Hive:窗口函数
一、窗口函数是什么
二、窗口函数分类
一、累计计算窗口函数
1、sum() over()
在工作中经常遇到计算截止某月的累计数值,此时需要用sum()开窗
比如给一张交易表user_trade:
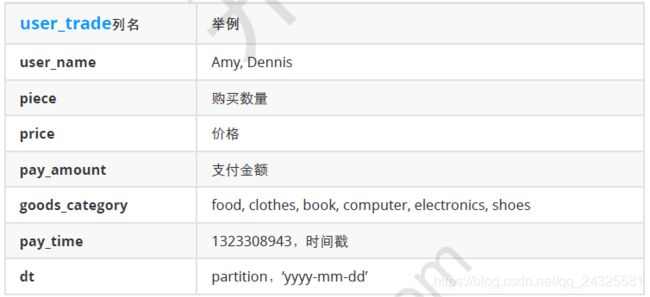
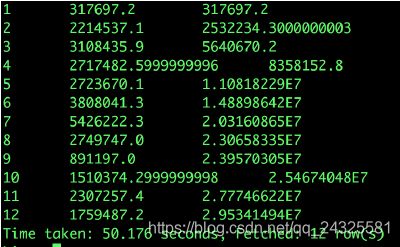
现在需要计算出2018年每月的支付总额和当年累计支付总额:
select
a.month,
a.pay_amount,
sum(pay_amount) over(order by month) pay_amount
from(
select
month(dt) month,
sum(pay_amount) pay_amount
from
user_trade
where year(dt)=2018
group by month(dt)
) a;
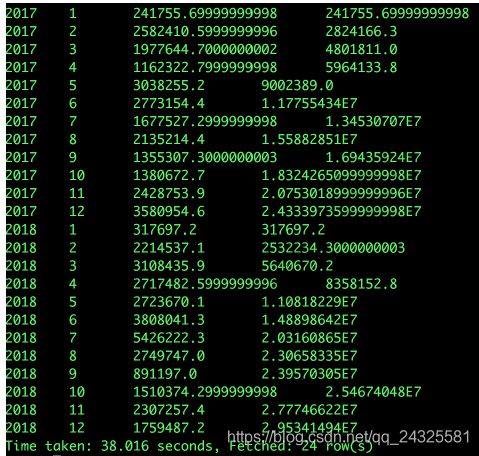
现在需要计算出2017-2018年每月的支付总额和当年累积支付总额:
select
a.year,
a.month,
a.pay_amount,
sum(a.pay_amount) over(partition by a.year order by a.month)
from
(
select
year(dt) year,
month(dt) month,
sum(pay_amount) pay_amount
from
user_trade
where year(dt) in (2017,2018)
group by year(dt),month(dt)
)a;
注意:
1、partition by : 起到了分组的作用
2、order by:按照什么顺序进行累加,升序ASC,降序DESC,默认升序
2、avg() over()
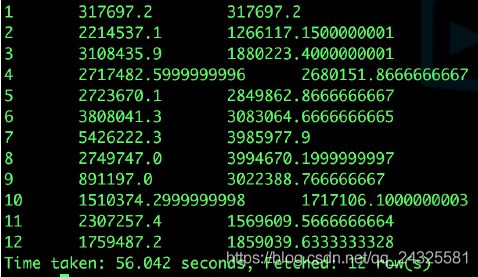
现在需要计算2018年每个月的近3个月的平均支付金额:
select
a.month,
a.pay_amount,
avg(a.pay_amount) over(order by a.month rows between 2 preceding and current row)
from
(select
month(dt) month,
sum(pay_amount) pay_amount
from
user_trade
where year(dt)=2018
group by month(dt)
)a;
3、语法总结
sum(…A…) over(partition by …B… order by …C… rows between …D1… and …D2…)
avg(…A…) over(partition by …B… order by …C… rows between …D1… and …D2…)
A:需要被加工的字段名称
B:分组的字段名称
C:排序的字段名称
D:计算的行数范围
rows between unbounded preceding and current row :代表包括本行和之前所有的行
rows between current row and unbounded following :包括本行和之后所有的行
rows between 3 preceding and current row : 包括本行以内和前三行
rows between 3 preceding and 1 following:从前三行到下一行(一共5行)
二、分区排序窗口函数
分区排序窗口函数有三个,分别是:
1、row_number() over(partition by A order by B)
2、rank() over(partition by A order by B)
3、dense_rank() over(partition by A order by B)
其中A代表分区的字段名称,B代表排序的字段名称
三者区别:
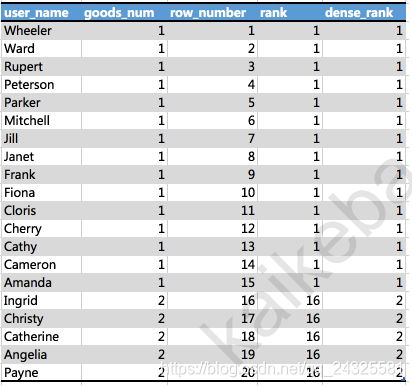
row_number:它会为查询出来的每一行记录生成一个序号,依次排序且不会重复
rank:排序后的记录值相同的都标记相同的序号,临近的不相同的记录值按之前相同的记录值的个数加1,就是rank排序之后的序号是不连续的
dense_rank:排序后的记录值相同的都标记相同的序号,临近不相同的记录值也按照之前的序号加1,也就是这个排序后的序号总是连续的
例:现在需要计算2019年1月,用户购买的商品品类数量的排名
select
user_name,
count(distinct goods_category),
row_number() over(order by count(distinct goods_category)),
rank() over(order by count(distinct goods_category)),
dense_rank() over(order by count(distinct goods_category))
from
user_trade
where substr(dt,1,7)='2019-01'
group by user_name;
例:选出2019年支付金额排名在第10、20、30名的用户
select
a.user_name,
a.pay_amount,
a.rank
from
(
select
user_name,
sum(pay_amount) pay_amount,
rank() over(order by sum(pay_amount) desc) rank
from
user_trade
where year(dt)=2019
group user_name
)a where a.rank in (10,20,30);

三、分组排序窗口函数
ntile(n) over(partition by …A… order by …B…)
n:切分的片数
A:分组的字段名称
B:排序的字段名称
注意:
1、ntile(n):用于将分组数据按照顺序分成n片,返回当前切片值
2、ntile不支持rows between
3、如果切片不均匀,默认增加第一个分片的分布
例:将2019年1月的支付用户,按照支付金额分成5组
select
user_name,
sum(pay_amount) pay_amount,
ntile(5) over(order by sum(pay_amount) desc) level
from
user_trade
where substr(dt,1,7)='2019-01'
group by user_name;
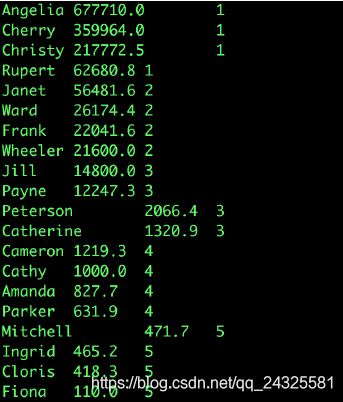
例:选出2019年退款金额排名前10%的用户
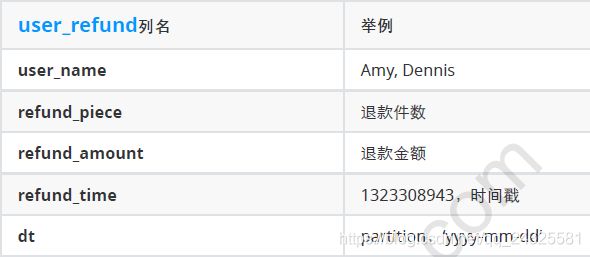
select
a.user_name,
a.refund_amount,
a.level
from
(
select
user_name,
sum(refund_amount) refund_amount,
ntile(10) over(order by sum(refund_amount) desc) level
from
user_refund
where year(dt)=2019
group by user_name
)a
where a.level=1;
四、偏移分析窗口函数
1、lag(…) over(…)
2、lead(…) over(…)
Lag和Lead分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列。
在实际应用当中,若要用到取今天和昨天的某字段差值时,Lag和Lead函数的应用就显得尤为重要。
lag(exp_str,offset,defval) over(partiton by … order by …)
lead(exp_str,offset,defval) over(partition by … order by …)
1、exp_str是字段名称
2、offset是偏移量。当使用lag时,假设当前行在表中排在第5行,而offset为3,则表示我们所要找的数据行就是表中的第2行(即5-3=2)。默认值为1。
3、defval是默认值。当两个函数取上N或下N个值时,当在表中从当前行向前数N行已经超出了表的范围时,就defval作为函数的返回值,若没有指定返回值,则返回NULL。
例如:用户Alice和Alexander的各种时间偏移
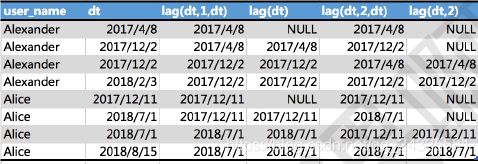
1、lag()
select
user_name,
dt,
lag(dt,1,dt) over(partition by user_name order by dt),
lag(dt) over(partition by user_name order by dt),
lag(dt,2,dt) over(partition by user_name order by dt),
lag(dt,2) over(partition by user_name order by dt)
from
user_trade
where dt>'0' and user_name in ('Alice','Alexander');
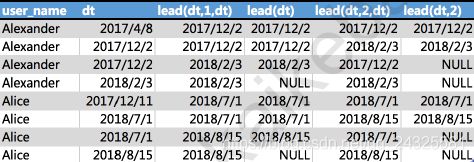
2、lead()
select
user_name,
dt,
lead(dt,1,dt) over(partition by user_name order by dt),
lead(dt) over(partition by user_name order by dt),
lead(dt,2,dt) over(partition by user_name order by dt),
lead(dt,2) over(partition by user_name order by dt)
from
user_trade
where dt>'0' and user_name in ('Alice','Alexander');
例:支付时间间隔超过100天的用户数
select
count(distinct user_name)
from
(
select
user_name,
dt,
lead(dt) over(partition by user_name order by dt) lead_dt
from
user_trade
where dt>'0'
)a
where a.lead_dt is not null
and datediff(a.lead_dt,a.dt)>100;
三、练习
四、参考文章
上述部分数据及sql参考自开课吧视频,视频链接丢失
Hive 窗口函数