车牌检测与识别:License plate detection and recognition (LPDR)
开始搞车牌的检测与识别,想边做便记录下来。
首先,我找的数据集是中科大的CCPD(Chinese City Parking Dataset)。
github
数据集对比(图片来源于作者论文)

CCPD layout (图片来源于作者论文)
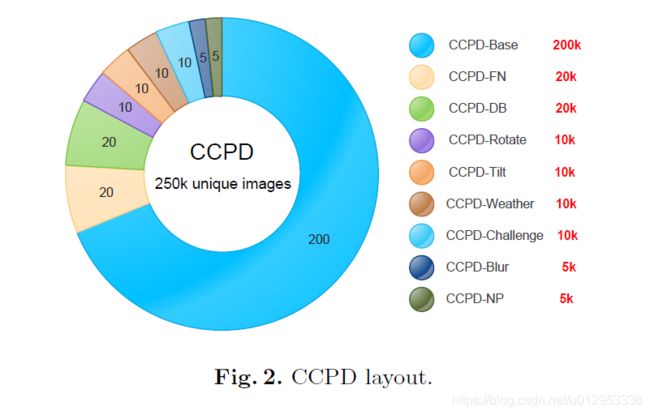
之前找了好几个数据集,感觉这个数据集是最全最大的。下载位置都在GitHub仓库中作者有给链接。
它的标签就是图片名。

项目clone下来,就遇到了第一个错误:

原因是:pytorch的版本问题。
解决方案:
在roi_pooling.py 文件中第18行把 type(input) 修改为input.type() 就可以解决。
第二个错误:

又是pytorch版本问题,修改位置如下:

解决方案:
wR2.py文件213行的:lossAver.append(loss.data[0]) 修改为:lossAver.append(loss.item())
作者给的github的代码,跑出来的结果是没有打印车牌第一个汉字,如图:

这样就感觉不是特别好,于是想办法把它打印出来,解决方案是修改一下demo.py文件:
import cv2
from PIL import ImageFont, ImageDraw, Image #导入相关包
...
provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂",
"琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"]
alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W',
'X', 'Y', 'Z', 'O']
ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X',
'Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']
...
font = '/usr/share/fonts/truetype/droid/DroidSansFallbackFull.ttf' #字体路径
font = ImageFont.truetype(fontpath, 32) #设置字体
for i, (XI, ims) in enumerate(trainloader):
if use_gpu:
x = Variable(XI.cuda(0))
else:
x = Variable(XI)
# Forward pass: Compute predicted y by passing x to the model
fps_pred, y_pred = model_conv(x)
outputY = [el.data.cpu().numpy().tolist() for el in y_pred]
labelPred = [t[0].index(max(t[0])) for t in outputY]
[cx, cy, w, h] = fps_pred.data.cpu().numpy()[0].tolist()
img = cv2.imread(ims[0])
left_up = [(cx - w/2)*img.shape[1], (cy - h/2)*img.shape[0]]
right_down = [(cx + w/2)*img.shape[1], (cy + h/2)*img.shape[0]]
cv2.rectangle(img, (int(left_up[0]), int(left_up[1])), (int(right_down[0]), int(right_down[1])), (0, 0, 255), 2)
#lpn = alphabets[labelPred[1]] + ads[labelPred[2]] + ads[labelPred[3]] + ads[labelPred[4]] + ads[labelPred[5]] + ads[labelPred[6]]
#lpn中加入省份的字符
lpn = provinces[labelPred[0]] + alphabets[labelPred[1]] + ads[labelPred[2]] + ads[labelPred[3]] + ads[labelPred[4]] + ads[labelPred[5]] + ads[labelPred[6]]
#cv2.putText(img, lpn, (int(left_up[0]), int(left_up[1])-20), cv2.FONT_ITALIC, 2, (0, 0, 255))
#绘制文字信息
draw.text((int(left_up[0]), int(left_up[1])-20), lpn, font = font, fill = (0, 255, 0))
cv2.imwrite(ims[0], img)
运行效果:

自己训练出来的效果图:
