爬虫提取规则之正则表达式的使用
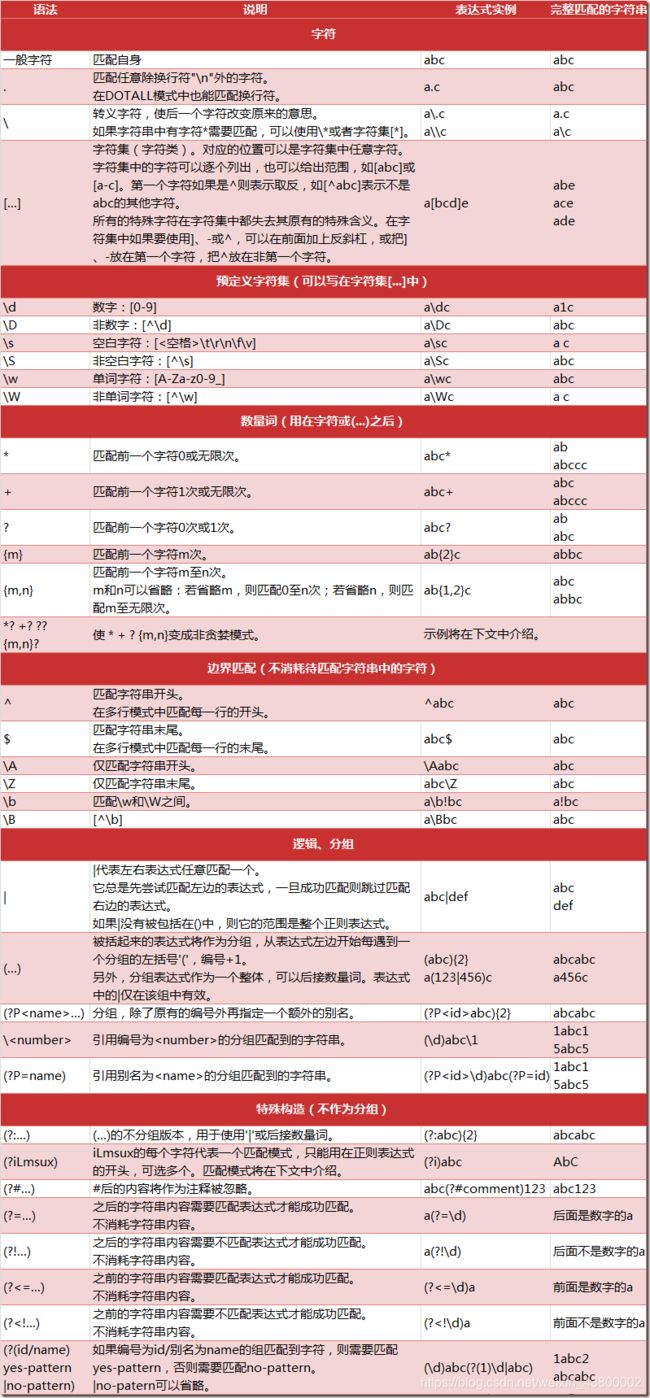
Re模式:
re.match函数
re.match(pattern, string, flags=0)
pattern 匹配的正则表达式
string 要匹配的字符串。
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
flags做为可选值如下
• re.I(全拼:IGNORECASE): 忽略大小写(括号内是完整写法,下同)
• re.M(全拼:MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
• re.S(全拼:DOTALL): 点任意匹配模式,改变'.'的行为
• re.L(全拼:LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
• re.U(全拼:UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
• re.X(全拼:VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
这种必须在字符串的起始位置就开始匹配,如果从字符串的任意非起始位置开始匹配的话match()就返回none。
>>> print(re.match('www', 'www.baidu.com'))
<re.Match object; span=(0, 3), match='www'>
>>> print(re.match('baidu', 'www.baidu.com'))
None
其中group()可以用来提取字符串
group() 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
groups()返回一个包含所有小组字符串的元组,从 1 到所含的小组号。
>>> import re
>>> line = "Stay foolish,stay hungry"
>>> matchObj = re.match( r'(.*),(.*?) .*', line, re.S)
>>> print ("matchObj.group(2) : ", matchObj.group(2))
matchObj.group(1) : stay
>>> print ("matchObj.group(1) : ", matchObj.group(1))
matchObj.group(1) : Stay foolish
>>> print ("matchObj.groups(1) : ", matchObj.groups(1))
matchObj.groups(1) : ('Stay foolish', 'stay') //注意这里的
group()和groups()是不同的
>>> print ("matchObj.group() : ", matchObj.group())
matchObj.group() : Stay foolish,stay hungry
re.serach函数
从整个字符串的任意位置开始匹配
re.search(pattern, string, flags=0)
同理上述的re.match,唯一的区别就是匹配的位置不同,字符串得到的结果不同。
>>> print(re.search('www', 'www.baidu.com'))
<re.Match object; span=(0, 3), match='www'>
>>> print(re.search('baidu', 'www.baidu.com'))
<re.Match object; span=(4, 9), match='baidu'>
re.sub函数
re.sub(pattern, repl, string, count=0, flags=0)
前三个为必选参数,后两个为可选参数。
pattern : 正则中的模式字符串。
repl : 替换后的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认0表示替换所有的匹配。
flags : 编译时用的匹配模式,数字形式。
#!/usr/bin/python3
import re
phone = "2004-959-559 # 这是一个电话号码"
# 删除注释
num = re.sub(r'#.*$', "", phone)
print ("电话号码 : ", num)
# 移除非数字的内容
num = re.sub(r'\D', "", phone)
print ("电话号码 : ", num)
re.compile函数
re.compile(pattern[, flags])
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
re.findall函数
re.findall(string[, pos[, endpos]])
string 待匹配的字符串。
pos 可选参数,指定字符串的起始位置,默认为 0。
endpos 可选参数,指定字符串的结束位置,默认为字符串的长度。
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
import re
pattern = re.compile(r'\d+')
print re.findall(pattern,'1one2two3three')
输出为
['1', '2', '3']