详解c++---位图模拟实现
目录标题
- 为什么会有位图
- 一道题了解位图
- 模拟实现位图
-
- set
- reset
- test
- 构造函数
- 代码测试
- 关于位图的几道题
-
- 第一题
- 第二题
- 第三题
为什么会有位图
通过前面的学习想必大家应该已经了解了哈希表的原理,我们使用两种不同的方法来模拟实现哈希表,第一种方法就是闭散列,这种方法是创建一个数组通过数组来存储每个节点的内容并且每个节点还对应包含一个枚举变量用来表示当前节点的状态,第二种方法就是开散列也可以称为哈希桶,这种方法就是将vector容器和链表组合起来,每个节点除了存储变量的数据外还有一个指针变量用来存储当前节点的下一个节点的地址,这两种方法都可以存储数据,但是这两种方法都有一个问题,他们消耗的空间都要多了,除了要存储的本身数据外还得存储一些其他的变量用来维持当前的规律,所以当哈希表面对一些数据庞大但是要求十分简单的情况时就显得有点杀鸡用牛刀的感觉,那么面对一些数据十分庞大但是要求简单的情况我们就可以使用位图来进行解决。
一道题了解位图
我们来通过一道面试题来了解了解位图的原理: 给40亿个不重复的无符号整数,没有排过序,给一个无符号整数,如何快速判断一个数是否在这40亿个数中?有些同学看到这里肯定会想到这里肯定会想到这里可以使用哈希表来进行解决,直接将这40亿个数据全部都存储到哈希表里面然后判断的时候直接使用find哈数进行查找即可,但是这样做真的可以吗?我们来简单的计算一下,假设哈希表是通过哈希桶的方法来实现,存储一个无符号整型需要4个字节,存储一个指针也需要4个字节,所以存储一个数据哈希桶需要8个字节,这里存在40亿个数据也就需要320亿个字节,那么我们可以简单的算一下320亿个字节到底是多少:
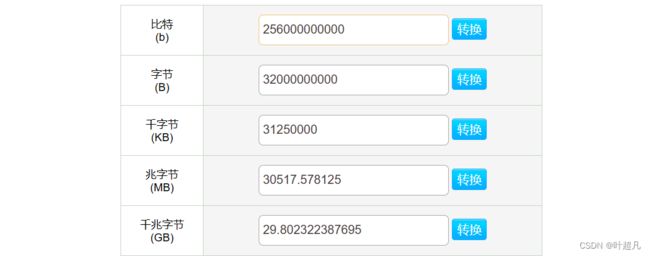
可以看到320亿个字节转换称为GB大概是30个GB,而我们平时使用的电脑也就8GB或者16GB,而用哈希表实现这么个功能需要大概30GB的空间,就算程序写好了我们的电脑也不一定能够正常的运行,并且这道题虽然数据庞大,但是想要的目的很简单只想知道一个数据是否存在即可,那我们将他的数据存储起来还有意义吗?一个数据在不在只有两种情况:在或者不在,那我们存储他数据本身还有意义吗?我们能不能使用另外一个东西表示数据的状态呢?当然是可以的,我们使用的计算机是二级制计算机,一个比特位刚好可以有两种情况1或者0,所以我们就可以使用一个比特位来表示每个数据的状态,1表述数据0就表示数据不存在,所以要想判断一个数据是否在40亿个无符号整型中出现过就可以使用40亿个比特来进行表示。而40亿个比特位转换一下也就是快0.5个G
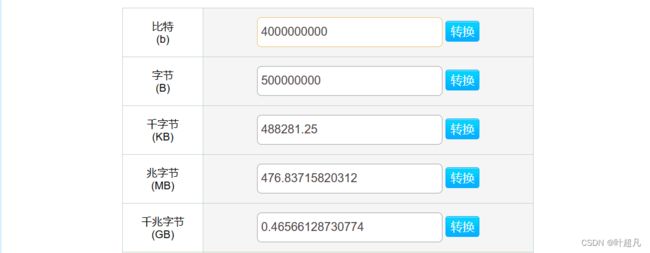
所以面对上面的问题我们这里就可以开辟42亿个比特位出来,第0个比特位就表示的是数据0是否存在,第1个比特位就可以表示数据1是否存在,第100个比特位就能够表示数据100是否存在,所以要想知道40亿个数据中哪些数据存在或者不存在就只需要遍历一遍40一个数据将对应的比特位上的0变成1,最后判断的时候根据简单的映射关系将数据对应到比特位看它是0还是1就可以解决这个问题,那么这就是位图的原理。
模拟实现位图
根据上面的讲解大家知道位图的方法就是开42亿个比特位,采用直接定值法的方式哪个数存在就把对应位的值修改为1,这种方法占用的内存就是512M。但是这个方法存在一个问题c++是不支持用位段的方式来开辟空间,所以我们只能用数组的形式来以char或者int为单元来一个一个的开辟空间,但是这就会存在一个问题:x映射的值,在第几个char或者int单元上呢?x映射的值在这个char或者int单元的第几个比特位上呢?那么这里的解决方法就是除8模8,但是这里就还有个问题如何让这个位的值由0变成1而其他位的值却保持不变呢?答案是对该位按位上1即可,比如说下面的图片:

当前数据的情况是这样:我们要是像让从左往右的第五位由0变成1的话就可以让他按位或上下面这样的数据即可:

这样就可以保证其他位不变的情况下让指定位由0变成1,而这个数据也可以通过将1左移一定的距离来实现,那么有了思路我们就可以模拟实现位图,首先位图也是一个模板,模板含有一个非类型的模板参数,类里面包含三个函数set,reset,test,这三个函数的功能分别是将位图中的某个位变成1,将位图中的某个位变成0,检测检测某个位上的数据是否为1,那么这里的位图类的底层就使用vector来模拟实现,并且vector的元素类型为char,那么这里的代码就如下:
#includeset
首先来实现以下set函数,要想将某个位变成1那么首先就得确定这个数字在哪个char单元上,那么这里就可以将x的值除上8来得到他在第几个char单元上,将x的值模上8来得到x的值是在char单元的第几个比特位上,比如说下面的代码:
void set(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
}
得到这个之后我们就可以通过数组的形式来获取对应char单元,然后对1进行左移来获取要用的数据,最后按位与就可以了,那么这里的代码就如下:
void set(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
ch[i] |= (1 << j);
}
当然这里肯定有小伙伴回想为什么是左移,难道不需要结合自己电脑采用的是大端存储还是小端存储综合来进行判断吗?答案是不需要的,大家回想一下我们在学习左移右移操作符的时候有分开讨论大端位存储还是小端存储吗?好像没有对吧,我们直说了左移是将数据往高位进行移动,右移是将数据往低段位进行移动跟大端机还是小端机没有任何关系!所以我感觉与其说是第一个char单元的第一个字节表示第一个数据,不如说是第一个char单元的最低位表示第一个数据,那么第二个char单元的最低位就表示的就是第9个数据,所以就可以按照上面的写法来实现。
reset
reset就是将对应位置的1改变成为0,那这是不是也可以使用上面同样的思路来进行实现对吧,然后这里就将除了该位的其他为全部按位或上1即可,然后对于指定位置按位或上0,所以这里的代码就如下:
void reset(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
ch[i] &= ~(1 << j);
}
test
test函数用来返回指定位置的数据是否为1,那么这里也采用相同的思路获取该位置上的数据然后将其结果进行返回即可,那么这里的代码就如下:
bool test(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
return ch[i] & (1 << j);
}
构造函数
位图有个模板,模板的参数是非模板参数,所以我们可以根据这个参数来确定要开辟多大的空间,那么构造函数里面我们就可以使用这个模板参数来给vector进行扩容,不如说我的数据范围是0-99,那么你就得开辟100个比特位大小的空间,也就是100/8+1个char单元(这里多开了一点也无所谓),那么这里的代码就如下:
bitset()
{
ch.resize(n / 8 + 1);
}
代码测试
我们可以用下面的代码来进行一下测试:
#include"bitset.h"
int main()
{
bitset<100> bs;
bs.set(5);
bs.set(10);
bs.set(15);
bs.set(85);
if (bs.test(85))
{
cout << "存在" << endl;
}
else
{
cout << "不存在" << endl;
}
bs.reset(85);
if (bs.test(85))
{
cout << "存在" << endl;
}
else
{
cout << "不存在" << endl;
}
return 0;
}
代码的运行结果如下:
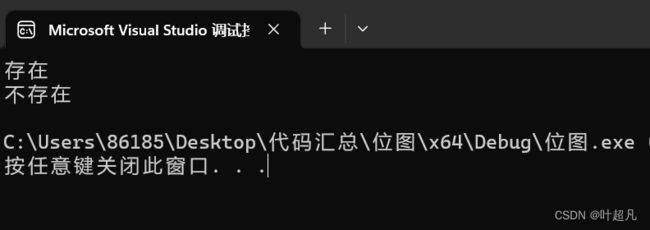
符合我们的预期,那么这里的代码实现就没有问题
关于位图的几道题
第一题
面试题:给定100亿个整数,设法找到只出现一次的整数
我们上面创建的位图是用一个比特位来表示一个数据的状态,但是这道题每个数据有多种情况,使用一个比特位无法全部表示,比如说一个数据可能没有出现,出现的次数为1,或者出现的次数大于1,这里存在三种情况用一个比特位肯定就没有办法表示,所以有小伙伴就想啊我们能不能用两个相邻的比特位来表示一个数据呢?比如说数据的范围是0~99我们就开辟200个比特位,每个数据有两个比特位来表示也就可以表示4种情况,但是这种方法得改变位图的结构很麻烦,所以我们采用另一种思路来解决这里的问题,创建两个位图,两个位图的相同位置表示同一个数据:00表示数据只出现了一次,01表示数据出现了一次,11表示数据出现了多次,那么这种思路就不需要我们改变原来的位图结构,那么这里的代码就如下:
template<size_t N>
class twobitset
{
public:
void set(size_t x)
{
if (!_bs1.test(x) && !_bs2.test(x)) // 00
{
_bs2.set(x); // 01
}
else if (!_bs1.test(x) && _bs2.test(x)) // 01
{
_bs1.set(x);
_bs2.reset(x); // 10
}
// 10
}
void PirntOnce()
{
for (size_t i = 0; i < N; ++i)
{
if (!_bs1.test(i) && _bs2.test(i))
{
cout << i << endl;
}
}
cout << endl;
}
private:
bitset<N> _bs1;
bitset<N> _bs2;
};
我们可以用下面的代码来做一个测试:
void test_twobitset()
{
twobitset<100> tbs;
int a[] = { 3, 5, 6, 7, 8, 9, 33, 55, 67, 3, 3, 3, 5, 9, 33 };
for (auto e : a)
{
tbs.set(e);
}
tbs.PirntOnce();
}
代码的运行结果如下:
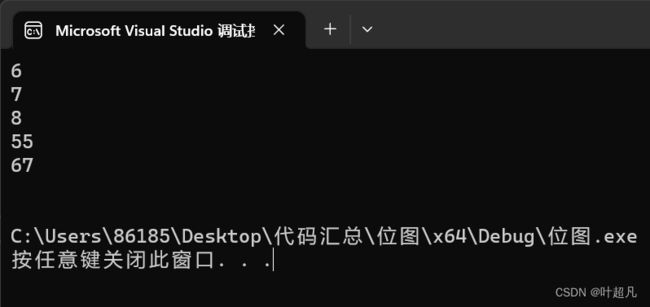
符合我们的预期,那么这就说明我们的代码实现的是正确的。
第二题
面试题:给两个分别含有100亿个整数的文件,我们只有1g的内存,如何找到两个文件的交集?
对于这种题我们的解决方法就是创建两个位图,每个位图对应一个文件的数据,只要数据出现了就将对应位置的数据置为1,两个文件的数据遍历完之后再来同时遍历两个位图,如果两个位图的相同位置都为一的话,就说明两个文件中都有这个数据,那么这就是这种题的解法。
第三题
面试题:给一个超过100G大小的log file,log中存着ip地址,设计算法找到出现次数最多的ip地址
这道题要找到出现次数最多的ip地址涉及到统计次数,所以就不能使用位图的方法来解决,而根据前面的学习我们知道map是可以用来统计次数的,所以这里使用map来解决此题,但是这里的数据有100个亿个数据,我们的内存一定装不下,因为不仅原始的数据多,map自身的数据还有消耗,但是这里也不能使用位图来存储数据,因为位图只能判断当前的数据在不在并不能统计次数,所以这里还是只能使用map来统计次数,100个亿我们无法一下子统计出来,但是我们可以将100亿个数据平均切割成为100份,这样我们就只用统计1份数据中出现的次数然后比较100份数据中出现次数最多的数据最终得到解决,但是这里的统计是不准确的因为不同的文件相同的ip出现的次数是没有联系的,所以这样统计的次数是不准确的,所以我们可以采用另外一个方法不使用平均切分而是哈希切分,这样出现在一个文件里面的数据要么是相同的要么是哈希冲突的,这样统计一个文件的数据就可以把100个G的数据中某个数据的次数全部统计出来,但是这里可能会出现一个问题因为map容器本身是存在额外的消耗的,所以当一个文件的数据大小超过一个G的话可能map就统计不下了,所以这个时候我们就得分情况进行讨论,首先就是文件确实超过了1个G但是map还是能够统计的下了,因为这个文件中大多数都是相同的数据,另外一个就是当前的文件超过一个G,但是map统计不下了这个时候map的insert函数就会插入失败,因为没有内存了,这就相当于new节点失败了,new会抛异常,这个时候我们就要对这个小文件换一个哈希函数再次递归切割,将该情况大于1个G的文件再次切分成为更小的文件这样就可以统计下来了,那么这就是本体的思路希望大家能够理解。