大数据 | Pyspark基本操作
大数据 | Pyspark基本操作
Apache Spark是新兴的一种快速通用的大规模数据处理引擎。它的优势有三个方面:
- 通用计算引擎 能够运行MapReduce、数据挖掘、图运算、流式计算、SQL等多种框架;
- 基于内存 数据可缓存在内存中,特别适用于需要迭代多次运算的场景;
与Hadoop集成 能够直接读写HDFS中的数据,并能运行在YARN之上。 - Spark是用Scala语言编写的,所提供的API也很好地利用了这门语言的特性,当然作为数据科学的一环,它也可以使用Java和Python编写应用。这里我们将用Python给大家做讲解。
Spark的运行架构基本由三部分组成,包括SparkContext(驱动程序)、ClusterManager(集群资源管理器)和Executor(任务执行进程)。
- SparkContext提交作业,向ClusterManager申请资源;
- ClusterManager会根据当前集群的资源使用情况,进行有条件的FIFO策略:先分配的应用程序尽可能多地获取资源,后分配的应用程序则在剩余资源中筛选,没有合适资源的应用程序只能等待其他应用程序释放资源;
- ClusterManager默认情况下会将应用程序分布在尽可能多的Worker上,这种分配算法有利于充分利用集群资源,适合内存使用多的场景,以便更好地做到数据处理的本地性;另一种则是分布在尽可能少的Worker上,这种适合CPU密集型且内存使用较少的场景;
- Excutor创建后与SparkContext保持通讯,SparkContext分配任务集给Excutor,Excutor按照一定的调度策略执行任务集。
文章目录
- 大数据 | Pyspark基本操作
- 一、数据结构
-
- 1.1 RDD(弹性分布式数据集)
-
- 1.1.1 初始化RDD方法一
- 1.1.2 初始化RDD方法二
- 1.1.3 RDD transformations和actionsmap()
- 1.2 DataFrame
-
- 1.2.1 构建SparkSession
- 1.2.2 创建DataFrame
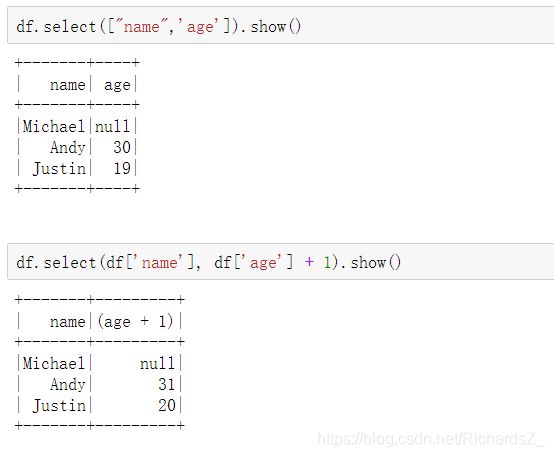
- 1.2.3 DataFrame的操作
一、数据结构
1.1 RDD(弹性分布式数据集)
RDD就像一个NumPy array或者一个Pandas Series,可以视作一个有序的item集合。
只不过这些item并不存在driver端的内存里,而是被分割成很多个partitions,每个partition的数据存在集群的executor的内存中
1.1.1 初始化RDD方法一
如果你本地内存中已经有一份序列数据(比如python的list),你可以通过sc.parallelize去初始化一个RDD
当你执行这个操作以后,list中的元素将被自动分块(partitioned),并且把每一块送到集群上的不同机器上。
import pyspark
from pyspark import SparkContext
from pyspark import SparkConf
conf=SparkConf().setAppName("miniProject").setMaster("local[*]")
sc=SparkContext.getOrCreate(conf)
my_list = [1,2,3,4,5] #存放在当前环境内存当中的list
rdd = sc.parallelize(my_list)
rdd
查看分区状态
rdd.glom().collect()

在这个例子中,是一个4-core的CPU笔记本
Spark创建了4个executor,然后把数据分成4个块
1.1.2 初始化RDD方法二
直接读取本地文件,如csv,txt等。
但注意!!!Spark一般默认你的路径是指向HDFS的,如果你要从本地读取文件的话,给一个file://开头的全局路径。
# File from Pandas exercises
rdd = sc.textFile("file://" + cwd + "/names/yob1880.txt")
rdd
1.1.3 RDD transformations和actionsmap()
| rdd.map(lambda x: func(x)) | 对RDD的每一个item都执行同一个操作 |
| rdd.flatMap(lambda x: x) | 对RDD中的item执行同一个操作以后得到一个list,然后以平铺的方式把这些list里所有的结果组成新的list |
| rdd.filter(lambda x: x>2) | 筛选出来满足条件的item |
| rdd.distinct() | 对RDD中的item去重, 不接受传参 |
| rdd.sample(withReplacement, fraction, seed) | 从RDD中的item中采样一部分出来,有放回或者无放回 |
| rdd.sortBy(lambda x: x[1], ascending=False) | 对RDD中的item进行排序 |
| rdd.join(rdd2) | 根据key值,内连接两个rdd的value;当有两个KeyValue的dataset(K,V)和(K,W),返回的是(K,(V,W))的dataset |
| rdd.leftOuterJoin(rdd2) | 根据左边rdd的key值,将右边rdd的value连接过来; |
| rdd.rightOuterJoin(rdd2) | 根据右边rdd的key值,将左边rdd的value连接过来; |
| rdd.union(rdd2) | 与另一个rdd结合,组成新的rdd,类似pandas中的concat |
| rdd.groupbyKey().mapValues(list) | 根据rdd的key值进行分组,常用mapValues(list)的action,比如rdd.groupbyKey().mapValues(list).map(lambda x: (x[0], len(x[1])))就可以统计key对应的分组后的样本数量 |
如果你想看操作后的结果,可以用一个叫做**collect()**的action把所有的item转成一个Python list。
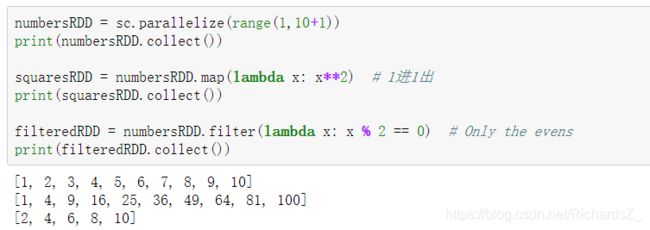
flatMap()
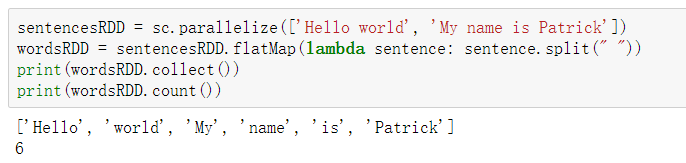
join()
rdd1.join(rdd2)方法是取rdd1,rdd2中相同key值的对,将value物理组合。
例如:
rdd1 = ([(‘a’, 1), (‘b’, 1), (‘c’, 1), (‘d’, 1)])
rdd2 = ((‘a’, 1), (‘e’, 1), (‘f’, 1), (‘g’, 1))
rdd1.join(rdd2).collect()
# Out[4]: [('a', (1, 1))]
Spark的一个核心概念是惰性计算。当你把一个RDD转换成另一个的时候,这个转换不会立即生效执行!!!
Spark会把它先记在心里,等到真的需要拿到转换结果的时候,才会重新组织你的transformations(因为可能有一连串的变换)
这样可以避免不必要的中间结果存储和通信。
| collect() | 计算所有的items并返回所有的结果到driver端,接着 collect()会以Python list的形式返回结果 |
| first() | 和上面是类似的,不过只返回第1个item |
| take(n) | 类似,但是返回n个item |
| count() | 计算RDD中item的个数 |
| top(n) | 返回头n个items,按照自然结果排序 |
| reduce() | 对RDD中的items做聚合 |
1.2 DataFrame
从RDD里可以生成类似大家在pandas中的DataFrame,同时可以方便地在上面完成各种操作。类比于Pandas当中Series是DataFrame的基本数据,在Pyspark中RDD也同样是DataFrame的基本数据。
1.2.1 构建SparkSession
Spark SQL 是 Spark 处理结构化数据的一个模块, 与基础的 Spark RDD API 不同,
Spark SQL中所有功能的入口点是 SparkSession 类. 要创建一个 SparkSession, 仅使用 SparkSession.builder()就可以了:
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
1.2.2 创建DataFrame
在一个 SparkSession中, 应用程序可以从一个 已经存在的 RDD 或者 hive表, 或者从Spark数据源中创建一个DataFrames.
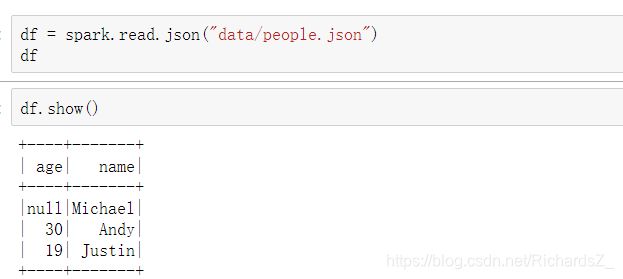
1.2.3 DataFrame的操作