Hadoop ----HDFS MapReduce

HDFS
NameNode
- 负责管理DataNode
- 保存所有的元数据(目录的位置结构 存储的磁盘位置)
- 是HDFS的核心 是单点故障 一旦出现问题 整个HDFS不在对外提供服务·
- edits 操作日志文件
- fsimage元数据文件
SecondaryNameNode
- 获取NameNode的数据延后将新的NameNode数据进行合并 然后再次写入NameNode中
DataNode
- 负责数据的存储
- 数据是按块存储的 hadoop 2.XXX以后 128M
- DataNode定时(心跳机制) 将自己的状态信息告知 NameNode
副本
- 对DataNode中的数据块的数据进行备份
- 默认备份数量是3个

归档
打包文件
hadoop archive -archiveName test.har -p /input /outfile
查看
hdfs dfs -ls har:///outfile/test.har
恢复
hdfs dfs -cp har:///outfile/test.har/1.txt /aaa
namenode下的元数据
- 内存元数据 在服务运行过程中的元数据会保存在内存中 方便快速进行数据操作
- 文件元数据 按照指定规则去将内存中的元数据持久化的以文件的形式保存在磁盘上
- edits 编辑文件数据 保存了所有的文件操作
# 文件查看
hdfs oev -i edits文件 -o 输出文件
- fsimage 文件,保存了文件信息,数据的磁盘路径信息不在fsimage中保存,有datanode定时告知给namenode
# 文件查看
hdfs oiv -i fsimage文件 -p 执行文件类型xml -o 输出文件
- /excpet/data/hadoop
- dfs/data name secondayname

安全机制
- 一旦安全机制被触发就不能执行事务操作,删除、创建、移动。读取数据不受影响
- 副本数量小于1。 副本在没有被创建,删除了数据,
- 副本创建的数量比例不能小于0.999
- 在条件满足后需要等待30s退出安全机制
MapReduce 分而治之
- Map 负责拆分
- Reduce 负责合并
词频计算
1、创建一个1.txt写入一些单词
2、文件上传到input目录
3、进入/export/server/hadoop-3.3.0/share/hadoop/mapreduce
4、执行 hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output
5、执行查看 hdfs dfs -cat /output/part-r-00000
hadoop jar /export/server/hadoop-3.3.0/share/hadoop/tools/lib/hadoop-streaming-3.3.0.jar -D mapred.reduce.tasks=1 -mapper "python mapper.py" -reducer "python reducer.py" -file /root/mapper.py -file /root/reducer.py -input /input/* -output /outpy
YARN
1.功能作用说明
独立的资源管理平台 协调各个主机的资源(内存 CPU 磁盘)
可以服务多个分布式系统 hadoop sqark
2.三大组件
namenode NN datanode DN secondarynamendoe snn
RecourseManager 需要在主机上进行启动服务 RM
- 负责协调各个主机资源
NodeManager 需要在主机上进行启动服务 NM
- 负责监控本机资源状态 汇报给RecourseManager
ApplicationMaster 在进行计算时生成对应进程 AM
- 完成具体的资源计算调度,会找RecourseManager申请资源 在计算程序中 在计算程序中给计算程序指定相应的资源内容,计算完成后释放资源。
3.yarn调度流程
- 计算请求RM (RecourseManager)
- 生成AM(ApplicationMaster ) 管理每个计算资源
- AM评估当前计算需要的资源大小
- AM向MR申请资源 资源由RM进行资源调度
- Am进行资源计算分配,Map 和 Reduce分别得到对应的计算进行机选操作
- contain监控每个计算构成消耗资源情况
- 计算结束后AM释放资源并通知AM
- RM结束AM

4.调度机制
1.FIFO(first in first out) 先进先出 队形形式

2.**capacity 容量分配 **

3.pair 公平分配

4.Hadoop 配置文件 信息说明
hadoop_env.sh 配置用户 配置java环境
core_site.xml 配置核心功能 数据存储位置 ,主节点位置
hdfs_site.xml
mapred_site.xml
yarn_site.xml
works 指定运行的主机名称
Hadoop的HA(High Available) 高可用
活动节点
备用节点
活动节点对外提供服务,当活动节点宕机后启用备用节点
hadoop实现高可用是对应HDFS和YARN服务是按高可用节点管理
HDFS服务主要使用NameNode节点
YARN服务主要使用ResourceManager节点
- Hadoop 2.xxx 高可用配置
1.修改Linux主机名
2.修改IP
3.修改主机名和IP的映射关系 /etc/hosts
4.关闭防火墙
5.ssh免登陆
6.安装JDK,配置环境变量等
7.注意集群时间要同步
集群部署节点角色的规划(7节点)
------------------
server01 namenode zkfc
server02 namenode zkfc
server03 resourcemanager
server04 resourcemanager
server05 datanode nodemanager zookeeper journal node
server06 datanode nodemanager zookeeper journal node
server07 datanode nodemanager zookeeper journal node
------------------
集群部署节点角色的规划(3节点)
------------------
server01 namenode resourcemanager zkfc nodemanager datanode zookeeper journal node
server02 namenode resourcemanager zkfc nodemanager datanode zookeeper journal node
server03 datanode nodemanager zookeeper journal node
------------------
---------------------------------------------------------------------------------------------------------------
安装步骤:
1.安装配置zooekeeper集群
1.1解压
tar -zxvf zookeeper-3.4.5.tar.gz -C /home/hadoop/app/
1.2修改配置
cd /home/hadoop/app/zookeeper-3.4.5/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改:dataDir=/home/hadoop/app/zookeeper-3.4.5/tmp
在最后添加:
server.1=hadoop05:2888:3888
server.2=hadoop06:2888:3888
server.3=hadoop07:2888:3888
保存退出
然后创建一个tmp文件夹
mkdir /home/hadoop/app/zookeeper-3.4.5/tmp
echo 1 > /home/hadoop/app/zookeeper-3.4.5/tmp/myid
1.3将配置好的zookeeper拷贝到其他节点(首先分别在hadoop06、hadoop07根目录下创建一个hadoop目录:mkdir /hadoop)
scp -r /home/hadoop/app/zookeeper-3.4.5/ hadoop06:/home/hadoop/app/
scp -r /home/hadoop/app/zookeeper-3.4.5/ hadoop07:/home/hadoop/app/
注意:修改hadoop06、hadoop07对应/hadoop/zookeeper-3.4.5/tmp/myid内容
hadoop06:
echo 2 > /home/hadoop/app/zookeeper-3.4.5/tmp/myid
hadoop07:
echo 3 > /home/hadoop/app/zookeeper-3.4.5/tmp/myid
2.安装配置hadoop集群
2.1解压
tar -zxvf hadoop-2.6.4.tar.gz -C /home/hadoop/app/
2.2配置HDFS(hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)
#将hadoop添加到环境变量中
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_55
export HADOOP_HOME=/hadoop/hadoop-2.6.4
export PATH=$PATH:$JAVA_HOME/cluster1n:$HADOOP_HOME/cluster1n
#hadoop2.0的配置文件全部在$HADOOP_HOME/etc/hadoop下
cd /home/hadoop/app/hadoop-2.6.4/etc/hadoop
2.2.1修改hadoop-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_55
###############################################################################
2.2.2修改core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://cluster1value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/export/data/ha-hadoopvalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>node1:2181,node2:2181,node3:2181value>
property>
configuration>
###############################################################################
2.2.3修改hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservicesname>
<value>cluster1value>
property>
<property>
<name>dfs.ha.namenodes.cluster1name>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.cluster1.nn1name>
<value>node1:8020value>
property>
<property>
<name>dfs.namenode.http-address.cluster1.nn1name>
<value>node1:50070value>
property>
<property>
<name>dfs.namenode.rpc-address.cluster1.nn2name>
<value>node2:8020value>
property>
<property>
<name>dfs.namenode.http-address.cluster1.nn2name>
<value>node2:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://node1:8485;node2:8485;node3:8485/cluster1value>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/export/data/journaldatavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.cluster1name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/root/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>
configuration>
###############################################################################
2.2.4修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
###############################################################################
2.2.5修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>yrcvalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>node1value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>node2value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>node1:2181,node2:2181,node3:2181value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
2.2.6修改slaves(slaves是指定子节点的位置,因为要在hadoop01上启动HDFS、在hadoop03启动yarn,所以hadoop01上的slaves文件指定的是datanode的位置,hadoop03上的slaves文件指定的是nodemanager的位置)
hadoop05
hadoop06
hadoop07
2.2.7配置免密码登陆
#首先要配置hadoop00到hadoop01、hadoop02、hadoop03、hadoop04、hadoop05、hadoop06、hadoop07的免密码登陆
#在hadoop01上生产一对钥匙
ssh-keygen -t rsa
#将公钥拷贝到其他节点,****包括自己****
ssh-coyp-id hadoop00
ssh-coyp-id hadoop01
ssh-coyp-id hadoop02
ssh-coyp-id hadoop03
ssh-coyp-id hadoop04
ssh-coyp-id hadoop05
ssh-coyp-id hadoop06
ssh-coyp-id hadoop07
#注意:两个namenode之间要配置ssh免密码登陆 ssh远程补刀时候需要
###注意:严格按照下面的步骤!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
2.5启动zookeeper集群(分别在hadoop05、hadoop06、tcast07上启动zk)
bin/zkServer.sh start
#查看状态:一个leader,两个follower
bin/zkServer.sh status
2.6手动启动journalnode(分别在在hadoop05、hadoop06、hadoop07上执行)
hadoop-daemon.sh start journalnode
#运行jps命令检验,hadoop05、hadoop06、hadoop07上多了JournalNode进程
2.7格式化namenode
#在hadoop00上执行命令:
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置的目录下生成个hdfs初始化文件,
把hadoop.tmp.dir配置的目录下所有文件拷贝到另一台namenode节点所在的机器
scp -r tmp/ hadoop02:/home/hadoop/app/hadoop-2.6.4/
##也可以这样,建议hdfs namenode -bootstrapStandby
2.8格式化ZKFC(在active上执行即可)
hdfs zkfc -formatZK
2.9启动HDFS(在hadoop00上执行)
start-dfs.sh
2.10启动YARN
start-yarn.sh
还需要手动在standby上手动启动备份的 resourcemanager
yarn-daemon.sh start resourcemanager
到此,hadoop-2.6.4配置完毕,可以统计浏览器访问:
http://hadoop00:50070
NameNode 'hadoop01:9000' (active)
http://hadoop01:50070
NameNode 'hadoop02:9000' (standby)
验证HDFS HA
首先向hdfs上传一个文件
hadoop fs -put /etc/profile /profile
hadoop fs -ls /
然后再kill掉active的NameNode
kill -9 <pid of NN>
通过浏览器访问:http://192.168.1.202:50070
NameNode 'hadoop02:9000' (active)
这个时候hadoop02上的NameNode变成了active
在执行命令:
hadoop fs -ls /
-rw-r--r-- 3 root supergroup 1926 2014-02-06 15:36 /profile
刚才上传的文件依然存在!!!
手动启动那个挂掉的NameNode
hadoop-daemon.sh start namenode
通过浏览器访问:http://192.168.1.201:50070
NameNode 'hadoop01:9000' (standby)
验证YARN:
运行一下hadoop提供的demo中的WordCount程序:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar wordcount /profile /out
OK,大功告成!!!
测试集群工作状态的一些指令 :
hdfs dfsadmin -report 查看hdfs的各节点状态信息
cluster1n/hdfs haadmin -getServiceState nn1 获取一个namenode节点的HA状态
scluster1n/hadoop-daemon.sh start namenode 单独启动一个namenode进程
./hadoop-daemon.sh start zkfc 单独启动一个zkfc进程
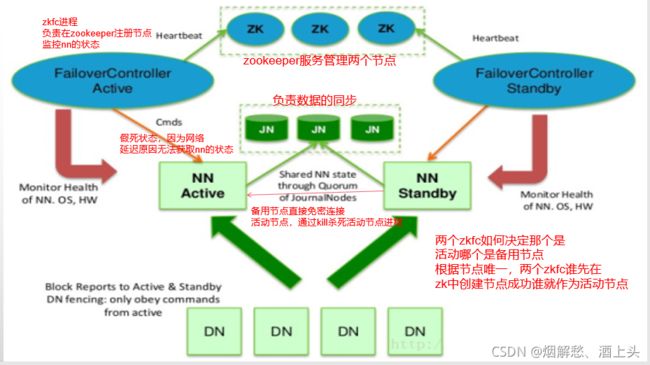
hadoop的HDFS对应一个namenode节点
实现高可用至少需要两个hadoop服务
使用zookeeper完成hadoop 的高可用主要用到了zookeeper的什么功能?
监听机制
临时节点
节点的唯一性
使用zkfc进程监控nn节点并且去连接zk进行状态更新
保证两个主备服务间的数据一致(QJM/Quorum Journal Manager)
hadoop资源调度服务有一个resourcemanager节点
使用zk实现resourcemanager节点的切换
resourcemanager本身不需要存储大量数据,可以直接把一些临时数据和一些nodemanager的信息存到zk
数据同步需要用zk的全局数据一致性
