【翻译】NCLS: Neural Cross-Lingual Summarization
Abstract
跨语言摘要(CLS)是为不同语言的源文件生成特定语言摘要的任务。现有方法通常将此任务分为两个步骤:摘要和翻译,导致错误传播的问题。为了解决这个问题,我们首次提出了一种端到端的CLS框架,我们称之为神经跨语言摘要(NCLS)。此外,我们建议通过将两个相关任务,即单语摘要和机器翻译,纳入多任务学习的CLS培训过程中,进一步改进NCLS。由于缺乏监督CLS数据,我们提出了一种往返翻译策略,基于现有的单语摘要数据集获得两个高质量的大规模CLS数据集。实验证明,我们的NCLS在英文到中文和中文到英文CLS人工校对测试集上相对于传统流水线方法实现了显著的改进。此外,多任务学习的NCLS可以进一步显著提高生成摘要的质量。我们在此公开我们的数据集和代码:http://www.nlpr.ia.ac.cn/cip/dataset.htm。
1. Introduction
在跨语言摘要中,给定一篇源语言文档,目标是生成一个不同目标语言的摘要,这有助于人们高效地获取外语文章的要点。传统的CLS方法基于流水线范式,要么首先将原始文档翻译成目标语言,然后摘要翻译后的文档(Leuski et al., 2003),要么首先摘要原始文档,然后将摘要翻译成目标语言(Lim et al., 2004;Orasan and Chiorean, 2008;Wan et al., 2010)。然而,目前的机器翻译(MT)并不完美,这导致了误差传播问题。尽管端到端的深度学习在自然语言处理方面取得了巨大进展,但由于缺乏大规模监督数据集,目前还没有人将其应用于CLS。
CLS的输入和输出位于两种不同的语言中,这使得数据获取比单语摘要(MS)要困难得多。据我们所知,还没有人研究如何自动构建高质量的大规模CLS数据集。因此,在这项工作中,我们提出了一种新颖的方法,直接解决了数据不足的问题。具体而言,我们提出了一种简单但有效的往返翻译策略,从现有的单语摘要数据集(Hermann et al., 2015; Zhu et al., 2018; Hu et al., 2015)中获取跨语言文档摘要对。更多细节可以在下面的第2节中找到。
基于我们构建的数据集,我们提出了跨语言摘要的端到端模型,我们将其称为神经跨语言摘要(NCLS)。此外,我们考虑通过两个相关任务来改进CLS:MS和MT。我们将MS和MT的训练过程纳入到CLS的多任务学习框架中(Caruana, 1997)。实验结果表明,NCLS在传统的流水线范式上取得了显著的改进。此外,MS和MT都可以显著帮助生成更好的摘要。我们的主要贡献如下:
- 我们提出了一种新颖的往返翻译策略,从现有的大规模MS数据集中获取大规模CLS数据集。我们已构建了一个包含37万个英文到中文(En2Zh)的CLS语料库和一个包含169万个中文到英文(Zh2En)的CLS语料库。
- 为了以端到端的方式训练CLS系统,我们提出了神经跨语言摘要(NCLS)。此外,我们建议将MT和MS纳入CLS培训过程中,采用多任务学习方法来改进NCLS。据我们所知,这是第一篇使用平行语料训练的端到端CLS框架的工作。
- 实验结果表明,NCLS相对于传统的流水线范式,在En2Zh上可以达到+4.87 ROUGE-2,而在Zh2En上可以达到+5.07 ROUGE-2。此外,采用多任务学习的NCLS还可以在En2Zh上进一步实现+3.60 ROUGE-2,在Zh2En上实现+0.72 ROUGE-2。我们的方法可以被视为进一步研究NCLS的基准。
2 Dataset Construction
现有的大规模单语摘要数据集是通过自动从互联网收集而来的。CNN/Dailymail(Hermann等人,2015年)数据集是从CNN和每日邮报网站收集而来的,其中文章和新闻亮点分别被视为输入和输出。与Hermann等人(2015年)类似,Zhu等人(2018年)构建了一个多模式摘要数据集MSMO,其中文本输入和输出与CNN/Dailymail中的类似。我们将CNN/Dailymail和MSMO的并集称为ENSUM1。胡等人(2015年)介绍了一个大规模的中文短文本摘要语料库(LCSTS2),该数据集是从中国微博网站新浪微博构建的。在本节中,我们介绍了如何基于ENSUM和LCSTS分别构建En2Zh和Zh2En的CLS数据集。
往返翻译策略。往返翻译(RTT)是将一段文本翻译成另一种语言(正向翻译),然后再将结果翻译回原始语言(逆向翻译),使用机器翻译服务。受Lample等人(2018年)的启发,我们提出采用往返翻译来从单语摘要数据集中获取CLS数据集。构建我们语料库的过程如图1所示。

图1:CLS语料库构建概览。我们的方法可以扩展到许多其他语言对,但本文重点关注En2Zh和Zh2En。在RTT过程中,我们过滤掉原始参考和往返翻译参考之间的ROUGE F1分数低于预设阈值T的样本。
以构建En2Zh语料库为例,给定一个文档-摘要对 ( D e n , S e n ) (D_{en},S_{en}) (Den,Sen),我们首先将摘要 S e n S_{en} Sen翻译成中文 S z h S_{zh} Szh,然后再翻译回英文 S e n ′ S'_{en} Sen′。满足ROUGE-1( S e n S_{en} Sen, S e n ′ S'_{en} Sen′)> T1和ROUGE-2( S e n S_{en} Sen, S e n ′ S'_{en} Sen′)> T2(这里T1分别设置为英文0.45和中文0.6,T2设置为0.2),En2Zh文档摘要对( D e n , S z h D_{en},S_{zh} Den,Szh)将被视为正面对。否则,将过滤掉这对。请注意,ENSUM中的 S e n S_{en} Sen中有多个句子,我们逐句应用RTT来过滤低质量的翻译参考句子。一旦在样本中保留了超过三分之二的摘要句子,我们将保留该样本。这个过程有助于确保我们任务中的最终压缩比不会与实际压缩比差距太大。构建Zh2En语料库时采用类似的过程。中文句子之间的ROUGE分数是使用中文字符作为分割单元来计算的。
语料库统计。在执行往返翻译策略后,我们从ENSUM获得了370,759个En2Zh CLS对,从LCSTS获得了1,699,713个Zh2En CLS对。En2Zh语料库(En2ZhSum)和Zh2En语料库(Zh2EnSum)的统计信息如表1所示。为了更可靠地评估各种CLS方法,我们招募了10名志愿者来纠正两个构建语料库中测试集的参考文本。
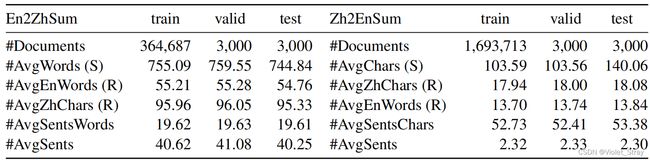
表1:语料库统计。#AvgWords(S)是源文档中英语单词的平均数量。每个参考文本都有一个双语版本,因为CLS语料库中的每个参考文本都是从MS语料库中相应的参考文本翻译而来的。#AvgEnWords(R)表示英文参考文本中的平均单词数,#AvgZhChars(R)表示中文参考文本中的平均字符数。#AvgSentsWords(#AvgSentsChars)表示源文档中一个句子中的平均单词数(字符数)。#AvgSents指的是源文档中的平均句子数。
3 Approach
传统方法(第3.1节)直观地将CLS视为一种流水线过程,这会导致错误传播。为了解决这个问题,我们提出了神经跨语言摘要方法(第3.2节),首次以端到端的方式训练CLS。由于CLS、MS和MT任务之间存在强烈的关联,我们提出将MS和MT纳入CLS培训的多任务学习中(第3.3节)。
3.1 Baseline Pipeline Methods
通常情况下,传统的CLS包括摘要步骤和翻译步骤。这两个步骤的不同顺序导致了以下两种策略。以En2Zh CLS为例:
Early Translation(ETran)。这个策略首先使用机器翻译将英文文档翻译成中文文档,然后使用摘要模型生成中文摘要。
Late Translation(LTran)。这个策略首先将英文文档总结为一个简短的英文摘要,然后将其翻译成中文。
3.2 Neural Cross-Lingual Summarization
考虑到Transformer编码器-解码器网络的出色文本生成性能(Vaswani et al., 2017),我们在这项工作中完全基于这一框架实现了我们的NCLS模型。如图2所示,给定一组CLS数据 D = ( X ( i ) , Y ( i ) ) D = (X^{(i)},Y ^{(i)}) D=(X(i),Y(i)),其中X和Y都是一系列标记,编码器将输入文档 X = ( x 1 , x 2 , ⋅ ⋅ ⋅ , x n ) X = (x_1, x_2, · · · , x_n) X=(x1,x2,⋅⋅⋅,xn)映射成一系列连续表示 z = ( z 1 , z 2 , ⋅ ⋅ ⋅ , z n ) z = (z_1, z_2, · · · , z_n) z=(z1,z2,⋅⋅⋅,zn),其大小随着源序列长度的变化而变化。解码器从连续表示中生成一个摘要 Y = ( y 1 , y 2 , ⋅ ⋅ ⋅ , y m ) Y = (y_1, y_2, · · · , y_m) Y=(y1,y2,⋅⋅⋅,ym),这是另一种语言,根据源序列最大化目标序列的条件概率,编码器和解码器联合训练:
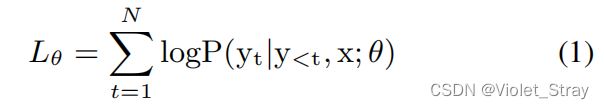
Transformer由堆叠的编码器和解码器层组成。编码器层由两个块组成,第一个块是自注意块,后面是位置感知的前馈块。尽管与编码器层具有相同的架构,解码器层还具有额外的编码器-解码器注意块。在每个块周围使用了残差连接和层归一化。此外,在解码器中,自注意块经过掩码修改,以防止在训练过程中当前位置关注未来位置。
对于自注意力和编码器-解码器注意力,使用多头注意块从不同的表示子空间和不同位置获取信息。每个头对应于一个经过缩放的点积注意力,它在查询Q、键K和值V上运行:

其中, d k d_k dk是键的维度。
最后,输出值被串联在一起,并通过一个前馈层进行投影,得到最终的值:

其中, W O 、 Q W i Q 、 K W i K W^O、QW_i^Q、KW_i^K WO、QWiQ、KWiK和 V W i K VW_i^K VWiK是可学习的矩阵, h h h是头的数量。
3.3 Improving NCLS with MS and MT
考虑到CLS任务与MS任务之间以及CLS任务与MT任务之间存在很强的关联性:(1) CLS与MS共享相同的目标,即把握原始文档的核心思想,但最终结果以不同的语言呈现。(2) 从信息压缩的角度来看,机器翻译可以被视为一种具有1:1压缩比的特殊跨语言摘要。因此,我们考虑使用MS和MT数据集在多任务学习下进一步提高CLS任务的性能。
受到Luong等人(2016)的启发,我们采用了一对多方案来将MS和MT的训练过程融入CLS的训练过程中。如图3所示,该方案涉及一个编码器和多个解码器,其中编码器可以被共享。我们在这里研究了两种不同的任务组合:CLS+MS和CLS+MT。

图3:多任务NCLS概览。下半部分是使用交替训练策略的CLS+MT。不同颜色代表不同的语言。
CLS+MS。请注意,CLS数据集中的每个参考文本都有一个双语版本。例如,En2ZhSum数据集包含总共370,687份文档,其中包括中文和英文的摘要。因此,我们考虑如下联合训练CLS和MS。给定一个源文档,编码器将其编码为连续的表示,然后两个解码器同时生成各自任务的输出。损失可以如下计算:

其中 y ( 1 ) y^{(1)} y(1)和 y ( 2 ) y^{(2)} y(2)是两个任务的输出。
CLS+MT。由于CLS的输入-输出对与MT的输入-输出对不同,我们考虑采用交替训练策略(Dong等人,2015年),即在切换到下一个任务之前,为每个任务优化固定数量的小批次,以联合训练CLS和MT。对于MT任务,我们使用来自LDC语料库的2.08M个句子对来训练CLS+MT,这些数据与CLS数据集一起使用。
4 Experiments
4.1 Experimental Settings
对于英语,我们采用了两种不同粒度的分词,即单词和子词(Sennrich等人,2016年)。我们将所有英文字符转换为小写。我们将输入截断为200个单词,将输出截断为120个单词(中文输出为150个字符)。对于中文,我们采用了三种不同粒度的分词:字符、词和子词。值得注意的是,我们只在Zh2En模型中应用基于子词的分词,因为基于子词的分词会使En2Zh中的英文文章变得非常长(特别是在中文目标端输出方面),这会导致Transformer表现极差。对于我们的基线管道模型,中文字符的词汇量为10,000,中文词汇、中文子词和英文词汇的词汇量都为100,000。在我们的En2Zh NCLS模型中,源端英文单词的词汇量为100,000,目标端中文字符和词汇的词汇量分别为18,000和50,000。在我们的Zh2En模型中,源端中文字符、词汇和子词的词汇量分别为10,000、100,000和100,000,而目标端英文单词和子词的词汇量都为40,000。我们通过Xavier初始化方法(Glorot and Bengio,2010)初始化所有参数。我们使用transformer base(Vaswani等人,2017)的配置训练我们的模型,其中包含一个6层编码器和一个6层解码器,具有512维的隐藏表示。
在训练过程中,在En2Zh模型中,每个小批次包含大约2,048个源标记和2,048个目标标记的文档-摘要对;在Zh2En模型中,每个小批次包含大约4,096个源标记和4,096个目标标记的文档-摘要对。我们使用Adam优化器(Kingma和Ba,2015),其中β1 = 0.9,β2 = 0.998,以及ε = 10−9。我们使用一块NVIDIA TITAN X来训练我们的模型。在TNCLS模型和基线模型中,均在1,000,000次迭代内达到收敛。在多任务NCLS模型中,我们每个任务训练大约800,000次迭代(达到收敛)。在测试时,我们使用束搜索(beam search)生成摘要,束大小为4。
4.2 Baselines and Model Variants
我们将我们的NCLS模型与以下两种传统方法进行了比较:
TETran:首先,我们使用在LDC语料库上训练的基于Transformer的机器翻译模型来翻译源文档。然后,我们使用LexRank(Erkan和Radev,2004),一种强大且广泛使用的无监督摘要方法,对翻译后的文档进行摘要。我们之所以选择应用无监督方法,是因为我们缺乏目标语言中MS数据集的版本,无法训练一个监督模型来摘要翻译后的文档。
TLTran:首先,我们构建了一个基于Transformer的MS模型,该模型在原始的MS数据集上进行了训练。然后,MS模型旨在将源文档总结为一份摘要。最后,我们使用在LDC语料库上训练的基于Transformer的机器翻译模型将摘要翻译成目标语言。我们的基于Transformer的MS模型的性能见表2和表3。
为了使我们的实验更全面,我们在TETran和TLTran的过程中将基于Transformer的机器翻译模型替换为Google Translator,这是最先进的机器翻译系统之一。我们将这两种方法分别称为GETran和GLTran。
我们的NCLS模型有三个变种:
- TNCLS:基于Transformer的NCLS模型,其中输入和输出是不同颗粒度单元的组合。
- CLS+MS:这是多任务NCLS模型,它接受输入文本,并同时执行CLS和MS任务的文本生成,并计算总损失。
- CLS+MT:它通过交替训练策略来训练CLS和MT任务。具体来说,我们在一个小批次中优化CLS任务,然后在下一个小批次中优化MT任务。
4.3 Experimental Results and Analysis
我们使用标准的ROUGE度量(Lin, 2004)对不同模型进行评估,报告了ROUGE-1、ROUGE-2和ROUGE-L的F1得分。结果见表4。

表4:在En2ZhSum和Zh2EnSum测试集上的ROUGE F1分数(%)。En2ZhSum和Zh2EnSum是经过人工校对的相应测试集。Unit表示文本单元的粒度组合,其中c表示字符,w表示单词,sw表示子词。RG表示ROUGE的缩写。↑表示数值越大,结果越好。我们的NCLS模型比基线模型表现明显更好,根据官方的ROUGE脚本8测量,置信区间为95%。
我们可以发现,GLTran优于TLTran,而GETran优于TETran,这表明当使用更强大的机器翻译系统时,基于流水线的方法表现更好。与GLTran或GETran相比,我们的TNCLS模型都取得了显著的改进,这可以验证我们的动机并证明我们构建的语料库的有效性。在En2Zh CLS任务中,每个模型在En2ZhSum上的结果与En2ZhSum上的结果相似。这是因为原始的ENSUM数据集来自新闻报道。现有的新闻报道机器翻译具有出色的性能。此外,在数据集构建过程中,我们已经对翻译质量较低的样本进行了预先过滤。因此,自动测试集的质量很高。TNCLS(w-c)的性能明显优于TNCLS(w-w)。这是因为基于字符的分词可以大大减小中文目标端的词汇量,从而在解码过程中几乎不会生成UNK标记。
在Zh2En CLS任务中,基于子词的模型优于其他模型,因为基于子词的分词可以大大减小词汇量并减少UNK标记的生成。与基线相比,TNCLS在Zh2EnSum上的改进最大可达+4.52 ROUGE-1,+6.56 ROUGE-2,+5.03 ROUGE-L,而在Zh2EnSum上的改进最大可达+3.40 ROUGE-1,+5.07 ROUGE-2,+3.77 ROUGE-L。TNCLS在经过人工校对的测试集上的结果明显下降,表明翻译参考文本的质量不如预期。原因很明显,原始的LCSTS数据集来自社交媒体,因此其中的文本中缩写词和省略标点符号的比例要高得多,导致翻译质量较低。总之,TNCLS模型在En2Zh和Zh2En CLS任务上明显优于传统的流水线方法。
为什么要使用回译?为了展示通过回译在RTT过程中过滤语料库的影响,我们使用了三种类型的数据集来训练我们的TNCLS模型并进行性能比较。它们分别是:(a) 仅使用MS数据集上的正向翻译获得的CLS数据集(Non-Filter);(b) 通过完整的RTT过程获得的CLS数据集(Filter);© 从Non-Filter数据集中抽样获得的数据集,以保持与Filter数据集相同的大小(Pseudo-Filter)。结果见表5。在En2Zh和Zh2En任务中,训练在Filter数据集上的模型在性能上明显优于在Pseudo-Filter数据集上训练的模型,这表明回译可以有效地过滤掉低质量的样本,提高了语料库的整体质量,从而提高了NCLS的性能。

表5:不同版本数据集的实验结果。Filter是使用RTT策略进行筛选的数据集版本。Non-Filter表示仅通过前向翻译获得的数据集版本,不包括回译等筛选过程。Pseudo-Filter是从Non-Filter版本随机抽样的数据集,与Filter版本的大小相同。BT表示RTT中的回译。对于En2Zh任务,我们训练TNCLS(w-c)。对于Zh2En任务,我们训练TNCLS(sw-sw)。
在En2Zh任务中,训练在Non-Filter数据集上的模型表现最佳。原因有两点:(1) 英语新闻的机器翻译质量可靠;(2) Non-Filter数据集的规模几乎是其他两个数据集的两倍,因此在数据量达到一定水平之后,它可以弥补语料库中翻译错误引起的噪声。在Zh2En任务中,训练在Non-Filter数据集上的模型性能不如在Filter数据集上的模型好。这可以归因于当前的机器翻译在社交媒体文本翻译方面不太理想,因此仅使用正向翻译构建的数据集包含太多噪声。因此,在机器翻译质量不太理想的情况下,在构建语料库的过程中,回译特别重要。
多任务NCLS的结果。为了探究MS和MT是否可以进一步提高NCLS的性能,我们将多任务NCLS与使用相同单位粒度组合的NCLS进行比较。结果如表6所示。正如表6所示,CLS+MS和CLS+MT都可以提高NCLS的性能,这可以归因于将MS和MT数据纳入训练过程增强了编码器。在En2Zh任务中,CLS+MT明显优于CLS+MS,而在Zh2En任务中,CLS+MS的性能与CLS+MT相当。原因有两个:(1)在En2Zh任务中,MT数据集比MS和CLS数据集大得多,因此更需要增强编码器的稳健性。 (2)在CLS+MT的训练过程中,我们使用了LDC MT数据集,该数据集与我们的En2ZhSum类似,都属于新闻领域。然而,Zh2EnSum属于社交媒体领域,因此CLS+MT在En2Zh中的改进要大于在Zh2En中的改进。总的来说,在CLS数据集不是很大时,多任务学习的NCLS在En2Zh任务中取得了更显著的改进,这表明在CLS数据集不是很大时,其他相关任务中的额外数据集对提高性能至关重要。

表6:多任务NCLS的结果。En2Zh任务中输入和输出的粒度组合是“词到字符”(w-c),而Zh2En任务中是“子词到子词”(sw-sw)。
人工评估。我们对En2ZhSum和Zh2EnSum测试集中各随机选择了25个样本进行人工评估。我们比较了我们的方法生成的摘要(包括TNCLS、CLS+MS和CLS+MT)与GLTran生成的摘要。我们请了三名研究生评估生成的摘要与人工修正的参考摘要,从三个独立的角度评估每个摘要:(1)摘要的信息量有多大?(2)摘要有多简洁?(3)摘要的流畅程度和语法如何?每个属性都以从1(最差)到5(最佳)的分数来评估。平均结果如表7所示。
如表7所示,与GLTran相比,TNCLS可以生成更多信息丰富的摘要,显示出端到端模型的优势。TNCLS的简洁度分数和流畅度分数与GLTran相当。这是因为GLTtrans和TNCLS都采用了单一的编码器-解码器模型,很容易导致生成不足和重复。我们的CLS+MS和CLS+MT可以显著提高生成摘要的简洁度和流畅度,这表明这些方法可以生成更短的摘要并减少语法错误。总之,TNCLS可以生成更丰富信息的摘要,但很难提高简洁度和流畅度。然而,借助MT和MS任务的帮助,可以显著提高简洁度和流畅度得分。

表7:人工评估结果。IF表示信息丰富,CC表示简洁,FL表示流畅。
4.4 Case Study
我们在图4中展示了来自Zh2EnSum人工校对测试集的一个示例的案例研究。如图4所示,由GETran生成的摘要明显受到机器翻译错误的影响(“distribution companies”应该更正为“circulation enterprises”)。由于GETran首先翻译所有的源文本,因此更容易引入机器翻译的错误。GLTran生成的摘要缩减了其中的一个事实,即其中的年份应该是2012而不是2011。该句子的翻译质量相对可靠,因此错误可能是在摘要步骤中产生的。与前两个生成的摘要相比,尽管由TNCLS生成的摘要不强调发生的时间和地点,但其表达的逻辑没有错误。由CLS+MS和CLS+MT生成的摘要总体上与事实一致,但它们的重点不同。CLS+MS摘要更好地与金标摘要相匹配。它们的缺点是它们没有反映原始文本中的“规模”。总之,我们的方法可以生成比基线更准确的摘要。

图4:生成摘要示例。
5 Related Work
跨语言摘要已经提出,以不同的语言呈现源文档中最显著的信息,在多语言信息处理领域非常重要。现有的大多数方法通过简单地应用两种典型的翻译方案来处理CLS任务,即早期翻译(Leuski等,2003;Ouyang等,2019)和后期翻译(Orasan和Chiorean,2008;Wan等,2010)。早期翻译方案首先将原始文档翻译成目标语言,然后生成已翻译文档的摘要。后期翻译方案首先将原始文档总结成源语言的摘要,然后再将其翻译成目标语言。
Leuski等人(2003年)将印地语文档翻译成英语,然后为其生成英语标题。Ouyang等人(2019年)提出了一个用于低资源语言的强大的抽象摘要系统,目前没有可用的摘要语料库。他们在嘈杂的英语文档和干净的英语参考摘要上训练了神经抽象摘要模型。然后,该模型可以学习从不流畅的输入生成流畅的摘要,从而可以为翻译后的文档生成摘要。Orasan和Chiorean(2008年)使用最大边际相关性方法(Goldstein等,2000年)总结了罗马尼亚新闻,并为英语使用者生成英语摘要。Wan等人(2010年)采用后期翻译方案来处理英语到汉语的CLS任务。他们提取英语句子,考虑了句子的信息量和翻译质量,然后自动将英语摘要翻译成最终的汉语摘要。上述研究仅利用了单一语言方面的信息。
已经提出了一些方法来提高CLS的性能,这些方法利用了双语信息。Wan(2011年)提出了两种基于图的摘要方法,以在英译汉的CLS任务中充分利用英语和汉语方面的信息。受到基于短语的翻译模型的启发,Yao等人(2015年)引入了一种压缩式CLS方法,同时执行句子选择和压缩。他们通过计算由MT服务获取的对齐双语短语而得到的句子分数,并通过删除冗余或翻译不佳的短语来进行压缩。Zhang等人(2016年)提出了一种抽象CLS方法,它构建了一个由源端谓词-论元结构(PAS)的双语元素和目标端对应元素表示的双语概念池。最终摘要是通过最大化PAS元素的突显度和翻译质量来生成的。
然而,所有这些研究都属于流水线范式,不仅严重依赖手工制作的特征,还会导致错误传播。最近,Ayana等人(2018年)提出了基于现有平行翻译语料库和单语头条生成的零-shot跨语言头条生成。类似地,Duan等人(2019年)提出使用单语抽象句子摘要系统来进行零-shot跨语言抽象句子摘要的教学,涵盖了摘要词生成和注意力两个方面。尽管在跨语言摘要方面已经付出了很大努力,但如何自动构建高质量的大规模跨语言摘要数据集仍然未被深入探讨。
在本文中,我们专注于英译汉和汉译英的CLS,并尝试自动构建两个大规模的语料库。此外,基于这两个语料库,我们进行了几种端到端的训练方法,称为神经跨语言摘要。
6 Conclusion and Future Work
在本文中,我们首次提出了神经跨语言摘要。为实现这一目标,我们提出通过往返翻译策略从现有的单语摘要数据集中获取大规模的监督数据。然后,我们在我们构建的数据集上应用端到端方法,并发现我们的NCLS模型明显优于传统的流水线范式。此外,我们考虑利用机器翻译和单语摘要进一步改进NCLS。实验结果表明,机器翻译和单语摘要都可以显著帮助NCLS生成更好的摘要。
在我们的未来工作中,我们将采用我们的RTT策略来获取其他语言对的CLS数据集,例如英译日、英译德、汉译日、汉译德等等。
7 Acknowledgments
略