基于虚幻引擎的AI训练合成数据生成

推荐:用 NSDT编辑器 快速搭建可编程3D场景
近年来,合成数据生成(Synthetic Data Generation)已成为手动收集和注释数据集的替代方法。
数据合成器的优点主要有两个。 首先,它使获取数据的成本几乎为零,同时消除了几乎所有的数据处理工作。 其次,即使在没有数据的情况下,它也有可能实现新机器学习想法的快速原型设计。
简而言之,一个结构良好的合成数据生成器可以为任何机器学习案例生成现成格式的数据。 然而,合成数据生成器面临的挑战是,它们通常是特定领域的,应用范围狭窄,并且远不如网络架构和学习方法成熟。
在计算机视觉领域,合成数据生成特别有趣,因为多年来相关资源和工具的数量不断增长和显着改进。 不过,这种发展并不是在机器学习领域,而是在虚幻引擎、Blender 和 Unity 等游戏引擎领域。 通常由专业设计师制作,逼真的场景提供了精彩的细节,如下面的视频所示。

视频 1:在虚幻引擎中徒步游览
Modulai 已在多个项目中部署了经过合成数据训练的模型,现在寻求了解 3D 渲染数据在解决计算机视觉任务方面的潜力。 具体来说,在这个项目中,任务是使用虚幻引擎生成由文本组成的合成数据图像。 这些数据将用于训练网络,旨在检测从真实环境捕获的图像中的文本。
1、使用静态背景合成场景文本数据
场景文本检测应用程序已经采用了合成数据的使用。 几乎所有最先进的网络都是根据合成数据进行预训练,然后根据真实数据进行微调。 用于预训练的最常见的合成数据集是 SynthText 数据集 [1]。 该数据集是由 8,000 张背景图像生成的。 通过在背景图像的不同位置粘贴各种颜色、字体和大小的文本,生成了80万张图像的数据集。 以下是 SynthText 数据集中的两个示例。

图 1:使用背景图像获得的场景文本数据
SynthText 提供了生成场景文本数据的基本方法和一组原则。 最重要的一点是文本的嵌入方式应该尽可能自然。 因此,渲染引擎旨在生成逼真的场景文本图像,其中使用语义分割和深度估计将文本混合到背景图像的合适区域中。 在图 2 中,合适的区域和不合适的区域都被可视化。

图 2:合适(左)和不合适(右)文本区域的示例。
将文本粘贴到背景图像上的过程会导致场景与人类在现实世界环境中自然观察到的场景不同。 从现实世界获得的文本可能具有视点、照明条件和遮挡的变化。 通过将文本插入 2D 背景图像很难产生这些变化。
2、使用 3D 引擎合成场景文本数据
随着游戏引擎缩小现实世界和合成世界之间的差距,探索基于游戏引擎的合成数据生成的可能性是很自然的。 游戏引擎的优点首先是可以通过将场景和文本作为一个整体渲染来实现现实世界的变化。 此外,3D 引擎提供真实场景信息,从而产生更真实的文本区域,并具有许多优点。
该项目使用游戏引擎Unreal Engine 4。当使用游戏引擎渲染场景文本图像时,[2]的工作提供了四个模块。 这些模块为游戏引擎获取带有文本的图像提供了基线,按以下顺序执行。
- 取景器:数据生成器用取景器初始化,自动确定场景中适合文本渲染的一组坐标。 这是通过在 3D 场景中移动相机来完成的。
- 环境随机化:在取景器之后,应用环境随机化。 该模块的目的是通过随机化场景中的参数来增加生成图像的多样性。
- 文本区域生成:然后使用文本区域生成模块来查找环境参数随机化的有效视点的文本区域。 第一阶段是基于 2D 场景信息提出文本区域。 然后使用从游戏引擎获得的 3D 信息完善最初的建议。
- 文本渲染:最后,应用文本渲染模块,其目的是生成文本实例并将其渲染到场景中。 此外,包含文本的图像部分的边界框是以标准对象检测格式获得的。
游戏环境和数据生成器之间的链接是通过 UnrealCV 包实现的,这是一个开源项目,使计算机视觉研究人员能够轻松地与虚幻引擎 4 进行交互 [3]。 开始数据生成的要求是具有嵌入式 UnrealCV 插件的场景以及包含文本和字体的语料库。 由于虚幻市场上有各种不同的场景,因此创建自定义数据集的机会无穷无尽。 然而,出于该项目的目的,我们使用[2]提供的现成编译场景。 下图展示了使用来自虚幻引擎市场的场景真实渲染和自定义语料库生成的图像示例。

图 3:使用虚幻引擎 4 渲染的图像
3、网络训练及结果
[4] 中的网络仅针对合成图像以及合成数据和真实数据的组合进行训练。 通过将 3D 引擎生成的数据训练的模型与 SynthText 的性能进行比较,评估 3D 引擎解决场景文本检测问题的有效性。 在评估模型时,使用来自现实世界数据集 ICDAR15 [5] 和 Total-Text [6] 的测试集。
精度和召回率是用于评估网络预测的性能指标。 虽然最佳场景是同时实现高召回率和高精度,但需要决定如何调整模型。 在这项工作中,可以调整文本实例被分类为存在或不存在的概率阈值以获得所需的度量。 通过让阈值范围从 0 到 1,并报告每个阈值获得的精度和召回对,可以获得模型的精度-召回曲线。 从精确率-召回率曲线来看,精确率-召回率曲线下的面积(AUC)可以作为模型的评估工具。
当分别使用 SynthText 和 Unreal 生成的数据训练模型,并在 ICDAR15 和 Total-Text 上评估模型时,得到以下精确率-召回率曲线。
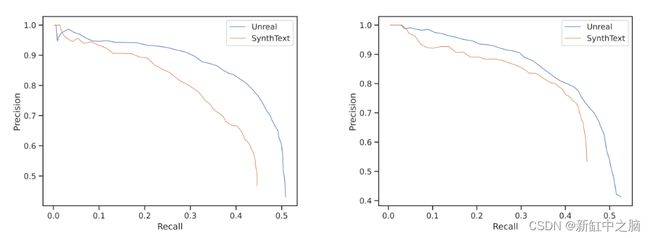
图 4:通过改变在 SynthText 和 Unreal 上训练的模型的推理阈值生成的精确召回图。 左边的模型是在 ICDAR15 上评估的,右边的模型是在 Total-Text 上评估的。
评估 ICDAR15 时,Unreal 模型的 AUC 为 0.45,SynthText 模型的 AUC 为 0.37。 在 Total-Text 上进行评估时,Unreal 模型的 AUC 为 0.45,SynthText 模型的 AUC 为 0.39。 下面显示了对现实世界测试集的预测示例。

图 5:模型推论示例。 左右示例分别利用在 SynthText 和 Unreal 上训练的模型对 ICDAR15 的推断。

图 6:模型推论示例。 左右示例分别利用在 SynthText 和 Unreal 上训练的模型对 Total-Text 的推断。
当用少量真实数据对预训练模型进行微调时,得到的精度-召回率曲线如下。
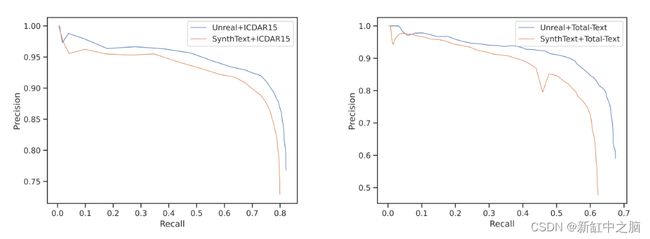
图 7:通过改变在 SynthText 和 Unreal 上训练的模型的推理阈值并使用真实数据进行微调而生成的精确召回图。 左边是在 ICDAR15 上评估模型,右边是在 Total-Text 上评估模型。
在 ICDAR15 上评估模型时,Unreal 模型的 AUC 为 0.77,SynthText 模型的 AUC 为 0.74。 在 Total-Text 上评估模型时,Unreal 模型的近似 AUC 为 0.62,SynthText 模型的近似 AUC 为 0.55。 微调模型的模型预测示例如下所示。

图 8:模型推论示例。 左右示例是分别在 SynthText 和 Unreal 上训练并使用真实数据进行微调的模型对 ICDAR15 的推论。

图 9:模型推论示例。 左右示例是分别在 SynthText 和 Unreal 上训练并使用真实数据进行微调的模型对 Total-Text 的推论。
4、结束语
与基于 2D 数据训练的模型相比,基于 3D 数据训练的网络对真实数据的泛化始终更好。 因此,3D 引擎可以在任何机器学习工程师的工具箱中发挥重要作用。
尽管回答为什么在 3D 数据上训练的模型能够获得更高的精确回忆分数很困难并且超出了本项目的范围,但对于大多数观察者来说,图 3 中的 3D 生成的数据似乎比图 1 中的 2D 生成的数据更真实 . 这表明现实主义确实很重要。 因此,即使游戏制作领域的发展是由对更美观的游戏的需求驱动的,这些游戏弥合了虚拟世界和现实世界之间的差距,但这项工作的结果表明,这些进步也为机器学习提供了巨大的价值。
5、参考文献
[1] Ankush Gupta, Andrea Vedaldi, and Andrew Zisserman. Synthetic data for text localization in natural images. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2315–2324, 2016.
[2] Shangbang Long and Cong Yao. Unrealtext: Synthesizing realistic scene text images from the unreal world. arXiv preprint arXiv:2003.10608, 2020.
[3] Yi Zhang Siyuan Qiao Zihao Xiao Tae Soo Kim Yizhou Wang Alan Yuille Weichao Qiu, Fangwei Zhong. Unrealcv: Virtual worlds for computer vision. ACM Multimedia Open Source Software Competition, 2017.
[4] Minghui Liao, Zhaoyi Wan, Cong Yao, Kai Chen, and Xiang Bai. Real-time scene text detection with differentiable binarization. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 11474–11481, 2020.
[5] Dimosthenis Karatzas, Lluis Gomez-Bigorda, Anguelos Nicolaou, Suman Ghosh, Andrew Bagdanov, Masakazu Iwamura, Jiri Matas, Lukas Neumann, Vijay Ramaseshan Chandrasekhar, Shijian Lu, et al. Icdar 2015 competition on robust reading. In 2015 13th international conference on document analysis and recognition (ICDAR), pages 1156-1160. IEEE, 2015.
[6] Chee Kheng Ch’ng and Chee Seng Chan. Total-text: A comprehensive dataset for scene text detection and recognition. In 2017 14th IAPR international conference on document analysis and recognition (ICDAR), volume 1, pages 935–942. IEEE, 2017.
原文链接:用虚幻引擎生成合成数据 — BimAnt