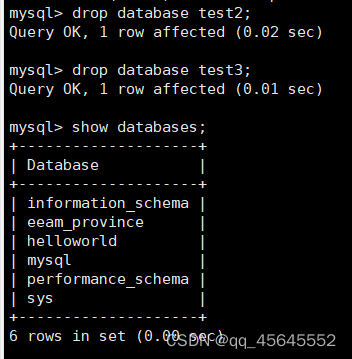
2.5查看数据库连接状态
show processlist;
2.6数据库备份
备份:
mysqldump -P3306 -u root -p[密码] -B 数据库名 > 数据库备份存储的文件路径
还原:
source 数据库备份存储的文件路径2.7数据库表备份
备份:
mysqldump -P3306 -u root -p[密码] -B 数据库名 表名1 表名2 > 数据库表备份存储的文件路径
还原:
source 数据库备份存储的文件路径
若备份时没有-B参数,恢复时需要先建立空数据库,再用source来还原3.表的操作
3.1表的创建
语法规则
create table 表名(
自定义变量名1 类型,
自定义变量名2 类型,
自定义变量名3 类型,
)character set 字符集 collate 校验规则 engine 存储引擎;
字符集与校对规则不设置,默认采用数据库的字符集与校对规则
创建示例:
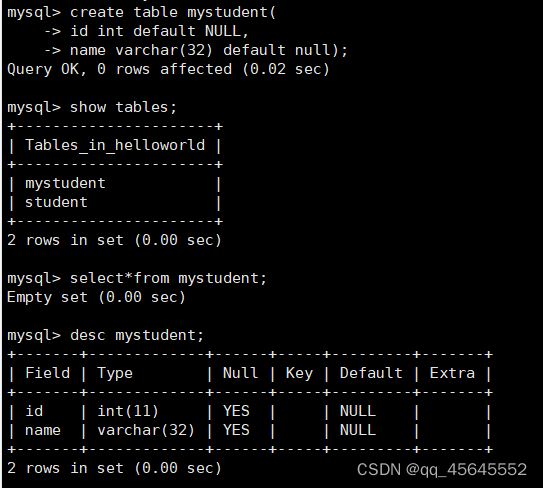
desc + 表名可以查看表结构
Innodb的存储:.frm文件为表结构文件,.ibd文件为表数据文件
MyISAM的存储:.frm为表结构,MYD为表数据,MYI为表索引
以上可以在/etc/var/lib/mysql下的各个数据库文件下找到
3.2查看表
查看如何建表:show create table 表名称;
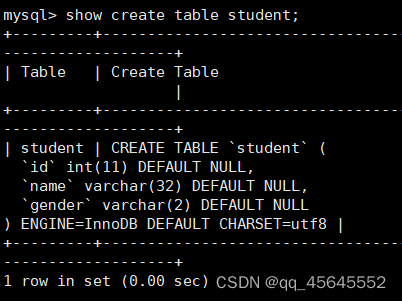
查看表结构desc 表名称;
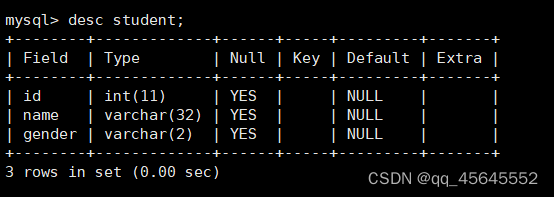
3.2修改表
增加列
alter table 表名 add 列名 类型;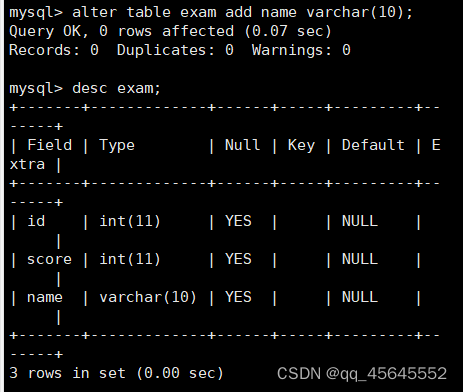
alter table 表名 drop 列名;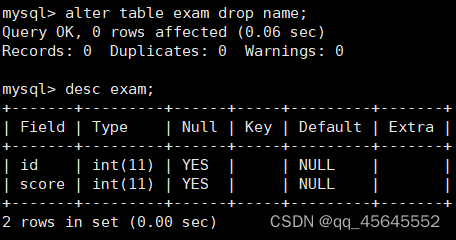
慎用删除列,因为会将列数据全部删除
修改属性(类型)
alter table 表名 modify 列名 列属性alter table 表名 change 列名 新列名 新类型;修改表名
alter table 表名 rename 新名称;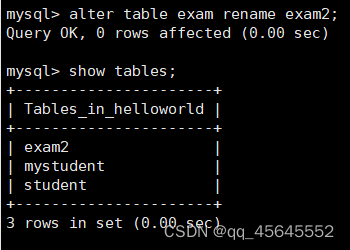
修改列名
alter table 表名 change 列名 新列名 新属性;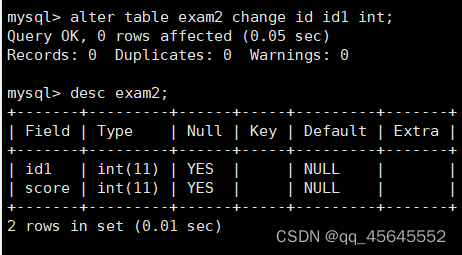
删除表
drop table 表名;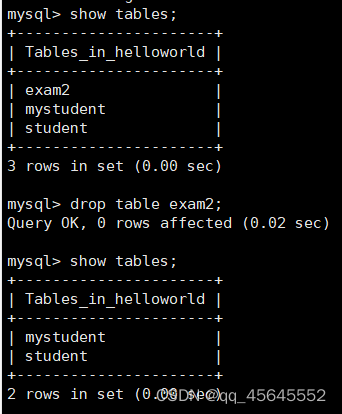
插入数据
insert into 表名 (列名,列名,...) values(值,值,...);不加列名则values中需要给出每个列的对应值
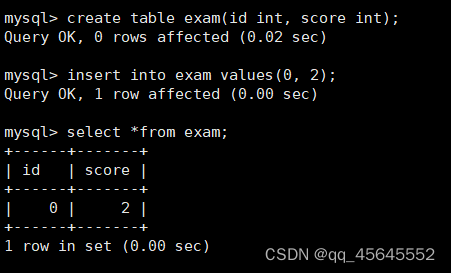
4. 数据类型
4.1数据类型分类
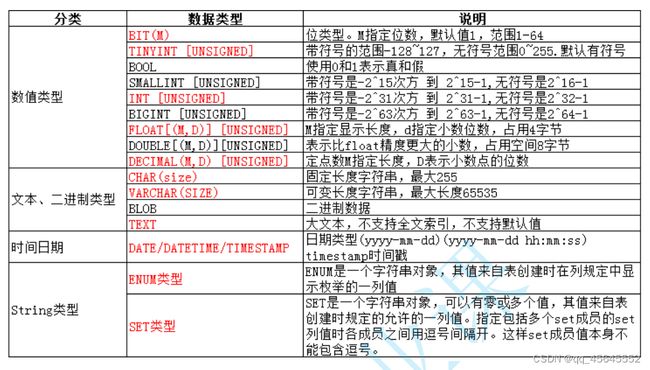
4.1.1bit类型
bit(M):位字段类型,M代表每个值的位数,范围1-64,M默认为1
bit字段在显示时按照ascii码对应值进行显示
4.1.2浮点数类型:
float(M,D)占用4字节,M代表显示位数,D代表小数位数,精度保证6-7位
double(M,D)占用8字节,M代表显示位数,D代表小数位数,精度保证15-16位
decimal(M,D):M代表显示位数,D代表小数位数,理论上精度不会丢失,因为是按照字符串进行保存,但存储时,一定确定存储的小数和D的关系。M最大65,D最大30
eg:decimal(10,2)存入1.123,实际存储1.12
4.1.3字符串类型
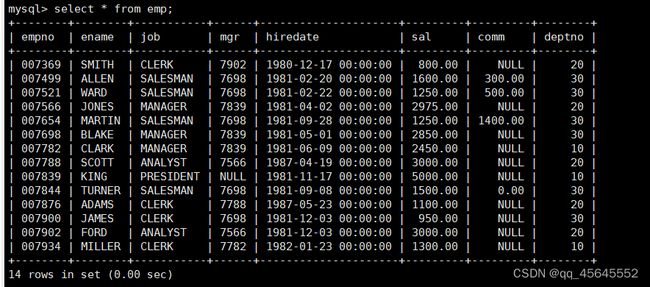
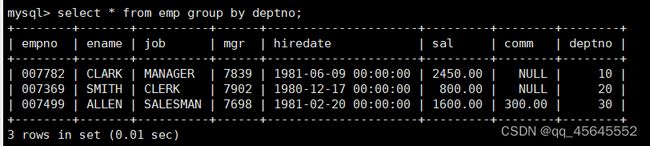
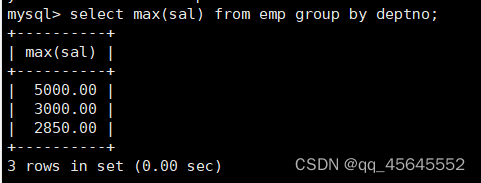
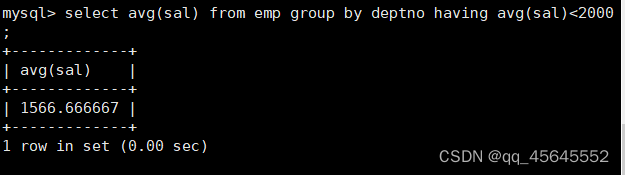
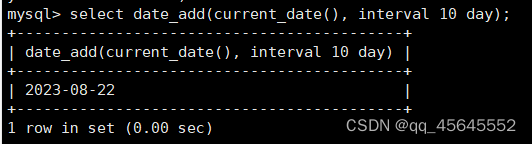
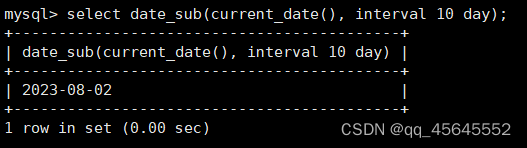
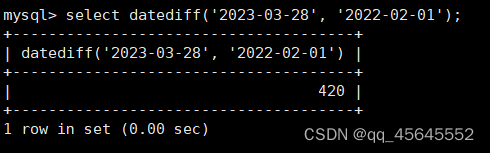
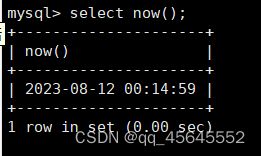
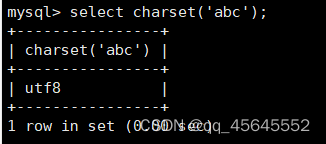
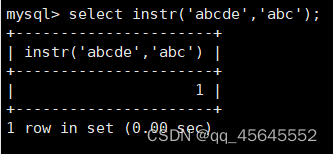
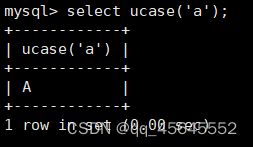
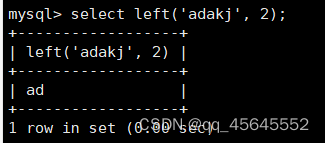
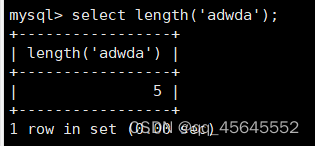
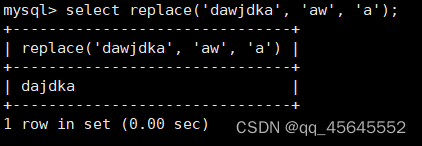
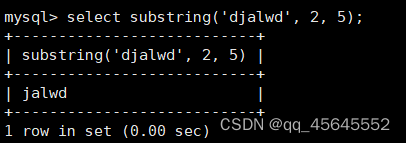
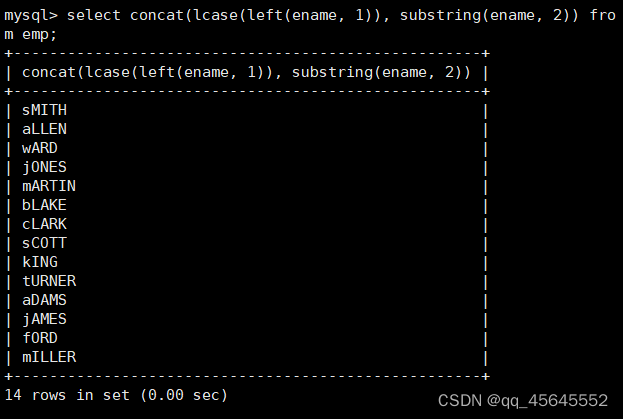
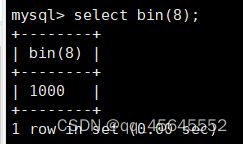
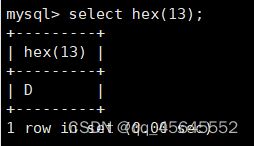
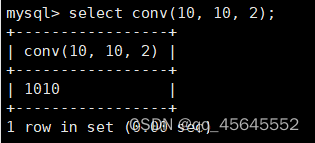
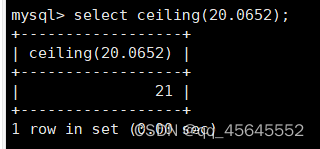
char(size)固定长度字符串:固定长度字符串,size是能够存储的长度,单位为字符,最大长度值可为255.该方法容易造成空间浪费,当存储的字符串长度 varchar(size):可变长度字符串,size代表字符长度,最大长度65535个字节 size最大有多大: 其中有1-3字节用于记录字符串多长,按最大情况算,剩余字节数量65532. 在utf8字符集中,每个字符占用字节数量为1-3字节,按照最大计算,65532/3=21844 char与varchar的比较: varchar占用字节中的“+1”是多了用于存储长度的字节 如何选择定长或变长字符串 若数据确定长度一样,则用定长,如身份证、手机号 若数据长度有变化,用变长,如名字、地址,但要保证最长的能够存储 定长的磁盘空间比较浪费,但效率高 变长的磁盘空间比较节省,但效率低 定长的意义:直接开辟好对应的空间 变长的意义:在不超过自定义范围的情况下,用多少开辟多少 常用日期有三种: date:日期'yyyy-mm-dd',占用3字节 datetime:日期时间格式'yyyy-mm-dd HH:ii:ss'表示范围从1000-9999,占8字节 timestamp:时间戳,从1970年的yyyy-mm-dd HH:ii:ss格式和datetime完全一致,占4字节 enum('选项1','选项2','选项3',...):该设定提供了若干个选项的值,最终一个单元格中,实际只存储其中某一个值,必须是其中的某个值 set('选项值1','选项值2'...):该设定提供了若干个选项的值,最终一个单元格中,可存储其中任意多个值。 find_in_set(sub,str_list)函数:若sub在str_list中,返回其下标,不在则返回0,str-list是用','分割的字符串 使用时前面加上select 表的约束指除了字段类型约束之外的额外约束 null:可以为空 not null 不能为空 默认字段基本都是字段为空 在创建表时,通过对字段定义not null可令其不能为空 default[val] 默认值:某一种数据会经常性的出现某个具体的值,可以在一开始就指定好,在需要真实数据的时候, 用户可以选择性的使用默认值 comment '描述' 对插入、查询没有影响,相当于注释 设置了zerofill的字段会按照设定的宽度进行输出 例如int(5)在输出时会输入5位 约束列字段:primary key 不能为空、不能重复 一张表只有一个主键 主键列通常为整数(方便建立索引) 主键创建方式 (1).创建表时指定 直接在某个字段后指定: 在所有字段后面指定: (2).alter修改表结构 删除主键: 复合主键: 例如:若name列可能重复,class列可能重复,但name与class组合自来的值没有重复,则可以用Name,class作为负荷主键 auto_increment:当对应字段,若不给值,则会自动被系统触发,系统会从当前字段中执行最大值+1操作 任何字段要自增长,前提是本身是个索引(key一栏有值) 自增长字段必须为整数 一张表最多只有一个自增长 一张表往往有多个字段需要唯一性,数据不能重复,但一张表只能有一个主键,因此引入唯一键。 可以解决表中有多个字段需要唯一性约束的问题 唯一键允许为空,可以多个为空,空字段不做唯一性比较 唯一键:unique 外键定义了表与表之间的关系 两个表从逻辑上区分为主表和从表 外键的约束定义在从表上 主表的字段需要为主键 从表定义的外键本质是通过主表的字段约束从表的外键列 外键定义: 当从表中有了外键约束后,在插入时,外键约束列必须是主表字段中的值 如:有物品和购买记录两个表,购买记录中的 物品列必须是物品表中的物品列时,可以将二者用外键约束。其中物品表为主表,购买记录表为从表。 这样做之后若向购买记录表中插入某个物品的记录,会看这个物品是否在主表的物品列中出现,是才会继续插入,否则会报错。 单行全列插入 单行指定列插入 多行全列插入 多行指定列插入 将表中某个数据替换成某个新的值 若主键或唯一键不冲突,则直接插入(有重复元素插入时,会删除之前的后再插入) 若主键或唯一键冲突,则删除后再插入 场景:有大量数据需要更新 其中(指定列)省略时则是全列替换 表当中有多少记录就查询多少记录 *代表的是查询全列,没有where约束是默认查询全表数据 如下 6.5.6结果去重 select distinct .... where查询 >,>=,<,<=:大于,大于等于,小于,小于等于 =:等于,NULL不安全,例如NULL=NULL的结果为NULL <=>:等于,NULL安全,例如NULL<=>NULL的结果为TRUE(1) !=,<>:不等于 BETWEEN a0 AND a1:范围匹配[a0,a1],若a0<=value<=a1,返回TRUE(1) IN(option,...):若是option中任意一个,返回TRUE(1) IS NULL:是NULL IS NOT NULL:不是NULL LIKE:模糊匹配。%代表任意多个字符(包括0个);_代表任意一个字符 AND、OR、NOT eg1:查询英语成绩小于60的同学: eg2:查询语文成绩在80-90之间的同学: eg3:查询数学成绩为58或59或98或99的同学 eg4:查询姓孙的同学 如果只想要“孙某” eg5:查询语文成绩好于英语的同学 eg6:查询总分在200以下的同学 eg7:查询语文成绩>80且不姓孙的同学 eg8:要么为孙某同学,要么总成绩>200 且语文成绩<数学成绩且英语>80 order by [字段名称(不用加引号)] asc/desc:查询结果按照某个字段的值进行排序,asc代表升序,desc为降序,默认升序。 空比任何值都小 NULL比任何值都小 若有如下语句: 则会先根据math进行降序,其中相同的math行的english会升序,相同math与english行的chinese会升序 按总分排序: 其中,t_s为总分的别名 注:order by中可以用别名,where中不可 数据量过大时,可令其分页显示 下标从0开始 limit n;添加后令其输出n条 limit start, n;从start开始输出n条 limit n offset start;从start开始输出n条 没有where则会更新所有行对应的列 eg: 该语句会经所有math改为100 找出所有姓孙的人,将其数学改为100. 删除数据之后,自增不会重置 直接将表数据全部删除,并重置表结构,当用delete删除数据后,自增不会重置,而经过截断之后则可以重新从1开始自增 注: 截断只对整表操作,不能向delete针对部分数据操作 当truncate在删除数据时,不经过真正的事务,因此无法回滚 其会重置AUTO_INCREMENT项 返回查询到的数据数量 返回查询的数据总和,不是数字没有意义 查询exam表中math的最大值 返回查询数据的平局值 返回最大值 返回最小值 在select 中使用group by 子句可以指定列进行分组查询 准备好雇员信息表(oracle 9i的经典测试表) 显示每个部门的平均工资与最高工资 group by 配合聚合函数进行分组查询 group by 配合having 进行分组过滤 注: 在使用group by 时遇到了报错: 解决方法: mysql中执行: mysql> set global sql_mode=‘STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION’; mysql> set session sql_mode=‘STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION’; 找出每个部门的工资最大值 : 找平均工资小于2000的部门 groupby 后可以用having进行分组过滤 current_date()当前日期 current_time()当前时间 current_timestamp()当前时间戳 date(datetime)返回datetime参数的日期部分 date_add(date,interval d_value_type)在date中添加日期或时间,interval后的数值单位可以是day date_sub(date, interval d_value_type)在date中减去日期或时间 datediff(date1,date2):两个日期的差,单位为天 now():当前日期时间 charset(set)返回字符串字符集 concat(以','分割的字符)连接字符串 instr(str, sub):返回sub在str中出现的位置,没有则为0,下标从1开始 ucase('')小写转大写 lcase('')大写转小写 left(str, n):从str左边开始取n个字符 length(str):求str长度 replace(str, search, des):将str中的search替换为des strcmp(str1, str2):比较两个字符串大小 substring (str, pos, [length]):从str的pos开始取length个字符 不添加length则取后续所有字符 eg:让emp表中ename的首字母小写: abs(n):取绝对值 bin(decimal_number)十进制转二进制 hex(n)转16进制 conv(n, from_base, to_base)进制转换 10从10进制转2进制 ceiling(n)向上取整 floor(n):向下取整 format(n, 小数位数):将n保留几位 rand()返回随机浮点数,范围[0, 1] mod(n, d):求模,取余 user()查询当前用户(mysql的用户,而非linux用户) database()显示正在使用的数据库 password()进行加密,密码强度有要求,mysql数据库使用该函数对用户进行加密 isnull(值1, 值2):判断值1是否为空,否则返回值2 实际开发中数据来自不同表,需要多表查询 案例:显示雇员名、雇员工资以及所在部门的名字,以上数据来自两个表:emp与dept,需要联合查询 emp: dept: 由于部门名字在dname中(dname),因此需要联合查询 当采用如下语句查询时会产生笛卡尔集 结果如下,会令每个雇员与每个部门进行结合,一共产生14*4=56个结果 而每个员工只可能有一个部门,所以必定有三个是不正确的,因此,对该结果还需要用where语句进行约束 由于只需要雇员名、工资以及部门名,因此最终语句为: 自连接指在同一张表连接查询 案例:显示员工ford的上级编号mgr和其对应的名字ename 需要先找到上级编号mgr,然后用mgr重新在表中找empno=mgr的人就是领导 自连接方式寻找上级: 该方法将两个相同的emp组成笛卡尔集,有14*14条记录 会让emp l中的每个记录与emp w中的每个记录形成组合,因此有14*14条记录 此时可以将l看做领导,w看做下级,则约束就是w.mgr=l.empno(即w的上级编号和领导的编号一致) 题目要求获取FORD的上级,最后结果如下: 子查询方法: 子查询的值为单行单列 eg: 子查询的值为多行单列 in: eg:找到与部门10工作岗位相同的雇员名、工资、编号 此处,子查询为一个多行单列的查询,会将编号为10的岗位显示出来 all:全部 eg:显示工资比部门30的所有员工的工资高的员工姓名 any:任意一个 eg:显示工资比30部门任意员工工资高的员工姓名、工资以及部门号包括自己部门 eg:查询与smith的部门与岗位完全相同的所有雇员,不含smith smith的部门与岗位的查询为一个单行多列的结果 此时用(列名)=子查询即可 即将子查询当做临时表使用 eg:显示每个高于自己部门平均工资的员工姓名、部门、工资、平均工资 子查询为select deptno dep, avg(sal) a_s from emp group by deptno;即每个部门的编号以及平局工资 将这个查询结果同tmp组成一个笛卡尔集,要保证tmp编号和emp的部门编号相同 且tmp.a_s(平均工资) 从中查询出ename、deptno、sal、a_s即可 union与union all 该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行(union),若不希望去重则使用union all。 eg:查找工资高于2500的或岗位为MANAGER的所有人 union: union all: 结果仅包含符合连接条件的两表中的行 实际是用where子句对两个表形成的笛卡尔集进行筛选 多表查询其实就是内连接 eg:显示smith的名字和部门名称 多表查询: 标准内连接写法: eg: 建立下表: 如下两张表: 要求查询姓名和考试成绩,若没有这个同学的成绩,也需要输出这个同学 eg:查询所有考试成绩,无论有无学生,必须展示所有成绩 可用于update语句中: #include 编译时需要链接库:-lmysqlclient 且需要指定位置:-L /usr/lib64/mysql
4.1.4日期和时间类型
4.1.5枚举类型
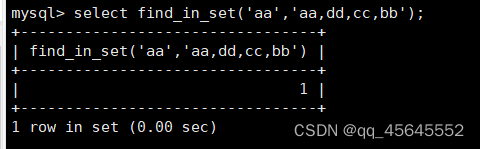
4.1.6集合类型

4.1.7集合查询
5.表的约束
5.1空属性
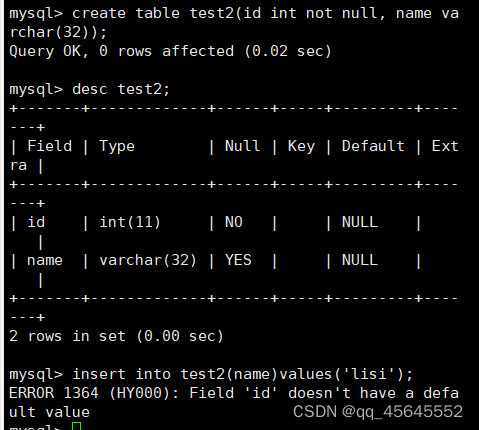
5.2默认值
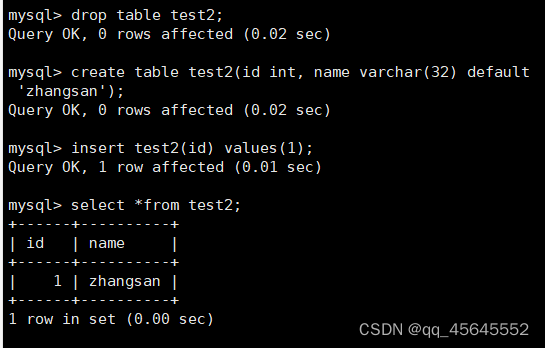
5.3列描述
5.4zerofill格式化输出
5.5主键
create table 表名(字段1 字段1类型 primary key,...);create table 表名(字段1 字段1类型,字段2 字段2类型...., primary key(字段名称));alter table 表名 add primary key 列名;alter table 表名 drop primary key;
当表中的字段值有重复可能时,若还想创立主键,可用多个列建立复合主键,复合主键的列的值,在表当中唯一。create table 表名(字段1,字段1类型, 字段2 字段2类型, 字段3....,primary key(字段1名称,字段2名称));5.6自增长
5.7唯一键
5.8外键
foreign key 字段名 references 主表列;放在从表insert into 表名(列名1, 列名2,...)values(列名1对应的值,列名2对应的值,...);6.基础查询(单表)
6.1创建表
create table 表名(列名1 列类型 [列约束], ...);6.2单行插入
insert into 表名 values(第一列的值,....);insert into 表名(列名1,列名2,...) values(列名1对应值, 列名2对应值,...);6.3多行插入
insert into goods values(所有的值1),(所有的值2)...;insert into goods(列名1,列名2) values(指定列的值1),(指定列的值2)...;6.4替换
replace into 表名 (指定列) values (指定列新的值);6.5查询
6.5.1全表查询
select * from 表名;6.5.2全列查询
select * from 表名;6.5.3指定列查询
select 列名1,列名2... from 表名;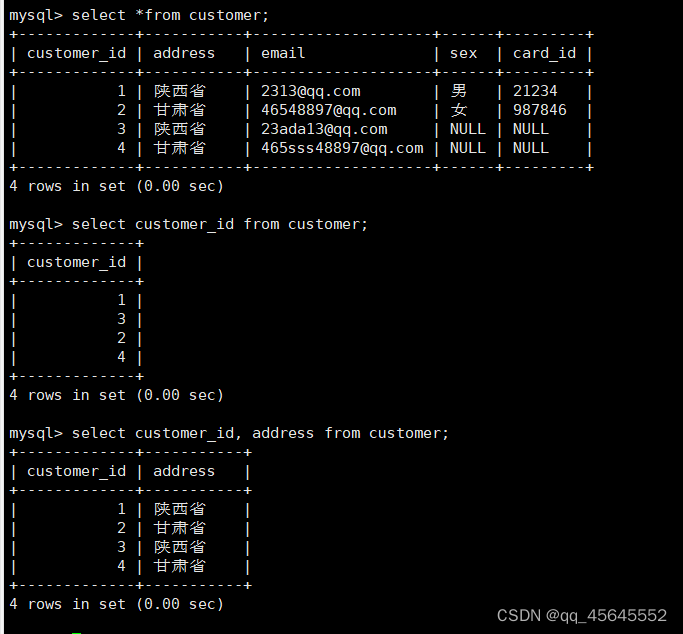
6.5.4查询字段为表达式
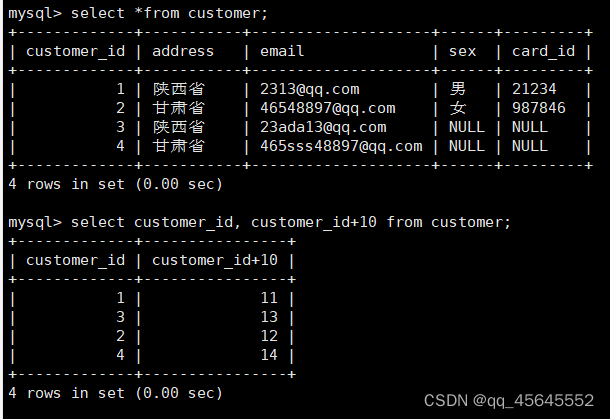
6.5.5查询结果重命名
select customer_id, customer_id+10 结果 from customer;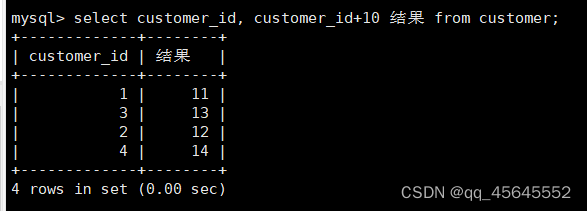

6.6指定行查询
6.6.1比较运算符
6.6.2逻辑运算符
select name, english from exam where english < 60;select name, chinese from exam where chinese >= 80 and chinese<=90;select name, chinese from exam where chinese between 80 and 90;select name, math from exam where math=58 or math=59 or math=98 or math=99;select name, math from exam where math in (58,59,98,99);select name from exam where name like '孙%';select name from exam where name like '孙_';select name, chinese, english from exam where chinese > english;select name, chinese+math+english from exam where chinese+math+english<200;select name, chinese from exam where chinese>80 and name not like '孙%';select * from exam where (name like '孙_') or (chinese+math+english>200 and chinese < math and english>80);6.7结果排序
select name, math, english, chinese from exam order by math desc, english, chinese;select name, chinese+math+english t_s from exam order by t_s;6.8筛选分页结果
6.9更新表
update 表名 set [字段]=[新的值] where [筛选条件];update exam set math=100update exam set math=100 where name like '孙%';6.10删除数据
delete from 表名 where 筛选条件6.11截断表
truncate table 表名6.12聚合函数
6.12.1count
select count(*) from exam;6.12.2sum
select max(math) from exam;6.12.3avg
6.12.4max
6.12.5min
6.13分组查询
select 列1,列2,... from 表名 group by 列名;ERROR 1055 (42000): Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'scott.emp.empno' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
7.内置函数
7.1日期函数

7.2字符串



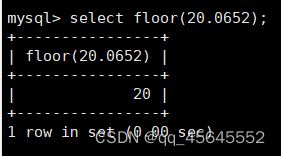
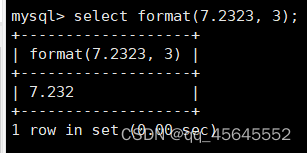
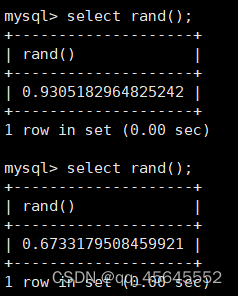
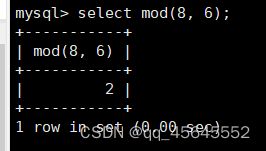
7.3数学函数
7.4其他函数
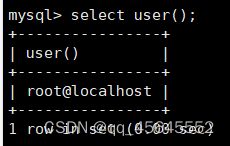
8.复合查询
8.1多表查询
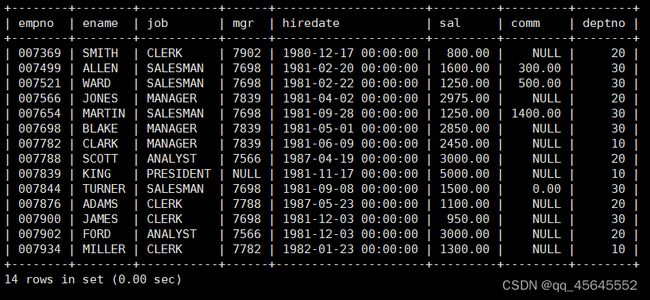
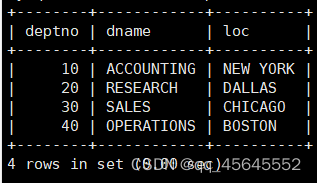
select *from emp, dept;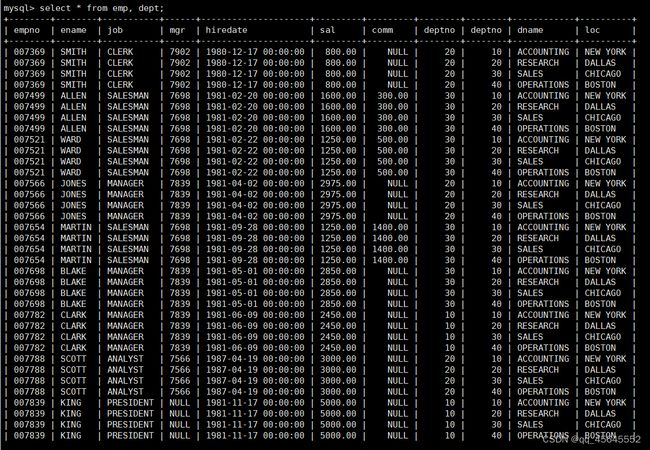
select *from emp, dept where emp.deptno = dept.deptno;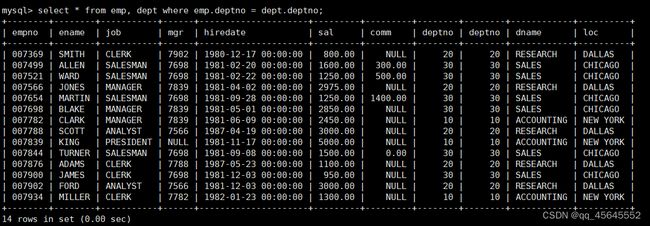
select ename, sal, dname from emp, dept where emp.deptno = dept.deptno;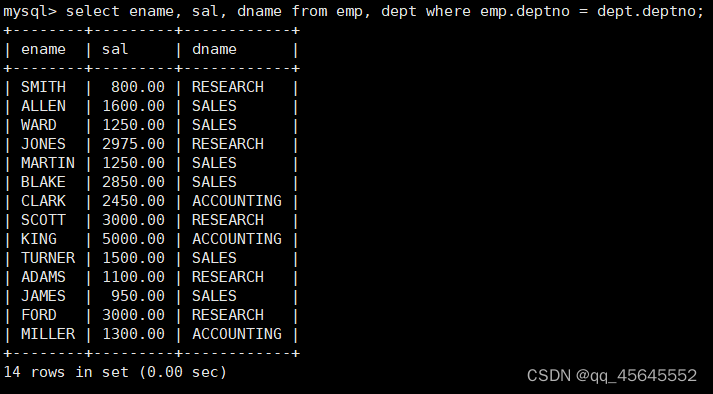
8.2自连接
select l.ename, l.empno from emp l, emp w where w.mgr = l.empno;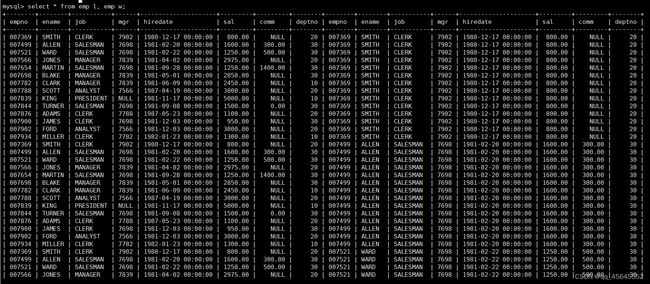
select l.ename, l.empno from emp l, emp w where w.mgr = l.empno and w.ename='FORD';

8.3子查询
8.3.1单行单列子查询
8.3.2多行单列子查询
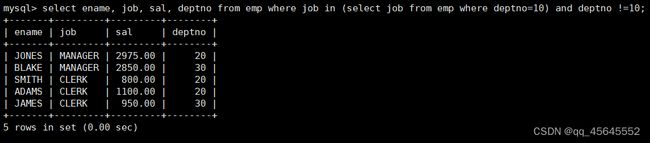
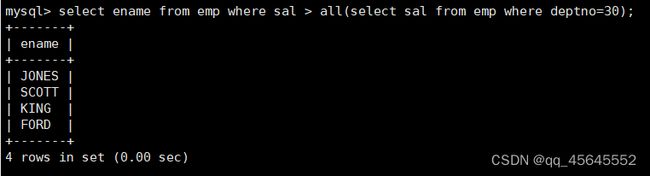
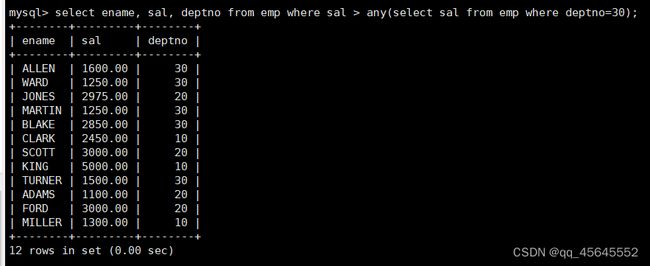
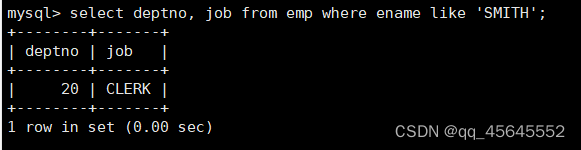
8.3.3单行多列子查询

8.3.4在from中使用子查询

8.4合并查询
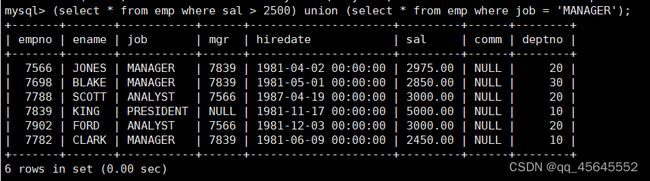
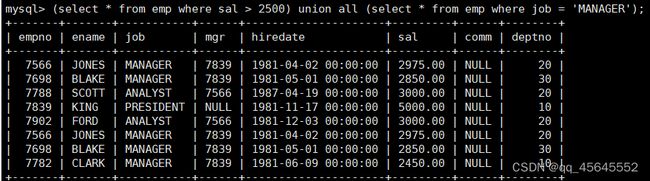
9.内外连接
9.1内连接
select 字段 from 表1 inner join 表2 on 连接条件 and 其他条件;

9.2外连接
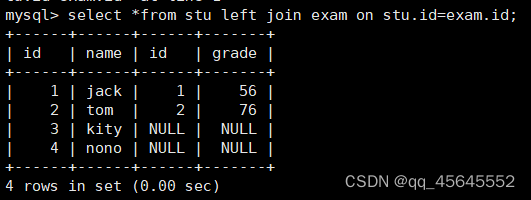
9.2.1左外连接
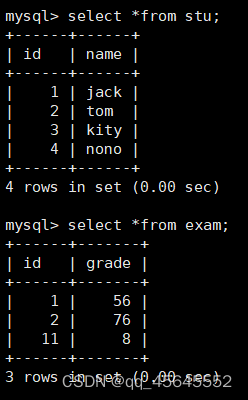
select 字段名 from 表1 left join 表2 on 连接条件;create table stu (id int, name varchar(30)); -- 学生表
insert into stu values(1,'jack'),(2,'tom'),(3,'kity'),(4,'nono');
create table exam (id int, grade int); -- 成绩表
insert into exam values(1, 56),(2,76),(11, 8);
9.2.2右外连接
select 字段 from 表1 right join 表2 on 连接条件;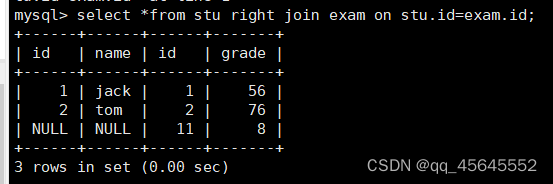
10.附加内容
10.1判断语句
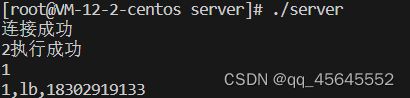
if(表达式, 成立时的值,不成立时的值);10.2程序中使用Mysql
初始化操作句柄
MYSQL *mysql_init(MYSQL *mysql)连接mysql服务端
mysql_real_connect(
MYSQL *mysql,//操作句柄
const char *host,//服务端ip
const char *user,//用户名
const char *passwd,//密码
const char *db,//数据库
unsigned int port,//端口
const char *unix_socket,//是否使用本地域套接字
unsigned long client_flag//数据库标志位,通常为0,采用默认属性
)
连接mysql服务端,若成功,返回mysql操作句柄,失败返回NULL#include![]()
#include