日常学习记录随笔-seata
我们知道所有的事务都要满足ACID的原则,也就是原子性 一致性 隔离性 持久性
在单体架构中服务访问db.基于数据库本身的特性就能够实现acid
微服务的架构比较复杂 可能一个业务要跨越多个服务
每个服务又会有自己的db库 再靠数据库本身的特性 还能保证acid么
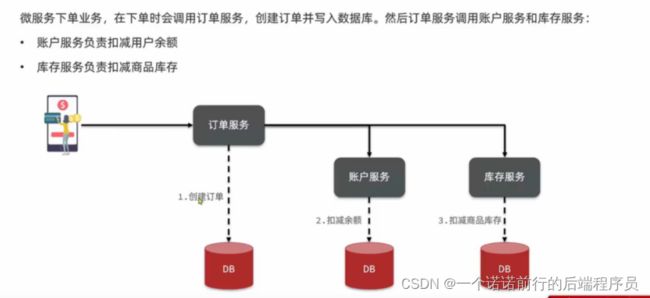
这个业务 就包含3个不同的微服务调用 每个微服务都有自己的数据库/独立的事务
我们最终希望的是事务一旦执行 每一个都的成功,如果失败的话 都的失败
但是能不能达成这种情况
基于业务发生的调用
正常情况下
order(订单创建)---->account(余额扣减)---->storage(库存扣减)
如果有一个失败 就代表全部失败了
库存失败了 但是余额扣减了 这个时候事务的状态不是一致的
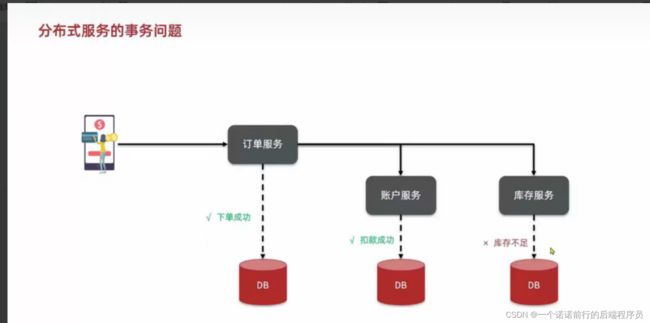
为什么会出现这种情况?
因为我们每一个服务都是独立的,库存抛异常,我账户是不知道的
每一个服务是独立的所以他们的事务也是独立的,我订单和账户业务结束了,我就commit了
我都提交了怎么做的回滚
所以最终就没有达成数据状态一致 此时就出现了分布式事务的问题
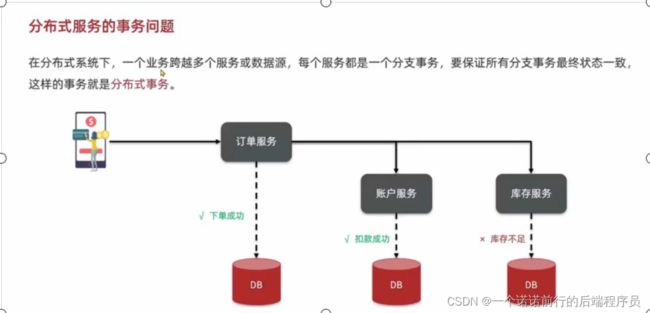
我们要保证所有分支事务都成功,或者所有分支事务都失败
呢为什么分布式事务出现问题,就是因为各个服务/分布式事务之间互相是感知不到的
状态不能一致
怎么去解决分布式事务的问题
{
1、分布式事务产生的原因
2、分析解决思路
3、Seata底层原理 怎么解决分布式事务
4、动手实践了 利用seata框架 去解决我们的问题
}
1. 解决分布式事务的理论基础cap/base理论
C(一致性)
A(可用性)
P(分区容错性)

C(一致性): 如果我对node1节点进行了更改,为了满足一致性,我就要做数据同步 吧node1节点数据同步到node2上
只有及时完成数据同步,才可以满足一致性
A(可用性):如果此时node3不可用 整个集群是对外提供服务的 可以访问集群的node1以及node2
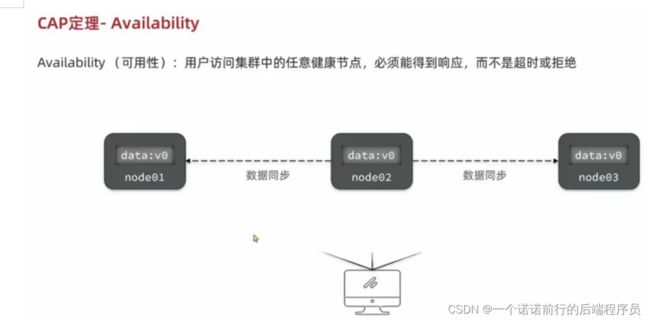
P(分区容错性):因为网络原因node3和(node1/node2)断开连接 .node1 node2正常连接 node感知不到
此时整个集群划分了2个分区了
如果此时insert 到node2 ,此时分区数据就会不一致,node3同步不了分区数据
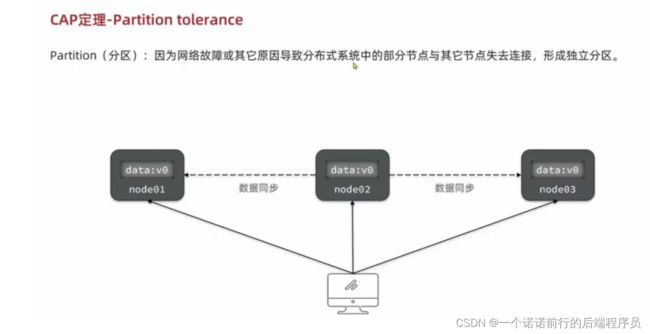
当网络出现分区时 可用性和一致性没有办法同时满足
但是分区是不可避免的 只要有一个分布式系统,节点之间一定是通过网络连接的
没有办法保证节点永远是健康的
分区一定会出现
要么C 要么A 没有办法同时满足

cap下在分布式系统中,分区是不可避免的,所以不得不在一致性和可用性之间做出选择
BASE理论

分布式事务包括什么问题
分支事务 有些成功 有些失败了.这个时候大家状态是不一致的
我们希望分布式事务中的每一个分支事务 大家最终都是成功的、或者失败的
状态是一致的.要么都成功 要么都失败
呢我们基于BASE理论怎么解决 AP 满足可用性 牺牲一致性

我们解决分布式事务都会基于ap和cp的思想去做
分布式事务的模型:
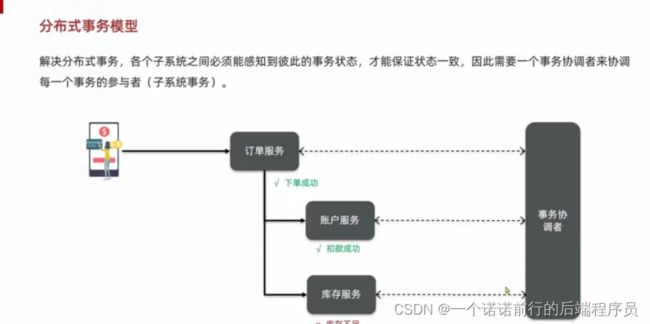
1.分支事务上报
2.事务些调整统一做回滚或者提交
每一个子系统的事务叫做分支事务 整个分布式事务叫做全局事务
事务协调者实际上就是协调各个分之事务状态的 让他们达成一致

以上就是我们解决分布式事务的思想和模型了
我们基于CAP定律和base理论 总结了分布式事务的解决思路和最后的模型
我们看看seata架构 看看seata架构和我们总结的模型有什么差别
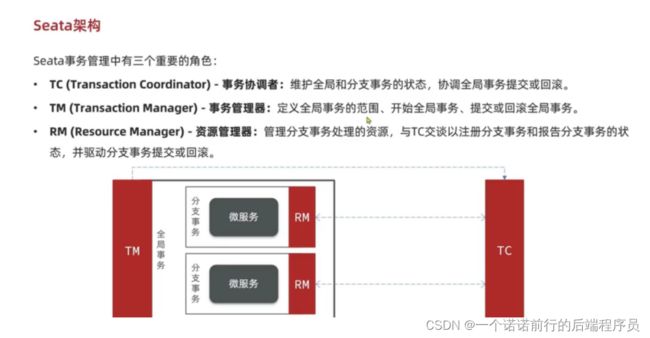
seata架构:
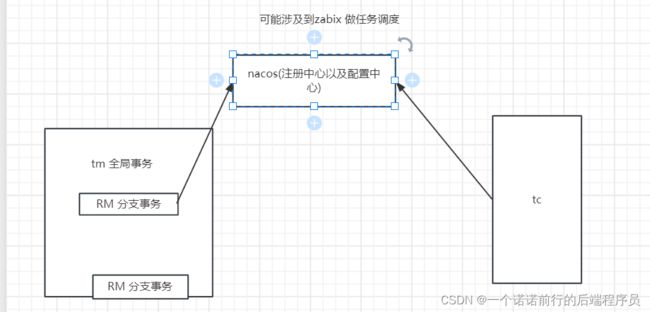
分布式seata:
3. tc 服务搭建(注册在注册中心中)
4. tm 开启全局事务
5. rm 注册分支事务 (rm 和tc 建立连接是在注册中心中寻找的) Rm和tm建立一个联系 必然通过注册中心去寻找 基于nacos注册
6. 让对应的rm 通过注册中心 找到对应的tc 服务
利用seata 去解决分布式事务的问题 seata中4中解决方案(xa,at,tcc,saga)
xa: 是一种规范 所有主流db 都支持xa
xa模式有什么优势和不足??
我们一阶段仅仅是执行事务而不提交
呢我们的事务还一致处于运行的状态
到了二阶段 等到所有的分支事务都执行完了 我们再一起提交
xa的工作原理
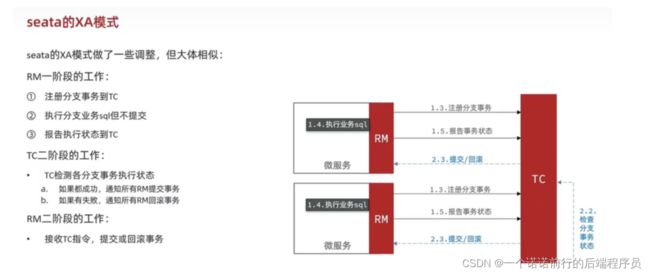
缺点就是:强一致性 二阶段再提交,但是你等的过程中要占用分布式锁,如果跨越分支事务
如果这个业务耗时较长这么多分支事务要耗时很久
占用数据库锁 别人都不能访问 可用性就降低了
第二个就是数据库要支持

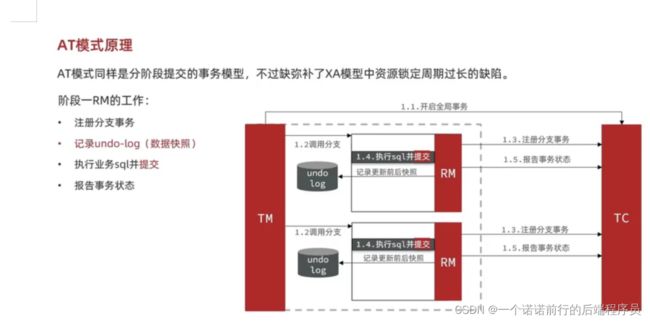
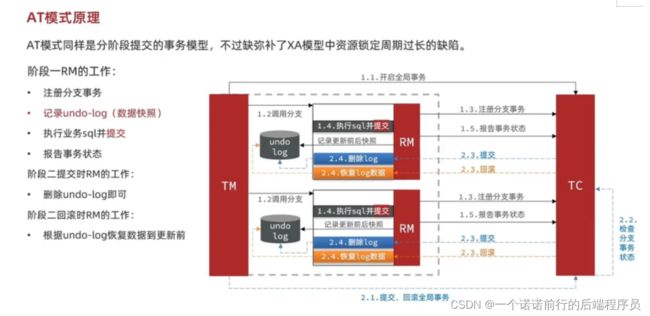
1.AT模式:at模式执行完业务sql后会直接提交事务,而不是等待因为他不是等待是立即提交了
所以他是没有对资源锁定了
2.所以他的性能方面会优于xa 此时的状态有成功的有失败的
3.at模式在执行业务sql之前会执行一个快照 如果出现问题了会依据快照恢复
第一阶段结束了 报告状态到tc 就可以了
AT:工作原理
at和tc的区别
如果一阶段有失败了 我基于log做数据恢复 数据一旦恢复 Log也没用了
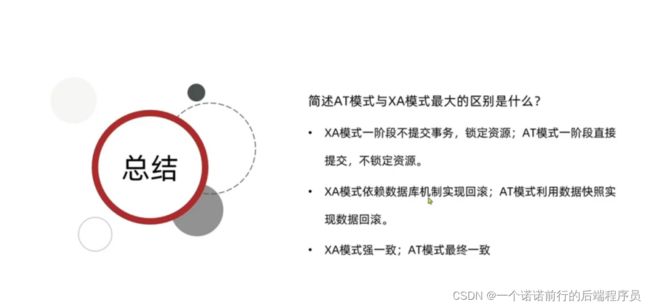
at模式 相对于xa来说 性能得到提升了
每天要让自己进行输出 让自己前进 哪怕前进一点点也可以