XLM-RoBERTa: 一种多语言预训练模型
点击上方,选择星标或置顶,每天给你送干货 !
!
阅读大概需要5分钟
跟随小博主,每天进步一丢丢


每日英文
Wisdom in the mind is better than money in the hand.
脑中有知识,胜过手中有金钱。
Recommender:云不见
作者:Branden Chan
原文链接:
https://medium.com/deepset-ai/xlm-roberta-the-multilingual-alternative-for-non-english-nlp-cf0b889ccbbf
翻译:王萌 澳门城市大学(深度学习自然语言处理公众号)
多语言模型是否改善了单语言模型的不足?

巴别塔(图片来自维基百科)
如果您使用非英语语言进行NLP,则经常会困扰于“我应该使用哪种语言模型?”这一问题。尽管社区的单语训练模型越来越多,但还有一种似乎不太受关注的替代方法:多语言模型。
在本文中,我们重点介绍XLM-R模型的关键要素,并探讨其在德语中的性能。我们发现,在三个流行的德语数据集上,它的表现优于我们的单语德语;虽然在 GermEval18 (仇恨语音检测) 上与 SOTA 性能相当,但在 GermEval14 (NER) 上显著优于以前的方法。
为什么要使用多语言模型?
XLM-Roberta的出现正值非英语模式如Finnish BERT,French BERT(又称CamemBERT)和German BERT激增之时。通过与研究人员的交流互动以及与业界的联系,我们意识到,现在确实需要将尖端NLP技术用于非英语语言。
我们也坚信,多语言模型对于那些期望未来扩张的公司来说是一个很好的解决方案。过去,我们与客户合作过,这些客户目前只使用一种语言运营,但有将服务扩展到全球的雄心。对他们来说,多语言模型是一种面向未来的形式,可确保其有的 NLP 基础架构能够让他们无论选择多少地区开展业务都可以去拓展。
XLM-Roberta有什么新功能?
Facebook AI团队于2019年11月发布了XLM-RoBERTa,作为其原始XLM-100模型的更新。它们都是基于转换器的语言模型,都依赖于掩码语言模型目标,并且都能够处理100种不同语言的文本。相较于原始版本,XLM-Roberta的最大更新是训练数据量的显著增加。经过清洗训练过的常用爬虫数据集占用高达2.5tb的存储空间!它比用来训练其前身的Wiki-100语料库大几个数量级,并且在资源较少的语言中,扩展尤其明显。它比用来训练其前版本的Wiki-100语料库大几个数量级,并且在资源较少的语言中,这种扩大尤其明显。“ RoBERTa”从某方面来说,它的训练程序与单语言RoBERTa模型相同,特别是唯一的训练目标是掩码语言模型。它没有下句预测的á la BERT模型或者句子顺序预测的á la ALBERT模型。
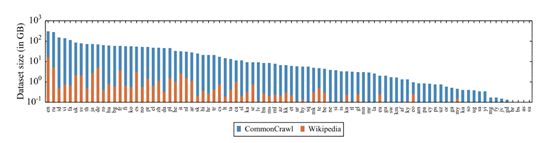
每种语言的常见爬虫数据集的容量增加超过了维基百科的(来自XLM-RoBERTa论文)
XLM-Roberta现在使用一个大型共享语句块模型来标记字符串,而不是像XLM-100那样具有大量特定语言的分词器。验证困惑度也不再用作训练时的停止标准,因为研究人员发现,即使困惑度没有提高,后续性能也继续提高。
结果
最后,我们对XLM-RoBERTa的一分类和两项NER任务进行了评估,它们表现出了非常出色的性能。XLM-RoBERTa Large与GermEval18(分类)的最佳提交分数不相上下。在GermEval14(NER)上,该模型在F1的表现比在Flair的要好2.35%。

评估结果。这里是GermEval18 的排行榜,这里是Flair报告的分数
这些结果是在不进行大量超参数调整的情况下得出的,我们希望通过进一步调整学习率和batch大小可以改善这些结果。另外,对于NER任务,我们认为在XLM-RoBERTa的上一层添加CRF层会有所收获。

结论
这些结果实力表明,即使在单一语言上进行评估,多语言模型也表现出出色的性能,我们建议德国NLP从业人员在为其NLP系统选择语言模型时至少考虑XLM-Roberta变体之一。打破以英语为中心的NLP研究的重要性已经被Emily Bender教授广泛地讨论过,我们相信非英语语言的研究只会增加。我们认为,未来最好的模型可以从文本中学习,不仅可以从不同的领域而且可以从不同的语言中学习,这并不是不可思议的。
编辑于17/02/20:我们之前曾报告过CoNLL2003的分数由于数据集问题而有误
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
专辑 | NLP论文解读

整理不易,还望给个在看!