【Linux】Docker入门
文章目录
- Docker 入门篇
- 一、初始容器
-
- 1.Docker 的安装
-
- 1.1 启动容器
- 1.2 验证容器是否安装成功
- 2.Docker 的使用
-
- 2.1 查看容器
- 2.2 拉取镜像
- 2.3 查看镜像
- 2.4 运行容器
- 3.Docker 的架构
- 4.小结
- 二、容器的本质
-
- 1.容器到底是什么
- 2.为什么要隔离
- 3.与虚拟机的区别是什么
- 4.隔离是怎么实现的
- 5.小结
- 三、容器化的应用:会了这些你就是Docker高手
-
- 1.什么是容器化的应用
- 2.常用的镜像操作有哪些
-
- 2.1 使用名字和 IMAGE ID 来删除镜像:
- 3.常用的容器操作有哪些
- 4.小结
- 四、创建容器镜像:如何编写正确、高效的Dockerfile
-
- 1.镜像的内部机制是什么
- 2.Dockerfile 是什么
- 3.怎样编写正确、高效的 Dockerfile
- 4.docker build 是怎么工作的
- 5.小结
- 五、镜像仓库: Dokcer Hub
-
- 1.什么是镜像仓库(Registry)
- 2.什么是 Docker Hub
- 3.如何在 Docker Hub 上挑选镜像
- 4.Docker Hub 上镜像命名的规则是什么
- 5.该怎么上传自己的镜像
- 6.离线环境该怎么办
- 7.小结
- 六、容器该如何与外界互联互通
-
- 1.如何拷贝容器内的数据
- 2.如何共享主机上的文件
- 3.如何实现网络互通
- 4.如何分配服务端口号
- 5.小结
- 七、玩转Docker
-
- 1.容器技术要点回顾
- 2. 搭建私有镜像仓库
- 3.搭建 WordPress 网站
- 4.小结
Docker 入门篇
简介:Docker是一个开源的引擎,可以轻松的为任何应用创建一个轻量级的、可移植的、自给自足的容器。开发者在笔记本上编译测试通过的容器可以批量地在生产环境中部署,包括VMs(虚拟机)、bare metal、OpenStack 集群和其他的基础应用平台。
容器是一种沙盒技术。那什么是沙盒呢?沙盒就像一个装着小猫的纸箱,把小猫“放”进去的技术。不同的小猫之间,因为有了纸箱的边界,而不至于互相干扰,纸箱 A 中吃饭的小猫并不会打扰到纸箱 B 中睡觉的小猫;而被装进纸箱的小猫,也可以方便地搬来搬去,你不用再去找它躲在哪里了!
一、初始容器
注意: 这里使用的系统是ubuntu
1.Docker 的安装
注意:可以先运行docker version 看命令是否存在,不存在可以执行以下命令进行安装
#安装Docker Engine
sudo apt install docker.io
1.1 启动容器
root@template:/# systemctl start docker
注意: 如果注重安全,可以使用普通用户进行操作,但必须做以下操作
sudo systemctl start docker #启动docker服务
sudo usermod -aG docker ${USER} #当前用户加入docker组
第一个 systemctl start docker 是启动 Docker 的后台服务,第二个 usermod -aG 是把当前的用户加入 Docker 的用户组。这是因为操作 Docker 必须要有 root 权限,而直接使用 root 用户不够安全,加入 Docker 用户组是一个比较好的选择,这也是 Docker 官方推荐的做法。当然,如果只是为了图省事,你也可以直接切换到 root 用户来操作 Docker。上面的三条命令执行完之后,我们还需要退出系统(命令 exit ),再重新登录一次,这样才能让修改用户组的命令 usermod 生效。
1.2 验证容器是否安装成功
验证 Docker 是否安装成功了,使用的命令是 docker version 和 docker info。
# docker version 会输出 Docker 客户端和服务器各自的版本信息:
root@template:/# docker version
Client:
Version: 20.10.21
API version: 1.41
Go version: go1.18.1
Git commit: 20.10.21-0ubuntu1~20.04.1
Built: Thu Jan 26 21:14:47 2023
OS/Arch: linux/amd64
Context: default
Experimental: true
Server:
Engine:
Version: 20.10.21
API version: 1.41 (minimum version 1.12)
Go version: go1.18.1
Git commit: 20.10.21-0ubuntu1~20.04.1
Built: Thu Nov 17 20:19:30 2022
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.6.12-0ubuntu1~20.04.1
GitCommit:
runc:
Version: 1.1.4-0ubuntu1~20.04.1
GitCommit:
docker-init:
Version: 0.19.0
GitCommit:
docker info 会显示当前 Docker 系统相关的信息,例如 CPU、内存、容器数量、镜像数量、容器运行时、存储文件系统等等,这里我也摘录了一部分:
root@template:/# docker info
Client:
Context: default
Debug Mode: false
Server:
Containers: 11
Running: 8
Paused: 0
Stopped: 3
Images: 13
Server Version: 20.10.21
Storage Driver: overlay2
Backing Filesystem: xfs
Supports d_type: true
Native Overlay Diff: true
userxattr: false
Logging Driver: json-file
Cgroup Driver: cgroupfs
Cgroup Version: 1
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog
Swarm: inactive
Runtimes: io.containerd.runtime.v1.linux runc io.containerd.runc.v2
Default Runtime: runc
Init Binary: docker-init
containerd version:
runc version:
init version:
Security Options:
apparmor
seccomp
Profile: default
Kernel Version: 5.4.0-144-generic
Operating System: Ubuntu 20.04.5 LTS
OSType: linux
Architecture: x86_64
CPUs: 2
Total Memory: 3.84GiB
Name: template
ID: 4LG5:PQRN:HJXS:4RJK:ROM5:JEL4:NVZI:FYWW:ZKPR:AOKA:4FU4:QIRP
Docker Root Dir: /var/lib/docker
Debug Mode: false
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
127.0.0.0/8
Registry Mirrors:
https://reg-mirror.qiniu.com/
Live Restore Enabled: false
WARNING: No swap limit support
2.Docker 的使用
现在,我们已经有了可用的 Docker 运行环境,可以做一些操作了
首先,我们使用命令 docker ps,它会列出当前系统里运行的容器,就像我们在 Linux 系统里使用 ps 命令列出运行的进程一样。
2.1 查看容器
root@template:/# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
注意: 所有的 Docker 操作都是这种形式:以 docker 开始,然后是一个具体的子命令,之前的 docker version 和 docker info 也遵循了这样的规则。你还可以用 help 或者 --help 来获取帮助信息,查看命令清单和更详细的说明。
我们尝试另一个非常重要的命令 docker pull ,从外部的镜像仓库(Registry)拉取一个 busybox 镜像(image),你可以把它类比成是 Ubuntu 里的“apt install”下载软件包:
2.2 拉取镜像
docker pull busybox #拉取busybox镜像
root@template:/# docker pull busybox
Using default tag: latest
latest: Pulling from library/busybox
Digest: sha256:c118f538365369207c12e5794c3cbfb7b042d950af590ae6c287ede74f29b7d4
Status: Downloaded newer image for busybox:latest
docker.io/library/busybox:latest
2.3 查看镜像
我们再执行命令 docker images ,它会列出当前 Docker 所存储(本地)的所有镜像:可以看到,命令会显示有一个叫 busybox 的镜像,镜像的 ID 号是一串 16 进制数字,大小是 1.41MB。
root@template:/# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
busybox latest 2bc7edbc3cf2 4 weeks ago 1.4MB
2.4 运行容器
现在,我们就要从这个镜像启动容器了,命令是 docker run ,执行 echo 输出字符串
root@template:/# docker run busybox echo hello world
hello world
root@template:/#
然后我们再用 docker ps 命令,加上一个参数 -a ,就可以看到这个已经运行完毕的容器:
root@template:/# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3fe3b3d75f72 busybox "echo hello world" 35 seconds ago Exited (0) 34 seconds ago nifty_brown
3.Docker 的架构
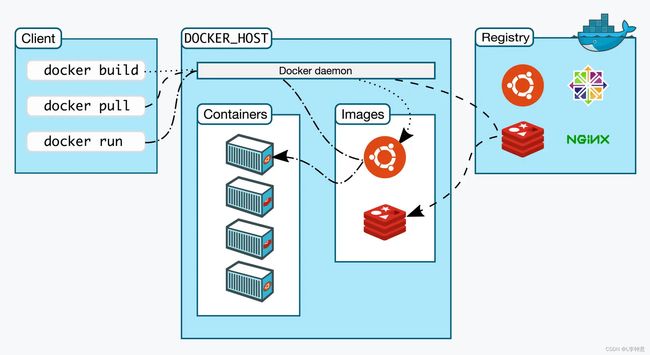
这张图精准地描述了 Docker Engine 的内部角色和工作流程,对学习研究非常有指导意义。

刚才敲的命令行 docker 实际上是一个客户端 client ,它会与 Docker Engine 里的后台服务 Docker daemon 通信,而镜像则存储在远端的仓库 Registry 里,客户端并不能直接访问镜像仓库。Docker client 可以通过 build、pull、run等命令向 Docker daemon 发送请求,而 Docker daemon 则是容器和镜像的“大管家”,负责从远端拉取镜像、在本地存储镜像,还有从镜像生成容器、管理容器等所有功能。所以,在 Docker Engine 里,真正干活的其实是默默运行在后台的 Docker daemon,而我们实际操作的命令行工具“docker”只是个“传声筒”的角色。
Docker 官方还提供一个“hello-world”示例,可以为你展示 Docker client 到 Docker daemon 再到 Registry 的详细工作流程,你只需要执行这样一个命令:
docker run hello-world
root@template:/# docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
2db29710123e: Pull complete
Digest: sha256:6e8b6f026e0b9c419ea0fd02d3905dd0952ad1feea67543f525c73a0a790fefb
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
4.小结
- 容器技术起源于 Docker,它目前有两个产品:Docker Desktop 和 Docker Engine,我们的课程里推荐使用免费的 Docker Engine,它可以在 Ubuntu 系统里直接用 apt 命令安装。
- Docker Engine 需要使用命令行操作,主命令是 docker,后面再接各种子命令。
- 查看 Docker 的基本信息的命令是 docker version 和 docker info ,其他常用的命令有 docker ps、docker pull、docker images、docker run。
- Docker Engine 是典型的客户端 / 服务器(C/S)架构,命令行工具 Docker 直接面对用户,后面的 Docker daemon 和 Registry 协作完成各种功能。
二、容器的本质
广义上来说,容器技术是动态的容器、静态的镜像和远端的仓库这三者的组合。不过,“容器”这个术语作为容器技术里的核心概念,不仅是大多数初次接触这个领域的人,即使是一些已经有使用经验的人,想要准确地把握它们的内涵、本质都是比较困难的。
1.容器到底是什么
从字面上来看,容器就是 Container,一般把它形象地比喻成现实世界里的集装箱,它也正好和 Docker 的现实含义相对应,因为码头工人(那只可爱的小鲸鱼)就是不停地在搬运集装箱。

集装箱的作用是标准化封装各种货物,一旦打包完成之后,就可以从一个地方迁移到任意的其他地方。相比散装形式而言,集装箱隔离了箱内箱外两个世界,保持了货物的原始形态,避免了内外部相互干扰,极大地简化了商品的存储、运输、管理等工作。再回到我们的计算机世界,容器也发挥着同样的作用,不过它封装的货物是运行中的应用程序,也就是进程,同样它也会把进程与外界隔离开,让进程与外部系统互不影响。
我们还是来实际操作一下吧,来看看在容器里运行的进程是个什么样子。
使用 docker pull 命令,拉取一个新的镜像——操作系统 Alpine:
docker pull alpine
使用 docker run 命令运行它的 Shell 程序:
docker run -it alpine sh
注意我们在这里多加了一个 -it 参数,这样我们就会暂时离开当前的 Ubuntu 操作系统,进入容器内部。
执行 cat /etc/os-release ,还有 ps 这两个命令,最后再使用 exit 退出,看看容器里与容器外有什么不同:
root@template:/# docker run -it alpine sh
/ #
/ # cat /etc/os-release
NAME="Alpine Linux"
ID=alpine
VERSION_ID=3.17.2
PRETTY_NAME="Alpine Linux v3.17"
HOME_URL="https://alpinelinux.org/"
BUG_REPORT_URL="https://gitlab.alpinelinux.org/alpine/aports/-/issues"
/ #
/ # ps -ef
PID USER TIME COMMAND
1 root 0:00 sh
7 root 0:00 ps -ef
/ # exit
就像这里所显示的,在容器里查看系统信息,会发现已经不再是外面的 Ubuntu 系统了,而是变成了 Alpine Linux 3.15,使用 ps 命令也只会看到一个完全“干净”的运行环境,除了 Shell(即 sh)没有其他的进程存在。也就是说,在容器内部是一个全新的 Alpine 操作系统,在这里运行的应用程序完全看不到外面的 Ubuntu 系统,两个系统被互相“隔离”了,就像是一个“世外桃源”。
我们可以在这个“世外桃源”做任意的事情,比如安装应用、运行 Redis 服务等。但无论我们在容器里做什么,都不会影响外面的 Ubuntu 系统(当然不是绝对的)。
到这里,我们就可以得到一个初步的结论:容器,就是一个特殊的隔离环境,它能够让进程只看到这个环境里的有限信息,不能对外界环境施加影响。
那么,很自然地,我们会产生另外一个问题:为什么需要创建这样的一个隔离环境,直接让进程在系统里运行不好吗?
2.为什么要隔离
相信因为这两年疫情,你对“隔离”这个词不会感觉到太陌生。为了防止疫情蔓延,我们需要建立方舱、定点医院,把患病人群控制在特定的区域内,更进一步还会实施封闭小区、关停商场等行动。虽然这些措施带来了一些不便,但都是为了整个社会更大范围的正常运转。
同样的,在计算机世界里的隔离也是出于同样的考虑,也就是系统安全。
对于 Linux 操作系统来说,一个不受任何限制的应用程序是十分危险的。这个进程能够看到系统里所有的文件、所有的进程、所有的网络流量,访问内存里的任何数据,那么恶意程序很容易就会把系统搞瘫痪,正常程序也可能会因为无意的 Bug 导致信息泄漏或者其他安全事故。虽然 Linux 提供了用户权限控制,能够限制进程只访问某些资源,但这个机制还是比较薄弱的,和真正的“隔离”需求相差得很远。
而现在,使用容器技术,我们就可以让应用程序运行在一个有严密防护的“沙盒”(Sandbox)环境之内,就好像是把进程请进了“隔离酒店”,它可以在这个环境里自由活动,但绝不允许“越界”,从而保证了容器外系统的安全。
另外,在计算机里有各种各样的资源,CPU、内存、硬盘、网卡,虽然目前的高性能服务器都是几十核 CPU、上百 GB 的内存、数 TB 的硬盘、万兆网卡,但这些资源终究是有限的,而且考虑到成本,也不允许某个应用程序无限制地占用。
容器技术的另一个本领就是为应用程序加上资源隔离,在系统里切分出一部分资源,让它只能使用指定的配额,比如只能使用一个 CPU,只能使用 1GB 内存等等,就好像在隔离酒店里保证一日三餐,但想要吃山珍海味那是不行的。这样就可以避免容器内进程的过度系统消耗,充分利用计算机硬件,让有限的资源能够提供稳定可靠的服务。所以,虽然进程被“关”在了容器里,损失了一些自由,但却保证了整个系统的安全。而且只要进程遵守隔离规定,不做什么出格的事情,也完全是可以正常运行的。
3.与虚拟机的区别是什么
你也许会说,这么看来,容器不过就是常见的“沙盒”技术中的一种,和虚拟机差不了多少,那么它与虚拟机的区别在哪里呢?又有什么样的优势呢?在我看来,其实容器和虚拟机面对的都是相同的问题,使用的也都是虚拟化技术,只是所在的层次不同,可以参考 Docker 官网上的两张图,把这两者对比起来会更利于学习理解。
Docker 官网的图示其实并不太准确,容器并不直接运行在 Docker 上,Docker 只是辅助建立隔离环境,让容器基于 Linux 操作系统运行
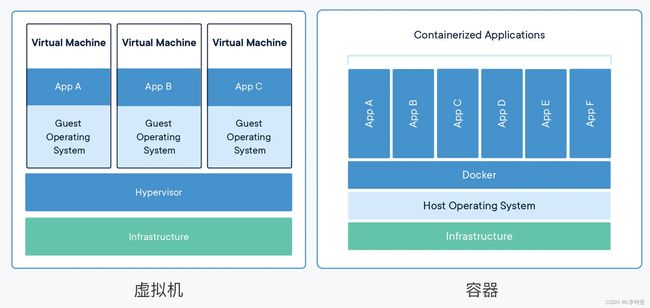
首先,容器和虚拟机的目的都是隔离资源,保证系统安全,然后是尽量提高资源的利用率。
VMware等虚拟化软件 创建虚拟机的时候,,它们能够在宿主机系统里完整虚拟化出一套计算机硬件,在里面还能够安装任意的操作系统,这内外两个系统也同样是完全隔离,互不干扰。
而在数据中心的服务器上,虚拟机软件(即图中的 Hypervisor)同样可以把一台物理服务器虚拟成多台逻辑服务器,这些逻辑服务器彼此独立,可以按需分隔物理服务器的资源,为不同的用户所使用。
从实现的角度来看,虚拟机虚拟化出来的是硬件,需要在上面再安装一个操作系统后才能够运行应用程序,而硬件虚拟化和操作系统都比较“重”,会消耗大量的 CPU、内存、硬盘等系统资源,但这些消耗其实并没有带来什么价值,属于“重复劳动”和“无用功”,不过好处就是隔离程度非常高,每个虚拟机之间可以做到完全无干扰。
我们再来看容器(即图中的 Docker),它直接利用了下层的计算机硬件和操作系统,因为比虚拟机少了一层,所以自然就会节约 CPU 和内存,显得非常轻量级,能够更高效地利用硬件资源。不过,因为多个容器共用操作系统内核,应用程序的隔离程度就没有虚拟机那么高了。
运行效率,可以说是容器相比于虚拟机最大的优势,在这个对比图中就可以看到,同样的系统资源,虚拟机只能跑 3 个应用,其他的资源都用来支持虚拟机运行了,而容器则能够把这部分资源释放出来,同时运行 6 个应用。

当然,这个对比图只是一个形象的展示,不是严谨的数值比较,不过可以用手里现有的 VirtualBox/VMware 虚拟机与 Docker 容器做个简单对比。
一个普通的 Ubuntu 虚拟机安装完成之后,体积都是 GB 级别的,再安装一些应用很容易就会上到 10GB,启动的时间通常需要几分钟,我们的电脑上同时运行十来个虚拟机可能就是极限了。
而一个 Ubuntu 镜像大小则只有几十 MB,启动起来更是非常快,基本上不超过一秒钟,同时跑上百个容器也毫无问题。不过,虚拟机和容器这两种技术也不是互相排斥的,它们完全可以结合起来使用,就像我们的课程里一样,用虚拟机实现与宿主机的强隔离,然后在虚拟机里使用 Docker 容器来快速运行应用程序。
4.隔离是怎么实现的
虚拟机使用的是 Hypervisor(KVM、Xen 等),那么,容器是怎么实现和下层计算机硬件和操作系统交互的呢?为什么它会具有高效轻便的隔离特性呢?
其实奥秘就在于 Linux 操作系统内核之中,为资源隔离提供了三种技术:namespace、cgroup、chroot,虽然这三种技术的初衷并不是为了实现容器,但它们三个结合在一起就会发生奇妙的“化学反应”
namespace 是 2002 年从 Linux 2.4.19 开始出现的,和编程语言里的 namespace 有点类似,它可以创建出独立的文件系统、主机名、进程号、网络等资源空间,相当于给进程盖了一间小板房,这样就实现了系统全局资源和进程局部资源的隔离。
cgroup 是 2008 年从 Linux 2.6.24 开始出现的,它的全称是 Linux Control Group,用来实现对进程的 CPU、内存等资源的优先级和配额限制,相当于给进程的小板房加了一个天花板。
chroot 的历史则要比前面的 namespace、cgroup 要古老得多,早在 1979 年的 UNIX V7 就已经出现了,它可以更改进程的根目录,也就是限制访问文件系统,相当于给进程的小板房铺上了地砖。
你看,综合运用这三种技术,一个四四方方、具有完善的隔离特性的容器就此出现了,进程就可以搬进这个小房间,过它的“快乐生活”了。我觉得用鲁迅先生的一句诗来描述这个情景最为恰当:躲进小楼成一统,管他冬夏与春秋。
5.小结
- 容器就是操作系统里一个特殊的“沙盒”环境,里面运行的进程只能看到受限的信息,与外部系统实现了隔离。
- 容器隔离的目的是为了系统安全,限制了进程能够访问的各种资源。
- 相比虚拟机技术,容器更加轻巧、更加高效,消耗的系统资源非常少,在云计算时代极具优势。
- 容器的基本实现技术是 Linux 系统里的 namespace、cgroup、chroot。
普通的进程 + namespace(一重枷锁,能看到什么进程) + cgroup(二重枷锁,能用多少资源,内存/磁盘。cpu等) + chroot(三重枷锁,能看到什么文件)= 特殊的进程 = 容器
容器和虚拟机有着本质的区别,虚拟机是虚拟出一套软硬件系统环境,我们的应用跑在虚拟机中,可以大致看作是跑在一个独立的服务器中,而容器只是一个进程,他们存在本质上的区别;如果硬要说他们的相同点,那么只是在隔离性这个广义的角度上,他们所做的事情是类似的。
三、容器化的应用:会了这些你就是Docker高手
容器技术中最核心的概念:容器,知道它就是一个系统中被隔离的特殊环境,进程可以在其中不受干扰地运行。我们也可以把这段描述再简化一点:容器就是被隔离的进程。
1.什么是容器化的应用
之前运行容器的时候,显然不是从零开始的,而是要先拉取一个“镜像”(image),再从这个“镜像”来启动容器,那么,这个“镜像”到底是什么东西呢?它又和“容器”有什么关系呢?
其实在其他场合中也曾经见到过“镜像”这个词,比如最常见的光盘镜像,重装电脑时使用的硬盘镜像,还有虚拟机系统镜像。这些“镜像”都有一些相同点:只读,不允许修改,以标准格式存储了一系列的文件,然后在需要的时候再从中提取出数据运行起来。
容器技术里的镜像也是同样的道理。因为容器是由操作系统动态创建的,那么必然就可以用一种办法把它的初始环境给固化下来,保存成一个静态的文件,相当于是把容器给“拍扁”了,这样就可以非常方便地存放、传输、版本化管理了。

如果还拿之前的“小板房”来做比喻的话,那么镜像就可以说是一个“样板间”,把运行进程所需要的文件系统、依赖库、环境变量、启动参数等所有信息打包整合到了一起。之后镜像文件无论放在哪里,操作系统都能根据这个“样板间”快速重建容器,应用程序看到的就会是一致的运行环境了。
从功能上来看,镜像和常见的 tar、rpm、deb 等安装包一样,都打包了应用程序,但最大的不同点在于它里面不仅有基本的可执行文件,还有应用运行时的整个系统环境。这就让镜像具有了非常好的跨平台便携性和兼容性,能够让开发者在一个系统上开发(例如 Ubuntu),然后打包成镜像,再去另一个系统上运行(例如 CentOS),完全不需要考虑环境依赖的问题,是一种更高级的应用打包方式。
docker pull busybox ,就是获取了一个打包了 busybox 应用的镜像,里面固化了 busybox 程序和它所需的完整运行环境。
docker run busybox echo hello world ,就是提取镜像里的各种信息,运用 namespace、cgroup、chroot 技术创建出隔离环境,然后再运行 busybox 的 echo 命令,输出 hello world 的字符串。
这两个步骤,由于是基于标准的 Linux 系统调用和只读的镜像文件,所以,无论是在哪种操作系统上,或者是使用哪种容器实现技术,都会得到完全一致的结果。
推而广之,任何应用都能够用这种形式打包再分发后运行,这也是无数开发者梦寐以求的“一次编写,到处运行(Build once, Run anywhere)”的至高境界。所以,所谓的“容器化的应用”,或者“应用的容器化”,就是指应用程序不再直接和操作系统打交道,而是封装成镜像,再交给容器环境去运行。
现在就知道了,镜像就是静态的应用容器,容器就是动态的应用镜像,两者互相依存,互相转化,密不可分。
之前的那张 Docker 官方架构图可以看到,在 Docker 里的核心处理对象就是镜像(image)和容器(container):

好,理解了什么是容器化的应用,接下来再来学习怎么操纵容器化的应用。因为镜像是容器运行的根本,先有镜像才有容器,所以先来看看关于镜像的一些常用命令。
2.常用的镜像操作有哪些
在前面已经了解了两个基本命令,docker pull 从远端仓库拉取镜像,docker images 列出当前本地已有的镜像。docker pull 的用法还是比较简单的,和普通的下载非常像,不过我们需要知道镜像的命名规则,这样才能准确地获取到我们想要的容器镜像。
镜像的完整名字由两个部分组成,名字和标签,中间用 : 连接起来。
名字表明了应用的身份,比如 busybox、Alpine、Nginx、Redis
等等。标签(tag)则可以理解成是为了区分不同版本的应用而做的额外标记,任何字符串都可以,比如 3.15 是纯数字的版本号、jammy
是项目代号、1.21-alpine
是版本号加操作系统名等等。其中有一个比较特殊的标签叫“latest”,它是默认的标签,如果只提供名字没有附带标签,那么就会使用这个默认的“latest”标签。
那么现在,就可以把名字和标签组合起来,使用 docker pull 来拉取一些镜像了:
docker pull alpine:3.15
docker pull ubuntu:jammy
docker pull nginx:1.21-alpine
docker pull nginx:alpine
docker pull redis
有了这些镜像之后,再用 docker images 命令来看看它们的具体信息:
root@template:/# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
busybox latest bab98d58e29e 5 days ago 4.86MB
redis latest f9c173b0f012 10 days ago 117MB
ubuntu jammy 74f2314a03de 11 days ago 77.8MB
127.0.0.1:5000/nginx alpine 2bc7edbc3cf2 4 weeks ago 40.7MB
nginx alpine 2bc7edbc3cf2 4 weeks ago 40.7MB
alpine 3.15 5ce65d7b0fde 4 weeks ago 5.59MB
alpine latest b2aa39c304c2 4 weeks ago 7.05MB
nginx 1.21-alpine b1c3acb28882 9 months ago 23.4MB
hello-world latest feb5d9fea6a5 17 months ago 13.3kB
在这个列表里,你可以看到,REPOSITORY 列就是镜像的名字,TAG 就是这个镜像的标签,那么第三列“IMAGE ID”又是什么意思呢?
它可以说是镜像唯一的标识,就好像是身份证号一样。比如这里我们可以用“ubuntu:jammy”来表示 Ubuntu 22.04 镜像,同样也可以用它的 ID“d4c2c……”来表示。
另外,截图里的两个镜像“nginx:1.21-alpine”和“nginx:alpine”的 IMAGE ID 是一样的,都是“a63aa……”。这其实也很好理解,这就像是人的身份证号码是唯一的,但可以有大名、小名、昵称、绰号,同一个镜像也可以打上不同的标签,这样应用在不同的场合就更容易理解。
IMAGE ID 还有一个好处,因为它是十六进制形式且唯一,Docker 特意为它提供了“短路”操作,在本地使用镜像的时候,我们不用像名字那样要完全写出来这一长串数字,通常只需要写出前三位就能够快速定位,在镜像数量比较少的时候用两位甚至一位数字也许就可以了。
来看另一个镜像操作命令 docker rmi ,它用来删除不再使用的镜像,可以节约磁盘空间,注意命令 rmi ,实际上是“remove image”的简写。
2.1 使用名字和 IMAGE ID 来删除镜像:
docker rmi redis
docker rmi d4c
这里的第一个 rmi 删除了 Redis 镜像,因为没有显式写出标签,默认使用的就是“latest”。第二个 rmi 没有给出名字,而是直接使用了 IMAGE ID 的前三位,也就是“d4c”,Docker 就会直接找到这个 ID 前缀的镜像然后删除。
Docker 里与镜像相关的命令还有很多,不过以上的 docker pull、docker images、docker rmi 就是最常用的三个了,更多的在后续。

3.常用的容器操作有哪些
现在已经在本地存放了镜像,就可以使用 docker run 命令把这些静态的应用运行起来,变成动态的容器了。
基本的格式是“docker run 设置参数”,再跟上“镜像名或 ID”,后面可能还会有附加的“运行命令”。
比如这个命令:
docker run -h srv alpine hostname
-h srv 就是容器的运行参数(指定容器的主机名),alpine 是镜像名,它后面的 hostname 表示要在容器里运行的“hostname”这个程序,输出主机名。
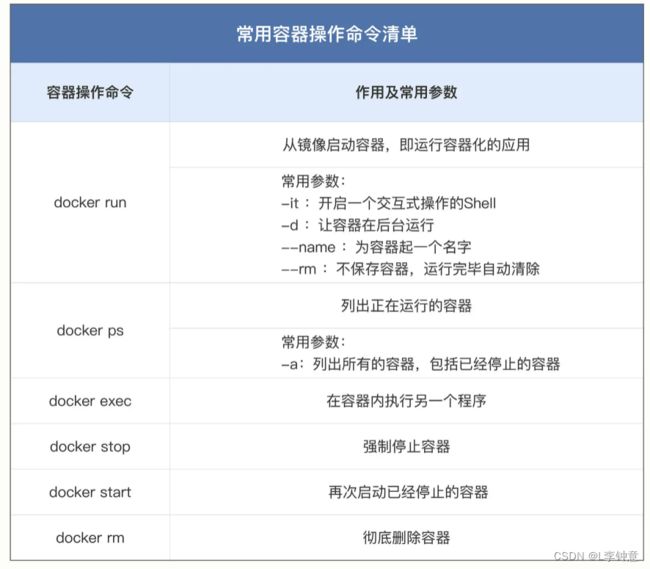
docker run 是最复杂的一个容器操作命令,有非常多的额外参数用来调整容器的运行状态,你可以加上 --help 来看它的帮助信息,今天我只说几个最常用的参数。
-it 表示开启一个交互式操作的 Shell,这样可以直接进入容器内部,就好像是登录虚拟机一样。(它实际上是“-i”和“-t”两个参数的组合形式)
--name 可以为容器起一个名字,方便我们查看,不过它不是必须的,如果不用这个参数,Docker 会分配一个随机的名字。
下面来练习一下这三个参数,分别运行 Nginx、Redis 和 Ubuntu:
docker run -d nginx:alpine # 后台运行Nginx
docker run -d --name red_srv redis # 后台运行Redis
docker run -it --name ubuntu 2e6 sh # 使用IMAGE ID,登录Ubuntu18.04
因为第三个命令使用的是 -it 而不是 -d ,所以它会进入容器里的 Ubuntu 系统,我们需要另外开一个终端窗口,使用 docker ps 命令来查看容器的运行状态:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
464e9c2226a4 redis "docker-entrypoint.s…" 42 seconds ago Up 41 seconds 6379/tcp red_srv
fd344a63ab4b nginx:alpine "/docker-entrypoint.…" 48 seconds ago Up 46 seconds 80/tcp festive_sutherland
可以看到,每一个容器也会有一个“CONTAINER ID”,它的作用和镜像的“IMAGE ID”是一样的,唯一标识了容器。
对于正在运行中的容器,我们可以使用docker exec 命令在里面执行另一个程序,效果和 docker run 很类似,但因为容器已经存在,所以不会创建新的容器。它最常见的用法是使用 -it 参数打开一个 Shell,从而进入容器内部,例如:
docker exec -it red_srv sh
这样就“登录”进了 Redis 容器,可以很方便地查看服务的运行状态或者日志。
运行中的容器还可以使用 docker stop 命令来强制停止,这里我们仍然可以使用容器名字,不过或许用“CONTAINER ID”的前三位数字会更加方便。
docker stop ed4 d60 45c
容器被停止后使用 docker ps 命令就看不到了,不过容器并没有被彻底销毁,可以使用 docker ps -a 命令查看系统里所有的容器,当然也包括已经停止运行的容器:
root@template:/# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
464e9c2226a4 redis "docker-entrypoint.s…" 3 minutes ago Up 3 minutes 6379/tcp red_srv
fd344a63ab4b nginx:alpine "/docker-entrypoint.…" 3 minutes ago Up 3 minutes 80/tcp festive_sutherland
00264fc0da74 redis "docker-entrypoint.s…" 5 minutes ago Exited (0) 3 minutes ago suspicious_banzai
30da924e0b9e busybox "sh" 6 minutes ago Exited (0) 6 minutes ago recursing_williamson
619b33d27020 alpine "sh" 51 minutes ago Exited (0) 20 minutes ago great_ride
7d23588a7734 hello-world "/hello" About an hour ago Exited (0) About an hour ago romantic_haibt
3fe3b3d75f72 busybox "echo hello world" About an hour ago Exited (0) About an hour ago nifty_brown
这些停止运行的容器可以用 docker start 再次启动运行,如果你确定不再需要它们,可以使用 docker rm 命令来彻底删除。
注意,这个命令与 docker rmi 非常像,区别在于它没有后面的字母“i”,所以只会删除容器,不删除镜像。
下面就来运行 docker rm 命令,使用“CONTAINER ID”的前两位数字来删除这些容器:
docker rm ed d6 45
执行删除命令之后,再用 docker ps -a 查看列表就会发现这些容器已经彻底消失了。
你可能会感觉这样的容器管理方式很麻烦,启动后要 ps 看 ID 再删除,如果稍微不注意,系统就会遗留非常多的“死”容器,占用系统资源,有没有什么办法能够让 Docker 自动删除不需要的容器呢?
办法当然有,就是在执行 docker run 命令的时候加上一个 --rm 参数,这就会告诉 Docker 不保存容器,只要运行完毕就自动清除,省去了我们手工管理容器的麻烦。
我们还是用刚才的 Nginx、Redis 和 Ubuntu 这三个容器来试验一下,加上 --rm 参数(省略了 name 参数):
docker run -d --rm nginx:alpine
docker run -d --rm redis
docker run -it --rm 2e6 sh
然后用 docker stop 停止容器,再用 docker ps -a ,就会发现不需要我们再手动执行 docker rm ,Docker 已经自动删除了这三个容器。
4.小结
镜像是容器的静态形式,它打包了应用程序的所有运行依赖项,方便保存和传输。使用容器技术运行镜像,就形成了动态的容器,由于镜像只读不可修改,所以应用程序的运行环境总是一致的。而容器化的应用就是指以镜像的形式打包应用程序,然后在容器环境里从镜像启动容器。由于 Docker 的命令比较多,而且每个命令还有许多参数,一节课里很难把它们都详细说清楚,希望你课下参考 Docker 自带的帮助或者官网文档
- 常用的镜像操作有 docker pull、docker images、docker rmi,分别是拉取镜像、查看镜像和删除镜像。
- 用来启动容器的 docker run 是最常用的命令,它有很多参数用来调整容器的运行状态,对于后台服务来说应该使用 -d。
- docker exec 命令可以在容器内部执行任意程序,对于调试排错特别有用。
- 其他常用的容器操作还有 docker ps、docker stop、docker rm,用来查看容器、停止容器和删除容器。
说一说你对容器镜像的理解,它与 rpm、deb 安装包有哪些不同和优缺点。
你觉得 docker run 和 docker exec 的区别在哪里,应该怎么使用它们?
1:容器镜像比起这些安装包的差别就在于通用,不同linux版本下的安装包还不同。
2: run是针对容器本身启动,而exec是进入了容器内部去跑命令,相当于进去操作系统跑应用。
四、创建容器镜像:如何编写正确、高效的Dockerfile
容器化的应用,也就是被打包成镜像的应用程序,然后再用各种 Docker 命令来运行、管理它们。
这些镜像是怎么创建出来的?我们能不能够制作属于自己的镜像呢?
今天学习镜像的内部机制,还有高效、正确地编写 Dockerfile 制作容器镜像的方法。
1.镜像的内部机制是什么
现在你应该知道,镜像就是一个打包文件,里面包含了应用程序还有它运行所依赖的环境,例如文件系统、环境变量、配置参数等等。
环境变量、配置参数这些东西还是比较简单的,随便用一个 manifest 清单就可以管理,真正麻烦的是文件系统。为了保证容器运行环境的一致性,镜像必须把应用程序所在操作系统的根目录,也就是 rootfs,都包含进来。
虽然这些文件里不包含系统内核(因为容器共享了宿主机的内核),但如果每个镜像都重复做这样的打包操作,仍然会导致大量的冗余。可以想象,如果有一千个镜像,都基于 Ubuntu 系统打包,那么这些镜像里就会重复一千次 Ubuntu 根目录,对磁盘存储、网络传输都是很大的浪费。
很自然的,我们就会想到,应该把重复的部分抽取出来,只存放一份 Ubuntu 根目录文件,然后让这一千个镜像以某种方式共享这部分数据。
这个思路,也正是容器镜像的一个重大创新点:分层,术语叫“Layer”。
容器镜像内部并不是一个平坦的结构,而是由许多的镜像层组成的,每层都是只读不可修改的一组文件,相同的层可以在镜像之间共享,然后多个层像搭积木一样堆叠起来,再使用一种叫“Union FS 联合文件系统”的技术把它们合并在一起,就形成了容器最终看到的文件系统
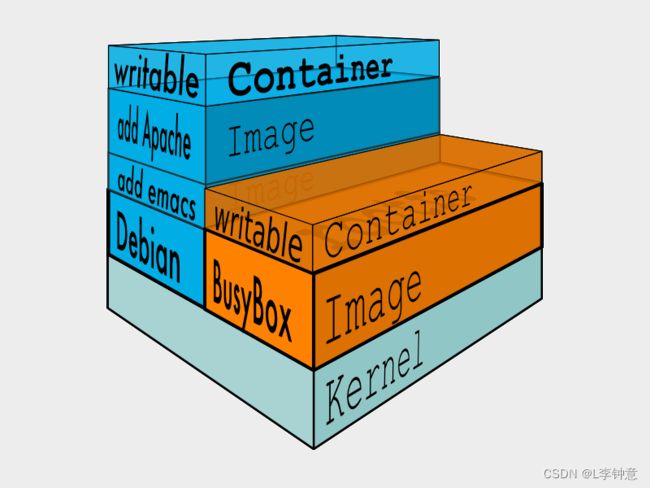
拿大家都熟悉的千层糕做一个形象的比喻吧。
千层糕也是由很多层叠加在一起的,从最上面可以看到每层里面镶嵌的葡萄干、核桃、杏仁、青丝等,每一层糕就相当于一个 Layer,干果就好比是 Layer 里的各个文件。但如果某两层的同一个位置都有干果,也就是有文件同名,那么我们就只能看到上层的文件,而下层的就被屏蔽了。
你可以用命令 docker inspect 来查看镜像的分层信息,比如 nginx:alpine 镜像:
docker inspect nginx:alpine
它的分层信息在“RootFS”部分:
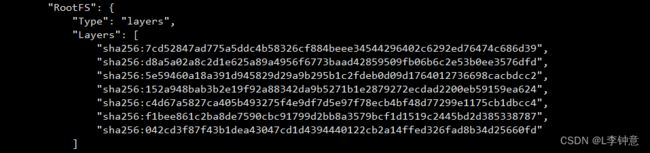
通过这张截图就可以看到,nginx:alpine 镜像里一共有 7 个 Layer。
相信你现在也就明白,之前在使用 docker pull、docker rmi 等命令操作镜像的时候,那些“奇怪”的输出信息是什么了,其实就是镜像里的各个 Layer。Docker 会检查是否有重复的层,如果本地已经存在就不会重复下载,如果层被其他镜像共享就不会删除,这样就可以节约磁盘和网络成本。
2.Dockerfile 是什么
知道了容器镜像的内部结构和基本原理,我们就可以来学习如何自己动手制作容器镜像了,也就是自己打包应用。
在之前我们讲容器的时候,曾经说过容器就是“小板房”,镜像就是“样板间”。那么,要造出这个“样板间”,就必然要有一个“施工图纸”,由它来规定如何建造地基、铺设水电、开窗搭门等动作。这个“施工图纸”就是“Dockerfile”。
比起容器、镜像来说,Dockerfile 非常普通,它就是一个纯文本,里面记录了一系列的构建指令,比如选择基础镜像、拷贝文件、运行脚本等等,每个指令都会生成一个 Layer,而 Docker 顺序执行这个文件里的所有步骤,最后就会创建出一个新的镜像出来。
我们来看一个最简单的 Dockerfile 实例:
# Dockerfile.busybox
FROM busybox # 选择基础镜像
CMD echo "hello world" # 启动容器时默认运行的命令
这个文件里只有两条指令。
第一条指令是 FROM,所有的 Dockerfile 都要从它开始,表示选择构建使用的基础镜像,相当于“打地基”,这里我们使用的是 busybox。
第二条指令是 CMD,它指定 docker run 启动容器时默认运行的命令,这里我们使用了 echo 命令,输出“hello world”字符串。现在有了 Dockerfile 这张“施工图纸”,我们就可以请出“施工队”了,用 docker build 命令来创建出镜像:
docker build -f Dockerfile.busybox .
Sending build context to Docker daemon 7.68kB
Step 1/2 : FROM busybox
---> d38589532d97
Step 2/2 : CMD echo "hello world"
---> Running in c5a762edd1c8
Removing intermediate container c5a762edd1c8
---> b61882f42db7
Successfully built b61882f42db7
你需要特别注意命令的格式,用 -f 参数指定 Dockerfile 文件名,后面必须跟一个文件路径,叫做“构建上下文”(build’s context),这里只是一个简单的点号,表示当前路径的意思。
接下来,你就会看到 Docker 会逐行地读取并执行 Dockerfile 里的指令,依次创建镜像层,再生成完整的镜像。
新的镜像暂时还没有名字(用 docker images 会看到是 ),但我们可以直接使用“IMAGE ID”来查看或者运行:
docker inspect b61
docker run b61
3.怎样编写正确、高效的 Dockerfile
大概了解了 Dockerfile 之后,我再来讲讲编写 Dockerfile 的一些常用指令和最佳实践,帮你在今后的工作中把它写好、用好。
首先因为构建镜像的第一条指令必须是 FROM,所以基础镜像的选择非常关键。如果关注的是镜像的安全和大小,那么一般会选择 Alpine;如果关注的是应用的运行稳定性,那么可能会选择 Ubuntu、Debian、CentOS。
FROM alpine:3.15 # 选择Alpine镜像
FROM ubuntu:bionic # 选择Ubuntu镜像
我们在本机上开发测试时会产生一些源码、配置等文件,需要打包进镜像里,这时可以使用 COPY 命令,它的用法和 Linux 的 cp 差不多,不过拷贝的源文件必须是“构建上下文”路径里的,不能随意指定文件。也就是说,如果要从本机向镜像拷贝文件,就必须把这些文件放到一个专门的目录,然后在 docker build 里指定“构建上下文”到这个目录才行。
这里有两个 COPY 命令示例,你可以看一下:
COPY ./a.txt /tmp/a.txt # 把构建上下文里的a.txt拷贝到镜像的/tmp目录
COPY /etc/hosts /tmp # 错误!不能使用构建上下文之外的文件
接下来要说的就是 Dockerfile 里最重要的一个指令 RUN ,它可以执行任意的 Shell 命令,比如更新系统、安装应用、下载文件、创建目录、编译程序等等,实现任意的镜像构建步骤,非常灵活。
RUN 通常会是 Dockerfile 里最复杂的指令,会包含很多的 Shell 命令,但 Dockerfile 里一条指令只能是一行,所以有的 RUN 指令会在每行的末尾使用续行符 \,命令之间也会用 && 来连接,这样保证在逻辑上是一行,就像下面这样:
RUN apt-get update \
&& apt-get install -y \
build-essential \
curl \
make \
unzip \
&& cd /tmp \
&& curl -fSL xxx.tar.gz -o xxx.tar.gz\
&& tar xzf xxx.tar.gz \
&& cd xxx \
&& ./config \
&& make \
&& make clean
有的时候在 Dockerfile 里写这种超长的 RUN 指令很不美观,而且一旦写错了,每次调试都要重新构建也很麻烦,所以你可以采用一种变通的技巧:把这些 Shell 命令集中到一个脚本文件里,用 COPY 命令拷贝进去再用 RUN 来执行:
COPY setup.sh /tmp/ # 拷贝脚本到/tmp目录
RUN cd /tmp && chmod +x setup.sh \ # 添加执行权限
&& ./setup.sh && rm setup.sh # 运行脚本然后再删除
RUN 指令实际上就是 Shell 编程,如果你对它有所了解,就应该知道它有变量的概念,可以实现参数化运行,这在 Dockerfile 里也可以做到,需要使用两个指令 ARG 和 ENV。
它们区别在于 ARG 创建的变量只在镜像构建过程中可见,容器运行时不可见,而 ENV 创建的变量不仅能够在构建镜像的过程中使用,在容器运行时也能够以环境变量的形式被应用程序使用。
下面是一个简单的例子,使用 ARG 定义了基础镜像的名字(可以用在“FROM”指令里),使用 ENV 定义了两个环境变量:
ARG IMAGE_BASE="node"
ARG IMAGE_TAG="alpine"
ENV PATH=$PATH:/tmp
ENV DEBUG=OFF
还有一个重要的指令是 EXPOSE,它用来声明容器对外服务的端口号,对现在基于 Node.js、Tomcat、Nginx、Go 等开发的微服务系统来说非常有用:
EXPOSE 443 # 默认是tcp协议
EXPOSE 53/udp # 可以指定udp协议
讲了这些 Dockerfile 指令之后,我还要特别强调一下,因为每个指令都会生成一个镜像层,所以 Dockerfile 里最好不要滥用指令,尽量精简合并,否则太多的层会导致镜像臃肿不堪。
4.docker build 是怎么工作的
- Dockerfile 必须要经过 docker build 才能生效,所以我们再来看看 docker build 的详细用法。
- 刚才在构建镜像的时候,你是否对“构建上下文”这个词感到有些困惑呢?它到底是什么含义呢?
- 我觉得用 Docker 的官方架构图来理解会比较清楚(注意图中与“docker build”关联的虚线)。
- 因为命令行“docker”是一个简单的客户端,真正的镜像构建工作是由服务器端的“Docker daemon”来完成的,所以“docker”客户端就只能把“构建上下文”目录打包上传(显示信息 Sending build context to Docker daemon ),这样服务器才能够获取本地的这些文件。
明白了这一点,你就会知道,“构建上下文”其实与 Dockerfile 并没有直接的关系,它其实指定了要打包进镜像的一些依赖文件。而 COPY 命令也只能使用基于“构建上下文”的相对路径,因为“Docker daemon”看不到本地环境,只能看到打包上传的那些文件。
但这个机制也会导致一些麻烦,如果目录里有的文件(例如 readme/.git/.svn 等)不需要拷贝进镜像,docker 也会一股脑地打包上传,效率很低。
为了避免这种问题,你可以在“构建上下文”目录里再建立一个 .dockerignore 文件,语法与 .gitignore 类似,排除那些不需要的文件。
下面是一个简单的示例,表示不打包上传后缀是“swp”“sh”的文件:
# docker ignore
*.swp
*.sh
另外关于 Dockerfile,一般应该在命令行里使用 -f 来显式指定。但如果省略这个参数,docker build 就会在当前目录下找名字是 Dockerfile 的文件。所以,如果只有一个构建目标的话,文件直接叫“Dockerfile”是最省事的。
现在我们使用 docker build 应该就没什么难点了,不过构建出来的镜像只有“IMAGE ID”没有名字,不是很方便。
为此你可以加上一个 -t 参数,也就是指定镜像的标签(tag),这样 Docker 就会在构建完成后自动给镜像添加名字。当然,名字必须要符合上节课里的命名规范,用 : 分隔名字和标签,如果不提供标签默认就是“latest”。
5.小结
重点理解容器镜像是由多个只读的 Layer 构成的,同一个 Layer 可以被不同的镜像共享,减少了存储和传输的成本。
如何编写 Dockerfile 内容稍微多一点,我再简单做个小结:
- 创建镜像需要编写 Dockerfile,写清楚创建镜像的步骤,每个指令都会生成一个 Layer。
- Dockerfile 里,第一个指令必须是 FROM,用来选择基础镜像,常用的有 Alpine、Ubuntu 等。其他常用的指令有:COPY、RUN、EXPOSE,分别是拷贝文件,运行 Shell 命令,声明服务端口号。
- docker build 需要用 -f 来指定 Dockerfile,如果不指定就使用当前目录下名字是“Dockerfile”的文件。
- docker build 需要指定“构建上下文”,其中的文件会打包上传到 Docker daemon,所以尽量不要在“构建上下文”中存放多余的文件。
- 创建镜像的时候应当尽量使用 -t 参数,为镜像起一个有意义的名字,方便管理。
比如使用缓存、多阶段构建等等,可以再参考 Docker官方文档
当然还有两个思考题:
- 镜像里的层都是只读不可修改的,但容器运行的时候经常会写入数据,这个冲突应该怎么解决呢?
- 你能再列举一下镜像的分层结构带来了哪些好处吗?
答案:
1.容器最上一层是读写层,镜像所有的层是只读层。容器启动后,Docker daemon会在容器的镜像上添加一个读写层。
2.容器分层可以共享资源,节约空间,相同的内容只需要加载一份份到内存。
五、镜像仓库: Dokcer Hub
知道了如何创建自己的镜像。那么镜像文件应该如何管理呢,具体来说,应该如何存储、检索、分发、共享镜像呢?不解决这些问题,我们的容器化应用还是无法顺利地实施。
1.什么是镜像仓库(Registry)
还是来看 Docker 的官方架构图(它真的非常重要):

图里右边的区域就是镜像仓库,术语叫 Registry,直译就是“注册中心”,意思是所有镜像的 Repository 都在这里登记保管,就像是一个巨大的档案馆。
然后我们再来看左边的“docker pull”,虚线显示了它的工作流程,先到“Docker daemon”,再到 Registry,只有当 Registry 里存有镜像才能真正把它下载到本地。
当然了,拉取镜像只是镜像仓库最基本的一个功能,它还会提供更多的功能,比如上传、查询、删除等等,是一个全面的镜像管理服务站点。
你也可以把镜像仓库类比成手机上的应用商店,里面分门别类存放了许多容器化的应用,需要什么去找一下就行了。有了它,我们使用镜像才能够免除后顾之忧。
2.什么是 Docker Hub
不过,你有没有注意到,在使用 docker pull 获取镜像的时候,我们并没有明确地指定镜像仓库。在这种情况下,Docker 就会使用一个默认的镜像仓库,也就是大名鼎鼎的“Docker Hub”(https://hub.docker.com/)。
Docker Hub 是 Docker 公司搭建的官方 Registry 服务,创立于 2014 年 6 月,和 Docker 1.0 同时发布。它号称是世界上最大的镜像仓库,和 GitHub 一样,几乎成为了容器世界的基础设施。
Docker Hub 里面不仅有 Docker 自己打包的镜像,而且还对公众免费开放,任何人都可以上传自己的作品。经过这 8 年的发展,Docker Hub 已经不再是一个单纯的镜像仓库了,更应该说是一个丰富而繁荣的容器社区。
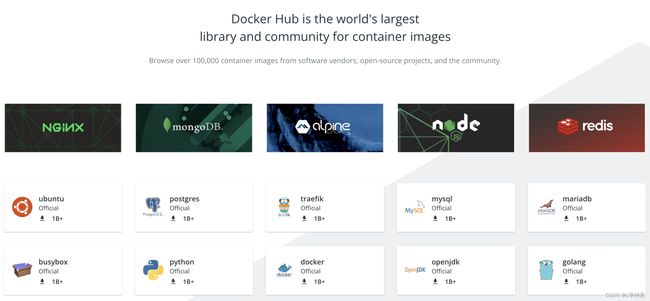
你可以看看下面的这张截图,里面列出的都是下载量超过 10 亿次(1 Billion)的最受欢迎的应用程序,比如 Nginx、MongoDB、Node.js、Redis、OpenJDK 等等。显然,把这些容器化的应用引入到我们自己的系统里,就像是站在了巨人的肩膀上,一开始就会有一个高水平的起点。
但和 GitHub、App Store 一样,面向所有人公开的 Docker Hub 也有一个不可避免的缺点,就是“良莠不齐”。
在 Docker Hub 搜索框里输入关键字,比如 Nginx、MySQL,它立即就会给出几百几千个搜索结果,有点“乱花迷人眼”的感觉,这么多镜像,应该如何挑选出最适合自己的呢?下面我就来说说自己在这方面的一些经验。
3.如何在 Docker Hub 上挑选镜像
首先,你应该知道,在 Docker Hub 上有官方镜像、认证镜像和非官方镜像的区别。
官方镜像是指 Docker 公司官方提供的高质量镜像(https://github.com/docker-library/official-images),都经过了严格的漏洞扫描和安全检测,支持 x86_64、arm64 等多种硬件架构,还具有清晰易读的文档,一般来说是我们构建镜像的首选,也是我们编写 Dockerfile 的最佳范例。
官方镜像目前有大约 100 多个,基本上囊括了现在的各种流行技术,下面就是官方的 Nginx 镜像网页截图:
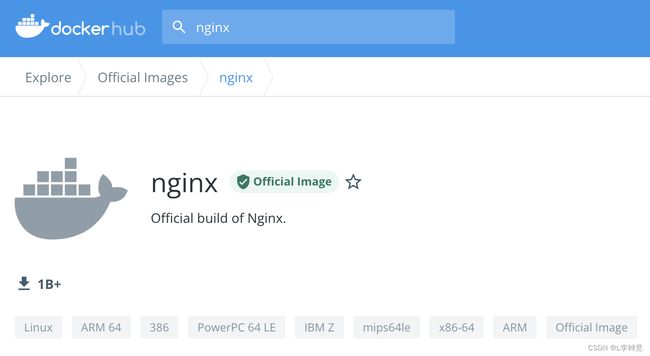
你会看到,官方镜像会有一个特殊的“Official image”的标记,这就表示这个镜像经过了 Docker 公司的认证,有专门的团队负责审核、发布和更新,质量上绝对可以放心。
第二类是认证镜像,标记是“Verified publisher”,也就是认证发行商,比如 Bitnami、Rancher、Ubuntu 等。它们都是颇具规模的大公司,具有不逊于 Docker 公司的实力,所以就在 Docker Hub 上开了个认证账号,发布自己打包的镜像,有点类似我们微博上的“大 V”。

这些镜像有公司背书,当然也很值得信赖,不过它们难免会带上一些各自公司的“烙印”,比如 Bitnami 的镜像就统一以“minideb”为基础,灵活性上比 Docker 官方镜像略差,有的时候也许会不符合我们的需求。
除了官方镜像和认证镜像,剩下的就都属于非官方镜像了,不过这里面也可以分出两类。
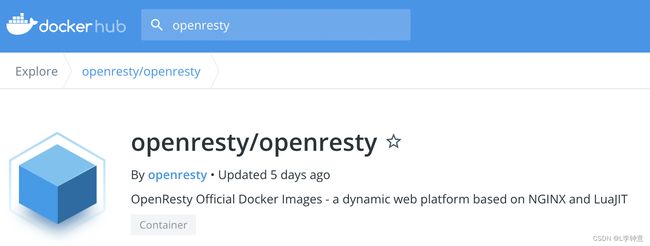
第一类是“半官方”镜像。因为成为“Verified publisher”是要给 Docker 公司交钱的,而很多公司不想花这笔“冤枉钱”,所以只在 Docker Hub 上开了公司账号,但并不加入认证。
这里我以 OpenResty 为例,看一下它的 Docker Hub 页面,可以看到显示的是 OpenResty 官方发布,但并没有经过 Docker 正式认证,所以难免就会存在一些风险,有被“冒名顶替”的可能,需要我们在使用的时候留心鉴别一下。不过一般来说,这种“半官方”镜像也是比较可靠的。
第二类就是纯粹的“民间”镜像了,通常是个人上传到 Docker Hub 的,因为条件所限,测试不完全甚至没有测试,质量上难以得到保证,下载的时候需要小心谨慎。
除了查看镜像是否为官方认证,我们还应该再结合其他的条件来判断镜像质量是否足够好。做法和 GitHub 差不多,就是看它的下载量、星数、还有更新历史,简单来说就是“好评”数量。
一般来说下载量是最重要的参考依据,好的镜像下载量通常都在百万级别(超过 1M),而有的镜像虽然也是官方认证,但缺乏维护,更新不及时,用的人很少,星数、下载数都寥寥无几,那么还是应该选择下载量最多的镜像,通俗来说就是“随大流”。
下面的这张截图就是 OpenResty 在 Docker Hub 上的搜索结果。可以看到,有两个认证发行商的镜像(Bitnami、IBM),但下载量都很少,还有一个“民间”镜像下载量虽然超过了 1M,但更新时间是 3 年前,所以毫无疑问,我们应该选择排在第三位,但下载量超过 10M、有 360 多个星的“半官方”镜像。

看了这么多 Docker Hub 上的镜像,你一定注意到了,应用都是一样的名字,比如都是 Nginx、Redis、OpenResty,该怎么区分不同作者打包出的镜像呢?
如果你熟悉 GitHub,就会发现 Docker Hub 也使用了同样的规则,就是**“用户名 / 应用名”**的形式,比如 bitnami/nginx、ubuntu/nginx、rancher/nginx 等等。
所以,我们在使用 docker pull 下载这些非官方镜像的时候,就必须把用户名也带上,否则默认就会使用官方镜像:
docker pull bitnami/nginx
docker pull ubuntu/nginx
4.Docker Hub 上镜像命名的规则是什么
确定了要使用的镜像还不够,因为镜像还会有许多不同的版本,也就是“标签”(tag)。
直接使用默认的“latest”虽然简单方便,但在生产环境里是一种非常不负责任的做法,会导致版本不可控。所以我们还需要理解 Docker Hub 上标签命名的含义,才能够挑选出最适合我们自己的镜像版本。
下面我就拿官方的 Redis 镜像作为例子,解释一下这些标签都是什么意思。
通常来说,镜像标签的格式是应用的版本号加上操作系统。
版本号你应该比较了解吧,基本上都是主版本号 + 次版本号 + 补丁号的形式,有的还会在正式发布前出 rc 版(候选版本,release candidate)。而操作系统的情况略微复杂一些,因为各个 Linux 发行版的命名方式“花样”太多了。
Alpine、CentOS 的命名比较简单明了,就是数字的版本号,像这里的 alpine3.15 ,而 Ubuntu、Debian 则采用了代号的形式。比如 Ubuntu 18.04 是 bionic,Ubuntu 20.04 是 focal,Debian 9 是 stretch,Debian 10 是 buster,Debian 11 是 bullseye。
另外,有的标签还会加上 **slim、fat,**来进一步表示这个镜像的内容是经过精简的,还是包含了较多的辅助工具。通常 slim 镜像会比较小,运行效率高,而 fat 镜像会比较大,适合用来开发调试。
下面我就列出几个标签的例子来说明一下。
- nginx:1.21.6-alpine,表示版本号是 1.21.6,基础镜像是最新的 Alpine。
- redis:7.0-rc-bullseye,表示版本号是 7.0 候选版,基础镜像是 Debian 11。
- node:17-buster-slim,表示版本号是 17,基础镜像是精简的 Debian 10。该怎么上传自己的镜像
5.该怎么上传自己的镜像
现在,我想你应该对如何在 Docker Hub 上选择镜像有了比较全面的了解,那么接下来的问题就是,我们自己用 Dockerfile 创建的镜像该如何上传到 Docker Hub 上呢?
这件事其实一点也不难,只需要 4 个步骤就能完成。
第一步,你需要在 Docker Hub 上注册一个用户,这个就不必再多说了。(https://hub.docker.com/)
第二步,你需要在本机上使用 docker login 命令,用刚才注册的用户名和密码认证身份登录,像这里就用了我的用户名“Lizhongyi”:
docker login -u Lizhongyi 然后输入密码
第三步很关键,需要使用 docker tag 命令,给镜像改成带用户名的完整名字,表示镜像是属于这个用户的。或者简单一点,直接用 docker build -t 在创建镜像的时候就起好名字。
这里我就用上次课里的镜像“ngx-app”作为例子,给它改名成 Lizhongyi /ngx-app:1.0:
docker tag ngx-app Lizhongyi /ngx-app:1.0
第四步,用 docker push 把这个镜像推上去,我们的镜像发布工作就大功告成了:
docker push chronolaw/ngx-app:1.0
你还可以登录 Docker Hub 网站验证一下镜像发布的效果,可以看到它会自动为我们生成一个页面模板,里面还可以进一步丰富完善,比如添加描述信息、使用说明等等
现在你就可以把这个镜像的名字(用户名 / 应用名: 标签)告诉你的同事,让他去用 docker pull 下载部署了。
6.离线环境该怎么办
使用 Docker Hub 来管理镜像的确是非常方便,不过有一种场景下它却是无法发挥作用,那就是企业内网的离线环境,连不上外网,自然也就不能使用 docker push、docker pull 来推送拉取镜像了。
那这种情况有没有解决办法呢?
方法当然有,而且有很多。最佳的方法就是在内网环境里仿造 Docker Hub,创建一个自己的私有 Registry 服务,由它来管理我们的镜像,就像我们自己搭建 GitLab 做版本管理一样。
自建 Registry 已经有很多成熟的解决方案,比如 Docker Registry,还有 CNCF Harbor,不过使用它们还需要一些目前没有讲到的知识,步骤也有点繁琐,所以我会在后续的课程里再介绍。
下面我讲讲存储、分发镜像的一种“笨”办法,虽然比较“原始”,但简单易行,可以作为临时的应急手段。
Docker 提供了 save 和 load 这两个镜像归档命令,可以把镜像导出成压缩包,或者从压缩包导入 Docker,而压缩包是非常容易保管和传输的,可以联机拷贝,FTP 共享,甚至存在 U 盘上随身携带。
需要注意的是,这两个命令默认使用标准流作为输入输出(为了方便 Linux 管道操作),所以一般会用 -o、-i 参数来使用文件的形式,例如:
docker save ngx-app:latest -o ngx.tar
docker load -i ngx.tar
7.小结
了解了 Docker Hub 的使用方法,整理一下要点方便加深理解:
- 镜像仓库(Registry)是一个提供综合镜像服务的网站,最基本的功能是上传和下载。
- Docker Hub 是目前最大的镜像仓库,拥有许多高质量的镜像。上面的镜像非常多,选择的标准有官方认证、下载量、星数等,需要综合评估。
- 镜像也有很多版本,应该根据版本号和操作系统仔细确认合适的标签。
- 在 Docker Hub 注册之后就可以上传自己的镜像,用 docker tag 打上标签再用 docker push 推送
- 离线环境可以自己搭建私有镜像仓库,或者使用 docker save 把镜像存成压缩包,再用 docker load 从压缩包恢复成镜像。
六、容器该如何与外界互联互通
在前面,我们已经学习了容器、镜像、镜像仓库的概念和用法,也知道了应该如何创建镜像,再以容器的形式启动应用。
不过,用容器来运行“busybox”“hello world”这样比较简单的应用还好,如果是 Nginx、Redis、MySQL 这样的后台服务应用,因为它们运行在容器的“沙盒”里,完全与外界隔离,无法对外提供服务,也就失去了价值。这个时候,容器的隔离环境反而成为了一种负面特性。
所以,容器的这个“小板房”不应该是一个完全密闭的铁屋子,而是应该给它开几扇门窗,让应用在“足不出户”的情况下,也能够与外界交换数据、互通有无,这样“有限的隔离”才是我们真正所需要的运行环境。
那么今天,我就以 Docker 为例,来讲讲有哪些手段能够在容器与外部系统之间沟通交流。
1.如何拷贝容器内的数据
我们先来看看 Docker 提供的 cp 命令,它可以在宿主机和容器之间拷贝文件,是最基本的一种数据交换功能。
试验这个命令需要先用 docker run 启动一个容器,就用 Redis 吧:
docker run -d --rm redis
注意这里使用了 -d、--rm 两个参数,表示运行在后台,容器结束后自动删除,然后使用 docker ps 命令可以看到 Redis 容器正在运行,容器 ID 前三位 是“062”。。
docker cp 的用法很简单,很类似 Linux 的“cp”“scp”,指定源路径(src path)和目标路径(dest path)就可以了。如果源路径是宿主机那么就是把文件拷贝进容器,如果源路径是容器那么就是把文件拷贝出容器,注意需要用容器名或者容器 ID 来指明是哪个容器的路径。
假设当前目录下有一个“a.txt”的文件,现在我们要把它拷贝进 Redis 容器的“/tmp”目录,如果使用容器 ID,命令就会是这样:
docker cp a.txt 062:/tmp
接下来我们可以使用 docker exec 命令,进入容器看看文件是否已经正确拷贝了:
docker exec -it 062 sh
[root@Template ~]# docker exec -it 062 sh
# ls /tmp
a.txt
可以看到,在“/tmp”目录下,确实已经有了一个“a.txt”。
现在让我们再来试验一下从容器拷贝出文件,只需要把 docker cp 后面的两个路径调换一下位置:
docker cp 062:/tmp/a.txt ./b.txt
这样,在宿主机的当前目录里,就会多出一个新的“b.txt”,也就是从容器里拿到的文件。
2.如何共享主机上的文件
docker cp 的用法模仿了操作系统的拷贝命令,偶尔一两次的文件共享还可以应付,如果容器运行时经常有文件来往互通,这样反复地拷来拷去就显得很麻烦,也很容易出错。
你也许会联想到虚拟机有一种“共享目录”的功能。它可以在宿主机上开一个目录,然后把这个目录“挂载”进虚拟机,这样就实现了两者共享同一个目录,一边对目录里文件的操作另一边立刻就能看到,没有了数据拷贝,效率自然也会高很多。
沿用这个思路,容器也提供了这样的共享宿主机目录的功能,效果也和虚拟机几乎一样,用起来很方便,只需要在 docker run 命令启动容器的时候使用 -v 参数就行,具体的格式是“宿主机路径: 容器内路径”。
我还是以 Redis 为例,启动容器,使用 -v 参数把本机的“/tmp”目录挂载到容器里的“/tmp”目录,也就是说让容器共享宿主机的“/tmp”目录:
docker run -d --rm -v /tmp:/tmp redis
然后我们再用 docker exec 进入容器,查看一下容器内的“/tmp”目录,应该就可以看到文件与宿主机是完全一致的。
docker exec -it b5a sh # b5a是容器I
你也可以在容器里的“/tmp”目录下随便做一些操作,比如删除文件、建立新目录等等,再回头观察一下宿主机,会发现修改会即时同步,这就表明容器和宿主机确实已经共享了这个目录。
-v 参数挂载宿主机目录的这个功能,对于我们日常开发测试工作来说非常有用,我们可以在不变动本机环境的前提下,使用镜像安装任意的应用,然后直接以容器来运行我们本地的源码、脚本,非常方便。
这里我举一个简单的例子。比如我本机上只有 Python 2.7,但我想用 Python 3 开发,如果同时安装 Python 2 和 Python 3 很容易就会把系统搞乱,所以我就可以这么做:
- 先使用 docker pull 拉取一个 Python 3 的镜像,因为它打包了完整的运行环境,运行时有隔离,所以不会对现有系统的 Python 2.7 产生任何影响。
- 在本地的某个目录编写 Python 代码,然后用 -v 参数让容器共享这个目录。
- 现在就可以在容器里以 Python 3 来安装各种包,再运行脚本做开发了。
docker pull python:alpine
docker run -it --rm -v `pwd`:/tmp python:alpine sh
显然,这种方式比把文件打包到镜像或者 docker cp 会更加灵活,非常适合有频繁修改的开发测试工作。
3.如何实现网络互通
现在我们使用 docker cp 和 docker run -v 可以解决容器与外界的文件互通问题,但对于 Nginx、Redis 这些服务器来说,网络互通才是更要紧的问题。
网络互通的关键在于“打通”容器内外的网络,而处理网络通信无疑是计算机系统里最棘手的工作之一,有许许多多的名词、协议、工具,在这里我也没有办法一下子就把它都完全说清楚,所以只能从“宏观”层面讲个大概,帮助你快速理解。
Docker 提供了三种网络模式,分别是 null、host 和 bridge。
1.null 是最简单的模式,也就是没有网络,但允许其他的网络插件来自定义网络连接,这里就不多做介绍了。
2.host 的意思是直接使用宿主机网络,相当于去掉了容器的网络隔离(其他隔离依然保留),所有的容器会共享宿主机的 IP 地址和网卡。这种模式没有中间层,自然通信效率高,但缺少了隔离,运行太多的容器也容易导致端口冲突。
host 模式需要在 docker run 时使用 --net=host 参数,下面我就用这个参数启动 Nginx:
docker run -d --rm --net=host nginx:alpine
为了验证效果,我们可以在本机和容器里分别执行 ip addr 命令,查看网卡信息:
ip addr # 本机查看网卡docker exec xxx ip addr # 容器查看网卡
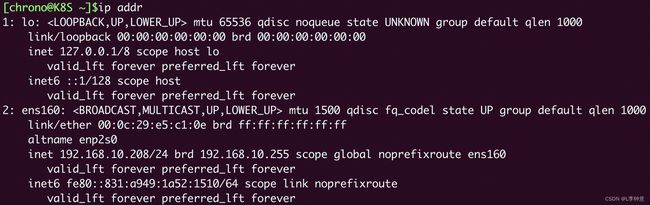
可以看到这两个 ip addr 命令的输出信息是完全一样的,比如都是一个网卡 ens160,IP 地址是“192.168.10.208”,这就证明 Nginx 容器确实与本机共享了网络栈。
第三种 bridge,也就是桥接模式,它有点类似现实世界里的交换机、路由器,只不过是由软件虚拟出来的,容器和宿主机再通过虚拟网卡接入这个网桥(图中的 docker0),那么它们之间也就可以正常的收发网络数据包了。不过和 host 模式相比,bridge 模式多了虚拟网桥和网卡,通信效率会低一些。

和 host 模式一样,我们也可以用 --net=bridge 来启用桥接模式,但其实并没有这个必要,因为 Docker 默认的网络模式就是 bridge,所以一般不需要显式指定。
下面我们启动两个容器 Nginx 和 Redis,就像刚才说的,没有特殊指定就会使用 bridge 模式:
docker run -d --rm nginx:alpine # 默认使用桥接模式
docker run -d --rm redis # 默认使用桥接模式
然后我们还是在本机和容器里执行 ip addr 命令(Redis 容器里没有 ip 命令,所以只能在 Nginx 容器里执行):

对比一下刚才 host 模式的输出,就可以发现容器里的网卡设置与宿主机完全不同,eth0 是一个虚拟网卡,IP 地址是 B 类私有地址“172.17.0.2”。
我们还可以用 docker inspect 直接查看容器的 ip 地址:
docker inspect xxx |grep IPAddress
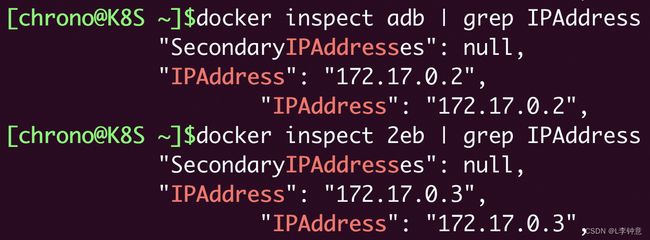
这显示出两个容器的 IP 地址分别是“172.17.0.2”和“172.17.0.3”,而宿主机的 IP 地址则是“172.17.0.1”,所以它们都在“172.17.0.0/16”这个 Docker 的默认网段,彼此之间就能够使用 IP 地址来实现网络通信了。
4.如何分配服务端口号
使用 host 模式或者 bridge 模式,我们的容器就有了 IP 地址,建立了与外部世界的网络连接,接下来要解决的就是网络服务的端口号问题。
你一定知道,服务器应用都必须要有端口号才能对外提供服务,比如 HTTP 协议用 80、HTTPS 用 443、Redis 是 6379、MySQL 是 3306。在学习编写 Dockerfile 的时候也看到过,可以用 EXPOSE 指令声明容器对外的端口号。
一台主机上的端口号数量是有限的,而且多个服务之间还不能够冲突,但我们打包镜像应用的时候通常都使用的是默认端口,容器实际运行起来就很容易因为端口号被占用而无法启动。
解决这个问题的方法就是加入一个“中间层”,由容器环境例如 Docker 来统一管理分配端口号,在本机端口和容器端口之间做一个“映射”操作,容器内部还是用自己的端口号,但外界看到的却是另外一个端口号,这样就很好地避免了冲突。
端口号映射需要使用 bridge 模式,并且在 docker run 启动容器时使用 -p 参数,形式和共享目录的 -v 参数很类似,用 : 分隔本机端口和容器端口。比如,如果要启动两个 Nginx 容器,分别跑在 80 和 8080 端口上:
docker run -d -p 80:80 --rm nginx:alpine
docker run -d -p 8080:80 --rm nginx:alpine
这样就把本机的 80 和 8080 端口分别“映射”到了两个容器里的 80 端口,不会发生冲突,我们可以用 curl 再验证一下:
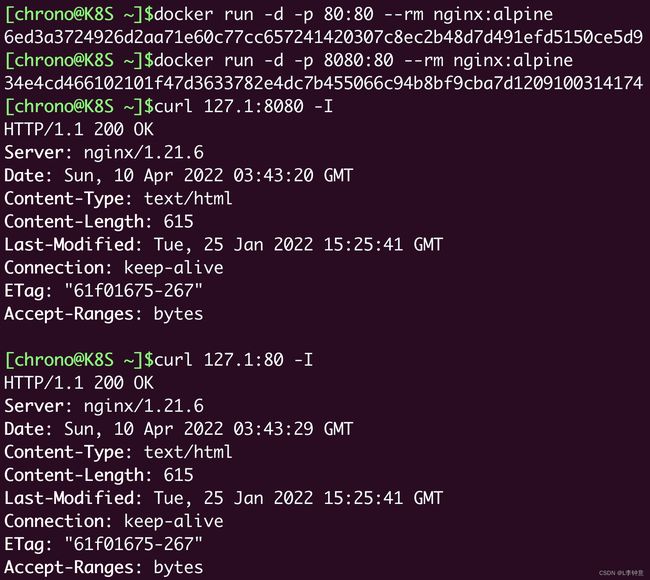
使用 docker ps 命令能够在“PORTS”栏里更直观地看到端口的映射情况:
![]()
5.小结
今天学习了容器与外部系统之间沟通交流的几种方法。
你会发现,这些方法几乎消除了容器化的应用和本地应用因为隔离特性而产生的差异,而因为镜像独特的打包机制,容器技术显然能够比 apt/yum 更方便地安装各种应用,绝不会“污染”已有的系统。
我们也可以把 Redis、MySQL、Node.js 都运行起来,让容器成为我们工作中的得力助手。
- docker cp 命令可以在容器和主机之间互相拷贝文件,适合简单的数据交换。
- docker run -v 命令可以让容器和主机共享本地目录,免去了拷贝操作,提升工作效率。
- host 网络模式让容器与主机共享网络栈,效率高但容易导致端口冲突。
- bridge 网络模式实现了一个虚拟网桥,容器和主机都在一个私有网段内互联互通。
- docker run -p 命令可以把主机的端口号映射到容器的内部端口号,解决了潜在的端口冲突问题。
思考:
1.docker cp 命令和第 4 讲 Dockerfile 里的 COPY 指令有什么区别吗?
2.你觉得 host 模式和 bridge 模式各有什么优缺点,在什么场景下应用最合适?
答:
1.第四节的copy命令是在容器启动过程中的COPY命令,该命令应该是在声明了“namespace”之后,所以这个时候进程看到的世界是一个隔离的环境;而这里的COPY更像是站在“上帝视角(宿主机操作系统层面)”进行拷贝,所以这里不受“namespace”的约束;(copy 拷贝的文件会新增镜像层,从而是永久性的,而docker cp只会临时存在)
2.host就是简单粗暴效率高,适合小规模集群的简单拓扑结构;bridge适合大规模集群,有了bridge就有更多的可操作空间,比如XLAN和VXLAN这些,它可以提供更多的可定制化服务,比如流量控制、灰度策略这些,从而像flannel和Calico这些组件才有了更多的发挥余地。
七、玩转Docker
要提醒你的是,Docker 相关的内容很多很广,在入门篇中,我只从中挑选出了一些最基本最有用的介绍给你。而且在我看来,我们不需要完全了解 Docker 的所有功能,我也不建议你对 Docker 的内部架构细节和具体的命令行参数做过多的了解,太浪费精力,只要会用够用,需要的时候能够查找官方手册就行。
我先把容器技术做一个简要的总结,然后演示两个实战项目:使用 Docker 部署 Registry 和 WordPress。
1.容器技术要点回顾
容器技术是后端应用领域的一项重大创新,它彻底变革了应用的开发、交付与部署方式,是“云原生”的根本
容器基于 Linux 底层的 namespace、cgroup、chroot 等功能,虽然它们很早就出现了,但直到 Docker“横空出世”,把它们整合在一起,容器才真正走近了大众的视野,逐渐为广大开发者所熟知
容器技术中有三个核心概念:容器(Container)、镜像(Image),以及镜像仓库(Registry)

从本质上来说,容器属于虚拟化技术的一种,和虚拟机(Virtual Machine)很类似,都能够分拆系统资源,隔离应用进程,但容器更加轻量级,运行效率更高,比虚拟机更适合云计算的需求。
镜像是容器的静态形式,它把应用程序连同依赖的操作系统、配置文件、环境变量等等都打包到了一起,因而能够在任何系统上运行,免除了很多部署运维和平台迁移的麻烦。
镜像内部由多个层(Layer)组成,每一层都是一组文件,多个层会使用 Union FS 技术合并成一个文件系统供容器使用。这种细粒度结构的好处是相同的层可以共享、复用,节约磁盘存储和网络传输的成本,也让构建镜像的工作变得更加容易
为了方便管理镜像,就出现了镜像仓库,它集中存放各种容器化的应用,用户可以任意上传下载,是分发镜像的最佳方式
目前最知名的公开镜像仓库是 Docker Hub,其他的还有 quay.io、gcr.io,我们可以在这些网站上找到许多高质量镜像,集成到我们自己的应用系统中。
容器技术有很多具体的实现,Docker 是最初也是最流行的容器技术,它的主要形态是运行在 Linux 上的“Docker Engine”。我们日常使用的 docker 命令其实只是一个前端工具,它必须与后台服务“Docker daemon”通信才能实现各种功能。
操作容器的常用命令有 docker ps、docker run、docker exec、docker stop 等;操作镜像的常用命令有 docker images、docker rmi、docker build、docker tag 等;操作镜像仓库的常用命令有 docker pull、docker push 等。
好简单地回顾了容器技术,下面我们就来综合运用在“入门篇”所学到的各个知识点,开始实战演练,玩转 Docker。
2. 搭建私有镜像仓库
在第 5 节 Docker Hub 的时候曾经说过,在离线环境里,我们可以自己搭建私有仓库。但因为镜像仓库是网络服务的形式,当时还没有学到容器网络相关的知识,所以只有到了现在,我们具备了比较完整的 Docker 知识体系,才能够搭建私有仓库。
私有镜像仓库有很多现成的解决方案,今天我只选择最简单的 Docker Registry,而功能更完善的 CNCF Harbor 留到后续学习 Kubernetes 时再介绍。
你可以在 Docker Hub 网站上搜索“registry”,找到它的官方页面 https://registry.hub.docker.com/_/registry/
Docker Registry 的网页上有很详细的说明,包括下载命令、用法等,我们可以完全照着它来操作。
首先,你需要使用 docker pull 命令拉取镜像:
docker pull registry
然后,我们需要做一个端口映射,对外暴露端口,这样 Docker Registry 才能提供服务。它的容器内端口是 5000,简单起见,我们在外面也使用同样的 5000 端口,所以运行命令就是 docker run -d -p 5000:5000 registry :
docker run -d -p 5000:5000 registry
启动 Docker Registry 之后,你可以使用 docker ps 查看它的运行状态,可以看到它确实把本机的 5000 端口映射到了容器内的 5000 端口。
![]()
接下来,我们就要使用 docker tag 命令给镜像打标签再上传了。因为上传的目标不是默认的 Docker Hub,而是本地的私有仓库,所以镜像的名字前面还必须再加上仓库的地址(域名或者 IP 地址都行),形式上和 HTTP 的 URL 非常像。
比如在这里,我就把“nginx:alpine”改成了“127.0.0.1:5000/nginx:alpine”:
docker tag nginx:alpine 127.0.0.1:5000/nginx:alpine
现在,这个镜像有了一个附加仓库地址的完整名字,就可以用 docker push 推上去了:
docker push 127.0.0.1:5000/nginx:alpine
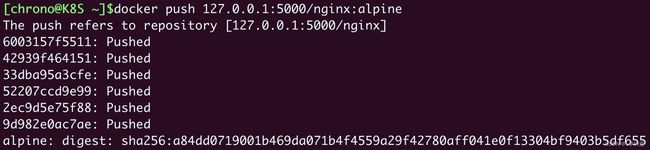
为了验证是否已经成功推送,我们可以把刚才打标签的镜像删掉,再重新下载:
docker rmi 127.0.0.1:5000/nginx:alpine
docker pull 127.0.0.1:5000/nginx:alpine

这里 docker pull 确实完成了镜像下载任务,不过因为原来的层原本就已经存在,所以不会有实际的下载动作,只会创建一个新的镜像标签。
Docker Registry 虽然没有图形界面,但提供了 RESTful API,也可以发送 HTTP 请求来查看仓库里的镜像,具体的端点信息可以参考官方文档(https://docs.docker.com/registry/spec/api/),下面的这两条 curl 命令就分别获取了镜像列表和 Nginx 镜像的标签列表:
curl 127.1:5000/v2/_catalog
curl 127.1:5000/v2/nginx/tags/list

可以看到,因为应用被封装到了镜像里,所以我们只用简单的一两条命令就完成了私有仓库的搭建工作,完全不需要复杂的软件安装、环境设置、调试测试等繁琐的操作,这在容器技术出现之前简直是不可想象的。
3.搭建 WordPress 网站
Docker Registry 应用比较简单,只用单个容器就运行了一个完整的服务,下面我们再来搭建一个有点复杂的 WordPress 网站。
网站需要用到三个容器:WordPress、MariaDB、Nginx,它们都是非常流行的开源项目,在 Docker Hub 网站上有官方镜像,网页上的说明也很详细,所以具体的搜索过程我就略过了,直接使用 docker pull 拉取它们的镜像:
docker pull wordpress:5
docker pull mariadb:10
docker pull nginx:alpine
我画了一个简单的网络架构图,你可以直观感受一下它们之间的关系:
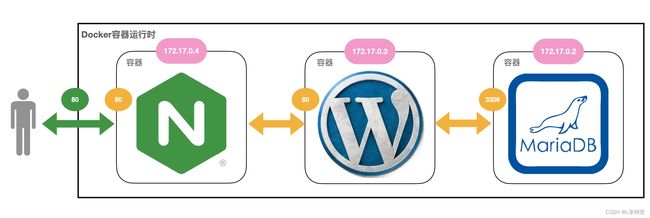
这个系统可以说是比较典型的网站了。MariaDB 作为后面的关系型数据库,端口号是 3306;WordPress 是中间的应用服务器,使用 MariaDB 来存储数据,它的端口是 80;Nginx 是前面的反向代理,它对外暴露 80 端口,然后把请求转发给 WordPress。
我们先来运行 MariaDB。根据说明文档,需要配置“MARIADB_DATABASE”等几个环境变量,用 --env 参数来指定启动时的数据库、用户名和密码,这里我指定数据库是“db”,用户名是“wp”,密码是“123”,管理员密码(root password)也是“123”。
下面就是启动 MariaDB 的 docker run 命令:
docker run -d --rm \
--env MARIADB_DATABASE=db \
--env MARIADB_USER=wp \
--env MARIADB_PASSWORD=123 \
--env MARIADB_ROOT_PASSWORD=123 \
mariadb:10
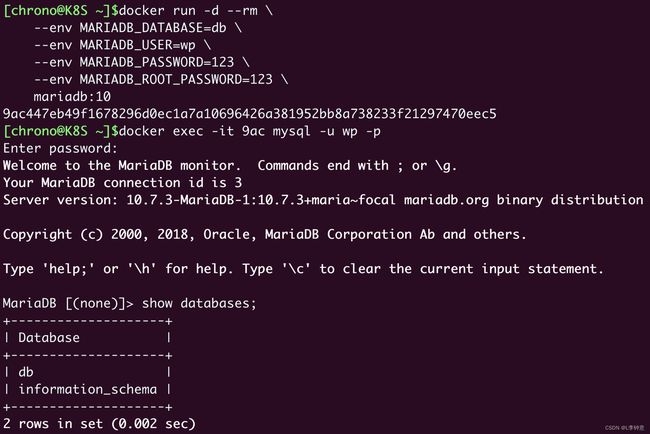
启动之后,我们还可以使用 docker exec 命令,执行数据库的客户端工具“mysql”,验证数据库是否正常运行:
docker exec -it 9ac mysql -u wp -p
输入刚才设定的用户名“wp”和密码“123”之后,我们就连接上了 MariaDB,可以使用 show databases; 和 show tables; 等命令来查看数据库里的内容。当然,现在肯定是空的。

因为 Docker 的 bridge 网络模式的默认网段是“172.17.0.0/16”,宿主机固定是“172.17.0.1”,而且 IP 地址是顺序分配的,所以如果之前没有其他容器在运行的话,MariaDB 容器的 IP 地址应该就是“172.17.0.2”,这可以通过 docker inspect 命令来验证:
docker inspect 9ac |grep IPAddress

现在数据库服务已经正常,该运行应用服务器 WordPress 了,它也要用 --env 参数来指定一些环境变量才能连接到 MariaDB,注意“WORDPRESS_DB_HOST”必须是 MariaDB 的 IP 地址,否则会无法连接数据库:
docker run -d --rm \
--env WORDPRESS_DB_HOST=172.17.0.2 \
--env WORDPRESS_DB_USER=wp \
--env WORDPRESS_DB_PASSWORD=123 \
--env WORDPRESS_DB_NAME=db \
wordpress:5
WordPress 容器在启动的时候并没有使用 -p 参数映射端口号,所以外界是不能直接访问的,我们需要在前面配一个 Nginx 反向代理,把请求转发给 WordPress 的 80 端口。
配置 Nginx 反向代理必须要知道 WordPress 的 IP 地址,同样可以用 docker inspect 命令查看,如果没有什么意外的话它应该是“172.17.0.3”,所以我们就能够写出如下的配置文件(Nginx 的用法可参考其他资料,这里就不展开讲了):
server {
listen 80;
default_type text/html;
location / {
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_pass http://172.17.0.3;
}
}
有了这个配置文件,最关键的一步就来了,我们需要用 -p 参数把本机的端口映射到 Nginx 容器内部的 80 端口,再用 -v 参数把配置文件挂载到 Nginx 的“conf.d”目录下。这样,Nginx 就会使用刚才编写好的配置文件,在 80 端口上监听 HTTP 请求,再转发到 WordPress 应用:
docker run -d --rm \
-p 80:80 \
-v `pwd`/wp.conf:/etc/nginx/conf.d/default.conf \
nginx:alpine
三个容器都启动之后,我们再用 docker ps 来看看它们的状态:

可以看到,WordPress 和 MariaDB 虽然使用了 80 和 3306 端口,但被容器隔离,外界不可见,只有 Nginx 有端口映射,能够从外界的 80 端口收发数据,网络状态和我们的架构图是一致的。
现在整个系统就已经在容器环境里运行好了,我们来打开浏览器,输入本机的“127.0.0.1”或者是虚拟机的 IP 地址(我这里是“http://192.168.10.208”),就可以看到 WordPress 的界面:
在创建基本的用户、初始化网站之后,我们可以再登录 MariaDB,看看是否已经有了一些数据:
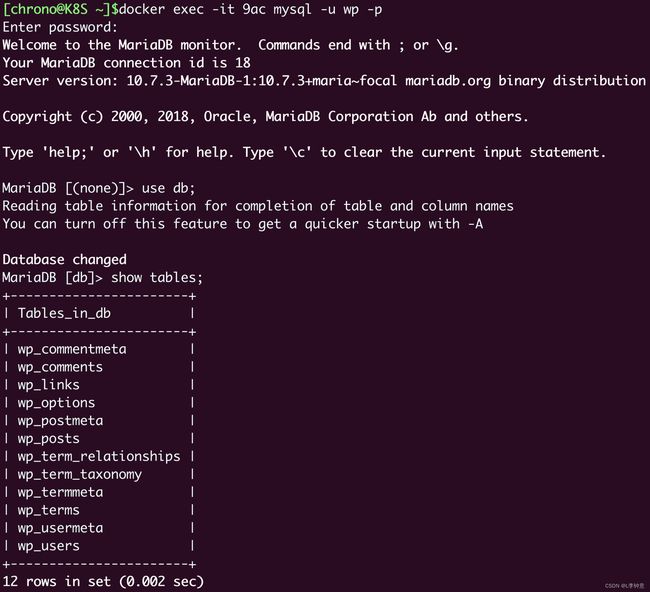
可以看到,WordPress 已经在数据库里新建了很多的表,这就证明我们的容器化的 WordPress 网站搭建成功。
4.小结
好了,今天先简单地回顾了一下容器技术,这里有一份思维导图,是对前面所有容器知识要点的总结,你可以对照着用来复习。
我们还使用 Docker 实际搭建了两个服务:Registry 镜像仓库和 WordPress 网站。
通过这两个项目的实战演练,你应该能够感受到容器化对后端开发带来的巨大改变,它简化了应用的打包、分发和部署,简单的几条命令就可以完成之前需要编写大量脚本才能完成的任务,对于开发、运维来绝对是一个“福音”。
不过,在感受容器便利的同时,你有没有注意到它还是存在一些遗憾呢?比如说:
- 我们还是要手动运行一些命令来启动应用,然后再人工确认运行状态。
- 运行多个容器组成的应用比较麻烦,需要人工干预(如检查 IP 地址)才能维护网络通信。
- 现有的网络模式功能只适合单机,多台服务器上运行应用、负载均衡该怎么做?
- 如果要增加应用数量该怎么办?这时容器技术完全帮不上忙。
其实,如果我们仔细整理这些运行容器的 docker run 命令,写成脚本,再加上一些 Shell、Python 编程来实现自动化,也许就能够得到一个勉强可用的解决方案。
这个方案已经超越了容器技术本身,是在更高的层次上规划容器的运行次序、网络连接、数据持久化等应用要素,也就是现在我们常说的“容器编排”(Container Orchestration)的雏形,也正是后面要学习的 Kubernetes 的主要出发点。
思考:
1.你觉得容器编排应该解决哪些方面的问题?
答:
容器编排主要应用于大规模集成应用。可以类比分布式系统,但是规模一旦变大到系统层面,就会出现一些问题,比如如何保证数据一致性?如何保证负载均衡?如何尽可能减少网络故障所带来的影响?如何能保证数据(容器)的持久化等等。。。这些问题需要运用容器编排来解决