spark原理及其优化
一、spark大数据处理引擎介绍
Spark是一种基于内存的快速、通用、可扩展的大数据分析引擎。
spark版本演进
- 2009 年,Spark 诞生于伯克利大学的 AMPLab 实验室;
- 2010 年,伯克利大学正式开源了 Spark 项目;
- 2013 年 6 月,Spark 成为了 Apache 基金会下的项目;
- 2014 年 2 月,Spark 以飞快的速度成为了 Apache 的顶级项目;
- 2014年 6 月,发布1.0版本
- 内存计算
- 丰富API、多语言支持
- 一站式解决方案
- 多部署模式
- 2016 年 7 月发布2.0版本
- ANSI SQL and Streamlined APls
- Structured Streaming
- Whole-stage Code Generation
- 2020年发布3.0版本
- Adaptive Query Execution
- Dynamic Partition Pruning
- Accelerator-aware scheduling
- 2022年发布3.3版本
- Bloom Filter Joins
- Query Execution Enhancements
spark生态与特点
- Spark Core
Spark Core 中提供了 Spark 最基础与最核心的功能,Spark 其他的功能如:Spark SQL,Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基础上进行扩展的。
- Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
- Spark Streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的 API。
- Spark MLlib
MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
- Spark GraphX
GraphX 是 Spark 面向图计算提供的框架与算法库。
特点
- 统一引擎,支持多种分布式场景
- 多语言支持
- 支持java/Scala、SQL、Python、R
- 可读写丰富数据源
- 内置DateSource
- 自定义DateSource
- 丰富灵活的API/算子
- SparkCore的RDD
- SparkSQL的DateFrame
- 支持K8S/YARN/Mesos资源调度
Spark部署模式
- Local模式
所谓的 Local 模式,就是不需要其他任何节点资源就可以在本地执行 Spark 代码的环境,一般用于教学,调试,演示等,之前在 IDEA 中运行代码的环境我们称之为开发环境,不太一样。
- Standalone模式
local 本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用 Spark 自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式。Spark 的 Standalone 模式体现了经典的 master-slave 模式。集群规划:
- Yarn模式
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。(其实是因为在国内工作中,Yarn 使用的非常多)。
spark相关名词
-
Application(应用):Spark上运行的应用。Application中包含了一个驱动器(Driver)进程和集群上的多个执行器(Executor)进程。
-
Driver Program(驱动器):运行main()方法并创建SparkContext的进程。
-
Cluster Manager(集群管理器):用于在集群上申请资源的外部服务(如:独立部署的集群管理器、Mesos或者Yarn)。
-
Worker Node(工作节点):集群上运行应用程序代码的任意一个节点。
-
Executor(执行器):在集群工作节点上为某个应用启动的工作进程,该进程负责运行计算任务,并为应用程序存储数据。
-
Task(任务):执行器的工作单元。
-
Job(作业):一个并行计算作业,由一组任务(Task)组成,并由Spark的行动(Action)算子(如:save、collect)触发启动。
-
Stage(阶段):每个Job可以划分为更小的Task集合,每组任务被称为Stage。
Spark目前支持几个集群管理器:
-
Standalone :Spark 附带的简单集群管理器,可以轻松设置集群。
-
Apache Mesos:通用集群管理器,也可以运行 Hadoop MapReduce 和服务应用程序。(已弃用)
-
Hadoop YARN: Hadoop 2 和 3 中的资源管理器。
-
Kubernetes:用于自动部署、扩展和管理容器化应用程序的开源系统。
二、SparkCore原理解析
什么是RDD
-
RDD(Resilient Distributed Dataset):弹性分布式数据集,是一个容错的、并行的数据结构
-
RDD算子:对任何函数进行某一项操作都可以认为是一个算子,RDD算子是RDD的成员函数
rdd要素

Transform(转换)算子: 根据已有RDD创建新的RDD
Action(动作)算子: 将在数据集上运行计算后的数值返回到驱动程序,从而触发真正的计算
DAG(Directed Acyclic Graph): 有向无环图,Spark中的RDD通过一系列的转换算子操作和行动算子操作形成了一个DAG
DAGScheduler:将作业的DAG划分成不同的Stage,每个Stage都是TaskSet任务集合,并以TaskSet为单位提交给TaskScheduler。
TaskScheduler:通过TaskSetManager管理Task,并通过集群中的资源管理器(Standalone模式下是Master,Yarn模式下是ResourceManager)把Task发给集群中Worker的Executor
Shuffle:Spark中数据重分发的一种机制。
两类RDD算子
- Transform算子:生成一个新的RDD
- map/filter/flatMap/groupByKey/reduceByKey…
- Action算子
- collect/count/take/saveAsTextFilel…
RDD依赖
-
窄依赖
- 父RDD的每个partition至多对应个子RDD分区。
-
宽依赖
- 父RDD的每个partition都可能对应多个子RDD分区。

执行流程

调度
根据ShuffleDependency 切分 Stage,并按照依赖顺序调度Stage,为每个Stage生成并提交TaskSet到 TaskScheduler

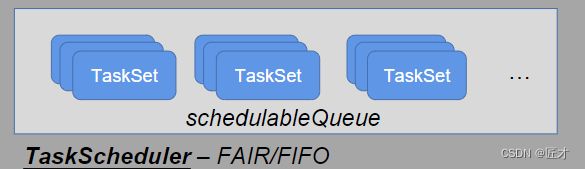
根据调度算法(FIFO/FAIR)对多个TaskSet进行调度,对于调度到的TaskSet,会将Task 调度(locality)到相关Executor上面执行,Executor SchedulerBackend提供

内存管理
UnifiedMemoryManager 统一管理多个并发Task的内存分配
每个Task获取的内存区间为1/(2*N)~1/N,
N为当前Executor中正在并发运行的task数量

三、SparkSQL原理解析


DataFrame: 是一种以RDD为基础的分布式数据集, 被称为SchemaRDD
DataSource:SparkSQL支持通过 DataFrame 接口对各种数据源进行操作。
Runtime Filter:运行时过滤
Codegen:生成程序代码的技术或系统,可以在运行时环境中独立于生成器系统使用
SparkSql执行过程:
-
Unresolved Logical Plan:未解析的逻辑计划,仅仅是数据结构,不包含任何数据信息。
-
Logical Plan:解析后的逻辑计划,节点中绑定了各种优化信息。
-
Optimized Logical Plan:优化后的逻辑计划
-
Physical Plans:物理计划列表
-
Selected Physical Plan 从列表中按照一定的策略选取最优的物理计划
Catalyst优化器
Catalyst:SparkSQL核心模块,主要是对执行过程中的执行计划进行处理和优化
RBO
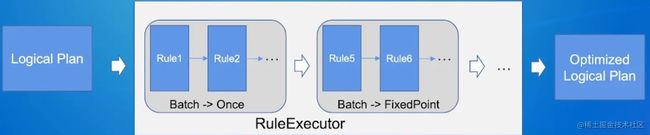
Batch执行策略:
-
Once ->只执行一次
-
FixedPoint -> 重复执行,直到plan不再改变,或者执行达到固定次数(默认100次)
RBO匹配规则:
transformDown 先序遍历树进行规则匹配
transformUp 后序遍历树进行规则匹配
AQE(Adaptive Query Execution自适应查询)
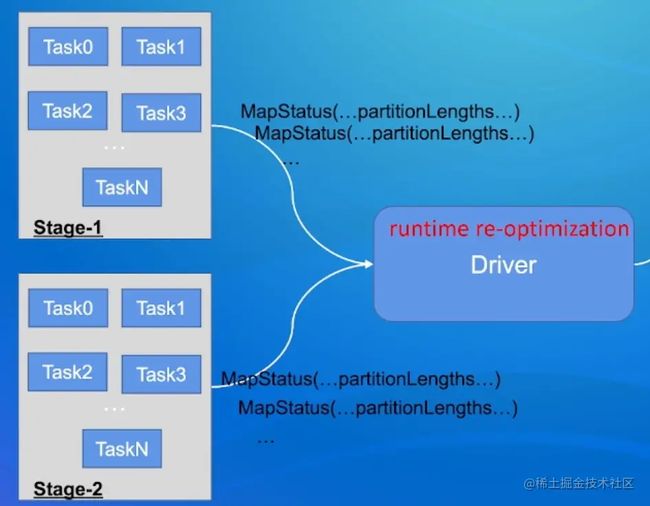
每个Task结束会发送MapStatus信息给Driver
Task的MapStatus中包含当前Task Shuffle产生的每个Partition的size统计信息
Driver获取到执行完的Stages的MapStatus信息之后,
按照MapStatus中partition大小信息识别匹配一些优化场景,然后对后续未执行的Plan进行优化
特点:边优化边执行,根据已经完成计划的真实节点去做统计,进行反馈,优化剩余计划。
所支持的优化场景
- Partition合并

作业运行过程中,根据前面运行完的Stage的MapStatus中实际的partition大小信息,可以将多个相邻的较小的partition进行动态合并,右一个Task读取进行处理。
- 动态切换JOIN策略

1…存在的问题时Catalyst Optimizer优化阶段,算子的statistics估算不准确,生成的执行计划并不是最优。
2.的解决方案时AQE运行过程中动态获取准确JOIN的leftChild/rightChild的实际大小,将SMJ转换为BHJ。
- Skew Join

AQE根据MapStates信息自动检测是否右倾斜,将大的partition拆分成多个Task进行Join
Runtime Filter
Runtime Filter减少了大表的扫描,shuffle的数据量以及参加啊Join的数据量,所以对整个集群IO/网络/CPU有比较大的节省
Bloom Runtime Filter
Codegen Expression(表达式)

将表达式中的大量虚函数调用压平到一个函数内部,类似手写代码。动态生成代码,Janino即时编译执行
WholeStageCodegen

原先编译的火山模型算子之间大量的虚函数调用,开销大
现在将同一个Stage中的多个算子压平到一个函数内部去执行。
untime Filter
Codegen Expression(表达式)
[外链图片转存中…(img-Fuk2lc7i-1660053933146)]
将表达式中的大量虚函数调用压平到一个函数内部,类似手写代码。动态生成代码,Janino即时编译执行
WholeStageCodegen
[外链图片转存中…(img-aARYujLF-1660053933147)]
原先编译的火山模型算子之间大量的虚函数调用,开销大
现在将同一个Stage中的多个算子压平到一个函数内部去执行。