【Hadoop】HDFS——分布式文件系统
文章目录
- 一、Hadoop分布式文件系统架构
-
- 1 概念
-
-
- 1.1 文件存放在一个磁盘上效率低
- 1.2 字节数组
- 1.3 切分数据
- 1.4 拼接数据
- 1.5 偏移量
- 1.6 数据存储的原理
-
- 2.Block拆分标准
-
-
- 2.1 拆分的数据块需要等大
- 2.2 数据块block
- 2.3 注意事项
- 2.4 Block数据安全
- 2.5 Block的管理效率
-
- 二、Hadoop伪分布式搭建
- 三、NomeNode
- 四、DataNode
- 五、SecondaryNameNode
-
- 1 传统的内存持久化方案
-
-
- 1.1 日志机制
- 1.2 拍摄快照
-
- 2 持久化机制
-
-
- 2.1 解决思路
- 2.2 何为持久化?持久化的作用?
- 2.3 持久化到底持久了什么
- 2.4 持久化可以交给NameNode吗?
- 2.5 持久化过程
-
- 六、安全模式
- 七、HDFS的权限
- 八、机架感知策略
-
- 1 作用
- 2 第一个节点
- 3 第二个节点
- 4 第三个节点
- 5 第四个节点
- 九、HDFS读写数据流程
-
- 1 写数据流程
-
-
- 1.1 宏观流程
- 1.2 微观流程
-
- 2 读数据流程
- 十、Hadoop完全分布式搭建
- 十一、Hadoop1.x的困境
-
-
-
- 1. namenode的隐患
- 2. Hadoop2.x的解决方法
-
-
- 十二、HA高可用
-
- 1 设计思路
- 2 组织架构
- 3 脑裂brain-split
-
-
- 3.1 定义
- 3.2 原因
- 3.3 脑裂场景
- 3.4 解决方案----隔离(Fencing)
- 3.5 解决过程
- 3.6 Zookeeper
-
- 十三、Federation联邦
-
- 1 单NameNode局限性
- 2 Federation
-
-
- 2.1 块池 Block Pool
- 2.2 命名空间卷 Namespace Volume
- 2.3 通过多个namenode/namespace把元数据的存储和管理分散到多个节点中
- 2.4 namenode/namespace可以通过增加机器来进行水平扩展
- 2.5 通过namenode和namespace组合使用
-
- 十四、搭建高可用集群
-
- 1 搭建Zookeeper
- 2 搭建高可用集群-HA
一、Hadoop分布式文件系统架构
FS File System:
- 文件系统是基于银盘之上的一个文件管理的工具
- 用户操作文件系统可以和硬盘进行解耦
DFS Distributed File System:
- 分布式文件系统
- 将数据存档在多台电脑上存储
- 分布式文件系统有很多
- HDFS是MapReduce计算的基础
1 概念
1.1 文件存放在一个磁盘上效率低
- 读取效率低
- 若文件较大会超出单机的存储范围
1.2 字节数组
文件在磁盘真实存储文件的抽象概念
1.3 切分数据
对字节数组进行切分
1.4 拼接数据
按照数组的偏移量将数据连接到一起,连接字节数据
1.5 偏移量
当前数据在数组中的相对位置
1.6 数据存储的原理
- 不管文件大小,所有文件都是由字节数组构成
- 若要切分文件,就是将一个字节数组分成多份
- 将切分后的数据拼接在一起,数据可以继续使用
- 根据数据的偏移量进行数据的重新拼接
2.Block拆分标准
2.1 拆分的数据块需要等大
系统会将大文件线性切割成块block,分散存放在集群的节点中。
- 数据计算时简化问题的复杂度
- 数据拉取时,时间相对一致
- 通过偏移量得到块的位置
- 进行分布式计算时,数据不统一,算法很难设计
2.2 数据块block
单一文件的block块大小一致,不同文件可以不一样。
- 数据被切分后的一个整体称之为块
- Hx1.*版本默认大小为64M,Hx2.*版本默认大小为128M
- 同一个文件中,每个数据块大小需一致,最后一个节点除外
- 不同文件中,块的大小可以不一致,文件大小不同可以设置不同的块数量
- 真实情况下,会根据文件大小和集群节点的数量综合考虑块的大小
- 数据块的个数=Ceil(文件大小/每个块的大小)
2.3 注意事项
(1)HDFS中一旦文件被存储,数据不允许修改
- 修改会影响偏移量
- 修改会导致数据倾斜
- 修改数据会导致蝴蝶效应
(2)可以在尾部追加数据,但是不推荐
(3)一般HDFS存储的都是历史数据
(4)块的大小一旦文件上传就不允许被修改(128M-512M)
(5)为了数据安全,存在副本机制
(6)系统只支持一次写入多次读取,同一时刻只有一个写入者
(5)如果数据文件的切割点128M正好是一个单词的中间部分,切分数据如何保证数据的完整性?
2.4 Block数据安全
为了保证数据安全,存在副本机制,对存储数据进行备份。
- 备份的数据不存放在一个节点上,使用数据时可以就近获取数据
- 备份数量小于等于节点数量
- 每个数据块会有三个副本,相同副本不存放在同一个节点上
- 副本的数量可以变更
如何进行备份操作?
- 如果是集群内提交:第一个block提交至上传请求的服务器上
- 如果是集群外提交:第一个block提交到负载不高的一台服务器上
- 第一个备份:存放在与第一个block不同机架的随机一台服务器上
- 第二个备份:存放在与第一个备份的block相同机架但是不同服务器上
- 更多的副本:随机存放;默认一个block有两个备份
2.5 Block的管理效率
需要专门给节点进行分工:
- 存储 DataNode
- 记录 Namenode
- 日志 SecondaryNameNode
二、Hadoop伪分布式搭建
| Hadoop节点 | 物理机 | 配置文件 |
|---|---|---|
| NameNode | node1 | core-site.xml |
| DateNode | node1 | slaves |
| SecondaryNameNode | node1 | hdfs-site.xml |
1.主机间免秘钥
具体可参考:主机间免秘钥具体操作
2.上传安装包并解压
tar -zxvf hadoop-2.7.1.tar.gz
3.修改JAVA_HOME配置信息
①hadoop-env.sh
# 25行
export JAVA_HOME=/usr/java/jdk1.8.0_162
②mapred-env.sh
# 16行
export JAVA_HOME=/usr/java/jdk1.8.0_162
③yarn-env.sh
# 23行
export JAVA_HOME=/usr/java/jdk1.8.0_162
4.修改核心配置文件
core-site.xml
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://node1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/var/abc/hadoop/localvalue>
property>
<configuration>
5.修改HDFS配置文件
hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>node1:50090value>
property>
<configuration>
6.配置Slaves文件
vim slaves
# localhost
node1
7.配置Hadoop环境变量
export HADOOP_HOME=/opt/hadoop-2.7.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
8.初始化namenode节点
hdfs namenode -format
注意:
- 只有首次开启需要格式化,第二次开启不要格式化
- 格式化会重新生成Namenode的CID,导致和Datanode的CID不一致
- 后果就是NameNode启动后没有对应的DataNode
9.启动集群
开启集群
start-dfs.sh
web端口:50070
10.创建文件夹及上传文件
hdfs dfs -mkdir -p /abc/
hdfs dfs -put ./a.txt /abc/
hdfs dfs -D dfs.blocksize=1048576 -put ./a.txt /abc/
三、NomeNode
功能:
- 掌控全局,管理DataNode以及文件的元数据信息(描述数据的数据,存放在内存中)
文件的归属、文件的权限、文件的大小时间、Block信息 - 接受客户端的读写服务,NameNode知道DataNode的对应关系
- 收集Block的位置信息,Block的位置信息并不会持久化,需要每次开启集群的时候DataNode上报
①系统启动
- NameNode关机时不会存储任意的Block与DataNode的映射信息
- DataNode启动时会将自己节点上存储的Block信息汇报给NameNode
- NameNode接受请求之后重新生成映射关系
File -> Block
Block -> DataNode - 如果某个数据块的副本数小于设置数,NameNode会将这个副本拷贝到其它节点上
②集群运行中
- NameNode与DataNode保持心跳机制,3秒钟发送一次
- 如果客户端需要读取或者上传数据的时候,NameNode可以知道DataNode的健康情况
- 可以让客户端读取存活的DataNode节点
- 如果DataNode超过3秒没有心跳,则认为DataNode出现异常,就不会让新的数据读写到Datanode
- 如果DataNode超过10分钟没有心跳,那么NameNode会将当前DataNode存储的数据转存到其它节点
- NameNode为了效率,将所有的操作都在内存中完成,执行速度块
- NameNode不会和磁盘进行任何数据交换
- 数据的持久化问题;数据保存在内存中,掉电易失
四、DataNode
- 存放文件的数据信息
- 数据存放在硬盘上,存储block的元数据信息(namenode存放的元数据是整个大文件的,datanode存放每一个block的元文件)
- 汇报
①启动时
1.汇报前验证Block文件是否被损坏
2.向NameNode汇报当前DataNode上的Block信息
②运行中
向NameNode保持心跳机制 - 当客户端读写数据时,首先去NameNode查询file与block与datanode之间的映射关系,与datanode建立连接,读写数据
五、SecondaryNameNode
1 传统的内存持久化方案
1.1 日志机制
- 做任何操作之前先记录日志
- 在数据改变之前先记录对应的日志
- 下次启动时,按照日志“重做”一遍
- 缺点:log文件大小不可控,随着时间的发展,集群启动的时间越来越长;日志中可能存在大量的无效日志
1.2 拍摄快照
- 序列化:将内存中的数据写出到磁盘上
- 反序列化:将硬盘上的数据写回到内存中
- 缺点:关机时间过长;如果是异常关机,数据还在内存中,无法写入硬盘;如果写出频率过高,会导致内存使用效率低
2 持久化机制
2.1 解决思路
- 让日志大小可控
- 快照需要定时保存
- 日志+快照
2.2 何为持久化?持久化的作用?
持久化: 当集群或者系统因为各种原因关闭之后,在重启时,可以返回到我们集群关闭的那一时刻
作用: 为了防止系统故障导致的数据丢失,采用持久化机制
2.3 持久化到底持久了什么
将namenode管理的文件元数据信息存放到磁盘上,为了防止namenode因为过度繁忙而挂掉
2.4 持久化可以交给NameNode吗?
可以: 前提是成本低,数据量小。
不可以: 因为namenode本身工作很繁忙,如果再进行持久化,namenode会很累;当元数据持久化到磁盘的过程中,通过IO来进行传输,在传输的过程中,namenode无法进行元数据的修改,也无法对外提供服务,相当于集群短暂性宕机。
2.5 持久化过程
| 文件 | 内容 |
|---|---|
| edits | 日志文件 |
| fsimage | 系统镜像 |
| seen_txid | 事务id |
| VERSION | 集群相关信息 |

1.将namenode的edits和fsimage拉取到secondary namenode进行合并,生成fsimage.ckpt
2.从secondary namenode拉回fsimage.ckpt形成新的fsimage,这次已经完成相应的更新,有了更新之前的所有数据
3.当我们secondary namenode进行合并的时候,再有新的系统操作进行怎么办?
会生成一个新的edites,默认大小64M,与更新后的fsimage再进行合并,当新的edits和fsimage生成之后,在满足一定条件下,会再次进行重演,将其拉到secondary namenode中进行合并
4.满足一定条件指的是什么条件?
时间:超过3600s
内存:edits文件超过64M
5.合并过程中又有系统文件产生,并超过64m怎么办?
可以改变edits默认值(前提:自己清楚会有很多操作,有可能会出现问题)
系统会自动再次创建
6.当持久化结束之后,系统已经更新完成,之前的数据保存在合并之后的文件中,这些文件会持久化到磁盘中,在磁盘中进行存储,防止在内存中因为系统故障丢失(内存是断电清零的)
六、安全模式
安全模式: 指集群启动时的一个状态
NameNode启动时:
- 将镜像文件fsimage载入内存,并执行编辑日志(edits)中的各项操作
- 一旦在内存中成功建立文件系统元数据的映像,则创建一个新的fsimage文件和一个空的编辑日志
- 此时namenode运行在安全模式,即namenode的文件系统对客户端来说是只读的
- 处于这个状态是为了保护数据的安全所以不可以被客户端访问
安全模式干了什么?
- datanode会向namenode发送最新的块列表信息
- namenode收集block的信息达到最少副本数,就会脱离安全模式
- namenode了解到足够多的块位置信息之后,即可高效运行文件系统
- 如果有datanode挂掉,进行备份拷贝操作,数据存储时会有备份机制,拷贝状态系统仍然处于安全模式
- 如果datanode又恢复了,当有新的任务时,根据情况,将新的任务发放到此节点上,若无新任务,他原来上面的数据都丢失,它丢失的block会存放到其他节点上,原先备份机制的block不变
七、HDFS的权限
HDFS对权限的控制:
- 只能防止好人做错事
- 不能防止坏人做坏事
- 你告诉它你是谁,他就认为你是谁
八、机架感知策略
1 作用
为了保证副本在集群的安全性,将副本放在不同的datanode节点上,节点也需要一定的考虑
2 第一个节点
集群内部: 优先考虑与客户端相同节点作为第一个节点
集群外部: 选择资源丰富且不繁忙(负载不高)的节点作为第一个节点
3 第二个节点
选择和第一个节点不同机架的随机一个节点
4 第三个节点
与第二个节点相同机架的其它节点
5 第四个节点
与前面节点不重复的其它节点
九、HDFS读写数据流程
1 写数据流程
1.1 宏观流程
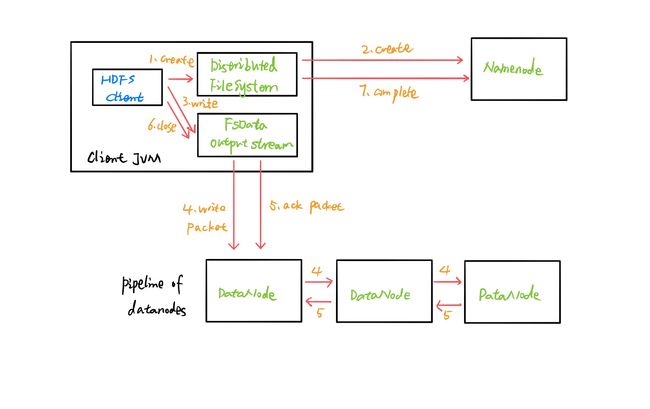
- 客户端向HDFS发送写数据请求
- HDFS通过rpc调用namenode的create方法,namenode首先会检查是否拥有足够的空间权限等条件创建这个文件或路径是否存在;校验成功,创建一个空的Entry对象,并将成功状态返回给HDFS;检验失败,直接抛出异常
- HDFS如果接收到成功状态,会创建一个FSDataOutputStream的对象给客户端使用
- 客户端向namenode询问第一个block存放的位置,namenode通过机架感知策略给出对应的datanode
- 客户端和datanode节点通过管道机制创建连接
- 客户端将文件按照块block切分数据,按照packet发送数据
- 客户端通过pipeline管道开始使用FSDataOutputStream对象将数据输出
- 客户端接收到成功的状态,就认为某个packet发送成功,直至所有的packet发送完成
- 如果客户端接收到最后一个packet的成功状态,说明当前block传输完成
- 客户端将这个消息传递给namenode,namenode确认传输完成
- 客户端继续向namenode询问第二个block的存储位置
- 当所有block传输完成后,namenode在Entry中存储所有的File与block与datanode的映射关系
- 关闭FSDataOutputStream
pipeline管道机制
client请求block存放位置之后,namenode会返回一批负载不高的datanode,client会与这批datanode之间形成pipeline管道
pipeline管道连接
- 客户端和node1创建连接,socket
- node1和node2创建连接,socket
- node2和node3创建连接,socket
pipeline管道中的数据传输
数据首先以block形式存储,在pipeline中,会将block再次细分,分成一个个的ack packet,ack packet在管道中流淌。
默认一个packet大小为64k,128M为2048个packet
pipeline管道中的数据传输流程
- 客户端首先将一个packet发送给node1,同时给予node1一个ack状态
- node1接收数据后将数据继续传递给node2,同时给与node2一个ack状态
- node2接收数据后将数据继续传递给node3,同时给node3一个ack状态
- node3将这个packet接收完成后,会响应这个ack给node2为true
- node2会响应给node1,同理,node1会响应给客户端
1.2 微观流程

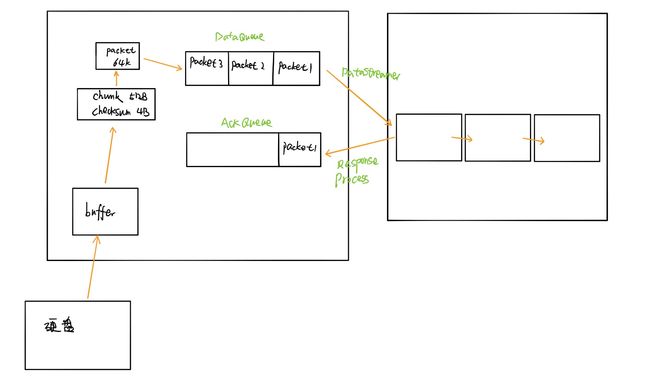
- 客户端从自己的硬盘以流的方式读取数据文件到自己的buffer缓存中
- 将缓存中的数据以chunk(512B)和checksum(4B)的方式放入到packet(64K)
- 当packet满的时候,添加到dataqueue队列
- datastreamer开始从dataqueue队列上取出一个packet,通过FSDataOPS发送到pipeline(生产者-消费者模式)
- datastreamer也会将发送出去的packet添加到ackqueue队列
- 客户端发送一个packet数据包以后开始接收ack,会有一个用来接收ack的ResponseProcessor线程,如果接收到成功的ack
若ack为true,从ackqueue删掉这个packet
若ack为false,将ackqueue中所有的packet重新挂载到发送队列,重新发送 - 最终DFS保存的数据格式
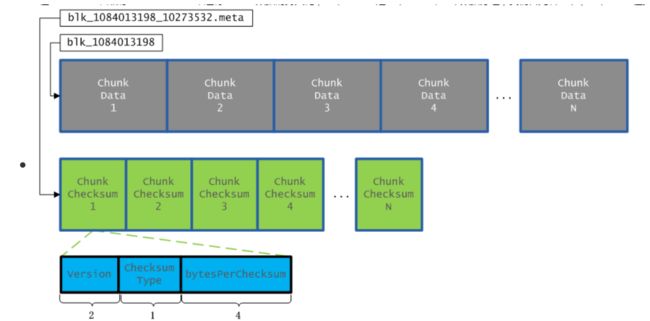
packet数据包
- chunk:checksum=128:1
- checksum:在数据处理和数据通信领域中,用于校验目的的一组数据项的和
- packet分为两类:实际数据包、heater包
packet数据包的组成结构
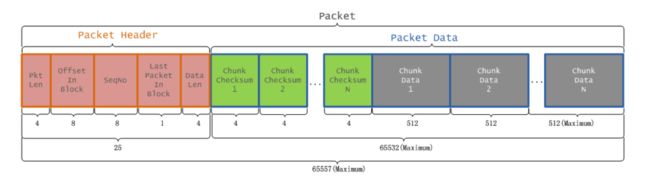
| 字段名称 | 字段类型 | 字段长度 | 字段含义 |
|---|---|---|---|
| pktLen | int | 4 | 4+dataLen+checksumLen |
| offsetInBlock | long | 8 | packet在Block中的偏移量 |
| seqNo | long | 8 | packet序列号,在同一个Block中唯一 |
| lastPacketInBlock | boolean | 1 | 是否是一个Block的最后一个packet |
| dataLen | int | 4 | dataPos-dataStart,不包含Header和checksum的长度 |
| 参数名称 | 参数值 | 参数含义 |
|---|---|---|
| chunkSize | 512+4=516 | 每个chunk的字节数(数据+校验和) |
| csize | 512 | 每个chunk数据的字节数 |
| psize | 64*1024 | 每个packet的最大字节数(不包含header) |
| DataNode.PKT_HEADER_LEN | 21 | 每个packet的header的字节数 |
| chunksPerPacket | 127 | 组成每个packet的chunk的个数 |
| packetSize | 25+516*127=65557 | 每个packet的字节数(一个header+一组chunk) |
2 读数据流程

- 客户端发送请求到DFS,申请读取某一文件
- DFS去namenode查找这个文件的相关信息,包括权限以及文件是否存在等等
若文件不存在,抛出指定错误
若文件存在,返回成功状态 - DFS创建FSDataInputStream对象,客户端通过这个对象读取数据
- 客户端获取文件第一个block信息
- 客户端根据就近原则选择datanode上对应的数据
- 依此类推,直到最后一个块,将block合并成一个文件
十、Hadoop完全分布式搭建
伪分布式集群: 单台节点实现了类似于分布式的处理方式
完全分布式: 多台服务器协同作业,改变的是节点的数量以及不同节点在哪一个服务器上启动
| NameNode | SecondaryNameNode | DataNode | |
|---|---|---|---|
| node1 | * | * | |
| node2 | * | * | |
| node3 | * |
1.预备条件
与伪分布式一样,需要主机间免秘钥并安装JDK
2.上传安装包并解压
tar -zxvf hadoop-2.7.1.tar.gz
3.修改JAVA_HOME配置信息
①hadoop-env.sh
# 25行
export JAVA_HOME=/usr/java/jdk1.8.0_162
②mapred-env.sh
# 16行
export JAVA_HOME=/usr/java/jdk1.8.0_162
③yarn-env.sh
# 23行
export JAVA_HOME=/usr/java/jdk1.8.0_162
4.修改核心配置文件
core-site.xml
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://node1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/var/abc/hadoop/fullvalue>
property>
<configuration>
5.修改HDFS配置文件
hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>node2:50090value>
property>
<property>
<name>dfs.namenode.secondary.https-addressname>
<value>node2:50091value>
property>
<configuration>
6.配置Slaves文件
vim slaves
# localhost
node1
node2
node3
7.配置Hadoop环境变量
export HADOOP_HOME=/opt/hadoop-2.7.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
8.将配置好的文件拷贝至其它节点服务器上
scp -r hadoop-2.7.1 root@node2:`pwd`
scp -r hadoop-2.7.1 root@node3:`pwd`
scp /etc/profile root@node2:/etc/profile
scp /etc/profile root@node3:/etc/profile
9.初始化namenode节点
hdfs namenode -format
注意:
- 只有首次开启需要格式化,第二次开启不要格式化
- 格式化会重新生成Namenode的CID,导致和Datanode的CID不一致
- 后果就是NameNode启动后没有对应的DataNode
10.启动集群
开启集群
start-dfs.sh
web端口:50070
11.创建文件夹及上传文件
hdfs dfs -mkdir -p /abc/
hdfs dfs -put ./a.txt /abc/
hdfs dfs -D dfs.blocksize=1048576 -put ./a.txt /abc/
十一、Hadoop1.x的困境
1. namenode的隐患
①单点故障: 仅有一个namenode主节点,当namenode出现故障,整个集群都会瘫痪,无法提供对外服务
②namenode只有一个节点,很难水平扩展: 服务器启动时,启动速度慢
③namenode随着业务增多,内存占用也会越来越多: 如果namenode内存占满,将无法继续提供服务
④业务隔离性差
⑤存储计算: 可能需要存储不同部分的数据,可能存在不同业务的计算流程
⑥namenode的吞吐量将会是集群的瓶颈: 客户端所有请求都会先访问namenode
2. Hadoop2.x的解决方法
高可用(HA,high availability): 单点有问题,集群容易全面崩塌,为了解决问题,采用多个namenode,实现namenode节点的高可用
联邦(Federation): 服务器能力有限,当要处理的问题超过他最大承载量或者datanode的数量超过其的管理量,namenode达到性能瓶颈,易出现问题,可以采用多个人联合的方式来进行namenode的水平扩展,这种方式成为联邦
十二、HA高可用
1 设计思路
- 启用主备节点切换模式(一主一备)
- 当主节点出现异常的时候,集群直接将备用节点切换成主节点
- 有独立的线程对主备节点健康状态进行监控
- 有一定的选举机制,帮助确定主从关系
- 需要适时存储日志的中间件
2 组织架构
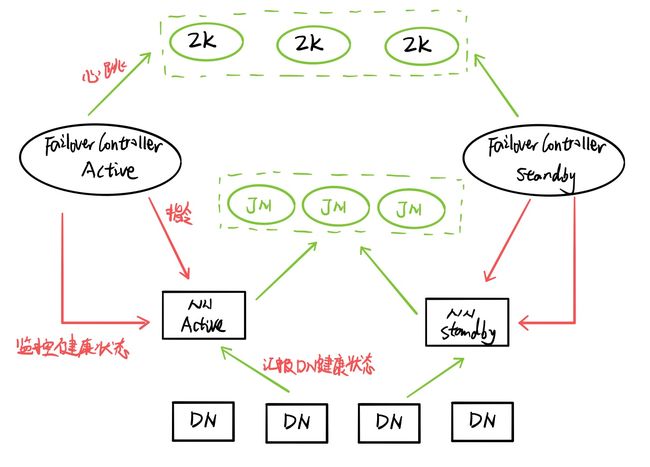
Active NameNode(ANN)
- 功能与原理和NameNode一致
- 接收客户端请求,查询数据块DataNode信息
- 存储数据的元数据信息(映射关系)
- 工作
启动时:接收datanode的block汇报
运行时:和datanode保持心跳(3s,10M) - 存储介质:完全基于内存
Standby NameNode(SNN)
-
NameNode的备用节点
-
和主节点做同样的工作,但是不发出任何指令
-
合并日志文件及镜像
- 当搭建好集群时,格式化主备节点的时候,ANN和SNN都会默认创建镜像文件
- 操作HDFS时,ANN会产生日志文件
- 主节点将日志文件中新增的数据同步到journalnode集群上
- SNN从journalnode集群上同步日志信息,合并镜像和日志文件
- SNN将合并好的镜像文件发送给ANN,ANN验证无误后,存放到自己的目录中
DateNode(DN)
- 存储文件的block信息
- 启动时同时向两个NameNode汇报block信息
- 运行时同时和两个NameNode节点保持心跳机制
Quorum JournalNode Manager(QJM)
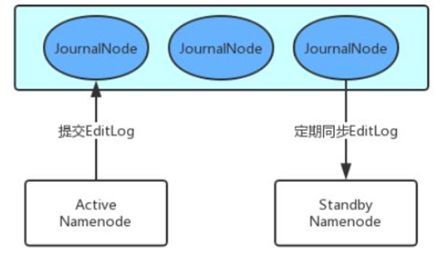
- 共享存储系统,NameNode通过共享存储系统实现日志数据同步
- journalNode是一个独立的小集群,实现原理与Zookeeper一致
- ANN产生日志文件时会同时发送到JournalNode集群中的每个节点上
- JournalNode要求只要半数以上的节点接收到日志,本条日志即生效
- SNN每隔一段时间去QJN上取回最新的日志
Failover Controller(故障转移控制器)
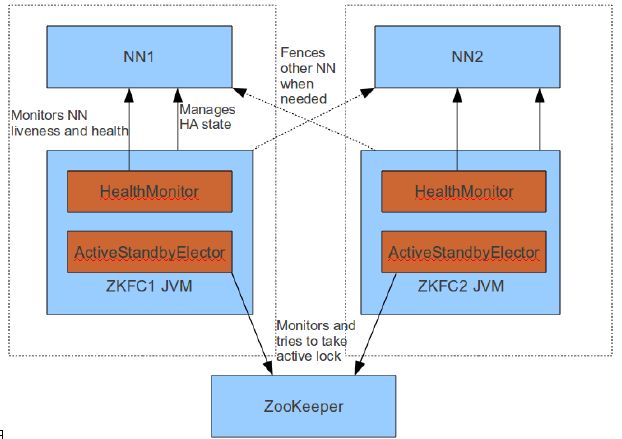
- 对NameNode的主备切换进行总体控制,及时检测NameNode的健康状况
①在主NameNode故障时借助Zookeeper实现全自动的主备选举和切换
②防止NameNode的GC(内存回收)失败导致心跳受影响,zkfv作为一个deamon守护进程从NameNode分离出来 - 启动时
①集群启动时,主备节点的概念是模糊的
②当ZKFC只检查到一个节点是健康状态,直接将其设置为主节点
③当ZKFC检查到两个节点是健康状态,发起投票机制
④通过投票机制选出一个主节点,一个备用节点,并修改主备节点的状态 - 运行
由ZKFailoverController、HealthMonitor和ActiveStandbyElector这三个组件来协同实现主备切换
①ZKFC启动时会创建HealthMonitor和ActiveStandbyElector这两个主要的内部组件
②HealthMonitor: 起监控作用,定期监控NameNode的状态,并有异常时,将异常返回
③ActiveStandbyElector: 主要负责完成自动的主备选举,内部封装了Zookeeper的处理逻辑
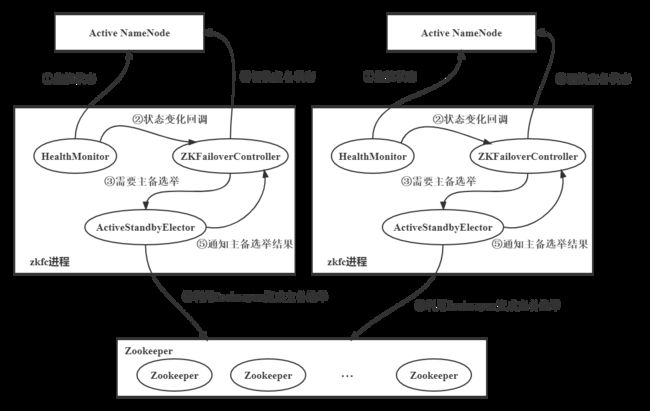
- 主备节点正常切换
①NameNode在选举成功后,ActiveStandbyElectorLock临时节点,备NameNode节点中的ActiveStandbyElector会监控这个节点
②如果ActiveNameNode对应的HealthMonitor检测到NameNode状态异常时,ZKFailoverController会主动删除当前在Zookeeper上建立的临时节点ActiveStandbyElectorLock
③处于Standby状态的NameNode的ActiveStandbyElector注册的监听器会收到ActiveStandbyElectorLock这个节点NodeDeleted事件,并创建ActiveStandbyElectorLock临时节点,本来处于Standby状态的NameNode就选举为主NameNode并随后开始切换为Active状态
④如果是Active状态的NameNode所在的机器整个宕机的话,跟Zookeeper连接的客户端线程也会挂掉,会话结束,根据Zookeeper临时节点特性,ActiveStandbyElectorLock节点会自动删除,从而也会自动进行一次主备切换
3 脑裂brain-split
3.1 定义
脑裂是Hadoop2.x版本之后出现的全新问题,实际运行过程中有可能出现两个NameNode同时服务于整个集群的情况,这种情况称之为脑裂
3.2 原因
脑裂通常发生在主从NameNode切换时,由于ActiveNameNode的网络延迟、设备故障等问题,另一个NameNode会认为活跃的NameNode成为失效状态,此时StandbyNameNode会转换成活跃状态,集群中将会出现两个活跃的NameNode。因此,可能出现的因素有网络延迟、心跳故障、设备故障等。
3.3 脑裂场景
- NameNode在垃圾回收(GC)时,可能会在长时间内整个系统无响应
- zkfc客户端已经无法向zk写入心跳信息,这样的话可能会导致临时节点掉线,备NameNode会切换到 Active状态。这种情况可能会导致整个集群会有同时有两个NameNode
3.4 解决方案----隔离(Fencing)
- 第三方共享存储:任一时刻,只有一个NameNode可以写入
- DataNode需要保证只有一个NameNode可以发出与管理数据副本有关的删除命令
- Client需要保证同一时刻只有一个NameNode能够对Client的请求发出正确的响应
(a)每个NameNode改变状态的时候,向DataNode发送自己的状态和一个序列号
(b)DataNode在运行过程中维护此序列号,当failover时,新的NameNode在返回DataNode心跳时会返回自己的Active状态和一个更大的序列号;DataNode接收到这个返回时是认为该NameNode为新的Active
©如果这时原来的Active(比如GC)恢复,返回给DataNode的心跳信息包含Active状态和原来的序列号,这时DataNode就会拒绝这个NameNode
3.5 解决过程
- ActiveStandbyElector为了实现 Fencing,当NameNode成为ANN之后创建Zookeeperl临时节点ActiveStandbyElectorLock,创建ActiveBreadCrumb的持久节点,这个节点里面保存了这个ActiveNameNode的地址信息
- ActiveNameNode的ActiveStandbyElector在正常的状态下关闭Zookeeper Session的时候,会一起删除这个持久节点
- 如果ActiveStandbyElector在异常的状态下关闭,那么由于ActiveBreadCrumb是持久节点,会一直保留下来,当另一个NameNode选主成功之后,会注意到上一个ActiveNameNode遗留下来的这个节点,从而会回调ZKFailovercontroller的方法对旧的ActiveNameNode进行Fencing.
- 首先尝试调用这个旧ActiveNameNode的HAServiceProtocol RPC接口的TransitionToStandby方法,看能不能把它转换为Standby状态
- 如果TransitionToStandby方法调用失败,那么就执行Hadoop 配置文件之中预定义的隔离措施。
①sshfence:通过SSH 登录到目标机器上,执行命令fuser将对应的进程杀死
②shellfence:执行一个用户自定义的shell脚本来将对应的进程隔离
- 在成功地执行完成 fencing之后,选主成功的ActiveStandbyElector才会回调zKFailoverController的 becomeActive方法将对应的NameNode转换为Active状态,开始对外提供服务。
3.6 Zookeeper
- 为主备切换控制器提供主备选举支持
- 辅助投票
- 和ZKFC保持心跳机制,确定ZKFC的存活
十三、Federation联邦

HDFS Federation就是使得HDFS支持多个命名空间,并且允许在HDFS中同时存在多个Name Node。
1 单NameNode局限性
- ·Namespace(命名空间)的限制:单个DataNode从4T增长到36T,集群的尺寸增长到8000个DataNode;存储的需求从12PB增长到大于100PB
- 性能的瓶颈:整个HDFS文件系统的吞吐量受限于单个NameNode的吞吐量
- 隔离问题:HDFS上的一个实验程序就很有可能影响整个HDFS上运行的程序
- 集群的可用性:NameNode的宕机无疑会导致整个集群不可用
- Namespace和Block Management的紧密耦合
- 纵向扩展目前的NameNode不可行:将Namenode的Heap空间扩大到512GB启动花费的时间太长;NameNode在Full GC时,如果发生错误将会导致整个集群宕机
2 Federation

2.1 块池 Block Pool
- Block poo(块池)就是属于单个命名空间的一组Block(块)管理区域
- 每一个DataNode为所有的Block pool存储
- DataNode是一个物理概念,而Block pool是一个重新将Block划分的逻辑概念
- 一个NameNode失效不会影响其下的DataNode为其它NameNode的服务
- DataNode与NameNode建立联系并开始会话后自动建立Block pool
2.2 命名空间卷 Namespace Volume
- 一个Namespace和它的Block Pool一起称作Namespace Volume
- Namespace Volume是一个独立完整的管理单元; 当一个Namenode/Namespace被删除,与之相对应的Block Pool也会被删除
2.3 通过多个namenode/namespace把元数据的存储和管理分散到多个节点中
- 降低单个节点数据压力,计算压力
2.4 namenode/namespace可以通过增加机器来进行水平扩展
- 可以让更多的节点参与到运算
- namespace命名空间,通过这种方式确定要处理数据的路径
2.5 通过namenode和namespace组合使用
- 所有的NameNode共享DataNode
- 每一个Namespace会单独管理自己的块
- 会创建一个管理块的机制:Blocks pool
十四、搭建高可用集群
1 搭建Zookeeper
1.主机间相互免密钥
2.上传zookeeper解压拷贝
tar -zxvf zookeeper-3.4.6.tar.gz # [1]
mv zookeeper-3.4.6 /opt/ # [1]
3.修改配置文件
zoo.cfg
cd /opt/zookeeper-3.4.6/conf/ # [1]
cp zoo_sample.cfg zoo.cfg # [1]
vim zoo.cfg # [1]
# 修改zookeeper数据存放目录
dataDir=/var/data/zookeeper
# 设置服务器内部通信的地址和zk集群的节点
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
创建myid
[123]mkdir -p /var/data/zookeeper
[123]touch /var/data/zookeeper/myid
[1]echo 1 > /var/data/zookeeper/myid
[2]echo 2 > /var/data/zookeeper/myid
[3]echo 3 > /var/data/zookeeper/myid
拷贝zookeeper
scp -r /opt/zookeeper-3.4.6 root@node3:/opt/ # [1]
scp -r /opt/zookeeper-3.4.6 root@node4:/opt/ # [1]
设置环境变量
vim /etc/profile # [1]
# 添加
export ZOOKEEPER_HOME=/opt/zookeeper-3.4.6
export PATH=$ZOOKEEPER_HOME/bin:$PATH
scp /etc/profile root@node3:/etc/profile # [1]
scp /etc/profile root@node4:/etc/profile # [1]
source /etc/profile # [123]
开启集群
zkServer.sh start # [123]
zkServer.sh status # [123]
zkServer.sh stop # [123]
2 搭建高可用集群-HA
| NN-1 | NN-2 | DN | ZK | ZKFC | JN | |
|---|---|---|---|---|---|---|
| node1 | * | * | * | * | * | |
| node2 | * | * | * | * | * | |
| node3 | * | * | * |
1.预备条件
与伪分布式一样,需要主机间免秘钥并安装JDK
2.上传安装包并解压
tar -zxvf hadoop-2.7.1.tar.gz
3.修改JAVA_HOME配置信息
①hadoop-env.sh
# 25行
export JAVA_HOME=/usr/java/jdk1.8.0_162
②mapred-env.sh
# 16行
export JAVA_HOME=/usr/java/jdk1.8.0_162
③yarn-env.sh
# 23行
export JAVA_HOME=/usr/java/jdk1.8.0_162
4.修改核心配置文件
core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://myclustervalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>node1:2181,node2:2181,node3:2181value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/var/data/hadoop/havalue>
property>
configuration>
5.修改HDFS配置文件
hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservicesname>
<value>myclustervalue>
property>
<property>
<name>dfs.ha.namenodes.myclustername>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1name>
<value>node1:8020value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2name>
<value>node2:8020value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1name>
<value>node1:50070value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2name>
<value>node2:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://node1:8485;node2:8485;node3:8485/myclustervalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/var/data/hadoop/ha/jnvalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.myclustername>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
<value>shell(true)value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/root/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
configuration>
6.配置Slaves文件
vim slaves # [1]
# localhost
node1
node2
node3
7.配置Hadoop环境变量
vim /etc/profile # [1]
export HADOOP_HOME=/opt/hadoop-2.7.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
8.将配置好的文件拷贝至其它节点服务器上
scp -r hadoop-2.7.1 root@node2:`pwd` # [1]
scp -r hadoop-2.7.1 root@node3:`pwd` # [1]
scp /etc/profile root@node2:/etc/profile # [1] node23节点上存放zookeeper的环境变量
scp /etc/profile root@node3:/etc/profile # [1]
9.单独启动journalNode线程
[123]hadoop-daemon.sh start journalnode
[123]jps
10.启动zookeeper
[123]zkServer.sh start
[123]zkServer.sh status
11.初始化主namenode节点
[1]hdfs namenode -format
[1]hadoop-daemon.sh start namenode
12.启动备用namenode节点
[2]hdfs namenode -bootstrapStandby
13.格式化zkfc
[1]hdfs zkfc -formatZK
14.启动集群
开启集群
[1]start-dfs.sh
web端口:50070
15.创建文件夹及上传文件
[1]hdfs dfs -mkdir -p /abc/
[1]hdfs dfs -put ./a.txt /abc/
[1]hdfs dfs -D dfs.blocksize=1048576 -put ./a.txt /abc/
16.关闭
[1]stop-dfs.sh
[123]zkServer.sh stop