系统性谈谈软件可靠性——第5讲:软件测试及常见测试用例设计方法
目录
一、软件测试的概念
二、软件测试的分类
三、软件测试计划
四、测试用例的设计
五、测试用例的评审
六、如何记录Bug
七、回归测试
八、测试报告的输出
本文为拓展内容,《可靠性工程师手册》一书中并无此内容。本文参考书籍:《软件测试工程师》(江楚 编著),部分例子来自CSDN其他文章。
一、软件测试的概念
首先,我们要明确软件测试和软件可靠性测试是不同的。软件测试是从前期需求文档的评审,到中期测试用例及测试执行,再到后期问题单的提交和关闭等一系列的测试过程。
而软件可靠性测试,我们在上一节讲过了,是指为了满足用户对软件的可靠性要求,基于用户使用模型对软件进行测试,发现并纠正软件中的缺陷提高软件的可靠性水平,并验证软件能否达到用户可靠性要求的软件测试方法。
软件错误:测试人员在测试软件的过程中,当发现实际运行的结果和预期的结果不一致时(这个预期的效果其实就是指需求文档里面的规格要求),就把这个不一致的地方统成为软件错误。
软件错误不仅仅是指与需求文档不符的地方,在测试过程中,测试人员发现有影响用户体验和使用的任何地方,都可以把它当做软件错误提出来。软件错误称为Bug(Bug、错误、缺陷、问题,这四类表述是同一个意思)。
二、软件测试的分类
根据测试原理,软件测试可以分为黑盒测试、白盒测试、灰盒测试。
◆黑盒测试:黑盒测试(Black-box testing是通过使用整个软件或某种软件功能来严格地测试而并没有通过检查程序的源代码或者很清楚地了解该软件或某种软件功能的源代码程序具体是怎样设计的。测试人员通过输入他们的数据然后看输出的结果从而了解软件怎样工作。通常测试人员在进行测试时不仅使用肯定出正确结果的输入数据,而且还会使用有挑战性的输入数据以及可能结果会出错的输入数据以便了解软件怎样处理各种类型的数据。
◆白盒测试:白盒测试(White-box testing或glass-box testing是通过程序的源代码进行测试而不使用用户界面。这种类型的测试需要从代码句法发现内部代码在算法,溢出,路径,条件等等中的缺点或者错误,进而加以修正。
◆灰盒测试:灰盒测试(Gray-box testing就像黑盒测试一样是通过用户界面测试,但是测试人员已经有所了解该软件或某种软件功能的源代码程序具体是怎样设计的,甚至于还读过部分源代码,因此测试人员可以有的放矢地进行某种确定的条件或功能的测试。这样做的意义在于:如果你知道产品内部的设计和透过用户界面对产品有深入了解,你就能够更有效和深入地从用户界面来测试它的各项性能。
按测试阶段,软件测试可分为4个阶段,分别为单元测试、集成测试、系统测试、验收测试。

◆单元测试:一小段代码称为软件系统的最小组成单元,单元测试指对这小段代码进行测试。采用白盒测试的方法,主要由开发人员来做。
◆集成测试:单元模块组合在一起形成“组合体”。集成初期,模块比较少,采用白盒测试,由开发人员执行。集成后期,由于集成模块越来越多,模块之间的依赖性越来越强,此时,可对软件进行部分的功能测试,采用黑盒测试,一般也是由开发人员进行。
◆系统测试:对软件系统做全面测试,关注软件的外观界面、功能、性能、安全性、易用性、兼容性,采用黑盒测试方法,由测试人员进行。
外观测试:界面功能模块的布局是否合理,整体风格是否一致,界面文字是否正确,命名是否统一,页面是否美观,文字、颜色、图片组合是否完美等。
功能测试:软件所呈现给用户的所有功能点是否都能正常使用和操作,是否满足需求文档里的要求。
性能测试:软件在不同环境和压力下是否能正常运转,其中有一个很重要的指标就是系统响应时间。
安全性测试:测试软件防止非法侵入的能力。
易用性测试:测试软件是否容易操作,主观性比较强,站在用户的角度体验软件产品好不好用。
兼容性测试:测试该软件与其他软件的兼容能力,例如经常见的:与浏览器的兼容。
◆验收测试:由用户进行的测试,测试的内容与系统测试的内容相似,主要测试软件系统是否满足需求文档里的要求、是否满足用户的需求。采用的方法也是黑盒测试。通常验收测试通过之后,软件才能交付投产。例如:PLM系统的UAT1测试,UAT2测试。
三、软件测试计划
软件测试前,首先会制定软件测试计划,包括测试范围的描述、测试环境、测试策略、测试管理和测试中可能出现的风险。
测试范围:主要测试哪些内容,哪些内容不在本次测试范围中,是否需要额外的测试。
测试环境:运行软件的软硬件环境。例如测试的温度、湿度,也属于硬件环境。
测试策略:包括测试的依据、测试的准入标准、测试工具的选择、测试的重点及方法、测试的准出标准等内容。
测试管理:任务的分配,时间进度的安排,沟通方式。
测试风险:常见风险有不透彻理解需求温度、估计不足测试时间、测试执行不到位。
一般有各类模板来体系管控,举例:一个测试环境确认表(局部摘录)
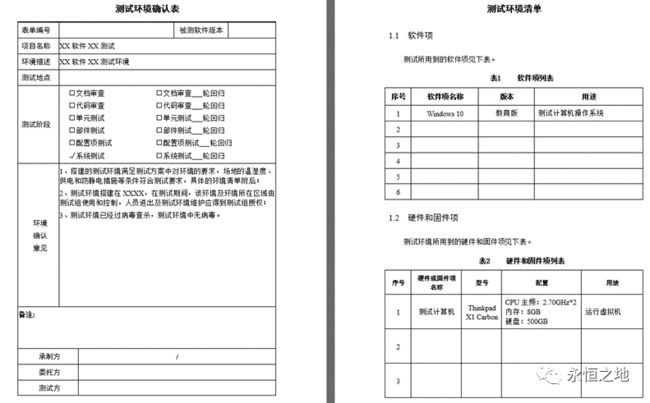
四、测试用例的设计
什么是测试用例?测试用例是为某个特殊目标而编制的一组测试输入、执行条件以及预期结果,以便核实是否满足某个特定需求。
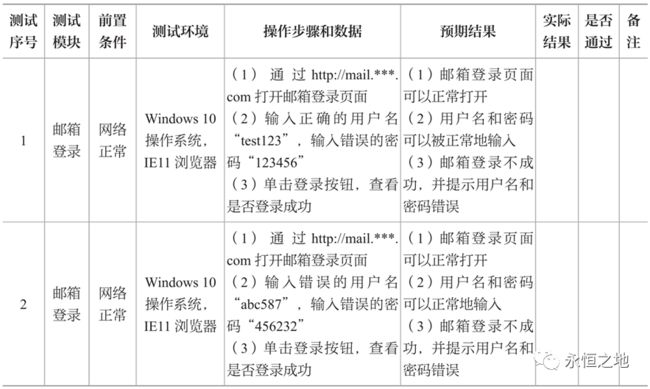
测试用例是测试的一个例子,这个例子包括:测试序号、测试模块、前置条件、测试环境、操作步骤和数据、预期结果、实际结果、是否通过、备注这9个关键的基本元素。每个公司的规范可能不一样,有的还包括测试时间、测试人员、软件的版本名称、优先级等一些附加元素。
我们以邮箱登录为例:
一个测试用例如下:
五种常见测试用例设计方法:
(1)等价类划分法
等价类划分法是一种重要的、常用的黑盒测试方法,它将不能穷举的测试过程进行合理分类,从而保证设计出来的测试用例具有完整性和代表性。
这里有两个概念,有效等价和无效等价。
有效等价:有效,是指它们都是符合需求文档中定义的数据;等价,是指它们都是同一类型的数据。
无效等价:无效,是指它们都是不符合需求文档中定义的数据;等价,是指它们都是同一类型的数据。
举个例子,很多时候我们会有填年龄的情形,假设要求的是填20-99的整数。

那我们就可以把值划分为:

取代表性数据后:
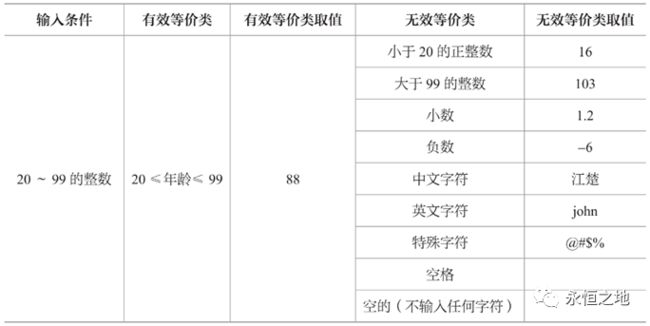
(2)边界值分析法
边界值分析法是取稍高于或稍低于边界的一些数据进行测试,通常被视为对等价类划分法的一种补充。
在以下两种情况下经常被用到:第一种,输入条件是一个取值范围;第二种,输入条件规定输入的数据是一个有序集合。
为什么要取这些数据做测试?因为测试经验告诉我们,程序在处理边界数据的时候容易出错。
继续上面的例子:

涉及的边界值如下:

(3)错误推测法
测试人员凭借自己的直觉、测试经验、发散思维去设计一些容易导致软件出错的测试点,也可看作是对等价类划分法和边界值分析法的一个补充。
还是这个例子:
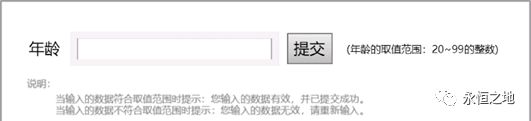
一般情况下,程序在处理空格、空的、边界值、超长字符串、全角字符串、0以及单引号等情况下较容易出错。所以使用错误推测法,取值如下:
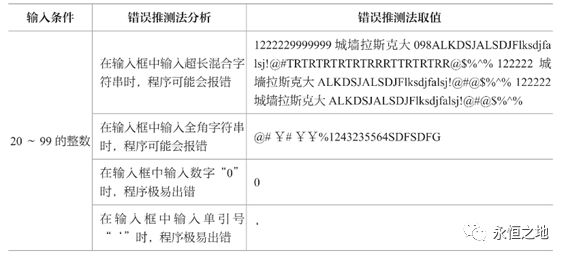
工作中可根据自己的想象力,或者参考以前测试过的模块和设计过的测试用例,尽可能地多去设计出有可能让程序出现错误的测试点。这个就比较靠想象力和经验了。
测试数据的整合
运用前面3种测试用例的设计方法,把测试点统一到一个表中,就变成了一个较为完整的测试用例。
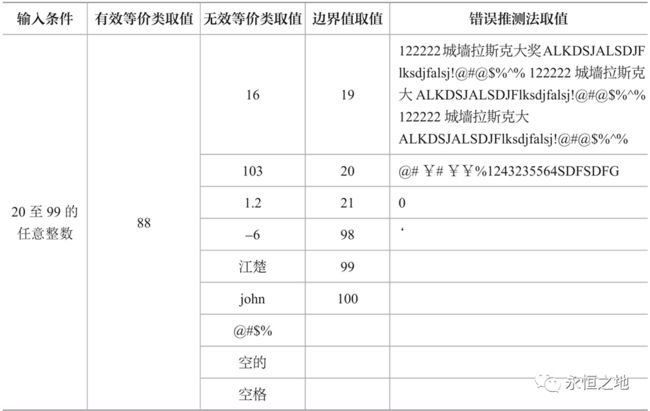
测试用例中可能存在等价,如上表中的16和19,103和100,如何选取?一般可以把靠近边界的值保留下来,对于相对复杂的需求文档,也可以把这些数据全部测试一遍。
(4)正交表分析法
正交表分析法是一种有效地减少用例设计个数的方法。测试人员需要根据实际的业务场景和组合特点进行算法设计,必要时还可以咨询开发人员,最终的目的就是选择一些典型的组合进行测试。
我们举个例子,某个人信息查询系统的查询页面如下,只有3个框都输入时才可查询:
我们要验证的就是3个框都有输入时才可以查询,其他情况都不可查询。它全部的组合可能如下,一共8个组合,称之为3因子2水平全测试用例:![]()
而如果我们采用正交表方法,则可以用如下组合去完成验证,对比原来少了3个测试用例:

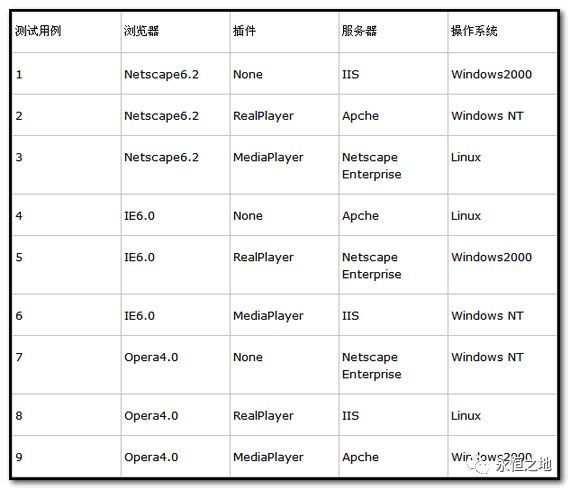
再举一个例子,假设一个WEB站点,该站点有大量的服务器和操作系统,并且有许多具有各种插件的浏览器浏览:
WEB浏览器:Netscape6.2、IE6.0、Opera4.0
插件:无、RealPlayer、MediaPlayer
应用服务器:IIS、Apche、Netscape Enterprise
操作系统:Windows2000、Windows NT、Linux
属于4因子3水平,全部组合会去到3^4=81种,测试起来就很麻烦。可以用正交表去设计,我们选L9,我用minitab跑了出来:
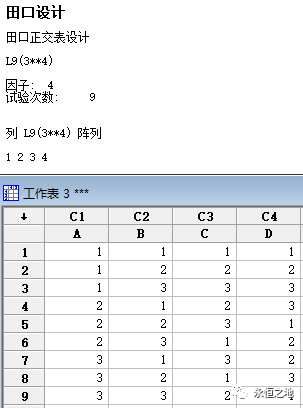
WEB浏览器:1=Netscape6.2、2=IE6.0、3=Opera4.0
插件: 1=None、2=RealPlayer、3=MediaPlayer
应用服务器: 1=IIS、2=Apche、3=Netscape Enterprise
操作系统: 1=Windows2000、2=Windows NT、3=Linux
把因子、状态映射上去,就得到了正交表:
(5)因果判定法
因果判定法一般主要应用于页面中各类按钮之间存在组合和制约的关系,测试人员需要去分析它们的因果对应关系,并最终去检查输出结果的正确性。
比如这个例子,常见的就是公交充值,地铁充值。

列出它的因果判断表如下:
因果判定法的步骤:
1.明确所有的输入条件(因)。
2.明确所有的输出条件(果)。
3.明确哪些条件可以组合在一起,哪些条件不能组合在一起。
4.明确什么样的输入组合条件可产生哪些输出结果。
5.通过判定表展示输入条件的组合与输出结果的对应关系。
6.根据判定表设计测试用例。
我们做家电,很多按键的组合,是可能存在的,其实应该去做因果判定。
比如我举一个例子,假设某机器,只有2个按键,长按,短按,同时按,都会有不同的结果,我们假设是如下表这样要求的:

这样一个因果判断表,我们看起来觉得很简单。但是软件设计的时候,就很可能会出错。例如对按键的去抖没做好,对两个按键信号的优先级没有考虑好,就很可能出问题。
我遇到的一个真实的案例,用户真就误触发了组合按键,而这个按键理论上不应该被用户触发。
五、测试用例的评审
我在讲评审时提到,评审是包含方方面面的,包括了测试方案的评审。
测试用例评审的目的在于,通过测试用例的评审,确保用例是全面的、正确的、没有冗余的。
评审主要内容包括:
1.测试用例是否是依据需求文档编写的。
2.测试用例中的执行步骤、输入数据是否清晰、简洁、正确;对于重复度高的执行步骤,是否进行了简化。
3.每个测试用例是否都有明确的预期结果。
4.测试用例中是否存在多余的用例(无效、等价、冗余的用例)。
5.测试用例是否覆盖了需求文档中所有的功能点,是否存在遗漏。
需求、开发过程中是存在变化的,测试案例在不同的阶段需要维护。
如同FMEA一样,很难见到一份非常完美的测试用例,你很难穷举覆盖所有,写得很完善。
我自己参与过的大项目测试,就觉得有些测试用例描述不清晰,且覆盖不够。因为内部项目,这里就不举例放出来了。
六、如何记录Bug
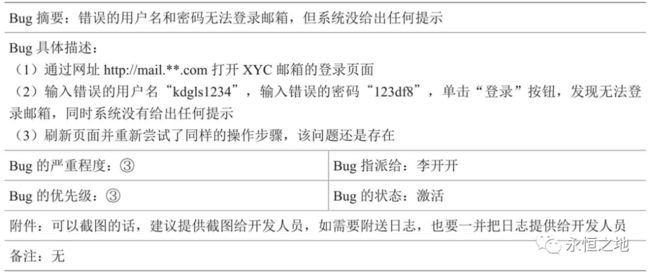
1.Bug的概要一定要清晰简洁。
2.在Bug的具体描述中,测试的步骤和使用到的具体数据都要清楚地写出来。
3.如果可以截图,一定要截图,因为这是最直接的证据。
主流Bug管理工具有很多,如Test Director(简称TD)、Quality Center(简称QC,它是TD的升级版)、JIRA、禅道、Mantis以及各公司自行开发的Bug管理工具等。
七、回归测试
开发人员把Bug修复好之后,测试人员需要重新验证Bug是否修复好了,同时在新版本中进行测试以检测开发人员在修复代码过程中是否引入新的Bug,此过程称为回归测试。
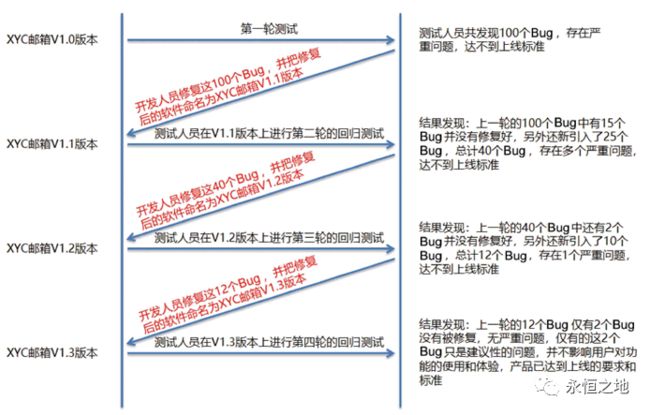
1.回归测试执行全部的测试用例。一般情况下,当第一轮测试发现的Bug数量过多时,第二轮回归测试应该执行全部用例。
2.选择重要的功能点、常用的功能点、与Bug相关联的功能点进行回归测试。
3.选择性执行关键功能点的测试用例。
4.仅测试出现Bug的功能点。
每个策略都有其适应的场景,不能一概而论,应当以Bug的数量和严重程度为导向,深入分析,然后得出适合本项目的回归测试策略。
说到回归测试,我就觉得我们比较痛苦,原因是开发过程中,很可能因为需求变化,导致程序要改变。
八、测试报告的输出
最后输出测试报告,描述软件的测试过程、测试环境、测试范围、测试结果,分析总结存在的风险以及测试结论。
举例:一份软件测试报告内容

本文为《软件可靠性简介》培训课程中摘录的公开内容,关注微信公众号“永恒之地”,后台回复“软件可靠性”,下载培训课件。
