大数据——SparkCore学习笔记
Spark
一、Spark简介
- Spark 是一种由 Scala 语言开发的快速、通用、可扩展的大数据分析引擎
- Spark Core 中提供了 Spark 最基础与最核心的功能
- Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
- Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
Spark 和Hadoop 的根本差异是多个作业之间的数据通信问题 : Spark 多个作业之间数据通信是基于内存,而 Hadoop 是基于磁盘。
hadoop file---->map---->data---->reduce---->file---->map…
spark file---->map---->data---->reduce---->memory---->map…

二、Spark运行架构
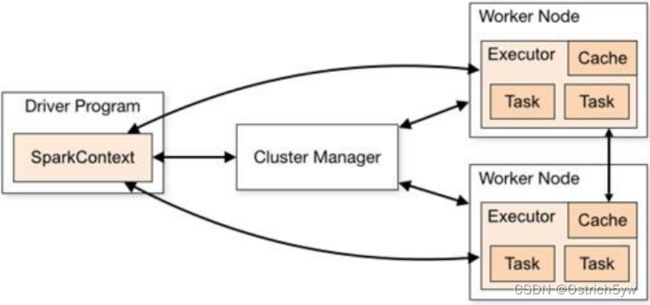
Spark独立部署下,其Master相当于ResourceManager,Worker相当于NodeManager
Yarn模式下,直接由ResourceManager进行调度,Executor运行在NodeManager中
1. 两类工作节点:Driver与Worker
——驱动器节点(Driver)
Driver 负责实际代码的执行工作,在 Spark 作业执行时主要负责:
➢ 将用户程序转化为作业(job)
➢ 在 Executor 之间调度任务(task)
➢ 跟踪 Executor 的执行情况
➢ 通过 UI 展示查询运行情况
——工作节点(Worker)
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了 故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点 上继续运行。
➢ 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
➢ 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
2. Yarn模式下两种部署方式:Client与Cluster
——Client 模式将用于监控和调度的Driver模块在客户端执行,而不是在Yarn中
➢ Driver 在任务提交的本地机器上运行
➢ Driver 启动后会和 ResourceManager 通讯申请启动 ApplicationMaster
➢ ResourceManager分配container,在合适的NodeManager上启动 ApplicationMaster,负责向ResourceManager申请Executor内存
➢ ResourceManager接到ApplicationMaster 的资源申请后会分配 container,然后 ApplicationMaster 在资源分配指定的 NodeManager 上启动 Executor 进程
➢ Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行 main 函数
➢ 执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个stage生成对应TaskSet,之后将task分发到各个Executor上执行。
——Cluster 模式将用于监控和调度的 Driver 模块启动在 Yarn 集群资源中执行。
➢ 在 YARN Cluster 模式下,任务提交后会和 ResourceManager 通讯申请启动 ApplicationMaster
➢ 随后 ResourceManager 分配 container,在合适的 NodeManager 上启动 ApplicationMaster, 此时的 ApplicationMaster 就是 Driver。
➢ Driver 启动后向 ResourceManager 申请 Executor 内存,ResourceManager 接到 ApplicationMaster 的资源申请后会分配 container,然后在合适的 NodeManager 上启动 Executor 进程
➢ Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行 main 函数
➢ 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生 成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。
三、Spark核心编程
Spark封装了三大数据结构,用于 处理不同的应用场景。三大数据结构分别是:
➢ RDD : 弹性分布式数据集
➢ 累加器:分布式共享只写变量
➢ 广播变量:分布式共享只读变量
(1)RDD(Resilient Distributed Dataset)
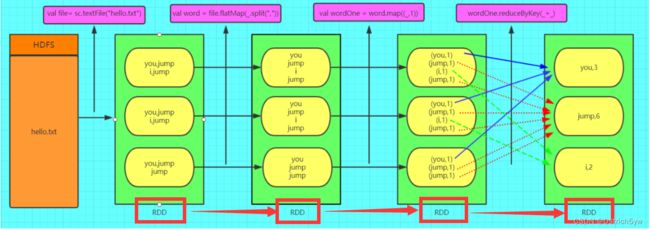
弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
上述图中四个步骤的具体关系如图所示,RDD与IO流类似,都属于装饰者模式。如下图中,每一个RDD都是封装关系。
-
RDD在运行流程中不存储数据
-
RDD只有在执行collect函数时,才会真正开始执行业务逻辑
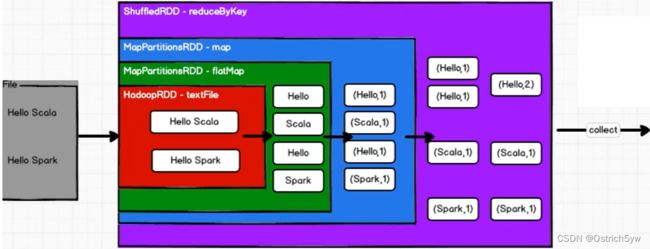
RDD五大属性 -
分区列表:用于执行并行任务
-
分区计算函数:用于对分区进行计算
-
RDD间依赖关系:如上图所示的封装关系
-
分区器:对KV类型的数据进行自定义分区
-
首选位置:保障计算任务下发到数据近邻节点
RDD运行流程

RDD算子(方法)
注意:(1)Spark中,涉及到shuffle操作必须进行落盘处理,因为在内存中等待可能造成内存溢出。解释——比如groupByKey操作下,分区一的数据已经处理完毕,而分区二的数据还未处理完成,就会等待二中的数据全部处理完成才算操作完成。这个等待过程可能消耗大量内存。
(2)从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor 端执行。那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就 形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor 端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列化,这个操作我们称之为闭包检测。
(3)涉及shuffle的操作会将分区的数据打乱重组。所以针对操作如果涉及shuffle,我们将其分为不同执行阶段。每一个阶段的最后一个RDD的分区个数就是执行的任务个数。
- 一个SparkContext对应一个Application
- 一个Action算子对应一个Job
- 一个shuffle操作对应一个新的Stage
- 一个Stage中最后一个RDD的分区个数对应Task个数
——Value类型
| 方法名 | 作用 |
|---|---|
| map(func) | 将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换(每次处理一条数据) |
| mapPartitions(Iterator) | 将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理(可以理解为缓冲区,每次将一个分区的数据引用进内存) |
| mapPartitionsWithIndex(Iterator) | 将待处理的数据以分区为单位发送到计算节点进行处理,在处理时同时可以获取当前分区索引 |
| flatMap(func) | 将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射(比如将一个完整的数组,拆分成一个一个数再进行映射)。该函数需要的是一个List,也即map的运算结果 |
| glom() | 将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变 |
| groupby(func) | 将数据根据指定的规则进行分组, 数据会被打乱重新组合,我们将这样的操作称之为 shuffle。极限情况下,数据可能被分在同一个分区中,一个组的数据在一个分区中,但是并不是说一个分区中只有一个组(即分组与分区没有必然联系) |
| filter(func) | 数据根据指定的规则进行筛选,符合规则的数据保留,不符合规则的数据丢弃。 当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜。 |
| sample() | 根据指定的规则从数据集中抽取数据 |
| distinct() | 将数据集中重复的数据去重 |
| coalesce() | 根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率 当 spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少 分区的个数,减小任务调度成本 |
| repartition() | coalesce一般用于减少分区,repartition一般用于扩大分区 |
| sortBy(func) | 在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理 的结果进行排序,默认为升序排列。排序后新产生的 RDD 的分区数与原 RDD 的分区数一 致。中间存在 shuffle 的过程(因为会重排数据序列,所以分区会改变) |
| mapValue(value) | key不变,只对value进行操作 |
——双Value类型
| 方法名 | 作用 |
|---|---|
| intersection() | 对源 RDD 和参数 RDD 求交集后返回一个新的 RDD |
| union() | 对源 RDD 和参数 RDD 求并集后返回一个新的 RDD |
| subtract() | 以一个 RDD 元素为主,去除两个 RDD 中重复元素,将其他元素保留下来 |
| zip() | 将两个 RDD 中的元素,以键值对的形式进行合并。其中,键值对中的 Key 为第 1 个 RDD 中的元素,Value 为第 2 个 RDD 中的相同位置的元素。 |
——key-value类型
| 方法名 | 作用 |
|---|---|
| partitionBy() | 将数据按照指定 Partitioner 重新进行分区 |
| reduceByKey() | 可以将数据按照相同的 Key 对 Value 进行聚合。支持分区内预聚合操作(分区内聚合再进行区间聚合),减少shuffle落盘和再读取的数据量。 |
| groupByKey() | 将数据源的数据根据 key 对 value 进行分组(会导致数据分区被打乱。即存在shuffle操作) |
| aggregateByKey() | 将数据根据不同的规则进行分区内计算和分区间计算 |
| foldByKey() | 当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey |
| combineByKey() | 对 key-value 型 rdd 进行聚集操作的聚集函数(aggregation function) |
| sortByKey() | 在一个(K,V)的 RDD 上调用,K 必须实现 Ordered 接口(特质),返回一个按照 key 进行排序的rdd |
| join() | 在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的 (K,(V,W))的 RDD |
| leftOuterJoin() | SQL 语句的左外连接 |
| rightOuterJoin() | 右外连接 |
| cogrpup() | 在类型为(K,V)和(K,W)的 RDD 上调用,先进行分组后进行左外连接 |
——行动算子(触发整个任务的执行)
| 方法名 | 作用 |
|---|---|
| reduce() | 聚集 RDD 中的所有元素,先聚合分区内数据,再聚合分区间数据 |
| collect() | 在驱动程序中,以数组 Array 的形式返回数据集的所有元素 |
| count() | 返回 RDD 中元素的个数 |
| first() | 返回 RDD 中的第一个元素 |
| take() | 返回 RDD 中的第一个元素 |
| takeOrdered() | 返回该 RDD 排序后的前 n 个元素组成的数组 |
| aggregate() | 分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合 |
| fold() | 折叠操作,aggregate 的简化版操作 |
| countByKey() | 统计每种 key 的个数 |
| saveAsTextFile()、saveAsObjectFile()、saveAsSequenceFile() | 将数据保存到不同格式的文件中:文本文件、对象序列化后保存的文件、二进制形式的key-value平面文件 |
| foreach() | 分布式遍历 RDD 中的每一个元素,调用指定函数 |
| foreachPartition() | 按分区得到一个RDD迭代序列 |
rddList.foreach { rdd =>{
val conn = JDBCUtil.getConnection
}
}
//上述操作将为每一个RDD建立一个数据库连接对象,浪费资源
rddList.foreach {
val conn = JDBCUtil.getConnection
rdd =>{
}
}
//上述操作,foreach作为一个算子,之外的操作会在Driver端执行,而之内的将在Executor端执行,这样涉及序列化操作,而连接对象不支持序列化
rddList.foreachPartition {
iter =>{
val conn = JDBCUtil.getConnection
iter.foreach(iter => {})
}
}
//所以我们使用foreachPartition返回一个分区列表,而在分区列表中我们可以为每个分区建立一个连接对象,减少资源消耗
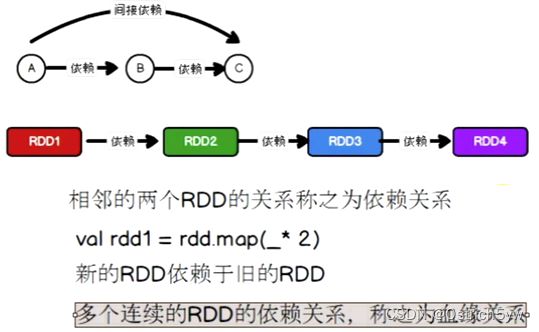
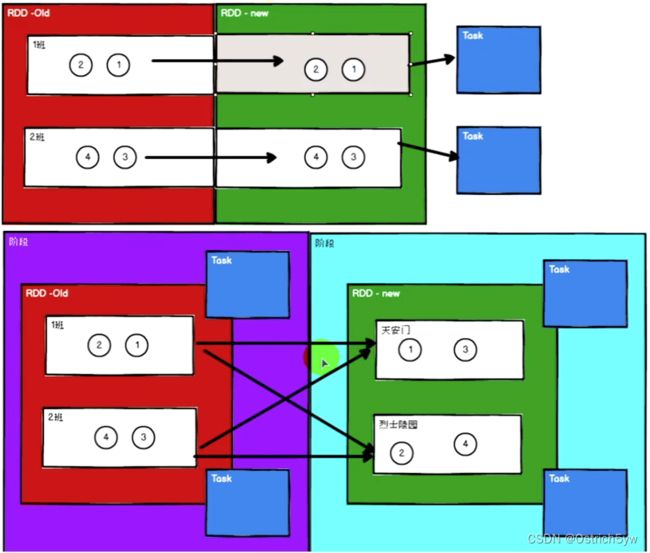
RDD依赖关系
-
RDD不会保存数据,但会存储RDD间的血缘关系(如RDD2会保存2-4的所有操作),提高容错性
-
旧RDD的每个分区只被新RDD的一个分区使用(OneToOneDependency,窄依赖,上图),旧RDD的每个分区被新RDD的多个分区使用(ShuffleDependency,宽依赖,下图)
方法名 作用 toDebugString() RDD保存的血缘关系 dependencies RDD保存的依赖关系
RDD持久化
val rdd = sc.makeRDD(List(1,2,3,4), 2)
val res1 = rdd.map(num => num + 1)
val res2 = res1.map(num => num + 1)
val res3 = res1.map(num => num + 2)
针对以上代码,发现res2,res3结果都是正确的,这是因为res3在执行时,又重新执行了一遍rdd->res1->res3的操作。结论如下:
-
RDD不存放数据,只存放操作
-
RDD对象可以重用,但是数据不可以重用
-
如果多次用同一个RDD,则每一次调用都会从头计算一遍
因此如果需要重复利用一个RDD,需要对其进行缓存。
方法名 作用 RDD.cache() 存放RDD数据到cache缓存 RDD.persist() 更改缓存级别
RDD检查点
所谓的检查点其实就是通过将 RDD 中间结果写入磁盘。
| 方法名 | 作用 |
|---|---|
| RDD.checkpoint | RDD数据落盘 |
1)Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。因为checkpoint会将数据落盘,而血缘关系正是为了记录操作从而恢复数据,所以无需记录血缘。
2)Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存储在 HDFS 等容错、高可用的文件系统,可靠性高。
3)建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存中读取数据即可,否则checkpoint为了得到数据,需要再从头计算一次 RDD。
RDD分区器
Spark 目前支持 Hash 分区和 Range 分区,和用户自定义分区。
- Hash 分区:对于给定的 key,计算其 hashCode,并除以分区个数取余
- Range 分区:将一定范围内的数据映射到一个分区中,尽量保证每个分区数据均匀,而且分区间有序
- 自定义分区
rdd.partitionBy(new Mypartitioner)
class Mypartitioner extends Partitioner{
override def numPartitions: Int = 3
override def getPartition(key:Any): Int = {
key match{
case "my" => 0
case "you" => 1
case "we" => 2
}
}
}
(2)累加器(分布式共享只写变量)
累加器的作用就是将sum在各Executor执行后传回Driver端,再进行整体sum,比如Executor1将sum+3,Executor2将sum+7,传回Driver后就是sum+3+7=10
注意:
-
只有行动算子可以触发累加器,所以累加器一般放在行动算子中
-
可以自定义累加器(1. 继承 AccumulatorV2,并设定泛型 2. 重写累加器的抽象方法)
val sum1 = sc.longAccumulator(name = "Sum")
//sc.doubleAccumulator sc.collectionAccumulator
rdd.foreach(num => {
sum1.add(num)
})
println(sum1.value)
(3)广播变量(分布式共享只读变量)
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个 Spark 操作使用。

- 闭包数据都以Task为单位发送,每个任务都包含闭包数据
- 当一个Executor执行了多个Task,会导致有大量重复数据
- 可以将任务中的闭包数据保存到内存中,实现共享的目的,减少空间占用
具体代码可以参考:
https://github.com/Ostrich5yw/java4BigData