【论文笔记】—深度残差网络—ResNet—2015-CVPR
论文介绍
《用于图像识别的深度残差学习》通过残差模块解决深层网络的退化问题,大大提升神经网络深度,各类计算机视觉任务均从深度模型提取出的特征中获益。 ResNet获得2015年ImageNet图像分类、定位、目标检测竞赛冠军,MS COCO目标检测、图像分割冠军。并在ImageNet图像分类性能上超过人类水平。
题目:Deep Residual Learning for Image Recognition
DOI:10.1109/CVPR.2016.90
时间:2015-12-10上传于arxiv
会议:2016-CVPR
机构:微软亚洲研究院
作者:何恺明、张祥雨、任少卿、孙剑。
论文链接:https://arxiv.org/abs/1512.03385
代码链接:https://chsasank.com/vision/_modules/torchvision/models/resnet.html
作者主页:http://kaiminghe.com/
video:https://www.youtube.com/watch?v=C6tLw-rPQ2oImageNet图像分类竞赛代表作:网络深度(虚线)& top5 error(%)(柱状图)
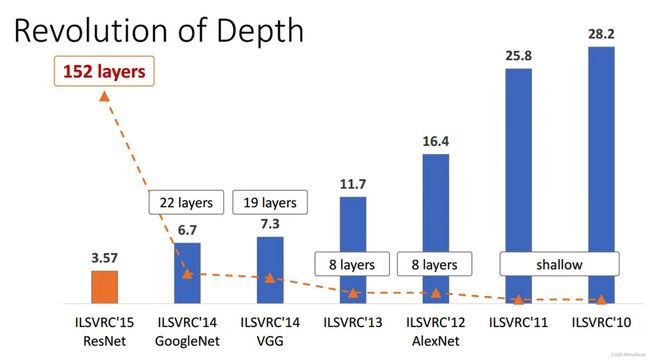
提出问题
问题1:梯度消失或梯度爆炸
梯度消失:若每一层的误差梯度小于1,反向传播时,网络越深,梯度越趋近于0;(浅层参数更新困难)
梯度爆炸:若每一层的误差梯度大于1,反向传播时,网络越深,梯度越来越大。
目前优化神经网络的方法都是基于BP(是一种多层前馈网络,具有信息前向传递,误差反向传递的特点),即根据损失函数计算的误差通过梯度反向传播的方式,指导深度网络权值的更新优化。其中将误差从末层往前传递的过程需要链式法则(Chain Rule)的帮助,因此反向传播算法可以说是梯度下降在链式法则中的应用。
而链式法则是一个连乘的形式,所以当层数越深的时候,梯度将以指数形式传播。梯度消失问题和梯度爆炸问题一般随着网络层数的增加会变得越来越明显。在根据损失函数计算的误差通过梯度反向传播的方式对深度网络权值进行更新时,得到的梯度值接近0或特别大,也就是梯度消失或爆炸。
问题2:网络退化(degradation problem)
如下图,网络变深之后性能不如浅层网络(不是过拟合,也不是梯度消失)
过拟合:训练集上误差低,测试集上误差高。
梯度消失:不会收敛。

解决方法
ResNet深度残差网络:精妙之处在于它把对于完整的输出的学习问题归结于对于残差的学习(Residual Learning)问题。何凯明有这样想法的灵感来源于如果只把浅层的输出做恒等映射(即F(X)=0)输入到深层,这样网络加深也并不会出现网络退化。所以,他在网络中加入了“短路”机制,并且这样不但解决了梯度消失问题,同时也提高了计算效率。
如图ResNet残差网络随着网络层数的增加,错误率下降,改善了网络退化的问题。

残差:预测值和真实值之间的偏差。

Residual Learning / Shortcut connection:
- F(x)+x(深层的输出)是逐元素相加,F(x)是残差分支的结果,x(浅层的输出)是恒等映射的结果。
- 对x优化:拟合偏移量F(x)即可,如果x是最优的(x代表的特征已经足够成熟,任何对于特征x 的改变都会让loss变大),则做恒等映射F(x)权重为0。
- 前向过程中,恒等的shortcut connection并不增加额外的参数和计算复杂度。
- 前向过程中帮助网络中的特征进行恒等映射,反向过程中帮助传导梯度,让更深的模型能够成功训练。

用于不同深度网络的残差模块(residual module):
左:ResNet18的残差模块。右:ResNet-50/101/152的残差模块。

降维的残差结构:
- 对输入矩阵的高、宽和深度进行一个变化。(主分支与shortcut的输出特征矩阵shape必须相同)
- 当shortcut跨越两种尺寸的特征图时,均使用stride为2的卷积。
观察下图的 ResNet18层网络,可以发现有些残差块的 shortcut 是实线的,而有些则是虚线的。
这些虚线的 shortcut 上通过1×1的卷积核进行了维度处理(特征矩阵在长宽方向降采样,深度方向调整成下一层残差结构所需要的channel)。

ResNet-18/34降维的残差结构用在下采样conv3_1、conv4_1、conv5_1层。

ResNet-50/101/152降维的残差结构用在下采样conv2_1、conv3_1、conv4_1、conv5_1层。
1x1卷积核用来降维和升维,减少参数,增加非线性和减小输出的深度以减小计算成本。

残差网络的优点:
- 易于优化收敛;
- 解决网络退化问题;
- 网络可以很深,准确率大大提升。
神经网络拟合恒等映射的效果是比较差的(因为什么都不做对于神经网络来说是比较难的),拟合残差的效果会比较好。通过残差网络不断修正上一层的误差:

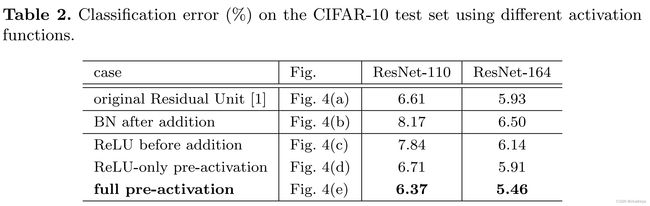
Post-activation or Pre-activation? 答:Pre-activation
探索激活函数位置对于残差网络的影响。
一个残差块的输出并不总是下一个残差块的输入,因为在添加后有一个ReLU激活函数。因此,在【Identity Mappings in Deep Residual Networks】中,何凯明等人通过改变运算顺序来固定残差块。
(c)会让F中拟合的对于x的残差只有正值,会大大减小残差的表示性。
(e)pre-activation的方式,即把BN和relu放在卷积的前面,这样就可以保证F中所有的操作都在和x相加之前完成,并且不会对残差产生限制,上图中的(e)。实际上把激活层(BN +relu)放在卷积的前面的操作在VGG等网络中不会产生不同的影响,但是在残差网络中就可以保证输入和输出加和之后在输入下一层之前没有别的操作,让整个信息的前向后向流动没有任何阻碍,从而让模型的优化更加简单和方便。
(d)只把relu提前的操作也会产生问题,当F中经过最后一个BN后,还要经过一个和x相加的运算,本来BN就是为了给数据一个固定的分布,一旦经过别的操作就会改变数据的分布,会削减BN的作用。在原版的ResNet中就是这么使用的BN,所以(e)pre-activation的方式也增加了残差模块的正则化作用。

为什么要对输入的数据做Normalization?
神经网络学习过程本质上是为了学习数据的分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另一方面,一旦在mini-batch梯度下降训练的时候,每批训练数据的分布不相同,那么网络就要在每次迭代的时候去学习以适应不同的分布,这样将会大大降低网络的训练速度。
Normalization指计算出整个训练集的feature map然后在进行标准化处理,对于一个大型的数据集明显是不可能的。所以用到Batch Normalization,也就是计算一个Batch数据的feature map然后在进行标准化(batch越大越接近整个数据集的分布,效果越好)。
Batch Normalization原理:
Batch Normalization是google团队在2015年2月11号论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》提出的。通过该方法能够加速网络的收敛并提升准确率。
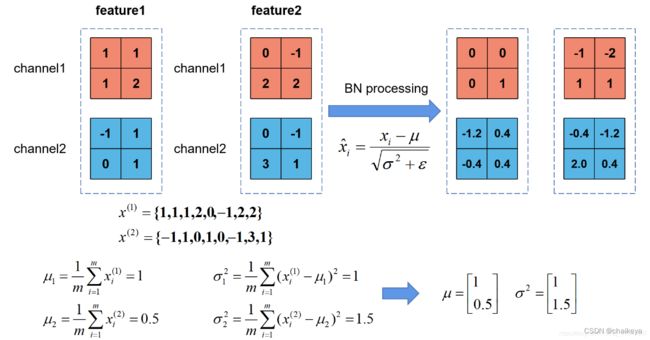
在图像预处理过程中通常会对图像进行标准化处理,这样能够加速网络的收敛,如下图所示,对于Conv1来说输入的就是满足某一分布的特征矩阵,但对于Conv2而言输入的feature map就不一定满足某一分布规律了(注意这里所说满足某一分布规律并不是指某一个feature map的数据要满足分布规律,理论上是指整个训练样本集所对应feature map的数据要满足分布规律)。而Batch Normalization的目的就是使feature map满足均值为0,方差为1的分布规律。
γ是用来调整数值分布的方差大小,β是用来调节数值均值的位置。这两个参数是在反向传播过程中学习得到的,γ的默认值是1,β的默认值是0。
上图展示了一个batch size为2(两张图片)的Batch Normalization的计算过程,假设feature1、feature2分别是由image1、image2经过一系列卷积池化后得到的特征矩阵,feature的channel为2,那么代表该batch的所有feature的channel1的数据,同理代表该batch的所有feature的channel2的数据。然后分别计算和的均值与方差,得到我们的和两个向量。然后在根据标准差计算公式分别计算每个channel的值(公式中的是一个很小的常量,防止分母为零的情况)。在我们训练网络的过程中,我们是通过一个batch一个batch的数据进行训练的,但是我们在预测过程中通常都是输入一张图片进行预测,此时batch size为1,如果在通过上述方法计算均值和方差就没有意义了。所以我们在训练过程中要去不断的计算每个batch的均值和方差,并使用移动平均(moving average)的方法记录统计的均值和方差,在训练完后我们可以近似认为所统计的均值和方差就等于整个训练集的均值和方差。然后在我们验证以及预测过程中,就使用统计得到的均值和方差进行标准化处理。
Batch Normalization的优势:
(1)增大学习率(Increase learning rate)
(2)去掉Dropout(Remove Dropout)
(3)去掉L2正则化(Reduce the L2 weight regularization)
(4)加速学习率的衰减(Accelerate the learning rate decay)
(5)删除局部响应归一化(Remove Local Response Normalization)
(6)将训练集充分打乱(Shuffle training examples more thoroughly),这一点有助于提升准确率。
(7)减少图像的拉伸形变,更多的专注于真是图像(Reduce the photometric distortions)


ResNet网络模型
- 超深的网络结构(突破1000层)
- 提出residual模块,易于优化收敛,解决网络退化和梯度消失问题。
- 使用Batch Normalization,加速训练(丢弃dropout)。
- 改进:使用Pre-activation会使模型优化变得更为简单,降低过拟合。


实验结果
图7:有恒等映射的残差模块输出的扰动比较小。

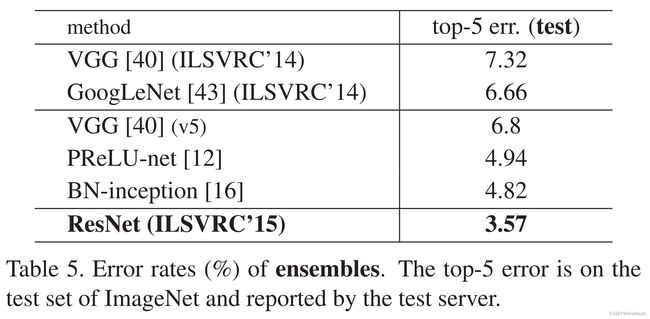
表5: 各组合模型在ImageNet测试集上的top-5错误率。
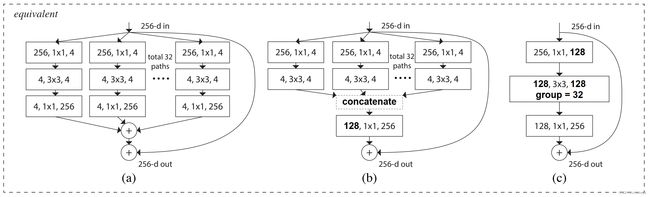
ResNeXt:
策略:分割-变换-融合
亮点:提出了基数C的概念,将模型从卷积层的叠加变成了自网络的叠加。而C概念的提出,也是模型从卷积核的宽度和网络的深度这两个方向之外,找到了一个新的方向对模型进行改进,这也是其被称作NeXt的“原因”。
ResNeXt 的等效模块:

参考文献:
【Pre-activation】 Identity Mappings in Deep Residual Networks
【Batch Normalization】 Accelerating Deep Network Training by Reducing Internal Covariate Shift
【ResNeXt】 Aggregated Residual Transformations for Deep Neural Networks
参考资料:
Batch Normalization详解以及pytorch实验
ResNet网络结构,BN以及迁移学习详解
参考博客1
参考博客2