算法—— LeetCode 第一遍
注意本篇博客多为LeetCode中的讨论题解,加上我当时的理解,放在这里是方便自己查看答案。5部分组成:数组,链表,树,动态规划,字符串,共计170道题
一、数组
001 两数之和
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer,Integer> map=new HashMap<>();
for(int i = 0;i < nums.length;i++){
int complenment=target-nums[i];
if(map.containsKey(complenment)){
return new int[]{map.get(complenment),i};
}
map.put(nums[i],i);
}
throw new IllegalArgumentException("No two sum solution");
}
}
031 找出下一个数
class Solution {
public void nextPermutation(int[] nums) {
//1、确定 i 的位置
//从后向前找出开始递减的位置
int i=nums.length-2;
//因为和 i + 1 进行比较,找出 i 位置
while(i>=0&&(nums[i+1]<=nums[i])){
i--;
}
//2、与仅仅大于 i 的值交换
if(i>=0){
int j=nums.length-1;
while(j>=0&&(nums[j]<=nums[i])){
j--;
}
swap(nums,i,j);
}
//3、逆序排列后半部分
reverse(nums,i+1);
}
//从 i 位置处开始交换
private void reverse(int[] nums,int start){
int i=start,j=nums.length-1;
while(i<j){
swap(nums,i,j);
i++;
j--;
}
}
//交换数组中的两个元素
private void swap(int[] nums,int i,int j){
int temp=nums[i];
nums[i]=nums[j];
nums[j]=temp;
}
}
033 在 logn 时间内找出指定元素的位置
class Solution {
public int search(int[] nums, int target) {
//判断空数组的情况
if(nums.length==0){
return -1;
}
int lo=0,hi=nums.length-1;
//迭代实现
while(lo<hi){
int mid=(lo+hi)/2;
if(nums[mid]==target){
return mid;
}
//分为两种情况
//1、左端值小于中点值类似于 2,4,5,6,7,0,1 前半部分有序
if(nums[lo]<=nums[mid]){
//确定是否前半部分有序
if(target>=nums[lo]&&target<nums[mid]){
hi=mid-1;
}else{
lo=mid+1;
}
//2、左端值大于中点值类似于 6,7,0,1,2,4,5 后半部分有序
}else{
if(target<=nums[hi]&&target>nums[mid]){
lo=mid+1;
}else{
hi=mid-1;
}
}
}
return nums[lo]==target?lo:-1;
}
}
034 找出目标值出现在数组中的第一个和最后一个位置;todo:用二分法实现
//两次扫描,O(n) 的复杂度
class Solution {
public int[] searchRange(int[] nums, int target) {
int[] res=new int[]{-1,-1};
if(nums.length==0){
return res;
}
//从前到后扫描寻找第一个目标值
for(int i=0;i<nums.length;i++){
if(nums[i]==target){
res[0]=i;
//找到就退出循环
break;
}
}
//如果不含有目标值就不用再进行扫描
if(res[0]==-1){
return res;
}
//从后向前扫描寻找最后一个目标值
for(int j=nums.length-1;j>=0;j--){
if(nums[j]==target){
res[1]=j;
break;
}
}
return res;
}
}
//二分法实现,未弄懂
class Solution {
// returns leftmost (or rightmost) index at which `target` should be
// inserted in sorted array `nums` via binary search.
private int extremeInsertionIndex(int[] nums, int target, boolean left) {
int lo = 0;
int hi = nums.length;
while (lo < hi) {
int mid = (lo + hi) / 2;
if (nums[mid] > target || (left && target == nums[mid])) {
hi = mid;
}
else {
lo = mid+1;
}
}
return lo;
}
public int[] searchRange(int[] nums, int target) {
int[] targetRange = {-1, -1};
int leftIdx = extremeInsertionIndex(nums, target, true);
// assert that `leftIdx` is within the array bounds and that `target`
// is actually in `nums`.
if (leftIdx == nums.length || nums[leftIdx] != target) {
return targetRange;
}
targetRange[0] = leftIdx;
targetRange[1] = extremeInsertionIndex(nums, target, false)-1;
return targetRange;
}
}
035 将目标值插入到合适位置
class Solution {
public int searchInsert(int[] nums, int target) {
int lo=0,hi=nums.length-1;
//注意有等号
while(lo<=hi){
int mid=(lo+hi)/2;
if(nums[mid]==target){
return mid;
}
else if(target<nums[mid]){
hi=mid-1;
}else{
lo=mid+1;
}
}
return lo;
}
}
039 找出所有相加等于目标值的元素,元素可以重复使用,结果数组不可重复
class Solution {
public List<List<Integer>> combinationSum(int[] candidates, int target) {
List<List<Integer>> list=new ArrayList<>();
Arrays.sort(candidates);
sum(list,new ArrayList<Integer>(),candidates,target,0);
return list;
}
private void sum(List<List<Integer>> list,List<Integer> tempList,int[] candidates,int remain,int start){
if(remain<0){
return;
}else if(remain==0){
list.add(new ArrayList<>(tempList));
}else{
//循环遍历数组中的元素,i 从 start 开始,不是从 0 开始(会出现重复数组),递归实现
for(int i=start;i<candidates.length;i++){
tempList.add(candidates[i]);
//可以重复利用同一个元素,传入的开始参数为 i
sum(list,tempList,candidates,remain-candidates[i],i);
// tempList.remove(candidates.length-1);
tempList.remove(tempList.size()-1);
}
}
}
}
040 与 39 题的区别是元素只能被使用一次
class Solution {
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
List<List<Integer>> list=new ArrayList<>();
Arrays.sort(candidates);
sum(list,new ArrayList<Integer>(),candidates,target,0);
return list;
}
private void sum(List<List<Integer>> list,List<Integer> tempList,int[] candidates,int remain,int start){
if(remain<0){
return;
}else if(remain==0){
list.add(new ArrayList<>(tempList));
}else{
//循环遍历数组中的元素,i 从 start 开始,不是从 0 开始,递归实现
for(int i=start;i<candidates.length;i++){
// 跳过同一个元素多次使用的情况
if(i > start && candidates[i] == candidates[i-1]) continue;
tempList.add(candidates[i]);
//可以重复利用同一个元素,传入的开始参数为 i
sum(list,tempList,candidates,remain-candidates[i],i+1);
// tempList.remove(candidates.length-1);
tempList.remove(tempList.size()-1);
}
}
}
}
041 找出缺少的第一个最小整数
//大于 n 的整数可以被忽略,因为返回的值范围是 1 到 n + 1;
class Solution {
public int firstMissingPositive(int[] nums) {
int n=nums.length,i=0;
//这两个循环不等价
// for(int i=0;i
// if(nums[i]>=0&&nums[i]
// swap(nums,i,nums[i]);
// }
// }
while(i<n){
if(nums[i]>=0&&nums[i]<n&&nums[nums[i]]!=nums[i]){
swap(nums,i,nums[i]);
}else{
i++;
}
}
//从 1 开始,从 0 开始结果会输出 0,
int k=1;
//找到第一个不按规则排列的位置
while(k<n&&nums[k]==k){
k++;
}
//不含元素或者找到上述的位置
if(n==0||k<n){
return k;
}else{
//不懂这的含义
return nums[0]==k?k+1:k;
}
}
private void swap(int[] nums,int i,int j){
int temp=nums[i];
nums[i]=nums[j];
nums[j]=temp;
}
}
042 求雨水最大面积
//暴力法,太慢了,动态规划和双指针还不会
class Solution {
public int trap(int[] height) {
int sum=0;
//注意起始和结束位置
for(int i=1;i<height.length-1;i++){
int max_left=0,max_right=0;
//寻找左边的最大值包含 i
for(int j=i;j>=0;j--){
max_left=Math.max(max_left,height[j]);
}
//寻找右边的最大值包含 i
for(int j=i;j<height.length;j++){
max_right=Math.max(max_right,height[j]);
}
sum+=Math.min(max_left,max_right)-height[i];
}
return sum;
}
}
045 跳一跳到最后
//使用贪心算法,每次找到可以跳的最远距离,注意只需统计跳的次数,不需要每次跳的位置
class Solution {
public int jump(int[] nums) {
//当前能跳到的边界,跳到的最远距离,步数
int end=0,maxPosition=0,steps=0;
//为什么边界在倒数第二个位置?
for(int i=0;i<nums.length-1;i++){
//找能跳到最远的,找到后暂时定下,但 i 还在向后循环
maxPosition=Math.max(maxPosition,nums[i]+i);
//遇到边界,就更新边界
if(i==end){
end=maxPosition;
steps++;
}
}
return steps;
}
}
048 二维矩阵旋转 90 度
//相当优美的解法
class Solution {
public void rotate(int[][] matrix) {
for(int i=0;i<matrix.length;i++){
//从 i 开始
for(int j=i;j<matrix[i].length;j++){
int temp=matrix[i][j];
matrix[i][j]=matrix[j][i];
matrix[j][i]=temp;
}
}
for(int i=0;i<matrix.length;i++){
//从 0 开始,到二分之一长度结束
for(int j=0;j<matrix[i].length/2;j++){
int temp=matrix[i][j];
matrix[i][j]=matrix[i][matrix[0].length-1-j];
matrix[i][matrix[0].length-1-j]=temp;
}
}
}
}
053 通过动态规划求最大的子数组的和
//加上一个大于 0 的数,数组会变的更大
class Solution {
public int maxSubArray(int[] nums) {
int N=nums.length;
//以 nums[i] 结束的最大子数组的最大和
int[] dp=new int[N];
dp[0]=nums[0];
int ans=dp[0];
for(int i=1;i<N;i++){
dp[i]=nums[i]+(dp[i-1]>0?dp[i-1]:0);
ans=Math.max(ans,dp[i]);
}
return ans;
}
}
054 顺时针循环输出矩阵
class Solution {
public List<Integer> spiralOrder(int[][] matrix) {
//存放结果的容器
ArrayList<Integer> ans=new ArrayList<>();
//最先进行非空判断,否则会报空指针异常
if(matrix.length==0){
return ans;
}
//行数
int R=matrix.length;
//列数
int C=matrix[0].length;
//判断是否已经被访问过的,二维数组
boolean[][] seen=new boolean[R][C];
//dr dc 两个数组组成判断行走方向,向右 0 1,向下 1 0,向左 0 -1,向上 -1 0
int[] dr={0,1,0,-1};
int[] dc={1,0,-1,0};
//当前的行标和列标,di 为方向表示
int r=0,c=0,di=0;
//循环的次数为矩阵中元素的个数
for(int i=0;i<R*C;i++){
ans.add(matrix[r][c]);
seen[r][c]=true;
//下一个点的行标和列标
int cr=r+dr[di];
int cc=c+dc[di];
//不需要转向的情况
if(cr>=0&&cr<R&&cc>=0&&cc<C&&!seen[cr][cc]){
r=cr;
c=cc;
}else{//需要转向的情况
//转向分为四种情况通过以下代码处理
di=(di+1)%4;
r+=dr[di];
c+=dc[di];
}
}
return ans;
}
}
055 判断是否能根据数组从第一个位置跳到最后一个位置
//不能通过,超时,通过动态规划改进
class Solution {
//判断是否能跳到最后一个元素
public boolean canJump(int[] nums) {
//第一次没写 return
return canJumpHelper(0,nums);
}
private boolean canJumpHelper(int position,int[] nums){
//如果位置在最后一个元素,返回真
if(position==nums.length-1){
return true;
}
//能跳到的最远位置,最后一个元素的位置是数组长度减一
int furthestPosition=Math.min(position+nums[position],nums.length-1);
//注意边界条件的等号,不然结果会出错
for(int nextPosition=position+1;nextPosition<=furthestPosition;nextPosition++){
if(canJumpHelper(nextPosition,nums)){
return true;
}
}
return false;
}
}
057 插入集合元素,可能有重合
/**
* Definition for an interval.
* public class Interval {
* int start;
* int end;
* Interval() { start = 0; end = 0; }
* Interval(int s, int e) { start = s; end = e; }
* }
*/
class Solution {
public List<Interval> insert(List<Interval> intervals, Interval newInterval) {
//已经排好序的集合
List<Interval> result=new LinkedList<>();
// i 为全局变量
int i=0;
//1、第一种情况,老元素的结尾小于新元素的开头
while(i<intervals.size()&&intervals.get(i).end<newInterval.start){
// i 的自加运算不能丢掉
result.add(intervals.get(i++));
}
//2、第二种情况,新元素的结尾大于老元素的开头,代表元素有重合
while(i<intervals.size()&&intervals.get(i).start<=newInterval.end){
//将两个元素合并就是创造一个新的元素
newInterval=new Interval(Math.min(intervals.get(i).start,newInterval.start),
Math.max(intervals.get(i).end,newInterval.end));
i++;
}
//将合并好的元素加入到结果集合中
result.add(newInterval);
//3、第三种情况,遍历之后的元素将其加入到结果集合中
while(i<intervals.size()){
result.add(intervals.get(i++));
}
return result;
}
}
059 循环输入的二维数组
//思路:用上右下左四个变量代表四个方向,根据左右方向大小的不同
class Solution {
public int[][] generateMatrix(int n) {
//输入的 n 代表行数和列数
int[][] result=new int[n][n];
int top=0,left=0;
int down=n-1,right=n-1;
//存入数组的元素
int count=1;
//很精妙,怎么想出来的呢
while(left<=right&&top<=down){
//从左向右移动
for(int i=left;i<=right;i++){
result[top][i]=count++;
}
top++;
//从上到下移动
for(int i=top;i<=down;i++){
result[i][right]=count++;
}
right--;
//从右到左
for(int i=right;i>=left;i--){
result[down][i]=count++;
}
down--;
//从下到上移动
for(int i=down;i>=top;i--){
result[i][left]=count++;
}
left++;
}
return result;
}
}
062 探索矩阵格子中从起点到终点的路径数目
//利用动态规划的方法
class Solution {
public int uniquePaths(int m, int n) {
int[][] grid=new int[m][n];
//将第一行置为 1
for(int i=0;i<n;i++){
grid[0][i]=1;
}
//将第一列置为 1
for(int i=0;i<m;i++){
grid[i][0]=1;
}
//利用数学表达式 grid[i][j]=grid[i-1][j]+grid[i][j-1];
for(int i=1;i<m;i++){
for(int j=1;j<n;j++){
grid[i][j]=grid[i-1][j]+grid[i][j-1];
}
}
return grid[m-1][n-1];
}
}
063 有障碍物的探索路径数目,障碍用 1 表示
//利用动态规划的方法
class Solution {
public int uniquePathsWithObstacles(int[][] obstacleGrid) {
int m=obstacleGrid.length;
int n=obstacleGrid[0].length;
//当第一个位置为 0 时,代表没有路径可走
if(obstacleGrid[0][0]==1){
return 0;
}
//如果可以通过,就将初始位置置为 1
obstacleGrid[0][0]=1;
//将第一行和第一列填满作为初始条件,如果当前数为零并且前一个数为一就填入 1 否则填入 0
for(int j=1;j<n;j++){
if(obstacleGrid[0][j]==0&&obstacleGrid[0][j-1]==1){
obstacleGrid[0][j]=1;
}else{
obstacleGrid[0][j]=0;
}
}
for(int i=1;i<m;i++){
//可以通过一个 ? : 表达式进行简化
if(obstacleGrid[i][0]==0&&obstacleGrid[i-1][0]==1){
obstacleGrid[i][0]=1;
}else{
obstacleGrid[i][0]=0;
}
}
//利用和上一题相同的递归式
for(int i=1;i<m;i++){
for(int j=1;j<n;j++){
if(obstacleGrid[i][j]==0){
obstacleGrid[i][j]=obstacleGrid[i-1][j]+obstacleGrid[i][j-1];
}else{
obstacleGrid[i][j]=0;
}
}
}
return obstacleGrid[m-1][n-1];
}
}
064 探索路径并求出权重和的最小值
//主要过程和之前两道题一样,都是通过动态规划
class Solution {
public int minPathSum(int[][] grid) {
int m=grid.length;
int n=grid[0].length;
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
if(i==0&&j!=0){
grid[i][j]=grid[i][j]+grid[i][j-1];
}else if(j==0&&i!=0){
grid[i][j]=grid[i][j]+grid[i-1][j];
}else if(i==0&&j==0){
grid[i][j]=grid[i][j];
}else{
//出错,不是 grid[i][j]=grid[i-1][j]+grid[i][j-1]; 而是加上上一次较小的值
grid[i][j]=Math.min(grid[i-1][j],grid[i][j-1])+grid[i][j];
}
}
}
return grid[m-1][n-1];
}
}
066 将数组作为整数加 1
class Solution {
public int[] plusOne(int[] digits) {
//分为两种情况,1、当各位数全为 9 时;2、各位数不全为 9 时
int len=digits.length-1;
for(int i=len;i>=0;i--){
if(digits[i]<9){
digits[i]++;
return digits;
}
digits[i]=0;
// digits[i-1]++;不用加,进入 if 作用域自会加
}
int[] newDigits=new int[len+2];
newDigits[0]=1;
return newDigits;
}
}
073 替换 0 所在行列的数值都为 0
//效率不高
class Solution {
public void setZeroes(int[][] matrix) {
//两次遍历,第一次将要操作的行号和列号存储在 set 集合中,利用 contains 方法再次遍历的时候将其改变
Set<Integer> rows=new HashSet<>();
Set<Integer> cols=new HashSet<>();
int R=matrix.length;
int C=matrix[0].length;
//第一次遍历
for(int i=0;i<R;i++){
for(int j=0;j<C;j++){
if(matrix[i][j]==0){
rows.add(i);
cols.add(j);
}
}
}
//第二次遍历进行操作
for(int i=0;i<R;i++){
for(int j=0;j<C;j++){
//只要在那一行或者那一列都进行操作
if(rows.contains(i)||cols.contains(j)){
//对遍历到的当前元素进行操作
matrix[i][j]=0;
}
}
}
}
}
074 在有序的二维数组中找出目标值
class Solution {
public boolean searchMatrix(int[][] matrix, int target) {
//疏忽了非空判断
if(matrix.length==0 || matrix==null || matrix[0].length==0){
return false;
}
//按照jianzhioffer 的方法,利用两个指针从右上角开始探索,没有二分查找的效率高
//行数列数写反了
int i=0,j=matrix[0].length-1;
//注意循环的终止条件,边界条件是用行数还是列数
while(i<matrix.length&&j>=0){
if(matrix[i][j]==target){
return true;
}else if(matrix[i][j]>target){
j--;
}else{
i++;
}
}
return false;
}
}
075 将代表三种颜色数值在数组中进行排序
class Solution {
public void sortColors(int[] nums) {
//1、利用两次遍历的方法
int count0=0,count1=0,count2=0;
for(int i=0;i<nums.length;i++){
if(nums[i]==0){
count0++;
}else if(nums[i]==1){
count1++;
}else{
count2++;
}
}
for(int i=0;i<nums.length;i++){
if(i<count0){
nums[i]=0;
}
//连用 if 语句就不能出正确结果,改成 else 语句就可以了
else if(i<count0+count1){
nums[i]=1;
}
else{
nums[i]=2;
}
}
//TODO: 2、利用依次遍历的方法
}
}
078 输出一个数组的所有可能得子组合,不能有重复使用的元素
class Solution {
public List<List<Integer>> subsets(int[] nums) {
//正整数数组,找出所有可能的子集合,子集合中不含重复元素;特征是递归和一个临时的列表集合
//存放结果的容器
List<List<Integer>> list=new ArrayList<>();
//对数组进行排序
Arrays.sort(nums);
//通过递归回溯的方法解决问题
backtrack(list,new ArrayList<>(),nums,0);
return list;
}
private void backtrack(List<List<Integer>> list,List<Integer> tempList,int[] nums,int start){
list.add(new ArrayList<>(tempList));
for(int i=start;i<nums.length;i++){
tempList.add(nums[i]);
backtrack(list,tempList,nums,i+1);
//容器的长度计算用的是 size()方法
//该方法用于保持 t1 的原貌,可以在下一次循环中进行添加其他元素的操作
tempList.remove(tempList.size()-1);
}
}
}
//递归轨迹
list.add
for 0
t1.add
list.add
for 1
t2.add
list.add
for 2
t3.add
list.add
t3.rm
t2.rm
for 2
t2.add
list.add
t2.rm
for 1
t1.add
list.add
for 2
t1.add
list.add
for 2
t1.add
list.add
t1.rm
t1.rm
for 2
t1.add
list.add
t1.add
list.add
t1.tm
t1.rm
079 找出字母矩阵中是否包含目标单词,从上下左右连续
class Solution {
public boolean exist(char[][] board, String word) {
//找出二维字母组中是否包含相应的单词,字母不能重复利用
//主要用到了 bit mask 和 dfs 设计算法的方法; 递归方法
//将字符串转换成字符数组
char[] w=word.toCharArray();
//遍历整个二维字母矩阵
for(int y=0;y<board.length;y++){
for(int x=0;x<board[y].length;x++){
if(exist(board,y,x,w,0)){
return true;
}
}
}
return false;
}
//这就是深度优先搜索的过程
private boolean exist(char[][] board,int y,int x,char[] word,int i){
//1、到达字符串最后一个字母说明含有这个字符串
if(i==word.length){
return true;
}
//2、超出矩阵的边界说明不含有这个字符串
if(y<0||x<0||y==board.length||x==board[y].length){
return false;
}
//3、出现不相等的情况说明不含对应的字符串,当前的 exist 方法标记为 false
if(board[y][x]!=word[i]){
return false;
}
//利用二进制掩码标记元素是否被访问过,Bit Mask 的原理是什么?
board[y][x]^=256;
//对四个方向进行探索,有一个方向符合条件当前 exist 方法标记为 true,一直探索下去,知道有 true 或者 false 的返回为止
boolean flag=exist(board,y,x+1,word,i+1)
||exist(board,y,x-1,word,i+1)
||exist(board,y+1,x,word,i+1)
||exist(board,y-1,x,word,i+1);
board[y][x]^=256;
return flag;
}
}
080 除去数组中超过两次重复的元素后统计数组的长度
class Solution {
public int removeDuplicates(int[] nums) {
//有序数组,原地操作,允许两次重复,统计出剩余的元素个数
//有序数组,后面的数一定大于等于前面位置的数
int i=0;
//从前到后依次取出数组中的元素
for(int n:nums){
//前两个数一定能够满足要求,根据数组的有序性,若大于向前数第二个位置的数,则说明不相等,满足要求
if(i<2||n>nums[i-2]){
nums[i++]=n;
}
}
return i;
}
}
081 循环的有序数组判断目标值是否包含在数组中
class Solution {
public boolean search(int[] nums, int target) {
int lo=0,hi=nums.length-1;
while(lo<=hi){
int mid=lo+(hi-lo)/2;
if(nums[mid]==target){
return true;
}
//1、判断是否处于有序的后半部分
if(nums[mid]<nums[hi]){
if(target>nums[mid]&&target<=nums[hi]){
lo=mid+1;
}else{
hi=mid-1;
}
//2、判断是否处于有序的前半部分
}else if(nums[mid]>nums[hi]){
if(target<nums[mid]&&target>=nums[lo]){
hi=mid-1;
}else{
lo=mid+1;
}
//为什么要
}else{
hi--;
}
}
return false;
}
}
084
//找出不规则柱状图中的连续最大矩形
//关键点:将所有的高度包括 0 高度入栈;
//栈中存放的是索引; else 作用域中底边长度的判断
class Solution {
public int largestRectangleArea(int[] heights) {
//数组长度
int len=heights.length;
//利用栈存放数组的索引
Stack<Integer> s=new Stack<>();
//初始化最大面积
int maxArea=0;
for(int i=0;i<=len;i++){
//当前位置的高度,当在 len 位置处为 0
int h=(i==len?0:heights[i]);
//1、栈中没有元素或者当前高度大于栈顶的索引对应的高度,就将当前高度对应的索引入栈
if(s.isEmpty()||h>=heights[s.peek()]){
//将索引加入栈中
s.push(i);
//2、栈顶高度大于当前高度,将栈顶元素出栈
}else{
//拿到当前栈顶元素,也就是当前最大的那个元素
int tp=s.pop();
// i = 4 时 6 * 4 - 1 - 2 ; 再次进入 5 * 4 - 1 - 1 ,此时栈中只剩索引 1,栈为空时说明之前是递减的数组
maxArea=Math.max(maxArea,heights[tp]*(s.isEmpty()?i:i-1-s.peek()));
i--;
}
}
return maxArea;
}
}
085 ***
//在二进制矩阵中找到由 1 组成的最大矩形的面积
//利用动态规划的方法; 或者联系到 084 题(这里使用的方法)
class Solution {
public int maximalRectangle(char[][] matrix) {
//非空判断
if(matrix==null||matrix.length==0||matrix[0].length==0){
return 0;
}
//行数
int R=matrix.length;
//列数
int C=matrix[0].length;
//存放高度的数组
int[] h=new int[C+1];
h[C]=0;
//初始化最大面积
int maxArea=0;
//循环遍历每一行
for(int r=0;r<R;r++){
Stack<Integer> s=new Stack<>();
//遍历每一行中的元素
for(int c=0;c<=C;c++){
//构造一个和 84 题类似的数组表示柱状图
if(c<C){
//分两种情况,当前元素是 0 和当前元素是 1,题目中给的是字符串
if(matrix[r][c]=='1'){
h[c]+=1;
}else{
h[c]=0;
}
}
if(s.isEmpty()||h[c]>=h[s.peek()]){
s.push(c);
}else{
//与之前的不同之处
while(!s.isEmpty()&&h[c]<h[s.peek()]){
int tp=s.pop();
maxArea=Math.max(maxArea,h[tp]*(s.isEmpty()?c:c-1-s.peek()));
}
//与之前的不同之处
s.push(c);
}
}
}
return maxArea;
}
}
//动态规划的方法未理解
088
//与归并算法中的实现相同
//nums1 = [1,2,3,0,0,0], m = 3,注意这里 m 的初试值为 3 不是 6
//nums2 = [2,5,6], n = 3
class Solution {
public void merge(int[] nums1, int m, int[] nums2, int n) {
//定义两个数组都是从尾部开始遍历,组成的新数组的长度为两个数组长度相加,索引都是长度减一
int i=m-1,j=n-1,k=m+n-1;
while(i>=0&&j>=0){
nums1[k--]=nums1[i]>nums2[j]?nums1[i--]:nums2[j--];
}
while(j>=0){
nums1[k--]=nums2[j--];
}
}
}
090
//列出所有数组所可能包含的子数组的情况
//所给数组中包含重复元素,结果集合中不能包含重复的集合元素
//与前一个类似的题目唯一不同之处在于需要跳过原数组中的重复元素
class Solution {
public List<List<Integer>> subsetsWithDup(int[] nums) {
List<List<Integer>> list=new ArrayList<>();
Arrays.sort(nums);
backtrack(list,new ArrayList<>(),nums,0);
return list;
}
private void backtrack(List<List<Integer>> list,List<Integer> tempList,int[] nums,int start){
list.add(new ArrayList<>(tempList));
for(int i=start;i<nums.length;i++){
//跳过重复元素
if(i>start&&nums[i]==nums[i-1]){
continue;
}
tempList.add(nums[i]);
backtrack(list,tempList,nums,i+1);
tempList.remove(tempList.size()-1);
}
}
}
105
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
//通过给出的前序遍历和中序遍历结果构造二叉树,假设树中不存在重复元素
//pre[0] 是根节点,中序数组中 pre[0] 左边的为根的左子树,右边同理;迭代处理子数组就能得到原始的树
//两个数组的左右字数对应的索引起始位置是相同的
class Solution {
public TreeNode buildTree(int[] preorder, int[] inorder) {
return buildTree(0,0,inorder.length-1,preorder,inorder);
}
//前序数组的第一个元素;中序数组的第一个元素;中序数组的最后一个元素;前序数组;中序数组
private TreeNode buildTree(int preStart,int inStart,int inEnd,int[] preorder,int[] inorder){
//传入的两个数组为空, 并为叶子结点赋值为 null
//如果 inEnd 用 inorder.length 代替会报越界异常??
if(preStart>preorder.length-1||inStart>inEnd){
return null;
}
//定义根节点
TreeNode root=new TreeNode(preorder[preStart]);
//初始化根节点在中序遍历数组中的索引位置
int inIndex=0;
//边界条件丢掉了等号导致 StackOverflowError 错误
//注意这里的循环起点和终点是根据递归变化的,不是 0 和最后一位
for(int i=inStart;i<=inEnd;i++){
if(inorder[i]==root.val){
inIndex=i;
}
}
//主要问题是确定新的左右子树的索引位置
//左子树的根等于当前根的索引加一
root.left=buildTree(preStart+1,inStart,inIndex-1,preorder,inorder);
//关键是根据中序遍历的规律确定第一个参数也就是根节点的在前序遍历中的索引
//右子树的根等于左子树的根加上左子树所含的节点数目
root.right=buildTree(preStart+inIndex-inStart+1,inIndex+1,inEnd,preorder,inorder);
return root;
}
}
106
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
//根据中序和后序输入数组构造二叉树
class Solution {
public TreeNode buildTree(int[] inorder, int[] postorder) {
//后续数组的遍历开始点与之前的前序遍历有区别
return buildTree(postorder.length-1,0,inorder.length-1,postorder,inorder);
}
private TreeNode buildTree(int postStart,int inStart,int inEnd,int[] postorder,int[] inorder){
if(postStart>postorder.length-1||inStart>inEnd){
return null;
}
TreeNode root=new TreeNode(postorder[postStart]);
int inIndex=0;
for(int i=inStart;i<=inEnd;i++){
if(inorder[i]==root.val){
inIndex=i;
}
}
//对于第一次操作 4 - (4 - 1) - 1 = 0 左子树的根节点
//不要丢掉括号
//左子树的根节点位置是右子树根节点减去右子树的节点数目
root.left=buildTree(postStart-(inEnd-inIndex)-1,inStart,inIndex-1,postorder,inorder);
//右子树的根节点是父节点索引位置减一
root.right=buildTree(postStart-1,inIndex+1,inEnd,postorder,inorder);
return root;
}
}
118
//两侧元素都是 1 ,输入的是二维矩阵的行数
class Solution {
public List<List<Integer>> generate(int numRows) {
//一个存放结果的集合
List<List<Integer>> list=new ArrayList<>();
//1、第一种基本情况,输入为 0 时,结果为空,非空判断
if(numRows==0){
return list;
}
//2、第二种易得的情况,第一行永远为 1,先添加一行,再将这一行的第一个元素设置为 1
//先加一行,再取出来放入元素 1
list.add(new ArrayList<>());
list.get(0).add(1);
//从第二行(也就是行索引为 1 的位置)开始,总行数已知
//嵌套循环利用表达式将集合元素赋值
for(int r=1;r<numRows;r++){
//存放当前行数据的集合, 新建
//对每一行进行处理
List<Integer> nowRow=new ArrayList<>();
//存放前一行数据的集合,从总集合中获得
//前面已经给第一行初始化了,所以可以直接取到第一行集合的值
List<Integer> preRow=list.get(r-1);
//每一行的第一个元素总是 1
//循环取到每一行元素的时候将其第一个元素赋值为 1
nowRow.add(1);
//根据题意列表达式,每一行的元素数目等于当前行号
for(int c=1;c<r;c++){
nowRow.add(preRow.get(c)+preRow.get(c-1));
}
//最后一个元素设为 1 ,将行集合加入到总集合中
nowRow.add(1);
list.add(nowRow);
}
return list;
}
}
119
//注意标号是从 0 开始,输入行号,返回那一行的数组
class Solution {
public List<Integer> getRow(int rowIndex) {
List<Integer> list=new ArrayList<>();
//后面的方法可以处理索引为 0 的情况
if(rowIndex<0){
return list;
}
//循环相加到指定索引所在的行,边界条件很重要
for(int i=0;i<=rowIndex;i++){
//add 和 set 方法用反了
list.add(0,1);
//循环到倒数第二个位置结束
for(int j=1;j<list.size()-1;j++){
//用 set 方法替换而不是用 add 向后叠加
//注意将哪两个索引位置处的数据相加
//注意 +1
list.set(j,list.get(j)+list.get(j+1));
//不用再最后位置加 1 了
}
}
return list;
}
}
120
//从下向上依次求出相邻的较小值叠加
//需要一个额外的数组存放数据
class Solution {
public int minimumTotal(List<List<Integer>> triangle) {
//因为最后用到了第长度位置处的元素
int[] result=new int[triangle.size()+1];
for(int i=triangle.size()-1;i>=0;i--){
for(int j=0;j<triangle.get(i).size();j++){
result[j]=Math.min(result[j],result[j+1])+triangle.get(i).get(j);
}
}
return result[0];
}
}
121
//返回数组中的从后到前的最大差值
class Solution {
public int maxProfit(int[] prices) {
int maxProfit=0;
int len=prices.length;
// i 到最后第二个位置为止
for(int i=0;i<len-1;i++){
for(int j=i+1;j<len;j++){
int nowProfit=prices[j]-prices[i];
if(nowProfit>maxProfit){
maxProfit=nowProfit;
}
}
}
return maxProfit;
}
}
//通过初始化最大值和最小值达到遍历一遍数组就得到结果的效果
public class Solution {
public int maxProfit(int prices[]) {
int minprice = Integer.MAX_VALUE;
//注意设置的是最大利润,而不是最大值
int maxprofit = 0;
for (int i = 0; i < prices.length; i++) {
if (prices[i] < minprice)
minprice = prices[i];
else if (prices[i] - minprice > maxprofit)
maxprofit = prices[i] - minprice;
}
return maxprofit;
}
}
122
//可以进行多次交易的求最大利润
//将所有分段的从波峰到波谷的差值相加
//关键点是检查曲线的单调性
class Solution {
public int maxProfit(int[] prices) {
//未进行非空判断
if(prices==null||prices.length==0){
return 0;
}
int i=0;
int vallay=prices[0];
int peak=prices[0];
int maxProfit=0;
//倒数第二个位置为止,在这出错了
while(i<prices.length-1){
//寻找波谷, 找到开始递减的位置,下一个位置就是波谷
//不是和波峰或者波谷比较,是当前元素和下一个元素比较
while(i<prices.length-1&&prices[i]>=prices[i+1]){
i++;
}
vallay=prices[i];
//寻找波峰,开始递增的下一个位置为波峰
while(i<prices.length-1&&prices[i]<=prices[i+1]){
i++;
}
peak=prices[i];
maxProfit+=peak-vallay;
}
return maxProfit;
}
}
123 ***
//最多进行两次交易,求交易能够获得的最大利润
//网格 dp 中存放的是有几段元素时当前的最大利润,k 代表行号,i 代表列号
//不卖,最大利润和前一天相等,在 j 天买入并在 i 天卖出的利润最大为 prices[i] - prices[j] + dp[k-1, j-1]
//对于本例来说画一个 3 行 7 列的表格
class Solution {
public int maxProfit(int[] prices) {
if(prices.length==0){
return 0;
}
//相当于建立一个网格
int[][] dp=new int[3][prices.length];
for(int k=1;k<=2;k++){
for(int i=1;i<prices.length;i++){
//要放在 i 循环里面,每一次的最小值是不同的
int min=prices[0];
//注意这的边界是小于等于 i
for(int j=1;j<=i;j++){
min=Math.min(min,prices[j]-dp[k-1][j-1]);
}
dp[k][i]=Math.max(dp[k][i-1],prices[i]-min);
}
}
return dp[2][prices.length-1];
}
}
126 ***
在这里插入代码片
128
//无序数组,找出最大连续串的长度
//考虑是否需要先进行排序,可能之前比遍历过得是最大长度,也可能目前的是最大长度
class Solution {
public int longestConsecutive(int[] nums) {
if(nums==null||nums.length==0){
return 0;
}
//之前没有先进行排序
Arrays.sort(nums);
//保存最大字符串长度的变量
int longestStreak=1;
//目前连续的最大长度
int currentStreak=1;
//与前一个元素开始比较,因此 i 从 1 开始
for(int i=1;i<nums.length;i++){
//与前一个元素不相等的情况下
if(nums[i]!=nums[i-1]){
if(nums[i]==nums[i-1]+1){
currentStreak++;
//当遇到不连续的时候,才判断是否替换当前的最大长度
}else{
longestStreak=Math.max(longestStreak,currentStreak);
//将当前流长度重置为 1
currentStreak=1;
}
}
}
return Math.max(longestStreak,currentStreak);
}
}
152
//找出无序数组中连续子数组的连乘最大值不能通过排序进行预处理了,整数数组,可正可负可为零
//循环遍历数组,每一步记住之前产生的最大值和最小值,最重要的是更新最大值和最小值,每一步都需要进行比较
//这里的连续是索引位置的连续,因为题意中是子数组,上一题的连续是数组中的值的连续
class Solution {
public int maxProduct(int[] nums) {
if(nums==null||nums.length==0){
return 0;
}
int max=nums[0];
int min=nums[0];
int result=nums[0];
for(int i=1;i<nums.length;i++){
//保存 max 的值,因为求最小值的过程中要用到未被改变的最大值
int temp=max;
//因为数组中可能含有负数,所以最大的乘积可能出现在最大元素和当前元素相乘,或者最先元素和当前元素相乘
//也可能是单独的当前元素
max=Math.max(Math.max(max*nums[i],min*nums[i]),nums[i]);
min=Math.min(Math.min(temp*nums[i],min*nums[i]),nums[i]);
if(result<max){
result=max;
}
}
return result;
}
}
153
//找到循环数组中的最小值,假设数组中没有重复元素
//使用二分查找,只有一个元素的情况,正好是有序数组的情况
//与查找数组中是否含有指定元素还是不同的解决方法
class Solution {
public int findMin(int[] nums) {
int lo=0,hi=nums.length-1;
if(nums.length==1||nums[lo]<nums[hi]){
return nums[0];
}
while(lo<=hi){
int mid=lo+(hi-lo)/2;
//return 部分是循环的终止条件
if(nums[mid]>nums[mid+1]){
return nums[mid+1];
}
if(nums[mid]<nums[mid-1]){
return nums[mid];
}
//如果左半部分有序,则最小值反而在右半部分,这里弄反了
if(nums[mid]>nums[lo]){
hi=mid-1;
}else{
lo=mid+1;
}
}
return -1;
}
}
在这里插入代码片
154
//在有序的旋转数组中,遇上一题的不同是数组中可能含有重复的元素
//logn
class Solution {
public int findMin(int[] nums) {
if(nums.length==1){
return nums[0];
}
int lo=0,hi=nums.length-1;
while(lo<=hi){
int mid=lo+(hi-lo)/2;
//最小值落在右半部分
//与最右端的元素进行比较,而不是与最左端的元素比较
if(nums[mid]>nums[hi]){
lo=mid+1;
}else if(nums[mid]<nums[hi]){
//hi 等于 mid 而不是 mid - 1,因为最小值有可能就是当前的 mid
hi=mid;
}else{
//去掉最后一个元素
hi--;
}
}
//返回的是元素不是索引
return nums[lo];
}
}
167
//一个升序排列的数组,输出两数相加等于目标数的元素索引加一,第一个索引要小于第二个索引,不能使用同一个元素超过一次
//使用 map 数据结构
class Solution {
public int[] twoSum(int[] numbers, int target) {
int[] result=new int[2];
if(numbers==null||numbers.length==0){
return result;
}
Map<Integer,Integer> map=new HashMap<>();
for(int i=0;i<numbers.length;i++){
map.put(numbers[i],i);
}
for(int i=0;i<numbers.length;i++){
if(map.containsKey(target-numbers[i])){
int index=map.get(target-numbers[i]);
//没有对数组中含有重复元素的情况进行处理
if(target%2==0&&numbers[i]==target/2){
if(map.get(numbers[i])==i){
continue;
}
}
if(index<i){
result[0]=index+1;
result[1]=i+1;
}else{
result[0]=i+1;
result[1]=index+1;
}
}
}
return result;
}
}
169
//统计出数组中出现次数超过一半数组长度的元素,假设不是空数组且这样的元素存在
//第一种方法:先进行排序,返回中间位置的元素;第二种方法:利用 map 数据结构存储结果
//hashmap 存放的是统计出来的每一个元素出现的次数,一个键值对就是一个 entry
class Solution {
public int majorityElement(int[] nums) {
Map<Integer,Integer> counts=countsNums(nums);
//初始化一个键值对为 null
Map.Entry<Integer,Integer> majorityEntry=null;
//注意获取键值对列表的方法
//括号不能丢
for(Map.Entry<Integer,Integer> entry:counts.entrySet()){
//如果主要的元素为 0 或者当前键值对中值大于之前初始化的值,也就是出现了出现次数更多的元素
if(majorityEntry==null||entry.getValue()>majorityEntry.getValue()){
majorityEntry=entry;
}
}
return majorityEntry.getKey();
}
//构造 hashmap 数据结构的方法
private Map<Integer,Integer> countsNums(int[] nums){
Map<Integer,Integer> counts=new HashMap<>();
for(int i=0;i<nums.length;i++){
//如果键种不包含当前元素,将其值设置为 1 ,包含则将其值加 1
//判断是否包含 key 而不是直接 contains
if(!counts.containsKey(nums[i])){
counts.put(nums[i],1);
//加一的位置写错了,应该放在第一个括号后面
}else{
counts.put(nums[i],counts.get(nums[i])+1);
}
}
return counts;
}
}
189
//暴力法
public class Solution {
public void rotate(int[] nums, int k) {
int temp, previous;
for (int i = 0; i < k; i++) {
previous = nums[nums.length - 1];
for (int j = 0; j < nums.length; j++) {
temp = nums[j];
nums[j] = previous;
previous = temp;
}
}
}
}
class Solution {
public void rotate(int[] nums, int k) {
int len=nums.length;
int[] helpArray=new int[len];
for(int i=0;i<len;i++){
//关键是确定这里的公式
helpArray[(i+k)%len]=nums[i];
}
for(int i=0;i<len;i++){
nums[i]=helpArray[i];
}
}
}
209
//给定一个目标值和一个数组,找出数组中连续的子数组的相加和大于等于目标值,返回这样的子数组的最小长度,如果不含有这样的子数组,返回 0
//方法一:暴力法
//方法二:二分查找
//方法三:双指针
class Solution {
public int minSubArrayLen(int s, int[] nums) {
//非空判断
if(nums==null||nums.length==0){
return 0;
}
//设置两个指针,一个用于向前加数组中的元素,一个用于向后减数组中的元素
int j=0,i=0;
//用于比较判断是否存存在符合要求的子数组,符合要求的子数组的最小长度
//整数的最大值的表示方法
int min=Integer.MAX_VALUE;
//用于统计当前子数组和的变量
int sum=0;
while(j<nums.length){
//注意 while 循环语句的 ++ 是放在数组索引中的
sum+=nums[j++];
while(sum>=s){
min=Math.min(min,j-i);
sum-=nums[i++];
}
}
//不存在就返回零,存在就返回最小长度子数组的长度
return min==Integer.MAX_VALUE?0:min;
}
}
216
//param:k 组成指定和的元素 param:n 指定的和,return 相应的数组,组成的元素从 1 - 9 挑选,输出的集合不能含有重复的子集合
//方法一:回溯,和之前输出所有的子数组类似,只是判断条件那里做改变
class Solution {
public List<List<Integer>> combinationSum3(int k, int n) {
List<List<Integer>> list=new ArrayList<>();
//因为要遍历的数组中的元素从 1 开始
backtracking(list,new ArrayList<>(),1,n,k);
return list;
}
//需要将 k 作为参数传入辅助方法,不然无法使用这个变量
private void backtracking(List<List<Integer>> list,List<Integer> tempList,int start,int n,int k){
if(tempList.size()==k&&n==0){
list.add(new ArrayList<>(tempList));
return;
}
for(int i=start;i<=9;i++){
tempList.add(i);
backtracking(list,tempList,i+1,n-i,k);
tempList.remove(tempList.size()-1);
}
}
}
217
//判断数组中是否含有重复的元素先排序再进行查找比较
//利用 HashSet 中的 contains 方法
class Solution {
public boolean containsDuplicate(int[] nums) {
Set<Integer> set=new HashSet<>();
for(int i:nums){
if(set.contains(i)){
return true;
}
//判断和添加在一个作用域中进行,思考一下为什么可以这样
set.add(i);
}
return false;
}
}
219
//给定一个数组和一个目标值,判断是否存在重复的元素并且,下标的差值不超过 k
//比起上一题多了下标差值的限制
//判断是否使用 foreach 看代码中是不是要用到索引
//set 添加元素的过程中默认判断是否集合中已经存在钙元素
class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
Set<Integer> set=new HashSet<>();
for(int i=0;i<nums.length;i++){
//这是一个滑动窗口, set 中只能包含 k+1 各元素,保证相同元素的差值不大于 k
if(i>k){
//这个只是怎么计算出来的呢?保证窗口中含有 k+1 个元素,那相同元素的差值就一定在 0-k 之间了
set.remove(nums[i-1-k]);
}
if(!set.contains(nums[i])){
return true;
}
}
return false;
}
}
228
//给定一个不含有重复元素的数组,输出这个数组包含的连续的范围
class Solution {
public List<String> summaryRanges(int[] nums) {
List<String> list=new ArrayList<>();
//当数组中只有一个元素时,,直接添加第一个元素后返回
if(nums.length==1){
//加空字符串在这里代表的是什么意思
//不能和 return 连起来写,单纯的 add 是返回 boolean 的,加索引的话奖没有返回值
list.add(nums[0]+"");
return list;
}
for(int i=0;i<nums.length;i++){
//判断是否是连续的下一个元素的条件,因为只要找到最后一个元素,所以用 while 循环,而且开始保存当前元素的值
int start=nums[i];
//判断是否超过边界的条件丢掉了
while(i+1<nums.length&&nums[i+1]==nums[i]+1){
i++;
}
int end=nums[i];
//当当前元素不等于之前保存的元素时,说明存在连续的数组元素
//保存初始到目前元素的输出
//代表这是一段连续空间
if(start!=end){
list.add(start+"->"+end);
//代表这是一个孤立的点
}else{
list.add(start+"");
}
}
return list;
}
}
229
//寻找给定的无序数组中,出现次数超过,三分之一长度的元素,可以有多个结果,要求时间复杂度不超过 On 空间复杂度不超过 O1,超过的意思是不包括等于的那个边界值
//类似于摩尔投票,摩尔投票又是啥呢
//结果肯定是保存在集合数据结构中
//注意一个关键点,重复次数超过三分之一长度的元素个数不会超过 2 个
class Solution {
public List<Integer> majorityElement(int[] nums) {
List<Integer> result=new ArrayList<>();
if(nums==null||nums.length==0){
return result;
}
//因为符合要求的元素最多有两个,两个计数变量设置为 0
int num1=nums[0],count1=0;
int num2=nums[0],count2=0;
int len=nums.length;
//第一次遍历,如果存在符合要求的元素,将存放在 num1 和 num2 中
//计数变量 count 重复利用,所以需要再一次,遍历数组,找到符合要求的元素
//该算法的重点全在这个逻辑,找出符合要求的元素
for(int i=0;i<len;i++){
if(nums[i]==num1){
count1++;
}else if(nums[i]==num2){
count2++;
}else if(count1==0){
num1=nums[i];
count1=1;
//将新的可能是结果的元素给 n2
}else if(count2==0){
num2=nums[i];
count2=1;
//为了再一次使用 count 给接下来的其他元素
//将数量较少的元素统计量先减为 0 ,用来存放下一个可能的元素
}else{
count1--;
count2--;
}
}
//将计数变量初始化为 0
count1=0;
count2=0;
//再次比那里数组找到满足要求的元素加入到结果集合中去
for(int i=0;i<len;i++){
if(nums[i]==num1){
count1++;
}else if(nums[i]==num2){
count2++;
}
}
if(count1>len/3){
result.add(num1);
}
if(count2>len/3){
result.add(num2);
}
return result;
}
}
238
//给定一个长度大于 1 的数组,输出的数组对应位置的元素等于输出除当前位置以外的元素的乘积
class Solution {
public int[] productExceptSelf(int[] nums) {
int len=nums.length;
int[] result=new int[len];
//设置第一个元素的左边的值和最后一个元素右边的值都为 1
//第一次遍历,result 中存放的是当前元素左边的值的乘积
//第一个元素设为 1
result[0]=1;
for(int i=1;i<len;i++){
result[i]=result[i-1]*nums[i-1];
}
//right 是当前元素右边的值的乘积
//第二次遍历,result 中存放的就是左右两边乘积的积
//因为是右边值的连乘,从后向前遍历
int right=1;
for(int i=len-1;i>=0;i--){
result[i]*=right;
// right 乘的是原数组中的值,而不是 result 中的元素
right*=nums[i];
}
return result;
}
}
268
//一个无序数组的总成元素是从 0-n 找出,中间缺少的元素,题意假设只缺失一个元素
//方法一:先排序,在判断,缺失的元素在第一个位置和最后一个位置单独考虑
//方法二:利用 hashset
//注意:如果缺失的是最后一个元素,因为是从零开始,不缺失的情况下,长度应该为最后一个元素值加一
class Solution {
public int missingNumber(int[] nums) {
Set<Integer> set=new HashSet<>();
//利用 foreach 便利添加所有元素到集合中
for(Integer num:nums){
set.add(num);
}
//原本应该的数组长度为当前长度加一
for(int i=0;i<nums.length+1;i++){
if(!set.contains(i)){
return i;
}
}
return -1;
}
}
283
//给定一个无序数组,将数组中的 0 元素移动到数组的后半部分
//先取非零的元素填入数组,再将数组中剩余位置用 0 补全
class Solution {
public void moveZeroes(int[] nums) {
if(nums==null||nums.length==0){
return;
}
//在原数组中进行操作,不需要额外空间
//通过一个额外的变量来表示当前不为零的元素的位置
int insertPos=0;
for(int i=0;i<nums.length;i++){
if(nums[i]!=0){
//将 i 位置处不为 0 的元素赋值到 insertPos 位置处
nums[insertPos++]=nums[i];
}
}
//将剩余位置用 0 补全
while(insertPos<nums.length){
nums[insertPos++]=0;
}
}
}
287
//给定一个无序数组 n+1 长度,由元素 1-n 组成,只有一个元素重复,输出重复的元素
//通过 sort 或者利用 set 解决
class Solution {
public int findDuplicate(int[] nums) {
// hash 加快了查找的顺序
Set<Integer> set=new HashSet<>();
//不是先遍历添加元素到 set 中,而是在遍历的过程中添加元素,就能启到判断重复的作用
//返回的是元素不是索引所以用 foreach 循环更加便利
for(int num:nums){
if(set.contains(num)){
return num;
}
//注意添加元素相对于代码中的位置
set.add(num);
}
return -1;
}
}
289 ***
// m*n 的二维数组,元素可以和其周围的八个方向上的元素进行交互,当前元素的邻居中少于两个元素存活时,该元素会死亡,2-3 个元素存活时可以产生下一代,多于三个元素时,会死亡,正好等于三个元素时会死而复生
//四种情况: 0,1 活变死 2,3 保持 3 死变活 4,5,6,7,8 活变死
//通过一个二位 bite 代表这四种情况
//以下为重点及难点
//获得当前元素的状态 board[i][j] & 1
//获得下一代元素的状态 board[i][j] >> 1
//00 dead<-dead | 01 dead<-live | 10 live<-dead | 11 live<-live
class Solution {
public void gameOfLife(int[][] board) {
if(board==null||board.length==0){
return;
}
//行数
int M=board.length;
//列数
int N=board[0].length;
for(int m=0;m<M;m++){
for(int n=0;n<N;n++){
//统计当前元素邻居的状态
int lives=liveNeighbors(board,M,N,m,n);
//01--->11 也就是 3
if(board[m][n]==1&&lives>=2&&lives<=3){
board[m][n]=3;
}
//00--->10 也就是 2
if(board[m][n]==0&&lives==3){
board[m][n]=2;
}
}
}
//产生下一代的过程,又二比特的第一位决定,0 代表不存活,1 代表存活
//每个位置处的元素通过移位的方法产生下一代
for(int m=0;m<M;m++){
for(int n=0;n<N;n++){
//等价于 board[m][n]=board[m][n]>>1
board[m][n]>>=1;
}
}
}
//统计存活的邻居的辅助方法
//也就是当前元素小范围内的一个二维数组的统计
private int liveNeighbors(int[][] board,int M,int N,int m,int n){
int lives=0;
//从当前元素周围的元素开始遍历,注意考虑四周的边界值及表示方法
//如果输入正好是 [0,0] 则判断是否超出上下左右的边界
//右边界和下边界分别为长度减一,发生数组越界异常先检查边界的值
for(int i=Math.max(m-1,0);i<=Math.min(m+1,M-1);i++){
for(int j=Math.max(n-1,0);j<=Math.min(n+1,N-1);j++){
//这里的当前元素是 1 ,则 board[i][j]&1 等于 1 否则为 0
lives+=board[i][j]&1;
}
}
//因为上述的遍历过程包含了当前元素,在这一步需要减去当前元素的状态
lives-=board[m][n]&1;
return lives;
}
}
//来源 : https://leetcode.com/problems/game-of-life/discuss/73223/Easiest-JAVA-solution-with-explanation
380
//每项操作 O1 的时间复杂度,可以进行插入删除和获得随机值的操作,不允许含有重复的元素
//通过 ArrayList 和 HashMap 数据结构作为底层实现,一个作为添加元素的工具,一个作为随机产生相应的位置的数据
//ArrayList 的优势就是可以通过索引得到相应位置处的值,map 的键是 list 中的值,值是 list 中相应值的位置
class RandomizedSet {
//存放值
List<Integer> list;
//存放值和位置的键值对
Map<Integer,Integer> map;
java.util.Random rand=new java.util.Random();
/** Initialize your data structure here. */
public RandomizedSet() {
list=new ArrayList<>();
map=new HashMap<>();
}
/** Inserts a value to the set. Returns true if the set did not already contain the specified element. */
public boolean insert(int val) {
if(map.containsKey(val)){
return false;
}
//因为第一个元素的索引是 1 ,所以要先执行这一条语句
map.put(val,list.size());
list.add(val);
return true;
}
/** Removes a value from the set. Returns true if the set contained the specified element. */
public boolean remove(int val) {
//HashMap 的查找速度很快,这里用 map 进行判断
if(!map.containsKey(val)){
return false;
}
//保存要删除的元素的索引
int index=map.get(val);
//将要删除的索引和最后一个元素交换位置
//注意边界条件是 -1
if(index<list.size()-1){
//因为后面需要最后一个元素,暂时保存最后一个元素的值
//这是通过 list 的索引得到其中对应的元素
int last=list.get(list.size()-1);
//替换要删除元素处的值,用 set 而不用 add
//list 和 map 都要更新
//注意健值的关系
list.set(index,last);
//相当于重新建立了键值对关系
map.put(last,index);
}
//map 中是通过键进行删除的
map.remove(val);
//将最后一个元素删除
list.remove(list.size()-1);
return true;
}
/** Get a random element from the set. */
public int getRandom() {
//通过 list 得到通过集合长度产生的一个随机数
//注意获得一个随机数的方法和边界
return list.get(rand.nextInt(list.size()));
}
}
/**
* Your RandomizedSet object will be instantiated and called as such:
* RandomizedSet obj = new RandomizedSet();
* boolean param_1 = obj.insert(val);
* boolean param_2 = obj.remove(val);
* int param_3 = obj.getRandom();
*/
381
//可以含有重复元素的数据结构,插入时仍然是包含返回 false 不包含返回 true
//本来 map 中一个键是不能有两个索引,也就是值的,通过 LinkedHashSet 将对应的值进行扩展,但存放的还是元素在 nums 中的索引
//删除的话只删除其中的一个重复元素
class RandomizedCollection {
List<Integer> nums;
Map<Integer,Set<Integer>> locs;
java.util.Random rand=new java.util.Random();
/** Initialize your data structure here. */
public RandomizedCollection() {
nums=new ArrayList<>();
locs=new HashMap<>();
}
/** Inserts a value to the collection. Returns true if the collection did not already contain the specified element. */
public boolean insert(int val) {
//需要在这里设置变量,不然这个值在代码执行过程中改变了
//返回值与插入之前的 set 中是否有该元素的这一状态有关
boolean contain=locs.containsKey(val);
if(!contain){
locs.put(val,new LinkedHashSet<>());
}
//上一步的条件判断只是加入了一个空 set,这一步向里面添加索引
locs.get(val).add(nums.size());
nums.add(val);
//不包含则返回 true,根据题意 包含就返回 false,也是遇上一题的一个不同之处
return !contain;
}
/** Removes a value from the collection. Returns true if the collection contained the specified element. */
public boolean remove(int val) {
if(!locs.containsKey(val)){
return false;
}
//保存当前元素的位置索引,第一次出现的索引,删除可以指定元素删除,但是想要得到一个元素的位置就需要通过迭代器
int loc=locs.get(val).iterator().next();
//先从 set 中删除该元素
locs.get(val).remove(loc);
//如果要删除的不是最后一个元素,需要交换与最后一个元素的位置,因为 linkedlist 不能指定索引位置删除,而之前一步得到的只是索引位置
if(loc<nums.size()-1){
//通过 nums 得到最后的元素更为方便
int lastone=nums.get(nums.size()-1);
//将最后的元素放到要删除元素的位置
nums.set(loc,lastone);
//需要在 map 中更新 lastone 的新位置,本质上是在 set 中更新,map 只是一个中间途径
//先删除,再重置
//比前一道题多了先删除的这一步骤,删除的是 set 集合中位于最后一位的lastone 对应的 set
//也不是交换最后元素和要删除元素的位置,而是先删除相应的元素,再用最后的元素填补那一位置
locs.get(lastone).remove(nums.size()-1);
locs.get(lastone).add(loc);
}
//错误:丢掉这条语句导致一直得不出正确结果
nums.remove(nums.size() - 1);
//因为在前面代码中删除了 map 中 val 对应的一个 set 如果那是最后一个,那么就可以完全删除 val 这个键值对了
if(locs.get(val).isEmpty()){
locs.remove(val);
}
return true;
}
/** Get a random element from the collection. */
public int getRandom() {
return nums.get(rand.nextInt(nums.size()));
}
}
/**
* Your RandomizedCollection object will be instantiated and called as such:
* RandomizedCollection obj = new RandomizedCollection();
* boolean param_1 = obj.insert(val);
* boolean param_2 = obj.remove(val);
* int param_3 = obj.getRandom();
*/
414
//对于一个给定的无序数组,输出所有元素中第三大的值,如果没有,则输出最大的那一个
//使用 Integer 和 equals 执行速度会减慢?为什么?
//使用 ?: 判别式,设置三个变量作为最大值,次大值和第三大值
//多个 else if 的组合充分体现了程序的顺序执行的特点
//如果用 int 代替可以使用 Integer.MAX_VALUE 作为起始值
class Solution {
public int thirdMax(int[] nums) {
//设置最大值变量
Integer max1=null;
//设置次大值
Integer max2=null;
//设置第三大值
Integer max3=null;
//用不到索引,所以使用 foreach 遍历,增强代码的可读性
for(Integer num:nums){
//跳过与最大的三个数值重复的元素
if(num.equals(max1)||num.equals(max2)||num.equals(max3)){
//不进行任何操作,结束本次循环
continue;
}
//当前元素比最大的值还大
//注意将 max 为空的情况先考虑进来,放在或操作符前面才可以
if(max1==null||num>max1){
//从当前元素开始依次向后移动最大值
max3=max2;
max2=max1;
max1=num;
//此处的判断条件不用再写小于 max1 了
}else if(max2==null||num>max2){
//最大值不懂,后面两个值移动
max3=max2;
max2=num;
//写错一个数字标号,导致一直得不到正确结果
}else if(max3==null||num>max3){
//仅仅第三大值改变
max3=num;
}
}
//通过查看第三大值是否被赋予新的元素来决定输出结果
//通过前三步已经将数组中的前三大元素找出来,不存在的用 null 代替
return max3==null?max1:max3;
}
}
442 ***
//找出 1-n 组成的数组中重复的元素,重复的元素只出现两次,要求时间复杂度为 On 空间复杂度为 O1
//遍历的情况下,通过一个元素出现两次,则对应的元素负负为正找到重复的元素
class Solution {
public List<Integer> findDuplicates(int[] nums) {
List<Integer> result=new ArrayList<>();
for(int i=0;i<nums.length;i++){
//通过由元素本身关联一个新的索引
//为什么这里需要用绝对值?
//因为当确实出现重复元素的时候,nums[i] 已经变成了负值,而负值不能作为索引
//index 与 i 既是独立又是联系的索引
//i ---> nums[i] ---> index ---> nums[index]
int index=Math.abs(nums[i])-1;
if(nums[index]<0){
//这里是 index+1 而不是绝对值加一
//index+1 代表的就是 nums[i]
result.add(Math.abs(index+1));
}
//因为如果该元素再次出现,那肯定是负值了
nums[index]=-nums[index];
}
return result;
}
}
448
//找出 1-n 组成的数组中缺失的元素,可能含有重复
//因为元素由 1-n 组成,所以元素和索引之间就能产生简单的多层映射
class Solution {
public List<Integer> findDisappearedNumbers(int[] nums) {
List<Integer> result=new ArrayList<>();
for(int i=0;i<nums.length;i++){
int index=Math.abs(nums[i])-1;
if(nums[index] > 0) {
nums[index] = -nums[index];
}
}
//这里为什么是判断 i 位置处的元素
for(int i=0;i<nums.length;i++){
if(nums[i]>0){
result.add(i+1);
}
}
return result;
}
}
457 (问题评价不高)
未做
485
//给定一个二进制数组,找到连续 1 的子数组的最大长度
//需要两个变量,一个保存当前连续 1 的个数,一个保存最大的连续个数
//注意开始未进行初始化
class Solution {
public int findMaxConsecutiveOnes(int[] nums) {
//最大的连续个数
int result=0;
//当前的连续个数
int count=0;
for(int num:nums){
if(num==1){
count++;
result=Math.max(count,result);
//丢掉了 else 重置计数变量
}else{
count=0;
}
}
return result;
}
}
495
//数组代表每次攻击的时间点,造成持续性伤害,每次攻击持续指定个时间单位,输出一共持续受到伤害的时间总长度
//判断的时候分两种情况,下一次攻击来临时,上一次的持续性伤害没有结束;或者下一次攻击来临之前上一次的持续性伤害已经结束
class Solution {
public int findPoisonedDuration(int[] timeSeries, int duration) {
//非空判断
//不能少
if(timeSeries==null||timeSeries.length==0||duration==0){
return 0;
}
//存放结果的变量
int result=0;
//对于第一次攻击的开始时间和持续结束时间初始化
int start=timeSeries[0],end=timeSeries[0]+duration;
for(int i=1;i<timeSeries.length;i++){
if(timeSeries[i]>end){
//将持续时间添加到结果变量中
result+=end-start;
//更新开始的时间点
//与下面 end 语句位置放反了导致出错
start=timeSeries[i];
}
//如果下一次击打时仍有持续伤害则不需要更新 start 只需更新 end
//新一次攻击持续时间结束的时间点
end=timeSeries[i]+duration;
}
//添加最后一次攻击持续的时间
//或者只有一次攻击,程序根本没有执行到循环中
result+=end-start;
return result;
}
}
二、 链表
002
//给定两个正数的非空链表通过链表进行多位数的加法运算,其中的元素反向存储在链表中
//因为每一位的数字是 0 到 9 之间,所以相加后可能溢出,包括进位的最大可能总和为 9+9+1=19,所以表示进位的变量不是 0 就是 1
//明确链表的头是哪个
/**
* Definition for singly-linked list. 定义的节点类
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
//初始化临时的头结点为 0
ListNode dummyHead=new ListNode(0);
//进位标志符初始化为 0
int carry=0;
//临时变量
ListNode p=l1,q=l2,curr=dummyHead;
//或条件判断,只要有一个链表没有遍历完就继续
while(p!=null||q!=null){
//如果一个链表比较短,先到达尾节点,根据条件判断加上的值
//每一位的数字
int x=(p!=null)?p.val:0;
int y=(q!=null)?q.val:0;
//计算当前位置的和
int sum=x+y+carry;
carry=sum/10;
//和链表的新节点赋值
curr.next=new ListNode(sum%10);
//下一个结点指向当前节点
curr=curr.next;
//不为空的情况下才继续向下移动
if(p!=null){
p=p.next;
}
if(q!=null){
q=q.next;
}
}
//最高位需要向前进位
if(carry>0){
curr.next=new ListNode(carry);
//有没有都一样,只会降低效率 curr=curr.next;
}
return dummyHead.next;
}
}
019
//从链表尾部删除第 n 个节点,并返回头结点
//遍历两次链表
//找到要删除节点的前一个节点,进行跳过下一个节点的操作
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
//创建一个新链表用于返回
ListNode dummy=new ListNode(0);
//暂时将老链表拼接到结果链表之上
//不然会报空指针异常
dummy.next=head;
//老链表长度
int length=0;
//统计哪个链表的长度就指向哪个链表的头
ListNode first=head;
//统计链表长度
while(first!=null){
length++;
first=first.next;
}
length-=n;
//开始新链表的遍历
//没有指向就会报空指针异常
first=dummy;
while(length>0){
length--;
first=first.next;
}
//跳过要删除的节点
first.next=first.next.next;
return dummy.next;
}
}
021
//合并两个有序链表,要求新链表仍然有序,超时
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
//特殊情况的判断
//全为空
if(l1==null&&l2==null){
return null;
}
//其中一个为空就返回另一个
if(l1==null){
return l2;
}
if(l2==null){
return l1;
}
ListNode dummty=new ListNode(0);
ListNode prev=dummty;
//正常的判断逻辑,比较两个相应节点的大小,先添加较小的节点值
//l1 l2 均不为零的情况
while(l1!=null&&l2!=null){
if(l1.val<=l2.val){
//相应的节点接到 prev 链表上
//相应的老链表向后移动一位
prev.next=l1;
l1=l1.next;
}else{
prev.next=l2;
l2=l2.next;
}
//超时的原因是丢掉这一句,一直在循环
prev = prev.next;
}
//如果又剩下的节点没有添加,全部添加到后面
//用 if 语句而不是 while
if(l1!=null){
//相当于把 l1 后面接的一串都添加进去了
prev.next=l1;
}
if(l2!=null){
prev.next=l2;
}
return dummty.next;
}
}
//递归方法,未理解
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
if(l1 == null) return l2;
if(l2 == null) return l1;
if(l1.val < l2.val){
l1.next = mergeTwoLists(l1.next, l2);
return l1;
} else{
l2.next = mergeTwoLists(l1, l2.next);
return l2;
}
}
}
023
//多路链表的归并,上一道题的扩展形式
//通过优先队列的数据结构,主要利用了优先队列的轮训查找最小值方法
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
//非空判断
if(lists==null||lists.length==0){
return null;
}
//通过内部类的方式创建优先队列
//创建具有初始容量,并且根据指定的比较器进行比较的队列
PriorityQueue<ListNode> queue=new PriorityQueue<ListNode>(lists.length,new Comparator<ListNode>(){
//重写比较方法,比较的是两个链表节点中的值
//比较器的内部类
public int compare(ListNode l1,ListNode l2){
if(l1.val<l2.val){
return -1;
}else if(l1.val==l2.val){
return 0;
}else{
return 1;
}
}
});
ListNode dummty=new ListNode(0);
ListNode tail=dummty;
//将集合中的头结点添加到队列中
for(ListNode node:lists){
if(node!=null){
queue.add(node);
}
}
//在队列中利用轮训将多个链表拼接成一个
while(!queue.isEmpty()){
//将比较小的头结点赋值到目标链表中
tail.next=queue.poll();
//两个节点连接起来
//tail 指针移动到下一个
tail=tail.next;
//tail 的下一个结点就是当前三个中的最小值的下一个结点
//指针怎么移动到多个链表的下一个结点是关键
if(tail.next!=null){
//将之前移动了的下一个结点添加到队列
queue.add(tail.next);
}
}
return dummty.next;
}
}
024
//交换相邻两个节点,只能对节点进行整体操作,而不能改变节点的值
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode swapPairs(ListNode head) {
//新链表头结点之前的元素
ListNode dummy=new ListNode(0);
dummy.next=head;
//一个指向头结点的指针
ListNode curr=dummy;
//当前节点的下一个结点和下下一个节点都不为空时,说明可以进行交换
while(curr.next!=null&&curr.next.next!=null){
//需要两个指针保存下面两个节点
ListNode first=curr.next;
ListNode second=curr.next.next;
//1 ---> 3
//.next赋值就是链表箭头的指向
first.next=second.next;
//curr ---> 2
curr.next=second;
//2 ---> 1
curr.next.next=first;
//curr 向后挪两个位置
curr=curr.next.next;
}
return dummy.next;
}
}
025
//将链表中的节点按输入的单位长度进行倒置,如果剩余节点不足这个数组,则不进行操作
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*----------------------------
*prev
*tail head
*dummy 1 2 3 4 5
*----------------------------
*prev head tail
*dummy 1 2 3 4 5
* cur
*----------------------------
* 每次让prev.next的元素插入到当前tail之后,这样tail不断前移,被挪动的元素头插入tail之后的链表
*prev tail head
*dummy 2 3 1 4 5
* cur
*----------------------------
*prev tail head
*dummy 3 2 1 4 5
* cur
*----------------------------
* prev
* tail
* head
*dummy 3 2 1 4 5
*----------------------------
* prev head tail
*dummy 3 2 1 4 5 null
*----------------------------
*/
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
//什么情况下不进行改变直接输出
if(head==null||head.next==null||k<2){
return head;
}
ListNode dummy=new ListNode(0);
dummy.next=head;
//三个指针,前,尾,临时
//前尾指针用于找到相应的要反转的部分
//当前指针在之后的导致过程中使用,开始并不使用
ListNode tail=dummy,prev=dummy,curr;
//保存 k 的变量,因为每一次倒置都需要固定的 k
int count;
//注意用无限循环的方法,和 break 语句的使用
while(true){
//以 k 节点为边界进行遍历
count=k;
//先向后遍历 k 个节点
//先确定第一段反转的尾节点
while(count>0&&tail!=null){
count--;
tail=tail.next;
}
//tail 到达尾节点,退出外层循环
if(tail==null){
break;
}
//每一段都需要新的 head 来进行反转
head=prev.next;
//用作截取的头尾节点没有相遇就可继续反转
while(prev.next!=tail){
//每一步循环都是将头结点移动到尾节点的下一个
//将要吧头结点移动走
curr=prev.next;
//找到头结点的下一个进行与第零个节点连接
prev.next=curr.next;
//将头节点移动到原来尾节点的位置
curr.next=tail.next;
//将尾节点向前移动一个
tail.next=curr;
}
//反转之后 head 节点已经移动到了一段的最后一个位置
tail=head;
prev=head;
}
return dummy.next;
}
}
061
//将由正整数组成的链表循环向后移动 k 个位置
//找出移动前后对应节点的位置关系式
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode rotateRight(ListNode head, int k) {
//当链表为空或者只含有一个元素的时候,直接返回头结点
if(head==null||head.next==null){
return head;
}
//新建一个要返回的链表
ListNode dummy=new ListNode(0);
//下一个结点指向老链表的头结点
dummy.next=head;
//两个特殊的节点,一个是老链表的尾节点,一个是新链表的尾节点
ListNode oldTail=dummy,newTail=dummy;
//统计链表的总长度
int length=0;
//是下一个结点不为空,就继续循环
//报空指针异常一般都是边界出了问题
while(oldTail.next!=null){
length++;
oldTail=oldTail.next;
}
//找到新链表的尾节点
int index=length-k%length;
while(index>0){
newTail=newTail.next;
index--;
}
//改变头结点和新老尾节点的指向
oldTail.next=dummy.next;
dummy.next=newTail.next;
newTail.next=null;
return dummy.next;
}
}
082
//给定一个有序的链表,删除重复的节点再返回,删除后的链表
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode deleteDuplicates(ListNode head) {
if(head==null||head.next==null){
return head;
}
ListNode dummy=new ListNode(0);
dummy.next=head;
//当前节点在头结点的下一个结点
ListNode prev=dummy,curr=dummy.next;
//注意循环结束的边界条件
while(curr!=null){
//找到相同元素段的尾节点
//什么时候用 while 什么时候用 if
while(curr.next!=null&&curr.val==curr.next.val){
curr=curr.next;
}
//通过判断前节点的下一个结点是否是当前节点查看这个节点元素是否唯一
if(prev.next==curr){
//这个节点唯一
prev=prev.next;
}else{
//需要删除所有重复的节点,一个也不剩
prev.next=curr.next;
}
//不管有无重复的元素,curr 指针都需要继续向前移动,进入下次一循环
curr=curr.next;
}
return dummy.next;
}
}
083
//删除重复的节点,并且保留一个重复的节点再链表中,上一题中是将重复的借点全部删除
//直接按照逻辑写代码,如果重复就跳过
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode deleteDuplicates(ListNode head) {
//不知道这样做的必要性在哪里
ListNode dummy=new ListNode(0);
dummy.next=head;
//当前节点从头结点作为起点,不然会出现异常
ListNode curr=dummy.next;
//需要当前节点和下一个结点均不为空时才进行循环
//因为在循环语句中用到了 next 的值,所以需要判断是否下一个结点为空
while(curr!=null&&curr.next!=null){
if(curr.val==curr.next.val){
//与下一个结点一样,就跳过当前节点
curr.next=curr.next.next;
}else{
//移动当前节点的指针
//与 if 语句形成互斥的关系
curr=curr.next;
}
}
return dummy.next;
}
}
086
//将链表中的节点进行分区,以输入的 x 为分区边界点,两个半区内各节点的相对顺序不变
//在添加点处打破改变原链表的结构
//使用两个指针跟踪创建的两个链表,最后将两个链表组合我们需要的结果
//使用虚拟节点进行初始化链表可以减少我们的条件检测次数,并且使得实现更容易,在合并两个链表时,只需要两个指针向前移动就好
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode partition(ListNode head, int x) {
//虚拟头结点
//虚拟节点将一直保留在开始位置,方便直接进行操作
ListNode before_dummy=new ListNode(0);
ListNode after_dummy=new ListNode(0);
//分别指向两个新链表的指针
ListNode before=before_dummy;
ListNode after=after_dummy;
//原始链表通过 head 指针进行遍历
while(head!=null){
//遍历到的节点小于 x 就移动到前半部分的链表,大于就移动到后半部分的链表
//那半部分的链表增加了,链表指针就向前移动一个
if(head.val<x){
before.next=head;
before=before.next;
}else{
after.next=head;
after=after.next;
}
head=head.next;
}
//尾节点的后面接空节点
after.next=null;
//前半部分的尾节点接后半部分虚拟节点的下一位
//在这里体现出虚拟节点的优越性
before.next=after_dummy.next;
return before_dummy.next;
}
}
092 ***
//难点,单向链表中没有向后的指针和索引
//通过递归中的回溯过程模拟指针向后的移动,如果子链表长度是奇数,左右指针将会重合,偶数,左右指针则会形成交叉
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
//使用全局布尔标志来停止指针交叉后的交换
private boolean stop;
//用于充当链表左端点的左指针
private ListNode left;
public ListNode reverseBetween(ListNode head, int m, int n) {
this.left=head;
this.stop=false;
this.recurseAndReverse(head,m,n);
return head;
}
//递归和反转的方法
private void recurseAndReverse(ListNode right,int m,int n){
//递归的基准条件,右端位置是 1 时,退出当前递归
if(n==1){
return;
}
//移动右指针直到 n==1
right=right.next;
if(m>1){
//因为是全局变量,不是从参数中传进来的变量,需要加上 this 关键词
this.left=this.left.next;
}
this.recurseAndReverse(right,m-1,n-1);
if(this.left==right||right.next==this.left){
this.stop=true;
}
//如果没有满足结束递归的条件,需要交换两个指针指向的节点的位置
//交换的是节点中保村的值,而不是交换节点
if(!this.stop){
//临时变量存放左端点的值
int temp=this.left.val;
this.left.val=right.val;
right.val=temp;
//交换过节点之后,左节点向右移动一个位置,右节点向左回溯一个位置
this.left=this.left.next;
}
}
}
109 ***
//给定一个有序的单向链表,将其转换成一个平衡二叉树,平衡二叉树的定义是一个节点的两个子树高度相差不超过 1
//递归方法
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
//建立树的递归方法
public TreeNode sortedListToBST(ListNode head) {
if(head==null){
return null;
}
//找到链表的中间元素
ListNode mid=this.findMiddleElement(head);
//之间位置的节点成为二叉搜索树的根节点
TreeNode node=new TreeNode(mid.val);
//当子链表中只有一个节点时,结束递归
if(head==mid){
return node;
}
//使用左半部分和右半部分递归的形成二叉搜索树
node.left=this.sortedListToBST(head);
node.right=this.sortedListToBST(mid.next);
return node;
}
//递归方法
private ListNode findMiddleElement(ListNode head){
//用于断开左端和中间节点的指针
ListNode prev=null;
//两个步进分别为 1 和 2 的指针
//目的是找出中间位置节点
ListNode slow=head;
ListNode fast=head;
//当步进为 2 的指针到达尾节点的时候,步进为 1 的指针正好到达中间位置,也就是根节点
while(fast!=null&&fast.next!=null){
prev=slow;
slow=slow.next;
fast=fast.next.next;
}
//将前半部分与中间节点断开, prev 代表中间节点的前一个节点
if(prev!=null){
prev.next=null;
}
return slow;
}
}
138
//生成一个特殊的链表,每个节点除了 next 指针之外还含有随机指针,最终目的是对这种特殊的链表进行深拷贝
//普通方法和使用 map 数据结构进行优化
//就是能够通过节点访问到链表中的值下一个结点和下一个随机节点
/*
// Definition for a Node.
class Node {
public int val;
public Node next;
public Node random;
public Node() {}
public Node(int _val,Node _next,Node _random) {
val = _val;
next = _next;
random = _random;
}
};
*/
class Solution {
public Node copyRandomList(Node head) {
//链表的非空判断,不然在进行 next 操作时会出现空指针异常
if(head==null){
return null;
}
//这里的 node 节点相当于之前常用的 curr 节点的表示方法
Map<Node,Node> map=new HashMap<>();
//添加节点到节点的映射
Node node=head;
while(node!=null){
//相当于只是进行的赋值操作
map.put(node,new Node(node.val,node.next,node.random));
node=node.next;
}
//指定下一个节点和随机节点的值
//进行链表之间的连接操作
node=head;
//这里不能使用 head 遍历,因为 head 在这充当的是虚拟节点的作用,用来返回结果链表
while(node!=null){
//先从 map 中取得节点
map.get(node).next=map.get(node.next);
map.get(node).random=map.get(node.random);
node=node.next;
}
return map.get(head);
}
}
141
//在链表中产生环,根据指定的 pos 的位置产生从尾节点指向那个位置的环,pos = -1 表示不产生环
//注意目的是判断链表中是否含有环
//两种方法:快慢指针和 set 数据结构
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public boolean hasCycle(ListNode head) {
Set<ListNode> set=new HashSet<>();
while(head!=null){
if(set.contains(head)){
return true;
}else{
set.add(head);
}
head=head.next;
}
return false;
}
}
//第二种方法,快慢指针
public class Solution {
public boolean hasCycle(ListNode head) {
ListNode slow=head;
ListNode fast=head;
while(fast!=null&&fast.next!=null){
slow=slow.next;
fast=fast.next.next;
if(slow==fast){
return true;
}
}
return false;
}
}
142
//返回含有环的链表环开始的相对节点的第几个位置
//快慢指针
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode detectCycle(ListNode head) {
ListNode slow=head;
ListNode fast=head;
while(fast!=null&&fast.next!=null){
//慢指针先进行移动,并且是快指针追赶上慢指针才行,反过来不可以
slow=slow.next;
fast=fast.next.next;
//快指针走过的距离是慢指针的二倍,因此新指针以 1 的步进向前移动,与满指针再次相遇的时候就是进入环的位置
//环中需要的步数等于走到慢指针位置需要的步数
//慢指针再走几步走满新的一圈,考虑重合的步数,相当于从起点开始再走几步走到环开始的位置
if(fast==slow){
//通过一个新的指针
ListNode temp=head;
while(temp!=slow){
slow=slow.next;
temp=temp.next;
}
return slow;
}
}
return null;
}
}
143 ***
//重点是看出将链表从中间截取,把后半部分的节点按照要求插入到前半部分
//所以问题的解决可以分为以下三步
//找到中间的节点,将后半部分逆序,将两段链表连接成一段链表
//head 节点默认指向的是第一个节点,不是第一个节点前的虚拟节点
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public void reorderList(ListNode head) {
//非空或者一个节点判断,一个节点的时候必须也得单独考虑
if(head==null||head.next==null){
return;
}
//通过快慢指针的方法取得中间节点的位置
ListNode slow=head;
ListNode fast=head;
//循环条件是下一个结点和下下一个节点不是空,而不是当前和下一个结点
//两个条件的顺序不能变
//这个判断条件与后面一体的判断条件当节点个数为奇数时没有区别,节点个数为偶数时,这个 slow 落在前半区最后一个节点,下一题落在后半区的第一个节点
while(fast.next!=null&&fast.next.next!=null){
slow=slow.next;
fast=fast.next.next;
}
//中间节点的位置就是现在 slow 指针指向的位置
ListNode prevMidd=slow;
ListNode prevCurr=slow.next;
//依次将中间节点后面的节点两两交换位置
//因为交换位置的时候用到了 prevCurr 节点的下一个结点,所以判断循环的结束条件需要是该节点的下一个结点
//下面代码中用到了三个指针,要注意区分,交换的是四个节点中间的两个节点
while(prevCurr.next!=null){
//交换时用到的暂时保存的节点
//操作时是按照上一条语句的右边是下一条语句的左边的顺序进行交换
ListNode nextTemp=prevCurr.next;
prevCurr.next=nextTemp.next;
nextTemp.next=prevMidd.next;
prevMidd.next=nextTemp;
//交换完之后已经相当于当前指针向后移动了一个位置,所以不需要在通过代码 next 来移动当前指针
}
//依次将两段链表组合成符合要求的一段链表
//慢指针从第一个及节点开始,快指针从中间节点的下一个结点开始,分别是两段链表的第一个节点
slow=head;
//这里与前面快慢指针的循环终止条件相对应
fast=prevMidd.next;
//前一段链表的长度等于后一段链表的长度或者比其长度多一个
//没有返回值不需要使用虚拟指针,不然反而更加麻烦
while(slow!=prevMidd){
//从中间节点的断开开始执行
//从断点处向后拿出一个节点插入到前面,也没有断开链表
//每一步的顺序不能有变化
prevMidd.next=fast.next;
fast.next=slow.next;
slow.next=fast;
//进行指针的向前移动时需要注意
//原来的 slow 指针的下一个节点,是现在 fast 指针的下一个结点
slow=fast.next;
//原来的 fast 指针的下一个结点,是现在中间节点指针的下一个结点
fast=prevMidd.next;
}
}
}
147
//使用插入排序的方法对一个链表进行排序
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode insertionSortList(ListNode head) {
if(head==null||head.next==null){
return head;
}
ListNode dummy=new ListNode(0);
ListNode curr=head;
while(curr!=null){
//每一次从虚拟节点重新开始进行比较
//相当于每次将指针初始化到头结点的位置
ListNode prev=dummy;
//dummy.null 等于空,第一次不进入循环,只将链表中的第一个节点插入到虚拟节点和空节点之间
while(prev.next!=null&&prev.next.val<curr.val){
prev=prev.next;
}
//经过上面的语句,指针停留在前面均小于当前指针的位置处
//在 prev 与 after 之间插入 curr
//因为 curr.next 遭到了破坏,需要暂时保存下一个节点的信息
ListNode next=curr.next;
curr.next=prev.next;
prev.next=curr;
curr=next;
}
return dummy.next;
}
}
148
//在 O(nlogn) 时间复杂度之内对链表进行排序
//归并排序的方法的使用,与递归的结合
//为什么从中间位置的前一个位置处断开,因为如果是含有偶数个节点,中间节点的前一个位置正好将长度一分为二,奇数则前半部分比后半部分少一个节点
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode sortList(ListNode head) {
//递归的基准条件
if(head==null||head.next==null){
return head;
}
//通过快慢指针找到中间节点
//想要完全分割成两个链表就需要在左链表的结束位置加上 null 节点
ListNode slow=head,fast=head,prev=null;
//prev 始终是 slow 上一个节点
//这里的边界条件影响着是否含有空指针异常
//如果用前一体的条件,需要保存的就是 slow 后一个节点的情况
while(fast!=null&&fast.next!=null){
prev=slow;
slow=slow.next;
fast=fast.next.next;
}
//将两段链表断开,从 slow 指针的前一个位置
prev.next=null;
//对每个半区进行排序
ListNode left=sortList(head);
//相当于传入了第二段链表的 head
ListNode right=sortList(slow);
//归并操作
return merge(left,right);
}
private ListNode merge(ListNode left,ListNode right){
//使用虚拟指针进行归并
ListNode dummy=new ListNode(0);
ListNode curr=dummy;
//与之前两条链表的归并排序完全一样
//不是判断 curr 而是判断左右链表的情况
while(left!=null&&right!=null){
if(left.val<right.val){
curr.next=left;
left=left.next;
}else{
curr.next=right;
right=right.next;
}
curr=curr.next;
}
if(left!=null){
curr.next=left;
}
if(right!=null){
curr.next=right;
}
return dummy.next;
}
}
160
//找出两条汇合链表汇合处节点的值
//非空检查也就是边界检查,考虑比较特殊的输入值的情况
//为什么不需要预处理两个链表的差异?因为我们只要保证两个指针同时到达交叉节点处就行
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
//边界检查
if(headA==null||headB==null){
return null;
}
ListNode a=headA;
ListNode b=headB;
while(a!=b){
//当一种一个指针到达一个链表的结尾时,让其指向另一个链表的开始,如果有交叉,呢么必然会在交叉点处汇合
//以下式子可以用多想表达式直接替换
//a = a == null? headB : a.next;
//b = b == null? headA : b.next;
if(a!=null){
a=a.next;
}else{
a=headB;
}
if(b!=null){
b=b.next;
}else{
b=headA;
}
}
return a;
}
}
203
//从链表中删除含有指定值的节点,该节点可能不只有一个
//方法:设置两个指针,一个在前,一个在后,如果需要删除,就用前面的指针的下一个结点的操作对后指针进行跳过也就是删除的操作
//但凡是需要返回链表的,都要考虑下是否需要虚拟节点
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode removeElements(ListNode head, int val) {
//因为要用到头结点的前一个节点,使用虚拟节点较为方便
ListNode dummy=new ListNode(0);
dummy.next=head;
ListNode prev=dummy,curr=head;
while(curr!=null){
if(curr.val==val){
prev.next=curr.next;
}else{
//不进行任何操作,只在移动 curr 前,将指针向后移动一个位置
prev=prev.next;
}
curr=curr.next;
}
return dummy.next;
}
}
206
//将整个链表进行反转
//主要分为两种方法,分别是递归和迭代;递归比迭代可能更容易理解,但是空间复杂度会更高
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
//调转每个指针箭头的指向
//一个指针指向尾节点,一个从头结点开始向后移动
ListNode tail=null;
ListNode curr=head;
//相当于循环进行的操作
while(curr!=null){
//暂时保存当前节点的下一个节点
ListNode nextTemp=curr.next;
//头结点的下一个结点指向当前的尾节点,第一次进行操作时就是尾节点
curr.next=tail;
//curr 在上一条命令后变成新的尾节点
tail=curr;
curr=nextTemp;
}
return tail;
}
}
//递归的方法
public ListNode reverseList(ListNode head) {
if (head == null || head.next == null) return head;
ListNode p = reverseList(head.next);
head.next.next = head;
head.next = null;
return p;
}
234
//确定链表是否是回文链表
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public boolean isPalindrome(ListNode head) {
//使用快慢指针将链表分成两个两个指针
//注意中间节点的边界条件
//偶数和奇数情况需要区分对待
ListNode fast=head,slow=head;
while(fast!=null&&fast.next!=null){
slow=slow.next;
fast=fast.next.next;
}
//奇数情况,slow 指针停在正好中间位置,需要再向后移动一个位置,使前半部分比后半部分长 1
//偶数时,slow 指针正好停在等分位置的下一个指针位置处,不需要进行额外操作,直接传入反转函数将后半部分进行反转处理
//链表的长度为奇数
if(fast!=null){
slow=slow.next;
}
//反转后半部分链表
//重复利用 slow 指针,下一次遍历
slow=reverse(slow);
//重复利用 fast 指针,进行下一次的步进为 1 的遍历前半部分的链表
fast=head;
//后半部分先遍历结束
//和归并排序的区别是没必要完全分开生成两个链表,只需要判断就行
while(slow!=null){
if(fast.val!=slow.val){
return false;
}
fast=fast.next;
slow=slow.next;
}
return true;
}
//反转链表的辅助方法
private ListNode reverse(ListNode head){
//一个指向尾节点的指针
ListNode tail=null;
//因为返回的是尾节点,没必要在设置一个 curr 指针了,直接用 head 进行移动就好了
while(head!=null){
ListNode nextTemp=head.next;
head.next=tail;
tail=head;
head=nextTemp;
}
return tail;
}
}
237
//删除指定值相应的节点,没有给定输入的头结点,直接输入的是要删除节点的值
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public void deleteNode(ListNode node) {
//为什么这里需要将下一个结点的值赋值给要删除的节点?
//因为无法获得上一个节点的信息,不能用上一个节点指向当前节点的下一个结点这种方法
//通过将当前节点的值变成下一个结点的值,再跳过下一个结点这种方法来实现
node.val=node.next.val;
node.next=node.next.next;
}
}
三、树
094
//中序遍历:给定一个二叉树,返回其中序遍历
//分别使用递归和迭代的方法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
//使用集合数据结构存放结果
List<Integer> res=new ArrayList<>();
helper(root,res);
return res;
}
//定义一个辅助方法用于实现递归
//为了每次不重新建立新的集合存放结果
private void helper(TreeNode root,List<Integer> res){
//当根节点为空时,不进行任何操作
if(root!=null){
if(root.left!=null){
helper(root.left,res);
}
//关键是在这一步将根节点的值加入到集合中
res.add(root.val);
if(root.right!=null){
helper(root.right,res);
}
}
}
}
//迭代方法
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
//使用到栈的迭代方法,保存的是值
List<Integer> res=new ArrayList<>();
//使用栈来存放向下遍历过程中经过的节点
Stack<TreeNode> stack=new Stack<>();
//用来临时存放根节点
TreeNode curr=root;
//遍历完所有节点的循环终止条件为什么是 curr==null 和 stack 为空呢?
while(curr!=null||!stack.isEmpty()){
//一直找到最左子树,在这个过程中将遍历过的树节点加入到栈中
while(curr!=null){
stack.push(curr);
//深入到下一层左子树
curr=curr.left;
}
//此时出栈的节点就是最左节点了
//pop 的作用是从栈中删除并取得这一节点
curr=stack.pop();
res.add(curr.val);
//深入到下一层右子树
curr=curr.right;
}
return res;
}
}
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
//先将根节点入栈,
// 一直往其左孩子走下去,将左孩子入栈,直到该结点没有左孩子,则访问这个结点,如果这个结点有右孩子,则将其右孩子入栈,
// 重复找左孩子的动作,这里有个要判断结点是不是已经被访问的问题。 非递归中序遍历(效率有点低),
// 使用map(用set貌似更合理)来判断结点是否已经被访问
List<Integer> res=new ArrayList<>();
//保存已经访问过的节点
Map<TreeNode,Integer> map=new HashMap<>();
//将要访问的节点
Stack<TreeNode> stack=new Stack<>();
if(root==null){
return res;
}
stack.push(root);
while(!stack.isEmpty()){
//注意这里是peek而不是pop,因为这一步是要一直递归到最左端而不是进行访问
TreeNode tempNode=stack.peek();
//一直往左子树深入
while(tempNode.left!=null){
//如果没有被访问过加入到栈中并且继续深入,访问过就退出
if(map.get(tempNode.left)!=null){
break;
}
stack.push(tempNode.left);
tempNode=tempNode.left;
}
//访问该节点,访问过后就从栈中删除并在map中添加,所以用的是pop方法
tempNode=stack.pop();
res.add(tempNode.val);
map.put(tempNode,1);
//右节点入栈
if(tempNode.right!=null){
stack.push(tempNode.right);
}
}
return res;
}
}
//前序遍历的非递归方法
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res=new ArrayList<>();
if(root==null){
return res;
}
Stack<TreeNode> stack=new Stack<>();
stack.push(root);
while(!stack.isEmpty()){
//将栈顶元素弹出并保存
TreeNode tempNode=stack.pop();
if(tempNode!=null){
res.add(root.val);
//注意是先添加右子树节点再添加左子树节点
stack.push(root.right);
stack.push(root.left);
}
}
return res;
}
}
//后序遍历的费递归方法
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
//先进行前序遍历,再将结果链表倒置相当于后序遍历返回结果
List<Integer> res=new ArrayList<>();
if(root==null){
return res;
}
Stack<TreeNode> stack=new Stack<>();
stack.push(root);
while(!stack.isEmpty()){
//将栈顶元素弹出并保存
TreeNode tempNode=stack.pop();
if(tempNode!=null){
res.add(root.val);
//注意是先添加右子树节点再添加左子树节点
stack.push(root.right);
stack.push(root.left);
}
}
Collections.reverse(res);
return res;
}
}
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res=new ArrayList<>();
if(root==null){
return res;
}
Map<TreeNode,Integer> map=new HashMap<>();
Stack<TreeNode> stack=new Stack<>();
stack.push(root);
while(!stack.isEmpty()){
TreeNode tempNode=stack.peek();
//如果当前节点是叶子结点或者左右节点均被访问过
if(tempNode.left==null&&tempNode.right==null||(!((tempNode.left!=null&&map.get(tempNode.left)==null)||tempNode.right!=null&&map.get(tempNode.right)==null))){
res.add(tempNode.val);
map.put(tempNode,1);
stack.pop();
continue;
}
//当左节点不是空时
if(tempNode.left!=null){
//左节点没有被访问的情况下,一直找到最左边没有被访问的左节点
while(tempNode.left!=null&&map.get(tempNode.left)==null){
stack.push(tempNode.left);
tempNode=tempNode.left;
}
}
//当右节点不为空时
if(tempNode.right!=null){
//每次只访问一个右节点就好
if(map.get(tempNode.right)==null){
stack.push(tempNode.right);
}
}
}
return res;
}
}
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
//使用两个栈的方法
List<Integer> res=new ArrayList<>();
if(root==null){
return res;
}
Stack<TreeNode> stack=new Stack<>();
Stack<TreeNode> stack1=new Stack<>();
stack.push(root);
while(!stack.isEmpty()){
//将栈顶元素弹出并保存
TreeNode tempNode=stack.pop();
stack1.push(tempNode);
//先将左节点入栈1,再将右节点入栈1
//因为经过了两个栈,后进先出的顺序又反过来了,所以对比只有一个栈的前序遍历
if(tempNode.left!=null){
stack.push(tempNode.left);
}
if(tempNode.right!=null){
stack.push(tempNode.right);
}
}
while(!stack1.isEmpty()){
res.add(stack1.pop().val);
}
return res;
}
}
//层序遍历的非递归实现
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> res=new LinkedList<>();
//记录层数
int height=0;
//使用队列存放节点
Queue<TreeNode> queue=new LinkedList<>();
queue.add(root);
while(!queue.isEmpty()){
height=queue.size();
List<Integer> tempList=new ArrayList<>();
while(height>0){
TreeNode tempNode=queue.poll();
if(tempNode!=null){
tempList.add(tempNode.val);
queue.add(tempNode.left);
queue.add(tempNode.right);
}
height--;
}
if(tempList.size()>0){
res.add(tempList);
}
}
return res;
}
}
095
//独特的二叉搜索树2:给定一个整数,生成用来存储从 1 到这个整数的所有可能的二叉搜索树的数据结构
//思路:将n个数字一直分成两部分,分开的中间节点一直增加,把这两部分分别递归的添加到左右子树中
//方法,递归或者动态规划
//树就是多了一个指向的链表
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<TreeNode> generateTrees(int n) {
if(n==0){
return new ArrayList<>();
}
//从开始参数到结束参数构造二叉树
return generateHelper(1,n);
}
private List<TreeNode> generateHelper(int start,int end){
//为什么结果集合是在辅助方法中创建呢
List<TreeNode> list=new ArrayList<>();
//添加叶子结点也就是空节点的情况
if(start>end){
list.add(null);
return list;
}
//当左右子树中只有一个节点时添加到集合中去
//将树添加到集合中的过程
if(start==end){
//注意添加的是节点不是整数
list.add(new TreeNode(start));
return list;
}
//左右子树分别保存在两个由节点组成的节点集合中
List<TreeNode> left,right;
//从开始到结束节点开始遍历添加到整个二叉搜索树之中
//在这里就选定了每次递归的根节点
//创造树的过程
for(int i=start;i<=end;i++){
//每次循环选定 i 作为根节点,依次输入左右子树的开始和结束节点对应的值
//通过递归得到相应的左右子树节点的集合
left=generateHelper(start,i-1);
right=generateHelper(i+1,end);
//遍历左右子树组成不同形式的二叉树
for(TreeNode lnode:left){
for(TreeNode rnode:right){
//构建临时的根节点
//构建由三个节点组成的最基本的二叉树,注意要满足二叉搜索树的定义
TreeNode root=new TreeNode(i);
root.left=lnode;
root.right=rnode;
list.add(root);
}
}
}
return list;
}
}
//简化版
public List<TreeNode> generateTrees(int n) {
return generateSubtrees(1, n);
}
private List<TreeNode> generateSubtrees(int s, int e) {
List<TreeNode> res = new LinkedList<TreeNode>();
if (s > e) {
res.add(null); // empty tree
return res;
}
for (int i = s; i <= e; ++i) {
List<TreeNode> leftSubtrees = generateSubtrees(s, i - 1);
List<TreeNode> rightSubtrees = generateSubtrees(i + 1, e);
for (TreeNode left : leftSubtrees) {
for (TreeNode right : rightSubtrees) {
TreeNode root = new TreeNode(i);
root.left = left;
root.right = right;
res.add(root);
}
}
}
return res;
}
096
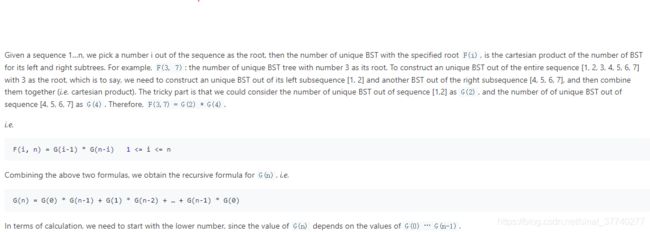
//独特的二叉搜索树1:给定 n 统计出结构上唯一的二叉树的个数
//枚举序列中的数字分别作为根,递归的从子序列构造树,通过这种方法可以保证构造的树是独特的,因为具有独特的根
//G(n) 使我们要求的函数,F(i,n) 是当 i 作为根时构成的唯一二叉搜索树的数目,其中n代表总数,i代表当前的数字作为根节点的情况
//1\ G(n) = F(1, n) + F(2, n) + ... + F(n, n) 并且 G(0)=1, G(1)=1
//2\ F(i, n) = G(i-1) * G(n-i) 1 <= i <= n
//3\ G(n) = G(0) * G(n-1) + G(1) * G(n-2) + … + G(n-1) * G(0)
//以上三步也是嵌套循环与数学求和联系的过程
//指定根节点 F(i) 的可组成二叉树的数目是其左右子树的笛卡尔积
//动态规划
class Solution {
public int numTrees(int n) {
//在基础情况,只有一种可能来描述只有艮或者空树的情况
int[] G=new int[n+1];
//基准情况
G[0]=1;
G[1]=1;
//分别以 i 为根节点的情况
//其中用 G 来表示 F 来通过循环解决
for(int i=2;i<=n;i++){
for(int j=1;j<=i;j++){
//求笛卡尔积的过程
//假设当前根节点为 3 总结点数为 7,那么右子树的节点数为 7-4+1=4 = 7-3
G[i]+=G[j-1]*G[i-j];
}
}
return G[n];
}
}
098
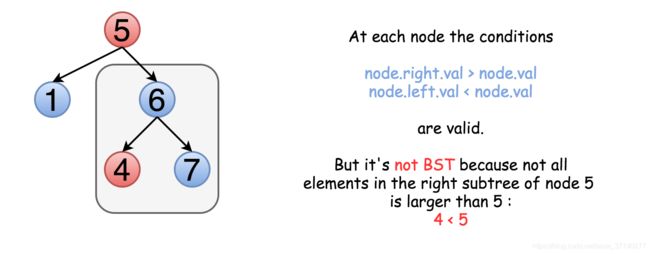
//验证二叉搜索树:二叉搜索树的定义,给定一个二叉树,判断其是否为二叉搜索树
//左子树节点的键均小于根节点的键,右子树节点的键均大于根节点的键,左右字数都是二叉搜索树
//要保证左子树的所有节点均小于根节点,就要设置左右的极限值。以便下一轮遍历时作比较
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public boolean isValidBST(TreeNode root) {
//空树也是一个二叉搜索树
if(root==null){
return true;
}
return isBSTHelper(root,null,null);
}
//递归的辅助方法
//参数 lower 和 upper 代表当前循环比较的一个极限值,树的搜索每深入一个层级,极限值也就跟着改变
private boolean isBSTHelper(TreeNode node,Integer lower,Integer upper){
//递归方法的基准条件一般都写在这个递归遍历语句的前半部分
if(lower!=null&&node.val<=lower){
return false;
}
if(upper!=null&&node.val>=upper){
return false;
}
//如果左子树节点为空,则返回 true ,不为空就继续往下一层深入
//left 和 right 相当于是左右子树分别的判断是否是二叉搜索树的标识符
boolean left=(node.left!=null)?isBSTHelper(node.left,lower,node.val):true;
//如果对左子树的遍历返回为真,则继续遍历右子树,否则直接跳到 else 作用域返回 false
if(left){
//根据具体情况,右子树的判断值可能为 true 也可能为 false
boolean right=(node.right!=null)?isBSTHelper(node.right,node.val,upper):true;
return right;
}else{
return false;
}
//等价于
boolean left=(root.left!=null)?helper(root.left,lower,root.val):true;
boolean right=(root.right!=null)?helper(root.right,root.val,upper):true;
return left&&right;
}
}
099***
//修复错误:二叉搜索树中的两个节点被错误的交换,在不改变树结构的情况下修复这一错误
//找出不对顺序的第一第二个节点元素
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
// //中序遍历的最简单形式
// private void traverse(TreeNode root){
// if(root==null){
// return;
// }
// traverse(root.left);
// //做一些你需要的操作
// traverse(root.right);
// }
//全局变量
TreeNode firstElement=null;
TreeNode secondElement=null;
//将前项指针用最小的整数进行初始化
TreeNode prevElement=new TreeNode(Integer.MIN_VALUE);
public void recoverTree(TreeNode root) {
//中序遍历整棵树,在这个过程中改变上面三个节点变量的值
traverse(root);
//交换找出的 first 和 second 出错变量的值
int temp=firstElement.val;
firstElement.val=secondElement.val;
secondElement.val=temp;
}
//目的就是找出顺序错误的节点并存放到 first 和 second 全局变量中去
//使用的是中序遍历
private void traverse(TreeNode root){
if(root==null){
return;
}
traverse(root.left);
if(firstElement==null&&prevElement.val>=root.val){
firstElement=prevElement;
}
if(firstElement!=null&&prevElement.val>=root.val){
secondElement=root;
}
prevElement=root;
traverse(root.right);
}
}
100
//相同的树:检查两个二叉树是否完全相同,完全相同的定义是结构上相同并且对应节点具有相等的值
//递归方法,比较简单,迭代方法很难
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public boolean isSameTree(TreeNode p, TreeNode q) {
//主要分成三种情况,两棵树全为空,有一颗为空,全不为空
//这三个 if 语句共同构成这个递归的基准条件
if(p==null&&q==null){
return true;
}
if(p==null||q==null){
return false;
}
//不是判断相等,是找出所有不等时的返回条件
if(p.val!=q.val){
return false;
}
//根节点相同的情况下才继续比较左右节点
return isSameTree(p.left,q.left)&&isSameTree(p.right,q.right);
}
}
101
//镜像二叉树:判断一棵二叉树是否是关于自身镜像的,该树的给出是通过前序遍历的数组
//思路;判断镜像需要比较两个节点的情况,因此最好有一个辅助方法可以传入两个参数,在传入参数的时候做文章
//同样是通过递归和迭代两种方法解决,目前只考虑递归的解决方法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public boolean isSymmetric(TreeNode root) {
return isMirror(root,root);
}
//因为比较的时候输入时两个节点比较直接,通过辅助的递归方法实现
private boolean isMirror(TreeNode t1,TreeNode t2){
//因为叶子结点默认是空节点
if(t1==null&&t2==null){
return true;
}
if(t1==null||t2==null){
return false;
}
//这一步没想起来
//注意是右子树的左节点和左子树的右节点进行比较
return (t1.val==t2.val)&&isMirror(t1.left,t2.right)&&isMirror(t1.right,t2.left);
//和判断两个树是否全等本质上时相同的
}
}
102
//二叉树的层序遍历:返回二叉树的层序遍历,结果存放在集合中,每一层存放成一个子集合
//使用广度优先搜索的方法,也可以利用队列
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
//存放结果的集合
List<List<Integer>> res=new ArrayList<>();
helper(res,root,0);
return res;
}
private void helper(List<List<Integer>> res,TreeNode root,int height){
//判断是否到了叶子结点
//递归的基准条件
if(root==null){
return;
}
//当树的遍历进行到下一层时,需要向集合中添加新的链表
if(height>=res.size()){
res.add(new LinkedList<>());
}
res.get(height).add(root.val);
//因为不管是左子树还是右子树的递归,只要在同一层递归中,所处的层次就是相同的,每次递归需要取出当前的层次
helper(res,root.left,height+1);
helper(res,root.right,height+1);
}
}
103
//z字型的层序遍历:层序遍历的扩展题,按 z 字型返回二叉树的每层节点值子集合组成的集合
//思路:通过一个标识符表示当前是奇数层还是偶数层,一层一变号;不使用递归就得借助额外的数据结构实现递归过程
//关于树的解决方案中很多也用到了 bfs 和 dfs
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<List<Integer>> zigzagLevelOrder(TreeNode root) {
//标准的广度优先实现方法
List<List<Integer>> res=new ArrayList<>();
if(root==null){
return res;
}
//queue 数据结构的内部就是完全有 LinkedList 实现的
Queue<TreeNode> queue=new LinkedList<>();
//和添加链表中的头结点类似,添加了根节点相当于把整棵树都添加到了队列之中,因为可以通过根节点遍历得到整棵树
queue.offer(root);
//当层级数是奇数时,改变 reverse 标识符,这一层的树节点将从后往前进行遍历,也就实现了偶数行用 false 表示
boolean reverse=false;
while(!queue.isEmpty()){
//遍历节点的时候用到
int size=queue.size();
//使用临时链表,将添加节点的时间复杂度降到 O1
//不能使用接口,不然解析不到 addFirst 这个方法
LinkedList<Integer> tempList=new LinkedList<>();
for(int i=0;i<size;i++){
TreeNode currNode=queue.poll();
//reverse 为真,表示当前行是奇数行
if(reverse){
//接口没有这个方法
//从头部开始添加
//最新的在最前面,和栈的性质有点像,也就实现了奇数行从后向前遍历
tempList.addFirst(currNode.val);
}else{
//添加到尾部,最新添加的元素在最后面
tempList.add(currNode.val);
}
//依次向下遍历左右子树
//队列数据结构能够始终保证下一层元素在当前层元素后面入队
if(currNode.left!=null){
queue.offer(currNode.left);
}
if(currNode.right!=null){
queue.offer(currNode.right);
}
}
res.add(tempList);
//没深入一个层次,标识符变换一次符号
reverse=!reverse;
}
return res;
}
}
104
//求一个二叉树的最大深度,也就是从根节点到叶子结点的最长路径所包含的节点数
//分别使用,递归,迭代的方法又分别可以使用深度优先所搜和广度优先搜索的方法,
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int maxDepth(TreeNode root) {
if(root==null){
return 0;
}
//1 代表的是当前节点,最长路径必然包含当前节点
return 1+Math.max(maxDepth(root.left),maxDepth(root.right));
}
}
107
//从底向上按照层级存放树的结构到集合中并返回
//分别使用深度优先和广度优先的方法
//深度优先算法为使用递归,广度优先算法使用了递归
//也是相当于层序遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<List<Integer>> levelOrderBottom(TreeNode root) {
//什么时候需要使用队列进行存放呢
Queue<TreeNode> queue=new LinkedList<>();
//需要返回的结果集合
List<List<Integer>> res=new LinkedList<>();
if(root==null){
return res;
}
//相当于将整棵树存入到 queue 中
queue.offer(root);
//与之前 z 字型层序遍历的解法类似
while(!queue.isEmpty()){
int size=queue.size();
//临时存放一层节点的链表
//在 for 循环外边定义
//将元素添加到链表中
List<Integer> tempList=new LinkedList<>();
for(int i=0;i<size;i++){
//因为临时保存了当前节点的信息,所以先添加还是先判断左右子树都可以执行
TreeNode currNode=queue.poll();
if(currNode.left!=null){
queue.offer(currNode.left);
}
if(currNode.right!=null){
queue.offer(currNode.right);
}
//具体存放节点的值的位置
tempList.add(currNode.val);
//与上面代码是等价的
// if(queue.peek().left != null) queue.offer(queue.peek().left);
// if(queue.peek().right != null) queue.offer(queue.peek().right);
// subList.add(queue.poll().val);
}
//插入到第一个位置,相当于栈
//将链表添加到结果集合的过程
res.add(0,tempList);
//将 res 由 List 变成 LinkedList 可以直接使用 addFirst 方法,效果是一样的
}
return res;
}
}
//bfs
class Solution {
public List<List<Integer>> levelOrderBottom(TreeNode root) {
List<List<Integer>> res=new LinkedList<>();
helper(res,root,0);
return res;
}
//为了使程序更符合人的逻辑
private void helper(List<List<Integer>> res,TreeNode root,int height){
if(root==null){
return;
}
if(height>=res.size()){
//在结果集合中新建立的一条链表
res.add(0,new LinkedList<>());
}
//bfs 是从最底层开始向上填充数据的
helper(res,root.left,height+1);
helper(res,root.right,height+1);
//因为前面插入新链表的时候是按照栈的方式来的,
res.get(res.size()-height-1).add(root.val);
}
}
108
//给定一个升序排列的数组,将其转变成平衡的二叉搜索树
//相当于给定的是二叉树的中序遍历,通过中序遍历确定根节点的位置
//有序数组相当于中序遍历的输出结果
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode sortedArrayToBST(int[] nums) {
if(nums.length==0){
return null;
}
TreeNode root=helper(nums,0,nums.length-1);
return root;
}
//后面的两个参数相当于两个指针,用来确定组成子树的节点的左右端点
//这是从底向上构造的
private TreeNode helper(int[] nums,int lo,int hi){
//递归的结束条件,直到叶子节点终止
//返回 null 作为叶子结点
if(lo>hi){
return null;
}
//找到组成子树的这段数组中根节点,也就是数组的中点
int mid=lo+(hi-lo)/2;
//构造出根节点
TreeNode root=new TreeNode(nums[mid]);
root.left=helper(nums,lo,mid-1);
root.right=helper(nums,mid+1,hi);
return root;
}
}
110
//判断一个二叉树是否是平衡二叉树
//两种解决方法,大致是从上向下和从下向上的解决
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
//分析:需要遍历每一个节点,时间复杂度是 O(N^2)
class Solution {
public boolean isBalanced(TreeNode root) {
if(root==null){
return true;
}
//左子树的高度和右子树的高度
int left=helper(root.left);
int right=helper(root.right);
//递归判断当前节点是否是平衡的并且它的左右节点是否也是平衡的
return (Math.abs(left-right)<=1)&&isBalanced(root.left)&&isBalanced(root.right);
}
//辅助方法,返回当前根节点的高度
private int helper(TreeNode root){
if(root==null){
return 0;
}
return 1+Math.max(helper(root.left),helper(root.right));
}
}
//分析:树中的每个节点只需要访问一次。因此,时间复杂度为O(N),优于第一解决方案。
class Solution {
public boolean isBalanced(TreeNode root) {
//基于DFS。我们不是为每个子节点显式调用depth(),而是在DFS递归中返回当前节点的高度
return helper(root)!=-1;
}
//辅助方法显示的判断是否是平衡的,平衡的返回当前节点的高度,不平衡的返回 -1
private int helper(TreeNode root){
if(root==null){
return 0;
}
//左子树节点的高度
int left=helper(root.left);
//判断左子树是否是平衡的二叉树
if(left==-1){
return -1;
}
//右子树节点的高度
int right=helper(root.right);
if(right==-1){
return -1;
}
//判断当前节点构成的树是否是平衡的二叉树
if(Math.abs(left-right)>1){
return -1;
}
//程序执行到这一步说明是平衡的节点构成的树,因此返回该节点的高度
//所以计算节点高度和判断当前节点是否是平衡的树在一段递归程序中执行了,只遍历了一次所有节点,降低了时间复杂度
return 1+Math.max(left,right);
}
}
111
//计算一个给定二叉树的最小深度,也就是根节点到达叶子结点的最短路径所包含的节点数目
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
//这是一种由底向上的方法
class Solution {
public int minDepth(TreeNode root) {
//和之前判断是否是平衡的二叉树 bfs 解决方案有相似的地方
if(root==null){
return 0;
}
//左子树的最小深度
int left=minDepth(root.left);
//右子树的最小深度
int right=minDepth(root.right);
//分为三种情况:右子树和右子树全为空返回的就都是 0 ,返回只是代表当前节点的层数 1;其中有一边的子树为 0 ,返回的就是另一边的最小深度+1;两边全不为 0 ,返回的则是较小的一边的深度+1
return (left==0||right==0)?(1+right+left):(1+Math.min(left,right));
}
}
112
//给定一个二叉树和一个目标值,判断是否含有一条从根节点到叶子结点的路径使得节点的值相加等于目标值
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public boolean hasPathSum(TreeNode root, int sum) {
//什么时候表示没有找到相应的路径
//当 root 节点变成空时,也就是到了叶子结点,sum 仍然没有减少到 0,说明不存在这样的路径
if(root==null){
return false;
}
//什么时候表示找到相应的路径
//必须当前节点就是叶子结点,意味着当前节点的左右子树全是空,并且 sum 值正好减少到 0,则找到相应的路径
//注意是减去当前节点的值之后等于 0
if(root.left==null&&root.right==null&&sum==root.val){
return true;
}
//像这种判断是否含有相加和的问题,在递归中使用的是减法
//只要存在一条这样的路径就行,所以用或操作符
return hasPathSum(root.left,sum-root.val)||hasPathSum(root.right,sum-root.val);
}
}
113
//给定一个二叉树和一个目标值,判断是否含有一条从根节点到叶子结点的路径使得节点的值相加等于目标值,返回由这些路径组成的集合
//和之前做过的找出数组中所有可能的子数组非常相似
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<List<Integer>> pathSum(TreeNode root, int sum) {
List<List<Integer>> res=new LinkedList<>();
pathSum(res,new LinkedList<>(),root,sum);
return res;
}
private void pathSum(List<List<Integer>> res,List<Integer> tempList,TreeNode root,int sum){
//表示不含有这样路径的情况
if(root==null){
return;
}
tempList.add(root.val);
//找到一条可行的路径的时候
if(root.left==null&&root.right==null&&sum==root.val){
res.add(new LinkedList<>(tempList));
//这里用到了回溯
tempList.remove(tempList.size()-1);
//找到了就返回
//所以是两种情况,一种是找到相应的路径,一种是没有找到相应的路径,都得返回
return;
}else{
pathSum(res,tempList,root.left,sum-root.val);
pathSum(res,tempList,root.right,sum-root.val);
}
tempList.remove(tempList.size()-1);
}
}
114
//将一颗二叉树转换成链表
//递归方法从下往上拼接
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public void flatten(TreeNode root) {
if(root==null){
return;
}
//暂时保存当前树节点的左右子树,等同于链表中暂时保存下一节点
TreeNode leftTree=root.left;
TreeNode rightTree=root.right;
//递归的进行左右子树,直到叶子结点
flatten(leftTree);
flatten(rightTree);
//将左子树置为空
root.left=null;
//将之前保存的左子树部分接到右子树
root.right=leftTree;
//保存当前的根节点,防止以后用到
//直接用 root 指针进行移动也是可以的
//一定要从 root 开始移动如果从 leftNode 开始,则会出现空指针异常
//为什么一定要从 root 开始呢???
TreeNode curr=root;
//将指针移动到右子树的最后一个节点
while(curr.right!=null){
curr=curr.right;
}
//将之前保存的右子树拼接到最后
curr.right=rightTree;
}
}
116
//一个满二叉树并且叶子结点都在同一层级上,每个父节点均有两个子节点,并且具有兄弟节点,next 指针指向当前节点的右边的节点
//只能使用固定的额外空间,递归方法的隐式堆栈不算作额外空间
//该题目的目的是为节点增加向右的指针
/*
// Definition for a Node.
class Node {
public int val;
public Node left;
public Node right;
public Node next;
public Node() {}
public Node(int _val,Node _left,Node _right,Node _next) {
val = _val;
left = _left;
right = _right;
next = _next;
}
};
*/
class Solution {
public Node connect(Node root) {
//非空判断不能少,因为第一层循环的空值 left 会出空指针异常
if(root==null){
return root;
}
//一层一层向下遍历,先找到每一层的最左端节点
//需要临时存储每层最左端的节点作为头,因为链表没有向前的指针
//一个保存当前层次的头结点,一个向后移动
Node prev=root;
Node curr=null;
while(prev.left!=null){
//此时是上一层的最左端节点
curr=prev;
//第一次进入循环
//在一层上向右移动直到空节点
while(curr!=null){
//上一层的右子树为这一层的左子树的下一个结点
curr.left.next=curr.right;
//用到了三个节点进行拼接
if(curr.next!=null){
curr.right.next=curr.next.left;
}
//当前层的指针向后移动一位
curr=curr.next;
}
//左子树的指针向左下移动一个位置
prev=prev.left;
}
return root;
}
}
117
//给定一个不是完美的二叉树,也就是不一定每一个父节点均有两个子节点,?但每一层的均有右子树?
/*
// Definition for a Node.
class Node {
public int val;
public Node left;
public Node right;
public Node next;
public Node() {}
public Node(int _val,Node _left,Node _right,Node _next) {
val = _val;
left = _left;
right = _right;
next = _next;
}
};
*/
class Solution {
//根节点的 next 怎么添加 null 节点的
public Node connect(Node root) {
//使用层序遍历的方法
//为了能直接返回根节点,使用虚拟根节点,和之前链表的题目异曲同工
Node dummy=new Node(0);
Node prev=root,curr=dummy;
//判断是否到了叶子结点的后面节点
while(prev!=null){
//判断是否到达了这一层级的最后一个节点
while(prev!=null){
if(prev.left!=null){
curr.next=prev.left;
curr=curr.next;
}
if(prev.right!=null){
curr.next=prev.right;
curr=curr.next;
}
//这一层的左右节点都添加到了新的层级
prev=prev.next;
}
//因为 curr 指针已经将结点添加到 dummy 后面
//相当于将上一层的左子树赋值给 prev 指针
prev=dummy.next;
//重新初始化虚拟根节点和 curr 指针,用于下一层级的遍历
dummy.next=null;
curr=dummy;
}
return root;
}
}
124
//给定一个非空的二叉树,寻找最大路径的总和,一个路径定义为一个从书中任意节点到另一个节点的序列,不一定包含根节点,至少含有一个节点
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
//设置一个类成员变量的最大值,只要辅助方法中对其进行了改变,主方法中的 max 也会赋予新的值
//一般这种求最大值的问题,初始化为整数中的最小值
//也就不需要在辅助函数中返回 max 了,辅助函数调用的是递归,更加方便的编写程序
int max=Integer.MIN_VALUE;
public int maxPathSum(TreeNode root) {
helper(root);
return max;
}
//帮助返回最大的分支,添加当前节点的值到路径上
private int helper(TreeNode root){
if(root==null){
return 0;
}
//依次向下找出左子树和右子树的最大路径
int left=Math.max(helper(root.left),0);
int right=Math.max(helper(root.right),0);
//判断经过当前节点的值是否是最大的值
max=Math.max(max,root.val+left+right);
//返回的是当前节点的值加上左子树或者右子树中较大的路径的值
return root.val+Math.max(left,right);
}
}
129
//设置一个类成员变量存放结果值,初始化可以在这里,也可以在函数中进行
//因为返回的 res 只有一个,并且每一条路径组成的数字的值都需要传入到下一层循环中才行,因此需要一个辅助方法将携带每条路径数字信息的值传入
//辅助函数没有返回值,只是对 res 的值进行每次的添加改变
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
//设置一个类成员变量存放结果值,初始化可以在这里,也可以在函数中进行
int res;
public int sumNumbers(TreeNode root) {
res=0;
//存放一条路径组成的数字的变量
int sum=0;
helper(root,sum);
return res;
}
//一层一层递进的过程中,上一层的值通过 sum 变量传入,不需要返回值
private void helper(TreeNode root,int sum){
if(root==null){
return;
}
//利用参数 sum 携带的上一层的节点值信息,计算当前路径组成的数字大小
//越是上层代表着越高的位次
sum=sum*10+root.val;
//达到叶子结点,可以进行返回了,之后递归计算左右子树的情况
if(root.left==null&&root.right==null){
//将一条路径组成的数字加到总和上面
res+=sum;
return;
}
//分别对左右子树进行递归操作
//遇上一条语句谁在前执行都没有关系
helper(root.left,sum);
helper(root.right,sum);
}
}
144
//给定一个二叉树,返回它的节点值的前序遍历
//分别使用递归和迭代的方法完成
//返回值是一个集合,同时因为有 addAll 方法,所以不用辅助方法通过原方法的递归就能实现
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
//递归的方式,中左右的顺序添加节点就好了
//注意每次均会创建一个新的结合来存储节点元素
List<Integer> res=new ArrayList<>();
//在当前节点不是空的时候才执行,若当前节点为空,则不执行任何代码直接返回
if(root!=null){
res.add(root.val);
res.addAll(preorderTraversal(root.left));
res.addAll(preorderTraversal(root.right));
}
//返回的是集合,所以添加的时候通过 addAll 方法直接添加集合
return res;
}
}
//给定一个二叉树,返回它的节点值的前序遍历
//分别使用递归和迭代的方法完成
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
//通过非递归的方法
//使用栈作为存放中间节点的数据结构
List<Integer> res=new ArrayList<>();
if(root==null){
return res;
}
//使用队列可以吗?
Stack<TreeNode> stack=new Stack<>();
//将根节点压入栈中
stack.push(root);
while(!stack.isEmpty()){
TreeNode currNode=stack.pop();
res.add(currNode.val);
//根据栈的先进后出原则,应该先将右子树压入栈中,才能在之后先出栈
//为什么试验了一下,交换左右子树的入栈顺序后,结果没有区别呢?
if(currNode.right!=null){
stack.push(currNode.right);
}
if(currNode.left!=null){
stack.push(currNode.left);
}
}
return res;
}
}
145
//和前序遍历的代码极其相似,只是将添加节点元素的值放到了递归左右子树的后面而已
//返回一个给定二叉树的后序遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res=new ArrayList<>();
//加上这样的非空判断,可以去掉后面的 if 条件判断
//if(root==null){
// return res;
//}
if(root!=null){
res.addAll(postorderTraversal(root.left));
res.addAll(postorderTraversal(root.right));
res.add(root.val);
}
return res;
}
}
173
//在二叉搜索树上面实现迭代器,通过根节点进行初始化
//注意题目中是二叉搜索树,并且 next 方法返回的是下一个最小的元素,也就是按顺序返回
//二叉搜索树相当于一个有序数组的中序遍历
//想想用什么数据结构来实现
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class BSTIterator {
//因为每个方法中都用了了 stack 而且是对同一个 stack 进行操作,因此应该设置为类方法变量
private Stack<TreeNode> stack=new Stack<>();
//将所有的左子树加入到栈中的方法
private void pushAll(TreeNode root){
//注意什么时候用 if 判断,什么时候用 while
while(root!=null){
stack.push(root);
root=root.left;
}
}
//构造迭代器的过程就相当于将所有左子树入栈的过程
public BSTIterator(TreeNode root) {
pushAll(root);
}
/** @return the next smallest number */
//每次 next 方法用到的只是当前节点右子树的左节点
public int next() {
//从栈中弹出最靠左端的节点
TreeNode currNode=stack.pop();
//考虑只有三个节点的情况下是怎么样进行的遍历,在进行推理
pushAll(currNode.right);
return currNode.val;
}
/** @return whether we have a next smallest number */
//栈为空,说明已经把叶子节点进行了出栈操作
public boolean hasNext() {
return !stack.isEmpty();
}
}
/**
* Your BSTIterator object will be instantiated and called as such:
* BSTIterator obj = new BSTIterator(root);
* int param_1 = obj.next();
* boolean param_2 = obj.hasNext();
*/
199
//给定一个二叉树,想象一下自己站在这棵树的最右边,从上到下的返回你能看到的最右边那一列的节点的值,也就是获得二叉树的右侧视图
//分别使用深度优先和广度优先搜索的方法实现
//时间复杂度和空间复杂度均是 On
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<Integer> rightSideView(TreeNode root) {
//深度优先搜索,我们总是首先访问最右侧的节点,保存每一层的值,一旦获得了最终的层数,我们就能够获得最终的结果数组
//递归通过存放节点的栈间接实现
//左右子树都是同样的这种操作
//使用 map 保存深度与其最右边节点的映射关系
Map<Integer,Integer> rightmostValueAtDepth=new HashMap<>();
//两个同步操作的栈分别保存深度和相应的节点
Stack<TreeNode> nodeStack=new Stack<>();
Stack<Integer> depthStack=new Stack<>();
nodeStack.push(root);
depthStack.push(0);
//最大的深度
int max_depth=Integer.MIN_VALUE;
while(!nodeStack.isEmpty()){
TreeNode node=nodeStack.pop();
int depth=depthStack.pop();
//当前节点不为空时,将判断是否需要进行 map 更新,两个栈的值必须更新
//注意判断的是当前节点是否为空
if(node!=null){
max_depth=Math.max(max_depth,depth);
//map 中的映射是否需要更新需要判断之前是否存入过这一深度的值
if(!rightmostValueAtDepth.containsKey(depth)){
rightmostValueAtDepth.put(depth,node.val);
}
//将左右子树分别入栈,深度栈也进行加 1 操作
nodeStack.push(node.left);
nodeStack.push(node.right);
depthStack.push(depth+1);
depthStack.push(depth+1);
}
}
//经过前面的过程,最右边的节点以及深度均存放在的 map 中
//map 中存放数据并不用考虑先后的顺序
//构造输出的结果
List<Integer> res=new ArrayList<>();
//最大深度就是在这里发挥作用,因为仅仅通过 map 是无法直接知道最大深度的
for(int depth=0;depth<=max_depth;depth++){
res.add(rightmostValueAtDepth.get(depth));
}
return res;
}
}
//广度优先搜索的方法
class Solution {
public List<Integer> rightSideView(TreeNode root) {
//广度优先算法和树的层序遍历非常相似
//和之前的深度优先算法结构上类似,只是将存放节点和深度的数据结构把栈换成队列
//注意创建队列时右边的 new 的对象是什么
Map<Integer,Integer> rightmostValueAtDepth=new HashMap<>();
Queue<TreeNode> nodeQueue=new LinkedList<>();
Queue<Integer> depthQueue=new LinkedList<>();
nodeQueue.add(root);
depthQueue.add(0);
int max_depth=Integer.MIN_VALUE;
while(!nodeQueue.isEmpty()){
TreeNode node=nodeQueue.remove();
int depth=depthQueue.remove();
//对于 max 的赋值也要放在 if 作用域里面,不然会多统计一个 null 节点
if(node!=null){
max_depth=Math.max(max_depth,depth);
rightmostValueAtDepth.put(depth,node.val);
nodeQueue.add(node.left);
nodeQueue.add(node.right);
//这里的深度为什么要添加两次呢?添加两次并不是在 depth 的基础上加 2 而是一个节点的左右节点均在同一层级上,需要在 queue 中保存两个同样层级的信息
depthQueue.add(depth+1);
depthQueue.add(depth+1);
}
}
List<Integer> res=new ArrayList<>();
for(int depth=0;depth<=max_depth;depth++){
res.add(rightmostValueAtDepth.get(depth));
}
return res;
}
}
222
//给定一个完全二叉树,统计其节点数目,节点的添加时从层级的左向右进行的,除了最后一层,其余均是满二叉树
//当前节点构成的树的总结点数等于左右子树的情况加上当前节点
//注意用到了满二叉树的节点总数与树高度的关系
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int countNodes(TreeNode root) {
//使用两个辅助方法分别计算,左右子树的深度,利用深度与节点个数之间的数学关系式计算出总的节点个数
//具体说辅助方法计算的不是节点深度,而是最左边节点的深度,和最右边节点的深度,判断当前节点构成的树是否是满二叉树
int leftmostDepth=leftDepth(root);
int rightmostDepth=rightDepth(root);
//判断是否是满二叉树
if(leftmostDepth==rightmostDepth){
//return (1 << leftDepth) - 1; 使用位操作对代码进行优化
//不能有 2*leftmostDepth-1 进行简单的替换,完全是两回事
//等价的数学表达式为 2的深度次方减 1
return (1 << leftmostDepth) - 1;
}else{
return 1+countNodes(root.left)+countNodes(root.right);
}
}
//最右子树的深度
private int rightDepth(TreeNode root){
int depth=0;
//叶子结点的高度为 1
//使用 while 语句,不到空节点就一直往下进行遍历
//只需要将指针移动到空指针就行,不用其他操作
while(root!=null){
//错误是在这使用了递归,,
root=root.right;
depth++;
}
return depth;
}
private int leftDepth(TreeNode root){
int depth=0;
while(root!=null){
root=root.left;
depth++;
}
return depth;
}
}
226
//将二叉树进行左右镜像转换,也就是反转二叉树
//分别有递归和迭代的方法,发现凡是将递归方法转换成迭代方法的过程,均使用到了其他数据结构代替递归的过程,可能是栈也可能是队列,这要视情况而定
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode invertTree(TreeNode root) {
// if(root!=null){
// TreeNode leftTemp=invertTree(root.left);
// TreeNode rightTemp=invertTree(root.right);
// root.left=rightTemp;
// root.right=leftTemp;
// }
// return root;
//上面是等价形式
if(root==null){
return null;
}
//利用两个临时变量保存转换后的左右子树的信息
//到达叶子结点的商议后相当于把一个有三节点构成的树的左右节点交换的问题
TreeNode leftTemp=invertTree(root.left);
TreeNode rightTemp=invertTree(root.right);
root.left=rightTemp;
root.right=leftTemp;
//交换之后返回其父节点
return root;
}
}
230
//给定一个二叉搜索树,返回其中第 k 小的节点元素,k 的范围大于等于 1 小于等于树的总结点数目
//使用中序遍历的方法,分别又可以递归和迭代实现,
//中序遍历的意思就是在递归遍历左右子树之间进行数据的操作
//提到二叉搜索树的时候我们就要考虑中序遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
//使用类的全局变量,保存结果和计数变量
//一旦遇到让求最小或者第几小的情况,都可以使用整数中的最小值对结果变量进行初始化
private int res=Integer.MIN_VALUE;
private int count=0;
public int kthSmallest(TreeNode root, int k) {
inorderTraversal(root,k);
//如果不使用类全局标量,在这一步将很难取得 res 的结果值
return res;
}
//中序遍历的方法是没有返回值的,并且遍历之后将形成一个升序排列的数组
//只有在树是二叉搜索树的条件下这种情况才成立
private void inorderTraversal(TreeNode root,int k){
if(root==null){
return;
}
inorderTraversal(root.left,k);
//为什么在这个地方计数变量加 1?
//只要在这一层的递归语句的作用域内,都代表当前遍历的是一个节点,将计数变量的值加 1 就好了
count++;
if(k==count){
res=root.val;
}
inorderTraversal(root.right,k);
}
}
//迭代的解决方法,使用栈代替递归的过程
//未懂
public int kthSmallest(TreeNode root, int k) {
Stack<TreeNode> stack = new Stack<TreeNode>();
TreeNode p = root;
int count = 0;
while(!stack.isEmpty() || p != null) {
if(p != null) {
stack.push(p); // Just like recursion
p = p.left;
} else {
TreeNode node = stack.pop();
if(++count == k) return node.val;
p = node.right;
}
}
return Integer.MIN_VALUE;
}
235
//给定一个二叉搜索树,找到给定的俩个节点的值代表的节点的最小公共节点,节点的后代也包括它自身,二叉搜索树中没有相同的元素值
//分别有递归和迭代的方法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
//使用递归的方法,因为是二叉搜索树,在判断条件中应该会出现对于节点左右和当前节点值的比较
//分为三种情况,两个输入均在当前节点的左边,都在当前节点的右边
//第三种情况是等于其中一个等于当前节点或者两个输入在当前节点的两侧,代表当前节点即为要找的节点
//要找的节点再当前节点的右边
if(p.val>root.val&&q.val>root.val){
//每个作用域内总是要返回值的,以便构成递归
return lowestCommonAncestor(root.right,p,q);
}else if(p.val<root.val&&q.val<root.val){
return lowestCommonAncestor(root.left,p,q);
}else{
return root;
}
}
}
//迭代就是通过递归实现
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
while(root!=null){
if(p.val>root.val&&q.val>root.val){
root=root.right;
}else if(p.val<root.val&&q.val<root.val){
root=root.left;
}else{
return root;
}
}
return null;
}
}
236
//这次给定的树不是二叉搜索树,而是一棵普通的二叉树,找出给定的两个节点的最小公共父节点
//分为递归和迭代的方法,迭代又分为设置父指针的迭代不不含有父指针的迭代
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
//定义一个类全局变量使得两个方法均能使用
private TreeNode res;
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
//首先基于深度优先的遍历,通过标志符号判断子树中是否含有给定的节点,判断符号两个都是 true 的时候,说明这个节点就是我们想找的节点
traverseTree(root,p,q);
return res;
}
//这个返回值是在递归中使用,而不是在主方法中使用,主方法中利用的是在给 res 赋值的时候
private boolean traverseTree(TreeNode root,TreeNode p,TreeNode q){
if(root==null){
return false;
}
//对整棵树进行了遍历,所以最后的 res 值就是我们想要找的节点
//如果左递归中含有目标节点中的一个,返回 1,否则 0,右递归同理
int left=traverseTree(root.left,p,q)?1:0;
int right=traverseTree(root.right,p,q)?1:0;
//判断是否给出的节点就是父节点本身
int mid=(root==p||root==q)?1:0;
//关键是对 1 和 0 的标志的利用,怎么通过简单的标志位反映是否含有相应的节点的信息
if(mid+left+right==2){
res=root;
}
//如果是 0 说明没有两个为 1 的标识符
//为什么相加结果为 1 的情况也满足呢?
return (mid+left+right!=0);
}
}
257
//给定一个二叉树,返回它的所有从跟到叶子结点的路径
//使用递归的方法,考虑是否需要辅助函数进行递归,要是能在一个函数中进行递归那是最好不过的了
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<String> binaryTreePaths(TreeNode root) {
//到达空节点时怎么处理
List<String> paths=new LinkedList<>();
if(root==null){
return paths;
}
//到达叶子结点的时候要怎么做
if(root.left==null&&root.right==null){
paths.add(root.val+"");
return paths;
}
//最终到达的左子树的叶子结点有多少个,就有多少个涉及左子树的路径
//递归在以集合的形式进行,和之前的 addAll 方法一样的效果
for(String path:binaryTreePaths(root.left)){
paths.add(root.val+"->"+path);
}
//右子树的情况和左子树一样
for(String path:binaryTreePaths(root.right)){
paths.add(root.val+"->"+path);
}
return paths;
}
}
297
//序列化和反序列化二叉树:设计一种算法可以将二叉树进行序列化和反序列化,使用什么方法进行没有特殊要求,只需要能够成功的进行转换就行
//不能使用全局变量或者静态变量来存放状态,设计的序列化算法应该是无状态的
//将二叉树转换成字符串
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Codec {
//使用类变量存放分隔符
private static final String spliter=",";
//使用类变量存放代表空值的X
private static final String NN="X";
// Encodes a tree to a single string.
public String serialize(TreeNode root) {
StringBuilder sb=new StringBuilder();
buildString(root,sb);
return sb.toString();
}
//进行序列化时的辅助方法
private void buildString(TreeNode node,StringBuilder sb){
if(node==null){
sb.append(NN).append(spliter);
}else{
sb.append(node.val).append(spliter);
buildString(node.left,sb);
buildString(node.right,sb);
}
}
// Decodes your encoded data to tree.
public TreeNode deserialize(String data) {
//使用队列来存放节点元素
Deque<String> nodes=new LinkedList<>();
nodes.addAll(Arrays.asList(data.split(spliter)));
return buildTree(nodes);
}
//反序列化的辅助函数
//使用了回溯法
private TreeNode buildTree(Deque<String> nodes){
String val=nodes.remove();
if(val.equals(NN)){
return null;
}else{
//该方法表示字符串指定的整数值,和parseInt(java.lang.String)方法返回一个整数值类似
TreeNode node=new TreeNode(Integer.valueOf(val));
node.left=buildTree(nodes);
node.right=buildTree(nodes);
return node;
}
}
}
// Your Codec object will be instantiated and called as such:
// Codec codec = new Codec();
// codec.deserialize(codec.serialize(root));
四、动态规划
005
//给定一个字符串,找出其中的最长回文数
//使用将字符串倒置比较公共子串的方法是不正确的,因为当字符串变长时,难免出现巧合,使得公共子串不是回文字符串
//使用动态规划的方法
//一定要先弄清 dp[i][j] 代表的是从 i 到 j 位置处的子字符串是否是回文字符串
class Solution {
public String longestPalindrome(String s) {
//防止输入的是 ""
if(s.length()==0){
return s;
}
//动态规划的二维数组代表从 i 到 j 索引是否是一个回文字符串,
//注意区分数组,字符串,集合的求长度方法
int n=s.length();
boolean[][] dp=new boolean[n][n];
//返回的最长的回文子串
String res=null;
//为什么从最后一个字符开始遍历
for(int i=n-1;i>=0;i--){
for(int j=i;j<n;j++){
//是一个回文字符串的条件是前后向内移动一个字符的位置仍然是回文,并且前后的当前字符相等
//当前后比较的字符位置相差0,1,2时,只要当前字符相等,那就是一个回文字符串
//只要前面的条件满足了,只要位置相差在3以内就都是回文字符串
dp[i][j]=(s.charAt(i)==s.charAt(j))&&(j-i<3||dp[i+1][j-1]);
//如果找到一个回文字符串,比较与存放在结果变量中的字符串长度,如果比其长,则替换
//如果只是第一次查找,res 是 null 则直接替换
//在这一行报空指针异常是因为没把res=null考虑进来
if(dp[i][j]&&(res==null||j-i+1>res.length())){
//取自字符串的时候,右边索引不包含在内
res=s.substring(i,j+1);
}
}
}
return res;
}
}
010
//官方给的这种答案没有看懂
//实现正则表达式中 . 和 * 的功能,功能分别是匹配单字符和0或者多次的同一个字符匹配,匹配的是整个字符串而不是部分
//给定一个字符串和一个给定的模式,判断二者是否符合正则表达式
//方法分为两种,递归和动态规划,动态规划又分为自顶向下和自底向上的实现
class Solution {
//s 代表文本,p 代表模式
public boolean isMatch(String s, String p) {
//使用动态规划,自底向上的方法。因为这个问题有最佳子结构?所以缓存中间结果是很自然的,dp[i][j]代表文本 i 是否与模式 j 相匹配
//也就是从最后一个字符开始进行处理
int textLen=s.length();
int pattLen=p.length();
boolean[][] dp=new boolean[textLen+1][pattLen+1];
//存放最终结果的位置是 dp 的第一行第一列个元素
dp[textLen][pattLen]=true;
for(int i=textLen;i>=0;i--){
for(int j=pattLen-1;j>=0;j--){
//对处理的第一个字符进行比较看是否匹配
//首先索引没超过文本的长度,而文本与模式匹配的字符情况有两种,一种是相等,一种是模式的当前字符是 .
boolean first_match=(i<textLen&&((p.charAt(j)==s.charAt(i))||p.charAt(j)=='.'));
if(j+1<pattLen&&p.charAt(j+1)=='*'){
dp[i][j]=dp[i][j+2]||first_match&&dp[i+1][j];
}else{
dp[i][j]=first_match&&dp[i+1][j+1];
}
}
}
return dp[0][0];
}
}
// 1, If p.charAt(j) == s.charAt(i) : dp[i][j] = dp[i-1][j-1];
// 2, If p.charAt(j) == '.' : dp[i][j] = dp[i-1][j-1];
// 3, If p.charAt(j) == '*':
// here are two sub conditions:
// 1 if p.charAt(j-1) != s.charAt(i) : dp[i][j] = dp[i][j-2] //in this case, a* only counts as empty
// 2 if p.charAt(i-1) == s.charAt(i) or p.charAt(i-1) == '.':
// dp[i][j] = dp[i-1][j] //in this case, a* counts as multiple a
// or dp[i][j] = dp[i][j-1] // in this case, a* counts as single a
// or dp[i][j] = dp[i][j-2] // in this case, a* counts as empty
class Solution {
//s 代表文本,p 代表模式
public boolean isMatch(String s, String p) {
//两者中有一个是空字符串,不包括全是空字符串的情况
if(s==null||p==null){
return false;
}
int sl=s.length();
int pl=p.length();
boolean[][] dp=new boolean[sl+1][pl+1];
//这里有什么作用,为什么要这样写
dp[0][0]=true;
//dp[i][j] 代表文本第i个字符,模式第j个字符之前的子字符串都是匹配的***
//创建的 boolean 默认应该是 false 吧
for(int i=0;i<pl;i++){
if(p.charAt(i)=='*'&&dp[0][i-1]){
dp[0][i+1]=true;
}
}
for(int i=0;i<sl;i++){
for(int j=0;j<pl;j++){
if(p.charAt(j)=='.'){
//前面的匹配结果会对后面的匹配产生影响
dp[i+1][j+1]=dp[i][j];
}
if(p.charAt(j)==s.charAt(i)){
dp[i+1][j+1]=dp[i][j];
}
if(p.charAt(j)=='*'){
if(p.charAt(j-1)!=s.charAt(i)&&p.charAt(j-1)!='.'){
dp[i+1][j+1]=dp[i+1][j-1];
}else{
dp[i+1][j+1]=(dp[i+1][j]||dp[i][j+1]||dp[i+1][j-1]);
}
}
}
}
return dp[sl][pl];
}
}
032
//找到满足()组成的有效最长子串,算法应该返回其长度
//两种解决方法,一种是利用栈的后进先出,一种是使用动态规划
class Solution {
public int longestValidParentheses(String s) {
int res=0;
Stack<Integer> stack=new Stack<>();
//如果一个这样的括号都没有,则返回 -1
stack.push(-1);
//对给出的字符串进行遍历
for(int i=0;i<s.length();i++){
//如果遇到左半括号,将括号的索引入栈
if(s.charAt(i)=='('){
stack.push(i);
//如果遇到右半括号,则将栈中元素出栈,之前没有左括号入栈的话出栈的将是 -1
}else{
stack.pop();
//如果之前没有左括号入栈,则将现在右括号的索引入栈
if(stack.isEmpty()){
stack.push(i);
//如果还有元素,可能是 -1 也可能是第一个左括号的索引
}else{
//更新结果变量,如果前两个字符就是满足条件的括号,1-(-1)=2
res=Math.max(res,i-stack.peek());
}
}
}
return res;
}
}
//使用动态规划的方法
class Solution {
public int longestValidParentheses(String s) {
//动态规划, We make use of a \text{dp}dp array where iith element of \text{dp}dp represents the length of the longest valid substring ending at iith index. 遍历到 i 索引为止最长的符合要求的子字符串长度
int res=0;
int dp[]=new int[s.length()];
//从 1 开始,因为一个符号不可能组成一组括号
for(int i=1;i<s.length();i++){
if(s.charAt(i)==')'){
//这个 if 作用域判断的是左右括号紧挨着的情况
if(s.charAt(i-1)=='('){
//把长度存放到 dp 相应的索引位置,方便以后的判断进行使用
//索引为 1 时不可能组成一对括号,向前数两个索引位置的长度加上当前一堆括号的长度
dp[i]=(i>=2?dp[i-2]:0)+2;
//i-dp[i-1]-1 代表的是出去前面紧挨着的括号的长度,找到再前面的一个符号的位置
}else if(i-dp[i-1]>0&&s.charAt(i-dp[i-1]-1)=='('){
//
dp[i]=dp[i-1]+((i-dp[i-1])>=2?dp[i-dp[i-1]-2]:0)+2;
}
res=Math.max(res,dp[i]);
}
}
return res;
}
}
044
//进行正则表达式的'?' and '*'匹配判断
//?代表任何单个字符
class Solution {
public boolean isMatch(String s, String p) {
int sl=s.length();
int pl=p.length();
boolean[][] dp=new boolean[sl+1][pl+1];
//dp 网格从后向前遍历
dp[sl][pl]=true;
for(int i=pl-1;i>=0;i--){
if(p.charAt(i)!='*'){
break;
}else{
dp[sl][i]=true;
}
}
for(int i=sl-1;i>=0;i--){
for(int j=pl-1;j>=0;j--){
if(s.charAt(i)==p.charAt(j)||p.charAt(j)=='?'){
dp[i][j]=dp[i+1][j+1];
}else if(p.charAt(j)=='*'){
dp[i][j]=dp[i+1][j]||dp[i][j+1];
}else{
dp[i][j]=false;
}
}
}
return dp[0][0];
}
}
070
//爬楼梯问题,每次只能爬1步或者2步,有几种途径可以爬到指定的数字高度
//这也是一个斐波那契数的问题
//因为通过观察可以发现这个问题可以分解成子问题
//dp[i]=dp[i−1]+dp[i−2]
class Solution {
public int climbStairs(int n) {
//因为从上一步跳到最后的结果位置,有两种可能,一是从上次一步跳过来,一种是从上次一次跳两步跳过来
//没有这个判断会出现数组越界异常
if(n==1){
return 1;
}
int[] dp=new int[n+1];
dp[1]=1;
dp[2]=2;
//所谓动态规划,就是根据公式对 dp 进行不同的操作
for(int i=3;i<=n;i++){
dp[i]=dp[i-1]+dp[i-2];
}
return dp[n];
}
}
072***
//给定两个单词,从前一个单词转换到后一个词所用的最小步骤,每步只能进行插入,删除,或者替换一个字符的操作
//使用 dp[i][j] 代表从 word1[0,i) and word2[0, j) 的最小距离
// Then compare the last character of word1[0,i) and word2[0,j), which are c and d respectively (c == word1[i-1], d == word2[j-1]):
// if c == d, then : f[i][j] = f[i-1][j-1]
// Otherwise we can use three operations to convert word1 to word2:
// (a) if we replaced c with d: f[i][j] = f[i-1][j-1] + 1;
// (b) if we added d after c: f[i][j] = f[i][j-1] + 1;
// (c) if we deleted c: f[i][j] = f[i-1][j] + 1;
class Solution {
public int minDistance(String word1, String word2) {
int l1=word1.length();
int l2=word2.length();
int[][] dp=new int[l1+1][l2+1];
// Base Case: f(0, k) = f(k, 0) = k
for(int i=0;i<=l1;i++){
dp[i][0]=i;
}
for(int i=1;i<=l2;i++){
dp[0][i]=i;
}
//对 dp 进行记忆赋值
for(int i=0;i<l1;i++){
for(int j=0;j<l2;j++){
//相应位置处的字符相同时,和之前进行操作的步骤相同
if(word1.charAt(i)==word2.charAt(j)){
dp[i+1][j+1]=dp[i][j];
}else{
//需要进行代替时的步骤
int a=dp[i][j];
//需要删除字符时的步骤
int b=dp[i][j+1];
//需要插入字符时的步骤
int c=dp[i+1][j];
//将三者中的最小值给下一个 dp 元素
dp[i+1][j+1]=a<b?(a<c?a:c):(b<c?b:c);
dp[i+1][j+1]++;
}
}
}
return dp[l1][l2];
}
}
091
//解码方式:26 个字母由1-26进行编码,给定一个数字,判断可能由几种解码方式,比如26可能代表的是Z,也可能是BF两个字母
class Solution {
public int numDecodings(String s) {
int n=s.length();
if(n==0){
return 0;
}
int[] dp=new int[n+1];
//确定基本情况的过程
//最后一个数字在后面的数字默认设置为一种解码方式
dp[n]=1;
//n-1 代表的是最后一个位置的数字,当其为 0 时没有解码方式,为 1 时有一种解码方式
dp[n-1]=s.charAt(n-1)!='0'?1:0;
//制作记忆字典的过程
for(int i=n-2;i>=0;i--){
//0 需要单独考虑,当在字符串中间遇到 0 时,进入下一次循环
if(s.charAt(i)=='0'){
continue;
}else{
//从数字的最后一个位置开始进行记录
//判断两个字符位置内组成的数字是否大于26
//因为输入的是字符串,需要将字符串转化成数字进行比较
dp[i]=(Integer.parseInt(s.substring(i,i+2))<=26)?dp[i+1]+dp[i+2]:dp[i+1];
}
}
return dp[0];
}
}
097
//交错字符串:判断给定的三个字符串中,第三个字符串是否是前两个字符串中的字符交错组成
class Solution {
public boolean isInterleave(String s1, String s2, String s3) {
int l1=s1.length();
int l2=s2.length();
int l3=s3.length();
//当前两个字符串的长度和不等于第三个字符串的长度时,直接返回 false
if(l3!=l1+l2){
return false;
}
boolean[][] dp=new boolean[l1+1][l2+1];
for(int i=0;i<=l1;i++){
for(int j=0;j<=l2;j++){
if(i==0&&j==0){
dp[i][j]=true;
}else if(i==0){
dp[i][j]=dp[i][j-1]&&s2.charAt(j-1)==s3.charAt(i+j-1);
}else if(j==0){
dp[i][j]=dp[i-1][j]&&s1.charAt(i-1)==s3.charAt(i+j-1);
}else{
dp[i][j]=(dp[i-1][j]&&s1.charAt(i-1)==s3.charAt(i+j-1))||(dp[i][j-1]&&s2.charAt(j-1)==s3.charAt(i+j-1));
}
}
}
return dp[l1][l2];
}
}
115
//给定两个字符串,判断从其中一个字符串选出一段序列后等于另一个字符串的数量
// The idea is the following:
// we will build an array mem where mem[i+1][j+1] means that S[0..j] contains T[0..i] that many times as distinct subsequences. Therefor the result will be mem[T.length()][S.length()].
// we can build this array rows-by-rows:
// the first row must be filled with 1. That's because the empty string is a subsequence of any string but only 1 time. So mem[0][j] = 1 for every j. So with this we not only make our lives easier, but we also return correct value if T is an empty string.
// the first column of every rows except the first must be 0. This is because an empty string cannot contain a non-empty string as a substring -- the very first item of the array: mem[0][0] = 1, because an empty string contains the empty string 1 time.
// So the matrix looks like this:
// S 0123....j
// T +----------+
// |1111111111|
// 0 |0 |
// 1 |0 |
// 2 |0 |
// . |0 |
// . |0 |
// i |0 |
// From here we can easily fill the whole grid: for each (x, y), we check if S[x] == T[y] we add the previous item and the previous item in the previous row, otherwise we copy the previous item in the same row. The reason is simple:
// if the current character in S doesn't equal to current character T, then we have the same number of distinct subsequences as we had without the new character.
// if the current character in S equal to the current character T, then the distinct number of subsequences: the number we had before plus the distinct number of subsequences we had with less longer T and less longer S.
// An example:
// S: [acdabefbc] and T: [ab]
// first we check with a:
// * *
// S = [acdabefbc]
// mem[1] = [0111222222]
// then we check with ab:
// * * ]
// S = [acdabefbc]
// mem[1] = [0111222222]
// mem[2] = [0000022244]
// And the result is 4, as the distinct subsequences are:
// S = [a b ]
// S = [a b ]
// S = [ ab ]
// S = [ a b ]
// It was really hard to find the reason. Hope the following makes sense.
// lets see if T[i] != S[j]
// then we stil have to find the entire T in a subset of S[j-1] hence it will be listed as
// dp[i,j] = dp[i,j-1] // i.e. ignore the jth character in S.
// now if T[i] == S[j] it means we have a choice, either we take the jth character to find the entire T or we do not take the jth character to find the entire T.
// If we take the jth character - that means now we have to find a solution to T[i-1] (because T[i] == S[j]))
// If we do not take the jth character - that means now we have to find a solution to T[i] from S[j-1] (not taking the jth character).
// The total number of permutations would be = permutations with considering the jth character + permutations without considering the jth character.
// Hence in this case dp[i,j] = dp[i-1,j-1] + dp[i,j-1].
// Hope that make sense.
class Solution {
public int numDistinct(String s, String t) {
int[][] dp=new int[t.length()+1][s.length()+1];
for(int j=0;j<=s.length();j++){
dp[0][j]=1;
}
for(int i=0;i<t.length();i++){
for(int j=0;j<s.length();j++){
if(t.charAt(i)==s.charAt(j)){
dp[i+1][j+1]=dp[i][j]+dp[i+1][j];
}else{
dp[i+1][j+1]=dp[i+1][j];
}
}
}
return dp[t.length()][s.length()];
}
}
132
//回文切分:给定一个字符串,使得对该字符串进行几次分割后,每个子字符串都是回文字符串,求进行分割的最小次数并返回
//先画出网格根据一个一般的字符串总结出规律,在列出伪代码,最后根据伪代码写出相应的可运行的代码
// This can be solved by two points:
// cut[i] is the minimum of cut[j - 1] + 1 (j <= i), if [j, i] is palindrome.
// If [j, i] is palindrome, [j + 1, i - 1] is palindrome, and c[j] == c[i].
// The 2nd point reminds us of using dp (caching).
// a b a | c c
// j i
// j-1 | [j, i] is palindrome
// cut(j-1) + 1
class Solution {
public int minCut(String s) {
int n=s.length();
//从 0 到 i 位置处代表需要切割机次才能完成目标
int[] cut=new int[n];
//从 j 到 i 位置的子字符串是否是回文的
boolean[][] dp=new boolean[n][n];
for(int i=0;i<n;i++){
//最小的切分次数变量,初始化为切分成单个字符
int min=i;
for(int j=0;j<=i;j++){
//从j+1到i-1不包含字符
if(s.charAt(j)==s.charAt(i)&&(j+1>i-1||dp[j+1][i-1])){
dp[j][i]=true;
min=j==0?0:Math.min(min,cut[j-1]+1);
}
}
cut[i]=min;
}
return cut[n-1];
}
}
139
//单词分割:给定一个非空字符串和一个由子字符串组成的非空字符串列表,判断该字符串能否被分割成列表中的单词,前提是列表中的字符串可以多次使用,但是列表中不能出现重复字符串
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
boolean[] dp=new boolean[s.length()+1];
dp[0]=true;
for(int i=1;i<=s.length();i++){
for(int j=0;j<i;j++){
if(dp[j]&&wordDict.contains(s.substring(j,i))){
dp[i]=true;
//不知道有什么用处
break;
}
}
}
return dp[s.length()];
}
}
140
//单词分割:返回所有可能的组成字符串的子字符串集合,前一题只是判断是否能分割,这一题需要返回分割成的
//一种带记忆的递归解决方法
class Solution {
//通过一个 HashMap 建立缓存,缓存已经遍历过的子字符串
private final Map<String,List<String>> cache=new HashMap<>();
public List<String> wordBreak(String s, List<String> wordDict) {
if(cache.containsKey(s)){
return cache.get(s);
}
List<String> res=new LinkedList<>();
if(wordDict.contains(s)){
res.add(s);
}
for(int i=1;i<s.length();i++){
String left=s.substring(0,i),right=s.substring(i);
if(wordDict.contains(left)&&containsSuffix(right,wordDict)){
for(String str:wordBreak(right,wordDict)){
res.add(left+" "+str);
}
}
}
cache.put(s,res);
return res;
}
//通过对后缀的预判断直接排除后缀不同的字符串
private boolean containsSuffix(String str,List<String> wordDict){
for(int i=0;i<str.length();i++){
if(wordDict.contains(str.substring(i))){
return true;
}
}
return false;
}
}
174
//地牢游戏:九宫格代表不同的房间,需要骑士穿过房间从左上角到达右下角,求骑士需要的最小的生命值才能救到公主
class Solution {
public int calculateMinimumHP(int[][] dungeon) {
if(dungeon==null||dungeon.length==0||dungeon[0].length==0){
return 0;
}
//行数和列数
int m=dungeon.length;
int n=dungeon[0].length;
int[][] health=new int[m][n];
health[m-1][n-1]=Math.max(1-dungeon[m-1][n-1],1);
for(int i=m-2;i>=0;i--){
health[i][n-1]=Math.max(health[i+1][n-1]-dungeon[i][n-1],1);
}
for(int j=n-2;j>=0;j--){
health[m-1][j]=Math.max(health[m-1][j+1]-dungeon[m-1][j],1);
}
for(int i=m-2;i>=0;i--){
for(int j=n-2;j>=0;j--){
int down=Math.max(health[i+1][j]-dungeon[i][j],1);
int right=Math.max(health[i][j+1]-dungeon[i][j],1);
health[i][j]=Math.min(right,down);
}
}
return health[0][0];
}
}
188
//买卖股票的最佳时机:找出可以获取的最大利润,最多可以完成 k 笔交易
class Solution {
public int maxProfit(int k, int[] prices) {
int len=prices.length;
if(k>=len/2){
return quickSolve(prices);
}
int[][] t=new int[k+1][len];
for(int i=1;i<=k;i++){
int tempMax=-prices[0];
for(int j=1;j<len;j++){
t[i][j]=Math.max(t[i][j-1],prices[j]+tempMax);
tempMax=Math.max(tempMax,t[i-1][j-1]-prices[j]);
}
}
return t[k][len-1];
}
//处理角落问题的辅助方法
private int quickSolve(int[] prices){
int len=prices.length,profit=0;
for(int i=1;i<len;i++){
if(prices[i]>prices[i-1]){
profit+=prices[i]-prices[i-1];
}
}
return profit;
}
}
198
//房屋抢劫:给定一个数组,数组中的值代表房间中金钱的数目,不能抢劫连续的临近的房屋,否则就会被警察发现,求能够抢劫到的最大金额
//算法不太可能开始就给出一个完美的解决方案,除非是之前解决过的问题,需要提出一个基本可能的算法后,在实际中逐渐的改进算法的性能
//重点知识:解决算法问题的一般方法:
// 1、找到递归关系
// 2、自顶向下的进行递归
// 3、带有记忆的自顶向下的递归也是一种 dp 方法
// 4、带有记忆的自底向上的迭代
// 5、具有多个变量的自底向上的迭代
//抢劫时候,面临两种选择,抢目前房间和不抢目前房间 rob(i) = Math.max( rob(i - 2) + currentHouseValue, rob(i - 1) )
//特别好的答案解释:https://leetcode.com/problems/house-robber/discuss/156523/From-good-to-great.-How-to-approach-most-of-DP-problems.
//Recursive (top-down)
class Solution {
public int rob(int[] nums) {
//从后向前开始遍历整个数组
//自顶下下就体现在这里
return rob(nums,nums.length-1);
}
private int rob(int[] nums,int i){
if(i<0){
return 0;
}
return Math.max(rob(nums,i-2)+nums[i],rob(nums,i-1));
}
}
//Recursive + memo (top-down)
class Solution {
//定义一个存放记忆的数组变量
int[] memo;
public int rob(int[] nums) {
memo=new int[nums.length+1];
//初始化时数组,将指定元素填充满整个数组
Arrays.fill(memo,-1);
return rob(nums,nums.length-1);
}
private int rob(int[] nums,int i){
if(i<0){
return 0;
}
//memo 中的值大于 0 时说明之前已经计算过当前索引的总和直接返回就好
if(memo[i]>=0){
return memo[i];
}
int res=Math.max(nums[i]+rob(nums,i-2),rob(nums,i-1));
memo[i]=res;
return res;
}
}
//Iterative + memo (bottom-up)
class Solution {
public int rob(int[] nums) {
//迭代的带记忆方法,也就是dp
if(nums.length==0){
return 0;
}
//这里的 memo 就是相当于 dp 数组
int[] memo=new int[nums.length+1];
//为什么第一个元素初始化为 0
memo[0]=0;
memo[1]=nums[0];
for(int i=1;i<nums.length;i++){
//通过一个变量来保存当前的索引位置处的值
int val=nums[i];
memo[i+1]=Math.max(memo[i],memo[i-1]+val);
}
return memo[nums.length];
}
}
//Iterative + 2 variables (bottom-up)
class Solution {
public int rob(int[] nums) {
if(nums.length==0){
return 0;
}
//再上一步中我们只是用到了memo[i] and memo[i-1];两个值,可以设置两个变量来保存它们
//代表的是nums[i]
int prev1=0;
//代表的是nums[i-1]
int prev2=0;
for(int num:nums){
//怎么从上一步的代码改成这种由变量表示的形式是问题解决的关键
int temp=prev1;
prev1=Math.max(prev2+num,prev1);
prev2=temp;
}
return prev1;
}
}
213
//抢劫房屋:和之前的不同是所有的
class Solution {
public int rob(int[] nums) {
if(nums.length==1){
return nums[0];
}
return Math.max(rob(nums,0,nums.length-2),rob(nums,1,nums.length-1));
}
//掠夺指定范围内的房屋的辅助方法
private int rob(int[] nums,int lo,int hi){
int prev1=0;
int prev2=0;
for(int i=lo;i<=hi;i++){
int tempPrev1=prev1;
int tempPrev2=prev2;
prev1=tempPrev2+nums[i];
prev2=Math.max(tempPrev1,tempPrev2);
}
return Math.max(prev1,prev2);
}
}
221
//给定一个只有0和1组成的二维矩阵,返回其中只包含1的正方形的面积
//使用动态规划的方法,
// 1、首先将整个dp矩阵初始化为全0
// 2、dp[i][j]代表右下角是(i,j)的最大正方形的边长
// 3、从(0,0)索引处开始,没找到一个1元素就更新dp当前的值 dp(i,j)=min(dp(i−1,j),dp(i−1,j−1),dp(i,j−1))+1
// 4、这样只要遍历一次二维矩阵就能获得符合要求的最大面积
class Solution {
public int maximalSquare(char[][] matrix) {
if(matrix==null||matrix.length==0||matrix[0].length==0){
return 0;
}
int m=matrix.length,n=matrix[0].length;
int[][] dp=new int[m+1][n+1];
//最大满足要求的子矩阵的边长
int res=0;
for(int i=1;i<=m;i++){
for(int j=1;j<=n;j++){
//为什么选择(i-1,j-1)这个坐标进行比价呢?
if(matrix[i-1][j-1]=='1'){
dp[i][j]=Math.min(Math.min(dp[i][j-1],dp[i-1][j]),dp[i-1][j-1])+1;
res=Math.max(res,dp[i][j]);
}
}
}
return res*res;
}
}
264
//丑数扩展题:给定一个索引,找出位于指定位置的丑数并返回其值,一个丑数的指数因子只能是2,3,5
//通过不停的除以这些指数因子,最后余数为1的就是丑数了
// (1) 1×2, 2×2, 3×2, 4×2, 5×2, …
// (2) 1×3, 2×3, 3×3, 4×3, 5×3, …
// (3) 1×5, 2×5, 3×5, 4×5, 5×5, …
// 采用类似于合并的方法,每次从三个序列中选择较小的那个组曾一个新的序列,然后向后移动一位
class Solution {
public int nthUglyNumber(int n) {
//实际给的索引是从1开始数起的,而数组中的索引是从0开始数起的
int[] dp=new int[n];
dp[0]=1;
int indexOf2=0,indexOf3=0,indexOf5=0;
int factorOf2=2,factorOf3=3,factorOf5=5;
for(int i=1;i<n;i++){
int min=Math.min(Math.min(factorOf2,factorOf3),factorOf5);
dp[i]=min;
if(factorOf2==min){
factorOf2=2*dp[++indexOf2];
}
if(factorOf3==min){
factorOf3=3*dp[++indexOf3];
}
if(factorOf5==min){
factorOf5=5*dp[++indexOf5];
}
}
return dp[n-1];
}
}
279
//最好的正方数:给定一个正整数,找出总和为这个数的由最正方数组成的最少的正方数个数
// dp[0] = 0
// dp[1] = dp[0]+1 = 1
// dp[2] = dp[1]+1 = 2
// dp[3] = dp[2]+1 = 3
// dp[4] = Min{ dp[4-1*1]+1, dp[4-2*2]+1 }
// = Min{ dp[3]+1, dp[0]+1 }
// = 1
// dp[5] = Min{ dp[5-1*1]+1, dp[5-2*2]+1 }
// = Min{ dp[4]+1, dp[1]+1 }
// = 2
// .
// .
// .
// dp[13] = Min{ dp[13-1*1]+1, dp[13-2*2]+1, dp[13-3*3]+1 }
// = Min{ dp[12]+1, dp[9]+1, dp[4]+1 }
// = 2
// .
// .
// .
// dp[n] = Min{ dp[n - i*i] + 1 }, n - i*i >=0 && i >= 1
class Solution {
public int numSquares(int n) {
int[] dp=new int[n+1];
//将dp数组用最大的整数填充
Arrays.fill(dp,Integer.MAX_VALUE);
dp[0]=0;
for(int i=1;i<=n;i++){
int min=Integer.MAX_VALUE;
int j=1;
while(i-j*j>=0){
min=Math.min(min,dp[i-j*j]+1);
j++;
}
dp[i]=min;
}
return dp[n];
}
}
300
//最长的递增的子序列:时间复杂度要求On2或者nlogn,可能含有多个自小长度的子序列,但是只要返回其长度就好
class Solution {
public int lengthOfLIS(int[] nums) {
if(nums.length==0){
return 0;
}
//构造dp数组并初始化第一个元素
int[] dp=new int[nums.length];
dp[0]=1;
//存放结果的变量,如果数组单调递,则结果为1
int maxans=1;
//只有在判断条件中用到了nums数组,其他操作都是对dp数组进行的
for(int i=1;i<nums.length;i++)